原核表达综述
- 格式:doc
- 大小:108.51 KB
- 文档页数:15
细菌能随环境的变化,迅速改变某些基因表达的状态,这就是很好的基因表达调控的实验型。
人们就是从研究这种现象开始,打开认识基因表达调控分子机理的窗口的。
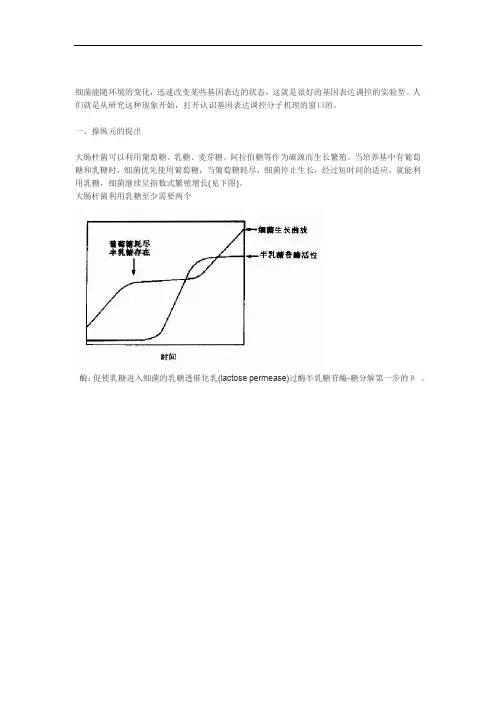
一、操纵元的提出大肠杆菌可以利用葡萄糖、乳糖、麦芽糖、阿拉伯糖等作为碳源而生长繁殖。
当培养基中有葡萄糖和乳糖时,细菌优先使用葡萄糖,当葡萄糖耗尽,细菌停止生长,经过短时间的适应,就能利用乳糖,细菌继续呈指数式繁殖增长(见下图)。
大肠杆菌利用乳糖至少需要两个酶:促使乳糖进入细菌的乳糖透催化乳(lactose permease)过酶半乳糖苷酶-糖分解第一步的β。
见下图)(β-galactosidase)(-β在环境中没有乳糖或其他β-半乳糖苷时,大肠杆菌合成细菌大量合成分钟后,2-3半乳糖苷酶量极少,加入乳糖半乳糖苷酶,其量可提高千倍以上,在以乳糖作为唯一β-半乳糖苷酶量可占到细菌总蛋白量的碳源时,菌体内的β-。
在上述二阶段生长细菌利用乳糖再次繁殖前,也能测3%半乳糖苷酶活性显著增高的过程。
这种典型的β-出细菌中诱导现象,是研究基因表达调控的极好模型。
和Jacob针对大肠杆菌利用乳糖的适应现象,法国的1961于Monod等人做了一系列遗传学和生化学研究实验,学说,如下图所示。
下图中年提出乳糖操纵元(lac operon)是转录是大肠杆菌编码利用乳糖所需酶类的基因,P、za开始的P结合而阻碍从O能与R,R编码合成调控蛋白i所需要的启动子,调控基因a、z基因转录,所以O就是调节基因开放的操纵序列,乳糖能改变R结构使其不能与P结合,因而乳糖浓度增高时基因就开放,转录合成所编码的酶类,这样大肠杆菌就能适应外界乳糖供应的变化而改变利用乳糖的状况,这个模型是人们在科学实验的基础上第一次开始认识基因表达调控的分子机理。
二、操纵元(operon)的基本组成乳糖操纵元模型被以后的许多研究实验所证实,对其有了更深入的认识,并且发现其他原核生物基因调控也有类似的操纵元组织(见下图),操纵元是原核基因表达调控的一种重要的组织形式,大肠杆菌的基因多数以操纵元的形式组成基因表达调控的单元。
原核表达步骤原核表达先要将基因克隆到原核表达载体上,然后通过转化到JM109或BL21等菌株中,诱导表达蛋白,然后进行蛋白纯化。
本实验方案的前提是,目的基因已克隆到载体,并已转进入JM109菌株中。
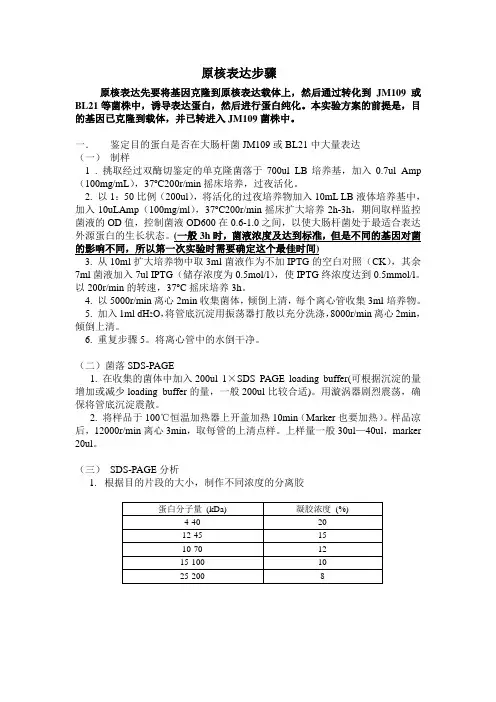
一.鉴定目的蛋白是否在大肠杆菌JM109或BL21中大量表达(一)制样1 . 挑取经过双酶切鉴定的单克隆菌落于700ul LB培养基,加入0.7ul Amp (100mg/mL),37o C200r/min摇床培养,过夜活化。
2. 以1:50比例(200ul),将活化的过夜培养物加入10mL LB液体培养基中,加入10uLAmp(100mg/ml),37o C200r/min摇床扩大培养2h-3h,期间取样监控菌液的OD值,控制菌液OD600在0.6-1.0之间,以使大肠杆菌处于最适合表达外源蛋白的生长状态。
(一般3h时,菌液浓度及达到标准,但是不同的基因对菌的影响不同,所以第一次实验时需要确定这个最佳时间)3. 从10ml扩大培养物中取3ml菌液作为不加IPTG的空白对照(CK),其余7ml菌液加入7ul IPTG(储存浓度为0.5mol/l),使IPTG终浓度达到0.5mmol/l。
以200r/min的转速,37o C摇床培养3h。
4. 以5000r/min离心2min收集菌体,倾倒上清,每个离心管收集3ml培养物。
5. 加入1ml dH2O,将管底沉淀用振荡器打散以充分洗涤,8000r/min离心2min,倾倒上清。
6. 重复步骤5。
将离心管中的水倒干净。
(二)菌落SDS-PAGE1. 在收集的菌体中加入200ul 1×SDS PAGE loading buffer(可根据沉淀的量增加或减少loading buffer的量,一般200ul比较合适)。
用漩涡器剧烈震荡,确保将管底沉淀震散。
2. 将样品于100℃恒温加热器上开盖加热10min(Marker也要加热)。
样品凉后,12000r/min离心3min,取每管的上清点样。


原核表达系统的工作原理原核表达系统是指利用原核生物(如大肠杆菌等)来表达外源蛋白质的工具,在生物技术和基因工程领域应用十分广泛。
原核表达系统通过重组DNA技术将目标基因插入原核细胞的表达载体中,并利用细胞自身的代谢机制,将目标蛋白质大量表达出来。
本文将详细介绍原核表达系统的工作原理。
1. 原核表达系统的基本构成原核表达系统的基本构成包括表达载体和宿主细胞两部分。
表达载体是一种重组DNA分子,通常包括以下基本组成成分:(1)起始位点(起始密码子):在大肠杆菌中通常为AUG。
(2)表达基因:包括编码目标蛋白质的DNA序列和转录启动子、转录终止子等序列。
(3)选择标记:旨在筛选出带有目标基因的细胞,并提高表达效率。
常用的选择标记有抗生素抵抗基因和荧光标记基因等。
(4)复制起点:能够使表达载体在宿主细胞内进行自我复制,提高表达效率。
宿主细胞则是一种能够实现表达载体遗传信号转录、翻译和合成目标蛋白质的生命体。
2. 原核表达系统的工作流程原核表达系统通过以下几个步骤来实现目标蛋白质的表达:(1)制备表达载体将目标基因插入表达载体中,构建成重组DNA分子。
(2)转化宿主细胞将制备好的表达载体转化(transform)到宿主细胞内。
转化过程中,表达载体通过电击、热激或溶菌酶处理等方法,被宿主细胞吞噬并与其细胞质融合。
(3)表达基因转录和翻译转录因子识别插入表达载体的启动子序列,调节基因在宿主细胞内能够合成被表达的mRNA。
转录后的mRNA与核糖体结合,开始翻译,合成蛋白质。
(4)目标蛋白质的后处理和纯化将宿主细胞内表达的蛋白质从培养基或细胞酶中提取出来。
通常采用离心、过滤或柱层析等方法,对蛋白质进行分离和纯化。
3. 原核表达系统的优缺点原核表达系统在生物技术和基因工程领域应用广泛,主要因为其有以下的优缺点。
(1)优点①高效:能够表达大量的目标蛋白质,通常能够达到10%以上的蛋白质总产量。
②简便:操作简便,不需要昂贵的设备,很容易进行规模化操作。

原核表达步骤原核表达是指在原核生物体内将基因转录成RNA,再将RNA翻译成蛋白质的过程。
本文将详细介绍原核表达的步骤。
1. 转录DNA的双链结构被酶RNA聚合酶解开,从而形成mRNA链。
RNA聚合酶沿着DNA模板链移动,将mRNA链合成在一起。
在这个过程中,RNA聚合酶根据DNA模板链上的碱基序列,选择正确的核苷酸,将其加入到正在合成的mRNA链上。
2. 剪接在细胞核内,mRNA链是在原核生物上转录的。
这些mRNA链可能包含顺式调节区域(UTR)和内含子区域。
在剪接过程中,内含子被剪除,UTR被保留下来。
这个过程由小核RNA(snRNA)和蛋白质共同完成。
3. 翻译翻译是将mRNA链转化为氨基酸序列的过程。
翻译是在核糖体中完成的。
核糖体是由rRNA和蛋白质组成的复合体。
核糖体通过识别mRNA上的起始密码子来开始翻译过程。
起始密码子是AUG。
核糖体将氨基酸连接在一起,直到遇到终止密码子。
终止密码子分别是UAA,UAG和UGA。
翻译完成后,成品蛋白被释放出来。
4. 后翻译修饰在翻译完成后,蛋白质可能需要进行后翻译修饰。
这些修饰可以包括磷酸化,甲基化,硫化,酰化和糖基化等。
这些修饰可以改变蛋白质的结构和功能,从而影响其生物学活性。
5. 折叠蛋白质被合成后,需要进一步折叠成其最终形态。
这个过程由分子伴侣和蛋白酶等分子机器完成。
分子伴侣可以协助蛋白质正确地折叠。
蛋白酶可以降解不正确折叠的蛋白质,防止它们对细胞造成损害。
6. 定位在折叠完成后,蛋白质需要被定位到其最终的位置。
这个过程由信号肽和其他分子机器完成。
信号肽是一段氨基酸序列,可以将蛋白质定位到细胞膜,内质网,线粒体等亚细胞结构中。
原核表达是一个复杂的过程,包括转录,剪接,翻译,后翻译修饰,折叠和定位。
这些步骤需要各种不同的分子机器和分子信号来协同完成。
理解原核表达的步骤可以帮助我们更好地理解生物学过程,从而为生命科学的研究和应用提供基础。




原核表达之目的基因克隆1.了解实验课题对目的蛋白的要求,包括:目的蛋白分子量有多大,表达目的(是蛋白结晶、药剂结合还是制备抗体,不同目的对蛋白要求不同);是否要其可溶;是胞内表达还是分泌表达,是组成型表达还是诱导型表达;另外,还要了解蛋白表达后需要采用什么样的方式进行纯化,纯化标签有多大,蛋白纯化后是否需要将标签去除(即标签的存在是否会影响蛋白的活性)。
还要对目的蛋白进行稀有密码子(仅限于真核生物基因通过原核表达系统表达时参考,注意稀有密码子的多少,位置5位或3位,稀有密码子是否成串出现等)和可溶性网上预测等。
稀有密码子预测网址:.ru/eng/scripts/01_11.html/~mmaduro/codonusage/usage.htm/RACC//~sumchan/caltor.html原核表达蛋白可溶性预测网址:/综合以上,选取合适的表达载体及宿主菌(做原核表达前对各种载体及宿主菌的充分了解是必须的,建议首先应阅读《默克原核表达宝典》)。
注意:不是所有的标签都是用来纯化蛋白的,有的标签有促进蛋白溶解的作用,有的则是二硫键形成或利于表达后蛋白的检测。
一般我们最常用的是胞内诱导型表达(即蛋白翻译后是存在于细胞内,通过加诱导物的方法来控制表达水平)。
2.搜索要表达的目的基因的序列,根据其编码区序列来设计引物;注意:要注意在引物上加入限制性内切酶识别位点(首先应分析蛋白编码区内是否含有相同的内切酶识别位点),并通过查阅资料看两种酶(上下游引物分别加入酶切位点)是否可以在同一反应体系中起作用,并注意标签序列是在N端还是在C端,若要在C 端保留标签,则需要将下游引物的终止密码子替换掉;若要在引物上引入标签序列,则引物上应加入标签序列碱基(即在上游引物或下游引物处引入His的密码子);另外,还要注意引物不能造成蛋白的编码框发生改变;1,2步的分析至关重要,只有在完成前两步的工作后才可以进行后续的实验操作。

实验九表达质粒的构建与诱导表达第一节原核表达概述基因工程的研究一方面是获得基因的表达产物,另一方面是研究基因结构与功能的关系,最终都涉及目的基因的表达问题。
表达载体(express vector)是指本身携带有宿主细胞基因表达所需的调控序列,能使克隆的基因在宿主细胞内进行转录与翻译的载体。
也就是说,克隆载体只是携带外源基因,使其在宿主细胞内扩增;表达载体不仅使外源基因扩增,还使其表达。
表达载体在基因工程中具有十分重要的作用。
外源基因在宿主(受体)细胞内是否表达以及表达水平受到许多因素(调控元件)的制约:1.正确的阅读框架为了获得正确编码的外源蛋白,外源基因编码区在插入表达质粒中原核基因编码区时,阅读框架应保持一致。
阅读框架是由每三个核苷酸为一组连接起来的编码序列,外源基因只有在它与载体DNA的起始密码相吻合时,才算处于正确的阅读框架之中,从而表达融合蛋白,使外源蛋白与宿主蛋白相融合。
2.目的基因有效转录的启动子启动子(promoter) 是DNA链上一段能与RNA聚合酶结合并能起始mRNA合成的序列,它是基因表达不可缺少的重要调控序列。
原核启动子是由两段彼此分开且又高度保守的核苷酸序列组成的,分别称为一35区和一10区。
一35区的序列为TTGACA,一10区序列为TATAAT。
此两序列之间的最佳间距为17 bp。
可与RNA聚合酶结合,并指导该酶在正确的转录部位开始合成mRNA。
由于细菌RNA聚合酶不能识别真核基因的启动子,因此原核表达载体必须用原核启动子带动真核基因在原核生物中转录。
原核表达载体启动子的转录常常是可以控制的,即一般情况下不转录,而受诱导剂诱导时就能转录,带动外源基因的高效表达。
目前常用的启动子:如大肠杆菌的lac启动子是乳糖操纵子的启动子,受la cⅠ编码的阻遏蛋白调节控制;trp 等启动子是色氨酸操纵子启动子,受trp R编码的阻遏蛋白调节控制;tac启动子,由lac启动子的一l0区和trp 启动子的一35区融合而成,汇合了lac和trp两者优点,是一个很强的启动子,受lacⅠ编码的阻遏蛋白调节;lacUV 5启动子是经紫外线诱变改造后的lac启动子,该启动子失去CAP和cAMP的正调控,只要有乳糖或IPTG 存在时就能够启动转录;噬菌体的λP L、R启动子是λ噬菌体左、右向启动子,是一个温度敏感的阻遏蛋白受温度调控的很强的启动子;T7噬菌体启动子,比大肠杆菌启动子强得多,并且十分专一,只被T7 RNA聚合酶所识别;SV40启动子、多角蛋白启动子以及花椰菜花叶病毒(CaMV)启动子。
原核表达技术原核表达技术是一种用于原核生物体中表达外源基因的技术。
通过将外源基因导入原核生物体中,并使其在细胞内得到表达,可以实现对目标基因的研究和利用。
原核表达技术在生物科学研究、生物工程、医学等领域具有广泛的应用前景。
原核表达技术的基本原理是将外源基因导入原核生物体中,并将其与宿主细胞的基因表达系统连接起来。
这样,外源基因就可以在宿主细胞内得到转录和翻译,从而表达出编码的蛋白质。
为了实现这一目标,研究人员通常需要构建一个包含外源基因的表达载体,并将其导入到宿主细胞中。
在构建表达载体时,研究人员通常会选择合适的启动子、转录终止子和调节元件等,以确保外源基因在宿主细胞中得到高效的转录和翻译。
此外,还可以通过引入信号肽序列等方式,使得目标蛋白质能够在宿主细胞中得到正确的翻译和定位。
在导入表达载体到宿主细胞中时,常用的方法有化学法转化、电转化和质粒共转化等。
其中,化学法转化是最常用的方法之一。
通过将表达载体和宿主细胞一起处理化学试剂,使得宿主细胞的细胞壁发生变化,从而导致表达载体进入细胞内。
电转化则是利用电场脉冲的作用,使得表达载体能够穿过宿主细胞的细胞膜进入细胞内。
质粒共转化是将表达载体与另一个能够进行共转化的质粒一起导入宿主细胞中,以提高转化效率。
一旦表达载体成功导入宿主细胞,外源基因就可以开始在细胞内得到表达。
为了检测外源基因的表达情况,研究人员通常会选择合适的检测方法,如聚合酶链反应(PCR)、蛋白质印迹、酶活性分析等。
通过这些方法,可以确定外源基因是否得到了正确的转录和翻译,并且能够得到目标蛋白质的定量和活性信息。
原核表达技术在生物科学研究中有着广泛的应用。
例如,通过原核表达技术可以实现对目标基因的功能研究。
研究人员可以通过构建不同的表达载体,将目标基因在宿主细胞中进行过量表达或靶向抑制,进而研究其在细胞生理过程中的作用机制。
另外,原核表达技术还可以用于生物工程领域。
研究人员可以利用原核表达技术生产大量的重组蛋白质,以满足药物研发和工业生产的需求。
原核表达技术原核表达技术是一种用于在原核生物中实现外源基因表达的技术。
原核生物是一类没有真核生物细胞核的微生物,包括细菌和古菌。
原核表达技术的发展为基因工程和生物技术领域提供了重要的工具和平台。
原核表达技术的基本原理是将目标基因转移到原核生物宿主细胞中,并在宿主细胞内进行转录和翻译,从而实现目标基因的表达。
这一过程通常包括以下几个步骤:选择适当的表达载体、构建重组表达载体、转化宿主细胞、选择阳性克隆并进行表达分析。
在选择适当的表达载体时,需要考虑载体的大小、复制起点、选择标记和表达调控元件等因素。
常用的表达载体包括质粒和噬菌体。
质粒是一种环状的DNA分子,可以在宿主细胞中自主复制并表达外源基因。
噬菌体则是一种病毒,可以利用宿主细胞的复制和转录机制来实现基因的表达。
构建重组表达载体是原核表达技术中的关键步骤。
通过酶切和连接技术,将目标基因插入到表达载体中的适当位置,确保基因的正确表达。
此外,还可以利用引物设计和PCR技术来扩增目标基因,以获得足够多的DNA材料。
转化宿主细胞是将重组表达载体导入原核生物宿主细胞的过程。
转化方法主要包括化学转化、电转化和热激转化等。
其中,化学转化是最常用的方法,通过改变细菌细胞壁的通透性,使得DNA能够进入细胞内。
选择阳性克隆并进行表达分析是对转化后的细菌进行筛选和鉴定。
常用的筛选方法有抗生素筛选和荧光筛选,通过检测细菌对抗生素的抗性或荧光蛋白的表达情况,可以筛选出带有目标基因的阳性克隆。
表达分析则可以通过蛋白质电泳、酶活性测定和免疫印迹等技术,来验证目标基因的表达水平和功能。
原核表达技术具有许多优点,使其成为研究和应用领域的重要工具。
首先,原核生物的生长速度快,培养成本低,易于大规模生产目标蛋白。
其次,原核表达系统可以实现对目标蛋白的定向表达和高效纯化,为后续的研究和应用提供了便利。
此外,原核表达系统还可以用来研究和揭示蛋白的结构和功能,以及进行药物筛选和疫苗研发等。
如何做原核表达人们合成与生物相关的物质是从尿素开始的,1828年,德国化学家维勒人工合成了存在于生物体的这种有机物。
在1960年我国科学家采用化学方法首次成功地合成了具有生物活性的蛋白质——胰岛素。
随着内切酶的发现和基因工程技术的发展,人们发现用各种不同的载体在原核、真核系统中进行蛋白表达更为行之有效。
而这其中大肠杆菌表达系统发展得最为迅速、成熟。
原核表达具有操作方便、快捷,需时较短,表达量大,适合工业化生产等优点。
虽然也有缺少糖基化和表达后加工等问题,当有了其它多种表达系统后,原核系统仍是我们合成外源蛋白的首选。
在网上看到有人把原核表达技术分成四个等级:初次尝试扫盲、乱棍打枣入门、系统优化中级和自成一体高手,觉得十分有意思。
但是根据笔者自己的经验以及耳闻目睹的一些经历告诉我:做表达?那是谋事在人,成事在天。
有时候你把克隆做出来了,双酶切鉴定没问题,测序没问题,可是就是看不到表达带。
原因当然可以分析,实验也是可以改进,但是窜改一下戈尔泰的话:“成功的实验都是一样的,失败的实验各有各的不幸。
”在实验遇到瓶颈的时候要如何进行分析,找到问题的症结是我们的实验关键所在。
在准备进行原核表达的时候需要考虑的因素很多,市面上可供选择的载体、菌株也很多,要如何进行正确的选择,找到适合自己的载体是十分重要的。
所以,现在要对目前常用的一些载体进行介绍,让我们对其相关产品及其表达原理进行了解,以方便实验设计。
首先来一些大肠杆菌表达的基本概念:一个完整的表达系统通常包括配套的表达载体和表达菌株,如果是特殊的诱导表达还包括诱导剂,如果是融合表达还包括纯化系统或者Tag检测等等。
选择表达系统通常要根据实验目的来考虑,比如表达量高低,目标蛋白的活性,表达产物的纯化方法等等。
主要归结在表达载体的选择上。
表达载体:我们关心的质粒上的元件包括启动子,多克隆位点,终止密码,融合Tag(如果有的话),复制子,筛选标记/报告基因等。
通常,载体很贵,我们可以通过实验室之间交换得到免费的载体。
原核表达蛋白镍离子亲和纯化-概述说明以及解释1.引言1.1 概述概述原核表达是一种重要的蛋白质表达方法,它在生物学和生物技术领域被广泛应用。
原核表达系统通常包括大肠杆菌、酵母和其他细菌等微生物,其表达效率高、表达周期短、操作简便,因此备受研究者青睐。
然而,由于细胞内含有大量的内源性蛋白和杂质,常规方法无法有效地纯化目标蛋白。
为了解决这一问题,科学家们开发了各种蛋白纯化方法。
其中,镍离子亲和纯化技术因其高选择性和高效性而备受关注。
镍离子亲和纯化的原理是基于镍离子(Ni2+)与某些蛋白的特定结构域(如组织因子蛋白A标签、组织因子蛋白S标签和组织因子蛋白H标签等)之间的特异性配位作用。
通过构建一定的表达载体,将含有目标蛋白的基因与镍离子亲和柱(如Ni-NTA柱)结合,可以实现目标蛋白在细胞裂解液中的高效富集。
在原核表达蛋白镍离子亲和纯化的方法中,首先需要构建包含目标蛋白编码序列的表达载体,并将其转化到适当的宿主细胞中。
然后,通过诱导表达剂(如异丙基β-D-硫代半乳糖苷)刺激蛋白的大量合成。
接着,使用一系列的细胞破碎方法,如超声波处理或高压细胞破碎仪,将细胞内的目标蛋白释放出来。
最后,通过镍离子亲和柱,将目标蛋白与杂质分离,得到纯化的目标蛋白。
镍离子亲和纯化在原核表达蛋白中具有广阔的应用前景。
通过该方法,可以高效地纯化大量的目标蛋白,为后续的结构解析、功能研究和药物开发提供了可靠的材料基础。
然而,该方法也存在一些局限性和可改进之处,例如对于某些难以表达的蛋白,亲和纯化的效率可能较低;此外,在某些情况下,镍离子柱可能与非特异性结合的蛋白相互作用,导致纯化产物的纯度下降。
综上所述,原核表达蛋白镍离子亲和纯化技术是一种高效、可靠的蛋白纯化方法,具有广泛的应用前景。
随着该技术的不断发展和改进,相信将为蛋白研究领域提供更多更好的工具和方法。
文章结构部分的内容可以如下所示:1.2 文章结构本文将按照以下结构进行论述:第一部分是引言。
原核基因的表达原核基因的表达是指在原核生物中,基因通过转录和翻译的过程转化为蛋白质的过程。
原核基因的表达是生物体正常生理活动的基础,对维持细胞的功能和生存至关重要。
原核基因的表达主要包括两个过程:转录和翻译。
转录是指DNA 的信息通过RNA聚合酶酶的作用,转录为mRNA的过程。
在原核生物中,转录发生在细胞质中,无需核糖体的参与。
转录的过程包括启动、延伸和终止三个阶段。
启动阶段是指RNA聚合酶与DNA 结合,形成开放复合物的过程。
延伸阶段是指RNA聚合酶沿着DNA链进行移动,合成mRNA链的过程。
终止阶段是指RNA聚合酶遇到终止信号,停止合成mRNA链的过程。
翻译是指mRNA的信息通过核糖体的作用,转化为蛋白质的过程。
在原核生物中,翻译发生在细胞质中的核糖体上。
翻译的过程包括起始、延伸和终止三个阶段。
起始阶段是指核糖体与mRNA的起始密码子结合,形成起始复合物的过程。
延伸阶段是指核糖体沿着mRNA链进行移动,合成蛋白质的过程。
终止阶段是指核糖体遇到终止密码子,停止合成蛋白质的过程。
原核基因的表达受到多种调控因子的调控。
其中包括启动子、转录因子和启动子区域的甲基化等。
启动子是指位于基因上游的DNA 序列,与RNA聚合酶结合,启动转录过程。
转录因子是指能够结合到启动子上的蛋白质,调控转录的起始和速率。
启动子区域的甲基化是指DNA上的甲基基团与转录因子结合,影响启动子的结构和功能。
原核基因的表达还受到环境因素的影响。
一些环境条件,如温度、pH值和营养物质的浓度等,可以改变细胞内的代谢状态,进而影响基因的表达。
例如,一些细菌在低温下可以产生一种特殊的蛋白质,帮助它们适应寒冷环境。
原核基因的表达异常会导致细胞功能的紊乱甚至细胞死亡。
例如,某些细菌感染病原体时,病原体的基因可以通过改变宿主细胞的基因表达来逃避免疫系统的攻击。
此外,某些基因的表达异常还与一些遗传疾病的发生相关。
例如,某些突变导致基因的表达异常,从而引起先天性疾病。
[Merck推荐]原核表达秘笈之宿主菌株选择指南在原核蛋白表达过程中,选择构建一个合适原核表达体系需要综合考虑3大因素:表达载体、宿主菌株、表达诱导条件,以获得最满意的表达效果。
事实上,在平时的实验中,最容易被忽视的就是宿主菌的选择——多数人会直接选择自己实验室曾经用过的表达菌株,或者是载体配套的菌株,而不去追究原因——即使表达结果不佳,大多在表达条件和载体上找原因,也不会考究菌株的选择是否适合。
作为原核表达的宿主,对外源基因的表达会产生一定的影响,是勿庸置疑的。
每一个宿主细胞都像一个微观的小工厂,按照细胞固有的程序完成“你给它们安排的生产任务”——因为很难亲眼观察微观世界中表达是如何进行的,当出现问题时,我们需要经验判断问题所在。
宿主细胞对原核表达可能会产生哪些影响呢?知其然还要知其所以然。
比如,菌株内源的蛋白酶过多,可能会造成外源表达产物的不稳定,所以一些蛋白酶缺陷型菌株往往成为理想的起始表达菌株。
堪称经典的BL21系列就是lon和ompT蛋白酶缺陷型,也是我们非常熟悉的表达菌株。
大名鼎鼎的BL21(DE3)融源菌则是添加T7聚合酶基因,为T7表达系统而设计。
真核细胞偏爱的密码子和原核系统有不同,因此,在用原核系统表达真核基因的时候,真核基因中的一些密码子对于原核细胞来说可能是稀有密码子,从而导致表达效率和表达水平很低。
改造基因是比较麻烦的做法,Rosetta 2系列就是更好的选择——这种携带pRARE2质粒的BL21衍生菌,补充大肠杆菌缺乏的七种(AUA, AGG, AGA, CUA, CCC, GGA 及CGG)稀有密码子对应的 tRNA,提高外源基因、尤其是真核基因在原核系统中的表达水平。
(已经携带有氯霉素抗性质粒)当要表达的蛋白质需要形成二硫键以形成正确的折叠时,可以选择K–12衍生菌Origami 2系列,thioredoxin reductase (trxB) 和glutathionereductase (gor)两条主要还原途径双突变菌株,显著提高细胞质中二硫键形成几率,促进蛋白可溶性及活性表达。
(卡那霉素敏感)Rosetta-gami™ 2则是综合上述两类菌株的优点,既补充7种稀有密码子,又能够促进二硫键的形成,帮助表达需要借助二硫键形成正确折叠构象的真核蛋白。
(卡那霉素敏感)Origami B是衍生自 lacZY突变的 BL21菌株,这个突变能根据IPTG的浓度精确调节表达产物,使得表达产物量呈现IPTG浓度依赖性。
(四环素敏感)在决定试用这些名字古怪的菌株时,有几个小Tips要注意的,一个是不同菌株有时已经携带某个质粒或者已经具有某种抗生素抗性,要注意自己的表达质粒是否能与之兼容。
比如Rosetta 2已经携带有氯霉素抗性质粒,不能再用氯霉素筛选等等。
原核表达个人秘笈:表达前的分析比什么都重要表达不同于其它一些实验,比如:提取质粒、PCR、电镜切片,这些人为控制的因素比较多,出问题相对来说也比较好分析。
表达呢,你把质粒克隆好啦,交给细胞,然后有些事情就不全是你要怎样就怎样了。
原核表达在表达当中来说还是比较简单,细菌培养条件简单、生长速度快,需要的仪器和培养基都比较便宜。
当然,它也存在一些缺乏高级修饰、细胞内部还原性过高等缺点。
原核表达从一开始的设计就非常重要,所谓好的开始是成功的一半。
做足准备功夫,可是省去很多将来后悔的事情。
首先,我们要根据是否要求可溶将载体分成两大类,如果希望可以同时尝试多种表达系统,也有许多商业化的系统供选择。
前面已经介绍过许多公司的商业化载体、菌株和多系统表达体系,现在我想先从自己的蛋白分析讲起。
同样的载体、同样的系统,很可能表达这个蛋白表达量奇高,但是另外一个就是做不出来,所以没有万能的载体,只有永恒的分析。
当然如果你的蛋白曾经在原核系统中成功表达出来那是最好的,选择同样的载体表达成功率会高很多。
如果没有也最好尝试找一些曾经表达过和你的蛋白拥有相类似结构的文献。
比如大部分含有哺乳动物src同源的SH2蛋白相互作用域的蛋白都是用pGEX系列载体表达出来的。
根据经验而言,含有较少半胱氨酸和脯氨酸的、平均大小为60kD的单体蛋白较容易表达。
在下面将列出几个影响表达的因素,大家可以在表达前根据这几个因素自己分析一下:1.翻译起始位点现在大部分的表达载体都提供起始位点,所以它已经把起始密码子与核糖体结合位点的距离进行优化了,一般情况下不需要自己再加,不过还是要留意载体图谱上是否注明有起始密码子和终止密码子2.GC含量表达序列中的GC含量超过70%的时候可能会降低蛋白在大肠杆菌中的表达水平。
GC含量可以利用DNA STAR、Vector NTI Suite等软件进行预测。
3.二级结构在起始密码子附近的mRNA二级结构可能会抑制翻译的起始或者造成翻译暂停从而产生不完全的蛋白。
如果利用软件分析DNA或RNA结构上有柄(stem)结构,并且结合长度超过8个碱基,这种结构会因为位点专一突变等因素而变得不稳定。
4.基因或者蛋白的大小一般说来小于5kD或者大于100kD的蛋白都是难以表达的。
蛋白越小,越容易被降解。
在这种情况下可以采取串联表达,在每个表达单位(即单体蛋白)间设计蛋白水解或者是化学断裂位点。
如果蛋白较小,那么加入融合标签GST、Trx、MBP或者其它较大的促进融合的蛋白标签就较有可能使蛋白正确折叠,并以融合形式表达。
对于另一个极端,大于60kD的蛋白建议使用较小的标签,如6×组氨酸标签。
对于结构研究较清楚的蛋白可以采取截取表达。
当然表达时要根据目的进行截取,如果是要进行抗体制备而截取,那么一定要保证截取的部位抗原性较强。
对于抗原性也可以利用软件分析,比如Vector NIT Suite或者一些在线软件,不过在分析之余也要认识到这是一种数据统计的结论,如果蛋白和免疫动物亲缘关系较远的话还是不妨一试的。
5.亲疏水性这也是一种经验之谈,相信经常做表达的人都发现表达亲水区域时表达量会比较高,如果你要表达一个膜蛋白,那么劝你做好长期抗战的准备吧。
有许多软件可以对氨基酸的亲疏水性进行分析,比如Vector NIT Suite,除此之外还可以利用在线跨膜区预测软件http://www.cbs.dtu.dk/services/TMHMM/ 对跨膜区进行预测。
对于自己表达的蛋白有所了解后就可以开始对载体进行选择了,目前商业化的载体基本上包含以下几个元件:除了上面标出的元件外还需要有复制起点,它对于控制质粒的拷贝数非常重要;另外就是筛选标记了,比如蓝白斑筛选的lacZ,各种抗生素标记。
在以上几个元件中,我们需要注意的是负责调节与启动的元件,也就是调控子和启动子。
其中启动子对于蛋白表达的速度起着举足轻重的作用,它与最终蛋白的表达量、是否可融密不可分。
这里,对于世面上广泛销售的几种原核表达载体使用的启动子进行总结。
启动子来源调控手段(浓度)强度LacUV5 乳糖操纵元lacI/IPTG (0.1-1mM) 强Trp 色氨酸操纵元trpR 3-β-吲哚丙烯酸强Tac 结合了色氨酸启动子的-35lacI/IPTG (0.1-1mM) 强序列和乳糖启动子的-10序列PLλ噬菌体λcI阻遏物/温度强噬菌体T5 T5噬菌体lacI/IPTG (0.1-1mM) 强pBAD 阿拉伯糖操纵元AraBAD/阿拉伯糖(1μm-10mM)严谨T7 T7 RNA聚合酶lacI/IPTG (0.1-1mM) 非常强乳糖操纵子是应用最广泛的调控模式,除了IPTG这种化学诱导方式之外还有利用吲哚丙烯酸和阿拉伯糖的化学诱导。
如果你害怕这些化学物质会损害细菌的生长,那么你可以尝试利用温度诱导的载体,如:pDH2。
它利用PL启动子,在温度上升到42℃后进行诱导表达。
可以看到在所有启动子里属T7启动子最强,它可以将大肠杆菌的资源最大程度地调用过来表达外源蛋白。
这样一些难表达的蛋白都可以在pET系统里面表达出来,但是是不是越强就越好呢?如果你需要表达蛋白是可溶的,那么T7启动子就不那么适合了。
较弱的启动子转录速度较慢,这样对于表达可溶、稳定、完整的蛋白比较有利。
Novagen可以说是的pET系统是最王牌的T7启动子表达系统,可是当T7启动子的强启动效应不受欢迎的时候怎么办呢?在这里给读者留个小小的疑问,看看大家有没有仔细看笔者写的Novagen篇。
提示一下,虽然它转录速度快,但是可以控制它的拷贝数,又或者是……利用这些原理Novagen载体也可以毒性高的外源蛋白。
载体上除了启动子这个需要注意之外,另外一个就是标签了。
很多标签是为了增加蛋白的可溶性,也有一些是为了方便鉴定表达产物,所以在表达时可以选择加标签。
是否加标签要看个人需要,笔者认为如果是表达一个人家没表达过的蛋白最好还是加标签,这样方便将来鉴定。
如果从经济角度考虑最好加入6×组氨酸标签,笔者曾经以为加什么标签都无所谓(前提是不需要融合表达),结果加了个Novagen的T7·Tag,等到鉴定的时候发现单抗那么贵。
而且还不好买的,一些较少人用的标签会让你很伤脑筋。
这也是表达前要准备的功课之一哦。
好了,如果你选好了载体,那么下一步就是设计引物的。
相信大多数人都是利用PCR把目的基因调出来的吧。
设计引物可以使用一下两个软件,Primer Premier或者Oligo。
如果要表达全长,其实也就没那么多要考虑,从一头一尾找至少8个匹配序列在加上与载体匹配的序列就可以了。
不过,我还是有以下几点提醒一下各位:1.这一点其实很容易理解,但是有时也容易被遗忘。
那就是先查查表达外源片段中含有什么内切酶位点,不要设计重了,否则酶切时发现怎么老是有预期外的小片段出现。
2.根据载体上的酶切位点设计引物,现在许多类似T载原理的克隆方法也可以应用到原核表达中了,如果T载克隆方法要定向很多时候要多加4个碱基,设计引物时候可别忘了加。
在设计酶切位点的5’端不要忘了加保护碱基,不同内切酶所需的保护碱基不同,SalⅠ不需要保护碱基,EcoRⅤ需要1个,NotⅠ需要2个,HindⅢ最好有3个。
一般情况下,都设计2个。
3.注意启始密码子和终止密码子的读码框。
如果载体上有ATG可以不另外加了,但是通常ATG后不是紧跟外源片段的,如果中间含有载体序列,务必确定中间这段序列不会造成你外源序列的移码。
按情况需要,可以加1到2个碱基在引物中使读码框正确。
有始有终,同样正常的终止密码子才能保证蛋白的产出。
大部分载体也有终止密码子,如果你对载体的不放心,也可以在引物中设计上终止密码子,这样万无一失。
4.还有就是设计一对引物需要注意的地方:一对引物之间Tm值相差不宜过大,能一样最好;一对引物不宜形成发夹结构、互相配对,若配对时最好不要是G-C的结合(可以用软件分析);3'端以G、C结尾为宜等等。