完整版逻辑回归模型分析见解
- 格式:docx
- 大小:68.35 KB
- 文档页数:8

二元逻辑回归结果解读
在解读二元逻辑回归结果时,我们需要关注以下几个关键点:
1. 模型概述:首先,我们需要了解模型的基本信息,例如自变量和因变量的名称、模型的公式以及用于拟合模型的样本数量。
2. 模型系数:模型系数是二元逻辑回归结果的核心部分。
我们需要注意每个自变量的系数、标准误、z值和P值。
其中,系数表示自变量每变动一个单位,因变量发生变动的概率;标准误表示系数的标准差;z值表示系数的显著性水平,通常用于判断系数的真假;P 值表示当原假设为真时,发生这类统计推断的概率。
3. 模型假设检验:在二元逻辑回归中,我们通常使用似然比卡方检验(LR chi-square)来检验模型的整体拟合效果。
这个检验的原假设是所有自变量的系数都为零,如果拒绝原假设,则说明至少有一个自变量的系数不为零,即模型能够显著地解释因变量的变动。
4. 模型拟合优度:我们可以通过计算AUC(曲线下面积)来评估模型的拟合优度。
AUC越接近1,说明模型的预测准确性越高。
5. 自变量对因变量的影响:通过二元逻辑回归结果,我们可以判断自变量对因变量的影响方向和程度。
如果某个自变量的系数为正,说明该自变量与因变量呈正相关关系,即该自变量增加时,因变量发生的概率也会增加;如果某个自变量的系数为负,说明该自变量与因变量呈负相关关系,即该自变量增加时,因变量发生的概率会降低。
总之,在解读二元逻辑回归结果时,我们需要关注模型的假设检验、拟合优度以及各个自变量对因变量的影响方向和程度。
这些信息
可以帮助我们更好地理解模型的结果并对未来的预测提供参考。

logistic回归模型结果解读
x
一、 logistic回归模型结果解读
Logistic回归模型是一种分类数据模型,主要用于对不同类别的输出结果进行预测,因此,其结果解读也要以分类的形式来解释。
1、系数与因变量之间的关系
Logistic回归模型通过对因变量的分析,来推断被解释变量的概率。
结果中的系数提供了因变量与被解释变量之间的关系,比如我们可以分析不同系数值大小,从而获得因变量对被解释变量的影响程度,正相关的影响是系数的正值,反之是负值。
2、P值
P值是从回归结果中获取的,它可以反映特定因变量对被解释变量的重要性,P值越小,表明相对于其它因变量,该因变量对被解释变量影响越明显,则说明该因变量是重要因素。
3、R-Square和平均绝对值
R-Square是可决系数,它反映回归结果的好坏,R-Square的值越大,表明模型的预测效果越好,也就是越能够准确的来预测被解释变量的值。
平均绝对值也是可以用来判断模型好坏的指标,它比较每个样本的预测值和实际值之间的误差,值越小则表示模型的预测精度越高。
4、改进模型
可以通过以上结果,来判断模型的预测效果好坏,从而思考如何改进模型:比如可以进行特征选择,去掉系数值较小或者P值较大的因变量;也可以使用其它模型,如决策树或神经网络模型来进行比较,看哪一个模型对被解释变量的预测效果更好。


情感分析是一种通过对文本中的情感色彩和情感倾向进行识别和分析的技术。
它可以帮助人们了解大众对某一事件、产品或话题的态度和情绪,对于企业的市场调研、舆情监控、产品改进等方面有着重要的应用价值。
在情感分析中,逻辑回归模型是一种常用且效果较好的方法。
本文将介绍如何使用逻辑回归模型进行情感分析。
一、数据准备在使用逻辑回归模型进行情感分析之前,首先需要准备好相应的数据。
情感分析的数据通常是文本数据,可以是用户评论、社交媒体上的帖子、新闻文章等。
这些数据需要经过清洗和预处理,去除无关信息、标点符号、停用词等,保留文本的实质内容。
然后,需要对文本数据进行标记,即给每条文本打上情感极性标签,比如正面情绪为1,负面情绪为0,中性情绪为。
这样的标记有利于构建监督学习模型,比如逻辑回归模型。
二、特征提取在准备好标记的文本数据之后,接下来需要进行特征提取。
逻辑回归模型的输入是特征向量,因此需要将文本数据转化为特征向量。
常用的特征提取方法包括词袋模型、TF-IDF模型、词嵌入模型等。
其中,词袋模型将每个文本表示为一个向量,向量的每个元素对应一个词语,表示该词在文本中的出现次数或频率。
TF-IDF模型考虑了词语在整个语料库中的重要程度,可以更好地反映单词的重要性。
词嵌入模型则将每个词映射到一个低维语义空间中的向量表示,能够更好地捕捉词语之间的语义关系。
三、模型训练有了特征向量之后,就可以开始训练逻辑回归模型了。
逻辑回归模型是一种广义线性模型,可以用于处理二分类问题。
在情感分析中,可以将文本的情感极性视为一个二分类问题,利用逻辑回归模型来预测文本的情感极性。
在训练模型之前,需要将数据集划分为训练集和测试集,用训练集来训练模型,用测试集来评估模型的性能。
训练模型时,可以利用交叉验证等方法来调参,找到最优的模型参数。
四、模型评估训练好逻辑回归模型之后,需要对模型进行评估。
常用的评估指标包括准确率、精确率、召回率、F1值等。
这些指标可以衡量模型对正负样本的分类能力、预测准确性等。

逻辑回归分析方法逻辑回归是一种重要的统计方法,用于预测二元类型的因变量。
它用于研究因果关系或者建立分类模型,根据自变量的特征判断结果的概率。
本文将介绍逻辑回归的方法、应用领域以及优缺点。
一、逻辑回归方法1. 模型基础逻辑回归模型的核心是逻辑函数,也被称为Sigmoid函数。
它将自变量线性组合的结果映射到[0,1]之间的概率值。
逻辑函数的方程为:p(X) = 1 / (1 + e^(-βX))2. 模型参数估计逻辑回归使用最大似然估计方法来估计模型的参数。
最大似然估计寻找使得观察数据出现的概率最大的参数值。
通过最大化似然函数,可以得到模型的参数估计值。
3. 模型评估为了评估逻辑回归模型的性能,常用的指标包括准确率、精确率、召回率和F1分数。
准确率指模型正确分类的样本占总样本数的比例;精确率表示预测为正例的样本中实际为正例的比例;召回率是指实际为正例的样本中被预测为正例的比例;F1分数是综合了精确率和召回率的一个综合指标。
二、逻辑回归的应用领域1. 预测分析逻辑回归广泛用于预测分析中,如市场营销活动中的顾客响应预测、信用评分模型中的违约预测、医学研究中的疾病发生预测等。
2. 分类问题逻辑回归能够对二元分类问题进行建模,如判断电子邮件是否是垃圾邮件、预测患者是否患有某种疾病等。
3. 社会科学研究逻辑回归在社会科学领域中也有广泛的应用,例如解释投票行为、预测选民意向、分析商品购买决策等。
三、逻辑回归方法的优缺点1. 优点逻辑回归是一种简单而常用的统计方法,易于理解和实现。
它适用于处理二元分类问题,计算效率高。
2. 缺点逻辑回归假设了自变量和因变量之间的线性关系,无法应对复杂的非线性问题。
此外,对于存在多重共线性的数据,逻辑回归模型的结果可能不准确。
四、总结逻辑回归是一种重要的分析方法,可用于预测二元类型的因变量。
它通过逻辑函数将自变量映射到[0,1]之间的概率值,并通过最大似然估计方法来估计模型的参数。
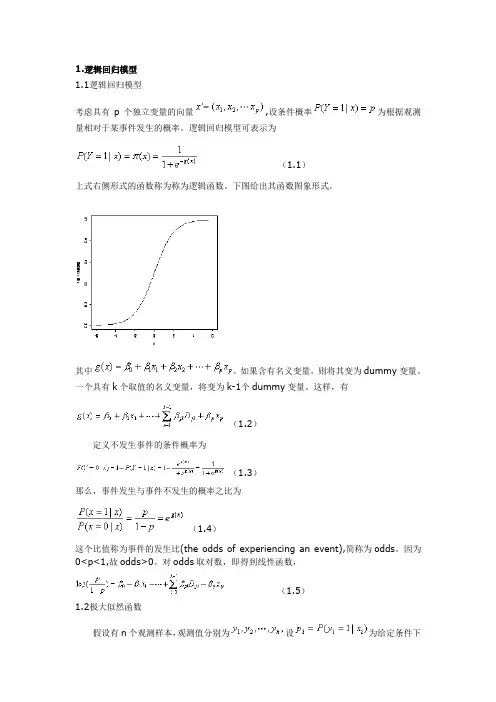
1.逻辑回归模型1.1逻辑回归模型考虑具有p个独立变量的向量,设条件概率为根据观测量相对于某事件发生的概率。
逻辑回归模型可表示为(1.1)上式右侧形式的函数称为称为逻辑函数。
下图给出其函数图象形式。
其中。
如果含有名义变量,则将其变为dummy变量。
一个具有k个取值的名义变量,将变为k-1个dummy变量。
这样,有(1.2)定义不发生事件的条件概率为(1.3)那么,事件发生与事件不发生的概率之比为(1.4)这个比值称为事件的发生比(the odds of experiencing an event),简称为odds。
因为0<p<1,故odds>0。
对odds取对数,即得到线性函数,(1.5)1.2极大似然函数假设有n个观测样本,观测值分别为设为给定条件下得到的概率。
在同样条件下得到的条件概率为。
于是,得到一个观测值的概率为(1.6)因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。
(1.7)上式称为n个观测的似然函数。
我们的目标是能够求出使这一似然函数的值最大的参数估计。
于是,最大似然估计的关键就是求出参数,使上式取得最大值。
对上述函数求对数(1.8)上式称为对数似然函数。
为了估计能使取得最大的参数的值。
对此函数求导,得到p+1个似然方程。
(1.9),j=1,2,..,p.上式称为似然方程。
为了解上述非线性方程,应用牛顿-拉斐森(Newton-Raphson)方法进行迭代求解。
1.3牛顿-拉斐森迭代法对求二阶偏导数,即Hessian矩阵为(1.10)如果写成矩阵形式,以H表示Hessian矩阵,X表示(1.11)令(1.12)则。
再令(注:前一个矩阵需转置),即似然方程的矩阵形式。
得牛顿迭代法的形式为(1.13)注意到上式中矩阵H为对称正定的,求解即为求解线性方程HX=U中的矩阵X。
对H进行cholesky分解。
最大似然估计的渐近方差(asymptotic variance)和协方差(covariance)可以由信息矩阵(information matrix)的逆矩阵估计出来。

如何解释逻辑回归模型的系数逻辑回归是一种常用的分类算法,它通过对特征和目标变量之间的关系进行建模,来预测离散的输出结果。
在逻辑回归模型中,系数扮演着重要的角色,它们代表了特征对于目标变量的影响程度。
本文将探讨如何解释逻辑回归模型的系数。
首先,我们需要明确逻辑回归模型的基本概念。
逻辑回归模型通过使用逻辑函数(也称为sigmoid函数)将线性回归模型的输出转化为概率值。
逻辑函数的取值范围在0和1之间,表示某个样本属于某个类别的概率。
模型的系数表示了特征对于目标变量的影响方向和程度。
在解释逻辑回归模型的系数时,我们可以从以下几个方面入手。
1. 系数的正负:逻辑回归模型的系数可以为正或负。
正系数表示特征与目标变量之间存在正相关关系,即特征值增加时,目标变量的概率也会增加。
负系数则表示特征与目标变量之间存在负相关关系,即特征值增加时,目标变量的概率会减少。
2. 系数的大小:系数的绝对值越大,表示特征对目标变量的影响越大。
例如,如果某个特征的系数为2,而另一个特征的系数为0.5,那么前者对目标变量的影响要比后者大4倍。
3. 系数的显著性:系数的显著性表示该系数是否具有统计学上的显著影响。
通常,我们使用假设检验来评估系数的显著性。
如果系数的p值小于某个事先设定的显著性水平(例如0.05),则可以认为该系数是显著的,即特征对目标变量的影响是真实存在的。
4. 系数的解释:系数的解释需要结合具体的特征和目标变量来进行。
例如,如果我们的目标是预测某人是否患有心脏病,而某个特征是血压,那么血压系数的解释可以是:血压每增加1单位,患心脏病的概率增加了x%。
5. 系数的互相影响:逻辑回归模型中的系数是同时估计的,它们之间可能存在相互影响。
因此,在解释系数时,需要考虑其他特征的取值。
例如,某个特征的系数可能为负,但是当其他特征取值较大时,该特征的影响可能会被抵消。
总之,解释逻辑回归模型的系数需要综合考虑系数的正负、大小、显著性、解释和互相影响等因素。

逻辑回归模型逻辑回归模型是一种分类学习算法,其主要用于分类判断,是机器学习算法中一种常用的模型。
它的工作原理是,将一系列的解释变量联系起来,并用概率来预测结果变量的取值,以实现对结果变量值的预测。
本文旨在阐述逻辑回归模型的原理、特点和应用,以解决分类问题。
一、逻辑回归模型简介逻辑回归模型是统计学中常用的分类技术,它可以计算出预测变量和因变量之间关系的强度,从而判断出应当采取何种行动。
它属于机器学习的监督学习模式,采用概率的方法预测输出,能准确预测出一个特征的概率为一个另一个特征的取值所对应的概率。
二、基本原理逻辑回归模型的基本原理是:通过解释变量和因变量之间的关系,来预测因变量的取值。
它的核心思想是:若解释变量的值发生改变,则因变量的值也会根据解释变量的变化而发生改变。
其模型公式可以表示为:Y = +1X1 +2X2+...+nXn其中,Y是因变量;α、β1,β2...βn分别为回归系数;X1,X2...Xn为解释变量。
三、特点1、准确率高:逻辑回归的预测准确率高,这就使得它可以用于细致的分类任务,如预测疾病发生的概率等。
2、简单方便:逻辑回归模型的构建简单,只需要简单的数学操作就可以得出结果,无需构建复杂的模型,省下了大量的计算时间。
3、无需输入特征缩放:逻辑回归模型基于logistic函数来处理输入,因此,它不会因受影响而受输入特征缩放的影响。
四、应用1、预测病患:逻辑回归模型可以用于政府或医疗机构的疾病预测,根据患者的性别、年龄、职业等信息,预测患者患某种疾病的几率,以便从更早的阶段采取控制措施。
2、市场营销:逻辑回归模型可以用于市场营销,利用用户的年龄、性别、购物频率等信息,可以预测出此次营销活动中每个客户是否会参与,从而更有效地实施营销活动。
3、金融风险控制:逻辑回归模型可以用于金融风险控制,可以预测客户的信用风险,以及未来贷款还款是否守约,以减少风险损失。
总之,逻辑回归模型是一种有效的分类技术,它可以以概率的方式预测出输出结果,具有准确率高、简单方便特性,并且无需特征缩放,在众多行业中有着广泛的应用,如预测疾病发生、市场营销和金融行业等,是一种有效的分类解决方案。

统计学中的逻辑回归分析方法解析逻辑回归是一种在统计学中常用的回归分析方法,用于预测二元变量的可能性。
它通过建立一个合适的回归模型,将自变量与因变量之间的关系进行建模和分析。
本文将深入探讨逻辑回归的原理、应用场景以及如何进行模型拟合和结果解读。
一、逻辑回归的原理逻辑回归是一种广义线性模型(Generalized Linear Model),它假设自变量与因变量之间的关系符合一个特定的概率分布,一般是二项分布或伯努利分布。
逻辑回归的目标是根据自变量的值来预测因变量的概率。
具体而言,逻辑回归通过采用对数几率函数(logit function)将概率转化为线性函数。
二、逻辑回归的应用场景逻辑回归广泛应用于分类问题,特别是当因变量是二元变量时。
例如,逻辑回归可以用于预测一个学生是否通过考试,一个客户是否购买某个产品,或者一个患者是否患有某种疾病。
逻辑回归也可以用于探索自变量与二元结果之间的关系,从而寻找影响结果的关键因素。
三、逻辑回归模型的建立和拟合逻辑回归模型的建立包括两个关键步骤:模型选择和模型拟合。
首先,根据实际问题和数据特点,选择适合的自变量进行建模。
这一步骤需要根据领域知识、特征选择算法或者经验来确定。
其次,通过最大似然估计等方法,对逻辑回归模型进行拟合。
拟合完成后,可以通过估计的参数来计算因变量的概率,进而进行预测和解释。
四、逻辑回归结果的解读逻辑回归模型的结果通常包括自变量的系数、标准误、Z值以及P值等信息。
系数表示自变量对因变量的影响程度,正负号表示影响的方向。
标准误可以用来评估模型的稳定性,Z值和P值用于检验自变量的显著性。
一般来说,P值小于0.05可以认为与因变量存在显著关系。
此外,还可以利用模型的准确率、召回率、F1分数等指标来评估模型的预测性能。
五、逻辑回归的改进与扩展逻辑回归作为一种经典的统计分析方法,在实际应用中也存在一些问题和局限性。
例如,逻辑回归假设了自变量与因变量之间的线性关系,无法处理非线性关系。

Logistic回归模型的分类及主要问题一、引言逻辑回归是一种广泛应用于分类问题的统计方法,用于预测某个实例属于特定类别的概率。
尽管其简单易懂并具有很好的可解释性,但在应用过程中仍然会遇到一些问题。
本文将详细讨论逻辑回归模型的分类及其主要问题。
二、逻辑回归模型的分类1. 二元逻辑回归:这是最简单也是最常见的逻辑回归形式,用于解决二分类问题(例如,电子邮件是否为垃圾邮件)。
在这种模型中,我们尝试找到一条线或一个超平面,以最大化正类和负类之间的分离度。
2. 多项式逻辑回归:当与线性回归模型相比,数据的特性更复杂时,可以使用多项式逻辑回归。
在这种情况下,我们使用非线性函数来映射自变量和因变量之间的关系。
3. 次序逻辑回归:当输出变量是有序的(例如,评级为1到5)时,可以使用次序逻辑回归。
这种模型可以估计有序概率比(OR),即成功的概率与失败的概率之比。
三、逻辑回归模型的主要问题1. 多重共线性:逻辑回归模型假设自变量之间不存在线性关系。
然而,在现实世界的数据集中,这种假设往往不成立,导致多重共线性问题。
多重共线性会导致模型系数的不稳定,影响模型的解释性和预测准确性。
2. 类别不平衡:在处理类别不平衡的数据时,逻辑回归模型可能会遇到问题。
例如,在垃圾邮件检测中,垃圾邮件的数量通常远少于非垃圾邮件。
这种情况下,模型可能会过于倾向于预测为非垃圾邮件,导致预测性能下降。
3. 忽略交互效应:逻辑回归模型默认自变量之间没有交互效应。
然而,在现实中,自变量之间可能存在复杂的交互关系。
忽略这些交互效应可能会导致模型的预测性能下降。
4. 精度-复杂性权衡:逻辑回归模型的一个关键问题是找到精度和复杂性之间的最佳平衡。
一方面,我们希望模型尽可能精确;另一方面,我们也希望模型尽可能简单,以便解释和应用。
然而,过度复杂的模型可能会导致过拟合,而过于简单的模型则可能无法捕捉到数据的真实结构。
四、总结逻辑回归是一种强大的分类工具,但在使用过程中需要注意以上提到的问题。

情感分析是一种非常有用的技术,它可以帮助企业了解消费者的情感和态度,从而更好地满足客户的需求。
逻辑回归模型是一种常用的机器学习算法,可以用来进行情感分析。
本文将介绍如何使用逻辑回归模型进行情感分析,并进行案例分析和实际应用。
一、逻辑回归模型简介逻辑回归模型是一种用于处理分类问题的统计模型。
它可以用来预测一个二元变量的概率,比如“是”或“否”、“成功”或“失败”。
逻辑回归模型的输出是一个介于0和1之间的概率值,通常被解释为一个事件发生的可能性。
逻辑回归模型的数学表达式为:\[P(y=1|x) = \frac{1}{1+e^{-\beta^Tx}}\]其中,\(P(y=1|x)\)表示在给定输入变量x的条件下,y取值为1的概率;\(\beta\)是模型的参数向量;x是输入变量的特征向量。
二、如何使用逻辑回归模型进行情感分析情感分析是一种对文本进行情感和态度分析的技术。
在情感分析中,逻辑回归模型可以被用来判断文本中的情感是积极的、消极的还是中性的。
首先,需要对文本进行预处理。
这包括去除文本中的标点符号、停用词和数字,对文本进行分词和词干提取等操作。
接下来,需要构建特征向量。
逻辑回归模型的输入是特征向量,因此需要将文本转换成数字特征。
常用的方法包括词袋模型和TF-IDF模型。
词袋模型将文本表示为一个词频向量,TF-IDF模型将文本表示为一个词的重要性向量。
然后,需要训练逻辑回归模型。
训练数据集通常包括标注好情感的文本数据,可以使用一些机器学习库如scikit-learn或TensorFlow来训练逻辑回归模型。
最后,可以使用训练好的逻辑回归模型来预测新的文本情感。
给定一个新的文本,可以将其转换成特征向量,然后使用逻辑回归模型来预测其情感。
三、案例分析假设我们有一个餐厅的评论数据集,其中包含顾客的评论和他们对餐厅的评分。
我们可以使用逻辑回归模型来进行情感分析,预测评论的情感是正面的还是负面的。
首先,我们需要对评论数据进行预处理,包括去除标点符号和停用词,进行分词和词干提取等操作。
逻辑回归模型是一种用于预测二元变量的统计方法,常用于分析用户行为。
在互联网时代,大数据已经成为了企业决策的重要参考依据,而用户行为分析正是其中的一项重要内容。
通过逻辑回归模型,我们可以更好地理解用户行为背后的规律,为企业提供更精准的决策支持。
一、搜集数据在使用逻辑回归模型进行用户行为分析之前,首先需要搜集大量的用户数据。
这些数据可以包括用户的基本信息、行为数据、购买记录、浏览历史等。
通过这些数据,我们可以了解用户的兴趣爱好、消费习惯、购买意向等信息,为后续的分析提供数据支持。
二、数据清洗在搜集到数据之后,我们需要对数据进行清洗和预处理。
这包括处理缺失值、异常值、重复值等,以确保数据的准确性和完整性。
此外,还需要进行数据转换和标准化,使得数据符合逻辑回归模型的要求,从而提高模型的预测能力。
三、变量选择在构建逻辑回归模型时,需要选择合适的自变量进行建模。
通过对用户行为数据的分析,我们可以选择一些与用户行为密切相关的变量,比如浏览次数、点击率、购买频次等。
同时,还可以通过特征工程的方法构建新的特征变量,以提高模型的预测能力。
四、模型建立在选择好自变量之后,就可以开始建立逻辑回归模型。
通过最大似然估计等方法,利用历史数据对模型参数进行估计,从而得到一个可以预测用户行为的模型。
在建立模型时,还需要考虑模型的拟合度和预测能力,可以通过交叉验证等方法进行模型评估和选择。
五、模型评估建立好模型之后,需要对模型进行评估。
这包括对模型的拟合度、预测准确率、召回率等指标进行评估。
通过对模型的评估,可以了解模型的优劣,进而对模型进行调整和优化。
六、应用场景逻辑回归模型广泛应用于用户行为分析的各个领域。
比如在电商领域,可以利用逻辑回归模型预测用户的购买意向,从而进行个性化推荐和营销策略优化;在金融领域,可以利用逻辑回归模型预测用户的信用风险,从而进行风险控制和信贷决策等。
总结逻辑回归模型是一种简单而有效的方法,可以用于用户行为分析。
逻辑回归模型是一种用于解决分类问题的统计学习模型,它常被用于用户行为分析。
在这篇文章中,我们将探讨逻辑回归模型在用户行为分析中的应用,并介绍如何使用该模型进行分析。
数据收集与预处理首先,进行用户行为分析需要有足够的数据支撑。
数据的收集可以通过用户行为日志、问卷调查、用户交互记录等方式进行。
在收集到的数据中,需要进行一定的预处理工作,例如去除异常值、缺失值处理、数据标准化等。
这一步骤是进行逻辑回归分析的前提,只有经过预处理的数据才能确保模型的准确性和可靠性。
特征选择与模型构建在进行用户行为分析时,需要对用户行为特征进行选择。
这些特征可以包括用户的基本信息、网站访问记录、购买记录、点击行为等。
在特征选择时,需要考虑特征之间的相关性和对目标变量的影响程度,以避免多重共线性和过拟合问题。
构建逻辑回归模型时,需要将选定的特征作为自变量,用户的行为结果(如购买与否、点击与否)作为因变量。
逻辑回归模型能够将自变量的线性组合映射到一个0-1之间的概率输出,因此非常适用于用户行为的分类预测。
模型训练与评估在构建好逻辑回归模型后,需要利用已有的数据进行模型训练。
在训练过程中,可以使用交叉验证等方法对模型进行优化,以选择最优的参数组合和提高模型的泛化能力。
在模型训练完成后,需要对模型进行评估。
评估的指标可以包括准确率、召回率、F1值等。
通过评估模型的性能,可以了解模型的预测能力和稳定性,从而为后续的应用提供依据。
模型应用与结果解释在模型训练和评估完成后,逻辑回归模型可以用于用户行为分析的实际应用中。
例如,可以利用模型预测用户购买意愿、点击广告的概率等,从而进行个性化推荐、广告投放等。
在模型的应用过程中,还可以对模型的结果进行解释。
逻辑回归模型可以提供各个特征对用户行为的影响程度,从而帮助我们了解用户行为背后的原因和规律。
总结逻辑回归模型作为一种简单而有效的分类模型,在用户行为分析中有着广泛的应用。
通过合理的特征选择、模型构建和训练,可以利用逻辑回归模型对用户行为进行深入分析和预测。
logistic回归结果解读Logistic回归是一种分类方法,主要应用于预测响应变量是二进制的情况,比如成功与失败、健康与疾病、风险与无风险等。
它相当于在特征区间内,将所有样本划分为两类,从而实现对数据集中每个样本的分类,并有效地实现了二元分类。
在衡量模型效果方面,logistic回归采用了准确率、召回率和ROC曲线等评估指标,可以更好地检验模型的性能。
Logistic回归结果解读是指解读Logistic回归模型的输出结果,其中包括:模型的性能、特征的重要性、概率和拟合度等。
首先,模型的性能是模型解释的重点。
Logistic回归模型一般使用AUC(Area Under Curve)值来衡量模型的性能,AUC值越大,模型的性能越好。
此外,查准率(Precision)和查全率(Recall)也是用来评估Logistic 回归模型性能的重要指标,查准率表示样本中被正确预测的个体占预测个体总数的比率,而查全率表示样本中被预测正确的个体占实际个体总数的比率。
其次,Logistic回归模型的参数可以用来判断特征变量对模型的重要性,通常来说,Wald检验的p值越小,特征变量对模型的重要性越大,反之,特征变量对模型的重要性越小。
最后,Logistic回归模型可以给出每个样本的概率,这样可以更加直观地看出模型的拟合度。
如果模型拟合度较差,说明存在模型拟合不足,此时可以对模型进行调整,比如添加新的特征变量或者更改模型的参数,以提高拟合度。
总的来说,Logistic回归结果的解读是一个重要的环节,它可以帮助我们更好地理解模型的性能、特征的重要性以及概率和拟合度。
只有解读了模型的结果,才能更好地分析模型的效果,并对模型进行调整,以达到更好的性能。
逻辑回归最详尽解释模型介绍Logistic Regression 是⼀个⾮常经典的算法,其中也包含了⾮常多的细节,曾看到⼀句话:如果⾯试官问你熟悉哪个机器学习模型,可以说 SVM,但千万别说 LR,因为细节真的太多了。
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常⽤于⼆分类。
Logistic Regression 因其简单、可并⾏化、可解释强深受⼯业界喜爱。
Logistic 回归的本质是:假设数据服从这个分布,然后使⽤极⼤似然估计做参数的估计。
1.1 Logistic 分布Logistic 分布是⼀种连续型的概率分布,其分布函数和密度函数分别为:其中,表⽰位置参数,为形状参数。
我们可以看下其图像特征:Logistic 分布是由其位置和尺度参数定义的连续分布。
Logistic 分布的形状与正态分布的形状相似,但是 Logistic 分布的尾部更长,所以我们可以使⽤ Logistic 分布来建模⽐正态分布具有更长尾部和更⾼波峰的数据分布。
在深度学习中常⽤到的函数就是 Logistic 的分布函数在的特殊形式。
1.2 Logistic 回归之前说到 Logistic 回归主要⽤于分类问题,我们以⼆分类为例,对于所给数据集假设存在这样的⼀条直线可以将数据完成线性可分。
决策边界可以表⽰为,假设某个样本点那么可以判断它的类别为 1,这个过程其实是感知机。
Logistic 回归还需要加⼀层,它要找到分类概率与输⼊向量的直接关系,然后通过⽐较概率值来判断类别。
考虑⼆分类问题,给定数据集考虑到取值是连续的,因此它不能拟合离散变量。
可以考虑⽤它来拟合条件概率,因为概率的取值也是连续的。
但是对于(若等于零向量则没有什么求解的价值),取值为 R ,不符合概率取值为 0 到 1,因此考虑采⽤⼴义线性模型。
最理想的是单位阶跃函数:但是这个阶跃函数不可微,对数⼏率函数是⼀个常⽤的替代函数:于是有:我们将视为为正例的概率,则为为其反例的概率。
信用卡消费大数据分析中的逻辑回归模型解析随着数字化和智能化的发展,信用卡消费数据已经成为大数据应用的重要变量之一。
这些数据不仅可以帮助各个行业企业分析消费者的购买喜好、消费习惯等,还可以通过预测消费者的未来行为来制定有效的市场营销策略。
那么,在信用卡消费大数据分析中,逻辑回归模型在预测分析方面起到了重要的作用。
逻辑回归模型是一种广泛应用于分类领域的统计模型。
在信用卡消费大数据分析中,逻辑回归模型可以通过对消费者的历史数据进行分析,预测他们遵循某个特定行为概率的大小。
逻辑回归预测模型的结构可以用以下公式表示:P(Y=1|X)=exp(W'X)/(1+exp(W'X))其中Y是输出结果,代表分类变量;X是自变量,代表用于分类的一组预测变量;W是逻辑回归模型的系数,需要通过训练样本进行拟合和求解。
在信用卡消费大数据分析中,逻辑回归模型可以用于以下几个方面:1.用户分类逻辑回归模型可以通过对消费数据进行挖掘和分析,实现对用户的基本特征进行分类。
对于信用卡消费数据而言,可以通过对用户的消费金额、消费频率、信用卡等级、还款方式等多个方面进行分析,将用户分为高消费、中等消费、低消费等几类,为相应的营销策略提供参考。
2.风险评估在信用卡消费大数据分析中,逻辑回归模型可以用于风险评估。
我们可以通过大量的信用卡消费数据,分析出哪些行为容易导致用户违约,从而预测哪些用户更有可能违约;同时也可以分析哪些行为会引起系统风险,从而采取相应的措施。
3.客户流失预测逻辑回归模型也可以用于客户流失预测。
我们可以通过对用户的异常消费行为、还款情况等进行分析,来预测哪些用户有可能流失。
据此,我们可以制定相应的措施,如提高用户的满意度、增加用户福利等,以留住关键客户。
总的来说,信用卡消费大数据分析中的逻辑回归模型不仅能够对用户进行分类,并对其消费行为进行预测,还能帮助企业在制定营销策略、风险评估等方面起到重要作用。
但是,我们需要注意的是,模型的精度和准确性是需要通过大量数据和实践来检验的。
1.逻辑回归模型1.1逻辑回归模型考虑具有p个独立变量的向量■',设条件概率卩;上二•丨门二广为根据观测量相对于某事件发生的概率。
逻辑回归模型可表示为:「( 1.1)上式右侧形式的函数称为称为逻辑函数。
下图给出其函数图象形式。
其中-" I' 1 c' ■-..【•。
如果含有名义变量,则将其变为dummy 变量。
一个具有k个取值的名义变量,将变为k-1个dummy 变量。
这样,有—I ( 1.2)这个比值称为事件的发生比(the odds of experie ncing an event),0<p<1,故odds>0 。
对odds取对数,即得到线性函数,h ■y —: j島一,厲-5 —+兀匸护9一 Q讣1 p 上】(1.5)假设有n个观测样本,观测值分别为设' 」I ■■-为给定条件下(1.3)简称为odds。
因为定义不发生事件的条件概率为那么,事件发生与事件不发生的概率之比为1.2极大似然函数得到I 的概率。
在同样条件下得到-- 的条件概率为丨:一"。
得到一个观测值的概率为因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。
(1.7)上式称为n个观测的似然函数。
我们的目标是能够求出使这一似然函数的值最大的参数估譏备心)(」' (1.10 是,◎ )*(1 ¥严(1.6 )i-l计。
于是,最大似然估计的关键就是求出参数:- ,使上式取得最大值。
对上述函数求对数— (1.8)上式称为对数似然函数。
为了估计能使亠取得最大的参数的值。
对此函数求导,得到p+1个似然方程。
Ei 片 n:—E L尹—心肿一时(1.9 )^叶切迄尸,j=1,2,..,p.上式称为似然方程。
为了解上述非线性方程,应用牛顿-拉斐森进行迭代求解。
(Newto n-Raphs on) 方法1.3 牛顿-拉斐森迭代法对-八•求二阶偏导数,即Hessian矩阵为如果写成矩阵形式,以H表示Hessian矩阵,X表示(1.11 )(2.1 )得牛顿迭代法的形式为对H 进行cholesky 分解。
最大似然估计的渐近方差(asymptotic 阵(information matrix )的逆矩阵估计出来。
而信息矩阵实际上是匚…—二阶导数的负值,表示为 。
估计值的方差和协方差表示为 -'_■',也就是说,估计值,二的 方差为矩阵I 的逆矩阵的对角线上的值,而估计值 ’】和厂的协方差为除了对角线以外的值。
然而在多数情况,我们将使用估计值■〔的标准方差,表示为2 .显著性检验下面讨论在逻辑回归模型中自变量?;[是否与反应变量显著相关的显著性检验。
零假设 ‘二,:■' = 0 (表示自变量 F 对事件发生可能性无影响作用)。
如果零假设被拒绝, 说明事件发生可能性依赖于"的变化。
2.1 Wald test对回归系数进行显著性检验时,通常使用Wald 检验,其公式为r-儿a-曹:(i(1.12 )则H=X TVX 。
再令 L 1九■■■“然方程的矩阵形式。
>i -兀i >2 - %■丹■①」(注:前一个矩阵需转置),即似(1.13 )注意到上式中矩阵H 为对称正定的,求解b'U 即为求解线性方程HX = U 中的矩阵X 。
varianee )和协方差(covarianee ) 可以由信息矩 for j=0,1,2. …,p (1.14 )4貝A.其中,■''匸•为二的标准误差。
这个单变量Wald 统计量服从自由度等于1的■-分布。
如果需要检验假设’'-:| :I = 0,计算统计量(2.2 )4 宀其中,厂为去掉'-所在的行和列的估计值,相应地, 准误差。
这里, Wald 统计量服从自由度等于 p 的」分布。
如果将上式写成矩阵形式,^ = (QMQ^^)QT\QA) (2.3) 矩阵Q 是第一列为零的一常数矩阵。
例如,如果检验然而当回归系数的绝对值很大时,这一系数的估计标准误就会膨胀,于是会导致 统计值变得很小,以致第二类错误的概率增加。
也就是说,在实际上会导致应该拒绝零假设 时却未能拒绝。
所以当发现回归系数的绝对值很大时, 就不再用 Wald 统计值来检验零假设, 而应该使用似然比检验来代替。
2.2似然比(Likelihood ratio test )检验在一个模型里面,含有变量①与不含变量山的对数似然值乘以-2的结果之差,服从分布。
这一检验统计量称为似然比(likelihood ratio ) ,用式子表示为L y 不纸似然、G7哙科麝(2.4)计算似然值采用公式(1.8 )。
倘若需要检验假设’‘一 :八一 -4 = 0,计算统计量讥『2>讣饵.“—"歸-十恥H m "HdfUWXl /cu 、“ (2.5 )上式中,"表示门=0的观测值的个数,而 匸表示门=1的观测值的个数,那么 n 就表示 所有观测值的个数了。
实际上,上式的右端的右半部分■■ 1_'- ' "■ 一‘ ' 表示只含有的似然值。
统计量 G 服从自由度为p 的■「分布 2.3 Score 检验在零假设"-'?= 0下,设参数的估计值为'1 :,即对应的 J = 0。
计算Score 统 计量的公式为A J TS4--为去掉’k 所在的行和列的标Wald5甩尸厂)(如刃(如〕(2.6 )上式中,’L-表示在=0下的对数似然函数(1.9 )的一价偏导数值,而''":■ :|表示 在匚=0下的对数似然函数(1.9 )的二价偏导数值。
Score 统计量服从自由度等于1的'■ 分布。
2.4模型拟合信息模型建立后,考虑和比较模型的拟合程度。
有三个度量值可作为拟合的判断根据。
(1) -2LogLikelihood】-乂 (2.7)(2) Akaike 信息准则(Akaike In formation Criterio n. 血=_25亂+ 2住+小(28)其中K 为模型中自变量的数目, S 为反应变量类别总数减1, 对于逻辑回归有 S=2-仁1 -2LogL 的值域为0至,其值越小说明拟合越好。
当模型中的参数数量越大时,似然值也 就越大,-2LogL 就变小。
因此,将2 (K+S )加到AIC 公式中以抵销参数数量产生的影响。
在其它条件不变的情况下,较小的 AIC 值表示拟合模型较好。
(3)Schwarz 准则这一指标根据自变量数目和观测数量对 -2LogL 值进行另外一种调整。
SC 指标的定义为 犯=-2比就+2也+心恤@)(2.9)其中ln (n )是观测数量的自然对数。
这一指标只能用于比较对同一数据所设的不同模型。
在 其它条件相同时,一个模型的 AIC 或SC 值越小说明模型拟合越好。
3. 回归系数解释 3.1发生比(1)连续自变量。
对于自变量J j:,每增加一个单位,odds ration 为OR(3.1)简写为AIC )odds=[p/(1-p)]3,即事件发生的概率与不发生的概率之比。
而发生比率(odds ration).odds.⑵二分类自变量的发生比率。
变量的取值只能为0或1,称为dummy variable 。
当取值为1,对于取值为0的发生比率为- :' (3.2)亦即对应系数的幕。
(3)分类自变量的发生比率。
如果一个分类变量包括m个类别,需要建立的dummy variable 的个数为m-1,所省略的那个类别称作参照类(referenee category) 。
设dummy variable 为八;:,其系数为,■,对于参照类,其发生比率为丁、。
3.2逻辑回归系数的置信区间对于置信度1 -二,参数「的100% (1 -「)的置信区间为玄土益X曲並" (3.3 )上式中,亠为与正态曲线下的临界乙值(critical value ), =为系数估计的标准误差,‘’和- '两值便分别是置信区间的下限和上限。
当样本较大时,匚=0.05水平的系数"的95%置信区间为&±1,92 込兀(3.4 )4. 变量选择4.1前向选择(forward selection ):在截距模型的基础上,将符合所定显著水平的自变量一次一个地加入模型。
具体选择程序如下(1 )常数(即截距)进入模型。
(2 )根据公式(2.6 )计算待进入模型变量的Score检验值,并得到相应的P值。
(3)找出最小的p值,如果此p值小于显著性水平-,则此变量进入模型。
如果此变量是某个名义变量的单面化(dummy) 变量,则此名义变量的其它单面化变理同时也进入模型。
不然,表明没有变量可被选入模型。
选择过程终止。
(4) 回到(2)继续下一次选择。
4.2后向选择(backward selection ):在模型包括所有候选变量的基础上,将不符合保留要求显著水平的自变量一次一个地删除。
具体选择程序如下(1) 所有变量进入模型。
(2) 根据公式(2.1 )计算所有变量的Wald检验值,并得到相应的p值。
(3) 找出其中最大的p值,如果此P值大于显著性水平,则此变量被剔除。
对于某个名义变量的单面化变量,其最小p值大于显著性水平,则此名义变量的其它单面化变量也被删除。
不然,表明没有变量可被剔除,选择过程终止。
(4) 回到(2)进行下一轮剔除。
4.3 逐步回归(stepwise selection)(1)基本思想:逐个引入自变量。
每次引入对Y影响最显著的自变量,并对方程中的老变量逐个进行检验,把变为不显著的变量逐个从方程中剔除掉,最终得到的方程中既不漏掉对Y影响显著的变量,又不包含对Y影响不显著的变量。
⑵筛选的步骤:首先给出引入变量的显著性水平-和剔除变量的显著性水平J ,然后按下图筛选变量。
Y亠―"I J厂巨二匸罠"J、、-iI 乳IJ ______ _十审谛丘至(3)逐步筛选法的基本步骤逐步筛选变量的过程主要包括两个基本步骤:一是从不在方程中的变量考虑引入新变量的步骤;二是从回归方程中考虑剔除不显著变量的步骤。
假设有p个需要考虑引入回归方程的自变量.①设仅有截距项的最大似然估计值为「。
对p个自变量每个分别计算Score检验值,设有最小p值的变量为'r-,且有2 " 1 ' J ^',对于单面化(dummy)变量,也如此。
若" …,则此变量进入模型,不然停止。
如果此变量是名义变量单面化(dummy)的变量,则此名义变量的其它单面化变量也进入模型。
其中=•・;为引入变量的显著性水平。