回归分析的模型SPSS概要
- 格式:ppt
- 大小:200.00 KB
- 文档页数:21





spss二元logistic回归分析结果解读二元logistic回归分析是一种被广泛应用于多元研究中的统计分析方法,它可以帮助研究者了解因变量与自变量之间的关系,探索如何调节自变量,以达到改变因变量的目的。
本文主要就二元logistic回归分析结果如何解释进行讨论,旨在帮助读者更好地理解并解读此类分析结果。
一、二元logistic回归分析概述二元logistic回归分析是一种常见的回归分析模型,它可以用来预测一个特定的结果,或者说一个事件的发生可能性,以及它的发生概率有多大。
它比较适合于研究两个变量之间的关系,一个变量是被解释变量,另一个变量是解释变量,被解释变量只有两种可能的结果,比如两个不同的类别。
二元logistic回归分析的基本思想是利用自变量来预测因变量,它通过计算自变量之间的相关性,来预测因变量的发生可能性,比如我们可以利用自变量,如性别、年龄等,来预测一个人是否会患上某种疾病。
二元logistic回归分析结果分析二元logistic回归分析的结果可以分为三类,分别是系数、截距和拟合指数。
1、系数系数指的是每个自变量变化时,因变量变化的程度,系数的正负可以表示因变量变化的方向,正数表示因变量随自变量变化而增大,负数表示因变量随自变量变化而减小。
系数的大小可以表示因变量变化的幅度,数值越大,表明因变量变化的越明显。
2、截距截距表示自变量为0时因变量的值,即任何自变量都不存在的情况下,因变量的值。
它的大小可以反映因变量变化的数量级,它的正负可以表示因变量变化的方向,正数表示因变量变化而增大,负数表示因变量变化而减小。
3、拟合指数拟合指数是一种衡量模型准确度的指标,其数值越大,表明模型越准确。
一般来说,当拟合指数大于0.6时,可以认为模型较准确。
三、典型二元logistic回归分析结果解读1、系数如果某个自变量的系数为正,表示随着自变量增加,因变量也随之增加;如果系数为负,表示随着自变量增加,因变量会减小。

回归分析的模型SPSS概要回归分析是一种统计学方法,用于研究自变量(或预测变量)对因变量(或响应变量)的影响关系。
它可以帮助我们了解变量之间的相关性,并通过建立数学模型对未来的变量进行预测。
SPSS是一款常用于数据分析和统计建模的软件,在回归分析中有广泛的应用。
简单线性回归是最基本也是最常用的回归分析方法之一、它适用于只有一个自变量和一个因变量的情况下,通过建立一条直线来描述变量之间的关系。
SPSS可以计算出斜率和截距,从而得出预测方程。
通过预测方程,我们可以根据已知的自变量的值来预测因变量的值。
在多元线性回归中,可以考虑多个自变量对因变量的影响。
SPSS可以用最小二乘法估计参数值,并提供一些统计指标来评估模型的拟合程度。
这些指标包括R方、调整后的R方、标准误差、F统计量等。
R方是衡量模型拟合度的指标,其值越接近1表示模型的拟合度越好。
逻辑回归是用于处理二分类问题的回归方法。
它通过建立一种数学模型来预测一个事件的概率。
SPSS可以通过最大似然法估计参数值,并提供一些统计指标来评估模型的拟合程度。
这些指标包括似然比、卡方值、准确率等。
除了上述的回归方法,SPSS还提供了其他一些回归分析方法,如多元逻辑回归、多项式回归、非线性回归等。
这些方法可以根据具体的研究问题和数据类型进行选择。
在进行回归分析之前,需要进行数据的准备工作。
首先,要收集相关的自变量和因变量数据,并进行数据清理、缺失值处理等。
接下来,根据研究目的和数据类型选择合适的回归分析方法,并进行模型的建立和参数的估计。
最后,对模型进行检验和评估,并分析结果的可靠性和实际意义。
总之,回归分析是一种重要的统计方法,在研究和预测变量之间的关系、制定决策等方面具有广泛的应用。
SPSS作为一款功能强大的统计分析软件,可以帮助用户进行回归分析,并提供一系列的统计指标和图表来解释结果。
通过合理使用回归分析和SPSS,可以更好地理解变量之间的关系,并做出准确的预测和决策。



回归分析的模型SPSS概要回归分析是一种用于研究两个或多个变量之间关系的统计分析方法。
它通过建立数学模型来预测一个变量(因变量)或解释一系列变量对另一个变量(自变量)的影响。
在SPSS软件中,可以使用回归分析模块进行回归分析的计算和结果输出。
回归分析的基本假设包括线性关系、常态性、独立性和同方差性。
线性关系指因变量和自变量之间的关系符合线性模型的假设;常态性指回归模型的残差满足正态分布;独立性指回归模型的残差之间相互独立;同方差性指回归模型的残差在不同自变量取值下具有相同的方差。
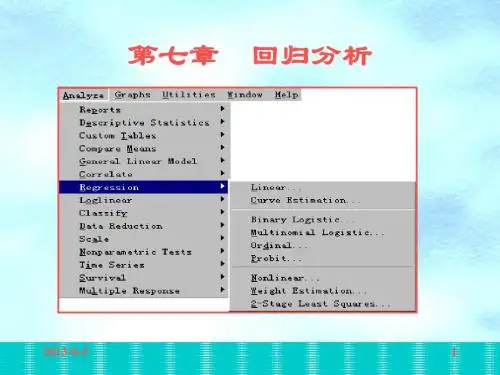
在SPSS中进行回归分析的步骤如下:1.打开SPSS软件,加载数据文件:在“文件”菜单中选择“打开”命令,选择所需的数据文件,然后点击“打开”按钮。
2.进入回归分析模块:在“分析”菜单中选择“回归”子菜单,然后选择“线性回归...”(用于线性回归)或“非线性回归...”(用于非线性回归)。
3.选择变量:在回归分析对话框中,将因变量和自变量从左侧的变量列表中拖动到右侧的“因变量”和“自变量”文本框中。
4.指定模型:选择回归模型的类型和形式。
对于线性回归,可以选择标准型、层级型或正交型;对于非线性回归,可以选择指数、对数、幂函数等形式。
5.设置选项:根据需要,设置其他选项,如常态性检验、变量选择等。
6.运行回归分析:点击“确定”按钮,SPSS将根据所选的变量、模型和选项进行回归分析计算,并显示结果。
回归分析结果的主要输出包括模型拟合度、回归系数、显著性检验结果和残差分析等。
模型拟合度可以通过判别系数R²来评估,其值越接近1表示模型拟合得越好;回归系数表示自变量对因变量的影响程度,可以用于解释和预测;显著性检验结果用于验证模型的显著性,包括F检验、t 检验和P值等;残差分析用于检验模型的假设前提,如常态性、独立性和同方差性等。
总之,回归分析是一种有效的统计方法,可以用于研究变量之间的关系和预测未知值。
在SPSS软件中,可以方便地进行回归分析,并获取相关结果和图表,帮助研究人员更好地理解数据和进行决策。
SPSS学习笔记之——二项Logistic回归分析一、概述Logistic回归主要用于因变量为分类变量(如疾病的缓解、不缓解,评比中的好、中、差等)的回归分析,自变量可以为分类变量,也可以为连续变量。
他可以从多个自变量中选出对因变量有影响的自变量,并可以给出预测公式用于预测。
因变量为二分类的称为二项logistic回归,因变量为多分类的称为多元logistic回归。
下面学习一下Odds、OR、RR的概念:在病例对照研究中,可以画出下列的四格表:------------------------------------------------------暴露因素病例对照-----------------------------------------------------暴露 a b非暴露 c d-----------------------------------------------Odds:称为比值、比数,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。
在病例对照研究中病例组的暴露比值为:odds1 = (a/(a+c))/(c(a+c)) = a/c,对照组的暴露比值为:odds2 = (b/(b+d))/(d/(b+d)) = b/dOR:比值比,为:病例组的暴露比值(odds1)/对照组的暴露比值(odds2) = ad/bc换一种角度,暴露组的疾病发生比值:odds1 = (a/(a+b))/(b(a+b)) = a/b非暴露组的疾病发生比值:odds2 = (c/(c+d))/(d/(c+d)) = c/dOR = odds1/odds2 = ad/bc与之前的结果一致。
OR的含义与相对危险度相同,指暴露组的疾病危险性为非暴露组的多少倍。
OR>1说明疾病的危险度因暴露而增加,暴露与疾病之间为“正”关联;OR<1说明疾病的危险度因暴露而减少,暴露与疾病之间为“负”关联。
SPSS第十讲线性回归分析线性回归分析是一种常用的统计方法,用于研究变量之间的关系。
它建立了一个线性模型,通过最小化误差平方和来估计自变量和因变量之间的关系。
在本次SPSS第十讲中,我将介绍线性回归分析的基本原理、假设条件、模型评估方法以及如何在SPSS中进行线性回归分析。
一、线性回归模型线性回归模型是一种用于预测连续因变量的统计模型,与因变量相关的自变量是线性的。
简单线性回归模型可以表示为:Y=β0+β1X+ε其中,Y表示因变量,X表示自变量,β0表示截距,β1表示自变量的斜率,ε表示误差项。
二、假设条件在线性回归分析中,有三个重要的假设条件需要满足。
1.线性关系:自变量和因变量之间的关系是线性的。
2.独立性:误差项是相互独立的,即误差项之间没有相关性。
3.常态性:误差项服从正态分布。
三、模型评估在线性回归分析中,常用的模型评估方法包括参数估计、显著性检验和拟合优度。
1.参数估计:通过最小二乘法估计回归系数,得到截距和斜率的值。
拟合优度和调整拟合优度是评价线性回归模型拟合程度的重要指标。
2.显著性检验:检验自变量对因变量的影响是否显著。
常用的检验方法包括t检验和F检验。
t检验用于检验单个自变量的系数是否显著,F检验用于检验整体模型的显著性。
3.拟合优度:拟合优度用于评估模型对数据的解释程度。
常见的拟合优度指标有R平方和调整的R平方,R平方表示因变量的变异程度能被自变量解释的比例,调整的R平方考虑了模型的复杂性。
SPSS是一款常用的统计软件,它提供了丰富的功能用于线性回归分析。
1.数据准备:首先,我们需要将数据导入SPSS中并进行数据准备。
将自变量和因变量分别作为列变量导入,可以选择将分类自变量指定为因子变量。
2.线性回归模型的建立:在“回归”菜单下选择“线性”选项,在“依赖变量”中选择因变量,在“独立变量”中选择自变量。
3.结果解读:SPSS会输出回归系数、显著性检验的结果和拟合优度指标。
通过解读这些结果,我们可以判断自变量对因变量的影响是否显著,以及模型对数据的解释程度如何。