交叉列联分析
- 格式:ppt
- 大小:1.80 MB
- 文档页数:27

交叉分析法怎么分析交叉分析法是一种常用的数据分析方法,主要用于对多个变量之间的关系进行分析。
采用交叉分析法可以发现不同变量之间的相互影响和作用方式,从而更好地理解数据背后的规律和特征。
在下面的文章中,我们将介绍交叉分析法的具体分析流程和注意事项,帮助读者更好地了解和应用这种方法。
一、交叉分析法的定义交叉分析法,也称为交叉表法或列联表法,是一种通过将不同变量交叉排列建立交叉表的方法来研究变量之间相关性的一种统计方法。
交叉分析法根据样本数据构造一个列联表,以便比较各个不同维度之间的差异,从而进一步发现其内在联系和潜在规律。
二、交叉分析法的分析流程1. 选取研究对象和指标首先需要确定研究对象和研究指标。
在选择研究对象时,要确保大样本数量和充分代表性,以免数据偏误。
在选择指标时,应该着重考虑研究目的,避免指标内部关联性太强而导致冗余信息。
2. 建立交叉表将所选变量进行顺序或随机排列,形成一个行×列的交叉表。
在表格中,每一行代表一种分类变量的不同组别,每一列代表另一种分类变量的不同组别。
然后根据实际情况,填入相应的数据或统计概率。
3. 描述表格特征通过观察交叉表格中的特征,了解各个指标之间的关系和变化趋势。
这可以从几个方面来分析,例如行、列、总体、对角线等方面考虑。
归纳总结这些特征,可以为后续分析提供有力支撑。
4. 进行自由度统计自由度(df)指代两种分类变量所构成的列联表中具有独立划分的单元格个数。
在使用交叉分析法时,通常需要根据列联表的大小和分类变量的个数计算可用的自由度。
一般来说,自由度等于“列数-1×行数-1”。
5. 计算卡方值和P值卡方值是用来衡量观察值与理论值之间差异的一个指标。
在进行交叉分析时,一般会使用χ^2检验计算卡方值。
当卡方值越大时,表明所观察到的差异也越大。
在计算卡方值之后,还需要计算对应的P值。
P值是一个统计学上的重要指标,用于表示样本与总体误差概率大小。
如果P 值小于等于0.05,可以认为差异显著,反之则不显著。

多变量描述统计分析交叉表分析法一、交叉表分析法的概念交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率类别比率,%无事故61至少有一次事故39样本总数,人17800从初始表1中可以看出,有61%的保险户在开车过程中从未出现过事故。
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率类别男,%女,%无事故5666至少有一次事故4434样本总数,人93208480这个表的结果令男士懊恼,因为他们的事故率较女士驾车时涉及的事故率要高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率类别男,%女,%驾驶距离>1万公里<1万公里>1万公里<1万公里无事故51735073至少有一次事49275027故样本总数,人7170215024306050结果表明,男士驾驶者的高事故率是由于他们的驾驶距离较女士长,但并没有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。

交叉分析法怎么分析交叉分析法是一种常用的数据分析方法,通过对不同因素之间的关系进行交叉比较和分析,帮助研究者发现变量之间的联系和差异。
本文将介绍交叉分析法的基本概念和步骤,并以具体案例进行说明。
一、交叉分析法概述交叉分析法(Cross-Tabulation Analysis)也被称为列联表分析(Contingency Table Analysis),是一种定量分析方法,用来研究两个或更多变量之间的关系。
通过构建列联表,对不同变量之间的交叉频数进行统计和比较,可以揭示变量之间的关联性和差异性。
二、交叉分析法步骤1. 确定研究问题:明确研究问题并选择需要分析的变量。
例如,假设我们想研究消费者对不同手机品牌的偏好与性别之间的关系。
2. 构建列联表:根据所研究的变量,构建列联表(也称为交叉表)。
横列为一个变量的不同水平(例如手机品牌),纵列为另一个变量的不同水平(例如性别)。
在交叉点上填写交叉频数。
3. 计算频数和比例:根据列联表,计算每个交叉点上的频数和比例。
频数表示各组别的数量,比例表示各组别所占比例。
4. 绘制图表:通过绘制图表,直观地展示不同变量之间的关系。
常用的图表包括堆叠柱状图、簇状柱状图、饼图等。
5. 进行统计检验:为了验证变量之间的关系是否显著,可以进行统计检验,如卡方检验。
卡方检验可以检验各组别之间的差异是否由随机因素引起。
6. 分析结果和讨论:根据交叉分析的结果,进行结果分析和讨论。
解释变量之间的关系和差异,并提出合理的解释和解决方案。
三、交叉分析方法案例以消费者对不同手机品牌的偏好与性别之间的关系为例,进行交叉分析。
我们调查了300名消费者,结果如下表所示:--------------------------------------------------| Apple | Samsung | Huawei | Others--------------------------------------------------男性 | 50 | 30 | 20 | 10--------------------------------------------------女性 | 20 | 40 | 50 | 20--------------------------------------------------根据上表,我们可以计算出各组别的频数和比例,如下所示:--------------------------------------------------| Apple | Samsung | Huawei | Others--------------------------------------------------男性 | 50 | 30 | 20 | 10--------------------------------------------------女性 | 20 | 40 | 50 | 20--------------------------------------------------| 70(23%) | 70(23%) | 70(23%) | 30(10%)--------------------------------------------------通过绘制堆叠柱状图,我们可以直观地看到不同手机品牌在不同性别中的偏好程度。

交叉列联表分析 ---------用于分析属性数据1. 属性变量与属性数据分析从变量的测量水平来看分为两类:连续变量和属性(Categorical)变量,属性变量又可分为有序的(Ordinal)和无序的变量。
对属性数据进行分析,将达到以下几方面的目的:1) 产生汇总分类数据——列联表;2) 检验属性变量间的独立性(无关联性); 3) 计算属性变量间的关联性统计量;4) 对高维数据进行分层分析和建模。
在实际中,我们经常遇到判断两个或多个属性变量之间是否独立的问题,如:吸烟与患肺癌是否有关?色盲与性别是否有关?上网时间与学习成绩是否有关等等.解决这类问题常用到建立列联表,利用χ2统计量作显著性检验来完成.2.列联表(Contingency Table )列联表是由两个以上的属性变量进行交叉分类的频数分布表。
设二维随机变量(X ,Y ),X可能取得值为x x x r ,,,21 ,Y可能取得值为y y y s ,,,21 .现从总体中抽取容量为n 的样本,其中事件(X =x i Y =y j )发生的频率为n j i (i = 1,2, …,r ,j=1,2, …,s ,)记n i ∙=∑=s j j i n 1,n j ∙=∑=ri j i n 1,则有n =∑∑==r i s j j i n 11=∑=∙r i i n 1= ∑=∙sj j n 1,将这些数据排列成如下的表:这是一张r ×s 列联表.3.属性变量的关联性分析对于不同的属性变量,从列联表中可以得到它们联合分布的信息。
但有时还想知道形成列联表的行和列变量间是否有某种关联性,即一个变量取不同数值时,另一个变量的分布是否有显著的不同,这就是属性变量关联性分析的内容。
属性变量关联性检验的假设为 H0:变量之间无关联性;H1:变量之间有关联性由于变量之间无关联性说明变量互相独立,所以原假设和备择假设可以写为:H0:变量之间独立; H1:变量之间不独立χ2检验H 0:X 与Y 独立.记P (X =x i ,η=y j ) = p ji ,i =1,2,…,r ,,j = 1,2,…,s ,P (X =x i ) =pi ., i =1,2,…,r ,P (Y =y j ) =p j . ,j = 1,2,…,s .由离散性随机变量相互独立的定义,则原假设等价于 H 0:pji =p i .p j . ,i =1,2,…,r ,,j = 1,2,…,s .若pji已知,我们可以建立皮尔逊χ2统计量 χ2=∑==∑-ri sij ji j i j i p n p n n 112)(.由皮尔逊定理知,χ2的极限分布为)1(2-rs χ.但这里p j i 未知,因此用它的极大似然估计p ij ∧代替,这时检验统计量为χ2=∑==∧∧∑-ri sij ji ji j i pn p n n 112)(.在H 0成立的条件下,pji =p i .p j .,即等价于用p i ∙和p j ∙.的极大似然估计p i ∙∧和p j ∙∧的积去代替.可以求得p i ∙∧=nn i ∙, i =1,2,…,r , p j ∙∧=nn j∙ , j = 1,2,…,s ,则p ij ∧= n n i ∙nn j ∙ . i =1,2,…,r ,,j = 1,2,…,s ,从而得到统计量χ2=∑==∧∙∧∙∧∙∧∙∑-ri sij ji ji j i p p n p p n n 112)(=⎪⎪⎭⎫ ⎝⎛-∑∑==∙∙1112r i s ij j i j i n n n n . 在H 0成立的条件下,当n →∞时,χ2的极限分布为)12(2--+-)(s r rs χ= ))1)(1((2--s r χ. 对给定的显著性水平α,当 χ2>))1)(1((21---s r χα,则拒绝H 0,否则接受H 0.特别,当r = s = 2 时,得到2×2列联表,常被称为四格表,是应用最广的一种列联表.这时检验统计量为χ2=n n n n n n n n n2121211222112)(∙∙∙∙-它的极限分布为χ2(1).对于二维随机变量(X ,Y )是连续取值的情况,我们可采用如下方法将其离散化.① 将X 的取值范围(-∞,+∞)分成r 个互不相交的区间,将Y 的取值范围(-∞,+∞)分成s 个互不相交的区间,于是整个平面分成了rs 个互不相交的小矩形;② 求出样本落入小矩形中的频数n j i i =1,2,…,r ,,j = 1,2,…,s ; ③ 建立统计量χ2=⎪⎪⎭⎫⎝⎛-∑∑==∙∙1112r i s ij j i j i n n n n , 在H 0成立时且n 充分大时,χ2的极限分布为))1)(1((2--s r χ,拒绝域的确定同离散型的情况. 3.属性变量的关联度计算2χ检验的结果只能说明变量之间是否独立,如果不独立,并不能由2χ的值说明它们之间关系的强弱,这可以由ϕ系数来说明ϕ系数=⎪⎪⎩⎪⎪⎨⎧==++-∙∙∙∙其它,2,2212121122211n s r n n n n n n n n χ其中 当r=s=2即2×2列联表时-1<ϕ<1,其它0<ϕ<1,|ϕ|越接近1,它们之间关联性越强,反之越弱。

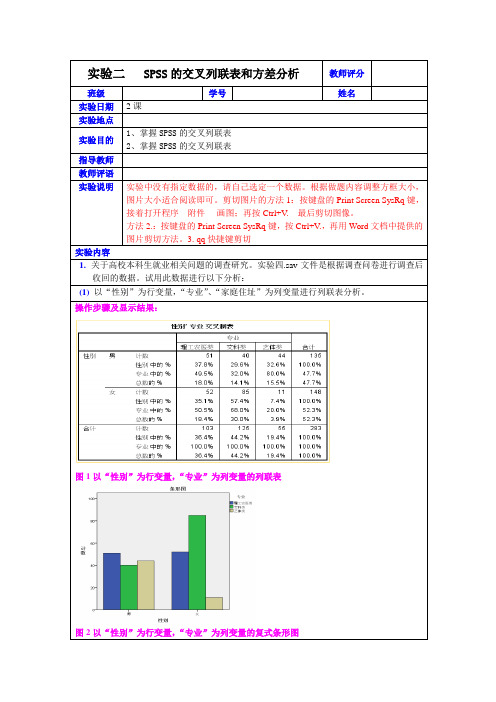
图1以“性别”为行变量,“专业”为列变量的列联表
图2以“性别”为行变量,“专业”为列变量的复式条形图
图4以“性别”为行变量,“家庭住址”为列变量的列联
图1以“性别”为行变量,“家庭住址”为列变量的复式条形图图1以“性别”为行变量,“家庭住址”为列变量的卡方分布
图1以“是否签约”为行变量,“就业形势看法”为列变量的交叉列联表图2以“是否签约”为行变量,“就业形势看法”为列变量的卡方检验
图3 以“是否签约”为行变量,“就业形势看法”为列变量的复式条形图图4 以“是否签约”为行变量,“预期薪酬”为列变量的交叉列联表
图6 以“是否签约”为行变量,“预期薪酬”为列变量的复式条形图
图7 以“是否签约”为行变量,“理想就业单位”为列变量的交叉列联表
图10 以“是否签约”为行变量,“培养模式契合”为列变量的列联表
图12 以“是否签约”为行变量,“培养模式契合”为列变量的复式条形图
图14 以“是否签约”为行变量,“在校努力与最终就业”为列变量的卡方检验图15 以“是否签约”为行变量,“在校努力与最终就业”为列变量的复式条形图图16 以“是否签约”为行变量,“所学专业与就业应该怎样”为列变量的列联表
图18 以“是否签约”为行变量,“所学专业与就业应该怎样”为列变量的复式条形图
(3)使用方差分析的方法探索不同性别在性别、形象、英语水平、计算机水平、毕业高校、专业背景、资格证书、社会实践经历、在校成绩这些因素对就业的影响方面的看法是否显著不同。
操作步骤及显示结果:。
多变量描述统计分析交叉表分析法一、交叉表分析法的概念交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率类别比率,%无事故61至少有一次事故39样本总数,人17800从初始表1中可以看出,有61%的保险户在开车过程中从未出现过事故。
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率类别男,%女,%无事故5666至少有一次事故4434样本总数,人93208480这个表的结果令男士懊恼,因为他们的事故率较女士驾车时涉及的事故率要高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率类别男,%女,%驾驶距离>1万公里<1万公里>1万公里<1万公里无事故51735073至少有一次事49275027故样本总数,人7170215024306050结果表明,男士驾驶者的高事故率是由于他们的驾驶距离较女士长,但并没有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。
叉生分析统计方法叉生分析统计方法是一种用来研究两个或多个变量之间关系的统计方法,也被称为交叉表分析或列联分析。
这种方法通过对变量之间的关系进行交叉分析,能够揭示出隐藏在数据背后的规律和趋势,提供了深入理解变量之间关系的洞见。
本文将详细介绍叉生分析统计方法的原理、应用场景和实施步骤。
叉生分析统计方法是基于列联表进行的,列联表是一种用来汇总两个或多个离散变量之间关系的统计表。
在列联表中,行表示一个自变量的水平,列表示另一个自变量的水平,交叉点处的数值表示两个变量同时出现的频次或百分比。
叉生分析则是对列联表进行进一步的分析。
1.市场调研:通过对顾客的性别和年龄进行叉生分析,可以了解特定产品或服务的受众特征,从而为市场定位和推广活动提供依据。
2.医学研究:在医学研究中,可以通过对病人的性别和病症进行叉生分析,来研究疾病的发病机制、风险因素和治疗效果。
3.教育评估:通过对教育项目的实施地区和参与学生的年级进行叉生分析,可以评估项目对学生学业成绩和学习动机的影响。
4.品牌研究:对消费者的品牌偏好和年收入水平进行叉生分析,可以了解品牌在不同收入阶层中的认知和接受度。
实施叉生分析统计方法的步骤下面将介绍进行叉生分析的具体步骤:1.收集数据:首先需要收集变量之间关系的数据,可以通过问卷调查、实地观察、实验设计等方式获取。
2.构建列联表:将收集到的数据整理成列联表的形式,行表示一个自变量,列表示另一个自变量,交叉点处的数值表示两个变量同步出现的频次或百分比。
3.描述性分析:对列联表中的数据进行描述性分析,可以计算出频次、百分比、平均值等统计指标,以了解两个变量间的总体关系。
4.统计推断:使用统计方法对列联表进行推断分析,用以确定代表显著性的P值,从而判断两个变量之间的关系是否具有统计学意义。
5.可视化呈现:使用图表或图形将叉生分析的结果可视化呈现,以便更直观地理解和传达研究结果。
总结叉生分析统计方法是一种揭示变量之间关系的重要工具。
交叉列表分析主要是用来检验两个变量之间是否存在关系,或者说是独立,其零假设为两个变量之间没有关系。
通过录入数据,建立数据库,然后确定交叉分析变量,对变量进行分析,得出交叉表。
通过表中数据分析出来结论。
如材料中的性别---对休闲生活的满意度---夫妻共度休闲时间状况。
多选变量是指对于包含了多个答案的一个问题,可以允许被调查者在其中作多项选择。
就是我们第一次实验做的一个问题
老师说的其中一个方法是多选变量二分法。
然后学习了多选变量的分析多选变量的频数分析多选变量的交叉分析实例。
SPSS多选变量分析方法可以把多个变量中相同答案的频数累加起来。
比如。