列联表资料的X2检验
- 格式:ppt
- 大小:276.32 KB
- 文档页数:3


X2检验X2检验是用途广泛的假设检验方法,它的原理是检验实际分布和理论分布的吻合程度。
主要用途有:两个及以上样本率(或构成比)之间差异比较,推断两变量间有无相关关系,检验频数分布的拟合优度。
X2检验类型有:四格表资料X2检验(用于两样本率的检验),行×列表X2检验(用于两个及两个以上样本率或构成比的检验), 行×列列联表X2检验(用于计数资料的相关分析)。
在SPSS中,所有X2检验均用Crosstabs完成。
Crosstabls过程用于对计数资料和有序分类资料进行统计描述和统计推断。
在分析时可以产生二维至n维列联表,并计算相应的百分数指标。
统计推断则包括了我们常用的X2检验、Kappa值,分层X2(X2M-H)。
如果安装了相应模块,还可计算n维列联表的确切概率(Fisher's Exact Test)值。
Crosstabs过程不能产生一维频数表(单变量频数表),该功能由Frequencies 过程实现。
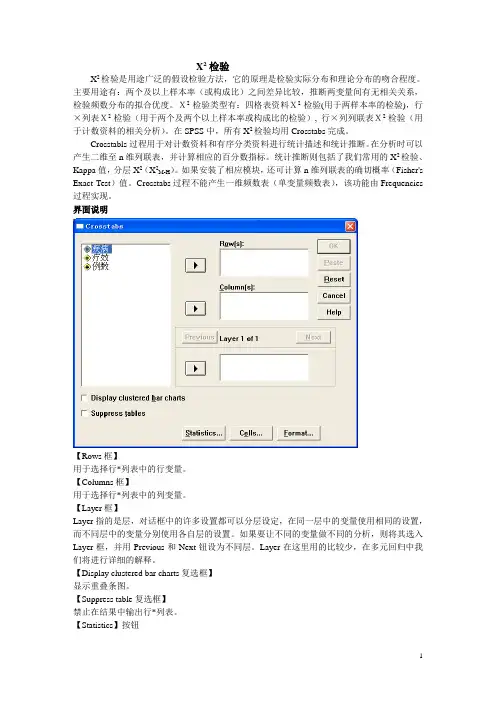
界面说明【Rows框】用于选择行*列表中的行变量。
【Columns框】用于选择行*列表中的列变量。
【Layer框】Layer指的是层,对话框中的许多设置都可以分层设定,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。
如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next钮设为不同层。
Layer在这里用的比较少,在多元回归中我们将进行详细的解释。
【Display clustered bar charts复选框】显示重叠条图。
【Suppress table复选框】禁止在结果中输出行*列表。
【Statistics】按钮弹出Statistics对话框,用于定义所需计算的统计量。
Chi-square复选框:计算X2值。
Correlations复选框:计算行、列两变量的Pearson相关系数和Spearman等级相关系数。
Norminal复选框组:选择是否输出反映分类资料相关性的指标,很少使用。

X2检验X2检验是用途广泛的假设检验方法,它的原理是检验实际分布和理论分布的吻合程度。
主要用途有:两个及以上样本率(或构成比)之间差异比较,推断两变量间有无相关关系。
X2检验类型有:四格表资料X2检验(用于两样本率的检验),行×列表X2检验(用于两个及两个以上样本率或构成比的检验), 行×列列联表X2检验(用于计数资料的相关分析)。
在SPSS中,所有X2检验均用Crosstabs完成。
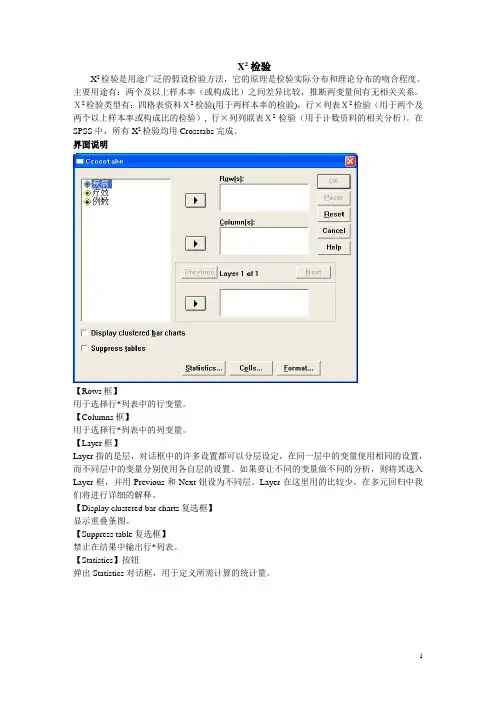
界面说明【Rows框】用于选择行*列表中的行变量。
【Columns框】用于选择行*列表中的列变量。
【Layer框】Layer指的是层,对话框中的许多设置都可以分层设定,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。
如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next钮设为不同层。
Layer在这里用的比较少,在多元回归中我们将进行详细的解释。
【Display clustered bar charts复选框】显示重叠条图。
【Suppress table复选框】禁止在结果中输出行*列表。
【Statistics】按钮弹出Statistics对话框,用于定义所需计算的统计量。
Chi-square复选框:计算X2值。
Correlations复选框:计算行、列两变量的Pearson相关系数和Spearman等级相关系数。
Norminal复选框组:选择是否输出反映分类资料相关性的指标,很少使用。
Contingency coefficient复选框:即列联系数,其值界于0~1之间;Phi and Cramer's V复选框:这两者也是基于X2值的,Phi在四格表X2检验中界于-1~1之间,在R*C表X2检验中界于0~1之间;Cramer's V 则界于0~1之间;Lambda复选框:在自变量预测中用于反映比例缩减误差,其值为1时表明自变量预测应变量好,为0时表明自变量预测应变量差;Uncertainty coefficient复选框:不确定系数,以熵为标准的比例缩减误差,其值接近1时表明后一变量的信息很大程度来自前一变量,其值接近0时表明后一变量的信息与前一变量无关。


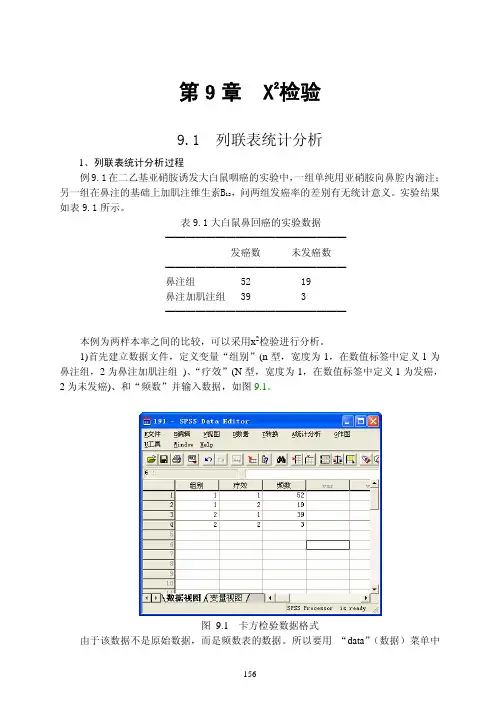
第9章 X2检验9.1 列联表统计分析1、列联表统计分析过程例9.1在二乙基亚硝胺诱发大白鼠咽癌的实验中,一组单纯用亚硝胺向鼻腔内滴注;另一组在鼻注的基础上加肌注维生素B12,问两组发癌率的差别有无统计意义。
实验结果如表9.1所示。
表9.1大白鼠鼻回癌的实验数据━━━━━━━━━━━━━━━━━━发癌数 未发癌数━━━━━━━━━━━━━━━━━━鼻注组 52 19鼻注加肌注组 39 3━━━━━━━━━━━━━━━━━━本例为两样本率之间的比较,可以采用x2检验进行分析。
1)首先建立数据文件,定义变量“组别”(n型,宽度为1,在数值标签中定义1为鼻注组,2为鼻注加肌注组)、“疗效”(N型,宽度为1,在数值标签中定义1为发癌,2为未发癌)、和“频数”并输入数据,如图9.1。
图 9.1 卡方检验数据格式由于该数据不是原始数据,而是频数表的数据。
所以要用“data”(数据)菜单中的weight cases(案例加权)来进行加权处理。
2)、单击Data(数据)菜单中的Weight Cases(案例加权)子菜单,弹出Weight Cases (案例加权)对话框,将“频数”变量单击进入Frequency Variable(频数变量)框内,按“频数”对数据进行加权,此时所有观测值相当于发生了“频数”次,如图9.1.2,单击Continue按钮返回主对话框。
图 9.2 案例加权3)、执行Analyze(统计分析)菜单|Descriptive Statistics(描述统计量)子菜单|Crosstabs…(交叉表)命令,系统弹出Crosstabs(交叉表)对话框,如图9.1.3,图 9.3交叉表对话框(1)单击变量从变量清单中选择1个(组别)或几个变量进入Row(s)(行)框中,作为交叉表的行,选择1个(疗效)或几个变量进入Column(s)(列)框中,作为交叉表的列,表示以“组别”变量为交叉表的行,以“疗效”为交叉表的列。



医学统计学第九章分类变量资料统计推断第九章χ2检验主要内容:一、四格表资料的χ2检验二、配对四格表资料的χ2检验三、R×C列联表资料的χ2检验第一节率的标准误与总体率的区间估计一、率的抽样误差与标准误在抽样调查中,由抽样造成的样本率与总体率之差,称为率的抽样误差,其大小可用率的标准误描述。
联想:抽样误差和均数的标准误x /x S复习率的标准误的计算公式:(1)p nππσ-=σp 为总体率的标准误,π为总体率,n 为样本含量。
复习(1)p p p S n-=当π未知时,可用样本率p 作为估计值,计算出样本率的标准误S p ,作为σp 估计值.例1为了解某地人群结核菌素试验阳性率情况,某医疗机构在该地人群中随机检测了1773人,结核菌素试验阳性有682人,阳性率为38.47%,试计算其标准误。
%16.10116.017733847.03847.0==)-(1=p s 分析:π未知,用p 来估计,s p 为δp 的估计,p=38.47%,1-p=61.53%二、总体率的区间估计①点估计:π=p②区间估计:按一定的概率(1-α),以p来估计π所在的范围。
一般α=0.05或0.01。
1、查表法因其计算比较复杂,统计学家已经编制了总体率可信区间估计用表,可根据样本含量n和阳性数x查阅统计学专著中的附表。
当n较小,如n 50,特别是p接近于0或1时,按二项分布原理估计总体率的可信区间。
例2 某市抽查了20名献血员乙型肝炎表面抗原(HBsAg)携带情况,阳性者4人,求该市献血员HBsAg阳性率的95%可信区间。
分析:n=20,实际发生数x=4,查表得上行:6~44(95%),下行4~51(99%)*如果n=20,实际发生的12(x大于n/2),如何查?先找n=20,1-x=8,查表得a~b,然后算得(100-b)~(100-a)2、正态近似法条件:n 足够大,p 和(1-p)均不太小,且np≥5和n(1-p)≥5时,p 近似服从正态分布。
统计学x2和p值计算过程统计学中X^2(卡方)检验和P值的计算过程是用于判断观察值与理论分布是否有显著差异的一种常用统计方法。
本文将详细介绍X^2检验和P值计算的过程。
一、X^2(卡方)检验概述X^2(卡方)检验是一种非参数统计方法,适用于观测数据是分类变量的情况。
它的核心思想是将观测值与理论值进行比较,通过计算卡方值来判断它们之间的差异程度。
计算具体过程如下:1.建立假设:在进行X^2检验时,首先需要建立原假设和备择假设。
原假设(H0)通常为“观测值与理论分布没有显著差异”,备择假设(H1)则通常为“观测值与理论分布存在显著差异”。
2.构建列联表:X^2检验通常使用列联表(Contingency Table)来整理数据,列联表是一个二维表格,行列分别代表两个变量的不同取值,交叉单元中的数值表示对应取值下的观测频数。
3.计算期望值:期望值是指在原假设成立的情况下,理论上每个交叉单元中的期望频数。
计算期望值的公式为:期望频数=(对应行的总频数*对应列的总频数)/总频数。
4.计算卡方值:计算卡方值的公式为:X^2=Σ(观测频数-期望频数)^2/期望频数。
计算得到的卡方值越大,观测值与理论分布之间的差异越大。
5.判断显著性:判断观测值与理论分布之间的差异是否显著,需要结合自由度和显著性水平进行判断。
计算卡方值后,可以查阅卡方分布表,根据初始设定的显著性水平(通常为0.05),确定拒绝域。
6.计算P值:P值是指在原假设成立的情况下,观察到当前或者更极端情况下的概率。
根据卡方分布的性质,可以通过查表或利用统计软件计算出对应的P 值。
如果P值小于设定的显著性水平,就拒绝原假设;否则,不能拒绝原假设。
二、P值计算的方法在进行X^2检验时,计算P值的方法有两种:查表法和计算器法。
下面将分别介绍这两种方法。
1.查表法:查表法是通过查找卡方分布表,确定对应卡方值所对应的P值。
卡方分布表通常提供不同自由度(df,自由度等于行数减1乘以列数减1)和显著性水平下的卡方临界值。