SPSS列联表分析
- 格式:ppt
- 大小:2.03 MB
- 文档页数:53

2 列联表分析(Crosstabs)列联表是指两个或多个分类变量各水平的频数分布表,又称频数交叉表。
SPSS的Crosstabs过程,为二维或高维列联表分析提供了22种检验和相关性度量方法。
其中卡方检验是分析列联表资料常用的假设检验方法。
例子:山东烟台地区病虫测报站预测一代玉米螟卵高峰期。
预报发生期y为3级(1级为6月20日前,2级为6月21-25日,3级为6月25日后);预报因子5月份平均气温x1(℃)分为3级(1级为16.5℃以下,2级为16.6-17.8℃,3级为17.8℃以上),6月上旬平均气温x2(℃)分为3级(1级为20℃以下,2级为20.1-21.5℃,3级为21.5℃以上),6月上旬降雨量x3(mm)分为3级(1级为15mm以下,2级为15.1-30mm,3级为30mm以上),6月中旬降雨量x4(mm)分为3级(1级为29mm以下,2级为29.1-36mm,3级为36mm以上)。
数据如下表。
山东烟台历年观测数据分级表()注:摘自《农业病虫统计测报》 131页。
1) 输入分析数据在数据编辑器窗口打开“”数据文件。
数据文件中变量格式如下:2)调用分析过程在菜单选中“Analyze-Descriptive- Crosstabs”命令,弹出列联表分析对话框,如下图3)设置分析变量选择行变量:将“五月气温[x1],六月上气温[x2],六月上降雨[x3],六月中降雨[x4]”变量选入“Rows:”行变量框中。
选择列变量:将“玉米螟卵高峰发生期[y]”变量选入“Columns:”列变量框中。
4)输出条形图和频数分布表Display clustered bar charts: 选中显示复式条形图。
Suppress table: 选中则不输出多维频数分布表。
5)统计量输出点击“Statistics”按钮,弹出统计分析对话框(如下图)。
Chi-Square: 卡方检验。
选中可以输出皮尔森卡方检验(Pearson)、似然比卡方检验(Likelihood-ratio)、连续性校正卡方检验(Continuity Correction)及Fisher精确概率检验(Fisher’s Exact test)的结果。

应用SPSS软件进行列联表分析在许多调查研究中,所得到的数据大多为定性数据,即名义或定序尺度测量的数据。
例如在一项全球教育水平的研究中,调查了400余人的个人信息,包括性别、学历、种族等,对原始资料进行整理就可以得到频数分布表。
定义四个变量:gender(性别)、educat(学历)、minority(种族)、count(人数),其中前三个为分类变量,并且gender变量取值为0、1,标签值定义为:0表示female,1表示male;educat变量取值为1、2、3,标签值定义为:1表示学历低,2表示学历中等,3表示学历高;minority变量值为0、1,标签值定义为:0表示非少数种族,1表示为少数种族。
下面做gender、educat、minority的三维列联表分析及其独立性检验。
数据文件如图1所示。
图1第一步:用“count”变量作为权重进行加权分析处理。
从菜单上依次选Data--weight Cases 命令,打开对话框,如图2所示。
图2点选Weight Cases by项,并将变量“count”移入Frequency Variable栏下,之后单击OK按钮。
第二步:从菜单上依次点选Analyze--Deseriptive Statistics--Crosstabs命令,打开列联分析对话框(Crosstabs),如图3所示。
图3第三步:在Crosstabs对话框中,如图4将变量性别gender从左侧的列表框内移入行变量Row(s)框内,并将受教育年限编码后得到的学历变量educat移入列变量Column(s)框内(若此时单击OK按钮,则会输出一个2*3的二维列联表)。
这里要输出一个三维列联表,将变量种族minority作为分层变量移入Layer框中,并且可以勾选左下方的Display clustered bar charts项,以输出聚集的条形图,如图8图9所示。
图4第四步:选择统计量,单击Cosstabs对话框下侧的Statistics按钮,打开其对话框,如图5 所示。





应用SPSS 软件进行列联表分析应用SPSS软件进行列联表分析在许多调查研究中,所得到的数据大多为定性数据,即名义或定序尺度测量的数据。
例如在一项全球教育水平的研究中,调查了400余人的个人信息,包括性别、学历、种族等,对原始资料进行整理就可以得到频数分布表。
定义四个变量:gender(性别)、educat (学历)、minority (种族)、count (人数),其中前三个为分类变量,并且gender变量取值为0、1,标签值定义为:0表示female,1表示male;educat变量取值为1、2、3,标签值定义为:1表示学历低,2表示学历中等,3表示学历高;minority变量值为0、1,标签值定义为:0表示非少数种族,1表示为少数种族。
下面做gen der.educa t minority的三维列联表分析及其独立性检验。
数据文件如图1所示。
ye Edit 辿ew Derta Transforfti Analyse Graphs Utlltie^ Add-cns Window Help®■昌国穷》8h再鄭H<5曲圜flj靄20图1第一步:用’Count”变量作为权重进行加权分析处理。
从菜单上依次选Data--weight Cases命令,打开对话框,如图2所示。
点选Weight Cases by项,并将变量“count”移入Frequency Variable栏下,之后单击OK按钮。
第二步:从菜单上依次点选An alyze--Deseriptive Statistics-Crosstabs命令,打开列联分析对话框(Crosstabs)如图3所示Fdi 迥 E住rH 丁 T W TPI►i : K 「Tl19CnprCdlK1 13131X5 0GCl 71H 1 9 1 tc 0 11皿F 耳第三步:在Crosstabs 对话框中,如图4将变量性别gender 从左侧的列表框内移 入行变量Row(s)框内,并将受教育年限编码后得到的学历变量educat 移入列变量Column(s)框内(若此时单击OK 按钮,则会输出一个2*3的二维列联表)。
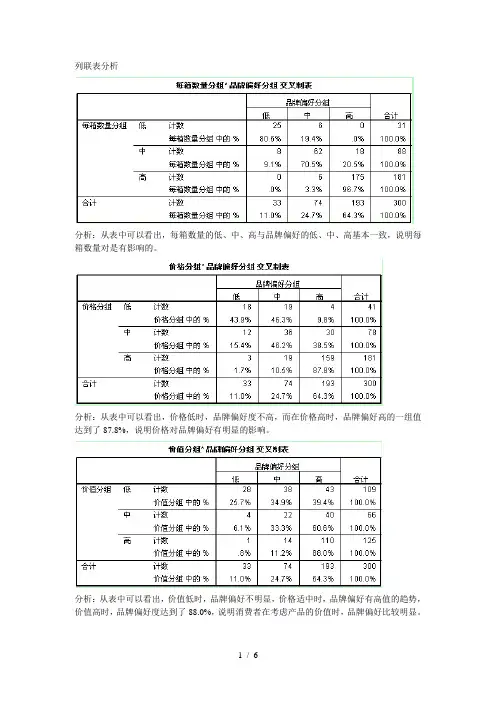
列联表分析分析:从表中可以看出,每箱数量的低、中、高与品牌偏好的低、中、高基本一致,说明每箱数量对是有影响的。
分析:从表中可以看出,价格低时,品牌偏好度不高,而在价格高时,品牌偏好高的一组值达到了87.8%,说明价格对品牌偏好有明显的影响。
分析:从表中可以看出,价值低时,品牌偏好不明显,价格适中时,品牌偏好有高值的趋势,价值高时,品牌偏好度达到了88.0%,说明消费者在考虑产品的价值时,品牌偏好比较明显。
分析:从表中可以看出,在护肤的低、中、高三组中,品牌偏好度高的比例都比较高,说明消费者在考虑产品护肤时,有较高的品牌偏好。
分析:从表中可以看出,在样式的低、中、高三组中,品牌偏好度高的比例都比较高,说明消费者在考虑产品样式时,有较高的品牌偏好。
分析:从表中可以看出,随着吸水性由低到高,品牌偏好的高值比例也在增加,说明吸水性越好,品牌选择偏好越明显。
分析:从表中可以看出,随着渗漏值由低到高,品牌偏好的高值比例也在增加,说明渗漏越差,品牌选择偏好越明显。
分析:从表中可以看出,在舒适度上,品牌偏好的高值比例一直都很高,说明在考虑产品的舒适度时,品牌偏好非常明显。
分析::从表中可以看出,在考虑舒胶带时,品牌偏好的高值比例一直都很高,说明在考虑产品是重复粘贴胶带还是普通胶带时,品牌偏好非常明显。
分析:这是控制了价格时的每箱数量和品牌偏好,可以看出,在价格低时,每箱数量的低、中、高与品牌偏好的低、中、高还是有关系的,但是与没有控制价格时相比,两者之间的关系被削弱了。
价格适中时,也是如此。
在价格高时,关系更加清晰。
分析:这是控制了样式时的护肤与品牌偏好,可以看出,在样式低组和中组,护肤与品牌偏好之间原有的关系被逆反了,只有在样式的值高的时候,护肤与品牌偏好才有一定正向相关关系。
分析:这是控制胶带时的舒适度与品牌偏好,可以看出,控制胶带以后,舒适度与品牌偏好完全一致,这加强了舒适度与品牌偏好之间原有的高度相关性。

