EG两步法协整检验和误差修正模型的建立
- 格式:doc
- 大小:1006.00 KB
- 文档页数:4
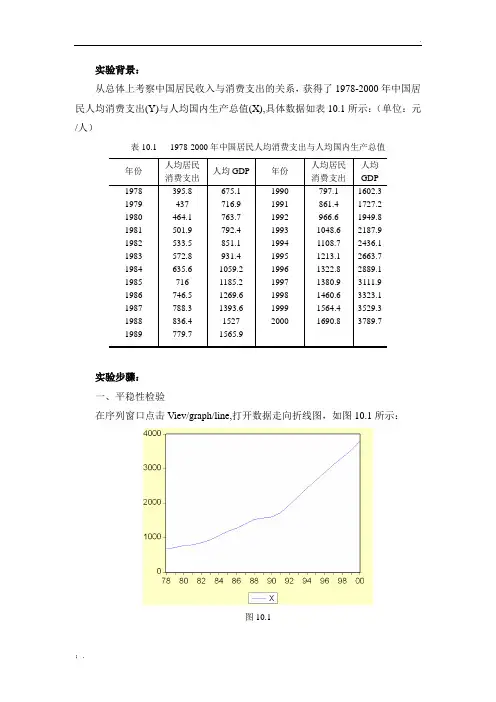
实验背景:从总体上考察中国居民收入与消费支出的关系,获得了1978-2000年中国居民人均消费支出(Y)与人均国内生产总值(X),具体数据如表10.1所示:(单位:元/人)表10.1 1978-2000年中国居民人均消费支出与人均国内生产总值年份人均居民消费支出人均GDP 年份人均居民消费支出人均GDP1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989395.8437464.1501.9533.5572.8635.6716746.5788.3836.4779.7675.1716.9763.7792.4851.1931.41059.21185.21269.61393.615271565.919901991199219931994199519961997199819992000797.1861.4966.61048.61108.71213.11322.81380.91460.61564.41690.81602.31727.21949.82187.92436.12663.72889.13111.93323.13529.33789.7实验步骤:一、平稳性检验在序列窗口点击Viev/graph/line,打开数据走向折线图,如图10.1所示:图10.1从人均国内生产总值折线图可以粗略判断其不是一个平稳时间序列。
现采用单位根来进一步检验其是否平稳。
在序列窗口,选择Vive/Unit Root Test,打开单位根检验对话框,如图10.2所示:图10.2图10.2共包含以下几个部分:Test type:用于选择检验类型。
EViews5提供了6种单位根检验的方法:Augmented Dickey-Fuller(ADF) Test、Dickey-Fuller GLS(ERS)、Phillips-Perron(PP) Test、Kwiatkowski,Phillips,Schmidt and Shin (KPSS) Test、Elliot,Rothenberg,and Stock Point Optimal(ERS) 、Test Ng and Perron (NP) Test。


模型建立—时间序列eviews协整检验EG两步法(Engle-Granger)1.首先,需要两列时间序列数据,将他们命名为future4,future5,存入eviews。
2.对两组数据取对数,得新的数据:P4=log(future4),P5=log(future5)。
可在eviews中点击Genr输入p4=log(future4)可自动产生对数数列。
为何取对数?:可以部分消除异方差的问题,另外,其差分可以表示发展速度的对数,也可以消除序列相关的问题.有时候要看经济意义!取对数也可减少数据的波动,在高频数据中尤是。
变量取对数是为了消除异方差,系数也是弹性系数,主要是为了消除金融时间序列的异方差现象,可以将可能的非线性关系转化为线性关系,减少变量的极端值、非正态分布以及异方差性(2012.4.10补充,针对上面提到的非线性关系转化为线性关系,做进一步的解释:经济序列通常做对数化处理,因为log有很多优良特性。
如取对数,很容易操作,正如上面所说,输入log(x)就可以产生原数列相应的对数数列。
还有一些关系式如log(a*b)=log(a)+log(b),log(a^2)=2*log(a),这种特性可以很容易的把函数之间的关系线性化。
加上log,常可以使得经济数列变得更容易处理。
)3.对两个时间序列分别做ADF检验。
1.eviews中选取时间序列P4,右键=》open。
在新的窗口中点击view=》unit root test。
2.ADF检验需要对3个模型依次检验,所以在unit root test窗口中先①选:level、trend and intercept。
然后确认=》得到第一行是所得t值,下面3行是临界值。
t=-2.0665>临界值,因此非平稳。
因此要继续检验②:level、intercept,假设还是非平稳。
继续检验③:level none。
假设还是非平稳,则做一阶差分,即将level换成1st difference,将之前①②③从新来过,一旦t<临界值就可以停止了。






什么是误差修正模型(ECM)如何建立和估计ECM模型误差修正模型(Error Correction Model, ECM)是一种用于揭示时间序列数据中长期和短期关系的统计模型。
它是基于协整理论(Cointegration Theory)的发展而来,用于处理非平稳时间序列数据的建模和分析。
本文将介绍误差修正模型的基本概念、建立方法以及估计过程。
一、误差修正模型的基本概念误差修正模型是基于向量自回归模型(Vector Autoregressive Model, VAR)的延伸,用于描述经济系统中变量之间的动态关系。
它的核心思想是变量之间存在长期均衡关系,并且当系统偏离均衡状态时,会通过误差修正机制迅速回归到均衡。
在误差修正模型中,被解释变量(因变量)的变化量由其自身的滞后项、其他变量的滞后项和误差修正项来决定。
其中,误差修正项是系统偏离均衡状态的驱动力,它通过反映系统失衡的程度来进行调整,促使系统回归到长期均衡。
因此,误差修正模型可以同时捕捉长期和短期的关系,具有强大的解释和预测能力。
二、建立误差修正模型的方法建立误差修正模型主要包括两个步骤:协整关系检验和模型参数估计。
1. 协整关系检验协整关系检验是判断变量之间是否存在长期均衡关系的重要步骤。
常用的协整关系检验方法包括ADF检验(Augmented Dickey-Fuller test)、PP检验(Phillips-Perron test)等。
这些检验方法可以判断变量是否为非平稳的单整序列,以及变量之间是否存在稳定的线性关系。
2. 模型参数估计在进行误差修正模型参数估计之前,需要确定模型的滞后阶数(Lag Order)。
滞后阶数的选择可以通过信息准则(如AIC、BIC等)来确定,准则值较小的滞后阶数会得到更好的模型拟合效果。
模型参数估计可以使用最小二乘法(Ordinary Least Squares, OLS)或极大似然估计法(Maximum Likelihood Estimation, MLE)进行。

E-G两步法协整检验和误差修正模型的建立实验内容:使用Eviews软件进行E-G两步法协整检验的操作,并建立误差修正模型。
分析我国居民实际可支配收入与居民实际消费之间是否存在长期均衡关系。
实验数据:我国的实际居民消费和实际可支配收入,变量均为剔除了价格因素的实际年度数据,样本区间为1978—2006年。
数据来源于各年的统计年鉴。
实验过程:1、实际居民消费CSP等于名义居民消费CS除于CPI,实际可支配收入INC 等于名义可支配收入YD除于CPI。
把上述数据导入到Eviews中,建立相应的系列。
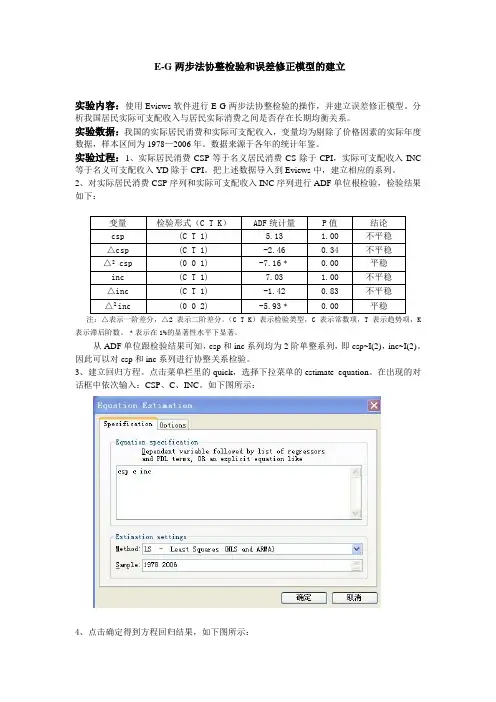
2、对实际居民消费CSP序列和实际可支配收入INC序列进行ADF单位根检验,检验结果如下:变量检验形式(C T K)ADF统计量P值结论csp (C T 1) 5.13 1.00 不平稳△csp (C T 1) -2.46 0.34 不平稳△2 csp (0 0 1) -7.16﹡0.00 平稳inc (C T 1) 7.03 1.00 不平稳△inc (C T 1) -1.42 0.83 不平稳△2 inc (0 0 2) -5.93﹡0.00 平稳注:△表示一阶差分,△2 表示二阶差分。
(C T K)表示检验类型,C表示常数项,T表示趋势项,K 表示滞后阶数。
﹡表示在1%的显著性水平下显著。
从ADF单位跟检验结果可知,csp和inc系列均为2阶单整系列,即csp~I(2),inc~I(2)。
因此可以对csp和inc系列进行协整关系检验。
3、建立回归方程。
点击菜单栏里的quick,选择下拉菜单的estimate equation。
在出现的对话框中依次输入:CSP、C、INC。
如下图所示:4、点击确定得到方程回归结果,如下图所示:5、在方程对象框中,单击proc,选择 make residual series,生成方程的残差系列,命名为“e”。
并对e系列进行ADF单位根检验,检验结果如下图所示:检验形式为即不包含常数项也不包含趋势项。
问题1:EG两步法做协整检验的思路?
思路1:以两个变量为例,在变量满足同阶单整的条件下,对变量做OLS,对残差的平稳性做检验,如果残差平稳,那么认为两个变量之间存在协整关系,同时进一步做误差修正模型,并对误差修正模型的残差进行自相关检验,如果存在自相关,要加入变量的滞后项消除自相关。
思路2:以两个变量为例,在变量满足同阶单整的前提下,对变量做OLS,先对回归方程的残差进行自相关检验,如果存在自相关先消除自相关,然后对消除自相关的回归方程的残差进行平稳性检验,如果残差平稳,则认为两个变量之间存在协整关系。
以上两种思路,那一种正确?第二种思路中,做残差平稳性检验之前先消除了自相关,比如加入了AR(1),
那么在做误差修正模型时,较思路1,加入的AR(1)应该如何处理?
问题2:如何做两个变量之间的定量分析?
如果两个变量之间存在着协整关系,那么可以写出一个表达式如Y=c+aX+u,如何在前两个变量之间的基础上,再引进一个变量,同样三个变量之间存在这一种协整关系,可以写出一个表达式如Y=c+AX+BZ+u,那么系数a和A会不同,这样的话应该如何做变量Y和X之间的定量分析?
方法1:先做因素分析,把影响Y的所有因素都找出来,然后做变量之间的协整检验,存在协整关系的前提下建立一个表达长期均衡的关系式,并用表达式中X的系数表示X对Y的影响
方法2:只做X与Y的协整检验,其它同方法1。
VAR模型稳定条件:①相反的特征方程| I - ∏1L | = 0的根都在单位圆以外②特征方程 |λ I - ∏1| = 0的根都在单位圆以内高阶VAR模型稳定的条件:①相反的特征方程| I- ∏1 L - ∏2 L2 - ∏3 L3-…-∏k Lk |=0的全部根必须在单位圆以外。
②VAR模型的稳定性要求A的全部特征值,即特征方程 | A - λ I | = 0的全部根必须在单位圆以内三、概念题1、白噪声模型对于随机过程{ xt , t∈T }, 如果(1) E(xt) = 0, (2) Var(xt) = σ2 <∞, t∈T;(3) Cov(xt ,xt + k)=0, (t + k ) ∈ T , k ≠ 0 , 则称{xt}为白噪声过程。
白噪声是平稳的随机过程,因其均值为零,方差不变,随机变量之间非相关。
显然上述白噪声是二阶宽平稳随机过程。
2、宽平稳过程(1)m阶宽平稳过程。
如果一个随机过程m阶矩以下的矩的取值全部与时间无关,则称该过程为m阶宽平稳过程。
(2)二阶宽平稳过程。
如果一个随机过程{xt} E[x(t) ] = E[x(t +k)] = μ< ∞,Var[x(t)] = Var[x(t +k)] = σ 2 < ∞, Cov[x(ti ),x(tj)] =Cov[x(ti+k),x(tj+k)]=σ2i j < ∞,其中μ, σ 2 和σij2为常数,不随 t, (t∈T ); k,((tr+ k)∈T, r = i, j ) 变化而变化,则称该随机过程 {x t} 为二阶平稳过程。
该过程属于宽平稳过程。
3、随机游走(random walk)过程对于表达式xt = xt -1 + ut,如果ut为白噪声过程,则称xt为随机游走过程。
4、p阶自回归模型如果一个线性过程xt可表达为xt = φ1xt-1+ φ2xt-2+ … + φpxt-p+ ut其中φi ,i =1,…,p 是自回归参数,ut是白噪声过程,则称xt为p阶自回归过程,用AR(p)表示。
1.什么是计量经济学?它与经济学、统计学和数学的关系怎样?答:1、计量经济学是一门运用经济理论和统计技术来分析经济数据的科学和艺术,它以经济理论为指导,以客观事实为依据,运用数学、统计学的方法和计算机技术,研究带有随机影响的经济变量之间的数量关系和规律。
2、经济理论、数学和统计学知识是在计量经济学这一领域进行研究的必要前提,这三者中的每一个对于真正理解现代经济生活中的数量关系是必要的,但不充分,只有结合在一起才行。
2计量经济学三个要素是什么?经济理论、经济数据和统计方法.3。
计量经济学模型的检验包括哪几个方面?其具体含义是什么?答:(1)经济意义检验,即根据拟定的符号、大小、关系,对参数估计结果的可靠性进行判断(2)统计检验,由数理统计理论决定。
包括:拟合优度检验、总体显著性检验。
(3)计量经济学检验,由计量经济学理论决定。
包括:异方差性检验、序列相关性检验、多重共线性检验.(4)模型预测检验,由模型应用要求决定。
包括:稳定性检验:扩大样本重新估计;预测性能检验:对样本外一点进行实际预测。
4。
计量经济学方法与一般经济数学方法有什么区别?答:计量经济学揭示经济活动中各因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各因素之间的理论关系,用确定性的数学方程加以描述。
5。
计量经济学模型研究的经济关系有那两个基本特征?一是随机关系,二是因果关系6.计量经济学研究的对象和核心内容是什么?计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律。
计量经济学的核心内容包括两个方面:一是方法论,即计量经济学方法或者理论计量经济学。
二是应用,即应用计量经济学.无论是理论计量经济学还是应用计量经济学,都包括理论、方法和数据三种要素。
7.计量经济学中应用的数据类型怎样?举例解释其中三种数据类型的结构.计量经济模型:WAGE=f(EDU,EXP,GEND,μ)1、时间序列数据是按时间周期收集的数据,如年度或季度的国民生产总值。
§3.2 时间序列的协整检验与误差修正模型一、长期均衡关系与协整二、协整的E-G检验二协整的三、协整的JJ检验四、关于均衡与协整关系的讨论关均衡与协整关系的讨论五、结构变化时间序列的协整检验六、误差修正模型一、长期均衡与协整分析q g Equilibrium and Cointegration1、问题的提出•经典回归模型(classical regression model)是建立在平稳数据变量基础上的,对于非平稳变量,不能使用经典回归模型,否则会出现虚假回归等诸多问题。
•由于许多经济变量是非平稳的,这就给经典的回归分析方法带来了很大限制。
•但是,如果变量之间有着长期的稳定关系,即它们之间是协整的(cointegration),则是可以使用经典回归模型方法建立回归模型的。
例如,中国居民人均消费水平与人均GDP变量的例子,从•例如,中国居民人均消费水平与人均GDP变量的例子经济理论上说,人均GDP决定着居民人均消费水平,它们之间有着长期的稳定关系,即它们之间是协整的。
2、长期均衡•经济理论指出,某些经济变量间确实存在着长期均衡关系这种均衡关系意味着经济系统不存在破坏均衡的内在系,这种均衡关系意味着经济系统不存在破坏均衡的内在机制,如果变量在某时期受到干扰后偏离其长期均衡点,则均衡机制将会在下一期进行调整以使其重新回到均衡状态。
假设X 与Y 间的长期“均衡关系”由式描述tt t X Y μαα++=10该均衡关系意味着:给定X 的一个值,Y 相应的均衡值也随 之确定为 α0+α1X 。
•期末存在下述三种情形之一:在t-1期末,存在下述三种情形之:–Y 等于它的均衡值:Y t-1=α0+α1X t ;–Y 小于它的均衡值:Y t-1<α0+α1X t ;–t 1+Y 大于它的均衡值:Y t-1>α0α1X t ;•在时期t ,假设X 有一个变化量∆X t ,如果变量X 与在时末仍满它间的均衡关Y 在时期t 与t-1末期仍满足它们间的长期均衡关系,即上述第一种情况,则Y 的相应变化量为:tt t v X Y +∆=∆1αv t =μt -μt-1•如果t-1期末,发生了上述第二种情况,即Y 的值小于其均衡值,则t 期末Y 的变化往往会比第种情形下的变化大些一种情形下Y 的变化大一些;•反之,如果t-1期末Y 的值大于其均衡值,则t 期的变化往往会小于第种情形下的末Y 的变化往往会小于第一种情形下的∆Y t 。