计量经济学线性回归模型
- 格式:ppt
- 大小:1.09 MB
- 文档页数:37





计量经济学回归分析模型计量经济学是经济学中的一个分支,通过运用数理统计和经济理论的工具,研究经济现象。
其中回归分析模型是计量经济学中最为常见的分析方法之一、回归分析模型主要用于确定自变量与因变量之间的关系,并通过统计推断来解释这种关系。
回归分析模型中的关系可以是线性的,也可以是非线性的。
线性回归模型是回归分析中最为常见和基础的模型。
它可以表示为:Y=β0+β1X1+β2X2+...+βkXk+ε其中,Y代表因变量,X1,X2,...,Xk代表自变量,β0,β1,β2,...,βk代表回归系数,ε代表随机误差项。
回归模型的核心是确定回归系数。
通过最小二乘法估计回归系数,使得预测值与实际观测值之间的差异最小化。
最小二乘法通过使得误差的平方和最小化来估计回归系数。
通过对数据进行拟合,我们可以得到回归系数的估计值。
回归分析模型的应用范围非常广泛。
它可以用于解释和预测经济现象,比如价格与需求的关系、生产力与劳动力的关系等。
此外,回归分析模型还可以用于政策评估和决策制定。
通过分析回归系数的显著性,可以判断自变量对因变量的影响程度,并进行政策建议和决策制定。
在实施回归分析模型时,有几个重要的假设需要满足。
首先,线性回归模型要求因变量和自变量之间存在线性关系。
其次,回归模型要求自变量之间不存在多重共线性,即自变量之间没有高度相关性。
此外,回归模型要求误差项具有同方差性和独立性。
在解释回归分析模型的结果时,可以通过回归系数的显著性来判断自变量对因变量的影响程度。
显著性水平一般为0.05或0.01,如果回归系数的p值小于显著性水平,则说明该自变量对因变量具有显著影响。
此外,还可以通过确定系数R^2来评估模型的拟合程度。
R^2可以解释因变量变异的百分比,值越接近1,说明模型的拟合程度越好。
总之,回归分析模型是计量经济学中非常重要的工具之一、它通过分析自变量和因变量之间的关系,能够解释经济现象和预测未来走势。
在应用回归分析模型时,需要满足一定的假设条件,并通过回归系数和拟合优度来解释结果。
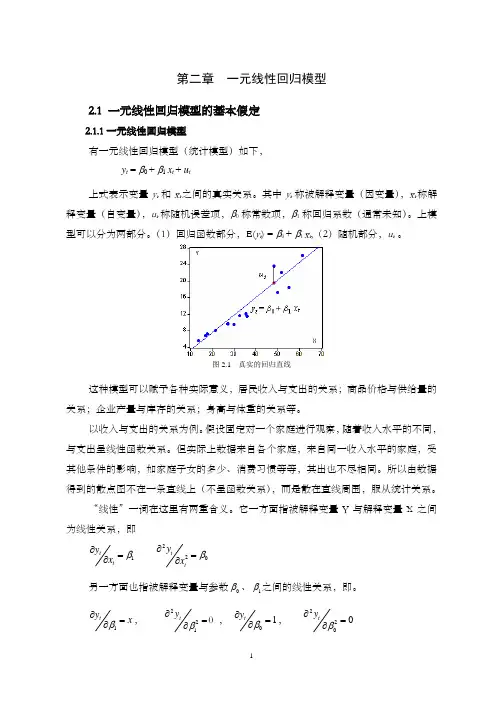
第二章 一元线性回归模型2.1 一元线性回归模型的基本假定2.1.1一元线性回归模型有一元线性回归模型(统计模型)如下, y t = β0 + β1 x t + u t上式表示变量y t 和x t 之间的真实关系。
其中y t 称被解释变量(因变量),x t 称解释变量(自变量),u t 称随机误差项,β0称常数项,β1称回归系数(通常未知)。
上模型可以分为两部分。
(1)回归函数部分,E(y t ) = β0 + β1 x t ,(2)随机部分,u t 。
图2.1 真实的回归直线这种模型可以赋予各种实际意义,居民收入与支出的关系;商品价格与供给量的关系;企业产量与库存的关系;身高与体重的关系等。
以收入与支出的关系为例。
假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。
但实际上数据来自各个家庭,来自同一收入水平的家庭,受其他条件的影响,如家庭子女的多少、消费习惯等等,其出也不尽相同。
所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。
“线性”一词在这里有两重含义。
它一方面指被解释变量Y 与解释变量X 之间为线性关系,即1tty x β∂=∂220tt y x β∂=∂另一方面也指被解释变量与参数0β、1β之间的线性关系,即。
1ty x β∂=∂,221ty β∂=∂0 ,1ty β∂=∂,2200ty β∂=∂2.1.2 随机误差项的性质随机误差项u t 中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。
所以在经济问题上“控制其他因素不变”是不可能的。
随机误差项u t 正是计量模型与其它模型的区别所在,也是其优势所在,今后咱们的很多内容,都是围绕随机误差项u t 进行了。
回归模型的随机误差项中一般包括如下几项内容: (1)非重要解释变量的省略, (2)数学模型形式欠妥, (3)测量误差等,(4)随机误差(自然灾害、经济危机、人的偶然行为等)。



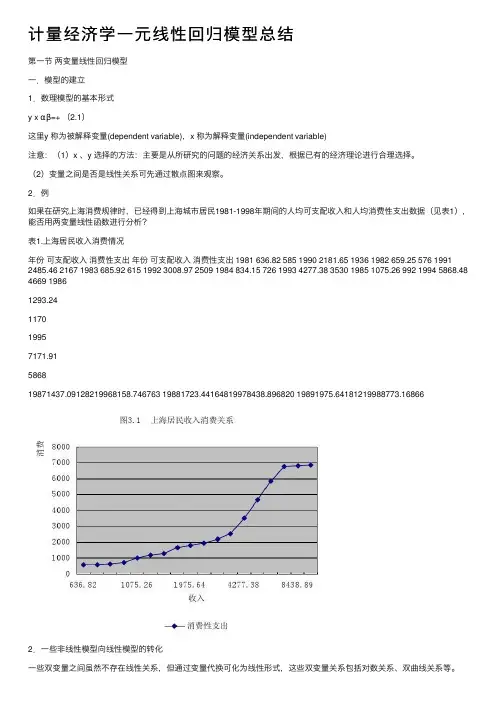
计量经济学⼀元线性回归模型总结第⼀节两变量线性回归模型⼀.模型的建⽴1.数理模型的基本形式y x αβ=+ (2.1)这⾥y 称为被解释变量(dependent variable),x 称为解释变量(independent variable)注意:(1)x 、y 选择的⽅法:主要是从所研究的问题的经济关系出发,根据已有的经济理论进⾏合理选择。
(2)变量之间是否是线性关系可先通过散点图来观察。
2.例如果在研究上海消费规律时,已经得到上海城市居民1981-1998年期间的⼈均可⽀配收⼊和⼈均消费性⽀出数据(见表1),能否⽤两变量线性函数进⾏分析?表1.上海居民收⼊消费情况年份可⽀配收⼊消费性⽀出年份可⽀配收⼊消费性⽀出 1981 636.82 585 1990 2181.65 1936 1982 659.25 576 1991 2485.46 2167 1983 685.92 615 1992 3008.97 2509 1984 834.15 726 1993 4277.38 3530 1985 1075.26 992 1994 5868.48 4669 19861293.24117019957171.91586819871437.09128219968158.746763 19881723.44164819978438.896820 19891975.64181219988773.168662.⼀些⾮线性模型向线性模型的转化⼀些双变量之间虽然不存在线性关系,但通过变量代换可化为线性形式,这些双变量关系包括对数关系、双曲线关系等。
例3-2 如果认为⼀个国家或地区总产出具有规模报酬不变的特征,那么采⽤⼈均产出y与⼈均资本k的形式,该国家或者说地区的总产出规律可以表⽰为下列C-D⽣产函数形式y Akα=(2.2)也就是⼈均产出是⼈均资本的函数。
能不能⽤两变量线性回归模型分析这种总量⽣产规律?3.计量模型的设定(1)基本形式:y x αβε=++ (2.3)这⾥ε是⼀个随机变量,它的数学期望为0,即(2.3)中的变量y 、x 之间的关系已经是不确定的了。

计量经济学1、一元线性回归模型:建立两个变量的数学模型:Yi=β₁+β₂Xi +μi ,Yi 为被解释变量。
Xi 为解释变量。
μi 为随机误差项(随机扰动项或随机项、误差项)。
β₁,β₂为回归系数(待定系数、待定参数),这样的模型含有一个解释变量,而且变量之间的关系又是线性的,所以上式称为一元线性回归模型。
2、线性回归模型的基本假设:假设1、解释变量X 是确定性变量,不是随机变量;假设2、随机误差项μi 具有零均值、同方差和不序列相关性:E(μi )=0 i=1,2, …,n 。
V ar(μi )= δu² i=1,2, …,n 。
Cov(μi ,μj)=0,i≠j i,j= 1,2, …n,假设3、随机误差项μi 与解释变量X之间不相关:Cov(Xi,μi)=0 i=1,2, …,n,假设4、μi 服从零均值、同方差、零协方差的正态分布: μi -N(0,δu²)i=1,2, …,n 。
注意:1、如果假设1、2满足,则假设3也满足;2、如果假设4满足,则假设2也满足。
3、普通最小二乘法(OLS ):为了研究总体回归模型中变量X 和Y 之间的线性关系,需要求一条拟合直线,一条好的拟合直线应该是使残差平方和达到最小,以此为准则,确定X 与Y之间的线性关系。
4、回归系数:β₁=1/n ﹙∑Yi -β₂∑Xi ﹚,β₂=n∑XiYi -∑Xi∑Yi /n∑Xi²-﹙∑Xi ﹚²5、常用结果:1、∑ei=0即残差项ei 的均值为0,2、∑eiXi=0即残差项ei 与解释变量Xi 不相关。
3、样本回归方程可以写成Yi º-¯Y¯=β₂(Xi-¯X¯)即样本回归直线过点(¯X¯, ¯Y¯)4、¯Yi º¯=¯Y¯即被解释变量的样本平均值等于其估计值的平均值6、样本可决系数:对样本回归直线与样本观测值之间拟合程度的检验。
计量经济学4种常用模型计量经济学是经济学的一个重要分支,主要研究经济现象的数量关系及其解释。
在计量经济学中,常用的模型有四种,分别是线性回归模型、时间序列模型、面板数据模型和离散选择模型。
下面将对这四种模型进行详细介绍。
第一种模型是线性回归模型,也是计量经济学中最常用的模型之一。
线性回归模型是通过建立自变量与因变量之间的线性关系来解释经济现象的模型。
在线性回归模型中,自变量通常包括经济学理论认为与因变量相关的变量,通过最小二乘法估计模型参数,得到经济现象的解释。
线性回归模型的优点是简单易懂,计算方便,但其前提是自变量与因变量之间存在线性关系。
第二种模型是时间序列模型,它主要用于分析时间序列数据的模型。
时间序列模型假设经济现象的变化是随时间演变的,通过分析时间序列的趋势、周期性和随机性,可以对经济现象进行预测和解释。
时间序列模型的常用方法包括自回归移动平均模型(ARMA)、自回归条件异方差模型(ARCH)等。
时间序列模型的优点是能够捕捉到时间的动态变化,但其局限性是对数据的要求较高,需要足够的时间序列观测样本。
第三种模型是面板数据模型,也称为横截面时间序列数据模型。
面板数据模型是将横截面数据和时间序列数据结合起来进行分析的模型。
面板数据模型可以同时考虑个体间的差异和时间的变化,因此能够更全面地解释经济现象。
面板数据模型的常用方法包括固定效应模型、随机效应模型等。
面板数据模型的优点是能够控制个体间的异质性,但其需要对个体间的相关性进行假设。
第四种模型是离散选择模型,它主要用于分析离散选择行为的模型。
离散选择模型假设个体在面临多种选择时,会根据一定的规则进行选择,通过建立选择概率与个体特征之间的关系,可以预测和解释个体的选择行为。
离散选择模型的常用方法包括二项Logit模型、多项Logit模型等。
离散选择模型的优点是能够分析个体的选择行为,但其局限性是对选择行为的假设较强。
综上所述,计量经济学中常用的模型有线性回归模型、时间序列模型、面板数据模型和离散选择模型。
计量经济学实验简单线性回归模型引言计量经济学是经济学中的一个分支,致力于通过经验分析和实证方法来研究经济问题。
实验是计量经济学中的重要方法之一,能够帮助我们理解和解释经济现象。
简单线性回归模型是实验中常用的工具之一,它能够通过建立两个变量之间的数学关系,预测一个变量对另一个变量的影响。
本文将介绍计量经济学实验中的简单线性回归模型及其应用。
简单线性回归模型模型定义简单线性回归模型是一种用于描述自变量(X)与因变量(Y)之间关系的线性模型。
其数学表达式为:Y = β0 + β1X + ε其中,Y表示因变量,X表示自变量,β0和β1为未知参数,ε表示误差项。
参数估计在实际应用中,我们需要通过数据来估计模型中的参数。
最常用的估计方法是最小二乘法(OLS)。
最小二乘法的目标是通过最小化观测值与拟合值之间的平方差来估计参数。
具体而言,我们需要求解以下两个方程来得到参数的估计值:∂(Y - β0 - β1X)^2 / ∂β0 = 0∂(Y - β0 - β1X)^2 / ∂β1 = 0解释变量与被解释变量在简单线性回归模型中,解释变量(X)用来解释或预测被解释变量(Y)。
例如,我们可以使用房屋的面积(X)来预测房屋的价格(Y)。
在实验中,我们可以根据收集到的数据来建立回归模型,并利用该模型进行预测和分析。
应用实例数据收集为了说明简单线性回归模型的应用,我们假设收集了一些关于学生学习时间与考试成绩的数据。
下面是收集到的数据:学习时间(小时)考试成绩(百分制)2 723 784 805 856 88模型建立根据收集到的数据,我们可以建立简单线性回归模型来分析学生学习时间与考试成绩之间的关系。
首先,我们需要确定自变量和因变量的符号。
在这个例子中,我们可以将学习时间作为自变量(X),考试成绩作为因变量(Y)。
然后,我们使用最小二乘法来估计模型中的参数。
通过计算,可以得到如下参数估计值:β0 = 69.85β1 = 2.95最终的回归方程为:Y = 69.85 + 2.95X预测与分析通过建立的回归模型,我们可以进行预测和分析。
常用计量经济模型引言计量经济学是经济学中的一个重要分支,研究经济现象的数理模型和定量分析方法。
在实际经济研究中,常用计量经济模型能够帮助经济学家和研究者更好地理解和解释经济现象。
本文将介绍一些常用的计量经济模型,并对其原理及应用进行解析。
一、线性回归模型线性回归模型是计量经济学中最基本、最常用的模型之一。
其基本形式为:\[ y = \beta_0 + \beta_1x_1 + \beta_2x_2 + … + \beta_kx_k +\varepsilon \]其中,y表示被解释变量,x1,x2,...,x k表示解释变量,$\\varepsilon$表示误差项。
线性回归模型假设被解释变量和解释变量之间存在线性关系,并通过最小二乘法来估计模型参数。
线性回归模型的应用非常广泛,例如在市场营销中,可以使用线性回归模型来分析广告投放对销售额的影响;在金融学中,线性回归模型可以用于股票价格预测等。
二、时间序列模型时间序列模型用于分析时间序列数据,这种数据通常表示某个指标随时间的变化情况。
常见的时间序列模型包括AR(自回归模型)、MA(移动平均模型)、ARMA(自回归移动平均模型)和ARIMA(差分自回归移动平均模型)等。
时间序列模型的应用非常广泛,例如经济学中的季节性调整和趋势预测、气象学中的天气预测等。
三、面板数据模型面板数据模型,也被称为固定效应模型或混合效应模型,主要用于分析具有面板数据结构的经济问题。
面板数据包括横截面数据和时间序列数据,通过对面板数据进行分析可以得到更加准确和丰富的经济结论。
面板数据模型的应用非常广泛,例如在国际贸易中,可以利用面板数据模型来研究贸易对GDP的影响;在劳动经济学中,可以使用面板数据模型来研究教育对收入的影响。
四、计量经济模型的评价指标在使用计量经济模型进行分析时,我们需要对模型的拟合程度和统计显著性进行评价。
常见的评价指标包括确定系数(R^2)、均方根误差(RMSE)和F统计量等。