模式识别中的模式判别
- 格式:pptx
- 大小:1.00 MB
- 文档页数:66

![[数学]模式识别方法总结](https://uimg.taocdn.com/9bfe35a6a0116c175f0e484a.webp)

魏尔斯特拉斯判别法
拉斯判别法(Fisher discrimination),又称魏尔斯-拉普拉斯判别式,是概率论中的一种模式识别算法。
这种方法源于一九三五年爱因斯坦颁奖典礼上提出的魏尔斯定理,由Ronald A. Fisher利用贝叶斯定理建立而成。
该方法的基本思想是对类的期望总密度进行估计,在此基础上构造出把类别隔离开来的线性判别式,用来识别新样本。
它以类内样本的类内散度矩阵(within-class scatter matrix)和类间散度矩阵(between-class scatter matrix)为依据,构建决策边界,此处的决策边界满足最优类内距离和最大类间距离的性质。
拉斯判别法属于线性判别(linear discrimination)的一种,它的特点是用一个线性判别式来区分类型,具有计算简单、实现方便等特点,因而被人们广泛使用,拉斯判别法也称为线性判别分析(linear discriminant analysis, LDA)。



模式识别感知器算法求判别函数
y = sign(w · x + b)
其中,y表示分类结果(1代表一个类别,-1代表另一个类别),x 表示输入特征向量,w表示权重向量,b表示偏置项,sign表示取符号函数。
判别函数的求解过程主要包括以下几个步骤:
1.初始化权重向量和偏置项。
一般可以将它们设置为0向量或者随机向量。
2.遍历训练集中的所有样本。
对于每个样本,计算判别函数的值。
4.如果分类错误,需要调整权重和偏置项。
具体做法是使用梯度下降法,通过最小化误分类样本到超平面的距离来更新权重和偏置项。
对于权重向量的更新,可以使用如下公式:
w(t+1)=w(t)+η*y*x
对于偏置项的更新,可以使用如下公式:
b(t+1)=b(t)+η*y
5.重复步骤2和步骤4,直到所有样本都分类正确或达到停止条件。
需要注意的是,如果训练集中的样本不是线性可分的,则判别函数可能无法达到100%的分类准确率。
此时,可以通过增加特征维度、使用非线性变换等方法来提高分类效果。
总结起来,模式识别感知器算法通过判别函数将输入数据分类为两个类别。
判别函数的求解过程是通过调整权重向量和偏置项,使用梯度下降法最小化误分类样本到超平面的距离。
这个过程是一个迭代的过程,直到所有样本都分类正确或达到停止条件。

模式识别上lda的原理
LDA(Linear Discriminant Analysis,线性判别分析)是一种经典的模式识别技术,用于降维、分类和数据可视化等任务。
其基本原理基于最大化类间差异和最小化类内差异,以找到能够有效区分不同类别的特征。
LDA 的主要目标是找到一个投影方向,使得投影后的数据在该方向上具有最大的可分性。
具体来说,LDA 假设数据来自两个或多个类别,并且每个类别可以通过一个高斯分布来描述。
通过找到一个投影方向,使得不同类别之间的投影距离尽可能大,同时同一类别内的投影距离尽可能小。
LDA 的原理可以通过以下步骤来解释:
1. 数据预处理:将数据进行标准化或中心化处理,使得每个特征具有零均值和单位方差。
2. 计算类内散度矩阵:通过计算每个类别的样本在原始特征空间中的协方差矩阵,得到类内散度矩阵。
3. 计算类间散度矩阵:通过计算所有类别样本的总体协方差矩阵,得到类间散度矩阵。
4. 计算投影方向:通过求解类间散度矩阵的特征值和特征向量,找到能够最大化类间差异的投影方向。
5. 投影数据:将原始数据在找到的投影方向上进行投影,得到降维后的特征。
6. 分类或可视化:可以使用投影后的特征进行分类任务或数据可视化。
LDA 的原理基于统计学习和降维的思想,通过最大化类间差异和最小化类内差异来找到最具判别力的投影方向。
它在模式识别和数据分析中具有广泛的应用,如人脸识别、语音识别和文本分类等领域。

在模式识别中,样本、模式和模式类是三个核心概念,它们之间的关系如下:
1. 样本(Sample):
样本是指从实际世界中抽取的一个具体观测或实例。
它可以是一个图像、一段声音、一段文本、一个数据记录等。
每个样本都包含了描述其特性的数据,这些特性被称为特征。
2. 模式(Pattern):
模式是对一类样本的抽象概括,它代表了一组具有相似特性和属性的样本。
模式通常是由样本的多个特征共同定义的,这些特征可以是定量的(如像素强度、频率成分等)或定性的(如颜色、形状等)。
3. 模式类(Pattern Class):
模式类是一组具有相同或相似性质的模式的集合。
在模式识别中,目标是根据样本的特征将其正确地分类到相应的模式类中。
每个模式类代表了某种有意义的概念或类别,如不同的物体类别(如猫、狗)、语音命令(如“开灯”、“关窗”)或者文本的主题类别(如新闻、体育报道)。
因此,样本、模式和模式类之间的关系可以理解为:每个样本都是某个模式的一个具体表现形式,而模式则是同一类样本共性的抽象描述。
模式识别的过程就是通过分析样本的特征,将其与已知的模式进行比较,并确定该样本最可能属于哪个模式类的过程。

统计模式识别的原理与⽅法1统计模式识别的原理与⽅法简介 1.1 模式识别 什么是模式和模式识别?⼴义地说,存在于时间和空间中可观察的事物,如果可以区别它们是否相同或相似,都可以称之为模式;狭义地说,模式是通过对具体的个别事物进⾏观测所得到的具有时间和空间分布的信息;把模式所属的类别或同⼀类中模式的总体称为模式类(或简称为类)]。
⽽“模式识别”则是在某些⼀定量度或观测基础上把待识模式划分到各⾃的模式类中去。
模式识别的研究主要集中在两⽅⾯,即研究⽣物体(包括⼈)是如何感知对象的,以及在给定的任务下,如何⽤计算机实现模式识别的理论和⽅法。
前者是⽣理学家、⼼理学家、⽣物学家、神经⽣理学家的研究内容,属于认知科学的范畴;后者通过数学家、信息学专家和计算机科学⼯作者近⼏⼗年来的努⼒,已经取得了系统的研究成果。
⼀个计算机模式识别系统基本上是由三个相互关联⽽⼜有明显区别的过程组成的,即数据⽣成、模式分析和模式分类。
数据⽣成是将输⼊模式的原始信息转换为向量,成为计算机易于处理的形式。
模式分析是对数据进⾏加⼯,包括特征选择、特征提取、数据维数压缩和决定可能存在的类别等。
模式分类则是利⽤模式分析所获得的信息,对计算机进⾏训练,从⽽制定判别标准,以期对待识模式进⾏分类。
有两种基本的模式识别⽅法,即统计模式识别⽅法和结构(句法)模式识别⽅法。
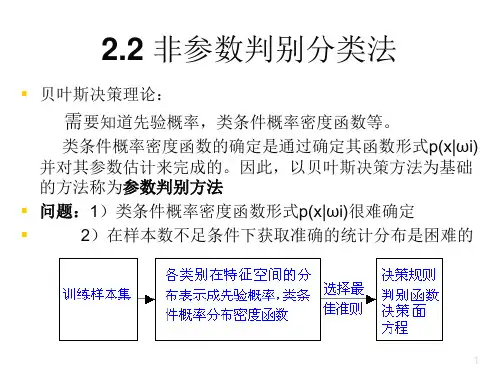
统计模式识别是对模式的统计分类⽅法,即结合统计概率论的贝叶斯决策系统进⾏模式识别的技术,⼜称为决策理论识别⽅法。
利⽤模式与⼦模式分层结构的树状信息所完成的模式识别⼯作,就是结构模式识别或句法模式识别。
模式识别已经在天⽓预报、卫星航空图⽚解释、⼯业产品检测、字符识别、语⾳识别、指纹识别、医学图像分析等许多⽅⾯得到了成功的应⽤。
所有这些应⽤都是和问题的性质密不可分的,⾄今还没有发展成统⼀的有效的可应⽤于所有的模式识别的理论。
1.2 统计模式识别 统计模式识别的基本原理是:有相似性的样本在模式空间中互相接近,并形成“集团”,即“物以类聚”。

论文(设计)《模式识别》题目Fisher线性判别的基本原理及应用Fisher判别准则一、基本原理思想Fisher线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远。
Fisher线性判别分析,就是通过给定的训练数据,确定投影方向W和阈值y0,即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
二、算法的实现及流程图1 算法实现 (1)W 的确定x 1m x, 1,2ii X ii N ∈==∑各类样本均值向量mi样本类内离散度矩阵和总类内离散度矩阵Tx S (x m )(x m ), 1,2ii i i X i ∈=--=∑样本类间离散度矩阵T1212S (m m )(m m )b =--在投影后的一维空间中,各类样本均值。
样本类内离散度和总类内离散度。
样本类间离散度。
Fisher 准则函数满足两个性质:·投影后,各类样本内部尽可能密集,即总类内离散度越小越好。
·投影后,各类样本尽可能离得远,即样本类间离散度越大越好。
根据这个性质确定准则函数,根据使准则函数取得最大值,可求出W :。
(2)阈值的确定采取的方法:【1】【2】【3】(3)Fisher 线性判别的决策规则对于某一个未知类别的样本向量x ,如果y=W T·x>y0,则x ∈w1;否则x ∈w2。
2 流程图归一化处理载入训练数据三、实验仿真1.实验要求试验中采用如下的数据样本集:ω1类: (22,5),(46,33),(25,30),(25,8),(31, 3),(37,9),(46,7),(49,5),(51,6),(53,3)(19,15),(23,18),(43,1),(22,15),(20,19),(37,36),(22,22),(21,32),(26,36),(23,39)(29,35),(33,32),(25,38),(41,35),(33,2),(48,37)ω2类: (40,25),(63,33),(43,27),(52,25),(55,27),(59,22) ,(65,59),(63,27)(65,30),(66,38),(67,43),(52,52),(61,49) (46,23),(60,50),(68,55) (40,53),(60,55),(55,55) (48,56),(45,57),(38,57) ,(68,24)在实验中采用Fisher线性判别方法设计出每段线性判别函数。
线性判别分析在模式识别中的应用线性判别分析(Linear Discriminant Analysis,简称LDA)是一种常用的模式识别算法,在许多领域中都有广泛的应用。
本文将探讨LDA在模式识别中的应用,并对其原理进行详细解析。
一、线性判别分析简介线性判别分析是一种监督学习的分类算法,其基本思想是将原始空间中的样本投影到低维子空间,从而使得不同类别的样本在投影后的子空间中能够更好地分离。
其目标是使得同类样本的投影点尽可能接近,不同类样本的投影点尽可能远离。
通过计算投影矩阵,将数据从高维空间映射到低维空间,从而实现维度的降低和分类的目的。
二、线性判别分析的原理1. 类内离散度和类间离散度的定义为了对数据进行降维和分类,我们需要定义类内离散度和类间离散度两个指标。
类内离散度(within-class scatter matrix)用于衡量同类样本在投影子空间中的分散程度,可以通过计算各类样本的协方差矩阵之和得到。
类间离散度(between-class scatter matrix)用于衡量不同类样本在投影子空间中的分散程度,可以通过计算各类样本均值的差异得到。
2. 目标函数的定义线性判别分析的目标是最大化类间离散度,同时最小化类内离散度。
为了实现这一目标,我们可以定义一个目标函数,即广义瑞利商(generalized Rayleigh quotient)。
广义瑞利商的定义如下:J(w) = (w^T * S_B * w) / (w^T * S_W * w)其中,w为投影向量,S_B为类间离散度的协方差矩阵,S_W为类内离散度的协方差矩阵。
3. 目标函数的求解通过求解广义瑞利商的极值问题,我们可以得到最优的投影方向。
对目标函数进行求导,并令导数为0,我们可以得到广义特征值问题。
S_W^(-1) * S_B * w = λ * w其中,λ为广义特征值,w为对应的广义特征向量。
通过求解该特征值问题,我们可以得到最优的投影方向,从而实现数据的降维和分类。
模式识别模式识别(Pattern Recognition)是指对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程,是信息科学和人工智能的重要组成部分。
模式识别又常称作模式分类,从处理问题的性质和解决问题的方法等角度,模式识别分为有监督的分类(Supervised Classification)和无监督的分类(Unsupervised Classification)两种定义1:借助计算机,就人类对外部世界某一特定环境中的客体、过程和现象的识别功能(包括视觉、听觉、触觉、判断等)进行自动模拟的科学技术。
所属学科:测绘学(一级学科);摄影测量与遥感学(二级学科)定义2:一类与计算机技术结合使用数据分类及空间结构识别方法的统称。
所属学科:地理学(一级学科);数量地理学(二级学科)定义3:昆虫将目标作为一幅完整图像来记忆和识别。
所属学科:昆虫学(一级学科);昆虫生理与生化(二级学科)定义4:主要指膜式识别受体对病原体相关分子模式的识别。
所属学科:免疫学(一级学科);概论(二级学科);免疫学相关名词(三级学科)模式识别研究内容:模式还可分成抽象的和具体的两种形式。
前者如意识、思想、议论等,属于概念识别研究的范畴,是人工智能的另一研究分支。
我们所指的模式识别主要是对语音波形、地震波、心电图、脑电图、图片、照片、文字、符号、生物传感器等对象的具体模式进行辨识和分类。
模式识别研究主要集中在两方面,一是研究生物体(包括人)是如何感知对象的,属于认识科学的范畴,二是在给定的任务下,如何用计算机实现模式识别的理论和方法。
前者是生理学家、心理学家、生物学家和神经生理学家的研究内容,后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力,已经取得了系统的研究成果。
应用计算机对一组事件或过程进行辨识和分类,所识别的事件或过程可以是文字、声音、图像等具体对象,也可以是状态、程度等抽象对象。
常见的模式识别方法一、引言在现代科技的推动下,模式识别技术已经广泛应用于各个领域,如图像识别、语音识别、文本分类等。
模式识别是指通过对已知模式的学习和分类,来识别新的、未知模式的技术。
在这篇文章中,我们将介绍一些常见的模式识别方法,并对其原理和应用进行简要概述。
二、特征提取特征提取是模式识别的关键步骤之一,其目的是从原始数据中提取出能够代表模式的特征。
常用的特征提取方法包括主成分分析(PCA)、线性判别分析(LDA)和局部二值模式(LBP)等。
PCA 通过线性变换将高维数据映射到低维空间,以保留原始数据中的主要信息。
LDA则是通过最大化类间散布矩阵和最小化类内散布矩阵的方式,进行特征投影,以达到最佳分类效果。
LBP是一种用于纹理分析的特征描述子,通过计算像素点与其周围像素点之间的灰度差异,来描述图像的纹理信息。
三、分类方法在特征提取之后,接下来需要将提取到的特征用于分类。
常见的分类方法有K最近邻算法(KNN)、支持向量机(SVM)和决策树等。
KNN算法是一种基于实例的学习方法,通过计算待分类样本与训练样本之间的距离,来确定其所属类别。
SVM是一种基于统计学习理论的分类方法,通过在特征空间中找到一个最优的超平面,来将不同类别的样本分开。
决策树是一种基于递归分割的分类方法,通过对特征空间进行划分,以达到最佳的分类效果。
四、聚类方法聚类是一种无监督学习方法,其目的是将数据集划分为若干个组,使得组内的样本相似度高,组间的样本相似度低。
常见的聚类方法有K均值聚类、层次聚类和密度聚类等。
K均值聚类将数据集划分为K个簇,通过计算样本与簇中心之间的距离,将样本分配到距离最近的簇中。
层次聚类是一种自底向上的聚类方法,通过计算样本之间的相似度,不断合并最相似的样本或簇,最终形成一个完整的聚类树。
密度聚类是一种基于密度的聚类方法,通过计算样本周围的密度,来确定样本所属的簇。
五、神经网络神经网络是一种模仿人脑神经元网络结构的计算模型,其应用于模式识别可以取得很好的效果。