Fisher判别函数
- 格式:doc
- 大小:70.50 KB
- 文档页数:2

Fisher判别分析原理详解说起Fisher判别分析,不得不提到一个大神级人物!Ronald Aylmer Fisher (1890~1962)英国统计学家和遗传学家主要著作有:《根据孟德尔遗传方式的亲属间的相关》、《研究者用的统计方法》、《自然选择的遗传理论》、《试验设计》、《近交的理论》及《统计方法和科学推理》等。
他一生在统计生物学中的功绩是十分突出的。
•生平1890年2月17日生于伦敦,1962年7月29日卒于澳大利亚阿德莱德。
1912年毕业于剑桥大学数学系,后随英国数理统计学家J.琼斯进修了一年统计力学。
他担任过中学数学教师,1918年任罗坦斯泰德农业试验站统计试验室主任。
1933年,因为在生物统计和遗传学研究方面成绩卓著而被聘为伦敦大学优生学教授。
1943年任剑桥大学遗传学教授。
1957年退休。
1959年去澳大利亚,在联邦科学和工业研究组织的数学统计部作研究工作。
大神解决的问题•Fisher 线性判别函数的提出:在用统计方法进行模式识别时,许多问题涉及到维数,在低维空间可行的方法,在高维空间变得不可行。
因此,降低维数就成为解决实际问题的关键。
Fisher 的方法,就是解决维数压缩问题。
对xn的分量做线性组合可得标量yn=wTxn,n=1,2,…,Ni得到N个一维样本yn组成的集合。
从而将多维转换到了一维。
考虑把d维空间中的数据点投影到一条直线上去的问题,需要解决的两个问题:(1)怎样找到最好的投影直线方向;(2)怎样向这个方向实现投影,这个投影变换就是要寻求的解向量w*。
这两个问题就是Fisher方法要解决的基本问题。
•判别分析的一些基本公式Fisher判别分析用于两类或两类以上间的判别,但常用于两类间判别。
Fisher判别函数表达式(多元线性函数式):判别函数的系数是按照组内差异最小和组间差异最大同时兼顾的原则来确定判别函数的。
Fisher判别准则:判别临界点:Fisher判别分析思想:1. 类间差异大,类内变异小,最大2. 方差分析的思想:以下值最大•Fisher判别的原理分析w1方向之所以比w2方向优越,可以归纳出这样一个准则,即向量w的方向选择应能使两类样本投影的均值之差尽可能大些,而使类内样本的离散程度尽可能小。




Fisher 线性判别式前面讲过的感知器准则、最小平方和准则属于用神经网络的方法解决分类问题。
下面介绍一种新的判决函数分类方法。
由于线性判别函数易于分析,关于这方面的研究工作特别多。
历史上,这一工作是从R.A.Fisher 的经典论文(1936年)开始的。
我们知道,在用统计方法进行模式识别时,许多问题涉及到维数,在低维空间行得通的方法,在高维空间往往行不通。
因此,降低维数就成为解决实际问题的关键。
Fisher 的方法,实际上涉及维数压缩。
如果要把模式样本在高(d )维的特征向量空间里投影到一条直线上,实际上就是把特征空间压缩到一维,这在数学上容易办到。
另外,即使样本在高维空间里聚集成容易分开的群类,把它们投影到一条任意的直线上,也可能把不同的样本混杂在一起而变得无法区分。
也就是说,直线的方向选择很重要。
在一般情况下,总可以找到某个最好的方向,使样本投影到这个方向的直线上是最容易分得开的。
如何找到最好的直线方向,如何实现向最好方向投影的变换,是Fisher 法要解决的基本问题。
这个投影变换就是我们寻求的解向量*w 。
1.线性投影与Fisher 准则函数在21/w w 两类问题中,假定有n 个训练样本),....,2,1(n k x k =其中1n 个样本来自i w 类型,2n 个样本来自j w 类型,21n n n +=。
两个类型的训练样本分别构成训练样本的子集1X 和2X 。
令:k Tk x w y =,n k ,...,2,1= (4.5-1)k y 是向量k x 通过变换w 得到的标量,它是一维的。
实际上,对于给定的w ,k y 就是判决函数的值。
由子集1X 和2X 的样本映射后的两个子集为1Y 和2Y 。
因为我们关心的是w 的方向,可以令1||||=w ,那么k y 就是k x 在w 方向上的投影。
使1Y 和2Y 最容易区分开的w 方向正是区分超平面的法线方向。
如下图:图中画出了直线的两种选择,图(a)中,1Y 和2Y 还无法分开,而图(b)的选择可以使1Y 和2Y 区分开来。

典则判别函数和fisher判别函数
典则判别函数和Fisher判别函数是模式分类中常用的两种算法。
它们都是通过选择合适的决策边界来对数据进行分类。
但是它们的实
现方式和应用场景有所不同。
典则判别函数是一种基于贝叶斯分类规则的判别函数。
它将数据
集分为多个类别,并计算每个类别的先验概率。
在观察到新的数据时,典则判别函数将计算各类别的后验概率并选择概率最大的类别作为分
类结果。
这种算法相对简单,但需要事先知道每个类别的先验概率。
Fisher判别函数则是一种基于判别分析的算法,它用于确定分类数据的最佳线性投影。
这个投影可以最大化类别之间的差异性,同时
最小化类别内部的差异性。
因此,Fisher判别函数在处理大量特征或
类别未知时效果更好。
它可以用于二分类和多分类问题,并且可以通
过聚类算法来确定类别数量。
总体而言,典则判别函数是一种简单而直接的方法,而Fisher
判别函数则更适合于处理高维数据和未知类别的情况。
但无论是哪种
算法,在实际应用中都需要根据具体的问题选择合适的算法,并根据
数据集进行调整。

判别分析公式Fisher线性判别二次判别判别分析是一种常用的数据分析方法,用于根据已知的类别信息,将样本数据划分到不同的类别中。
Fisher线性判别和二次判别是两种常见的判别分析方法,在实际应用中具有广泛的应用价值。
一、Fisher线性判别Fisher线性判别是一种基于线性变换的判别分析方法,该方法通过寻找一个合适的投影方向,将样本数据投影到一条直线上,在保持类别间离散度最大和类别内离散度最小的原则下实现判别。
其判别函数的计算公式如下:Fisher(x) = W^T * x其中,Fisher(x)表示Fisher判别函数,W表示投影方向的权重向量,x表示样本数据。
具体来说,Fisher线性判别的步骤如下:1. 计算类别内离散度矩阵Sw和类别间离散度矩阵Sb;2. 计算Fisher准则函数J(W),即J(W) = W^T * Sb * W / (W^T * Sw * W);3. 求解Fisher准则函数的最大值对应的投影方向W;4. 将样本数据投影到求得的最优投影方向上。
二、二次判别二次判别是基于高斯分布的判别分析方法,将样本数据当作高斯分布的观测值,通过估计每个类别的均值向量和协方差矩阵,计算样本数据属于每个类别的概率,并根据概率大小进行判别。
二次判别的判别函数的计算公式如下:Quadratic(x) = log(P(Ck)) - 0.5 * (x - μk)^T * Σk^-1 * (x - μk)其中,Quadratic(x)表示二次判别函数,P(Ck)表示类别Ck的先验概率,x表示样本数据,μk表示类别Ck的均值向量,Σk表示类别Ck的协方差矩阵。
具体来说,二次判别的步骤如下:1. 估计每个类别的均值向量μk和协方差矩阵Σk;2. 计算每个类别的先验概率P(Ck);3. 计算判别函数Quadratic(x);4. 将样本数据划分到概率最大的类别中。
判别分析公式Fisher线性判别和二次判别是常见的判别分析方法,它们通过对样本数据的投影或概率计算,实现对样本数据的判别。
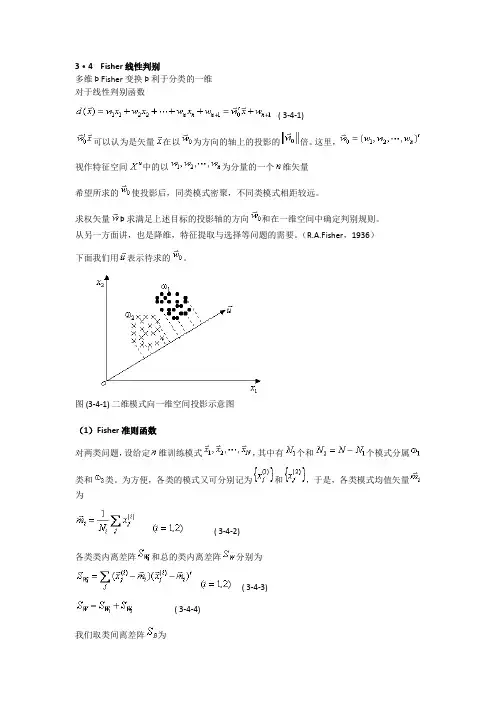
3·4 Fisher线性判别多维 Þ Fisher变换 Þ 利于分类的一维对于线性判别函数( 3-4-1)可以认为是矢量在以为方向的轴上的投影的倍。
这里,视作特征空间中的以为分量的一个维矢量希望所求的使投影后,同类模式密聚,不同类模式相距较远。
求权矢量Þ 求满足上述目标的投影轴的方向和在一维空间中确定判别规则。
从另一方面讲,也是降维,特征提取与选择等问题的需要。
(R.A.Fisher,1936)下面我们用表示待求的。
图 (3-4-1) 二维模式向一维空间投影示意图(1)Fisher准则函数对两类问题,设给定维训练模式,其中有个和个模式分属类和类。
为方便,各类的模式又可分别记为和,于是,各类模式均值矢量为( 3-4-2)各类类内离差阵和总的类内离差阵分别为( 3-4-3)( 3-4-4)我们取类间离差阵为( 3-4-5)作变换,维矢量在以矢量为方向的轴上进行投影( 3-4-6)变换后在一维空间中各类模式的均值为( 3-4-7)类内离差度和总的类内离差度为( 3-4-8)( 3-4-9)类间离差度为( 3-4-10)我们希望经投影后,类内离差度越小越好,类间离差度越大越好,根据这个目标作准则函数( 3-4-11)称之为Fisher准则函数。
我们的目标是,求使最大。
(2)Fisher变换将标量对矢量微分并令其为零矢量,注意到的分子、分母均为标量,利用二次型关于矢量微分的公式可得( 3-4-12)令可得当时,通常是非奇异的,于是有( 3-4-13)上式表明是矩阵相应于本征值的本征矢量。
对于两类问题,的秩为1,因此只有一个非零本征值,它所对应的本征矢量称为Fisher最佳鉴别矢量。
由式( 3-4-13)有( 3-4-14)上式右边后两项因子的乘积为一标量,令其为,于是可得式中为一标量因子。
这个标量因子不改变轴的方向,可以取为1,于是有( 3-4-15)此时的是使Fisher准则函数取最大值时的解,即是维空间到一维空间投影轴的最佳方向,( 3-4-16)称为Fisher变换函数。

关于fisher判别的⼀点理解最近⼀个朋友问这⽅⾯的⼀些问题,其实之前也就很粗略的看了下fisher,真正帮别⼈解答问题的时候才知道原来⾃⼰也有很多东西不懂。
下⾯⼩结下⾃⼰对fisher判别的理解:其实fisher和PCA差不多,熟悉PCA的⼈都知道,PCA其实就是在寻找⼀个⼦空间。
这个空间怎么来的呢,先求协⽅差矩阵,然后求这个协⽅差矩阵的特征空间(特征向量对应的空间),选取最⼤的特征值对应的特征向量组成特征⼦空间(⽐如说k个,相当于这个⼦空间有k 维,每⼀维代表⼀个特征,这k个特征基本上可以涵盖90%以上的信息)。
那么我们把样本投影在这个⼦空间,原来那么多维的信息就可以⽤这k维的信息代替了,也就是说降维了。
⾄于PCA为啥要⽤求协⽅差矩阵然后求特征⼦空间的⽅法,这个数学上有证明,记得在某篇⽂章上看过,有兴趣的可以找找,看看证明。
那么fisher空间⼜是怎么⼀回事呢,其实fisher判别和PCA是在做类似的⼀件事,都是在找⼦空间。
不同的是,PCA是找⼀个低维的⼦空间,样本投影在这个空间基本不丢失信息。
⽽fisher是寻找这样的⼀个空间,样本投影在这个空间上,类内距离最⼩,类间距离最⼤。
那么怎么求这个空间呢,类似于PCA,求最⼤特征值对应的特征向量组成的空间。
当我们取最⼤⼏个特征值对应的特征向量组成特征空间时(这⾥指出,最佳投影轴的个数d<=c-1,这⾥c是类别数),最佳投影矩阵如下:其实在⽂章Eigenfaces vs Fisherfaces :recognition using class specific linear projection中给出了PCA和LDA⽐较直观的解释,⽂中对⼀个⼆维的数据进⾏分析,PCA和LDA都是把⼆维数据降到⼀个⼀维空间,那么其实PCA使得数据投影在这个⼀维空间总的离散度最⼤,我的理解是这样的,如果数据在某⼀维上⽐较离散,说明这维特征对数据的影响⽐较⼤,也就是说这维特征是主成分。

基于Fisher判别分析的分类模型研究作者:代雪珍卫军超常在斌来源:《价值工程》2018年第26期摘要:Fisher判别分析是数据处理的常用技术。
Fisher线性判别模型是找到一条合适的直线,使得数据点在投影到直线后可以被分离。
本文通过对Fisher判别分析和高斯核函数的分类的研究,通过实际例子,在matlab中编程实现算法,分别画图比较了二维数据和三维数据的分类结果。
Abstract: Fisher discriminant analysis is a commonly used technique for data processing. The Fisher linear discriminant model is to find a suitable straight line so that the data points can be separated after being projected onto a straight line. In this paper, the classification of Fisher discriminant analysis and Gaussian kernel function is studied. Through practical examples, the algorithm is implemented in matlab, and the two-dimensional data and three-dimensional data are compared separately.关键词: Fisher准则;数据分类;matlab编程;高斯核函数Key words: Fisher criterion;data classification;matlab programming;Gaussian kernel function中图分类号:TP313 文献标识码:A 文章编号:1006-4311(2018)26-0211-030 引言分类是机器学习,统计学和模式识别领域的一个重要课题。

Fisher判别函数,也称为线性判别函数(Linear Discriminant Function),是一种经典的模式识别方法。
它通过将样本投影到一维或低维空间,将不同类别的样本尽可能地区分开来。
一、算法原理:Fisher判别函数基于以下两个假设:1.假设每个类别的样本都服从高斯分布;2.假设不同类别的样本具有相同的协方差矩阵。
Fisher判别函数的目标是找到一个投影方向,使得同一类别的样本在该方向上的投影尽可能紧密,而不同类别的样本在该方向上的投影尽可能分开。
算法步骤如下:(1)计算类内散度矩阵(Within-class Scatter Matrix)Sw,表示每个类别内样本之间的差异。
Sw = Σi=1 to N (Xi - Mi)(Xi - Mi)ᵀ,其中Xi 表示属于类别i 的样本集合,Mi 表示类别i 的样本均值。
(2)计算类间散度矩阵(Between-class Scatter Matrix)Sb,表示不同类别之间样本之间的差异。
Sb = Σi=1 to C Ni(Mi - M)(Mi - M)ᵀ,其中 C 表示类别总数,Ni 表示类别i 中的样本数量,M 表示所有样本的均值。
(3)计算总散度矩阵(Total Scatter Matrix)St,表示所有样本之间的差异。
St =Σi=1 to N (Xi - M)(Xi - M)ᵀ(4)计算投影方向向量w,使得投影后的样本能够最大程度地分开不同类别。
w= arg max(w) (wᵀSb w) / (wᵀSw w),其中w 表示投影方向向量。
(5)根据选择的投影方向向量w,对样本进行投影。
y = wᵀx,其中y 表示投影后的样本,x 表示原始样本。
(6)通过设置一个阈值或使用其他分类算法(如感知机、支持向量机等),将投影后的样本进行分类。
二、优点和局限性:Fisher判别函数具有以下优点:•考虑了类别内和类别间的差异,能够在低维空间中有效地区分不同类别的样本。
fisher判别法Fisher判别分析的基本思想:选取适当的投影方向,将样本数据进行投影,使得投影后各样本点尽可能分离开来,即:使得投影后各样本类内离差平方和尽可能小,而使各样本类间的离差平方和尽可能大。
为了克服“维数灾难”,人们将高维数据投影到低维空间上来,并保持必要的特征,这样,一方面数据点变得比较密集一些,另一方面,可以在低维空间上进行研究。
fisher判别法是判别分析的方法之一,它是借助于方差分析的思想,利用已知各总体抽取的样品的p维观察值构造一个或多个线性判别函数y=l′x其中l= (l1,l2…lp)′,x= (x1,x2,…,xp)′,使不同总体之间的离差(记为B)尽可能地大,而同一总体内的离差(记为E)尽可能地小来确定判别系数l=(l1,l2…lp)′。
数学上证明判别系数l恰好是|B-λE|=0的特征根,记为λ1≥λ2≥…≥λr>0。
所对应的特征向量记为l1,l2,…lr,则可写出多个相应的线性判别函数,在有些问题中,仅用一个λ1对应的特征向量l1所构成线性判别函数y1=l′1x不能很好区分各个总体时,可取λ2对应的特征向量l′2建立第二个线性判别函数y2=l′2x,如还不够,依此类推。
有了判别函数,再人为规定一个分类原则(有加权法和不加权法等)就可对新样品x判别所属。
Fisher判别法是根据方差分析的思想建立起来的一种能较好区分各个总体的线性判别法,由Fisher在1936年提出。
该判别方法对总体的分布不做任何要求。
Fisher判别法是一种投影方法,把高维空间的点向低维空间投影。
在原来的坐标系下,可能很难把样品分开,而投影后可能区别明显。
一般说,可以先投影到一维空间(直线)上,如果效果不理想,在投影到另一条直线上(从而构成二维空间),依此类推。
每个投影可以建立一个判别函数。
论文(设计)《模式识别》题目Fisher线性判别的基本原理及应用Fisher判别准则一、基本原理思想Fisher线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远。
Fisher线性判别分析,就是通过给定的训练数据,确定投影方向W和阈值y0,即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
二、算法的实现及流程图1 算法实现 (1)W 的确定x 1m x, 1,2ii X ii N ∈==∑各类样本均值向量mi样本类内离散度矩阵和总类内离散度矩阵Tx S (x m )(x m ), 1,2ii i i X i ∈=--=∑样本类间离散度矩阵T1212S (m m )(m m )b =--在投影后的一维空间中,各类样本均值。
样本类内离散度和总类内离散度。
样本类间离散度。
Fisher 准则函数满足两个性质:·投影后,各类样本内部尽可能密集,即总类内离散度越小越好。
·投影后,各类样本尽可能离得远,即样本类间离散度越大越好。
根据这个性质确定准则函数,根据使准则函数取得最大值,可求出W :。
(2)阈值的确定采取的方法:【1】【2】【3】(3)Fisher 线性判别的决策规则对于某一个未知类别的样本向量x ,如果y=W T·x>y0,则x ∈w1;否则x ∈w2。
2 流程图归一化处理载入训练数据三、实验仿真1.实验要求试验中采用如下的数据样本集:ω1类: (22,5),(46,33),(25,30),(25,8),(31, 3),(37,9),(46,7),(49,5),(51,6),(53,3)(19,15),(23,18),(43,1),(22,15),(20,19),(37,36),(22,22),(21,32),(26,36),(23,39)(29,35),(33,32),(25,38),(41,35),(33,2),(48,37)ω2类: (40,25),(63,33),(43,27),(52,25),(55,27),(59,22) ,(65,59),(63,27)(65,30),(66,38),(67,43),(52,52),(61,49) (46,23),(60,50),(68,55) (40,53),(60,55),(55,55) (48,56),(45,57),(38,57) ,(68,24)在实验中采用Fisher线性判别方法设计出每段线性判别函数。
1 实验1 Fisher 线性判别实验一、实验目的应用统计方法解决模式识别问题的困难之一是维数问题,在低维空间行得通的方法,在高维空间往往行不通。
因此,降低维数就成为解决实际问题的关键。
Fisher 的方法,实际上涉及维数压缩。
如果要把模式样本在高维的特征向量空间里投影到一条直线上,实际上就是把特征空间压缩到一维,这在数学上容易办到。
问题的关键是投影之后原来线性可分的样本可能变得混杂在一起而无法区分。
在一般情况下,总可以找到某个最好的方向,使样本投影到这个方向的直线上是最容易分得开的。
如何找到最好的直线方向,如何实现向最好方向投影的变换,是Fisher 法要解决的基本问题。
这个投影变换就是我们寻求的解向量*w本实验通过编制程序体会Fisher 线性判别的基本思路,理解线性判别的基本思想,掌握Fisher 线性判别问题的实质。
二、实验原理1.线性投影与Fisher 准则函数各类在d 维特征空间里的样本均值向量:∑∈=i k X x k i i x n M 1,2,1=i (4.5-2)通过变换w 映射到一维特征空间后,各类的平均值为:∑∈=i k Y y k i i y n m 1,2,1=i (4.5-3)映射后,各类样本“类内离散度”定义为:22()k i i k i y Y S y m ∈=-∑,2,1=i (4.5-4)显然,我们希望在映射之后,两类的平均值之间的距离越大越好,而各类的样本类内离散度越小越好。
因此,定义Fisher 准则函数:2122212||()F m m J w s s -=+ (4.5-5) 使F J 最大的解*w 就是最佳解向量,也就是Fisher 的线性判别式。
2.求解*w从)(w J F 的表达式可知,它并非w 的显函数,必须进一步变换。
2 已知:∑∈=i k Y y k ii y n m 1,2,1=i , 依次代入(4.5-1)和(4.5-2),有: i T X x k i T k X x T i i M w x n w x w n m i k i k ===∑∑∈∈)1(1,2,1=i (4.5-6) 所以:221221221||)(||||||||M M w M w M w m m T T T -=-=- w S w w M M M M w b T T T =--=))((2121 (4.5-7) 其中:T b M M M M S ))((2121--= (4.5-8) b S 是原d 维特征空间里的样本类内离散度矩阵,表示两类均值向量之间的离散度大小,因此,b S 越大越容易区分。
Fisher 判别函数的使用具体步骤
Fisher 多类判别模型
假定事物由p 个变量描述, 即: x=(p x x x ,...,,21)T
该种事物有G 个类型, 从每个类型中顺次抽取p n n n ,...,,21个样品, 共计n=
∑=G
i i
1
n
个样品。
即从第g 类取了g n 个样品, g=1,2,⋯, G, 第g 类的第i 个样品, 用向量:
gi x =(pgi gi gi x x ,...,,x 21)T (1)
( 1) 式中, 第一个下标是变量号, 第二个下标是类型号,第三个下标是样品号。
设判别函数为:
T x p p v x v x v x v =+++=...y 2211 (2)
其中: V=(p v v v ,...,21)T
按照组内差异最小, 组间差异最大同时兼顾的原则, 来确定判别函数系数。
(中间推导过程不在这里介绍了)
最终就有个判别函数:,y x V T
j j
=1,...,2,1s j = 一般只取前M=min(G- 1,p)个, 即:
M j x v x v x v y p pj j j j ,...,2,1,...2211=+++= (3)
根据上述M 个判别函数, 可对每一个待判样品做出判别。
),...,,(x 020100p x x x=
其过程如下:
1、把x0 代入式(3) 中每一个判别函数, 得到M 个数
,,...,2,1,...y 202101j 0M j x v x v x v p pj j j =+++=
记:T
M y y y y ),...,,(020100= 2、把每一类的均值代入式(3)得
G
g y y y y G g M j x v x v x v y M g
g
g
g pg pg g g g g j g ,...,2,1),,...,,(,...2,1,,...,2,1,...212211====+++=
3、计算:∑=-=M
j j j g g
y y D 1
2
02
)(,从这G 个值中选出最小值:)(min 212g G
g h D D ≤≤=。
这样就把0
x 判为h 类。
根据上面的Fisher 多类判别模型的具体求解步骤:1、把聚类分析的所有归一化后的用户向量代入已得到的4个Fisher 判别函数中(因为本模型中的变量数和类型数都比较少,故将得到的判别函数都用于判别样品中),每一个用户都可以得到4个数
T i i i i i f f f f ),,,(F 4321=,其中),(4,3,21
j f =j
i 代表第i 个手机用户的用户向量代入到第j 个判别函数的函数值;2、把每一类的均值代入已得到的4个Fisher 判别函数中,
得到4,3,2,1,),,,(F 4321g ==g f f f f T g g g g ,其中),(4,3,21
j f g =j
代表第g 类均值用户向量代入到第j 个判别函数的函数值;3、计算每一个用户的∑=-=M
j j i j g g
f f
D 1
22)(,
分别从每个用户的四个值中选出最小值:)(min 2
4
12
g g h D D i ≤≤=。
这样就把每一个用户判为i h 类(i h 表示第i 个用户被判的类)。