求n阶矩阵的随机一致性指标
- 格式:pdf
- 大小:114.77 KB
- 文档页数:3



function [w,CR]=mycom(A,m,RI)[x,lumda]=eig(A);r=abs(sum(lumda));n=find(r==max(r));max_lumda_A=lumda(n,n);max_x_A=x(:,n);w=A/sum(A);CR=(max_lumda_A-m)/(m-1)/RI;end本matlab程序用于层次分析法中计算判断矩阵给出的权值已经进行一致性检验。
其中A为判断矩阵,不同的标度和评定A将不同。
m为A的维数RI为判断矩阵的平均随机一致性指标:根据m的不同值不同。
当CR<0.1时符合一致性检验,判断矩阵构造合理。
下面是层次分析法的简介,以及判断矩阵构造方法。
一.层次分析法的含义层次分析法(The analytic hierarchy process)简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂(T.L.Saaty)正式提出。
它是一种定性和定量相结合的、系统化、层次化的分析方法。
由于它在处理复杂的决策问题上的实用性和有效性,很快在世界范围得到重视。
它的应用已遍及经济计划和管理、能源政策和分配、行为科学、军事指挥、运输、农业、教育、人才、医疗和环境等领域。
二.层次分析法的基本思路与人对一个复杂的决策问题的思维、判断过程大体上是一样的。
(1)层次分析法的原理层次分析法是将决策问题按总目标、各层子目标、评价准则直至具体的备投方案的顺序分解为不同的层次结构,然后得用求解判断矩阵特征向量的办法,求得每一层次的各元素对上一层次某元素的优先权重,最后再加权和的方法递阶归并各备择方案对总目标的最终权重,此最终权重最大者即为最优方案。
这里所谓“优先权重”是一种相对的量度,它表明各备择方案在某一特点的评价准则或子目标,标下优越程度的相对量度,以及各子目标对上一层目标而言重要程度的相对量度。
层次分析法比较适合于具有分层交错评价指标的目标系统,而且目标值又难于定量描述的决策问题。

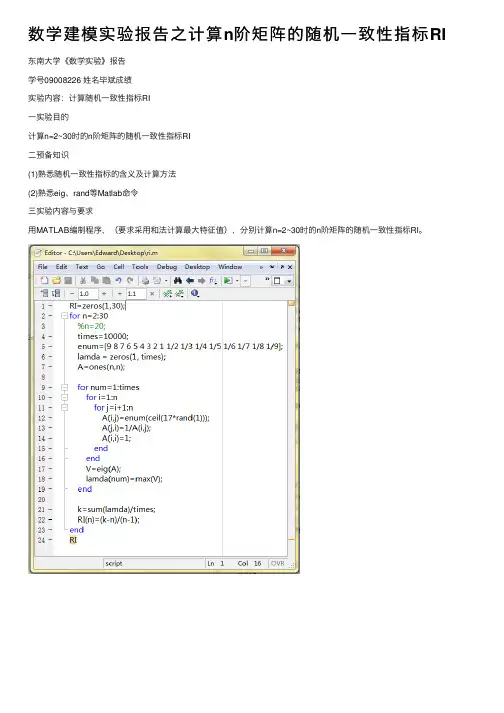
数学建模实验报告之计算n阶矩阵的随机⼀致性指标RI 东南⼤学《数学实验》报告学号09008226 姓名毕斌成绩实验内容:计算随机⼀致性指标RI⼀实验⽬的计算n=2~30时的n阶矩阵的随机⼀致性指标RI⼆预备知识(1)熟悉随机⼀致性指标的含义及计算⽅法(2)熟悉eig、rand等Matlab命令三实验内容与要求⽤MATLAB编制程序,(要求采⽤和法计算最⼤特征值),分别计算n=2~30时的n阶矩阵的随机⼀致性指标RI。
RI=zeros(1,30); %定义结果输出格式并初始化,RI(1)直接赋值为0 for n=2:30 %循环计算阶数2到30的随机正互反矩阵的RI %n=20; %起初以20阶矩阵为例测试times=10000; %10000个⼦样,应该够多了吧enum=[9 8 7 6 5 4 3 2 1 1/2 1/3 1/4 1/5 1/6 1/7 1/8 1/9]; %矩阵元素从enum中取得lamda = zeros(1, times); %最⼤特征值向量初始化A=ones(n,n); %初始化相应阶数的矩阵for num=1:times %循环for i=1:n %把矩阵A赋值为正互反矩阵for j=i+1:nA(i,j)=enum(ceil(17*rand(1))); %矩阵的上半部分从enum中随机取值A(j,i)=1/A(i,j); %矩阵的下半部分与上半部分成倒数A(i,i)=1; %矩阵对⾓线为1 endendV=eig(A); %求得A的特征向量lamda(num)=max(V); %以最⼤特征值给lamda向量赋值endk=sum(lamda)/times; %最⼤特征值的平均值RI(n)=(k-n)/(n-1); %得出对应的RI(n) endRI %最后输出RI向量,即1-30阶矩阵的平均随机⼀致性指标四实验⼼得由于⼀开始对matlab命令的不熟悉,⾛了很多弯路,后来反复查阅matlab Help⾥的信息,并⾃学matlab命令,终于摸索出了⼀些经验,⾃以为很完满的解决了问题。

---------------------------------------------------------------最新资料推荐------------------------------------------------------AHP模型和DEA模型综合评价模型之 AHP 模型和 DEA 模型一、 AHP 模型(层次分析模型) 1、基本概述层次分析是一种多层次权重解析方法。
AHP 是分析多目标、多准则的复杂大系统的有力工具 2、模型建立的基本步骤第一步:建立层次结构模型。
在深入分析面临的问题之后,当问题中所包含的因素划分为不同层次(如目标层、准则层、指标层、方案层、措施层等)时,用框图形式说明层次的梯阶结构与因素的从属关系。
当某个层次包括的因素较多时,可将该层次进一步划分为若干子层次。
第二步:构造判断矩阵。
判断矩阵元素的值反映了人们对各因素相对重要程度的认识,一般采用数字 1~9 及其倒数的标度方法。
当相互比较因素的重要性能够用具有实际意义的比值说明时,判断矩阵相应的值则可以取这个比值。
第三步:层次单排序及其一致性检验。
通过判断矩阵 A 的特征根的求解( W W Amax = )得到特征向量 W ,经过归一化后即为同一层次相应因素对于上一层次某因素相1 / 9对重要性的排序权值,这一过程称为层次单排序。
为进行层次单排序(或判断矩阵)的一致性检验,需要计算的一致性指标为 1max=nnCI, n 为判断矩阵的阶数。
对于 1~9 阶判断矩阵,平均随机一致性指标 RI 的值如表 1 所示:表 1 1-9 阶矩阵的平均随机一致性指标阶数 1 2 3 4 5 6 7 8 9 RI 0.00 0.00 0.58 0.90 1.12 1.24 1.32 1.41 1.45 当随机一致性比率 10 . 0 =RICICR 时,认为层次单排序的结果有满意的一致性,否则需要调整判断矩阵的元素取值。
AHP法的随机一致性(RC)指标在层次分析(AHP)法中,为了对判断矩阵的数值进行一致性检验,需要根据矩阵的阶次(n)计算判断一致率(consistency ratio, CR)。
为此,数学家引入了随机一致性(random consistency, RC)指标。
随机一致性指标又称随机指数(random index, RI)。
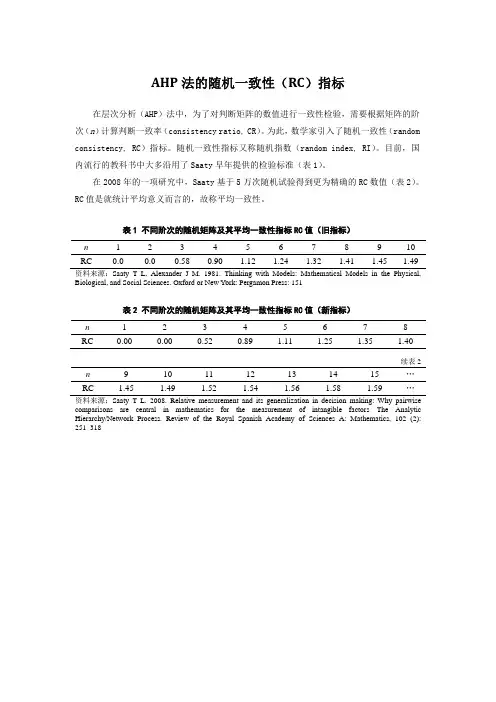
目前,国内流行的教科书中大多沿用了Saaty早年提供的检验标准(表1)。
在2008年的一项研究中,Saaty基于5万次随机试验得到更为精确的RC数值(表2)。
RC值是就统计平均意义而言的,故称平均一致性。
表1 不同阶次的随机矩阵及其平均一致性指标RC值(旧指标)n 1 2 3 4 5 6 7 8 9 10 RC 0.0 0.0 0.58 0.90 1.12 1.24 1.32 1.41 1.45 1.49资料来源:Saaty T L, Alexander J M. 1981. Thinking with Models: Mathematical Models in the Physical, Biological, and Social Sciences. Oxford or New York: Pergamon Press: 151表2 不同阶次的随机矩阵及其平均一致性指标RC值(新指标)n 1 2 3 4 5 6 7 8 RC 0.00 0.00 0.52 0.89 1.11 1.25 1.35 1.40续表2 n 9 10 11 12 13 14 15 …RC 1.45 1.49 1.52 1.54 1.56 1.58 1.59 …资料来源:Saaty T L. 2008. Relative measurement and its generalization in decision making: Why pairwise comparisons are central in mathematics for the measurement of intangible factors—The Analytic Hierarchy/Network Process. Review of the Royal Spanish Academy of Sciences A: Mathematics, 102 (2):251–318。

配电网可靠性评估及分析冯金帅 刘 杰(国网山东省电力公司临沂供电公司)摘 要:电力相关企业正在逐渐把建设重点放到建设配电网方面,而配电网规划对于电网安全、可靠、经济运行有着不可忽视的作用。
因此需要对配电网的可靠性开展深入研究和分析,作为评估程序的重要构成部分,建立一个相对完善并且可行性较高的评估指标系统,配电网规划成效分析则可以为其提供依据。
并且,它的真实性与数据有效性对配电系统评估也具有重大意义。
关键词:配电网;指标体系;评估分析;可靠性0 引言配电网络规划也就是在完善的规划下对于目标区域组织负荷预测和当前阶段网络架构的研究,在符合负荷标准和安全稳定性的基础上,对于目标区域电力网络在目前架构前提下进行合理布局规划,进而使其满足可靠性、稳定性、经济性要求。
完善的电网规划可以有效降低公司的运营成本,满足公司竞争需求,同样有助于减少财政基建投资压力,为保障经济发展提供坚实的基础保障[1]。
配电网的设计方案的成功与否和落实程度都会对日后配电服务网络体系的负荷程度、经济发展度发挥关键性影响,配电网络的超前或滞后建设都会在一定程度上对电网整体的发展产生负面影响[2]。
对于配电网络规划方案而言,首要评估其是否满足发展需求,是否满足可靠性要求,这对于配电网络的长远发展是十分关键的[3]。
1 配电网的规划可靠性分析(1)可靠性分析方法配电网络的主要功能是销售、分配电力能源给目标客户,和目标用户的日常生活工作有十分紧密的联系,电力网络的波动会对终端客户的经济利益产生重要影响。
因而精确的分析配电网络体系的稳定性对于保障民生质量、促进经济稳定健康发展有十分关键的作用,此外配电网络体系的稳定性评估是电网建设和持续发展的重要基础保障条件。
当前阶段,配电网络体系的稳定性评估重点使用的研究方法主要有蒙特卡洛抽样法和解析法两类[4-5]。
(2)配电网评价方法1)鱼骨图分析法也叫作因果研究法,这一研究法的主要原理是寻求问题自身的特征和相关作用要素,此后利用专项的逻辑研究来建立层级明确、调理明细的程序图。



判断矩阵的最大特征值项目六 矩阵的特征值与特征向量实验1求矩阵的特征值与特征向量实验目的学习利用Mathematica(4.0以上版本)命令求方阵的特征值和特征向量能利用软件计算 方阵的特征值和特征向量及求二次型的标准形 .求方阵的特征值与特征向量.(1) 求矩阵A 的特征值.输入A={{-1,0,2},{1,2,-1},{1,3,0}}MatrixForm[A]Eigenvalues[A]则输岀A 的特征值{-1,1,1}(2) 求矩阵A 的特征向量.输入A={{-1,0,2},{1,2,-1},{1,3,0}}MatrixForm[A]Eigenvectors[A]{{-3,1,0},{1,0,1},{0,0,0}}即A 的特征向量为 1,0.0 1⑶利用命令Eigensystem 同时矩阵A 的所有特征值与特征向量.输入A={{-1,0,2},{1,2,-1},{1,3,0}}MatrixForm[A]Eigensystem[A]例1.1 (教材例1.1)求矩阵A 21 .的特征值与特值向量则输出则输岀矩阵A的特征值及其对应的特征向量2 3 4例1.2求矩阵A 3 4 5的特征值与特征向量4 5 6输入A=Table[i+j,{i,3},{j,3}]MatrixForm[A](1)计算矩阵A 的全部(准确解)特征值,输入Eigenvalues[A]则输出{0, 6 ■. 42 , 6 ..42 }(2) 计算矩阵A 的全部(数值解)特征值,输入Eigenvalues[N[A]]则输出{12.4807,-0.480741,-1.3483 10 16}(3) 计算矩阵A 的全部(准确解)特征向量,输入Eigenvectors[A]//MatrixForm则输出2 120 3 42-------- 1 23 4 4220 3 42----- -- 123 4 42(4) 计算矩阵A 的全部(数值解)特征向量,输入Eigenvectors[N[A]]//MatrixForm则输出0.430362 0.566542 0.7027220.80506 0.11119 0.5826790.408248 0.816497 0.408248(5) 同时计算矩阵A 的全部(准确解)特征值和特征向量,输入OutputForm[Eigensystem[A]]则输岀所求结果(6) 计算同时矩阵A 的零空间,输入NullSpace[A]1 172 42 234 42 17 2 42 23 4 42仅供学习与交流,如有侵权请联系网站删除谢谢3则输出{{1,21}}(7)调入程序包vvLinearAlgebra'Orthogonalization'后,还可以做以下的运算GramSchmidt[]:用Gram-Schmidt过程将向量组单位正交化;Normalize]]:将向量组单位化;Projection[vect1,vect2]:求从向量组 vectl 到 vect2 的正交映射. 输入vvLinearAlgebra 'Orthogonalization 'GramSchmidt[Eigenvectors[N[A]]]//MatrixForm则输出0.430362 0.566542 0.7027220.80506 0.11119 0.5826790.408248 0.816497 0.4082481 2 3例1.3 求方阵M 2 1 3的特征值和特征向量3 3 6输入Clear[M];M={{1,2,3,},{2,1,3}{3,3,6}};Eigenvalues[M]Eigenvectors[M]Eigensystem[M]则分别输出{-1,0,9}{{-1,1,0},{-1,-1,1}{1,1,2}}{{-1,0,9},{{-1,1,0},{-1,-1,1}{1,1,2}}}1/3 1/3 1/2例1.4 (教材例1.2)求矩阵A 1/5 1 1/3的特征值和特征向量的近似值6 1 2输入A={{1/3,1/3,-1/2},{1/5,1,-1/3},{6,1,-2}};Eigensystem[A]仅供学习与交流,如有侵权请联系网站删除谢谢4则屏幕输岀的结果很复杂,原因是矩阵A的特征值中有复数且其精确解太复杂.此时,可采用近似形式输入矩阵 A,则输岀结果也采用近似形式来表达 .输入A={{1/3,1/3,-1/2},{1/5,1,-1/3},{6.0,1,-2}};Eigensystem[A]则输出{{-0.748989+1.27186i,-0.748989-1.27186i,0.831311},{{0.179905+0.192168i,0.116133+0.062477l,0.955675+0.i},{0.179905-0.192168i,0.116133-0.062477i,0.955675+0.i},{-0.0872248,-0.866789,-0.490987}}}从中可以看到A有两个复特征值与一个实特征值.属于复特征值的特征向量也是复的;属于实特征值的特征向量是实的.3 0 0例1.5 (教材例1.3)已知2是方阵A 1 t 3的特征值,求t .1 2 3输入Clear[A,q];A={{2-3,0,0},{-1,2-t,-3},{-1,-2,2-3}};q=Det[A]Solve[q==0,t]则输出{{t 8}}即当t 8时,2是方阵A的特征值.2 12例1.6 (教材例1.4)已知x (1,1, 1)是方阵A5 a 3 的一个特征向量,求参数1 b 2a,b及特征向量x所属的特征值.设所求特征值为t,输入Clear[A,B,v,a,b,t];A={{t-2,1,-2},{-5,t-a,-3},{1,-b,t+2}};v={1,1,-1};B=A.v;Solve[{B[[1]]==0,B[[2]]==0,B[[3]]==0},{a,b,t}]则输出仅供学习与交流,如有侵权请联系网站删除谢谢5{{a -3, b 0, t -1}}即a 3,b 0时,向量x (1,1, 1)是方阵A的属于特征值-1和特征向量.矩阵的相似变换4 1 1例1.7 (教材例1.5)设矩阵A 2 2 2,求一可逆矩阵P ,使P 1AP为对角矩阵.2 2 2方法1输入Clear[A,P];A={{4,1,1},{2,2,2},{2,2,2}};Eigenvalues[A]P=Eigenvectors[A]//Transpose则输出{0,2,6}{{0,-1,1},{-1,1,1},{1,1,1}}0 1 1 0 1 1即矩阵A的特征值为0,2,6特征向量为 1 , 1与1 矩阵P 1 1 11 1 1 1 1 1可验证P 1AP为对角阵,事实上,输入Inverse[P ]. A.P则输出{{0,0,0},{0,2,0},{0,0,6}}因此,矩阵A在相似变换矩阵P的作用下,可化作对角阵.方法2 直接使用JordanDecomposition命令,输入jor=JordanDecomposition[A]则输出{{{0,-1,1},{-1,1,1},{1,1,1}},{{0,0,0},{0,2,0},{0,0,6}}}可取岀第一个矩阵S和第二个矩阵,事实上,输入jor[【1]]jor[【2]]则输出{{0,-1,1},{-1,1,1},{1,1,1}}{{0,0,0},{0,2,0},{0,0,6}}输岀结果与方法1的得到的结果完全相同. 仅供学习与交流,如有侵权请联系网站删除谢谢61 0例1.8 方阵A 是否与对角阵相似?2 1输入Clear[A];A={{1,0},{2,1}};Eigensystem[A]输岀为{{1,1},{{0,1}{0,0}}}于是,1是二重特征值,但是只有向量{0,1}是特征向量,因此,矩阵A不与对角阵相似2 0 0 1 0 0 例1.9 (教材例1.6)已知方阵A 2x2与B 0 2 0相似,求x, y .3 11 0 0 y注意矩阵B是对角矩阵,特征值是1,2, y.又矩阵A是分块下三角矩阵,-2是矩阵A的特征值矩阵A与B相似,则y 2,且-1,2也是矩阵A的特征值.输入Clear[c,v];v={{4,0,0},{-2,2-x,-2},{-3,-1,1}};Solve[Det[v]==0,x]则输出{{x 0}}所以,在题设条件,x 0, y 2.输入0 1 1 01 0 1 0 1,求一个正交阵P,使P 1AP为对角阵1 1 0 00 0 0 2例1.10 对实对称矩阵AvvLinearAlgebra'OrthogonalizationClear[A,P]A={{0,1,1,0 },{1,0,1,0},{1,1,0,0},{0,0,0,2}};Eigenvalues[A]Eigenvectors[A]仅供学习与交流,如有侵权请联系网站删除谢谢7输岀的特征值与特征向量为{-1,-122}{{-1,0,1,0},{-1,1,0,0},{0,0,0,1},{1,1,1,0}} 再输入P=GramSchmidt[Eigenvectors[A]]//Transpose输岀为已经正交化和单位化的特征向量并且经转置后的矩阵P 丄。
实验报告(一)课程名称数学建模实验项目Matlab基本操作及其实际应用实验环境PC机、Matlab学院/班级学号/姓名指导教师实验日期成绩一、实验名称:随机一致性指标求解二、实验目的:1)掌握用matlab求解随机一致性指标的方法2)加深对随机一致性指标概念的理解三、实验内容:用matlab或C++编写程序分别计算n=3-30时的n阶矩阵的随机一致性检验指标的值RI。
//本组实验随机数产生正互反矩阵,这个数目必须取的相当大(超过1000000,所以此程序跑起来比较费时),才比较接近标准答案#include<iostream>#include<cmath>#include<ctime>#include<cstdlib>#include<iomanip>using namespace std;int getNameta(double a[],int n); //获取当前随机正互反矩阵的最大λvoid createMatrix(double a[],int n); //建立随机正互反矩阵int getMax(double b[],int n); //获取b矩阵中的最大值void Mifa(double a[],double b[],int n); //幂法过程void main(){int n; //矩阵阶数int m = 3000; //建立的随机正互反矩阵个数int all = 0; //所有最大λ的和int tem = 0;int ri = 0; //最终的RI(为了计算方便,将实际的RI扩大了100倍进行计算了)cout << "Please enter the size of the matrix:" << endl;cout << "n = " ;cin >> n;if(n > 2&& n <= 30){for(int i =0;i<m;i++){double *a = new double[n*n]; //声明n*n的随机正互反矩阵for(int j =0;j<n*n;j++){a[j] = 1;}createMatrix(a,n); //建立n*n的随机正互反矩阵all += getNameta(a,n); //获得最大λ}tem = all/m;//计算得RIri = (tem - n*100);ri = ri/(n-1); //计算得到的RI (乘以100后的结果)int baiwei = ri/100;int shiwei = (ri-100*baiwei)/10;int gewei = ri-100*baiwei-10*shiwei;cout << "The RI of the " << n <<" size matrix is " << baiwei << "." << shiwei << gewei<< endl;}else if(n ==1){cout << "The RI of the " << n <<" size matrix is " << 0 << endl;}elsecout << "The size of n you input is wrong" << endl;}void createMatrix(double a[],int n){doublesample[17]={1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,1.0/2.0,1.0/3.0,1.0/4.0,1.0/ 5.0,1.0/6.0,1.0/7.0,1.0/8.0,1.0/9.0};for(int i=0;i<n;i++)for(int j=i;j<n;j++){int t;t = rand()%17;if( j == i){a[n*i+j]=1.0;}else{a[n*i+j] = sample[t];a[n*j+i] = 1.0/sample[t];}}}int getNameta(double a[],int n){int tem=0;double *b=new double[n];for(int i=0;i<n;i++){b[i]=1.0/n;}Mifa(a,b,n);int max=getMax(b,n);while(tem != max){tem = max;for(int d = 0;d<n;d++){b[d] = b[d]*100/max;}Mifa(a,b,n);max = getMax(b,n);}int nameta;nameta = tem;return nameta;}void Mifa(double a[],double b[],int n) {double *c = new double[n];for(int r = 0;r<n;r++){c[r] = 0.0;}for(int i =0;i<n;i++)for(int j = 0 ;j<n;j++){c[i] += a[n*i+j]*b[j];}for(int k =0;k<n;k++){b[k] = c[k];}}int getMax(double b[],int n){int a = 0;for(int i = 0;i<n;i++){if(100*b[i]>a)a = 100*b[i];}int tem;tem = a;return tem;}实验结果:四、实验心得:本实验使用的是C++编制程序,令我更好的理解随机一致性指标RI,进一步掌握了随机一致性指标求解方法以及随机一致性检验的方法。
东南大学《数学实验》报告学号姓名成绩
实验内容:
一实验目的
1.掌握matlab基本矩阵编程计算方法
2.加深对层次分析法的理解
3.掌握矩阵随机一致性指标RI的计算过程
二实验思路
为了求任意n阶矩阵的随机一致性指标RI的值,我们需要做以下几步工作
1.先构造n阶的正互反矩阵
2.求正互反矩阵的特征值
3.找出最大特征值
4.取多个n阶正互反矩阵最大特征值的平均值
5.计算相应的RI值
三实验内容与要求
1.实验代码及说明
RI=zeros(1,30); %zeros(m,n)产生m*n的double类零矩阵,zeros(n)产生n*n的
全0阵。
%定义了结果输出格式(行向量)for n=3:30 %定义n的范围;3-30
times=10000; %任意n阶矩阵产生10000个正互反矩阵
enum=[9 8 7 6 5 4 3 2 1 1/2 1/3 1/4 1/5 1/6 1/7 1/8 1/9]; %定义一维矩阵
enum
x=zeros(1,times); %定义最大特征值向量并初始化
A=ones(n,n); %先生成n阶幺矩阵,矩阵所有元素都为1
for num=1:times %循环
for i=1:n
for j=i+1:n %先找到正互反矩阵的上三角
A(i,j)=enum(ceil(17*rand(1))); %rand(1)随机生成一个位于区间(0,1)的数
%17*rand(1)则随机生成位于区间(0,17)的数,
%经ceil函数取整后得到一个1-17之间的整数。
%则A(i,j)的值为矩阵enum中的某一个
A(j,i)=1/(A(i,j)); %矩阵的下三角元素是上三角元素的倒数
A(i,i)=1; %对角线元素取1
%以上五段为构造正互反矩阵
end
end
V=eig(A); %求矩阵的特征值
x(num)=max(V); %以最大特征值给x向量赋值
end
k=sum(x)/times; %最大特征值平均值
RI(n)=(k-n)/(n-1); %算出对应RI的值
end
RI
2.实验结果(随机运行两次代码,得到不同的结果)
(1)
RI =
1 至 14 列
0 0 0.5258 0.8924 1.1099 1.2507 1.3353 1.4087
1.4526 1.4876 1.5111 1.5369 1.5550 1.5704
15 至 28 列
1.5834 1.5950 1.6057 1.6159 1.6199 1.6280 1.6355 1.6402 1.6463 1.6508 1.6541 1.6597 1.6633 1.6661
29 至 30 列
1.6700 1.6723
(2)
RI =
1 至 14 列
0 0 0.5285 0.8935 1.1077 1.2530 1.3420 1.4026
1.4539 1.4903 1.5121 1.5346 1.5570 1.5719
15 至 28 列
1.5865 1.5946 1.6055 1.6149 1.6233 1.6292 1.6354 1.6413 1.6462 1.6522 1.6554 1.6593 1.6642 1.6667
29 至 30 列
1.6695 1.6720
3.结果分析
虽然运行两次得到的结果不同,但差距并不是很大,可以大致得到n 阶矩阵对应的RI值的范围。
为了简单,在误差范围内,可以取结果的前两位作为对应的RI值。