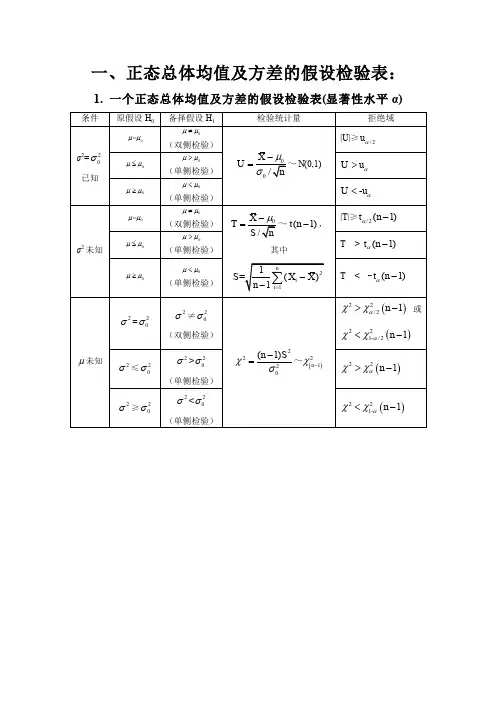
两个正态总体均值差的区间估计
- 格式:doc
- 大小:371.50 KB
- 文档页数:5


两个总体均值之差的区间估计公式引言在统计学中,我们经常需要估计两个总体均值之间的差异。
这有助于我们理解两个总体的差异程度,并在实际应用中做出相应的决策。
本文将介绍两个总体均值之差的区间估计公式,帮助读者理解如何进行参数估计。
一、独立样本均值差的区间估计当我们有两个独立的样本,且每个样本的观测值满足正态分布时,我们可以使用独立样本均值差的区间估计公式。
假设我们有两个样本的均值分别为$\b ar{X}_1$和$\ba r{X}_2$,样本大小分别为$n_1$和$n_2$,样本标准差分别为$s_1$和$s_2$。
那么两个总体均值之差的区间估计公式为:$$\l ef t(\b ar{X}_1-\b ar{X}_2\ri gh t)\p mt_{\a lp ha/2}\s q rt{\fr ac{s_1^2}{n_1}+\fr a c{s_2^2}{n_2}}$$其中,$t_{\al ph a/2}$是自由度为$n_1+n_2-2$的$t$分布上的临界值,$\al ph a/2$为显著性水平的一半。
二、配对样本均值差的区间估计当我们有一对配对的样本,例如同一组人在不同时间的观测,或同一组物体在不同条件下的观测时,我们可以使用配对样本均值差的区间估计公式。
假设我们有一对配对样本的均值差为$\b ar{D}$,样本大小为$n$,样本标准差为$s_D$。
那么配对样本均值差的区间估计公式为:$$\b ar{D}\pm t_{\a l ph a/2}\f ra c{s_D}{\sq rt{n}}$$其中,$t_{\al p h a/2}$是自由度为$n-1$的$t$分布上的临界值,$\al ph a/2$为显著性水平的一半。
三、示例应用为了更好地理解两个总体均值之差的区间估计公式,我们通过一个示例来说明其应用。
假设我们想要比较两个不同药物在降低血压上的效果。
我们随机选择了两组患者,并对每一组患者分别施用不同的药物。


两正态总体均值差的区间估计基于Wolfram Mathematica ,给出了两正态分布Ν[μ1,σ1]、Ν[μ2,σ2]总体均值差μ1-μ2在两总体方差已知、未知但相等、未知但样本量相等、未知但已知方差比、未知近似、未知精确的置信区间估计方法。
最后对理论结果进行程序模拟。
设X i ~Ν(μ1,σ1),i =1,2,...,n ,为正态总体X ~Ν(μ1,σ1)的一i.i.d.,样本均值X -=1n i =1n X i ,样本方差S X 2=1n -1 i =1n X i -X - 2。
设Y i ~Ν(μ2,σ2),i =1,2,...,m ,为正态总体Y ~Ν(μ2,σ2)的一i.i.d.,样本均值Y -=1m i =1m Y i ,样本方差S Y 2=1m -1 i =1m Y i -Y - 2。
一、两总体方差σ12=σ102、σ22=σ202已知定理1:X -Ν μ1,σ1n ,Y -Ν μ2,σ2m .CharacteristicFunction NormalDistribution [μ,σ],t n n;特征函数CharacteristicFunction 正态分布NormalDistribution μ,σn ,t ;%⩵%%//完全简化FullSimplify [#,n >0&&属于Element [n,整数域Integers ]]&True定理2:X --Y -Νμ1-μ2,⇔X --Y --(μ1-μ2)Ν[0,1].转换分布TransformedDistribution X -Y,X 正态分布NormalDistribution μ1,σ1n ,Y 正态分布NormalDistribution μ2,σ2m转换分布TransformedDistribution(X -Y )-(μ1-μ2), X 正态分布NormalDistribution μ1,σ1n ,Y 正态分布NormalDistribution μ2,σ2m //完全简化FullSimplifyNormalDistribution μ1-μ2,NormalDistribution [0,1]下面简要给出求μ1-μ2置信区间的方法:由α2≤Φ≤1-α2,得μ1-μ2的置信水平为1-α的置信区间为X --Y --Z1≤μ1-μ2≤X --Y --Zα2即X --Y --Z1-α2≤μ1-μ2≤X --Y -+Z1其长度:L =2Z 1-α2以下是程序模拟:需要Needs ["HypothesisTesting`"]μ10=10;μ20=1;σ10=3;σ20=4;X =伪随机变数RandomVariate [正态分布NormalDistribution [μ10,σ10],2000];Y =伪随机变数RandomVariate [正态分布NormalDistribution [μ20,σ20],1000];α=0.05;"(一)两方差已知""1.计算法"n =长度Length [X ];m =长度Length [Y ];M =平均值Mean [X ]-平均值Mean [Y ];σ=Q =分位数Quantile 正态分布NormalDistribution [0,1],1-α2;{M -Q σ,M +Q σ}"2.MeanDifferenceCI"MeanDifferenceCI X,Y,KnownVariance → σ102,σ202 ,置信级别ConfidenceLevel →1-α"3.NormalCI"NormalCI [M,σ,置信级别ConfidenceLevel →1-α]"区间长度:"L =2Q σ"相对区间长度:"r =L M "(二)两方差未知"清除Clear [μ,σ]{μ1,σ1}={μ,σ}/.求分布参数FindDistributionParameters [X,正态分布NormalDistribution [μ,σ]];2 正态分布\\正态分布统计分析\\两正态总体均值差的置信区间.nb求分布参数正态分布{μ2,σ2}={μ,σ}/.求分布参数FindDistributionParameters [Y,正态分布NormalDistribution [μ,σ]];"1.计算法"n =长度Length [X ];m =长度Length [Y ];M =平均值Mean [X ]-平均值Mean [Y ];σ=Q =分位数Quantile 正态分布NormalDistribution [0,1],1-α2;{M -Q σ,M +Q σ}"2.MeanDifferenceCI"MeanDifferenceCI X,Y,KnownVariance → σ12,σ22 ,置信级别ConfidenceLevel →1-α"3.NormalCI"NormalCI [M,σ,置信级别ConfidenceLevel →1-α]"区间长度:"L =2Q σ"相对区间长度:"r =L M(一)两方差已知1.计算法{8.75322,9.31447}2.MeanDifferenceCI {8.75322,9.31447}3.NormalCI{8.75322,9.31447}区间长度:0.561248相对区间长度:0.0621273(二)两方差未知1.计算法{8.75899,9.30871}2.MeanDifferenceCI {8.75899,9.30871}3.NormalCI{8.75899,9.30871}区间长度:正态分布\\正态分布统计分析\\两正态总体均值差的置信区间.nb30.549724相对区间长度:0.0608516二、两总体方差σ12=σ22未知σ12=σ22未知,由定理2,知X--Y- Ν μ1-μ2,σ,X--Y- -(μ1-μ2)σΝ[0,1]。

双正态总体参数的区间估计双正态总体参数的区间估计是统计学中的一种方法,用于估计由两个正态分布组成的总体的参数。
这种方法适用于当我们需要估计两个总体的平均值或比例时,且这两个总体可以被假定为来自两个不同的正态分布。
下面我们将详细介绍双正态总体参数的区间估计的原理和步骤。
双正态总体参数的区间估计可以分为两种情况:一种是当我们需要估计两个总体的平均值,另一种是当我们需要估计两个总体的比例。
首先,假设我们需要估计两个总体的平均值。
我们可以用样本平均值来估计总体平均值,并通过计算标准误差来构建置信区间。
如果我们假设两个总体的方差相等,则可以使用统计学中的配对t检验方法来进行推断。
具体步骤如下:1.收集样本数据。
从每个总体中随机抽取一定数量的样本,并记录下每个样本的观测值。
2.计算样本平均值。
对于每个总体,计算对应样本的平均值。
3.计算差值。
对于每个配对样本,计算它们的差值。
如果我们关注的是总体平均值的差异,则用两个总体对应样本的平均值之差来作为差值。
4.计算标准差。
计算差值样本的标准差,用来估计差值的标准误差。
5.确定置信水平。
选择一个置信水平,通常为95%。
这意味着我们希望有95%的置信度认为估计的区间包含真实的总体差异。
6.计算临界值。
确定配对t检验的自由度,并使用自由度和置信水平来查找相应的t临界值。
7.构建置信区间。
使用差值平均值±t临界值*标准误差来构建置信区间,这个区间将包含真实的总体差异。
另一种情况是当我们需要估计两个总体的比例。
在这种情况下,我们可以使用两个样本中的比例差异来估计总体的比例差异。
具体步骤如下:1.收集样本数据。
从每个总体中随机抽取一定数量的样本,并记录下每个样本中的成功次数和总次数。
2.计算样本比例。
对于每个总体,计算对应样本的比例,即成功次数除以总次数。
3.计算差异。
对于每个配对样本,计算它们的比例之差。
4.计算标准误差。
计算比例差异样本的标准误差,用来估计比例差异的标准误差。

、中位数可反映总体的趋势,四分位差可反映总体的7、以下数字特征不刻画分散程度的是A、极差B、离散系数C、中位数D、标准差8、已知总体平均数为200,离散系数为0.05,则总体方差为A、 B、10 C、100 D、0.19、两个总体的平均数不相等,标准差相等,则A、平均数大,代表性大B、平均数小,代表性大C、两个总体的平均数代表性相同D、无法判断10、某单位的生产小组工人工资资料如下:90元、100元、110元、120元、128元、148元、200元,计算结果均值为元,标准差为A、σ=33B、σ=34C、σ=34.23D、σ=3511、已知方差为 100 ,算术平均数为 4 ,则标准差系数为A、10B、2.5C、25D、无法计算12、有甲乙两组数列,若A、1<21>2,则乙数列平均数的代表性高B、1<21>2,则乙数列平均数的代表性低C、1=21>2,则甲数列平均数的代表性高D、1=21<2,则甲数列平均数的代表性低13、某城市男性青年27岁结婚的人最多,该城市男性青年结婚年龄为26.2岁,则该城市男性青年结婚的年龄分布为A、右偏B、左偏C、对称D、不能作出结论14、某居民小区准备采取一项新的物业管理措施,为此,随机抽取了100户居民进行调查,其中表示赞成的有69户,表示中立的有22户,表示反对的有9户,描述该组数据的集中趋势宜采用A、众数B、中位数C、四分位数D、均值15、如果你的业务是提供足球运动鞋的号码,哪一种平均指标对你更有用?A、算术平均数B、几何平均数C、中位数D、众数三、判断1、已知分组数据的各组组限为:10~15,15~20,20~25,取值为15的这个样本被分在第一组。
()2、将收集到得的数据分组,组数越多,丧失的信息越多。
()3、离散变量既可编制单项式变量数列,也可编制组距式变量数列。
)4、从一个总体可以抽取多个样本,所以统计量的数值不是唯一确定的。
()5、在给定资料中众数只有一个。

两个正态总体均值差的区间估计实验一一、实验目的熟悉SPSS的参数估计功能,熟练掌握两个正态总体均值之差(独立样本)的区间估计方法及操作过程,对SPSS运行结果能进行解释。
二、实验内容【例】(数据文件为data03—1。
sav)为估计两种方法组装产品所需要时间的差异,分别对两种不同的组装方法个随机安排12个工人,每个工人组装一件产品所需的时间(分钟)。
数据如表1所示:表1 两种方法组装产品所需的时间方法1方法2方法1方法228.330。
129.037。
632.128。
827.622.231.033.820.030.236.037。
238。
534。
428。
030.031.726。
032.031.233.426。
5试以95%的置信水平确定两种方法组装产品所需时间差值的置信区间。
解:第一步,打开数据文件“data03—1。
sav",选择菜单“Analyze→Compare Means→Independent-samples T Test”项,弹出“Independent- samples T Test”对话框。
从对话框左侧的变量列表中选“时间”,进入“Test Variable(s)”框,选择变量“方法”,进入“Grouping Variable”框。
如图4—7所示图4-7第二步:点击“Define Groups”按钮弹出“Define Groups"定义框,在Group 1中输入“1",在Group 2中输入“2".第三步:点击“Options”按钮弹出“Confidence Interval”定义框,在“Confidence Interval”框中输入“95”,点击“Continue”第四步:单击“OK"按钮,得到输出结果。
Independent Samples TestLevene'sTest forEqualityofVariances t-test for Equality of MeansF Sig.t dfSig.(2—tailed)MeanDifferenceStd。


双正态总体参数的区间估计双正态总体是指一个总体服从正态分布,且这两个分布的均值和方差都相等。
在双正态总体中,我们常常需要估计总体参数的区间估计,即估计参数的真实值落在哪个区间内。
对于双正态总体的均值μ,我们可以使用Z分数进行区间估计。
假设我们想要在95%的置信水平下估计μ的区间为(a,b),则有:P(μ-a < X < μ+b) = 0.95其中,X是从双正态总体中抽取的样本,a和b是未知的参数。
为了解决这个问题,我们可以利用双正态总体的对称性质,即在均值μ两侧的概率相等。
因此,我们可以使用Z分数的对称性质,得到:P(μ-a < X < μ+b) = 0.975这意味着,在95%的置信水平下,μ的区间为(a,b)的概率为0.975,也就是说,μ的真实值落在这个区间内的概率为0.975。
对于双正态总体的方差σ^2,同样可以使用Z分数进行区间估计。
假设我们想要在95%的置信水平下估计σ^2的区间为(d,e),则有:P(σ2-d < X2 <σ2+e) = 0.95其中,X2是从双正态总体中抽取的样本的方差,d和e 是未知的参数。
同样,我们可以利用双正态总体的对称性质,得到:P(σ2-d < X2 < σ2+e) = 0.975因此,在95%的置信水平下,σ2的区间为(d,e)的概率为0.975,也就是说,σ2的真实值落在这个区间内的概率为0.975。
需要注意的是,对于双正态总体的均值和方差的区间估计,我们需要先确定置信水平和区间长度。
一般来说,置信水平为95%是比较常见的选择,区间长度一般为2倍标准误差。
具体的参数和区间长度需要根据实际情况进行调整。
两个正态总体均值差的区间估计
实验一
一、实验目的
熟悉SPSS的参数估计功能,熟练掌握两个正态总体均值之差(独立样本)的区间估计方法及操作过程,对SPSS运行结果能进行解释。
二、实验内容
【例】(数据文件为data03-1.sav)为估计两种方法组装产品所需要时间的差异,分别对两种不同的组装方法个随机安排12个工人,每个工人组装一件产品所需的时间(分钟)。
数据如表1所示:
表1 两种方法组装产品所需的时间
试以95%的置信水平确定两种方法组装产品所需时间差值的置信区间。
解:第一步,打开数据文件“data03-1.sav”,选择菜单“Analyze→Compare Means→Independent-samples T Test”项,弹出“Independent- samples T Test”对话框。
从对话框左侧的变量列表中选“时间”,进入“Test Variable(s)”框,选择变量“方法”,进入“Grouping Variable”框。
如图4-7所示
图4-7
第二步:点击“Define Groups”按钮弹出“Define Groups”定义框,在Group 1中输入“1”,在Group 2中输入“2”。
第三步:点击“Options”按钮弹出“Confidence Interval”定义框,在“Confidence Interval”框中输入“95”,点击“Continue”
第四步:单击“OK”按钮,得到输出结果。
输出结果表明:(假定两种方法组装产品的时间服从正态分布,且方差相等,两种方法组装产品所需时间差值的置信区间为[0.1403,7.2597];假定两个总体的方差不相等,两种方法组装产品所需时间差值的置信区间为[0.1384,
7.2616]。
)本例方差齐性检验结果:0.9170.05
=>=,不能拒绝原假设,
pα
同方差假定是合理的,因而,两种方法组装产品所需时间差值的置信区间为(0.1403,7.2597)。
实验二:
一、实验目的
熟悉SPSS的参数估计功能,熟练掌握两个正态总体均值之差(匹配样本)的区间估计方法及操作过程,对SPSS运行结果能进行解释。
二、实验内容
【例】(数据文件为data03-2.sav)由10名学生组成一个随机样本,让他们分别采用A和B两套试卷进行测试。
结果如表2所示:
表2 10名学生两套试卷的得分
学生编号试卷A 试卷B
1 2 3 4 5 6 7 8 9 10 78.0
63.0
72.0
89.0
91.0
49.0
68.0
76.0
85.0
55.0
71.0
44.0
61.0
84.0
74.0
51.0
55.0
60.0
77.0
39.0
试建立两套试卷平均分数之差在95%的置信区间。
解:第一步,打开数据文件data03-2.sav,选择菜单“Analyz e→Compare Means→Paired-samples T Test”项,弹出“Paired - samples T Test”对话框。
从对话框左侧的变量列表中选择变量A卷、B卷进入Variables框。
第二步:点击“Options”按钮弹出“Confidence Interval”定义框,在“Confidence Interval”框中输入“95”,点击“Continue”
第三步:单击“OK”按钮,得到输出结果。
Paired Samples Test
Paired Differences
t df
Sig. (2-tailed)
Mean
Std.
Deviation
Std. Error
Mean
95% Confidence
Interval of the
Difference
Lower Upper
Pair 1 A卷-
B卷
11.000 6.532 2.066 6.327 15.673 5.325 9 .000
输出结果表明:两种试卷所产生的分数之差在95%的置信区间为(6.327,15.673)。