李克特量表法示范
- 格式:doc
- 大小:31.50 KB
- 文档页数:3

李克特LIKERT五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法。
李克特量表的编制方法是由李克特(RensisA.Likert)于1932年提出来的。
量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句。
这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级。
例如:十分同意、同意、未定、不同意、十分不同意。
第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类。
对这两类语句的答案所给的分数不同。
积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分。
第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分。
第四步:选择有鉴别力的语句,组成正式量表。
选择语句的方法通常有两种:平均值差数法和内在一致法。
平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组。
求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准。
差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除。
入选语句即可组成量表。
内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏。
如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关。
相关系数大者则表示应答者对该语句的态度与总态度相一致,因此语句入选。
相反,如果相关系数小,说明该语句的态度与总态度缺乏一致性,则该语句剔除。
依照此法,对每一语句加以筛选,最后所有入选语句即可组成一个量表。

李克特LIKERT五分量表法之羊若含玉创作李克特量表法是运用一个编制好的量表来丈量人们对告白、产品等对象的态度的办法.李克特量表的编制办法是由李克特(Rensis A.Likert)于1932年提出来的.量表的编制进程可分为以下四个步调:第一步:拟定若干条关于态度对象的语句.这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级.例如:十分同意、同意、未定、不合意、十分不合意.第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口胃”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类.对这两类语句的答案所给的分数不合.积极态度语句的给分办法是:十分同意5分,同意4分,未定3分,不合意2分,十分不合意1分;消极语句的给分办法恰好相反:十分同意1分,同意2分,未定3分,不合意3分,十分不合意4分.第三步:选定若干受查询拜访者,要求他们针对态度,依据自己的意见,就所列出的每一语句一一评分.第四步:选择有辨别力的语句,组成正式量表.选择语句的办法通常有两种:平均值差数法和内涵一致法.平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序分列,截取最高分数端的25%为高分组,最低分数端的25%为低分组.求出这两个组中每一语句的平均值,并以高下分组的平均值之差作为语句筛选的尺度.差值大者说明该语句的区分才能强,则入选;差值小者,说明语句区分度差,则剔除.入选语句即可组成量表.内涵一致法是将各答应者的总分分列成一栏,将某一语句的分数分列为别的一栏.如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量未几,把应答者的总分分离减去该语句的得分,尔后求等级相关.相关系数大者则暗示应答者对该语句的态度与总态度相一致,因此语句入选.相反,如果相关系数小,说明该语句的态度与总态度缺乏一致性,则该语句剔除.依照此法,对每一语句加以筛选,最后所有入选语句即可组成一个量表.量表制成后,其使用办法是:让应答者对每一语句作答复,然后转换成分数,并累加起来,这样就可以得到每一位应答者的态度分数,把所有应答者的得分平均起来,则可得出受查询拜访者对该评价对象的总体态度.如果这些受查询拜访者具有代表性,则可以推论出一般消费者的态度.在该量表中,被测试者对这些问题的态度不再是简略的同意或不合意两类,而是将赞成度分为若干类,规模从异常赞成到异常不赞成,中间为中性类,由于类型增多,人们在态度上的不同就能充分体现出来.别的,由于比较简略,被测试者完成起来也较为节俭时间.因此,李克特量表是从事意见或态度研究较受迎接、最常使用的一种量表之一.。


创作编号:GB8878185555334563BT9125XW创作者:凤呜大王*李克特LIKERT五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法。
李克特量表的编制方法是由李克特(Rensis A.Likert)于1932年提出来的。
量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句。
这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级。
例如:十分同意、同意、未定、不同意、十分不同意。
第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类。
对这两类语句的答案所给的分数不同。
积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分。
第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分。
第四步:选择有鉴别力的语句,组成正式量表。
选择语句的方法通常有两种:平均值差数法和内在一致法。
平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组。
求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准。
差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除。
入选语句即可组成量表。
内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏。
如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关。
相关系数大者则表示应答者对该语句的态度与总态度相一致,因此语句入选。
相反,如果相关系数小,说明该语句的态度与总态度缺乏一致性,则该语句剔除。

李克特L I K E R T五分量表格法文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-李克特L I K E R T五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法。
李克特量表的编制方法是由李克特(Rensis A.Likert)于1932年提出来的。
量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句。
这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级。
例如:十分同意、同意、未定、不同意、十分不同意。
第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类。
对这两类语句的答案所给的分数不同。
积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分。
第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分。
第四步:选择有鉴别力的语句,组成正式量表。
选择语句的方法通常有两种:平均值差数法和内在一致法。
平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组。
求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准。
差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除。
入选语句即可组成量表。
内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏。
如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关。
相关系数大者则表示应答者对该语句的态度与总态度相一致,因此语句入选。

李克特量表的具体操作步骤李克特量表(Likert scale)是属评分加总式量表最常用的一种,属同一构念的这些项目是用加总方式来计分,单独或个别项目是无意义的。
它是由美国社会心理学家利克特于1932年在原有的总加量表基础上改进而成的。
该量表由一组陈述组成,每一陈述有"非常同意"、"同意"、"不一定"、"不同意"、"非常不同意"五种回答,分别记为5、4、3、2、1,每个被调查者的态度总分就是他对各道题的回答所的分数的加总,这一总分可说明他的态度强弱或她在这一量表上的不同状态。
下面介绍它的操作方法:五点选项理清李克特量表(Likert Scale)和李克特选项(Likert item)的区别是重要的。
李克特量表是使用各种李克特选项的总称。
因为李克特选项,常常是一个视觉化量表(例如,在一个题目上的一条水平线,让受测者以画圈或点选的方式回答),这些选项有时也称为量表。
但是,这容易造成混淆,因此,比较好的做法是,李克特选项专指一个单独的选项。
一个李克特选项是一个陈述。
受测者被要求指出他或她们对该题目所陈述的认同程度,或任何形式的主观或客观评价。
通常使用五个回应等级,但许多计量心理学者(psychometrician)主张使用7或9个等级。
一项最近的实证研究指出,5等级、7等级和10等级选项的数据,在简单的资料转换后,其平均数、变异数、偏态和峰度都很相似。
例如李克特的五等选项的:1.强烈反对2.不同意3.既不同意也不反对4.同意5.坚决同意李克特量表是有两个极端的量化方法,衡量一个陈述的正面或负面回答。
当中间选项“无意见”不能用时,有时会使用四等量表──一个强迫选择(英语:forced choice)的方法。
李克特量表也许会受到几种因素干扰而失真。
受测者也许会回避勾选极端的选项(趋中倾向的偏差);对陈述的习惯性认同(惯性偏差);或试着揣摩并迎合他们自己或他们的组织希望的结果(社会赞许偏差)。

李克特量表一、基本含义李克特量表是总加量表的一种特定形式,是社会调查问卷中用得最多的一种量表形式。
美国社会心理学家李克特(R.A.Likert)于1932年在原有的总加量表基础上改进而成。
李克特量表由一组对某事物的态度或看法的陈述组成,回答者对这些陈述的回答被分成“非常同意、同意、不知道、不同意、非常不同意”5类,或者“赞成、比较赞成、无所谓、比较反对、反对”五类。
人们在态度上的差别,就在这一组的多样选择中被巧妙地反映出来。
二、具体操作第一步:对象填表请你对下列看法发表意见(请在每一行选一个方框打√)每一个回答者在这一量表上的4个得分(每行一个答案所对应的码值)加起来,就构成他对婚事操办方式的态度得分。
第三步:形成结论按上述赋值方式,一个回答者在该量表上的得分越高,表明他的态度越倾向于婚事大操大办。
三、设计方法①围绕要测量的态度或主题,以赞成或反对的方式写出与之相关的看法或陈述若干条(一般为20-30条)。
对每一陈述都给予5个答案:非常同意、同意、无所谓、不同意、很不同意,并根据赞成或反对的方向分别赋以1、2、3、4、5分。
②在所要测量的总体中,选择一部分对象(一般不能少于20人)进行试测。
③统计每位受测者在每条陈述上的得分以及每人在全部陈述上的总分。
④计算每一条陈述的分辨力,删除分辨力不高的陈述,保留分辨力高的陈述,形成正式的量表。
⑤分辨力的计算方法先根据受测对象全体的总分排序;然后取出总分最高的25%的人和总分最低的25%的人,并计算这两部分人在每一条陈述上的平均分;将这两个平均分相减,所得出的就是这一条陈述的分辨力系数;该系数的绝对值越大,说明这一陈述的分辨力越高。

李克特L I K E R T五分量表法集团公司文件内部编码:(TTT-UUTT-MMYB-URTTY-ITTLTY-李克特LIKERT五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法。
李克特量表的编制方法是由李克特(RensisA.Likert)于1932年提出来的。
量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句。
这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级。
例如:十分同意、同意、未定、不同意、十分不同意。
第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类。
对这两类语句的答案所给的分数不同。
积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分。
第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分。
第四步:选择有鉴别力的语句,组成正式量表。
选择语句的方法通常有两种:平均值差数法和内在一致法。
平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组。
求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准。
差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除。
入选语句即可组成量表。
内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏。
如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关。
相关系数大者则表示应答者对该语句的态度与总态度相一致,因此语句入选。
相反,如果相关系数小,说明该语句的态度与总态度缺乏一致性,则该语句剔除。

李克特LIKERT五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法。
李克特量表的编制方法是由李克特(Rensis A.Likert)于1932年提出来的。
量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句。
这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级。
例如:十分同意、同意、未定、不同意、十分不同意。
第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类。
对这两类语句的答案所给的分数不同。
积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分。
第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分。
第四步:选择有鉴别力的语句,组成正式量表。
选择语句的方法通常有两种:平均值差数法和内在一致法。
平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组。
求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准。
差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除。
入选语句即可组成量表。
内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏。
如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关。
相关系数大者则表示应答者对该语句的态度与总态度相一致,因此语句入选。
相反,如果相关系数小,说明该语句的态度与总态度缺乏一致性,则该语句剔除。
依照此法,对每一语句加以筛选,最后所有入选语句即可组成一个量表。
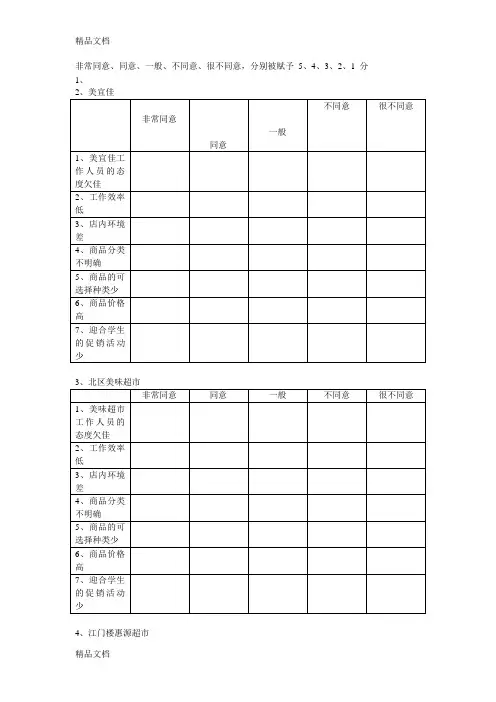
非常同意、同意、一般、不同意、很不同意,分别被赋予5、4、3、2、1 分1、
2、美宜佳
非常同意
同意一般
不同意很不同意
1、美宜佳工
作人员的态
度欠佳
2、工作效率
低
3、店内环境
差
4、商品分类
不明确
5、商品的可
选择种类少
6、商品价格
高
7、迎合学生
的促销活动
少
3、北区美味超市
非常同意同意一般不同意很不同意1、美味超市
工作人员的
态度欠佳
2、工作效率
低
3、店内环境
差
4、商品分类
不明确
5、商品的可
选择种类少
6、商品价格
高
7、迎合学生
的促销活动
少
4、江门楼惠源超市
非常同意同意一般不同意很不同意1、惠源超市
工作人员的
态度欠佳
2、工作效率
低
3、店内环境
差
4、商品分类
不明确
5、商品的可
选择种类少
6、商品价格
高
7、迎合学生
的促销活动
少。

李克特LIKERT五分量表法之迟辟智美创作李克特量表法是运用一个编制好的量表来丈量人们对广告、产物等对象的态度的方法.李克特量表的编制方法是由李克特(Rensis A.Likert)于1932年提出来的.量表的编制过程可分为以下四个步伐:第一步:拟定若干条关于态度对象的语句.这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的谜底相同,均为五个(或七个)品级.例如:十分同意、同意、未定、分歧意、十分分歧意.第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类.对这两类语句的谜底所给的分数分歧.积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,分歧意2分,十分分歧意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,分歧意3分,十分分歧意4分.第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分.第四步:选择有鉴别力的语句,组成正式量表.选择语句的方法通常有两种:平均值差数法和内在一致法.平均值差数法是先将应答者对每一句话所做的谜底换成份数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数真个25%为高分组,最低分数真个25%为低分组.求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准.差值年夜者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除.入选语句即可组成量表.内在一致法是将各承诺者的总分排列成一栏,将某一语句的分数排列为另外一栏.如果语句的数量较多,直接求这两列数据的品级相关,如果语句数量未几,把应答者的总分分别减去该语句的得分,而后求品级相关.相关系数年夜者则暗示应答者对该语句的态度与总态度相一致,因此语句入选.相反,如果相关系数小,说明该语句的态度与总态度缺乏一致性,则该语句剔除.依照此法,对每一语句加以筛选,最后所有入选语句即可组成一个量表.量表制成后,其使用方法是:让应答者对每一语句作回答,然后转换成份数,并累加起来,这样就可以获得每一位应答者的态度分数,把所有应答者的得分平均起来,则可得出受调查者对该评价对象的总体态度.如果这些受调查者具有代表性,则可以推论出一般消费者的态度.在该量表中,被测试者对这些问题的态度不再是简单的同意或分歧意两类,而是将赞成度分为若干类,范围从非常赞成到非常不赞成,中间为中性类,由于类型增多,人们在态度上的分歧就能充沛体现出来.另外,由于比力简单,被测试者完成起来也较为节省时间.因此,李克特量表是从事意见或态度研究较受欢迎、最常使用的一种量表之一.。
李克特L I K E R T五分量表法This model paper was revised by the Standardization Office on December 10, 2020李克特LIKERT五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法。
李克特量表的编制方法是由李克特(Rensis A.Likert)于1932年提出来的。
量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句。
这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级。
例如:十分同意、同意、未定、不同意、十分不同意。
第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类。
对这两类语句的答案所给的分数不同。
积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分。
第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分。
第四步:选择有鉴别力的语句,组成正式量表。
选择语句的方法通常有两种:平均值差数法和内在一致法。
平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组。
求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准。
差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除。
入选语句即可组成量表。
内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏。
如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关。
1 重新编码问卷中常有反向积分的情况,测量指标不一致,不能直接加减,所以量表分析的第一步是统一量表测量方向,重新编码。
RECODEq04 q05 q06 q08 q10 q11(4=1) (1=4) (2=3) (3=2) (ELSE=SYSMIS) INTO q04.1 q05.1 q06.1q08.1 q10.1 q11.1 .EXECUTE .2 求出量表总分 transform――computerCOMPUTE total = q01 + q02 + q03 +q04.1 +q05.1 + q06.1 + q07 + q08.1 + q09 + q10.1 + q11.1 + q12 + q13 .VARIABLE LABELS total '总得分' .EXECUTE .3 按总分高低排序:目的是找出总分最高和最低的25%的人的总分数。
因为在(3)中需要了解得分最高的25%和得分最低的25%的人在每一项指标上均值的差异,所以是独立样本的T检验。
现在的问题是怎么将最高的25%和得分最低的25%的人找出来并且分为2组。
第一步是排序,总得分从高到低&从低到高排列。
(1)首先将total按照升序排列,将总人数25%处的分数记下(19—35分)SORT CASES BYtotal (A) .(2)然后将total按照降序排列,将总人数25%处的分数记下(19-45分)SORT CASES BYtotal (D) .(3)将高分组(≥45)定位第一组(样本一),低分组(≤35)定位第二组(样本二),现在要做的就是将这两部分数据从total变量中分离出来,成为一个单独的变量。
重新编码RECODEtotal(45 thru Highest =1) (Lowest thru 35=2) INTO group .EXECUTE .(4)独立样本的T检验T-TESTGROUPS = group(1 2)/MISSING = ANALYSIS/VARIABLES = q01 q02 q03 q04 q05 q06 q07 q08 q09 q10 q11 q12 q13/CRITERIA = CI(.95) .。
李克特LIKERT五分量表法之相礼和热创作李克特量表法是运用一个编制好的量表来丈量人们对广告、产品等对象的态度的方法.李克特量表的编制方法是由李克特(Rensis A.Likert)于1932年提出来的.量表的编制过程可分为以下四个步调:第一步:制定多少条关于态度对象的语句.这些语句所表达态度的倾向有积极的和悲观的两个方面,每一语句的答案相反,均为五个(或七个)等级.例如:非常赞同、赞同、未定、分歧意、非常分歧意.第二步:把全部语句分为积极态度的语句(例如“这个品牌很合我的口味”)和悲观态度的语句(例如“这个品牌冷冰冰的”)这两类.对这两类语句的答案所给的分数分歧.积极态度语句的给分方法是:非常赞同5分,赞同4分,未定3分,分歧意2分,非常分歧意1分;悲观语句的给分方法恰恰相反:非常赞同1分,赞同2分,未定3分,分歧意3分,非常分歧意4分.第三步:选定多少受调查者,要求他们针对态度,根据本人的看法,就所列出的每一语句逐个评分.第四步:选择有鉴别力的语句,组成正式量表.选择语句的方法通常有两种:均匀值差数法和内在同等法.均匀值差数法是先将应对者对每一句话所做的答案换成分数,然后将全部应对者按其总分由高到低顺序陈列,截取最高分数端的25%为高分组,最低分数端的25%为低分组.求出这两个组中每一语句的均匀值,并以高低分组的均匀值之差作为语句挑选的尺度.差值大者阐明该语句的区分才能强,则当选;差值小者,阐明语句区分度差,则剔除.当选语句即可组成量表.内在同等法是将各答应者的总分陈列成一栏,将某一语句的分数陈列为另外一栏.假如语句的数量较多,直接求这两列数据的等级相关,假如语句数量未几,把应对者的总分分别减往该语句的得分,而后求等级相关.相关系数大者则暗示应对者对该语句的态度与总态度相反等,因而语句当选.相反,假如相关系数小,阐明该语句的态度与总态度缺乏同等性,则该语句剔除.按照此法,对每一语句加以挑选,末了全部当选语句即可组成一个量表.量表制成后,其运用方法是:让应对者对每一语句作答复,然后转换成分数,并累加起来,这样就可以得到每一位应对者的态度分数,把全部应对者的得分均匀起来,则可得出受调查者对该评价对象的总体态度.假如这些受调查者具有代表性,则可以推论出一样平常消费者的态度.在该量表中,被测试者对这些成绩的态度不再是简单的赞同或分歧意两类,而是将赞成度分为多少类,范围从非常赞成到非常不赞成,两头为中性类,由于类型增多,人们在态度上的不同就能充分表现出来.另外,由于比较简单,被测试者完成起来也较为俭省工夫.因而,李克特量表是从事意见或态度研讨较受欢迎、最常运用的一种量表之一.。