数学建模中SPSS运用
- 格式:docx
- 大小:1.29 MB
- 文档页数:4

20201/295徐燕1981要/数理统计学专业副教授/博士/广州民航职业技术学院人文社科学院/南方医科大学访问学者/从事统计学方法和应用研究工作(广州510403)以数学建模竞赛为例基于SPSS 建立ARIMA 模型Combined with learning pass and BOPPPS model to improve the teaching effect of electrical science徐燕基金项目:2019年高等学校中青年教师国内访问学者项目资助。
摘要SPSS 软件是当前应用最广泛的统计软件之一,其菜单化操作模式能够让使用者快速入门,SPSS 软件中时间序列模块能够实现模型的自动化筛选,参数估计和模型检验,是非统计学专业人员进行数据分析的有力工具。
是本文以2019年全国大学生数学建模竞赛D 题为例,以SPSS23软件为工具,对数据进行时间序列分析,建立ARIMA 模型。
关键词数学建模;SPSS;时间序列;ARIMA 模型中图分类号:R058文献标识码:ADOI :10.19694/ki.issn2095-2457.2020.01.160引言SPSS 软件是当前世界上应用最广泛的统计软件之一,菜单化操作、图表化输出的特点特别受到非统计学专业人员的欢迎。
使用SPSS 软件,我们几乎可以完全自动的自变量的预变换、筛选、模型优化、检验等工作。
SPSS 软件中的预测模块,纳入了常用的时间序列分析模型,如ARIMA 模型,包括自动的模型选择、参数估计和模型检验等功能,实现了简单操作即可得到可靠的时间序列模型,其功能得到了使用者的肯定。
近年来,全国大学生数学建模竞赛频频出现大数据统计建模试题,作为非统计学专业的大学生,对于复杂的数据统计分析方法和工具接触并不很多,如何让这些学生快速入门和掌握一门有利的数据分析软件工具、完成数据分析和建模等任务就是我们近几年来数学建模培训教学研究的重点。



以数学建模竞赛为例基于SPSS建立ARIMA模型一、引言数学建模竞赛是在各种学科领域中,通过数学方法解决实际问题的一种竞赛形式。
参加数学建模竞赛需要队员具备一定的数学建模能力,包括数学建模的理论知识、数学工具的使用和数学模型的构建能力。
在数学建模竞赛中,队员需要根据给定的问题和数据,使用数学方法建立合适的数学模型,并进行模型的求解和分析。
数学建模竞赛中的数学建模和数据分析方法对于队员来说是至关重要的。
在本文中,我们将以数学建模竞赛的一个实际问题为例,演示如何利用SPSS软件建立ARIMA模型对相关数据进行预测和分析。
我们将首先介绍ARIMA模型的基本原理和建模流程,然后利用SPSS软件对给定的数据进行ARIMA模型的建立和检验,最后对模型的效果进行评价并给出相关建议。
二、ARIMA模型的基本原理ARIMA模型是时间序列分析中常用的一种模型,用于对时间序列数据进行预测和分析。
ARIMA模型包括自回归(AR)、差分(I)和移动平均(MA)三部分,分别表示时间序列数据中的自相关、季节性趋势和误差项。
ARIMA模型的建立包括模型的识别、参数的估计和模型的检验三个步骤。
1. 模型的识别:首先需要对时间序列数据进行平稳性和自相关性检验,确定ARIMA模型的参数p、d、q。
p表示自回归的阶数,d表示差分的阶数,q表示移动平均的阶数。
2. 参数的估计:利用最大似然估计等方法,对ARIMA模型中的参数进行估计,得到模型的估计系数。
3. 模型的检验:对估计的ARIMA模型进行残差分析和预测检验,对模型的拟合效果进行评价,并进行模型的调整和优化。
三、SPSS建立ARIMA模型的步骤在SPSS软件中,利用时间序列建模功能可以方便地进行ARIMA模型的建立和分析。
下面我们以一个实际的数据为例,演示在SPSS中建立ARIMA模型的具体步骤。
1. 数据导入:首先在SPSS中导入要分析的时间序列数据,可以是Excel表格或者文本文件格式。



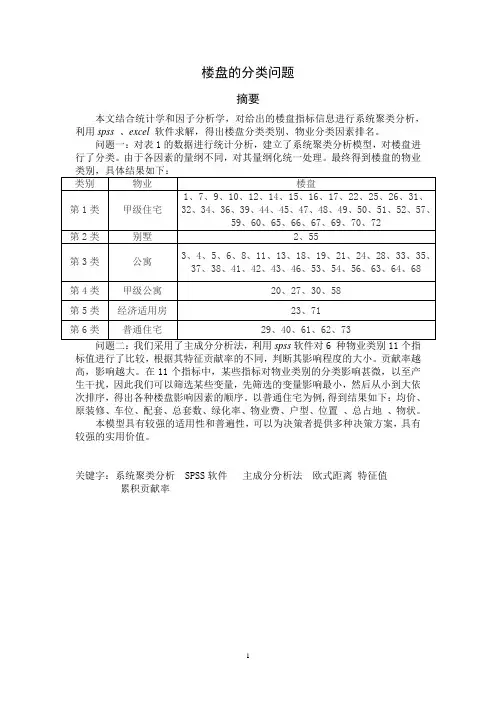
楼盘的分类问题摘要本文结合统计学和因子分析学,对给出的楼盘指标信息进行系统聚类分析,利用spss 、excel软件求解,得出楼盘分类类别、物业分类因素排名。
问题一:对表1的数据进行统计分析,建立了系统聚类分析模型,对楼盘进行了分类。
由于各因素的量纲不同,对其量纲化统一处理。
最终得到楼盘的物业标值进行了比较,根据其特征贡献率的不同,判断其影响程度的大小。
贡献率越高,影响越大。
在11个指标中,某些指标对物业类别的分类影响甚微,以至产生干扰,因此我们可以筛选某些变量,先筛选的变量影响最小,然后从小到大依次排序,得出各种楼盘影响因素的顺序。
以普通住宅为例,得到结果如下:均价、原装修、车位、配套、总套数、绿化率、物业费、户型、位置、总占地、物状。
本模型具有较强的适用性和普遍性,可以为决策者提供多种决策方案,具有较强的实用价值。
关键字:系统聚类分析 SPSS软件主成分分析法欧式距离特征值累积贡献率一、问题的背景21 世纪是世界城市化高度发展的世纪。
据联合国人居中心预测,2010年将达到55% ,2025 年达到65% ,其中发达国家将达到83% 。
发展中国家将达到61%。
我国目前的城市化水平约在30% 左右,不仅远落后于发达国家,也落后于发展中国家的平均水平,滞后于相对社会经济发展,需要迅速加以提高。
随着我国城市化进程的加快,人们在城市购房自然成为人人所关心的头等大事,那么我们就必要了解房产情况;面对眼花缭乱的楼盘信息,如何根据自己的实际情况,选择属于自己的物业呢?针对人们的需求,开发商该如何投资建设,又该考虑建哪些物业及关于楼盘该如何定价呢?解决这类问题是有很大的现实意义的。
二、问题的提出与重述根据商品房个性化,一般可以将商品房自高至低划分为6种物业类别,分别为:别墅、甲级公寓、公寓、甲级住宅、普通住宅、经济适用房。
现得到某城市一届房交会数据(见附表1),我们就此信息将解决以下问题: (1)给出表1各楼盘的物业类别;(2)关于该城市楼盘各物业类别,找出影响各物业类别的主要因素(或因素顺序);三、基本假设(1) 在人为的推测和软件的基础之上考虑,会出现许多的误差,假设误差极小。

以数学建模竞赛为例基于SPSS建立ARIMA模型一、引言二、题目描述假设某市某项产品的月销售数据如下(单位:件):月份销售量1 2002 2203 2104 2405 2506 2607 2708 2809 29010 30011 32012 330请建立ARIMA模型预测未来3个月的销售量。
三、建立ARIMA模型1. 数据处理在SPSS软件中导入上述数据,然后对数据进行时间序列图的绘制和基本统计分析。
通过时间序列图可以观察到数据是否存在趋势和季节性,基本统计分析可以得到数据的均值、标准差等关键统计量。
2. 差分运算由于ARIMA模型对原始数据的平稳性要求比较高,因此在建立模型之前需要进行差分运算以确保数据的平稳性。
在SPSS软件中,可以使用“Transform”菜单中的“Difference”功能对数据进行一阶差分或二阶差分操作。
在这个例子中,我们选择进行一阶差分操作。
3. 自相关和偏自相关图在差分运算之后,需要使用自相关和偏自相关图来确定ARIMA模型的p和q值。
在SPSS软件中,可以使用“Analyze”菜单中的“Forecasting”功能来生成自相关和偏自相关图,并根据图形来判断p和q的取值。
4. 建立ARIMA模型在确定了差分次数、p和q的取值之后,可以使用“Analyze”菜单中的“Forecasting”功能来建立ARIMA模型。
在输入模型参数的时候,需要根据之前的分析结果来设定差分次数、自回归阶数和移动平均阶数。
四、结果分析通过以上步骤,我们成功地建立了ARIMA模型并进行了未来3个月销售量的预测。
预测结果显示未来3个月销售量分别为340、350和360件。
我们还对模型的拟合效果进行了检验,结果表明模型的残差序列符合白噪声特性,预测结果较为可靠。
五、总结本文以一次数学建模竞赛题目为例,介绍了如何使用SPSS软件建立ARIMA模型进行时间序列分析和预测。
通过差分运算、自相关和偏自相关分析、模型建立和诊断以及预测分析等步骤,我们成功地对未来3个月销售量进行了预测。

以数学建模竞赛为例基于SPSS建立ARIMA模型ARIMA模型是一种时间序列的分析方法,可以用来对未来一段时间内的序列数据进行预测和分析,常常被应用于经济、金融、气象、流行病等领域。
在数学建模竞赛中,ARIMA模型也是常见的分析方法之一。
本文将以数学建模竞赛为例,介绍如何基于SPSS软件建立ARIMA模型。
一、数据收集与概览在建立ARIMA模型之前,需要先收集数据,并对数据进行概览。
假设我们研究的是某电商平台的销售数据,数据的格式为时间序列。
下面是部分数据:|日期 |销售额 ||--------|--------||2019-01-01|1000 ||2019-01-02|1200 ||2019-01-03|1300 ||2019-01-04|1150 ||2019-01-05|1400 ||2019-01-06|1250 ||2019-01-07|1350 ||2019-01-08|1500 ||2019-01-09|1650 ||2019-01-10|1800 ||2019-01-11|2000 ||2019-01-12|2200 ||2019-01-13|2300 ||2019-01-14|2400 ||2019-01-15|2500 |通过对数据的概览,我们可以看到销售额有逐渐增加的趋势,并且在一周内出现周期性的波动。
二、建立ARIMA模型1. 模型选择在建立ARIMA模型之前,需要先选择合适的模型。
ARIMA模型的选择最好基于时间序列的图形表示,以及ACF和PACF的分析。
可以通过以下步骤进行模型选择:① 绘制时序图,观察数据的整体趋势、周期变化和异常点等信息。
在SPSS中绘制时序图的方法是:点击菜单Data→Time Series→Line Chart,然后在弹出的对话框中选择“Month-Year”并勾选数据和选项,即可绘制出时序图。
② 绘制ACF和PACF的图形,观察自相关性和偏自相关性。

1.偏度(skewness)g1 0,则可以认为分布是对称的;若g1>0,则认为分布有右偏态;若g1<0,认为分布有左偏态2.峰度(kurtosis)它以正态分布为标准,比较两侧极端数据分布的情况。
对于正态分布有g2=0;若g2>0,表示数据中有较多远离均值的极端数据;若g2<0,则均值两侧极端数据较少。
1命令位置:分析\描述统计\频率(Frequencis)\统计量(Statistics)适合求分位点,一般情况下是首选命令2.分析\描述统计\描述统计(Descriptive)此命令可以完成数据的标准化,并把结果以变量的形式存放在数据文件上Z分数一般小数可以先行转化为T分数操作:转换(transform)→计算变量是否服从正态分布方法:⏹定性方法⏹观察偏度和峰度⏹画直方图⏹QQ图:散点基本在直线上,可以认为服从正态分布⏹可靠方法:单样本KS检验操作:图形->旧对话框3.假设检验的步骤提出原假设(零假设)H0;确定适当的检验统计量;计算检验统计量的值发生的概率(P值);给定显著性水平a;作出统计决策。
注:必须搞清楚原假设(零假设)是什么应该知道检验所用统计量服从什么分布会根据软件求得的p值(sig.),作出判断即:p<0.05,拒绝原假设;P>0.05, 接受原假设.4.单样本KS检验法:单样本KS检验-非参方法操作:分析――>非参数检验――>旧对话框5.列联表分析:判明所考察的各属性之间有无关联,即是否独立。
(利用交叉表分析)转化为一个假设检验问题,构造检验统计量卡方1)设置权重变量!数据\加权个案操作:分析->描述统计->交叉表->统计量->卡方6.1均值比较单样本t检验:目的:检验单个变量的均值是否与给定的常数(总体均值)之间是否存在显著差异。
要求样本来自的总体服从或近似服从正态分布。
H0:总体均值和指定检验值之间不存在显著差异。
⏹两独立样本t检验:目的:利用来自两个总体的独立样本,推断两个总体的均值是否存在显著性差异;样本来自的总体服从或近似服从正态分布,H0:两总体均值之间不存在显著差异Analyze――>compare――>independent-sample t test――>两配对样本t检验:根据样本数据对样本来自的两配对总体的均值是否有显著性差异进行推断。
2016年第8期25摘 要:SPSS 作为经典的统计学软件之一,具有简单易学、使用方便的特点,为非统计专业学生的使用提供便利。
本文依托2012年全国大学生数学建模竞赛C 题,以SPSS 11.0为例,简述该软件在数学建模竞赛中的简单应用:描述统计和回归分析。
关键词:SPSS 数学建模 应用DOI:10.16722/j.issn.1674-537X.2016.08.005一、引言SPSS,“统计产品与服务解决方案”软件,由斯坦福大学三位研究生于1968年开发。
SPSS 专门用于分析统计专业问题,突出特点是操作简便,除数据录入及少数命令程序需利用键盘输入,多数操作可通过鼠标完成。
SPSS 输出结果可读性较强,只要了解简单的统计知识就能读懂分析结果。
SPSS 提供多种统计分析方法,如统计描述、相关分析、方差分析、主成分分析、聚类分析、Logistic 回归等。
SPSS 具有数据输入和导入及编辑、统计分析、绘制图形等功能。
此外,SPSS 可读取的数据有多种格式,如EXCEL、*.dbf、ASC Ⅱ数据文件等,并能直接将该类数据转换为SPSS 能分析的数据。
SPSS 由于其界面简单易学习操作且输出结果可读性强的优点,现已广泛应用于经济学、医疗卫生、数学、统计学等众多领域。
此外,由于SPSS 软件统计分析功能强大且简单易学,对非统计专业的学生来讲使用较为简单,因此在全国大学生数学建模竞赛中如果有统计类的题目,学生选择SPSS 作为统计分析软件成为必然之举。
二、2012年全国大学生数学建模竞赛C 题简述为了分析得出脑中风高危人群具有的明显症状,以及所处的坏境对该病的高危人群的影响,原题以附件形式给出了脑中风病人的详细信息,要求建立数学模型对脑卒中的发病人群进行统计描述并研究脑中风发病率与相对湿度、气温、气压间的关系。
通过对该题的分析,此题为典型的统计类问题,故可利用SPSS 软件求解。
三、SPSS 在数学建模竞赛中的应用(一)数据录入附件所给数据格式为“.xls”,可利用SPSS 读取其他格式数据的方法,选择“File”->“Open”->“Data”,在打开的对话框中选择数据所在正确位置,并将“文件类型”选为“Excel(*.xls)”,选择要导入的数据文件,点击“打开”,在弹出的对话框中选择合适的选项,如是否从源文件中读取变量名称、数据录入区域等。
以数学建模竞赛为例基于SPSS建立ARIMA模型ARIMA模型是一种经典的时间序列分析方法,可用于分析和预测时间序列数据的趋势和周期性。
它结合了自回归(AR),差分(I)和移动平均(MA)三种技术,适用于非平稳时间序列数据的分析和预测。
在本文中,我们将以数学建模竞赛中的一个具体问题为例,介绍如何使用SPSS软件建立ARIMA模型,并进行数学建模分析,以解决问题。
问题描述假设某个城市的人口数量从1990年开始统计至今,我们需要通过已知的人口数量数据,建立一个模型来预测未来该城市的人口增长趋势。
数据处理我们需要收集并整理相关的人口数量数据。
通常,这些数据可以从政府或统计局的公开数据中获得。
假设我们已经获得了从1990年到2020年的人口数量数据,接下来我们将使用SPSS软件对这些数据进行分析和建模。
数据分析在SPSS软件中,我们首先需要导入已经收集好的人口数量数据,并进行数据的观察和初步分析。
通过查看数据的趋势和波动性,我们可以初步判断是否属于时间序列数据,并对数据进行初步的处理和分析。
接下来,我们可以使用SPSS软件中的时间序列分析功能,对数据进行进一步分析。
我们可以使用ARIMA模型来分析数据的趋势和周期性,并预测未来的发展趋势。
具体步骤如下:1. 导入数据:在SPSS软件中,选择导入数据,并选择已经整理好的人口数量数据文件进行导入。
2. 检验数据:通过查看数据的时间序列图和自相关性图,初步判断数据是否具有自相关性和趋势性,以确定是否适合使用ARIMA模型进行分析。
3. 拟合模型:选择合适的ARIMA模型,对数据进行拟合和参数估计,以确定数据的自相关性、差分阶数和移动平均阶数等参数。
4. 检验模型:对拟合的ARIMA模型进行残差检验和模型诊断,判断模型的拟合效果和预测精度。
5. 预测未来:通过拟合好的ARIMA模型,可以对未来的人口数量进行预测,得出未来的人口增长趋势和波动范围。
模型建立根据我们所收集到的人口数量数据,我们可以按照上述步骤在SPSS软件中建立ARIMA 模型,以预测未来该城市的人口数量。
以数学建模竞赛为例基于SPSS建立ARIMA模型【摘要】本文主要介绍了以数学建模竞赛为例,利用SPSS建立ARIMA模型的方法。
在背景介绍中,讨论了数学建模竞赛的重要性和研究意义。
在首先概述了数学建模竞赛的基本特点,然后介绍了SPSS软件的基本功能,接着详细解释了ARIMA模型的原理。
在基于SPSS建立ARIMA 模型的步骤中,说明了具体的操作流程,并通过实例分析展示了其应用效果。
在讨论了ARIMA模型在数学建模竞赛中的应用前景,并对全文进行了总结。
本文通过理论和实践相结合的方法,为使用ARIMA模型进行数学建模竞赛提供了一定的参考和指导。
【关键词】数学建模竞赛、SPSS、ARIMA模型、建立模型、实例分析、应用前景、总结1. 引言1.1 背景介绍在接下来的内容中,我们将详细介绍数学建模竞赛的概述、SPSS软件的介绍、ARIMA模型的原理、基于SPSS建立ARIMA模型的步骤以及实例分析,来探讨ARIMA模型在数学建模竞赛中的应用前景。
1.2 研究意义数目要求、格式要求等。
以下是关于的内容:基于SPSS建立ARIMA模型在数学建模竞赛中的应用具有重要的意义。
ARIMA模型是一种能够使用时间序列数据对未来进行预测的方法,能够更准确地预测未来的走势和变化趋势。
将ARIMA模型与SPSS软件相结合,可以更高效地进行数据分析和建模,为数学建模竞赛提供更加可靠和有效的解决方案。
研究如何基于SPSS建立ARIMA 模型在数学建模竞赛中的应用具有重要的意义和价值,对于提高数学建模竞赛的参赛水平和竞争力具有积极的推动作用。
2. 正文2.1 数学建模竞赛概述数学建模竞赛是一种培养学生科学建模能力的竞赛形式,旨在通过给定的问题和数据,参赛者利用数学方法进行建模和求解。
数学建模竞赛的题目通常来源于实际问题,涉及到各个领域,如经济、环境、医学等。
参赛者需要深入理解问题背景,提出合理的假设,采集、处理和分析数据,最终给出可行的解决方案。
以数学建模竞赛为例基于SPSS建立ARIMA模型数学建模竞赛是一种学生利用数学方法和技巧解决实际问题的比赛形式,它旨在培养学生的数学建模能力和创新意识。
在数学建模竞赛中,参赛队伍通常需要根据提供的真实数据,通过建立数学模型来预测未来的趋势和变化。
时间序列分析是数学建模竞赛中常用的方法之一,而ARIMA模型则是时间序列分析中的经典模型之一。
本文将以数学建模竞赛为例,基于SPSS软件建立ARIMA模型,展示其在实际问题中的应用。
一、数学建模竞赛及其意义数学建模竞赛是在激发学生对数学的兴趣和学习热情的培养他们的数学建模能力和创新意识的一种有效途径。
通过竞赛形式,学生们能够在实际问题中应用所学的数学知识和技巧,从而提高解决实际问题的能力。
数学建模竞赛也为学生提供了展示自己才华的舞台,激发了他们的学习动力和创新潜力。
二、ARIMA模型简介ARIMA模型是一种常用的时间序列分析方法,其全称为自回归积分移动平均模型(Autoregressive Integrated Moving Average Model)。
ARIMA模型主要用于分析时间序列数据的趋势和周期性变化,能够帮助人们预测未来的趋势和变化。
ARIMA模型包括自回归项(AR项)、差分项(I项)、移动平均项(MA项)三个部分,分别代表了时间序列数据的自相关、趋势和随机性成分。
通过调整这些参数,可以建立不同的ARIMA模型来描述和预测时间序列数据。
三、基于SPSS建立ARIMA模型的步骤SPSS是一种常用的统计分析软件,其强大的数据处理和分析功能使得建立ARIMA模型变得简单可行。
下面将介绍基于SPSS建立ARIMA模型的步骤:1. 数据准备:需要准备好要分析的时间序列数据,确保数据完整、准确和连续。
在SPSS中,可以选择“导入数据”功能将数据导入软件中进行后续分析。
2. 检查时间序列数据的平稳性:在建立ARIMA模型之前,需要对时间序列数据进行平稳性检验。
1.偏度(skewness)
g1 0,则可以认为分布是对称的;若g1>0,则认为分布有右偏态;若g1<0,认为分布有左偏态
2.峰度(kurtosis)
它以正态分布为标准,比较两侧极端数据分布的情况。
对于正态分布有g2=0;若g2>0,表示数据中有较多远离均值的极端数据;若g2<0,则均值两侧极端数据较少。
1命令位置:分析\描述统计\频率(Frequencis)\统计量(Statistics)
适合求分位点,一般情况下是首选命令
2.分析\描述统计\描述统计(Descriptive)
此命令可以完成数据的标准化,并把结果以变量的形式存放在数据文件上
Z分数一般小数可以先行转化为T分数
操作:转换(transform)→计算变量
是否服从正态分布
方法:
⏹定性方法
⏹观察偏度和峰度
⏹画直方图
⏹QQ图:散点基本在直线上,可以认为服从正态分布
⏹可靠方法:单样本KS检验
操作:图形->旧对话框
3.假设检验的步骤
提出原假设(零假设)H0;
确定适当的检验统计量;
计算检验统计量的值发生的概率(P值);
给定显著性水平a;
作出统计决策。
注:
必须搞清楚原假设(零假设)是什么
应该知道检验所用统计量服从什么分布
会根据软件求得的p值(sig.),作出判断
即:p<0.05,拒绝原假设;
P>0.05, 接受原假设.
4.单样本KS检验法:单样本KS检验-非参方法
操作:分析――>非参数检验――>旧对话框
5.列联表分析:判明所考察的各属性之间有无关联,即是否独立。
(利用交叉表分析)
转化为一个假设检验问题,构造检验统计量卡方
1)设置权重变量!
数据\加权个案
操作:分析->描述统计->交叉表->统计量->卡方
6.1均值比较
单样本t检验:目的:检验单个变量的均值是否与给定的常数(总体均值)之间是否存在显著差异。
要求样本来自的总体服从或近似服从正态分布。
H0:总体均值和指定检验值之间不存在显著差异。
⏹两独立样本t检验:目的:利用来自两个总体的独立样本,推断两个总体的均值是否存在显著
性差异;样本来自的总体服从或近似服从正态分布,H0:两总体均值之间不存在显著差异
Analyze――>compare――>independent-sample t test――>
两配对样本t检验:根据样本数据对样本来自的两配对总体的均值是否有显著性差异进行推断。
要求:1.两个样本应是配对的,首先两个样本的观察数目相同,其次两样本的观察值顺序不能随意改变。
2.样本来自的两个总体应服从正态分布。
操作:操作到pared-samples t test 对话框paiedvariables
7。
方差分析(NAOV A):用于两个及两个以上样本均数差别的显著性检验。
方差分析中的有关术语
1. 因素或因子(factor)
所要检验的对象
要分析颜色对销量是否有影响,颜色是要检验的因素或因子
2. 水平或处理(treatment)
因子的不同表现
如,四种颜色就是因子的水平
3. 观察值
在每个因素水平下得到的样本值
每种颜色的销量就是观察值
7.1单因素方差分析
•前提的检验:各水平下方差齐性检验
•实现方法:option中的statistics:Homogeneity-of-variance——检验各水平下各总体方差是否齐性.
1单因素方差分析中的多重比较:目的:多重比较将对每个水平的均值逐对进行比较检验.
2几种常用的多重比较方法
1.LSD(Least significant Difference)最小显著性差异法
2.特点:
利用了全部样本数据,而不仅是所比较的两组的数据,且认为各水平均是等方差的
与其他方法相比,其检验敏感度最高
在一定程度上克服了放大犯一类错误的问题
2. S-N-K法:运用最广泛的一种两两比较方法,采用student range分布进行所各组的组间均值的配对比较控制了一类错误post hoc选项
如果事先无法判断方差是否具有齐性,可以考虑都选上,从结果中选择应用。
Lsd法,tukey法,scheffe法,tamhane‘s t2法
1单因素方差分析步骤:分析――>比较均值――>单因素ANOV A (选项一定选方差同质性检验)
多重比较方差分析的步骤:(选两两比较中lsd选项和S-N-K)
8.相关分析与回归
8.1相关分析:0<r≤1,正。
−1≤r<0,负|r|=1,两者函数关系。
|r|>=0.8时,视为高度相关,0.5<=|r|<=0.8,中度相关。
0.3<=|r|<=0.5时,视为低度相关。
|r|<0.3时,视为不相关。
在二元变量的相关分析过程中比较常用的几个相关系数是
Pearson简单相关系数、用来衡量定距变量间的线性关系
Spearman
Kendall's tua-b等级相关系数。
Spss中的实现过程:先画散点图再做相关分析
8.2 回归分析
• 1 回归分析概述
• 2 线性回归分析
1确定回归方程中的解释变量(自变量)和被解释变量(因变量)2确定回归方程3对回归方程
进行各种检验4利用回归方程进行预测。
2.3 线性回归方程的统计检验,
一、回归方程的拟合优度
2、可决系数(判定系数、决定系数)
R 称为复相关系数(恰好是Pearson 相关系数的绝对值), R 或R 2是一个从直观
上判断回归方程拟合好坏的尺度,有0≤R ≤1,显然R 值越大,回归方程拟合越好。
一元—R 2 多元—调整的R 2
多元回归
● 二、回归方程的显著性检验(F 检验)多元回归f 检验~p 1F n p --(,)
利用方差分析F 检验,H0: β1=β2=…=βk =0H0: β1=β2=…=βk =0,(意:回归方程不显著)
● 三、回归系数的显著性检验(t 检验)
t 检验,(微观分析)
H0:βj =0(即变量X j 不显著) H1:βj ≠ 0
以上属于回归分析基本检验;
另有进一步检验:
如多元回归中的残差分析、多重共线性
检验等,待续…
● 四、残差分析
1残差分析包括以下内容:
2残差服从均值为零的正态分布(正态检验诊断)
3残差方差相等(方差齐性诊断)
4残差不存在自相关(残差独立性诊断)
5探测样本中的异常值(自学)
注:对于残差均值和方差齐性检验可以利用残差图进行分析。
1.残差均值为零的正态性诊断
残差的正态性诊断可以通过直方图和P -P 正态概率图来实现,当P -P 图基本成一直线时,
正态性诊断通过。
2.残差的方差齐性诊断
通过分析标准化预测值(X 轴)——学生化残差(Y 轴)散点图来实现。
当图中各点分布没有明显的规律性,即残差的分布不随预测值的变化而增大或减小时,(或图中各点在纵轴零点对应的直线下基本均匀分布),因此可以认为方差齐性的假设成立。
3、残差独立性诊断-常用DW 检验
DW=2表示无自相关,在0-2之间说明存在正自相关,在2-4之间说明存在负的自相关。
一般情况下,DW 值在1.5-2.5之间即可说明无自相关现象。
五、多元回归分析的解释变量筛选问题
变量的筛选一般有向前筛选、向后筛选、逐步筛选三种基本策略。
在对话框Linear Regession 分别是 Forward ,Backword 和Stepwise 三种方法
六、多元回归分析的多重共线性分析
1容忍度:容忍度的取值范围在0-1之间,越接近0表示多重共线性越强,越接近1表示多重共线性越弱。
2方差膨胀因子VIF ;方差膨胀因子是容忍度的倒数。
VIF 越大多重共线性越强,当VIF 大于等于10时,说明存在严重的多重共线性。
● 五、多重共线性
• 3 曲线估计
回归分析小结。