SPSS-非参数检验—两独立样本检验_案例解析
- 格式:doc
- 大小:194.50 KB
- 文档页数:5

SPSS两个独立样本秩和检验操作步骤SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,可用于执行各种统计分析操作,包括独立样本秩和检验。
独立样本秩和检验是一种非参数检验方法,用于比较两个独立样本的中位数是否存在差异。
以下是在SPSS中执行独立样本秩和检验的操作步骤:1.打开SPSS软件,并导入相关数据。
- 单击"File"选项卡,然后选择"Open"选项,以选择要导入的数据文件。
-在导入数据文件之前,确保数据文件符合SPSS格式要求。
2.在SPSS中创建秩和检验数据。
- 单击"Transform"选项卡,然后选择"Rank Cases"选项,以创建秩和检验所需的秩序变量。
- 在弹出的"Rank Cases"对话框中,选择要进行秩和检验的变量,并为新的秩序变量指定名称。
-单击"OK"按钮以创建秩序变量。
3.执行秩和检验。
- 单击"Analyze"选项卡,然后选择"Nonparametric Tests"选项,以访问非参数测试工具。
- 在"Nonparametric Tests"子菜单中,选择"Legacy Dialogs"选项,以显示传统对话框。
- 在传统对话框中,选择"2 Independent Samples"选项,以执行独立样本秩和检验。
- 在弹出的"2 Independent Samples"对话框中,选择要进行秩和检验的变量,并将其添加至"Test Variables"框中。
- 单击"Options"按钮以访问进一步的选项。
在"Options"对话框中,您可以选择计算效应大小指标等。

spss-非参数检验-K多个独立样本检验
(Kruskal-Wallis检验)案例解析Kruskal-Wallis检验,也称为KW检验,是一种非参数检验方法,用于比较两个或多个独立样本的中位数是否相等。
它利用秩(等级)来进行统计分析,而不是直接使用原始数据。
假设有一个关于人们在不同饮料中的品尝体验的数据集。
数据集中包含了人们在红酒、白酒和啤酒中品尝的感受,包括甜度、酸度、苦度等。
现在想要比较这三种饮料在甜度方面的中位数是否有显著差异。
首先,对每种饮料的甜度进行排序,得到每个人的秩。
然后,将每个人的秩平均分到他们所对应的饮料中,得到每个饮料的平均秩。
接着,对这些平均秩进行比较。
如果红酒、白酒和啤酒的平均秩存在显著差异,则说明这三种饮料在甜度方面的中位数存在显著差异。
如果平均秩没有显著差异,则说明这三种饮料在甜度方面的中位数没有显著差异。
下面是一个具体的案例数据:
根据上述数据,我们可以计算出每种饮料的平均秩:
红酒: (2+1)/2 = 1.5
白酒: (4+3)/2 = 3.5
啤酒: (6+5)/2 = 5.5
然后对这些平均秩进行比较。
由于红酒的平均秩最小,白酒的平均秩次之,啤酒的平均秩最大,因此可以得出结论:这三种饮料在甜度方面的中位数存在显著差异,其中啤酒的甜度最高,白酒次之,红酒最低。
需要注意的是,KW检验的前提假设是各个样本是独立同分布的,且样本容量足够大。
如果样本不满足这些条件,可能会导致检验结果出现偏差。
此外,KW检验只能告诉我们是否存在显著差异,但不能告诉我们差异的具体原因。
如果想要了解更多信息,需要进行后续的统计分析。

---------------------------------------------------------------最新资料推荐------------------------------------------------------
SPSS学习之——两独立样本的非参数检验
(Mann-Whitney U
SPSS 学习笔记之两独立样本的非参数检验( Mann-Whitney U 一、概述Mann‐WhitneyU 检验是用得最广泛的两独立样本秩和检验方法。
简单的说,该检验是与独立样本 t 检验相对应的方法,当正态分布、方差齐性等不能达到 t 检验的要求时,可以使用该检验。
其假设基础是:
若两个样本有差异,则他们的中心位置将不同。
二、问题为了研究某项犯罪的季节性差异,警察记录了 10 年来春季和夏季的犯罪数量,请问该项犯罪在春季和夏季有无差异。
下面使用Mann‐WhitneyU 检验进行分析。
SPSS 版本为 20。
三、统计操作SPSS 变量视图:
SPSS 数据视图:
进入菜单如下图:
点击进入如下的界面,目标选项卡不需要手动设置进入字段选项卡,将报警数量选入检验字段框,将季节选入组框中。
再进入设置选项卡,选中自定义检验单选按钮,选择Mann‐WhitneyU(二样本)检验。
1 / 2
点击运行即可。
四、结果解读这是输出的主要结果,零假设是报警数量的分布在季节类别上相同,其 P=0.0090.05,故拒绝原假设,认为报警数量在季节上有统计学差异。
双击该表格,可以得到更多的信息,不再叙述。

SPSS非参数检验—两独立样本检验_案例解析非参数检验是一种在统计学中常用于比较两个或多个独立样本的方法。
与参数检验不同,非参数检验不需要对数据的分布进行假设,并且适用于非正态分布的数据。
SPSS(统计软件包for社会科学)是一个广泛使用的统计分析软件,它提供了许多非参数检验的功能。
本文将以一个案例为例,解析如何使用SPSS进行两独立样本的非参数检验。
案例描述:一家公司正在评估一个新的培训课程对员工的绩效是否有显著影响。
为了评估培训课程的效果,研究人员随机选择了两组员工,一组接受了培训课程(实验组),另一组没有接受培训课程(对照组)。
研究人员想要比较两组员工在绩效上的差异。
步骤一:导入数据首先,将实验组和对照组的数据分别导入SPSS中。
假设每个样本中有n个观测值。
在SPSS中,每一组数据应该是一个独立的变量(或列),并且每个观测值应该占据矩阵中的一个单元格。
步骤二:选择非参数检验方法在SPSS中,可以使用Mann-Whitney U检验来比较两组独立样本的绩效差异。
该检验的原假设是两组样本来自同一个总体,备择假设是两组样本来自不同的总体。
步骤三:运行非参数检验在SPSS的菜单栏中,依次选择"分析" - "非参数检验" - "独立样本检验(Mann-Whitney U)"。
将实验组和对照组的变量分别输入到"因子1"和"因子2"中。
在"可选"选项中,可以选择在报告中包含各种统计量。
步骤四:解读结果SPSS将输出很多统计信息,包括推断统计、置信区间、效应大小等。
其中,最重要的是U值和显著性。
U值是用来检验两组样本是否来自同一个总体的统计量,显著性则是用来判断差异是否显著。
如果显著性小于0.05,则可以拒绝原假设,认为两组样本在绩效上存在显著差异。
总结:通过上述步骤,我们可以利用SPSS进行两独立样本的非参数检验。

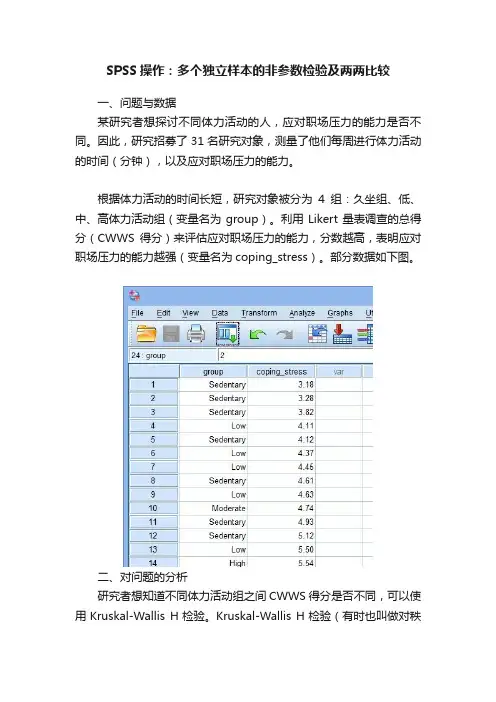
SPSS操作:多个独立样本的非参数检验及两两比较一、问题与数据某研究者想探讨不同体力活动的人,应对职场压力的能力是否不同。
因此,研究招募了31名研究对象,测量了他们每周进行体力活动的时间(分钟),以及应对职场压力的能力。
根据体力活动的时间长短,研究对象被分为4组:久坐组、低、中、高体力活动组(变量名为group)。
利用Likert量表调查的总得分(CWWS得分)来评估应对职场压力的能力,分数越高,表明应对职场压力的能力越强(变量名为coping_stress)。
部分数据如下图。
二、对问题的分析研究者想知道不同体力活动组之间CWWS得分是否不同,可以使用Kruskal-Wallis H检验。
Kruskal-Wallis H检验(有时也叫做对秩次的单因素方差分析)是基于秩次的非参数检验方法,用于检验多组间(也可以是两组)连续或有序变量是否存在差异。
使用Kruskal-Wallis H test进行分析时,需要考虑以下3个假设。
假设1:有一个因变量,且因变量为连续变量或等级变量。
假设2:存在多个分组(≥2个)。
假设3:具有相互独立的观测值,如本研究中各位研究对象的信息都是独立的,不存在相互干扰作用。
三、SPSS操作1. Kruskal-Wallis H检验在主界面点击Analyze→Nonparametric Tests→Independent Samples,出现Nonparametric Tests: Two or More Independent Samples对话框,默认选择Automatically compare distributions across groups。
点击Fields,在Fields下方选择Use custom field assignments,将变量coping_stress放入Test Fields框中,将变量group放入Groups框中。
点击Settings→Customize tests,在Compare MedianDifference to Hypothesized区域选择Kruskal-Wallis 1-way ANOVA (k samples),如下图。

实验报告——(非参数检验)实验目的:1、学会使用SPSS软件进行非参数检验。
2、熟悉非参数检验的概念及适用范围,掌握常见的秩和检验计算方法。
实验内容:1、某公司准备推出一个新产品,但产品名称还没有正式确定,决定进行抽样调查,在受访200人中,52人喜欢A名称,61人喜欢B名称,87人喜欢C 名称,请问ABC三种名称受欢迎的程度有无差别?(数据表自建)SPSS计算结果如下:此题为总体分布的卡方检验。
零假设:样本来自总体分布形态和期望分布没有显著差异。
即ABC三种名称受欢迎的程度无差别,分布形态为1:1:1,呈均匀分布。
观察结果,上表为200个观察数据对A、B、C三个名称(分别对应1,2,3)的喜爱的期望频数以及实际观察频数和期望频数的差。
从下表中可以看出相伴概率值为0.007小于显著性水平0.05,因此拒绝零假设,认为样本来自的总体分布与制定的期望分布有显著差异,即A、B、C三种名称受欢迎的程度有差异。
2、某村庄发生了一起集体食物中毒事件,经过调查,发现当地居民是直接饮用河水,研究者怀疑是河水污染所致,县按照可疑污染源的大致范围调查了沿河居民的中毒情况,河边33户有成员中毒(+)和均未中毒(-)的家庭分布如下:(案例数据run.sav)-+++*++++-+++-+++++----++----+----毒源问:中毒与饮水是否有关?SPSS计算结果如下:此题为单样本变量值随机检验零假设:总体某变量的变量值是随机出现的。
即中毒的家庭沿河分布的情况随机分布,与饮水无关。
相伴概率为0.036,小于显著性水平0.05,拒绝零假设,因此中毒与饮水有关。
3、某试验室用小白鼠观察某种抗癌新药的疗效,两组各10只小白鼠,以生存日数作为观察指标,试验结果如下,案例数据集为:npara1.sav,问两组小白鼠生存日数有无差别。
试验组:24 26 27 30 32 34 36 40 60 天以上对照组:4 6 7 9 10 10 12 13 16 16SPSS计算结果如下:此题为两独立样本非参数检验。
操作方法
01
首先需要输入数据,t检验数据的输入格式为区别为一列,数值为一列。
02
接下是做正态性检验。
首先需要拆分文件,对两组数据分别做检验。
即数据——拆分文件
03
然后点一下比较组,把组别调入分组方式这里,再点击确定。
这样就拆分完毕了。
04
继续点分析——非参数检验——旧对话框——1-样本K-S
05
这样就弹出了正态性检验的对话框,将需要分析的数值调入右边的框框,然后勾选上下方检验分布的第一个,正态(也写为常规,一般默认已经勾上),然后点击确定(数值调入右边后,确定键变为可用)
06
查看结果,第一组的正态性检验P=0.798,第二组为P=0.835,可认为近似正态分布。
07
接着取消拆分。
数据——拆分文件,在跳出来的框框中点一下第一个(分组所有组),然后点确定
08
然后点分析——比较均值——独立样本t检验
09
将组别调入分组变量,数值调入检验变量
10
接着点一下分组变量下方的定义组,在弹出来的框框中输入组别1、2,再点继续——确定
11
结果出来了。
第一个表格是两组数据的例数、均值、标准差和均数的标准误。
第二个表格前部是方差齐性检验,可看到P=0.141>0.05,具有方差齐性,
然后t检验的P值为0.007,可认为差异有统计学意义。



两独立样本T检验SPSS操作详解以下是步骤详解:1.打开SPSS软件,并导入数据文件。
在“文件”菜单中选择“打开”选项,浏览并选择你的数据文件,并点击“打开”。
数据文件需要包含两组要比较的两个变量。
2.选择菜单中的“分析”选项,然后选择“比较均值”子选项,再选择“独立样本T检验”。
3.在弹出的独立样本T检验对话框中,将你要比较的两个变量移动到变量框中。
其中一个变量移动到“依赖变量”框中,另一个变量移动到“提取组变量”框中。
4.点击“定义组”按钮,在出现的对话框中输入两个组的编号,并点击“添加”按钮。
然后关闭“定义组”对话框。
5.在独立样本T检验对话框中,确定其他参数,如显著性水平(默认为0.05)和描述统计量选项。
6.点击“确定”按钮运行分析。
SPSS将计算出两组的均值、标准差、样本大小等统计量,并给出T值、自由度和显著性水平。
7.分析结果将显示在输出窗口的“独立样本T检验”表中。
主要关注的结果包括均值差异、T值、自由度和显著性水平。
8.可以根据需要导出分析结果。
在输出窗口中选择你感兴趣的表格或图表,然后在菜单中选择“文件”选项,再选择“另存为”选项,将分析结果保存为你想要的格式。
需要注意的是,在进行两独立样本T检验之前,要确保数据满足T检验的假设:两组样本是独立的、来自正态分布总体和方差齐性。
如不满足这些假设,可以考虑使用非参数检验或进行数据转换。
此外,对于SPSS软件的具体操作细节可能会因软件版本而有些差异,但基本的步骤和参数设置是相同的。
以上就是两独立样本T检验SPSS操作的详解。
通过SPSS软件进行数据分析可以更方便地得到结果,并为研究者提供科学依据。
SPSS非参数检验—两独立样本检验_案例解析非参数检验是一种不基于总体分布特征的统计方法,适用于数据分布未知、非正态分布或无法满足参数检验假设的情况。
其中一种非参数检验是两独立样本检验,用于比较两组独立样本之间的统计差异。
本篇文章将结合案例解析,详细介绍SPSS软件中如何进行非参数检验的两独立样本检验。
案例背景:工厂生产两种不同形状的零件,为了比较两种零件的尺寸是否存在差异,随机选取了30个零件进行测量。
现在需要使用两独立样本检验来研究这两种零件的尺寸是否存在显著差异。
步骤一:数据导入首先,将收集到的数据导入SPSS软件中。
数据包括两个变量:零件类型(Group)和尺寸(Size)。
将数据按照Excel或CSV格式保存,然后在SPSS中选择"文件"->"导入"->"数据",选择导入文件,并进行数据格式定义。
步骤二:描述性统计分析在进行假设检验之前,首先进行描述性统计分析,以了解样本数据的基本特点。
在SPSS中,选择"分析"->"描述性统计"->"描述性统计",将"Size"变量拖入"变量"框中,然后点击"统计"按钮,选择要统计的统计量(如均值、标准差等),最后点击"确定"按钮进行计算。
步骤三:正态性检验在进行非参数检验之前,需要进行正态性检验,以确定数据是否满足参数检验的假设。
在SPSS中,选择"分析"->"非参数检验"->"单样本分布检验",将"Size"变量拖入"变量"框中,然后点击"选项"按钮,选择要进行的正态性检验方法,如Kolmogorov-Smirnov检验或Shapiro-Wilk检验等。
两独立样本非参数检验在统计学的领域中,两独立样本非参数检验是一种重要的分析方法,它为我们在处理不同样本数据时提供了有力的工具。
那么,什么是两独立样本非参数检验呢?简单来说,就是在我们研究两个相互独立的样本,且这些样本的数据不符合正态分布或者我们不知道其分布形态时,所采用的一类检验方法。
为什么我们会需要这种检验方法呢?想象一下这样的场景,我们想要比较两个不同地区的居民收入水平。
但是,经过初步观察,发现这些收入数据的分布并不规则,不像是常见的正态分布。
这时候,如果我们强行使用基于正态分布假设的参数检验方法,很可能会得出错误的结论。
所以,两独立样本非参数检验就派上用场了。
常见的两独立样本非参数检验方法有很多,比如曼惠特尼 U 检验、威尔科克森秩和检验以及克瓦氏 H 检验等。
先来说说曼惠特尼 U 检验。
它的基本思想是将两个样本混合起来进行排序,然后分别计算每个样本的秩和。
通过比较这两个秩和的差异,来判断两个样本是否来自同一个总体。
假设我们有两个样本 A 和 B,样本 A 包含{12, 15, 18, 20, 25},样本 B 包含{10, 13, 16, 19, 22}。
首先,我们把这两个样本混合起来,从小到大排序:{10, 12, 13, 15, 16, 18, 19, 20, 22, 25}。
然后,给每个数据赋予秩,最小的数秩为 1,次小的数秩为 2,以此类推。
得到秩之后,计算样本 A 的秩和以及样本 B的秩和。
最后,根据相应的公式和统计量,判断两个样本是否有显著差异。
威尔科克森秩和检验呢,与曼惠特尼 U 检验有些相似,但它更侧重于关注两个样本中数据的相对大小关系。
还是用刚才的例子,如果在威尔科克森秩和检验中,我们会计算样本 A 中每个数据大于样本 B 中数据的个数,以及样本 B 中每个数据大于样本 A 中数据的个数,从而得出检验结果。
克瓦氏 H 检验则适用于多组独立样本的情况。
比如我们要比较三个不同城市居民的收入水平,就可以用克瓦氏 H 检验。
SPSS20.0实现多个独立样本非参数检验后两两比较
SPSS---分析---非参数检验---独立样本(I)...
在出现的名为“非参数检验:两个或更多独立样本”的对话框里,点击“字段”选项卡。
在出现的画面中把要检验的变量放入右边的“检验字段(T)”文本框里,把分组变量
放入其下面的“组(G)”里。
点击“运行”按钮即可。
在输出的结果中,双击“假设检验汇总”图表,在出现的模型浏览器里的右下角的“视图”的
右边下拉菜单里,选中其中的“成对比较”,结果就会出现两两的非参数检验的比较的结果。
注:
①分组变量(G)变量类型(度量标准)需定义为“序号”或“名义”
变量;
②两两比较方法:Mann-Whitney U检验?。
SPSS两独立样本T检验结果解析SPSS中的两独立样本T检验是一种用于比较两个独立样本均值是否存在显著差异的统计方法。
在进行T检验时,SPSS会提供多个结果和统计指标,以下将对这些结果进行详细解析。
1.描述统计:首先,SPSS提供了每个样本的基本统计描述,包括样本均值(Mean)、标准差(Standard Deviation)、样本大小(N)等。
这些统计指标可以帮助我们了解样本的基本情况,并对比两个样本的差异。
2.正态性检验:T检验的前提是两个样本都满足正态分布。
SPSS会进行正态性检验,提供Shapiro-Wilk和Kolmogorov-Smirnov两种方法。
若p值大于显著性水平(通常是0.05),则我们可以认为数据满足正态分布假设;若p值小于显著性水平,则我们需谨慎解释数据结果,并可以采用非参数检验方法。
3.方差齐性检验:T检验还要求两个样本的方差齐性。
SPSS提供Levene's Test和Brown-Forsythe两种方差齐性检验方法。
若p值大于显著性水平,我们可以认为两个样本具有方差齐性;若p值小于显著性水平,则需要调整我们对于T检验结果的解释,例如使用修正的T检验方法。
4.独立样本T检验结果:SPSS提供了多个独立样本T检验的结果,包括T值、自由度、双侧p 值、置信区间等。
其中T值表示两个样本均值之间的差异是否显著,自由度用于计算T分布的临界值,p值则用于判断差异是否具有统计学意义,置信区间则给出了均值差异的范围估计。
通常,p值小于显著性水平(例如0.05)可以认为两个样本的均值存在显著差异。
5.效应量指标:除了上述的结果,SPSS还提供了一些效应量指标,可以帮助评估均值差异的大小。
其中,Cohen's d是一种常用的效应量指标,表示两个样本均值差异的标准化大小。
Cohen's d的值越大,表示两个样本的均值差异越大。
6.异常值和离群值:最后,SPSS还可以通过箱线图和散点图等方法帮助我们检查两个样本中是否存在异常值或离群值。
非参数检验的SPSS操作前面一章介绍的二项分布的比率检验、配合度检验——卡方检验和1-Sample K-S检验等都属于非参数检验。
这一节我们主要结合前面参数假设检验一章讲过的t检验以及方差分析一章讲过的方差分析,来进一步分析,当参数检验的前提条件不满足时,两个样本和多个样本平均数差异的SPSS操作方法。
一、两个独立样本的差异显著性检验两独立样本的的差异显著性检验只有在满足如下条件时才能进行T检验:变量为正态分布的连续测量数据。
若数据不满足这样的条件,强行进行T检验容易造成错误的结论。
在数据不能满足这种参数检验的条件下,我们可以选择非参数检验方法进行。
与两独立样本差异显著性检验相对应的方法可以在SPSS主菜单Analyze / Nonparametric Tests / 2 Independent Samples…中得到。
1.数据采用本章第一节中例2的数据(数据文件“9-4-1.sav”),具体介绍操作过程。
2.理论分析对于数据文件9-4-1.sav中的数据,目的是检验男女生之间注意稳定性是否存在显著差异,注意稳定性测量的结果虽然是测量数据但是从总体上来看不满足正态分布的前提假设,另外不同性别的学生可以看成是两组独立的样本,因此对上述资料的检验可以用非参数的独立样本的检验方法。
2.操作过程(1)在SPSS主菜单中选择Analyze / Nonparametric Tests / 2 Independent Samples…得到两个独立样本非参数检验的主对话框(图9-1),把因变量atten选入到检验变量表列(Test Independent-SampleTests)中去,把gender选到分组变量(Grouping Variable)中,并单击Define Groups…,在随后打开的对话框中分别键入1与2,单击Continue回到主对话框如图9-1所示。
在Test Type中有四个可选项,其中最常用的是第一种方法Mann-Whitney U(又称秩和检验法)。
SPSS-非参数检验—两独立样本检验案例解析
2011-09-16 16:29
好想睡觉,写一篇博文,希望可以减少睡意,今天跟大家研究和分享一下:spss非参数检验——两独立样本检验,
我还是引用教程里面的案例,以:一种产品有两种不同的工艺生产方法,那他们的使用寿命分别是否相同
下面进行假设:1:一种产品两种不同的工艺生产方法,他们的使用寿命分布是相同的
2:一种产品两种不同的工艺生产方法,他们的使用寿命分布是不相同的
我们采用SPSS进行分析,数据如下所示:
点击“分析”选择“非参数检验” 再选择“旧对话框——2个独立样本检
验如下所示:
在检验类型下面选择"Mann-Whitney U “ 检验类型(Mann-whitney u 检验等同于对两组数据的Wilcoxon秩和检验和Kruskal-Wallis检验,主要检验两个样本的总体在某些位置上是否相等。
)
两种工艺类型分别为:甲种工艺和乙种工艺分别用定义值为“1” 和
“2”将“工艺类型”变量拖入“分组变量”下拉框内,点击“定义组”按钮,在组别1 和组别 2 中分别填入 1和2,点击继续按钮
选择“使用寿命”作为“检验变量”点击确定,得到分析结果如下:
下面对结果,我将进行详细分解:
1:N 代表变量个数,甲种工艺秩和为 80
乙种工艺秩和为 40,
下面来分析“秩和”这个结果如何出来的
第一步:我们将”使用寿命“这个变量按照“从小到大”的顺序进行排序,得到如下结果:
得到数据如下:
甲种工
艺: 661 669 675 679 682 692 693
乙种工艺:
646 649 650 651 652 662 663 672
我们将“甲种工艺”和“乙种工艺”两组数据进行合并排序,并且对两组数据进行“秩次排序”分别用“序号”代替以上数据
序号分别为:
1 2 3 4 5 6 7 8
9 10 11 12 13
14 15
得到以下结果:
甲种工艺为:
6 9 11 12 13 14 15 (加起来刚好等于80)
乙种工艺为:
1 2 3 4 5 7 8 10
(加起来刚好等于40)
结果得到了验证
2:“在检验统计量B ”表中可以看出:
1:渐进显著性和“单侧显著性”(精确显著性“ 都分别小于 0.05,所以可以得出结论:
一种产品两种不同的工艺生产方法,他们的使用寿命分布是不相同的
大家可以采用其它“检验类型”来进一步验证这个结论
Mann-Whitney U 统计值可以通过以下计算公式得到:。