第三章 多元统计分析(3)
- 格式:doc
- 大小:482.00 KB
- 文档页数:16


多元统计分析第三章假设检验与⽅差分析第3章多元正态总体的假设检验与⽅差分析从本章开始,我们开始转⼊多元统计⽅法和统计模型的学习。
统计学分析处理的对象是带有随机性的数据。
按照随机排列、重复、局部控制、正交等原则设计⼀个试验,通过试验结果形成样本信息(通常以数据的形式),再根据样本进⾏统计推断,是⾃然科学和⼯程技术领域常⽤的⼀种研究⽅法。
由于试验指标常为多个数量指标,故常设试验结果所形成的总体为多元正态总体,这是本章理论⽅法研究的出发点。
所谓统计推断就是根据从总体中观测到的部分数据对总体中我们感兴趣的未知部分作出推测,这种推测必然伴有某种程度的不确定性,需要⽤概率来表明其可靠程度。
统计推断的任务是“观察现象,提取信息,建⽴模型,作出推断”。
统计推断有参数估计和假设检验两⼤类问题,其统计推断⽬的不同。
参数估计问题回答诸如“未知参数θ的值有多⼤?”之类的问题,⽽假设检验回答诸如“未知参数θ的值是0θ吗?”之类的问题。
本章主要讨论多元正态总体的假设检验⽅法及其实际应⽤,我们将对⼀元正态总体情形作⼀简单回顾,然后将介绍单个总体均值的推断,两个总体均值的⽐较推断,多个总体均值的⽐较检验和协⽅差阵的推断等。
3.1⼀元正态总体情形的回顾⼀、假设检验在假设检验问题中通常有两个统计假设(简称假设),⼀个作为原假设(或称零假设),另⼀个作为备择假设(或称对⽴假设),分别记为0H 和1H 。
1、显著性检验为便于表述,假定考虑假设检验问题:设1X ,2X ,…,n X 来⾃总体),(2σµN 的样本,我们要检验假设100:,:µµµµ≠=H H (3.1)原假设0H 与备择假设1H 应相互排斥,两者有且只有⼀个正确。
备择假设的意思是,⼀旦否定原假设0H ,我们就选择已准备的假设1H 。
当2σ已知时,⽤统计量nX z σµ-=在原假设0H 成⽴下,统计量z 服从正态分布z )1,0(~N ,通过查表,查得)1,0(N 的上分位点2αz 。

第三章 多元正态分布多元正态分布是一元正态分布在多元情形下的直接推广,一元正态分布在统计学理论和应用方面有着十分重要的地位,同样,多元正态分布在多元统计学中也占有相当重要的地位。
多元分析中的许多理论都是建立在多元正态分布基础上的,要学好多元统计分析,首先要熟悉多元正态分布及其性质。
第一节 一元统计分析中的有关概念多元统计分析涉及到的都是随机向量或多个随机向量放在一起组成的随机矩阵,学习多元统计分析,首先要对随机向量和随机矩阵有所把握,为了学习的方便,先对一元统计分析中的有关概念和性质加以复习,并在此基础上推广给出多元统计分析中相应的概念和性质。
一、随机变量及概率分布函数 (一)随机变量随机变量是随机事件的数量表现,可用X 、Y 等表示。
随机变量X 有两个特点:一是取值的随机性,即事先不能够确定X 取哪个数值;二是取值的统计规律性,即完全可以确定X 取某个值或X 在某个区间取值的概率。
(二)随机变量的概率分布函数随机变量X 的概率分布函数,简称为分布函数,其定义为:)()(x X P x F ≤=随机变量有离散型随机变量和连续型随机变量,相对应的概率分布就有离散型概率分布和连续型概率分布。
1、离散型随机变量的概率分布若随机变量X 在有限个或可列个值上取值,则称X 为离散型随机变量。
设X 为离散型随机变量,可能取值为1x ,2x ,…,取这些值的概率分别为1p ,2p ,…,记为k k p x X P ==)((Λ,2,1=k )称k k p x XP ==)((Λ,2,1=k )为离散型随机变量X 的概率分布。
离散型随机变量的概率分布具有两个性质: (1)0≥k p ,Λ,2,1=k(2)11=∑∞=k k p2、连续型随机变量的概率分布若随机变量X 的分布函数可以表示为dt t f x F x⎰∞-=)()(对一切R x ∈都成立,则称X 为连续型随机变量,称)(x f 为X 的概率分布密度函数,简称为概率密度或密度函数。

《多元统计分析》目录前言第一章基本知识﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍5 §1·1总体,个体与样本﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍5 §1·2样本数字特征与统计量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍6 §1·3一些统计量的分布﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍9 第二章统计推断﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍15 §2·1参数估计﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍15 §2·2假设检验﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍19 第三章方差分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍32 §3·1一个因素的方差分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍32 §3·2二个因素的方差分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍37 §3·3用方差分析进行地层对比﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍44 第四章回归分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍49 §4·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍49 §4·2回归方程的确定﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍49 §4·3相关系数及其显着性检验﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍52 §4·4回归直线的精度﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍55 §4·5多元回归分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍56 §4·6应用实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍60 第五章逐步回归分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍65 §5·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍65 §5·2“引入”和“剔除”变量的标准﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍66 §5·3矩阵变换法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍67 §5·4回归系数,复相关系数和剩余标准差的计算﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍69 §5·5逐步回归计算方法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍70§5·6实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍74 第六章趋势面分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍80 §6·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍80 §6·2图解汉趋势面分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍81 §6·3计算法趋势面分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍83 第七章判别分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍90 §7·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍90 §7·2判别变量的选择﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍91 §7·3判别函数﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍92 §7·4判别方法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍96 §7·5多类判别分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍104 第八章逐步判别分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍110 §8·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍110 §8·2变量的判别能力与“引入”变量的统计量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍110 §8·3矩阵变换与“剔除”变量的统计量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍113 §8·4计算步聚与实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍115 第九章聚类分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍ 125 §9·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍125 §9·2数据的规格化(标准化)﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍125 §9·3相似性统计量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍126 §9·4聚类分析方法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍131 §9·5实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍134 §9·6最优分割法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍134 第十章因子分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍142 §10·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍142 §10·2因子的几何意义﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍143 §10·3因子模型﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍145§10·4初始因子载荷矩阵的求法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍147 §10·5方差极大旋围﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍152 §10·6计算步聚﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍156 §10·7实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍157 附录﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍162 附录1标准正态分布函数量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍162 附录2正态分布临界值u a表﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍164 附录3t分布临界值t a表﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍165 附录4(a)F分布临界值Fa表(a=0·1)﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍附录4(b)F分布临界值Fa表 (a=0·05) ﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍附表4(c)F分布临界值Fa表(a=0·01)﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍附表5 x2分布临界值xa2表﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍第一章基本知识§1·1总体、个体与样本总体(母体)、个体一(样本点)和样本(子样)是统计分析中常用的名词。

第一章绪论一﹑多元统计分析的概念多元统计分析就是利用统计学和数学方法,将隐没在大规模原始数据群体中的重要信息集中提炼出来,简明扼要的把握系统的本质特征,分析数据系统中的内在规律性。
利用多元分析中不同的方法还可以对研究对象进行分类和简化。
多元分析是实现做定量分析的有效工具。
二﹑多元分析的起源和发展1.1928年,Wishart发表《多元正态总体样本协差阵的精确分布》,是多元统计分析的开端;2.20世纪30年代多元分析在理论上得到迅速发展;3.20世纪40年代应用于心理、教育、生物等方面;但由于计算量太大,其发展受到影响;4.50年代中期,由于电子计算机的出现和发展,使多元分析方法得到广泛应用;5.60年代由于新理论、新方法不断涌现使多元分析方法的应用范围更加扩大;6.多元统计分析在我国发展较晚,70年代初在我国才受到各个领域的极大关注,应用日益广泛。
三﹑多元分析能解决的实际问题多元分析在工业、农业、医学、经济学、教育学、体育科学、生态学、地质学、社会学、考古学、环境保护、军事科学、甚至文学中都有广泛应用,足见其应用的深度和广度。
四﹑多元分析课程讲授的主要内容本课程重点介绍多元分析中常用的六种方法:聚类分析判别分析主成分分析因子分析对应分析典型相关分析我们这门课重点在于应用,参考课本中的公式推导为次要内容,大致了解即可,对每一种分析方法我们要清楚掌握它解决哪类问题、前提条件和局限性,以及它们相互之间的区别与联系;会用SAS与SPSS软件实现上述过程,对所研究的问题能做出合理推断和科学评价。
五﹑作业﹑考试内容及方式平时作业类型:上机操作,论文;期末考试:3000字左右的课程论文;上机处理题;考试范围涵盖所讲的各种方法以及相关的英文帮助信息。
【思考题】1﹑什么是多元统计分析?2﹑多元统计分析能解决哪些类型的实际问题?第二章 基本知识一﹑多元正态分布的定义如同一元统计分析中一元正态分布的重要地位一样,多元正态分布在多元统计分析分析中占有重要的地位,因为多元统计分析中的许多重要理论和方法都是直接或间接建立在正态分布的基础上,多元正态分布是多元统计分析的基础。


黑龙江八一农垦大学
多元统计分析实验报告
实验项目因子分析
专业信息与计算科学专业
年级班
姓名
学号
黑龙江八一农垦大学文理学院数学实验室
学生实验守则
1、参加实验的学生必须按时到实验室上实验课,按指定的席位操作,不得迟到早退。
迟到10分钟,禁止实验。
2、遵守实验室的一切规章制度,不喧哗,不吸烟,保持室内安静、整洁。
3、学生实验前要认真预习实验内容,接受指导教师的提问和检查。
4、严格遵守操作规程。
5、应认真记录原始数据,填写实验报告,及时送交实验报告。
6、不准动用与本实验无关的仪器设备和室内的其它设施。
7、实验中发生事故时,要保持镇静,并立即采取抢救措施,及时向指导教师报告。
8、损坏实验设备应主动向指导教师报告,由指导教师根据情况进行处理,需要赔偿的应写出书面报告,填写赔偿单。
9、实验结束,将实验结果交实验教师检查,合格后,经指导教师同意后,方可离开实验室。
10、实验完毕后,应按时写出实验报告,及时交指导教师审阅,不交者,该实验无成绩。
实验报告。

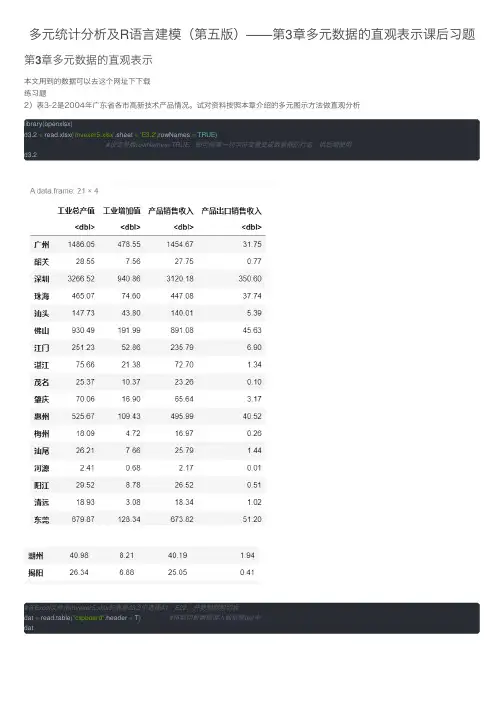
多元统计分析及R语⾔建模(第五版)——第3章多元数据的直观表⽰课后习题第3章多元数据的直观表⽰本⽂⽤到的数据可以去这个⽹址下下载练习题2)表3-2是2004年⼴东省各市⾼新技术产品情况。
试对资料按照本章介绍的多元图⽰⽅法做直观分析library(openxlsx)d3.2= read.xlsx('mvexer5.xlsx',sheet ='E3.2',rowNames =TRUE)#设定参数rowNames=TRUE,即可将第⼀列字符变量变成数据框的⾏名,供后期使⽤d3.2#在Excel⽂件中mvexer5.xlsx的表单d3.2中选择A1:E22,并复制到剪切板dat = read.table("clipboard",header = T)#将剪切板数据读⼊数据框dat中dat#数据框标记转换函数msa.X <-function(df){#将数据框第⼀列设置为数据框⾏名 X = df[,-1]#删除数据框df的第⼀列并赋给Xrownames(X)= df[,1]#将df的第⼀列值赋给X的⾏名X #返回新的数值数据框=return(X)}d3.2= msa.X(dat)d3.2barplot(apply(d3.2,2,mean))#按⾏作均值条形图barplot(apply(d3.2,1,mean),las =3)#修改横坐标标记barplot(apply(d3.2,2,mean))#按列作均值条图barplot(apply(d3.2,2,median))#按列作中位数条图barplot(apply(d3.2,2,median),col =1:8)#按列取⾊boxplot(d3.2)#按列作箱尾图boxplot(d3.2,horizontal = T)#箱尾图中图形按⽔平放置install.packages('aplpack',repos="https:///CRAN/") library(aplpack)faces(d3.2,ncol.plot =7)#按每⾏7个作脸谱图install.packages('TeachingDemos',repos="https:///CRAN/") library(TeachingDemos)faces2(d3.2,ncols =7)#作⿊⽩脸谱图install.packages('andrews',repos="https:///CRAN/") library(andrews)andrews(d3.2,clr =2,ymax =5)#⼀般调和曲线source('msaR.R')msa.andrews(d3.2)#改进调和曲线msa.andrews(d3.2[c(1,3,5,7,9,11,13,15,17),])#作第1,3,5,7,9,11,13,15,17个观测的调和曲线图。

第三章多元统计分析§4 聚类分析分类是人类认识世界的方式,也是管理世界的有效手段。
在科学研究中非常重要,许多科学的研究都是从分类研究出发的。
没有分类就没有效率;没有分类,这个世界就没有秩序。
瑞典博物学家林奈(Carl von Linnaeus, 1707-1778)因为对植物的分类成就被后人誉为“分类学之父”,后人评价说“上帝创世,林奈分类”——能与上帝的名字并列的人不多,另一个著名的科学家是牛顿。
由此可见分类成果的重要性。
最初分类都是定性了,后来随着科学的发展产生了定量分类技术,包括基于统计学的聚类方法和基于模糊数学的聚类技巧。
本节主要讲述统计学意义的数字分类方法思想和过程。
1 聚类的分类分类研究的成果的重要性决定了方法的重大实践意义。
在任何一门语言的语法学中,都要对词词汇进行分类,词汇分类可以根据词性:名词,动词,形容词……;英文还可以根据首字母分类:ABCD……;汉字则还可以根据笔划,如此等等。
在生物学中,将生物划分为:界,门,纲,目,科,属,种。
例如白菜(种)属于油菜属、十字花科、十字花目、双子叶植物纲、被子植物亚门、种子植物门、植物界;老虎(种)则属于猫属、猫科、食肉目、哺乳动物纲、脊椎动物亚门、脊索动物门、动物界。
这样,整个世界的生物就可以建立一个等级谱系,根据这个谱系,我们可以比较容易地判断那些生物已经认识了,哪些生物尚未发现,哪些生物已经灭绝了。
如果发现了新的生物,就可以方便地将其归类。
在天文学中,天体可以根据视觉区域分类,也可以根据发光性质与光谱特征进行分类。
在地理学中,城市既可以根据地域空间分类,也可以根据城市的职能进行分类。
表3-3-1 各种生物在分类学上的位置举例位置白菜虎界植物界动物界门种子植物门脊索动物门亚门被子植物亚门脊椎动物亚门纲双子叶植物纲哺乳动物纲目十字花目食肉目科十字花科猫科属油菜属猫属种白菜虎当我们走进一家图书馆,如果它们的图书没有分类编目,我们要找到一本图书与大海捞针没有什么区别。
分类的方式也会影响工作的效率。
书店的图书一般根据科学门类进行分类摆设,但有一段时间一家书店改为按照出版单位进行分类排列,结果读者很难找到所需图书,这家原本效益挺好的书店很快收到了消极影响。
早期的分类,一般根据事物的属性与特征进行划分,属于定性分类的范畴。
随着人们认识的深入和研究对象复杂程度的增加,单纯的定性分类方法就不能满足要求了,于是产生了定量分类技术,即所谓数字分类。
本节要讲述的就是根据多个指标进行数字分类的一种多元统计分析技术。
根据分类对象的不同,聚类分析又可以分为两类:一是在变量空间中根据变量特征或者指标性质对样本进行分类,这叫做Q 型聚类分析;二是在样本空间中根据变量在样本上的观测值对变量进行分类,叫做R 型距离分析。
我们着重讲述的是对样本分类,即Q 型距离分析。
此外,由于现实世界的事物很难做到一分为二:许多测度是模糊的,因此产生了模糊聚类技术,基本思路与我们学习的统计分类一致(图3-3-1)。
⎪⎪⎩⎪⎪⎨⎧⎪⎩⎪⎨⎧⎩⎨⎧—对变量分类—型聚类分析—对样本分类—型聚类分析数字分类模糊聚类定量分类定性分类关于分类方法的分类R Q 图3-3-1 关于分类的分类在地理学中,分类一般涉及到地域,基于地域的分类又可以分为两类,即同域分类和异域分类。
一般意义的分类是同域分类:对同一个地域系统的要素进行分类;但有时候需要进行异域分类:对不同地域系统的要素进行分类。
具体说明如下:同域分类:经济建设与濒危生物保护:例如公路建设,不仅要考虑城市之间以及城乡联系,还要考虑文物保护、濒危物种的保护——主要是保护生物『基因库』。
考察某种濒危物种,调查其生态环境的各种参数(变量)→分区(样本)→绘图→调查→落实→范围确定……→提交给交通部。
异域分类:引进日本福冈甜桔,可供选择的引进地点有:合肥、武汉、长沙、桂林、温州、成都……。
与甜桔生活有关的分析变量包括:年平均气温,年平均降雨量,年日照时数,年极端最低温,一月份平均气温。
利用上述变量,将日本福冈与候选城市放到一起聚类,就是所谓异域聚类。
人们采用模糊数学中的相似优先比得到如下结果:长沙,温州,成都,武汉,桂林,合肥。
我们采用异域聚类得到结果如下图(图3-3-2,由SPSS 给出):可以选择的顺序依次是:长沙,成都,温州,桂林,武汉,合肥。
可见,两种分析方法的结论是一样的:优先选择的地点是长沙,不宜选择的地点是合肥。
图3-3-2 异域聚类分析结果一例3-13 基于相似系数的异域聚类结果:长沙,成都,温州,桂林,合肥,武汉在多元统计学中,聚类分析又叫群分析,乃是研究样本或指标的分类问题的一种多元统计方法。
所谓类,通俗地讲,就是相似元素的集合。
聚类方法有包括如下种类:系统聚类法,有序样品法,模糊聚类法,图论聚类法,聚类预报法……。
2 距离与相似系数聚类分析是根据相似性和差异性来进行的,相似性可以借助相似系数之类表征,差异性则可以通过距离反映。
广义地将,距离和相似性是同一类别的数学问题。
广义距离,有各种各样的定义,不同的距离有不同的优点和缺点。
我们可以更加聚类分析的目的或者研究对象的特征选择距离,也可以自行定义一种距离。
需要明确的是,定义任何一种距离,都不得违背距离公理。
⒈ 距离公理设x 1、x 2、…、x n 为n 个样本,第i 个样本x i 与第j 个样本x j 之间建立一个函数关系式d ij =d (x i , x j ),如果它满足如下条件,则称d ij 为样本x i 与x j 之间的距离:① 非负性:0≥ij d 对所有的i 、j 成立; ② 规范性:0=ij d 当且仅当j i x x =; ③ 对称性:ji ij d d =对所有的i 、j 成立;④ 三点不等式,在数学上叫做Cauchy 不等式:kj ik ij d d d +≤对所有的i 、j 、k 成立。
距离的大小可以反映样本之间的差异程度。
⒉ 常见距离⑴ 欧式距离(Euclid 距离)2/112))((∑=-=mk jk ikij x xd . (3-3-1)下面以一个最简单的实例进行说明。
已知三个城市的三项指标,计算它们的欧式距离(表3-2-2)。
表3-3-2 甲乙丙三城市的三个指标城市甲(A ) 160 60 115 城市乙(B ) 110 43 93 城市丙(C ) 90 35 75 方 差866.667108.667267.556根据公式(3-3-1),甲、乙两城市的欧式距离为(注意,这不是地理或者交通意义的距离):210.57221750)93115()4360()110160(222222=++=-+-+-=AB d . (3-3-1)欧式距离的优点:几何意义明确,简单,容易掌握,由于中学数学就已初步接触,数学知识不多的人也可以把握它的基本含义。
缺点:从统计学的角度看,使用欧式距离要求一个向量的n 个分量不相关,且具有相当的方差,或者说各个坐标对欧式距离的贡献同等且变差大小相同,此时使用欧式距离才合适,且效果良好,否则就不能如实反映情况且容易导致错误的结论。
因此需要对坐标加权,化为统计距离(参见后面的精度加权距离)。
有时采用欧式距离平方(squared Euclid distance ):∑=-=mk jk ikijx xd 122)(, (3-3-2)⑵ 明氏距离(或译“闵氏距离”,Minkovski ,Minkowski 距离)设x i 、x j 均均为m 为向量,且⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=im i i i x x x x 21, ⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=jm j j j x x x x 21, (n i ,,2,1 =), (3-3-4)则称q mk qjk ik ij x x q d /11][)(∑=-=, (n j i ,,2,1, =) (3-3-5)① 当q =1时,得绝对距离(Block )∑=-=mk jk ikij x xd 1)1(. (3-3-6)对于前面的例子,绝对距离为89221750)1(=++=AB d . (3-3-7)② 当q =2时,得欧式距离2/112)()2(∑=-=mk jk ik ij x x d , (3-3-8)③ 当q →∞时,得切比雪夫距离(Chebychev 距离)。
明氏距离的有缺点如下:优点:人们使用较多,较熟悉,易于理解。
缺点:a 受指标量纲的影响;b 没有考虑指标之间的相关性。
⑶ B 模距离对于任意的正定矩阵B ,由下式确定的距离称为B 模距离[]2/1)()(j i T j i ij x x B x x d --=,(n i ,,2,1 =) (3-3-9)① 当B =I (单位矩阵)时,d ij 为欧式距离。
给定两个向量⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=im i i i x x x x 21, ⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=jm j j j x x x x 21, (n i ,,2,1 =, m k ,,2,1 =) (3-3-10)显然⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡---=-jm im j i j i j i x x x x x x x x 2211)(. (3-3-11) 从而[]⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡------=--=jm im j i j i jmim j i j i j i T j i ij x x x x x x x x x x x x x x I x x d 221122112)()(. (3-3-12)显然这正是欧式距离。
对于前面的例子,我们有⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=-221750)(j i x x , ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=100010001I , 210.57=AB d . (3-3-13)② 当)1,,1,1(diag 22221mB σσσ =,为精度加权距离。
这里)var(2ik k x =σ。
下面以三样本为例说明:[]⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡---⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡---=3322112322213322112/1000/1000/1j i j i j i j i j i j i ij x x x x x x x x x x x x d σσσ232332222221211)()()(σσσj i j i j i x x x x x x -+-+-=. (3-3-14)对于前面表3-3-2中的例子,容易得到71166.2809.1660.2885.2556.26722667.10817667.86650222=++=++=ABd . (3-3-15)③ 当11)][cov(--∑≡=x B 时,为马氏距离(Mahalanobis 距离)。
设∑表示协方差阵[]mm ij⨯=∑σ. (3-3-16)其中∑=---=nj j i i ij x x x x n 1))((11ααασ, (m j i ,,2,1, =) (3-3-17)这里∑==n i i x n x 11αα, ∑==nj j x n x 11αα. (3-3-18)如果逆矩阵∑-1存在,则两个样本之间的马氏距离可由下式定义)()(12j i T j i ij x x x x d -∑-=-; (3-3-19)样本X 到总体G 的马氏距离为)()(12),(μμ-∑-=-x x d T G X . (3-3-20)式中μ为总体的均值向量。