关联规则概念图
- 格式:vsd
- 大小:33.50 KB
- 文档页数:1


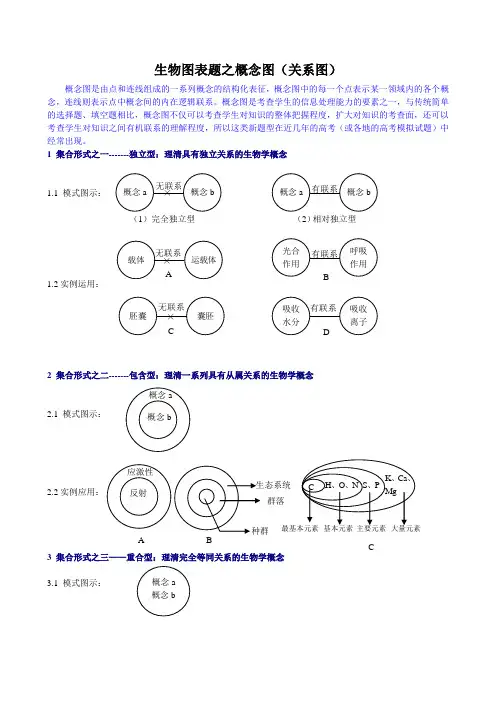
生物图表题之概念图(关系图)概念图是由点和连线组成的一系列概念的结构化表征,概念图中的每一个点表示某一领域内的各个概念,连线则表示点中概念间的内在逻辑联系。
概念图是考查学生的信息处理能力的要素之一,与传统简单的选择题、填空题相比,概念图不仅可以考查学生对知识的整体把握程度,扩大对知识的考查面,还可以考查学生对知识之间有机联系的理解程度,所以这类新题型在近几年的高考(或各地的高考模拟试题)中经常出现。
1 集合形式之一-------独立型:理清具有独立关系的生物学概念1.1 模式图示:1.2实例运用:2 集合形式之二-------包含型:理清一系列具有从属关系的生物学概念2.1 模式图示:2.2实例应用:3 集合形式之三——重合型:理清完全等同关系的生物学概念3.1 模式图示:概念a 概念b 概念a 概念b ×有联系 (1)完全独立型 (2)相对独立型 载体 运载体 × 光合作用呼吸作用有联系 A B 胚囊 囊胚 ×吸收水分 吸收离子 有联系 C D概念a概念b 应激性反射 A 群落 BC无联系无联系无联系4 集合形式之四——重叠型:理清具有公共关系的生物学概念4.1 模式图示:4.2 实例运用:5 集合形式之五——混合型:分散的生物学概念知识理顺为系统化5.1 模式图示:以上几种图示的混合型5.2 实例运用:染色体染色质基因工程DNA重组技术转基因技术基因拼接技术细胞外液内环境3.2 实例运用:A 物质相同B 技术相同C 范围相同概念a 概念b公共部分(交集)矿质元素必需元素必需的矿质元素(14种)患甲病概率患乙病概率同时患病概率CO2 H2O糖类氧化产物脂类氧化产物蛋白质氧化产物A B Cdcab乳酸菌蓝藻原核生物细菌Adacb无丝分裂减数分裂有丝分裂真核生物的分裂方式B【练习】1.图中①、②、③三个图分别代表某个概念或某类物质。
以下各项中,能构成图中关系的是A.DNA、染色体、基因 B.反射、应激性、适应性C.酶、蛋白质、激素 D.减数分裂、有丝分裂、无丝分裂【解析】C,大多数酶是蛋白质,有些激素(如胰岛素)也是蛋白质,因此酶和激素与蛋白质之间为交叉关系;酶和激素是两类物质,为并列关系。

在数据挖掘的知识模式中,关联规则模式是比较重要的一种。
关联规则的概念由Agrawal、Imielinski、Swami 提出,是数据中一种简单但很实用的规则。
关联规则模式属于描述型模式,发现关联规则的算法属于无监督学习的方法。
一、关联规则的定义和属性考察一些涉及许多物品的事务:事务1 中出现了物品甲,事务2 中出现了物品乙,事务3 中则同时出现了物品甲和乙。
那么,物品甲和乙在事务中的出现相互之间是否有规律可循呢?在数据库的知识发现中,关联规则就是描述这种在一个事务中物品之间同时出现的规律的知识模式。
更确切的说,关联规则通过量化的数字描述物品甲的出现对物品乙的出现有多大的影响。
现实中,这样的例子很多。
例如超级市场利用前端收款机收集存储了大量的售货数据,这些数据是一条条的购买事务记录,每条记录存储了事务处理时间,顾客购买的物品、物品的数量及金额等。
这些数据中常常隐含形式如下的关联规则:在购买铁锤的顾客当中,有70 %的人同时购买了铁钉。
这些关联规则很有价值,商场管理人员可以根据这些关联规则更好地规划商场,如把铁锤和铁钉这样的商品摆放在一起,能够促进销售。
有些数据不像售货数据那样很容易就能看出一个事务是许多物品的集合,但稍微转换一下思考角度,仍然可以像售货数据一样处理。
比如人寿保险,一份保单就是一个事务。
保险公司在接受保险前,往往需要记录投保人详尽的信息,有时还要到医院做身体检查。
保单上记录有投保人的年龄、性别、健康状况、工作单位、工作地址、工资水平等。
这些投保人的个人信息就可以看作事务中的物品。
通过分析这些数据,可以得到类似以下这样的关联规则:年龄在40 岁以上,工作在A 区的投保人当中,有45 %的人曾经向保险公司索赔过。
在这条规则中,“年龄在40 岁以上”是物品甲,“工作在A 区”是物品乙,“向保险公司索赔过”则是物品丙。
可以看出来,A 区可能污染比较严重,环境比较差,导致工作在该区的人健康状况不好,索赔率也相对比较高。

关联规则算法过程关联规则算法,又称为关联分析算法,是一种数据挖掘算法,用于发现数据集中项目之间的关联关系。
这些关联关系可以用于预测未来事件,或者用于制定更好的商业策略。
一、算法介绍关联规则算法的目的是发现数据集中项目之间的关系,这种关系可以用频繁项集来表示。
频繁项集是一个包含频繁项的项集,频繁项是在数据集中出现频率较高的项。
关联规则算法的基本思想是:在数据集中找出频繁项集,然后从频繁项集中生成关联规则。
关联规则是由一个前项和一个后项组成,前项和后项都是频繁项集。
关联规则的意义是:如果一个事物包含前项,则它也很可能包含后项。
关联规则可以用以下形式表示:前项→ 后项。
二、算法流程关联规则算法的流程如下:1. 扫描数据集,计算每个项的出现频率。
2. 选取阈值min_sup,过滤掉出现频率低于min_sup的项。
3. 构造长度为2的候选集,并扫描数据集,计算每个候选集的出现频率。
4. 选取阈值min_sup,过滤掉出现频率低于min_sup的候选集。
5. 根据长度为2的频繁项集,构造长度为3的候选集,并扫描数据集,计算每个候选集的出现频率。
6. 选取阈值min_sup,过滤掉出现频率低于min_sup的候选集。
7. 根据长度为3的频繁项集,构造长度为4的候选集,并扫描数据集,计算每个候选集的出现频率。
8. 重复上述步骤,直到不能生成更长的候选集为止。
9. 根据频繁项集生成关联规则。
10. 用关联规则进行预测或制定商业策略。
三、算法优化关联规则算法的时间复杂度很高,因为它需要在数据集中生成大量的候选集。
为了提高算法的效率,可以采用以下优化方法:1. 压缩数据集:对于出现频率较低的项,可以将它们从数据集中删除,从而减少候选集的数量。
2. 停止生长:当生成的候选集中有一个子集不是频繁项集时,就可以停止生成更长的候选集了。
3. 剪枝:当一个候选集的所有子集都是频繁项集时,它自己也是频繁项集,可以将它加入频繁项集中。





强直接关联规则
(实用版)
目录
1.强直接关联规则的定义
2.强直接关联规则的例子
3.强直接关联规则的应用领域
4.强直接关联规则的优缺点
正文
强直接关联规则是一种用于挖掘数据集中频繁项集的关联规则。
频繁项集指的是在数据集中出现频率达到一定阈值的项集,而强直接关联规则则是指在频繁项集中,任意两个项之间都存在直接关联。
换句话说,如果一个项集是频繁的,那么这个项集中的任意两个项都满足最小支持度阈值。
举个例子来说,假设我们有一个销售数据集,其中包括以下五个项:牛奶、面包、鸡蛋、啤酒和香烟。
通过计算,我们发现购买牛奶和面包、牛奶和鸡蛋、面包和啤酒、啤酒和香烟这四组物品之间的关联规则满足强直接关联规则。
换句话说,只要顾客购买了牛奶,他们就有很大可能会购买面包、鸡蛋、啤酒或香烟。
强直接关联规则在许多领域都有广泛的应用,例如市场营销、生物信息学、搜索引擎等。
在市场营销中,通过挖掘顾客购买行为的强直接关联规则,商家可以更好地进行商品推荐和促销活动。
在生物信息学领域,强直接关联规则可以用于研究基因之间的功能关联。
在搜索引擎中,强直接关联规则可以帮助我们更好地理解用户的查询意图,从而提供更准确的搜索结果。
强直接关联规则具有一定的优点,例如能够发现数据集中的潜在关联关系,有助于挖掘有价值的信息。
关联规则箭头读法【原创版】目录1.关联规则箭头读法的概念2.关联规则箭头读法的分类3.关联规则箭头读法的应用4.关联规则箭头读法的注意事项正文关联规则箭头读法是一种用于表示关联规则的图形化方法,它通过箭头来表示不同项之间的关联程度,从而帮助人们更好地理解和分析数据。
关联规则箭头读法主要应用于数据挖掘、人工智能和统计学等领域。
关联规则箭头读法可以分为以下几种类型:1.单向箭头:表示一个项只与另一个项相关联,例如,A → B,表示A 项与B 项有关联,但 B 项与 A 项之间没有关联。
2.双向箭头:表示两个项之间互相关联,例如,A → B 和 B → A,表示 A 项与 B 项互相关联。
3.环形箭头:表示一组项之间互相关联,例如,A → B → C 和 C →B → A,表示 A 项与 B 项、B 项与C 项、C 项与 A 项之间互相关联。
4.带有箭头宽度的箭头:表示关联程度的强弱,箭头越宽,关联程度越强。
例如,A → B(宽箭头)表示 A 项与 B 项关联程度较强,而 A →B(窄箭头)表示 A 项与 B 项关联程度较弱。
在实际应用中,关联规则箭头读法可以帮助我们更好地发现数据中的规律,从而为决策提供依据。
例如,在商品销售数据中,我们可以通过关联规则箭头读法分析不同商品之间的销售关系,以便制定合适的销售策略。
在绘制关联规则箭头读法时,需要注意以下几点:1.确保箭头的方向正确,避免箭头指向错误导致关联关系理解错误。
2.根据实际需求选择合适的箭头类型,例如,在分析双向关联关系时,应使用双向箭头。
3.适当使用箭头宽度表示关联程度,避免过度使用导致信息过载。
总之,关联规则箭头读法是一种直观、简洁地表示关联规则的方法,广泛应用于数据分析和决策领域。