ppt 第11章 聚类分析与判别分析
- 格式:ppt
- 大小:718.50 KB
- 文档页数:50

第十一章聚类分析与判别分析聚类分析与判别分析是两类常用多元分析方法。
聚类分析可以将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强;而判别分析则可以根据已掌握的样本信息建立判别函数,当遇到新的样本点时根据判别函数可以判断该样本点所属的类别。
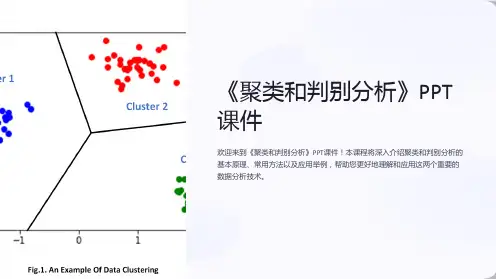
第一节聚类分析一、聚类分析的基本思想“物以类聚,人以群分”。
分类处理,在现实中极为普遍。
在生物、经济、社会、人口等领域的研究中,存在着大量量化分类研究。
例如:在生物学中,为了研究生物的演变,生物学家需要根据各种生物不同的特征对生物进行分类;在经济研究中,为了研究不同地区城镇居民生活中的收入和消费情况,往往需要划分不同的类型去研究;在人口学研究中,需要构造人口生育分类模式、人口死亡分类状况,以此来研究人口的生育和死亡规律。
历史上,这些分类方法多半是人们主要依靠经验作定性分类,致使许多分类带有主观性和任意性,特别是对于多因素、多指标的分类问题,定性分类的准确性不好把握。
为了克服定性分类存在的不足,人们把数学方法引入分类中,形成了数值分类学,进而产生了聚类分析这一最常用的技巧。
聚类分析将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。
其目的在于:使类内对象的同质性最大化和类间对象的异质性最大化。
聚类分析通常可以分为两种:Q型聚类和R型聚类。
Q型聚类是对观测个体的分类,R 型聚类是对变量的分类。
二者在数学上是对称的,没有本质区别。
二、符号说明多元统计分析中要注意区分样本和变量。
每个样品有p个指标(变量)从不同方面描述其性质,形成一个p维的向量,可以把n 个样品看成p维空间中的n个点。
X表示第k个变量第j次观测值(或称第j个项目的测量值),即:我们用记号jkX=第k个变量第j次观测值jkp个变量的n个观测值可表示如下:11121121222212121212k p k pj j jk jp n n nknpkp X X X X X X X X j X X X X nX X XX 变量变量变量变量观测观测观测观测记为:1112112122221212k p k p j j jk jp n n nknp X X X X X X X X X X X X X X X X ⎛⎫⎪ ⎪⎪=⎪ ⎪⎪ ⎪ ⎪⎝⎭X 记12(,,,)'jp j j jp X X X X R =∈,表示第j 个样品,它表示p 维空间的一个点。

「聚类分析与判别分析」聚类分析和判别分析是数据挖掘和统计学中常用的两种分析方法。
聚类分析是一种无监督学习方法,通过对数据进行聚类,将相似的样本归为一类,不同的样本归入不同的类别。
判别分析是一种有监督学习方法,通过学习已知类别的样本,构建分类模型,然后应用模型对未知样本进行分类预测。
本文将对聚类分析和判别分析进行详细介绍。
聚类分析是一种数据探索技术,其目标是在没有任何先验知识的情况下,将相似的样本聚集在一起,形成互相区别较大的样本群。
聚类算法根据样本的特征,将样本分为若干个簇。
常见的聚类算法有层次聚类、k-means聚类和密度聚类。
层次聚类是一种自下而上或自上而下的层次聚合方法,通过测量样本间的距离或相似性,不断合并或分裂簇,最终形成一个聚类树状结构。
k-means聚类将样本划分为k个簇,通过优化目标函数最小化每个样本点与其所在簇中心点的距离来确定簇中心。
密度聚类基于样本点的密度来判断是否属于同一簇,通过划定一个密度阈值来确定簇的分界。
聚类分析在很多领域中都有广泛的应用,例如市场分割、医学研究和社交网络分析。
在市场分割中,聚类分析可以将消费者按照其购买行为和偏好进行分组,有助于企业制定更精准的营销策略。
在医学研究中,聚类分析可以将不同患者分为不同的亚型,有助于个性化的治疗和药物开发。
在社交网络分析中,聚类分析可以将用户按照其兴趣和行为进行分组,有助于推荐系统和社交媒体分析。
相比之下,判别分析是一种有监督学习方法,其目标是通过学习已知类别的样本,构建分类模型,然后应用模型对未知样本进行分类预测。
判别分析的目标是找到一个决策边界,使得同一类别内的样本尽可能接近,不同类别之间的样本尽可能远离。
常见的判别分析算法有线性判别分析(LDA)和逻辑回归(Logistic Regression)。
LDA是一种经典的线性分类方法,它通过对数据进行投影,使得同类样本在投影空间中的方差最小,不同类样本的中心距离最大。
逻辑回归是一种常用的分类算法,通过构建一个概率模型,将未知样本划分为不同的类别。






