配对样本T检验实例
- 格式:doc
- 大小:176.00 KB
- 文档页数:6
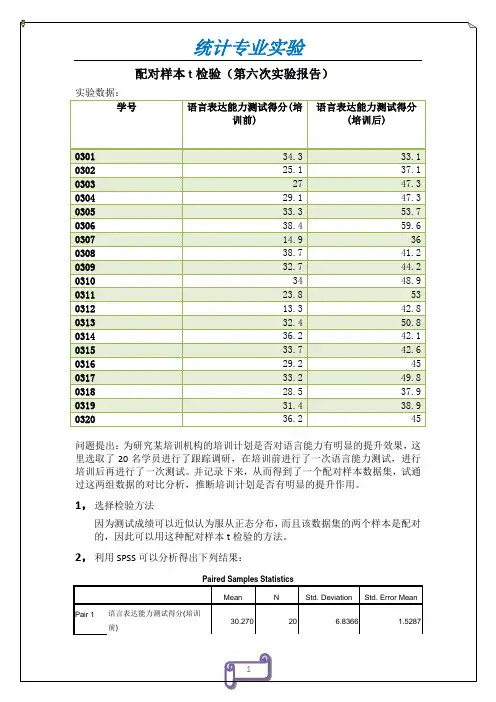


配对样本t检验,史上最完整SPSS操作教程!⼀、问题与数据研究者想验证⼀种新型运动饮料配⽅是否有助于提⾼⼈们的跑步距离。
传统饮料配⽅为纯碳⽔化合物,⽽新型饮料为碳⽔化合物-蛋⽩质混合物。
为了⽐较两种运动饮料对⼈们跑步距离的影响差异,研究者招募了20名受试者,每⼈进⾏2项试验,每项试验受试者均在跑步机上运动2⼩时。
2项试验中,同⼀受试者跑步前分别喝含纯碳⽔化合物饮料和碳⽔化合物-蛋⽩质混合饮料。
同时,均衡所有受试者进⾏2项试验的先后顺序,使⼀半⼈先喝纯碳⽔化合物饮料,另⼀半⼈先喝碳⽔化合物-蛋⽩质混合饮料,分别记录其跑步距离。
碳⽔化合物饮料组的跑步距离记为carb变量,碳⽔化合物-蛋⽩质饮料组的跑步距离记为carb_protein变量。
研究者想知道,是否2组的跑步距离有差异,即2种运动饮料对⼈们跑步距离的影响不同。
从变量层⾯上,也就是看是否carb变量和carb_protein变量的均数存在差异(部分数据如下图)。
展开剩余95%⼆、对问题的分析研究者想探索是否2个相关(配对)组别间的因变量均数存在差异,可以使⽤配对样本t检验。
使⽤配对样本t检验时,需要考虑4个假设:假设1:因变量为连续变量;假设2:⾃变量包含2个分类、且相关(配对)⾮独⽴的组别;假设3:2个相关(配对)组别间的因变量差值没有明显异常值;假设4:2个相关(配对)组别间的因变量差值近似服从正态分布。
那么进⾏配对样本t检验时,如何考虑和处理这4个假设呢?三、思维导图(点击图⽚可查看⼤图)四、对假设的判断假设1:因变量为连续变量;假设2:⾃变量包含2个分类、且相关(配对)⾮独⽴的组别。
和研究设计有关,需要根据实际情况进⾏判断。
假设3:2个相关(配对)组别间的因变量差值没有明显异常值。
对于配对样本t检验,异常值和正态性的假设检验都是基于2组间配对数值的差值进⾏的。
因此,我们⾸先需要计算2组因变量的差值,并把它作为⼀个新变量储存,变量名为difference,具体操作如下:1. 在主菜单栏中点击Transform > Compute Variable...:出现Compute Variable对话框:2. 在Target Variable:模块中输⼊difference,即为新创建的变量名;在Numeric Expression:模块中输⼊carb_protein – carb,即为2个配对组别间的因变量差值(也可以直接从左侧中部变量框中挑选变量进⼊Numeric Expression:模块,并选择中间的运算符号和数字进⾏运算):本例为⽤carb_protein变量值减去carb变量值,此顺序与研究设计和研究⽬的有关,通常⽤实验组的数值减去对照组的数值。



SPSS详细教程配对样本的t检验1、问题与数据某研究使⽤克矽平治疗矽肺病患者10名,分别测得治疗前、后患者的⾎红蛋⽩含量(g/dL),数据如下。
试问该药对矽肺患者的⾎红蛋⽩含量有⽆影响?病例号治疗前治疗后112.114.0214.714.2312.713.2414.212.7511.212.4613.513.3715.015.5814.914.4912.612.51013.113.42、对数据结构的分析整个数据资料涉及1组患者(共10名),每名患者有治疗前、后2个数据,采⽤⾃⾝前后对照设计,测量指标为⾎红蛋⽩含量,因此属于配对设计的定量资料。
要想知道克矽平对⾎红蛋⽩的含量有⽆影响,则要⽐较治疗前、后⾎红蛋⽩含量的差异是否有统计学意义。
若2组数据服从正态分布的要求,可选⽤配对样本的t检验。
3、SPSS分析⽅法(1)数据录⼊SPSS(2)选择Analyze→Compare Means→Paired-Samples T Test(3)选项设置主对话框设置:分别把“before”和“after”变量放⼊Paired Variables框中的Variable1和Variable2(Pair 1)→OK4、结果解读Paired Samples Statistics表格给出了治疗前、后⾎红蛋⽩含量的部分统计信息,包括均数(Mean)、配对数(N)、标准差(Std. Deviation)和样本均数的标准误(Std. Error Mean)。
Paired Samples Correlations 表格给出了治疗前、后⾎红蛋⽩含量的相关系数(Correlation),为0.676,P(Sig.)=0.032,具有相关关系。
Paired Samples Test表格给出了统计检验的结果。
Mean为治疗前、后⾎红蛋⽩差值的均数,Std. Deviation为差值的标准差,Std. Error Mean为差值均数的标准误,95% Confidence Internal of the Difference(Lower,Upper)为差值均数的95%可信区间。


配对t检验python代码配对t检验(paired t-test)是用于比较两组相关样本均值是否存在显著差异的统计方法。
在Python中,你可以使用SciPy库来进行配对t检验。
下面是一个简单的示例代码:python.import scipy.stats as stats.# 两组相关样本数据。
group1 = [15, 20, 25, 30, 35]group2 = [17, 22, 27, 32, 37]# 执行配对t检验。
t_statistic, p_value = stats.ttest_rel(group1, group2)。
# 输出结果。
print("t统计量:", t_statistic)。
print("p值:", p_value)。
# 判断显著性。
alpha = 0.05。
if p_value < alpha:print("拒绝原假设,两组均值存在显著差异")。
else:print("接受原假设,两组均值不存在显著差异")。
在这个示例中,我们首先导入了SciPy库中的stats模块。
然后,我们定义了两组相关样本数据group1和group2。
接下来,我们使用stats.ttest_rel()函数执行配对t检验,该函数返回t统计量和p值。
最后,我们输出结果并判断显著性水平。
需要注意的是,这只是一个简单的示例代码。
在实际应用中,你需要根据你的数据和研究问题进行相应的调整和处理。
希望这个示例能够帮助到你。

本科学生实验报告学号:*********** 姓名:&&&&&&学院:生命科学学院专业、班级:11级应用生物教育A班实验课程名称:生物统计学实验教师:孟丽华(讲师)开课学期:2012 至2013 学年下学期填报时间:2013 年 4 月22 日云南师范大学教务处编印的均值;2)、构造统计量:其中:为两配对样本差值的均值,为两总体均值之差,两配对样本T检验采用T统计量。
其思路是:首先,对两组样本分别计算出每对观测值的差值得到差值样本;然后,体用差值样本,通过对其均值是否显著为0的检验来推断两总体均值的差是否显著为0.如果差值样本的均值与0有显著差异,则可以认为两总体的均值有显著差异;反之,如果差值系列的均值与0无显著差异。
则可以认为两总体均值不存在显著差异;3)、计算检验统计量观测值和概率P-值:SPSS将计算两组样本的差值,并将相应数据代入式①,计算出T统计量的观测值和对应的概率P-值;4)、给定显著水平α,并作出决策:给定显著水平α,与检验统计量的概率P-值作比较。
如果概率P-值小于显著水平α,则应拒绝原假设,认为差值样本的总体均值与0有显著不同,两总体的均值有显著差异;反之,如果概率P-值大于显著水平α,则不应拒绝原假设,认为差值样本的总体均值与0无显著不同,两总体的均值不存在显著差异。
(四)、实验内容:内容:生物统计学(第四版)第73页第四章习题 4.9实验方法步骤1、启动spss软件:开始→所有程序→SPSS→spss for windows→spss 18.0 for windows,直接进入SPSS数据编辑窗口进行相关操作;2、定义变量,输入数据。
点击“变量视图”定义变量工作表,用“name”命令定义变量“治疗前”(小数点零位)及标签为“治疗前的舒张压(mmHg)”;变量“治疗后”(小数点零位)及标签为“治疗后的舒张压(mmHg)”;点击“变量视图工作表”,把治疗前后的舒张压的数据输入到单元格中;3、设置分析变量。

配对样本t检验-SPSS教程一、问题与数据某研究者拟分析某种药物是否可以降低低密度脂蛋白胆固醇(LDL)水平。
他招募了20位研究对象,测量基线低密度脂蛋白胆固醇水平,记录为LDL1,然后对患者进行4周的药物干预,再次测量低密度脂蛋白胆固醇水平,记录为LDL2,收集的部分数据如图1。
图1 部分数据二、对问题分析研究者想探索是否2个相关(配对)组别间的均数是否存在差异,可以使用配对样本t检验。
使用配对样本t检验时,需要考虑4个假设。
假设1:观测变量为连续变量。
假设2:分组变量包含两个分类、且相关(配对)。
假设3:两个相关(配对)组别间观测变量的差值没有明显异常值。
假设4:两个相关(配对)组别间观测变量的差值近似服从正态分布。
假设1和假设2取决于研究设计和数据类型,本研究数据满足假设1和假设2。
那么应该如何检验假设3和假设4,并进行配对样本t检验呢?三、SPSS操作3.1 检验假设3:两个相关(配对)组别间观测变量的差值没有明显异常值配对样本t检验中,异常值和正态性的假设检验都是基于两组间配对数值的差值进行的。
因此,我们首先需要计算两组观测变量的差值,并把它作为一个新变量储存,变量名为difference。
在主界面点击Transform→Compute Variable,出现Compute Variable对话框,在Target Variable中输入difference(新创建的变量名)。
将变量LDL1选入Numeric Expression框中,再双击下方的减号“-”,最后将变量LDL2选入Numeric Expression框中。
点击OK生成新变量difference。
如图2。
图2 Compute Variable本研究中,两组观测变量差值的计算方法是LDL1减LDL2。
实际研究中,差值的计算方法与研究设计和研究目的有关。
本研究关心的是某种药物是否可以降低LDL水平,如果差值是正数,则说明可以降低,反之亦然。
例子:挑选学生配对组班,更精确地评估教学效果。
在独立样本T检验的例子中,研究者考虑到没有对A班和B班的外国留学生本身的基础、智力水平等无关因素进行有效控制,重新设计了实验方案。
新方案如下,首先从不同年级的外国留学生中挑选了40个人,这40个人两两配对,共形成20对。
其中对每对学生的年龄、性别、智力水平、汉语水平、学习汉语的年限等无关因素进行了匹配,使之尽可能相同。
这20对学生进一步分成两组,每对学生的其中一个分到A租,另一个分到B组。
这样,A组和B组各20个人。
对A组学生采用的是集中识字的方式,即在学习课文以前集中学习生字,然后再学习课文;B班采用的是分散识字的方式,即一边学习课文一边学习生字。
在随后的测试中,要求两组学生对40个学过的汉子进行注音,每注对一个得1分,注错不得分。
问,根据测试成绩,两种教学方式对汉字读音的记忆效果是否有差异?。
配对实验样本量的计算公式在进行实验研究时,确定样本量是非常重要的一步,特别是在配对实验中。
配对实验是一种比较两组相关样本的实验设计,例如治疗前后的数据对比、同一组受试者在不同时间点的数据对比等。
确定合适的样本量可以保证实验结果的可靠性和稳定性,避免因样本量不足而导致的偏差和误差。
本文将介绍配对实验样本量的计算公式及其相关内容。
一、配对实验样本量的计算公式。
在进行配对实验时,样本量的计算公式可以使用t检验的配对样本量计算公式。
假设要比较两组相关样本的均值差异,样本量的计算公式为:\[ n = \frac{{(Z_{1-\alpha/2} + Z_{1-\beta})^2 \cdot \sigma^2}}{{\delta^2}} \]其中,n为每组的样本量,Z_{1-\alpha/2}和Z_{1-\beta}分别为显著性水平为α/2和统计功效为1-β对应的Z值,σ为总体标准差,δ为两组均值差异的最小显著性水平。
二、配对实验样本量计算公式的解释。
1. 显著性水平(α),显著性水平是指在假设检验中所允许的犯第一类错误的概率,通常取0.05或0.01。
Z_{1-\alpha/2}为显著性水平为α/2对应的Z值,可以在标准正态分布表中查找得到。
2. 统计功效(1-β),统计功效是指在假设检验中拒绝虚无假设的能力,通常取0.8或0.9。
Z_{1-\beta}为统计功效为1-β对应的Z值,可以在标准正态分布表中查找得到。
3. 总体标准差(σ),总体标准差是指总体数据的离散程度,通常通过样本标准差来估计。
在实际研究中,可以通过历史数据或者小样本试验来估计总体标准差。
4. 均值差异的最小显著性水平(δ),均值差异的最小显著性水平是指在假设检验中所能接受的两组均值差异的最小值。
通常根据实际研究需求和经验来确定。
通过上述配对实验样本量的计算公式,可以确定在给定的显著性水平、统计功效、总体标准差和均值差异的最小显著性水平下,每组样本的大小。
双样本t检验的例子【篇一:双样本t检验的例子】成对t检验pairedtest是对来自同一总体的样本,在不同条件影响下获取的2组样本进行分析,以评价不同条件是否对其有显著影响。
不同条件可以是不同存放环境、不同的测量系统等。
双样本t检验2 samplet-test是对通过2组样本来评判其是否来自2个“总体均值不同”的总体,即评判样本的制造环境是否产生变化。
paired test配对检验法:用在2个样本有关联的情况下,pairedtest在统计原理上与2 sample t-test有本质的不同。
pairedtest忽略成对数据对与对之间的关系,以对间的差来构造检验统计量,只适合有相互联系的两个样本的检验,而2 samplet-test 只适合满足独立条件的两个样本的检验。
它们使用的条件不一样。
2 samplet-test是从整体上考察两组数据间的关系(两组数据的样本大小可以不同,),说白了就是只考虑数据的平均值和方差,pairedtest是考察两组数据中一一对应的两个数据间的关系(既然是一一对应,那两组数据的样本数必须一样)。
举个例子,例如你要考察一台设备改造前后生产的产品有没有差别,那你应该用2sample t-test。
如果你要考察一组产品在长时间存放之后有没有变化,那你应该用p-t。
用哪种方法取决于抽取的两组样本是独立还是配对。
两组样本(成品),一组用a的原材料,另一组用b的原材料。
两组样本平均值的差异不仅包含因a和b不同引起的差异,还包含每组内不同产品间的差异。
这时使用2samplet,实际上是对组间变异和组内变异作比较。
假如样品是机械组装的产品,一组使用的是a的零件,另一组使用的是b的零件,假设此零件可以拆卸、重新装配并且重复装配不产生额外变异。
将使用a的零件的一组产品换装b的零件,得到产品换装零件前后的区别。
这种差异仅是由换装零件造成。
此时应该使用pariedt 。
双样本t检验和配对t检验,应用在不同的场合。
下肢爆发力训练是否能提高弹跳能力的研究
——配对样本T检验
邱志斌
(西北师范大学教育学院09级心理系 200941000125)
[摘要] 为了检验某发展下肢爆发力的训练方法是否有效?现抽取20名某大学的学生进行了为期3个月的发展腿部爆发力的训练,运用实验的方法在训练前后分别测试了每一人的立定跳远成绩。
统计20名学生训练前后的数据,再用配对T检验(Paired Samples T Test)对前后所收集数据的平均数进行差异显著性检验,进而推断该训练方法是否有效。
由配对样本T检验的结果表明该训练方法确实能提高学生的弹跳能力。
[关键词] 训练差异推断配对样本T检验
1.1、问题的提出
在生活中经常会遇到这样的问题,如某种教学方法是否对教学有效,也就是确实能提高学生成绩;某种训练是否对接受训练的人的某一身体机能有改善作用;或者某一种药物对某种病的治疗是否有效果等等,针对以上问题,我们通常就会采取统计学中的配对样本T检验的方法进行分析。
例如:某体育教学组织最新研究出了一种训练下肢爆发力的方法,如何才能知道该训练方法是否能提高学生的下肢爆发力呢?
1.2、配对样本T检验介绍
配对样本T检验通常可分为以下两种情形:
1.2.1、同源配对
也就是同质的被试分别接受两种不同的处理。
例如:为了验证某种记忆方法对改善儿童对词汇的记忆是否有效?先随机抽取40名学生,再随机分为两组。
一组使用该训练方法,一组不使用,三个月后对这两组的学生进行词汇测验,得到数据。
问该训练方法是否对提高词汇记忆量有效?
1.2.2、自身配对
(1)某组同质被试接受接受两种不同的处理。
例如:抽取一个班的同作为被试,分别测验他们的简单视觉反应时和简单听觉反应时。
试问他们的简单视觉反应时和简单听觉反应时是否存在差异?
(2)某组同质被试接受处理前后是否存在差异。
例如:某公司推广了一种新的促销方式,实施前和实施后分别统计了员工的业务量,得到数据。
试问这种促销方式是否有效?
1.3、配对样本T检验注意事项
在配对样本T检验中,强调被试一定要同质,其目的就为了消除目的是额外变量的影响,更能反映自变量和因变量之间的关系。
1.4、配对样本T检验的统计学原理
配对样本t检验的过程,是对两个同质的样本分别接受两种不同的处理或一个样本先后接受不同的处理,来判断不同的处理是否有差别。
这种检验的目的在于根据样本数据对样本来自的配对总体的均值是否有显著差异进行判断的。
在统计学中,若取显著水平α=0.05.若P>0.05,则差异不显著;若P<0.05,则差异显著。
1.5、配对样本T检验的步骤:
1.5.1、提出假设
建立虚无假设H0:μ1= μ2,即先假定两次测验成绩之间没有显著差异,即该训练方法对下肢爆发力没有效果。
确定假设的显著水平α,根据“小概率原理”,通常用5%和1%两个概率为标准,记作α=0.05和α=0.01。
本实验用α=0.05
1.5.2、收集数据
该实例采用实验的方法收集数据。
先随机抽取某大学的20名同学(大学生自然的弹跳发展已经基本停止了,所以就可以排除实验结论是由自身弹跳发展这一额外变量的影响)为研究对象。
采用组内实验设计。
对他们立定跳远的成绩进行测定。
然后对他们进行3个月的训练。
再一次测定他们立定跳远的成绩。
记录他们前后两次的数据。
实验数据如下:
1.5.3、数据处理
第一步:在spss的Variable View中建立数据库。
如下图:
图1:实验数据库建立图。
第二步:输入实验数据。
如下图:
图2 实验数据图
第三步:对数据进行配对样本T检验。
操作步骤:(1)Analyze中的Compare Means,再选取Paired-Samples T Test:
(2)在打开的菜单中选中训练前和训练后,然后“双击”,就可以将训练前和训练后两个变量分别输入variable1和varible2中,再点击OK。
第三步:分析数据
表1训练前后所测成绩的基本描述统计量(Paired Samples Statistics)
Paired Samples Statistics
Mean N
Std.
Deviation
Std. Error
Mean
038ir 1 训练前213.7500 20 17.03827 3.80987 训练后229.1500 20 12.76622 2.85461
表2 训练前后的相关系数及检验(Paired Samples Correlations)
Paired Samples Correlations
N Correlation Sig. Pair 1 训练前& 训练后20 .604 .005
表3配对样本t检验的结果(Paired Samples Test)
Paired Samples Test
Paired Differences
t df
Sig. (2-tailed)
Mean
Std.
Deviation
Std. Error
Mean
95% Confidence Interval
of the Difference
Lower Upper
Pair 1 训练前-
训练后
-15.400 13.80465 3.08681 -21.86078 -8.93922 -4.989 19 .000
1.6、结果解释
由表1看出,训练前20名同学的立定跳远的平均成绩是213.75分,标准差是17.03827,标准误是3.80987。
而训练后20名同学的立定跳远的平均成绩是229.15,标准差是12.776622,标准误是2.85461.
由表2看出,本次样本共抽取20名同学,相关性为0.604,显著水平为0.005。
由于选取的α=0.05,即选取置信度为95%,若P<0.05,则拒绝H0,接受H1,若P>=0.05,则还不能拒绝H0。
由表3看出P〈0.05,即训练前成绩与训练后成绩存在显著性差异。
由此可见,这种训练方法确实能提高学生的下肢爆发力。
参考文献
【1】SPSS 15.0统计分析从入门到精通;刘大海、李宁;清华大学出版社;配对样本T检验的SPSS 操作354页
【2】SPSS 17中文版统计分析典型实例精粹;赖国毅、陈超;电子工业出版社;配对样本T检验实例分析421页
【3】现代心理与教育统计学;张厚粲、徐建平;北京师范大学出版社;配对样本的非参数检验346页
【4】SPSS其实很简单;刘超、吴铮;中国人民大学出版社;配对样本T检验411页
学习spss的心得
从这学期开始接触spss这个数据处理和分析软件到现在,我对本学期学习spss的心得总结了一下几点:
一、我学到了些什么。
Spss的全称是Statistical Package for the Social Science,是为社会科学研究使用的一种分析和处理的软件。
在学习spss之前,我们首先复习了统计学上学过的一些关于的数据问题,包括数据的分类,以及描述统计和推论统计中的相关概念,如总体、样本、参数、统计量、频数和频率。
知道了变量可以分为连续变量和间断变量,针对不同的数据我们应该采用不同的处理方法,才能跟准确的反映由数据带给我们的信息。
接着我们学习了数据的录入和整理,开始简单的认识了spss的操作界面,掌握了每一个菜单的作用。
随后我们学习了一些简单的数据处理,包括数据变量的定义,数据的排序,数据的转置。
学会了求一组数据的集中和离散指标。
包括平均数,中位数,众数,标准差,标准误,四位位差,百分位差。
学习绘制各种统计图形来更形象地反映数据的特征,如条形图,折线图,饼状图等。
以上都是描述统计方面的spss技能,随后我们就开始进入了推论统计阶段。
我们学习了针对
连续变量的T检验和F检验,单因素方差分析和多因素方差分析,相关和回归,以及针对离散变量的卡方检验。
二、对于学习这门课的感觉。
首先spss是一个应用软件,必须注重实用,能够帮助我们解决一些生活中的问题。
因为它主要是为社会科学研究所服务的。
我觉得要想学好spss,应该具备以下三方面的知识:
1、一定的英语基础。
因为spss的版本通用的是英文版本,它的界面、状态栏、菜单栏都是英语。
所以一定要有一定的专业英语基础。
才能更好的操作spss软件。
2、一定的统计学基础,知道每种数据处理所依据的统计学原理。
统计学原理是spss的理论基础。
只有掌握了每一种数据处理的统计学原理后才能更深入的掌握这一统计方法的精髓。
只有掌握了原理以后,你才不会仅仅是死记下每一种数据处理的步骤。
你才能活学活用。
3、一些简单的电脑操作。
三、如何更好的教授spss。
既然spss是一种操作技能,那就在每学完一块内容后,让学生结合校园生活及学习,或者以小组的形式做一些校园和社会调研去研究某一个问题,解释某一种现象。
然后收集数据,在用spss进行数据的处理和分析,这样才能将理论和实践结合起来。
只有自己动手操作后,才能更好的掌握spss的操作技能。