DPRAM空间分配和数据交换流程
- 格式:doc
- 大小:27.50 KB
- 文档页数:2

MPC8280多通道HDLC控制器的应用1 概述时分复用是当前同步通信系统中用以提高数据传输效率的常用方法。
例如第2代移动通信GSM系统,光同步传输网SDH等都是使用时分复用的例子。
在现代通信设备的研发中,常常会遇到高速背板通信、多协议接口、网络管理信令通道等需要同时处理多个同步通信接口数据的情况。
本文介绍了一种采用MPC8280处理器芯片内部的多通道通信控制单元,来处理多个同步通信接口数据的方法。
MPC8280是飞思卡尔公司PowerQUICC II产品线的较新成员。
它采用0.13 μm工艺制造。
内核、I/O的供电电压分别为1.5 V、3.3 V。
MPC8280相比该公司的MPC8260,制造工艺和工作频率均有所提升,但因为核心电压下降,功耗反而下降。
而且,MPC8280片内的DPRAM(双口静态存储器)容量增加了一倍,此外还增加了PCI 和USB。
MPC8280芯片由主内核、SIU、CPM等3个主要功能模块组成,。
MPC8280的处理器主内核称为G2_LE,它是一种PowerPC架构的多级流水线超标量处理器。
MPC8280内核运行频率为166~450 MHz。
SIU模块主要负责60x总线控制、PCI桥及时钟产生。
CPM模块负责处理通信事务,即处理SCC、SMC、FCC、MCC、USB、SPI、I2C等通信控制单元收发数据。
本文所述的多通道HDLC控制器即采用CPM下的MCC(多通道控制器)通信控制单元来实现。
MPC8280片内集成的静态存储器包括DPRAM、全局配置寄存器、SI RAM(串行接口路由表配置空间)。
其中,第1块32 KB的数据DPRAM空间被等分成16个bank(存储空间块)。
CPM 中的通信控制单元除了使用全局配置寄存器进行最基本的参数配置外,还须使用参数配置存储区块进一步配置。
一般CPM中每个通信控制单元都有2个参数配置存储区块,参数配置存储区块均定位在DPRAM中的指定地址。

(1)面积和速度的平衡与互换原则。
“面积”指一个设计所消耗FPGA/CPLD的逻辑资源数量:对于FPGA,可以用所消耗的触发器(FF)和查找表(LUT)来衡量;对于CPLD,常用宏单元(MC)衡量。
“速度”指设计在芯片上稳定运行时所能达到的最高频率,这个频率由设计的时序状况决定,与设计满足的时钟周期、PAD to PAD time、clock setup time、clock hold time和clock-to-output delay等众多时序特征量密切相关。
如果设计的时序余量比较大,运行的频率比较高,则意味着设计的健壮性更强,整个系统的质量更有保证;另一方面,设计所消耗的面积更小,则意味着在单位芯片上实现的功能模块更多,需要的芯片数量更少,整个系统的成本也随之大幅度消减。
相比之下,满足时序、工作频率的要求更重要一些,当两者冲突时,采用速度优先的准则。
从理论上讲,一个设计如果时序余量较大,所能跑的频率远远高于设计要求,那么就能通过功能模块复用减少整个设计消耗的芯片面积,用速度的优势换面积的节约;反之,如果设计的时序要求很高,普通方法达不到设计频率,那么一般可以通过将数据流串并转换,并行复制多个操作模块,对整个设计进行“乒乓操作”和“串并转换”的思想进行处理,在芯片输出模块处再对数据进行“并串转换”。
“面积换速度”的思想:首先将输入的高速数据进行串并转换,然后利用较低的速度对多个模块并行处理所分配的数据,最后将处理结果“并串转换”,完成数据速率的要求。
这样我们在整个处理模块的两端看都是高速数据流。
操作过程中还涉及很多的方法和技巧,例如,对高速数据流进行串并转换,采用“乒乓操作”方法提高数据处理速率等。
(2)硬件原则。
for循环语句的使用:实际工作中,除了描述仿真测试激励(testbench)时使用for循环语句外,极少在RTL级编码中使用for循环,因为for循环会被综合器展开为所有变量情况的执行语句,每个变量独立占用寄存器资源,每条执行语句并不能有效地复用硬件逻辑资源,造成巨大的资源浪费。

stp协议原理交互流程STP协议(Spanning Tree Protocol)是一种用于在以太网中防止环路和冗余的网络协议。
它的原理是通过选择一个主干路径来屏蔽其他冗余路径,从而确保网络的稳定性和可靠性。
STP协议的交互流程如下:1. 网络中的所有交换机都默认为非根交换机,并且处于阻塞状态。
每个交换机都会发送BPDU(Bridge Protocol Data Units)消息来与其他交换机进行通信。
2. BPDU消息包含了交换机的优先级、MAC地址和路径成本等信息。
交换机会通过比较收到的BPDU消息来确定网络中的根交换机。
3. 在收到BPDU消息后,交换机会根据接收到的BPDU消息更新自己的状态。
如果收到的BPDU消息中的优先级比自己的优先级高,交换机将更新自己的优先级,并将发送更改后的BPDU消息。
4. 当交换机通过BPDU消息确定了根交换机后,它将选择一条与根交换机连接的最佳路径,并将其设置为非阻塞状态。
这条路径被称为根端口。
5. 对于与根交换机相连的交换机,它们会选择一条与根交换机连接的最佳路径,并将其设置为非阻塞状态。
这条路径被称为根端口。
6. 对于与根交换机相连的交换机,它们会选择一条与根交换机连接的次优路径,并将其设置为阻塞状态。
这样可以避免环路的产生。
7. 当网络中的拓扑结构发生变化时,交换机会重新计算路径并更新自己的状态。
这样可以保证网络中的路径始终是最优的。
通过STP协议,网络中的交换机可以自动选择最佳路径,并避免环路和冗余。
这样可以提高网络的可靠性和性能,并减少网络故障的发生。
STP协议的原理和交互流程使得网络管理员可以轻松管理和维护以太网网络,确保网络的稳定运行。

DP及其操作流程DP(动态规划)是一种通过空间换时间的优化方法,适用于有重叠子问题和最优子结构性质的问题。
DP算法适用于求解最优化问题,其基本思想是将原问题划分为若干个相互重叠的子问题,逐步求解子问题,并保存每个子问题的最优解,最终得到原问题的最优解。
DP的操作流程包括以下几个步骤:1.确定状态:首先确定问题的状态,即用什么变量来表示问题的状态。
状态可以是用一个或多个变量来描述问题的特征,例如背包问题中的背包容量和物品数量。
2.定义状态转移方程:根据问题的最优子结构性质,定义状态之间的转移关系。
状态转移方程描述了子问题之间的递推关系,可以通过递归或迭代的方式求解。
3.初始化边界条件:确定初始状态的值,即将问题的边界条件定义为初始状态的值。
通常需要设置初始状态或者一些特殊的边界条件,以便开始DP算法的递推过程。
4.递推求解:根据状态转移方程和初始状态,逐步求解子问题,并保存每个子问题的最优解。
通常需要使用一个二维数组或者其他数据结构来保存子问题的解。
5.返回结果:根据子问题的最优解,得到原问题的最优解。
通常是在递推过程中保存一些状态信息,最后根据这些信息恢复原问题的最优解。
DP算法的时间复杂度通常是O(n^2)或者O(n^3),其中n是问题的规模。
通过合适地定义状态转移方程和设计递推过程,可以优化DP算法的时间复杂度,降低计算复杂度。
举个例子来说明DP算法的操作流程:假设有一个背包容量为W,有n 个物品,每个物品的重量分别为w1,w2,...,wn,价值分别为v1,v2,...,vn。
要求在背包容量不超过W的情况下,装入物品的最大总价值。
1.确定状态:定义状态dp[i][j]表示在前i个物品中,背包容量为j 时的最大总价值。
2.定状态转移方程:dp[i][j]的值可以由dp[i-1][j]和dp[i-1][j-w[i]]+v[i]决定,即在前i-1个物品的情况下,背包容量为j的最大总价值与装入第i个物品后的最大总价值之间取最大值。

分组交换工作过程
分组交换是一种通信方式,它将数据分割成多个小块或“分组”,然后在网络中独立传输这些分组。
下面是分组交换工作过程的一般步骤:
1.数据分割:首先,将需要传输的数据分割成若干个小的数据分组,每个分组称为一个数据报或数据包。
2.传输:每个数据分组独立地通过网络进行传输。
每个分组可能会经过不同的路由,这取决于网络的当前状态和路由选择算法。
3.路由选择:在网络中,每个节点(或路由器)会根据其路由表选择最佳路径来传输数据分组。
这是动态的,因为网络状态会不断变化。
4.数据重组:当数据分组到达目的地时,它们会被重新组装成原始的数据。
这个过程也称为数据报重组或数据报恢复。
5.差错控制:为了确保数据的完整性和正确性,可能会使用差错控制机制,如校验和、重传、确认等。
6.流量控制:为了防止网络拥塞,还需要实施流量控制机制,例如使用滑动窗口协议等。
分组交换的好处是它可以根据网络状况动态地选择最佳路径,从而提高了网络的利用率和可靠性。
此外,由于数据分组是
独立传输的,所以可以同时使用多个路径来加速数据的传输。
然而,这也增加了网络协议的复杂性。

单片机数据存储空间分配日期: 2007-03-20 10:391、 data区空间小,所以只有频繁用到或对运算速度要求很高的变量才放到data区内,比如for循环中的计数值。
2、 data区内最好放局部变量。
因为局部变量的空间是可以覆盖的(某个函数的局部变量空间在退出该函数是就释放,由别的函数的局部变量覆盖),可以提高内存利用率。
当然静态局部变量除外,其内存使用方式与全局变量相同;3、确保你的程序中没有未调用的函数。
在Keil C里遇到未调用函数,编译器就将其认为可能是中断函数。
函数里用的局部变量的空间是不释放,也就是同全局变量一样处理。
这一点Keil C做得很愚蠢,但也没办法。
4、程序中遇到的逻辑标志变量可以定义到bdata中,可以大大降低内存占用空间。
在51系列芯片中有16个字节位寻址区bdata,其中可以定义8*16=128个逻辑变量。
定义方法是: bdata bit LedState;但位类型不能用在数组和结构体中。
5、其他不频繁用到和对运算速度要求不高的变量都放到xdata区。
6、如果想节省data空间就必须用large模式,将未定义内存位置的变量全放到xdata 区。
当然最好对所有变量都要指定内存类型。
7、当使用到指针时,要指定指针指向的内存类型。
在C51中未定义指向内存类型的通用指针占用3个字节;而指定指向data区的指针只占1个字节;指定指向xdata区的指针占2个字节。
如指针p是指向data区,则应定义为: char data *p;。
还可指定指针本身的存放内存类型,如:char data * xdata p;。
其含义是指针p指向data区变量,而其本身存放在xdata区。
查看全文 | (已有0条评论) 查看评论发表评论鲜花:0朵送鲜花便便:0坨扔便便单片机原理日期: 2007-03-20 10:37单片机原理随着大规模集成电路的出现及其发展,将计算的 CPU 、 RAM 、 ROM 、定时 / 计数器和多种 I/O接口集成在一片芯片上,形成芯片级的计算机,因此单片机早期的含义称为单片微型计算机,直译为单片机。
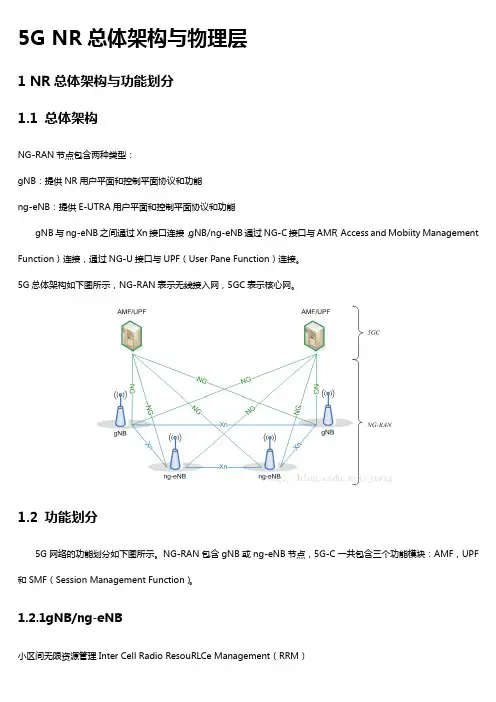
5G NR总体架构与物理层1 NR总体架构与功能划分1.1 总体架构NG-RAN节点包含两种类型:gNB:提供NR用户平面和控制平面协议和功能ng-eNB:提供E-UTRA用户平面和控制平面协议和功能gNB与ng-eNB之间通过Xn接口连接,gNB/ng-eNB通过NG-C接口与AMF(Access and Mobiity Management Function)连接,通过NG-U接口与UPF(User Pane Function)连接。
5G总体架构如下图所示,NG-RAN表示无线接入网,5GC表示核心网。
1.2 功能划分5G网络的功能划分如下图所示。
NG-RAN包含gNB或ng-eNB节点,5G-C一共包含三个功能模块:AMF,UPF 和SMF(Session Management Function)。
1.2.1gNB/ng-eNB小区间无限资源管理Inter Cell Radio ResouRLCe Management(RRM)无线承载控制Radio Bear(RB)Contro连接移动性控制Connection Mobiity Contro测量配置与规定Measurement Configuration and Provision 动态资源分配Dynamic ResouRLCe Aocation1.2.2AMFNAS安全Non-Access Stratum(NAS)Security空闲模式下移动性管理Ide State Mobiity Handing1.2.3UPF移动性锚点管理Mobiity AnchoringPDU处理(与Internet连接)PDU Handing1.2.4SMF用户IP地址分配UE IP Address AocationPDU Session控制1.3 网络接口1.3.1NG接口NG-U接口用于连接NG-RAN与UPF,其协议栈如下图所示。
协议栈底层采用UDP、IP协议,提供非保证的数据交付。

RAM,FIFO及FLASH总结1 RAMRAM(random access memory)随机存储器。
存储单元的内容可按需随意取出或存入,且存取的速度与存储单元的位置无关的存储器。
这种存储器在断电时将丢失其存储内容,故主要用于存储短时间使用的程序。
按照存储信息的不同,机存储器又分为静态随机存储器(Static RAM,SRAM)和动态随机存储器(Dynamic RAM,DRAM)。
1.1S RAMSRAM是Static Random Access Memory的缩写,中文含义为静态随机访问存储器,它是一种类型的半导体存储器。
“静态”是指只要不掉电,存储在SRAM 中的数据就不会丢失。
这一点与动态RAM(DRAM)不同,DRAM需要进行周期性的刷新操作。
然后,我们不应将SRAM与只读存储器(ROM)和Flash Memory相混淆,因为SRAM是一种易失性存储器,它只有在电源保持连续供应的情况下才能够保持数据。
“随机访问”是指存储器的内容可以以任何顺序访问,而不管前一次访问的是哪一个位置。
SRAM中的每一位均存储在四个晶体管当中,这四个晶体管组成了两个交叉耦合反向器。
这个存储单元具有两个稳定状态,通常表示为0和1。
另外还需要两个访问晶体管用于控制读或写操作过程中存储单元的访问。
因此,一个存储位通常需要六个MOSFET。
对称的电路结构使得SRAM的访问速度要快于DRAM。
SRAM比DRAM访问速度快的另外一个原因是SRAM可以一次接收所有的地址位,而DRAM则使用行地址和列地址复用的结构。
SRAM不应该与SDRAM相混淆,SDRAM代表的是同步DRAM (Synchronous DRAM),这与SRAM是完全不同的。
SRAM也不应该与PSRAM 相混淆,PSRAM是一种伪装成SRAM的DRAM。
从晶体管的类型分,SRAM可以分为双极性与CMOS两种。
从功能上分,SRAM可以分为异步SRAM和同步SRAM(SSRAM)。

NR 双激活协议栈(DAPS)切换协议定义: DAPS(Dual Active Protocol Stack)切换可定义为在接收到RRC 消息(切换命令)进行切换后,保持源gNB连接,直到成功随机接入目标gNB 后释放源小区的切换过程。
DAPS切换特性:•UE在接收到HO请求后继续在源小区发送/接收;•UE同时从源小区和目标小区接收用户数据;•完成RACH程序后,UE可以向目标小区进行上行用户数据传输;•DAPS通过在建立目标小区无线链路的同时保持源小区无线链路(包括数据流),减少了切换过程中接近0毫秒的中断;•可通过接口Xn和N2进行DAPS切换;•DAPS切换可用于RLC-AM或RLC-UM承载;我们为什么需要DAPS切换呢?在传统的4G LTE网络和5G NR直到R15,UE通常在与目标小区建立连接之前从源小区释放连接(硬切换)。
因此,上下行传输在UE开始与目标小区通信之前在源小区完成,从而导致UE和基站之间的通信中断几十毫秒。
这种中断对于使用5G的URLCC用例/应用程序非常致命。
因此协议提出了一种解决方案来解决这个问题,作为R16的一部分,称为双活动协议栈(DAPS),其中UE 与源小区连接以保持对用户数据的收发,直到它能够在目标小区中发送和接收用户数据。
这对UE端提出了新的要求,即在切换过程中,短时间内同时在源小区和目标小区收发数据。
类似于软切换。
如上图所示,为了支持DAHO,UE必须保持双栈处于活动状态。
一个用于目标小区的用户平面协议栈,包含PHY、MAC和RLC层,同时保持层2用户平面协议栈处于活动状态,以便在源小区中传输和接收用户数据。
UE同时从源小区和目标小区接收用户数据,PDCP层被重新配置为源和目标用户平面协议栈的一个公共PDCP实体。
为了确保用户数据的顺序传送,在整个切换过程中都保持PDCP序列号(SN)的连续性。
因此,在单个PDCP实体中提供了一个通用的(用于源和目标)重新排序和复制功能。

13.5 双端口RAM在单片机系统中的使用数据获取及交换是多CPU系统的重要组成部分。
在这类系统中,数据交换要求的通信速率往往很高,传统的并行接口和串行接口设计无论在通信速率还是在可靠性方面都不易满足要求。
而双端口RAM(Dual Port RAM,简称DPRAM)具有通信速率高、接口设计简单等特点,是一个较好的实现方案,在设计中得到广泛的应用。
本节以IDT7132为例介绍双端口RAM在单片机系统中的用法。
13.5.1 硬件设计1.IDT7132简介IDT7132是一种高速2 K×16bit双端口静态RAM,且带片内总线仲裁电路,具有两组数据总线和地址总线,两组总线可以同时访问不同的存储器单元。
当两组地址总线完全相同时,由片内总线仲裁逻辑向后访问的一方发出等待信号,使该方进入等待,待另一方访问结束后等待撤消,等待方继续访问这一地址。
由于双端口RAM的特殊结构,使得双机可以方便、快速地进行数据交换,从而大大提高了多CPU系统的并行处理能力。
IDT7132的结构框图如图13.12所示。
当引脚出现下降沿时选中DPRAM,即可通过控制或R/来访问内部存储单元。
IDT7312的核心部分是存储器阵列,用于数据存储,为左右两个端口公用。
这样,位于两个端口的左右处理单元就可以共享一个存储器。
当两个端口对双端口RAM 存取时,IDT7312芯片设计有硬件功能输出,其工作原理如下。
·当左右端口不对同一地址单元存取时,、均为高电平,可正常存储。
·当左右端口对同一地址单元存取时,有一端口的为低电平,禁止数据的存取,此时,两个端口中哪个存取请求信号出现在前,则其对应的为高电平,允许存取,否则其对应的为高电平,禁止其写入数据。
IDT7312的时序与RAM的读写时序非常类似:当CPU选中DPRAM时,引脚出现下降沿,当控制线为高且R/为低时,CPU对内部存储单元进行写操作;而当控制线为低且R/为高时,CPU对内部存储单元进行读操作。

5GNR上下行资源分配为了接收PDSCH或PUSCH,UE一般要先接收PDCCH,其中包含的DCI会指示UE接收PDSCH或PUSCH所需的所有信息,如时频域资源分配信息等。
当UE收到DCI以后,就可以根据DCI的指示对PDSCH或PUSCH进行调度。
下面先介绍下行资源分配,上行和下行有很多共通的地方,然后只介绍上行和下行不同的地方。
一下行资源分配1.时域资源分配DCI中的Time domain resource assignment字段会指示PDSCH的时域位置。
该字段共4个bit,所以其值为0-15,假设其值为m,则m+1指示了一个时域资源分配表格的行索引,该行中的信息就会具体指示PDSCH的时域资源。
指示的方式有两种:1> 一种是直接指示三个信息:PDSCH和调度该PDSCH的PDCCH之间的时隙偏移K0、PDSCH在时隙中的起始符号S以及PDSCH持续的符号长度L,如下表所示:PDSCH mapping type指示了PDSCH时域映射类型Type A或Type B,具体如下表:如果PDCCH没有在一个时隙的前三个符号内接收到,则UE不希望在该时隙内收到Type A的PDSCH,因为这种情况下PDSCH和PDCCH离的太近,UE会来不及解码PDCCH。
假如在时隙n接收到PDCCH,则在下式所指示的时隙中配置PDSCH:式中uPDCCH和uPDSCH分别为PDCCH和PDSCH的子载波间隔;2>另一种是指示PDSCH和调度该PDSCH的PDCCH之间的时隙偏移和一个SLIV值,UE根据SLIV值来计算PDSCH的起始符号和持续的符号个数,计算公式如下:式中S是起始符号,L表示持续的符号个数。
UE会根据不同情形,即加扰PDCCH的RNTI和PDCCH搜索空间类型的不同,确定具体的表格和表格来源。
对于处于初始接入状态的UE,只能用预定义的表格,有三个预定义的表格Default A Default B和Default C,上面用于举例的图1就是Default A,而对于RRC连接态的UE来说,高层信令pdsch-TimeDomainAllocationList会配置一个与预定义表格类似的列表。
大模型训练中dpo的定义全文共四篇示例,供读者参考第一篇示例:大模型训练中巨型数据并行处理技术的一部分是dpo(data parallelism optimization,数据并行优化)的优化。
dpo是一种通过将数据分配到多个计算资源进行并行处理来提高大型模型训练效率的技术。
在大型模型训练中,通常会使用巨大的数据集来训练模型,这些数据集的规模可能达到数十亿条数据。
在这种情况下,单个计算资源可能无法处理如此大规模的数据,而这个时候就需要使用多个计算资源来进行并行处理。
传统的数据并行方法是将整个数据集划分为多个部分,并将这些部分分配给不同的计算资源进行处理。
每个计算资源都会独立地计算模型的梯度,并将这些梯度加和到一起以更新模型的参数。
在大规模数据集上进行训练时,传统的数据并行方法可能会遇到一些问题。
其中之一是数据相互依赖性问题。
因为每个计算资源只看到部分数据,无法获取全局数据的完整信息,这可能会导致模型的收敛速度变慢甚至无法收敛。
为了解决这些问题,研究人员提出了一些dpo的优化方法。
其中之一是跨数据并行(cross-data parallelism)。
跨数据并行是一种新型的数据并行方法,它允许每个计算资源不仅仅在自己的本地数据上进行计算,还可以通过共享一部分数据与其他计算资源进行协作计算。
这样每个计算资源可以获得其他计算资源的数据,从而更好地利用全局数据信息,提高模型的训练效率。
另一个优化方法是基于数据动态调整的并行(dynamic data parallelism)。
在传统的数据并行方法中,数据划分是静态的,即一开始就根据数据集的规模划分好数据,并在整个训练过程中保持不变。
而动态数据并行方法则可以在训练过程中根据收集到的数据信息动态调整数据划分,从而更加灵活地适应不断变化的训练需求。
还有一些其他dpo的优化方法,比如混合并行(hybrid parallelism)、在线学习(online learning)和增强学习(reinforcement learning)。
DPRAM空间分配和数据交换流程本文是PKSPEC 405EP-FPGA板上DPRAM接口的内存空间分配,以及与DSP板交换数据的操作流程。
405EP-FPGA板上DPRAM实际上有64K Bytes,其中前32Kbytes是PPC向DSP发送数据的缓冲区,而后32Kbytes是DSP向PPC发送数据的缓冲区。
前32Kbytes是一个整体,也就是说,PPC每次向DSP发送的数据不超过32Kbytes。
后32Kbytes被分成两个16Kbytes,目前计划每次DSP向PPC发送的数据为16Kbytes,最后的16Kbytes做为预留。
系统的内存分配图如下所示:图1,系统DPRAM分配示意图数据交换流程分为两个部分,一个是PPC向DSP发送数据的流程;一个是DSP向PPC发送数据的流程。
PPC向DSP发送数据流程如下:首先,PPC向发送缓冲区(32Kbytes)写入数据。
写入完成以后,PPC将输出GPIO1置低,然后置高,也就是输出一个低电平有效的低脉冲。
DSP接收到该脉冲以后,从发送缓冲区(对DSP来说是接收缓冲区)接收数据。
总数据量不超过32Kbytes。
至此,PPC到DSP的数据流程结束。
PPC从DSP接收数据流程如下:DSP不断处理模拟前端的数据,并且将准备好的数据不断写入DPAM的接收缓冲区的前16Kbytes(对DSP来说是发送缓冲区)。
等到16Kbytes写入完成之后,DSP从输入GPIO1给PPC的中断发送一个低电平的中断信号。
PPC接收到中断以后,进入中断处理程序接收16Kbytes数据。
并且存储到内部的ramdisk 中(也就是内存中)。
随后以太网发送程序会准备将数据传输会到PC。
然后PowerPC从输出GPIO2发送一个低电平有效的脉冲给DSP,表示PowerPC已经将数据读取完毕。
至此,PPC从DSP接收数据的流程结束。
2007年1月2日薛涛于流星花园。
dpram测试机理DPRAM测试机理一、引言随着科技的发展和计算机应用的广泛应用,对于存储器的需求也越来越高。
而DPRAM(Dual-Port RAM)作为一种特殊的存储器,具有双口读写的特点,被广泛应用于高性能计算机、通信设备和嵌入式系统中。
本文将围绕DPRAM测试机理展开讨论。
二、DPRAM的基本原理DPRAM是一种具有两个独立的读写端口的存储器,这两个端口可以同时进行读写操作而不会造成冲突。
每个端口都有独立的地址线和数据线,通过控制信号进行读写操作。
DPRAM的读写操作是并行进行的,可以大大提高存储器的访问速度。
三、DPRAM测试的重要性DPRAM作为一种关键的存储器设备,其可靠性和稳定性对系统的正常运行至关重要。
因此,对DPRAM进行全面而准确的测试是必不可少的。
DPRAM测试的目的是发现潜在的故障和缺陷,确保DPRAM在各种工作条件下能够正常工作。
四、DPRAM测试方法1. 功能测试:测试DPRAM的基本读写功能,包括读写数据的正确性和稳定性。
通过向DPRAM中写入数据,然后再从DPRAM中读出数据,并与写入的数据进行比较,以验证数据的正确性。
2. 时序测试:测试DPRAM的时序要求是否满足,包括写入和读取的时序要求。
通过设定不同的时序参数,测试DPRAM在各种工作条件下的稳定性和可靠性。
3. 边界测试:测试DPRAM在边界情况下的工作情况,包括最大和最小访问延迟、最大和最小访问频率等。
通过对DPRAM进行极端工作条件下的测试,可以验证DPRAM在极限情况下的可靠性。
4. 写入和读取速度测试:测试DPRAM的写入和读取速度,以验证DPRAM在高速数据传输时的性能。
通过测试DPRAM在不同频率下的写入和读取速度,可以评估DPRAM的性能指标。
五、DPRAM测试的挑战DPRAM测试面临一些挑战,主要包括以下几个方面:1. 多端口冲突:由于DPRAM具有多个读写端口,因此在测试过程中需要防止不同端口之间的冲突。
DPRAM空间分配和数据交换流程
本文是PKSPEC 405EP-FPGA板上DPRAM接口的内存空间分配,以及与DSP板交换数据的操作流程。
405EP-FPGA板上DPRAM实际上有64K Bytes,其中前32Kbytes是PPC向DSP发送数据的缓冲区,而后32Kbytes是DSP向PPC发送数据的缓冲区。
前32Kbytes是一个整体,也就是说,PPC每次向DSP发送的数据不超过32Kbytes。
后32Kbytes被分成两个16Kbytes,目前计划每次DSP向PPC发送的数据为16Kbytes,最后的16Kbytes做为预留。
系统的内存分配图如下所示:
图1,系统DPRAM分配示意图
数据交换流程分为两个部分,一个是PPC向DSP发送数据的流程;一个是DSP向PPC发送数据的流程。
PPC向DSP发送数据流程如下:
首先,PPC向发送缓冲区(32Kbytes)写入数据。
写入完成以后,PPC将输出GPIO1置低,然后置高,也就是输出一个低电平有效的低脉冲。
DSP接收到该脉冲以后,从发送缓冲区(对DSP来说是接收缓冲区)接收数据。
总数据量不超过32Kbytes。
至此,PPC到DSP的数据流程结束。
PPC从DSP接收数据流程如下:
DSP不断处理模拟前端的数据,并且将准备好的数据不断写入DPAM的接收缓冲区的前16Kbytes(对DSP来说是发送缓冲区)。
等到16Kbytes写入完成之后,DSP从输入GPIO1给PPC的中断发送一个低电平的中断信号。
PPC接收到中断以后,进入中断处理程序接收16Kbytes数据。
并且存储到内部的ramdisk 中(也就是内存中)。
随后以太网发送程序会准备将数据传输会到PC。
然后PowerPC从输出GPIO2发送一个低电平有效的脉冲给DSP,表示PowerPC已经
将数据读取完毕。
至此,PPC从DSP接收数据的流程结束。
2007年1月2日薛涛于流星花园。