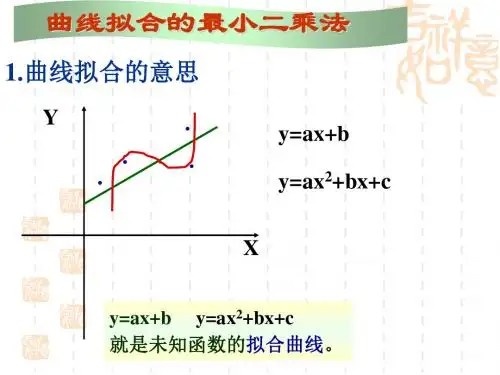
第五章 最小二乘法辨识
- 格式:ppt
- 大小:509.50 KB
- 文档页数:33

系统辨识之最小二乘法方法一、最小二乘一次性算法:首先对最小二乘法的一次性辨识算法做简要介绍如下:过程的黑箱模型如图所示:其中u(k)和z(k)分别是过程的输入输出,)(1-z G 描述输入输出关系的模型,成为过程模型。
过程的输入输出关系可以描述成以下最小二乘格式:)()()(k n k h k z T +=θ (1)其中z(k)为系统输出,θ是待辨识的参数,h(k)是观测数据向量,n(k)是均值为0的随机噪声。
利用数据序列{z (k )}和{h (k )}极小化下列准则函数:∑=-=Lk T k h k z J 12])()([)(θθ (2)使J 最小的θ的估计值^θ,成为最小二乘估计值。
具体的对于时不变SISO 动态过程的数学模型为 )()()()()(11k n k u z B k z z A +=-- (3)应该利用过程的输入、输出数据确定)(1-z A 和)(1-Z B 的系数。
对于求解θ的估计值^θ,一般对模型的阶次a n ,b n 已定,且b a n n >;其次将(3)模型写成最小二乘格式)()()(k n k h k z T +=θ (4)式中=------=T n n T b a b a b b b a a a n k u k u n k z k z k h ],,,,,,,[)](,),1(),(,),1([)(2121 θ (5)L k ,,2,1 =因此结合式(4)(5)可以得到一个线性方程组L L L n H Z +=θ (6)其中==T L TL L n n n n L z z z z )](),2(),1([)](),2(),1([ (7)对此可以分析得出,L H 矩阵的行数为),max(b a n n L -,列数b a n n +。
在过程的输入为2n 阶次,噪声为方差为1,均值为0的随机序列,数据长度)(b a n n L +>的情况下,取加权矩阵L Λ为正定的单位矩阵I ,可以得出:L T L L T L z H H H 1^)(-=θ (8)其次,利用在Matlab 中编写M 文件,实现上述算法。

第五章 广义逆及最小二乘解在应用上见得最频繁的、大约莫过于线性方程组了。
作一番调查或整理一批实验数据,常常归结为一个线性方程组:Ax b =然而是否是相容方程呢?倘若不是,又如何处理呢?最小二乘解是常见的一种处理方法。
其实它不过是最小二乘法的代数形式而已。
广义逆从1935年Moore 提出以后,未得响应。
据说: (S.L.Campbell & C.D.Meyer.Jr Generalized Inverses of Linear Transformations 1979 P9)原因之一,可能是他给出的定义,有点晦涩。
其后,1955年Penrose 给出了现在大都采用的定义以后,对广义逆的研究起了影响,三十年来,广义逆无论在理论还是应用上都有了巨大发展,一直成为了线性代数中不可缺少的内容之一。
为了讨论的顺利进行,我们在第一节中先给出点准备,作出矩阵的奇值分解。
§5.1 矩阵的酉交分解、满秩分解和奇值分解在线行空间中,知道一个线性变换在不同基偶下的矩阵表示是相抵的或等价的。
用矩阵的语言来说,就是:若 ,m n A B C ×∈,倘有非异矩阵()P m n ×,()Q n n ×存在,使B PAQ =则称A 与B 相抵的或等价的。
利用初等变换容易证明m n A C ×∈,秩为r ,则必有P ,Q ,使000r m nI PAQ C ×⎛⎞=∈⎜⎟⎝⎠(5.1-1) 其中r I 是r 阶单位阵。
在酉空间中,上面的说法,当然也成立,如果加上P ,Q 是酉交阵的要求,情形又如何呢?下面就来讨论这个问题。
定理 5.1.1 (酉交分解) m n A C ×∈,且秩为r ,则(),(),,H H m n U m n V n n U U I V V I ∃××==,使00r HU AV Δ⎛⎞=×⎜⎟⎝⎠(m n) (5.1-2) 其中r Δ为r 阶非异下三角阵。


最小二乘法参数辨识1 引言系统辨识是根据系统的输入输出时间函数来确定描述系统行为的数学模型。
现代控制理论中的一个分支。
通过辨识建立数学模型的目的是估计表征系统行为的重要参数,建立一个能模仿真实系统行为的模型,用当前可测量的系统的输入和输出预测系统输出的未来演变,以及设计控制器。
对系统进行分析的主要问题是根据输入时间函数和系统的特性来确定输出信号。
对系统进行控制的主要问题是根据系统的特性设计控制输入,使输出满足预先规定的要求。
而系统辨识所研究的问题恰好是这些问题的逆问题。
通常,预先给定一个模型类μ={M}(即给定一类已知结构的模型),一类输入信号u和等价准则J=L(y,yM)(一般情况下,J是误差函数,是过程输出y和模型输出yM的一个泛函);然后选择使误差函数J达到最小的模型,作为辨识所要求的结果。
系统辨识包括两个方面:结构辨识和参数估计。
在实际的辨识过程中,随着使用的方法不同,结构辨识和参数估计这两个方面并不是截然分开的,而是可以交织在一起进行的。
2 系统辨识的目的在提出和解决一个辨识问题时,明确最终使用模型的目的是至关重要的。
它对模型类(模型结构)、输入信号和等价准则的选择都有很大的影响。
通过辨识建立数学模型通常有四个目的。
①估计具有特定物理意义的参数有些表征系统行为的重要参数是难以直接测量的,例如在生理、生态、环境、经济等系统中就常有这种情况。
这就需要通过能观测到的输入输出数据,用辨识的方法去估计那些参数。
②仿真仿真的核心是要建立一个能模仿真实系统行为的模型。
用于系统分析的仿真模型要求能真实反映系统的特性。
用于系统设计的仿真,则强调设计参数能正确地符合它本身的物理意义。
③预测这是辨识的一个重要应用方面,其目的是用迄今为止系统的可测量的输入和输出去预测系统输出的未来的演变。
例如最常见的气象预报,洪水预报,其他如太阳黑子预报,市场价格的预测,河流污染物含量的预测等。
预测模型辨识的等价准则主要是使预测误差平方和最小。

锂离子电池等效电路参数辨识最小二乘法全文共四篇示例,供读者参考第一篇示例:锂离子电池是现代电子设备中常用的电池类型之一,其能量密度高、重量轻、使用寿命长等优点使其得到广泛应用。
在电子设备设计和性能优化过程中,我们常常需要对锂离子电池的等效电路参数进行辨识。
等效电路参数是描述锂离子电池内部特性的重要参数,包括电阻、电容、电压源等。
辨识锂离子电池的等效电路参数可以帮助我们更准确地模拟锂电池在不同电荷和放电状态下的特性,从而优化电子设备设计,提高性能和效率。
最小二乘法是一种常用的参数辨识方法,可以通过拟合实测数据来估计锂离子电池的等效电路参数。
最小二乘法是一种通过最小化观测值与模型预测值之间的误差平方和来确定参数估计值的方法。
在锂离子电池的等效电路参数辨识中,我们可以将实测数据与模型之间的误差定义为残差,然后通过最小化残差的平方和来求解最优参数估计值。
锂离子电池的等效电路模型一般包括电阻、电容和电压源三个主要参数。
电阻代表电池内部电阻,影响电流的流动;电容代表电池内的电荷存储能力,影响电压的变化;电压源代表电池的电动势,影响电池的输出电压。
通过最小二乘法,我们可以估计出这三个参数的最优值,实现对锂离子电池等效电路的准确描述。
第二篇示例:锂离子电池是当今最为普遍应用于电动汽车、手机、笔记本电脑等设备中的一种电池类型。
为了更好地管理和控制锂离子电池的性能,我们需要了解其等效电路参数。
而通过最小二乘法来辨识锂离子电池的等效电路参数就是一种常用的方法。
一、锂离子电池的等效电路模型锂离子电池的等效电路模型通常包括电池的内阻、电池的电压和电池的容量。
一般来说,我们可以将锂离子电池抽象成一个电压源和一个内阻的串联电路。
其等效电路模型如下图所示:\[V(t) = E(t) - R_i I(t) - R_v \frac{\partial Q(t)}{\partial t}\]\(V(t)\)是电池的电压,\(E(t)\)是电池的开路电压,\(R_i\)是电池的内阻,\(R_v\)是电池的电压响应,\(Q(t)\)是电池的电量,\(I(t)\)是电池的电流。

《系统辨识基础》第17讲要点第5章 最小二乘参数辨识方法5.9 最小二乘递推算法的逆问题辨识是在状态可测的情况下讨论模型的参数估计问题,滤波是在模型参数已知的情况下讨论状态估计问题,两者互为逆问题。
5.10 最小二乘递推算法的几种变形最小二乘递推算法有多种不同的变形,常用的有七种情况:① 基于数据所含的信息内容不同,对数据进行有选择性的加权; ② 在认为新近的数据更有价值的假设下,逐步丢弃过去的数据; ③ 只用有限长度的数据;④ 加权方式既考虑平均特性又考虑跟综能力; ⑤ 在不同的时刻,重调协方差阵P (k ); ⑥ 设法防止协方差阵P (k )趋于零; 5.10.1 选择性加权最小二乘法 把加权最小二乘递推算法改写成[]⎪⎪⎩⎪⎪⎨⎧--=+--=--+-=-)1()]()([)(1)()1()()()()1()()()]1(ˆ)()()[()1(ˆ)(ˆ1k k k k k k k k k k k k k k k z k k k P h K P h P h h P K h K τττθθθI ΛΛ算法中引进加权因子,其目的是便于考虑观测数据的可信度.选择不同的加权方式对算法的性质会有影响,下面是几种特殊的选择:① 一种有趣的情况是Λ()k 取得很大,在极限情况下,算法就退化成正交投影算法。
也就是说,当选择⎩⎨⎧=-≠-∞=0)()1()(,00)()1()(,)(k k k k k k k h P h h P h ττΛ 构成了正交投影算法⎪⎪⎩⎪⎪⎨⎧--=--=--+-=)1()]()([)()()1()()()1()()]1(ˆ)()()[()1(ˆ)(ˆk k k k k k k k k k k k k z k k k P h K P h P h h P K h K τττθθθI 算法初始值取P ()0=I 及 ()θε0=(任定值),且当0)()1()(=-k k k h P h τ时,令K ()k =0。


递推最小二乘法辨识与仿真现在有如下的辨识仿真对象:图中, )(k v 是服从N )1,0(分布的不相关随机噪声。
且)(1-zG )()(11--=z A z B ,)(1-z N )()(11--=zC zD , (1)⎪⎪⎩⎪⎪⎨⎧=+==+-=--------1)(5.00.1)()(7.05.11)(121112111z D z zz B z C z z a z A选择上图所示的辨识模型。
仿真对象选择如下的模型结构:)()2()1()2()1()(2121k w k u b k u b k y a k y a k y +-+-=-+-+可得系统模型为:)()2(5.0)1()2(7.0)1(5.1)(k w k u k u k y k y k y +-+-=-+-- 递推最小二乘法的推导公式如下:)]1(ˆ)()()[()1(ˆ)(ˆ--+-=k k k z k k k θh K θθτ )1()]()([)]()()1([)(11--=+-=--k k k k k k k τP h K I h h PP τ1]1)()1()()[()1()(-+--=k k k k k k h P h h P K τ相关程序如下:% exp053 %%递推最小二乘法程序%clear%清理工作间变量L=55;% M序列的周期y1=1;y2=1;y3=1;y4=0;%四个移位寄存器的输出初始值for i=1:L;%开始循环,长度为Lx1=xor(y3,y4);%第一个移位积存器的输入是第3个与第4个移位积存器的输出的“或”x2=y1;%第二个移位积存器的输入是第3个移位积存器的输出x3=y2;%第三个移位积存器的输入是第2个移位积存器的输出x4=y3;%第四个移位积存器的输入是第3个移位积存器的输出y(i)=y4;%取出第四个移位积存器幅值为"0"和"1"的输出信号,if y(i)>0.5,u(i)=-0.03;%如果M序列的值为"1"时,辨识的输入信号取“-0.03”else u(i)=0.03;%当M序列的值为"0"时,辨识的输入信号取“0.03”end%小循环结束y1=x1;y2=x2;y3=x3;y4=x4;%为下一次的输入信号做准备end%大循环结束,产生输入信号uw=normrnd(0, sqrt(0.1), 1, 55);%加入白噪声figure(1);%第1个图形,伪随机序列stem(u),grid on%以径的形式显示出输入信号并给图形加上网格z(2)=0;z(1)=0;%取z的前两个初始值为零for k=3:55;%循环变量从3到55z(k)=1.5*z(k-1)-0.7*z(k-2)+u(k-1)+0.5*u(k-2)+w(k);%给出理想的辨识输出采样信号endc0=[0.001 0.001 0.001 0.001,0.001]';%直接给出被辨识参数的初始值,即一个充分小的实向量p0=10^6*eye(5,5);%直接给出初始状态P0,即一个充分大的实数单位矩阵E=0.000000005;%相对误差E=0.000000005c=[c0,zeros(5,54)];%被辨识参数矩阵的初始值及大小e=zeros(5,55);%相对误差的初始值及大小for k=3:55; %开始求Kh1=[-z(k-1),-z(k-2),u(k-1),u(k-2),w(k)]'; x=h1'*p0*h1+1; x1=inv(x); %开始求K(k)k1=p0*h1*x1;%求出K的值d1=z(k)-h1'*c0; c1=c0+k1*d1;%求被辨识参数ce1=c1-c0;%求参数当前值与上一次的值的差值e2=e1./c0;%求参数的相对变化e(:,k)=e2; %把当前相对变化的列向量加入误差矩阵的最后一列c0=c1;%新获得的参数作为下一次递推的旧参数c(:,k)=c1;%把辨识参数c 列向量加入辨识参数矩阵的最后一列p1=p0-k1*k1'*[h1'*p0*h1+1];%求出 p(k)的值p0=p1;%给下次用if e2<=E break;%若参数收敛满足要求,终止计算end%小循环结束end%大循环结束c;%显示被辨识参数e;%显示辨识结果的收敛情况%分离参数a1=c(1,:); a2=c(2,:); b1=c(3,:); b2=c(4,:);d1=c(5,:);ea1=e(1,:); ea2=e(2,:); eb1=e(3,:); eb2=e(4,:);figure(2);%第2个图形i=1:55;%横坐标从1到55plot(i,a1,'r',i,a2,':',i,b1,'g',i,b2,':',i,b1,'k') %画出a1,a2,b1,b2的各次辨识结果title('系统辨识结果')%图形标题如果系统中的参数为:⎪⎪⎩⎪⎪⎨⎧+-=+==+-=----------211211121112.01)(5.00.1)()(7.05.11)(z z z D z zz B z C z z a z A 那么系统模型机构为:)2(2.0)1()()2(5.0)1()2(7.0)1(5.1)(-+--+-+-=-+--k w k w k w k u k u k y k y k y 相关程序如下: % exp054.m % %递推最小二乘法编程%clear%清理工作间变量 L=55;% M 序列的周期y1=1;y2=1;y3=1;y4=0;%四个移位寄存器的输出初始值 for i=1:L;%开始循环,长度为Lx1=xor(y3,y4);%第一个移位积存器的输入是第3个与第4个移位积存器的输出的“或” x2=y1;%第二个移位积存器的输入是第3个移位积存器的输出 x3=y2;%第三个移位积存器的输入是第2个移位积存器的输出 x4=y3;%第四个移位积存器的输入是第3个移位积存器的输出 y(i)=y4;%取出第四个移位积存器幅值为"0"和"1"的输出信号,if y(i)>0.5,u(i)=-0.03;%如果M序列的值为"1"时,辨识的输入信号取“-0.03”else u(i)=0.03;%当M序列的值为"0"时,辨识的输入信号取“0.03”end%小循环结束y1=x1;y2=x2;y3=x3;y4=x4;%为下一次的输入信号做准备end%大循环结束,产生输入信号uw=normrnd(0, sqrt(0.1), 1, 55);figure(1);%第1个图形,伪随机序列stem(u),grid on%以径的形式显示出输入信号并给图形加上网格z(2)=0;z(1)=0;%取z的前两个初始值为零for k=3:55;%循环变量从3到55z(k)=1.5*z(k-1)-0.7*z(k-2)+u(k-1)+0.5*u(k-2)+w(k)-w(k-1)+0.2*w(k-2);%给出理想的辨识输出采样信号endc0=[0.001 0.001 0.001 0.001,0.001]';%直接给出被辨识参数的初始值,即一个充分小的实向量p0=10^6*eye(5,5);%直接给出初始状态P0,即一个充分大的实数单位矩阵E=0.000000005;%相对误差E=0.000000005c=[c0,zeros(5,54)];%被辨识参数矩阵的初始值及大小e=zeros(5,55);%相对误差的初始值及大小for k=3:55; %开始求Kh1=[-z(k-1),-z(k-2),u(k-1),u(k-2),w(k),w(k-1),w(k-2)]';x=h1'*p0*h1+1; x1=inv(x); %开始求K(k)k1=p0*h1*x1;%求出K的值d1=z(k)-h1'*c0; c1=c0+k1*d1;%求被辨识参数ce1=c1-c0;%求参数当前值与上一次的值的差值e2=e1./c0;%求参数的相对变化e(:,k)=e2; %把当前相对变化的列向量加入误差矩阵的最后一列c0=c1;%新获得的参数作为下一次递推的旧参数c(:,k)=c1;%把辨识参数c 列向量加入辨识参数矩阵的最后一列p1=p0-k1*k1'*[h1'*p0*h1+1];%求出 p(k)的值p0=p1;%给下次用if e2<=E break;%若参数收敛满足要求,终止计算end%小循环结束end%大循环结束c;%显示被辨识参数e;%显示辨识结果的收敛情况%分离参数a1=c(1,:); a2=c(2,:); b1=c(3,:); b2=c(4,:);d1=c(5,:);d2=c(6,:);d3=c(7,:); figure(2);%第2个图形i=1:55;%横坐标从1到55plot(i,a1,'r',i,a2,':',i,b1,'g',i,b2,':',i,d1,'k',i,d2,':',i,d3,'*') %画出a1,a2,b1,b2的各次辨识结果title('系统辨识结果')%图形标题。

第五章OLS估计量的大样本性质OLS(最小二乘法)估计是一种常用的线性回归方法,通过最小化观测值残差的平方和来估计参数。
在大样本情况下,OLS估计量具有以下几个重要的性质。
一、一致性:OLS估计量在大样本情况下是一致的。
也就是说,当样本容量趋于无穷大时,OLS估计量会以概率1收敛于真实参数值。
证明一致性的一种常用方法是将OLS估计量写为样本均值的形式,并应用大样本理论方法,如中心极限定理或大数定律。
二、渐进正态性:OLS估计量在大样本情况下服从正态分布。
也就是说,当样本容量趋于无穷大时,OLS估计量的分布接近于一个正态分布。
这个性质在大样本下的推论非常重要,它使得我们可以使用正态分布的性质来进行参数估计的推断,如置信区间和假设检验。
三、渐进有效性:OLS估计量在大样本情况下是渐进有效的。
也就是说,在满足一定条件下,OLS估计量的方差趋近于零,且比其他一些估计量的方差更小。
这个性质使得OLS估计量成为一种较为理想的估计方法,因为它具有较小的方差,可以提供较准确的估计结果。
四、渐进偏差:OLS估计量在大样本情况下存在偏差。
也就是说,当样本容量趋于无穷大时,OLS估计量的期望值与真实参数值之间存在一定的差距。
这个性质说明,在大样本下,OLS估计量可能并不能完全准确地估计出真实的参数值,但由于一致性的性质,它依然可以提供较为可靠的估计结果。
总结起来,OLS估计量在大样本情况下具有一致性、渐进正态性、渐进有效性和渐进偏差等性质。
这些性质使得OLS成为常用的估计方法,并为进行参数估计的推断提供了理论依据。
然而,这些性质的成立都要求满足一定的条件,如误差项的独立性、同方差性和正态性等。
因此,在实际应用中,我们需要对数据进行必要的检验和验证,以确保这些条件的成立,从而保证OLS估计量的有效性和准确性。

文章标题:深入探讨多变量系统的最小二乘辨识问题在工程和科学研究中,我们经常面对多变量系统的最小二乘辨识问题。
这个问题涉及到了多个变量之间的关系、参数的估计以及模型的拟合,对于系统建模和预测具有重要意义。
在本文中,我们将从简单的基础概念开始,逐步深入探讨多变量系统的最小二乘辨识问题,帮助读者全面理解这一重要概念。
1. 多变量系统的基本概念在多变量系统中,我们通常研究多个相互关联的变量之间的数学模型。
这些变量可以是物理量、经济指标、生物参数等,它们之间存在着一定的关联和影响。
多变量系统的最小二乘辨识问题即是要通过已知的数据,利用最小二乘法来估计系统的参数,找到最优的模型拟合。
2. 最小二乘法的原理和应用最小二乘法是一种常用的参数估计方法,它通过最小化观测值与模型预测值之间的误差平方和来求解参数。
在多变量系统中,最小二乘法可以用来估计系统的多个参数,并得到最佳拟合的模型。
通过推导最小二乘法的数学公式,我们可以更好地理解其原理和应用。
3. 多变量系统的最小二乘辨识问题推导在进行多变量系统的最小二乘辨识时,我们首先需要建立适当的数学模型,并根据已知数据对模型进行估计。
推导多变量系统的最小二乘辨识问题涉及到矩阵运算、最优化理论等数学知识,需要深入分析和推演。
通过推导过程,我们可以清晰地理解多变量系统最小二乘辨识问题的数学基础和核心思想。
4. 我对多变量系统的最小二乘辨识问题的理解对于多变量系统的最小二乘辨识问题,我个人的观点是……(此处插入个人观点)总结回顾:通过本文的深入探讨,我们对多变量系统的最小二乘辨识问题有了更加全面、深刻和灵活的理解。
我们从基本概念出发,逐步介绍了最小二乘法的原理和应用,并对多变量系统的最小二乘辨识问题进行了详细推导。
我也共享了个人对这一主题的理解和观点。
希望本文能帮助读者更好地理解多变量系统的最小二乘辨识问题,并在实际应用中加以运用。
通过本文的撰写,我将多变量系统的最小二乘辨识问题进行了深入的探讨,并在知识的文章格式下进行了合理的编排与呈现。
广义最小二乘法第五章广义最小二乘法当计量经济学模型同时存在序列相关和异方差,而且随机误差项的方差-协方差矩阵未知时我们可以考虑使用广义最小二乘法(gls)。
即下列模型:y=xβ+μ满足这样一些条件:e(μ)=0cov(μμ')=δ2ωω=11ω1221ω221ωn2...ω1n...ω2nωnn设立ω=dd'用d左乘y=xβ+μ的两边,得到一个新的模型d-1y=d-1xβ+d-1μy=x**-1β+μ*(1)该模型具备同方差性和随机误差相互独立性。
因为可以证明:e(μ*μ*')=δ2i于是需用普通最轻二乘法估算(1)式,获得的参数估计结果为ˆ=(x*'x*)-1x*'y*β=(x'ωx)x'ωy整个过程最重要的一步就是要估计ω,当模型存在一阶自相关时。
我们取-1-1-1ρn-1ρn-2ρn-1ρn-21案例四:广义最小二乘法在这里我们举例子去表明广义最轻二乘法的应用领域。
在探讨这个问题时所使用的数据如下表中5.1右图:首先我们计算ρ,我们可以直接根据ols估计出来的dw来计算,ols估计出来的结果为下表5.2:可以根据ρ=1-dw/2,dw=0.8774,因此ρ=0.5613,在这个基础上,我们可以得出结论这个方差-协方差矩阵。
方差协方差矩阵可以由以下一个程序去赢得:!p=0.5613matrix(17,17)fac1for!i=1to17fac1(!i,!i)=1for!j=1to17for!i=!j+1to17fac1(!i,!j)=!p^(!i-!j)fac1(!j,!i)=fac1(!i,!j)得到的矩阵结果为下表5.3下面再展开cholosky水解,获得d,展开cholosky水解时所用至的命令如下:1sym(17,17)fact1matrixfact1=@cholesky(fact)得到的fact1矩阵如下解fact1的逆矩阵就可以将数据展开切换,获得m2和gdp,解逆矩阵时使用的命令如下:matrix(17,17)fact2**fact2=@inverse(fact)得到的fact1矩阵的逆矩阵fact2如下m2*=m2*fact2gdp*=gdp*fact这样就可以获得一组转换后的数据,数据如下再对这组数据进行普通最小二乘法就可以得到这个方程的广义最小二乘法的估计结果,结果如下:可以看见,采用广义最轻二乘法后,序列有关的情况获得提升。
最小二乘法参数辨识1 引言系统辨识是根据系统的输入输出时间函数来确定描述系统行为的数学模型。
现代控制理论中的一个分支。
通过辨识建立数学模型的目的是估计表征系统行为的重要参数,建立一个能模仿真实系统行为的模型,用当前可测量的系统的输入和输出预测系统输出的未来演变,以及设计控制器。
对系统进行分析的主要问题是根据输入时间函数和系统的特性来确定输出信号。
对系统进行控制的主要问题是根据系统的特性设计控制输入,使输出满足预先规定的要求。
而系统辨识所研究的问题恰好是这些问题的逆问题。
通常,预先给定一个模型类μ={M}(即给定一类已知结构的模型),一类输入信号u和等价准则J=L(y,yM)(一般情况下,J是误差函数,是过程输出y和模型输出yM的一个泛函);然后选择使误差函数J达到最小的模型,作为辨识所要求的结果。
系统辨识包括两个方面:结构辨识和参数估计。
在实际的辨识过程中,随着使用的方法不同,结构辨识和参数估计这两个方面并不是截然分开的,而是可以交织在一起进行的。
2 系统辨识的目的在提出和解决一个辨识问题时,明确最终使用模型的目的是至关重要的。
它对模型类(模型结构)、输入信号和等价准则的选择都有很大的影响。
通过辨识建立数学模型通常有四个目的。
①估计具有特定物理意义的参数有些表征系统行为的重要参数是难以直接测量的,例如在生理、生态、环境、经济等系统中就常有这种情况。
这就需要通过能观测到的输入输出数据,用辨识的方法去估计那些参数。
②仿真仿真的核心是要建立一个能模仿真实系统行为的模型。
用于系统分析的仿真模型要求能真实反映系统的特性。
用于系统设计的仿真,则强调设计参数能正确地符合它本身的物理意义。
③预测这是辨识的一个重要应用方面,其目的是用迄今为止系统的可测量的输入和输出去预测系统输出的未来的演变。
例如最常见的气象预报,洪水预报,其他如太阳黑子预报,市场价格的预测,河流污染物含量的预测等。
预测模型辨识的等价准则主要是使预测误差平方和最小。