DNA序列比对同源性分析图解BLAST
- 格式:doc
- 大小:231.00 KB
- 文档页数:7

序列比对,绝大多数战友都会想到BLAST,但BLAST的使用确实又是一个很大的难题,因为他的功能比较强悍,里面涉及到的知识比较多,而且比对结束后输出的结果参数(指标)又很多.如果把BLAST的使用详细的都讲出来,我想我发帖发到明天也发不完,更何况我自己也不是完全懂得BLAST的使用。
所以我在这里也就“画龙点睛"——以比对核酸序列为例来给大家介绍一下BLAST的使用,也算是BLAST的入门课程吧。
请看帖的战友好好体会,如果你用心看,在看帖完毕之后BLAST的基本使用(包括其他序列的比对)应该没有问题了。
一、打开BLAST 页面,http://www。
ncbi.nlm.nih。
go/BLAST/ 打开后如图所示:(缩略图,点击图片链接看原图)对上面这个页面进行一下必要的介绍:BLAST的这个页面主体部分(左面)包括了三部分:BLAST Assembled Genomes、Basic BLAST、Specialized BLAST.相信大家可以看懂这三个短语的意思,我就不多说了;我要说的是,可以认为这是三种序列比对的方法,或者说是BLAST的三条途径。
第一部分BLAST Assembled Genomes就是让你选择你要比对的物种,点击相应物种之后即可进入比对页面.第二部分Basic BLAST包含了5个常用的BLAST,每一个都附有简短的介绍。
第三部分Specialized BLAST是一些特殊目的的BLAST,如IgBLAST、SNP等等,这个时候你就需要在Specialized BLAST部分做出适当的选择了。
总之,这是一个导航页面,它的目的是让你根据自己的比对目的选择相应的BLAST 途径。
下面以最基本的核酸序列比对来谈一下BLAST的使用,期间我也会含沙射影的说一下其他序列比对的方法.二、点击Basic BLAST部分的nucleotide blast链接到一个新的页面.打开后如图所示:screen.width-333)this。

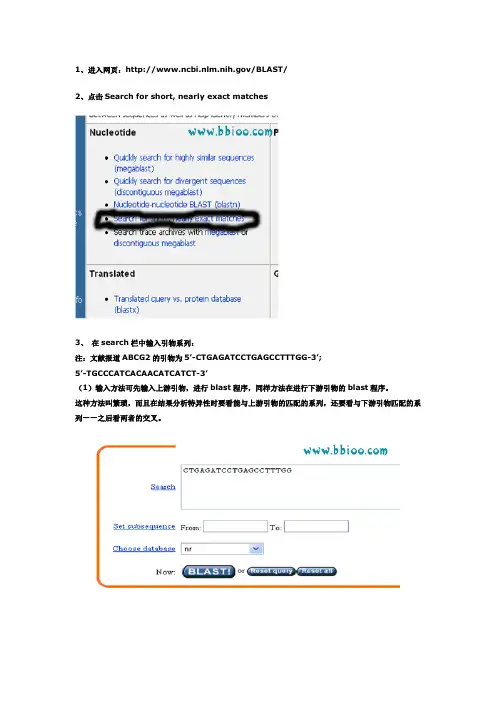
1、进入网页:/BLAST/2、点击Search for short, nearly exact matches3、在search栏中输入引物系列:注:文献报道ABCG2的引物为5’-CTGAGATCCTGAGCCTTTGG-3’;5’-TGCCCATCACAACATCATCT-3’(1)输入方法可先输入上游引物,进行blast程序,同样方法在进行下游引物的blast程序。
这种方法叫繁琐,而且在结果分析特异性时要看能与上游引物的匹配的系列,还要看与下游引物匹配的系列——之后看两者的交叉。
(2)简便的做法是同时输入上下游引物:有以下两种方法。
输入上下游引物系列都从5’——3’。
A、输入上游引物空格输入下游引物B、输入上游引物回车输入下游引物4、在options for advanced blasting中:select from 栏通过菜单选择Homo sapiensExpect后面的数字改为105、在format中:select from 栏通过菜单选择Homo sapiens Expect后面的数字填上0 106、点击网页中最下面的“BLAST!”7、出现新的网页,点击Format!8、等待若干秒之后,出现results of BLAST的网页。
该网页用三种形式来显示blast的结果。
(1)图形格式:图中①代表这些序列与上游引物匹配、并与下游引物互补的得分值都位于40~50分图中②代表这些序列与上游引物匹配的得分值位于40~50分,而与下游引物不互补图中③代表这些序列与下游引物互补的得分值小于40分,而与上游引物不匹配通过点击相应的bar可以得到匹配情况的详细信息。
(2)结果信息概要:从左到右分别为:A、数据库系列的身份证:点击之后可以获得该序列的信息B、系列的简单描述C、高比值片段对(high-scoring segment pairs, HSP)的字符得分。
按照得分的高低由大到小排列。
得分的计算公式=匹配的碱基×2+0.1。






最近看到很多战友在论坛上询问如何查询基因序列、如何进行引物设计、如何使用BLAST 进行序列比对……,这些问题在 NCBI 上都可以方便的找到答案。
现在我就结合我自己使用 NCBI的一些经历(经验)跟大家交流一下 BCBI 的使用。
希望大家都能发表自己的使用心得,让我们共同进步!我分以下几个部分说一下 NCBI 的使用:Part one 如何查找基因序列、mRNA、PromoterPart two 如何查找连续的 mRNA、cDNA、蛋白序列Part three 运用 STS 查找已经公布的引物序列Part four 如何运用 BLAST 进行序列比对、检验引物特异性特别感谢本版版主,将这个帖子置顶!从发帖到现在,很多战友对该帖给与了积极的关注,在此向给我投票的(以及想给我投票却暂时不能投票的)各位战友表示真诚的感谢,谢谢各位战友!请大家对以下我发表的内容提出自己的意见。
关于NCBI 其他方面的使用也请水平较高的战友给予补充First of all,还是让我们从查找基因序列开始。
第一部分利用Map viewer 查找基因序列、mRNA 序列、启动子(Promoter)下面以人的 IL6(白细胞介素 6)为例讲述一下具体的操作步骤1.打开Map viewer 页面,网址为:/mapview/index.html 在 search 的下拉菜单里选择物种,for 后面填写你的目的基因。
操作完毕如图所示:2.点击“GO”出现如下页面:3.在步骤二图示的右下角有一个Quick Filter,下面是让你选择的几个复选框,在Gene 前面的小方框里打勾,然后点击Filter. 出现下图:说明一下:1、染色体的红色区域即为你的目的基因所处位置。
2、下面参考序列给出了三个,是不同的部门做出来的,经我验证,序列有微小的差异,但总体来说基本相同。
尽管你分别点击后,序列代码、序列代码等有所差异,但碱基基本一致,不影响大家研究分析序列。

NCBI中Blast序列比对结果解释2011-07-26 20:30:12| 分类:生物信息学|字号大中小订阅NCBI中Blast可以用来进行序列比对、检验引物特异性Blast导航主页面主体包括三部分BLAST Assembled Genomes选择你要对比的物种,点击物种之后即可进入对比页面Basic BLAST包含5个常用的Blast,每一个都附有简单介绍Specialized BLAST是一些特殊目的的Blast,如Primer-BLAST、IgBLAST根据需要做出选择本人本学期学习了最基本的核苷酸序列的比对点击Basic BLAST部分的nucleotide链接到一个新的页面,打开后的页面特征:大体上包括三个部分Enter Query Sequence部分可以让我们输入序列,其中的Job Title部分可以为本次工作命一个名字Choose Search Set部分可以选择要与目的序列比对的物种或序列种类。
其中的Entrez Query可以对比对结果进行适当的限制。
Program Selection部分可以选择本次对比的精确度,种内种间等等。
其次Blast按钮下面有一个“Algorithm parameters”算法参数,可设置参数。
点击Blast后,出现的页面大体上包括四个部分一.所询问和比对序列的简单信息1.询问序列的简单信息——名称、描述、分子类型、序列长度2.所比对数据库的名称、描述和所用程序二.Graphic Summary——blast结果图形显示相似度颜色图(黑、蓝、绿、粉红、红,相似度由低到高)三.Descriptions——blast结果描述区1.到其他数据库的链接2.描述以表格的形式呈现(以匹配分值从大到小排序)(1)Accession下程序比对的序列名称,点击相应的可以进入更为详细的map viewer(2)Descriptions下是对所比对序列的简单描述接下来是5个结果数值:(3)Max score匹配分值,点击可进入第四部分相应序列的blast的详细比对结果(4)Total score总体分值(5)Query coverage覆盖率(6)E value——E(Expect)值,表示随机匹配的可能性。

序列相似性⽐较与同源性分析⾸先应该注意区分序列相似性与序列同源性的关系,序列相似不⼀定同源,但是判定同源性关系的时候有些算法(Maximum likelihood除外)要考虑到序列相似性。
序列相似性是将待研究序列与DNA或蛋⽩质序列库进⾏⽐较,⽤于确定该序列的⽣物属性,也就是找出与此序列相似的已知序列是什么,完成这⼀⼯作只需要⽤到两两序列⽐较算法,常⽤的程序包有BLAST,FASTA等。
同源性分析是将待研究序列加⼊到⼀组与之同源,但是来⾃不同物种的序列中进⾏多序列⽐对,以确定该序列与其它序列间的同源性⼤⼩。
多序列⽐较算法常⽤的程序包有CLUSTAL等。
1、序列⽐对,从数据库中寻找相似序列:⾸先打开NCBI的BLAST⽹站:,选择protein blast,然后将待⽐对序列粘贴进去,进⾏BLAST(⼀些参数的设置收藏夹或百度)。
等待⼀定时间后将会出现与所选数据库的⽐对结果,按照打分⾼低将top100(可以设置成其他数值)的序列显⽰出来,然后可以将该100条序列下载下来。
存成test.fasta⽂件。
这个⽂件就是在mega中进⾏多序列⽐对建树所⽤的⽂件。
2、多序列⽐对:打开mega,ALIGN-BUILDALIGNMENT-Create a new alignment-protein-open-retrieve sequences from file-no -test.fasta(或者直接拖动进去,或者双击打开test.fasta),然后点击Alignment——Align by ClustalW——OK——OK。
然后⽐对成功,选择Data——Export Alignment——MEGA format保存⽂件为test.meg,可以关闭Align会话框。
3、构建进化树:打开test.meg。
点击PHYLOGENY——选择最上⾯的ML⽅法,参数可以选择默认参数。
就出现了进化树。
当然⼀些参数最好还是⽤到,⽐如说可信度验证的次数设置最好要⼤于等于500次。
NCBI在线Blast的图文说明Blast(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST 结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、BLASTP 是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN 是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
NCBI的在线blast:/Blast.cgi1、进入在线blast界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
NCBI在线blast页面2、粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
NCBI在线blast页面3、blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
blast参数设置4、注意一下你输入的序列长度。
最近看到很多战友在论坛上询问如何查询基因序列、如何进行引物设计、如何使用BLAST 进行序列比对……,这些问题在 NCBI 上都可以方便的找到答案。
现在我就结合我自己使用 NCBI的一些经历(经验)跟大家交流一下 BCBI 的使用。
希望大家都能发表自己的使用心得,让我们共同进步!我分以下几个部分说一下 NCBI 的使用:Part one 如何查找基因序列、mRNA、PromoterPart two 如何查找连续的 mRNA、cDNA、蛋白序列Part three 运用 STS 查找已经公布的引物序列Part four 如何运用 BLAST 进行序列比对、检验引物特异性特别感谢本版版主,将这个帖子置顶!从发帖到现在,很多战友对该帖给与了积极的关注,在此向给我投票的(以及想给我投票却暂时不能投票的)各位战友表示真诚的感谢,谢谢各位战友!请大家对以下我发表的内容提出自己的意见。
关于NCBI 其他方面的使用也请水平较高的战友给予补充First of all,还是让我们从查找基因序列开始。
第一部分利用Map viewer 查找基因序列、mRNA 序列、启动子(Promoter)下面以人的 IL6(白细胞介素 6)为例讲述一下具体的操作步骤1.打开Map viewer 页面,网址为:/mapview/index.html 在 search 的下拉菜单里选择物种,for 后面填写你的目的基因。
操作完毕如图所示:2.点击“GO”出现如下页面:3.在步骤二图示的右下角有一个Quick Filter,下面是让你选择的几个复选框,在Gene 前面的小方框里打勾,然后点击Filter. 出现下图:说明一下:1、染色体的红色区域即为你的目的基因所处位置。
2、下面参考序列给出了三个,是不同的部门做出来的,经我验证,序列有微小的差异,但总体来说基本相同。
尽管你分别点击后,序列代码、序列代码等有所差异,但碱基基本一致,不影响大家研究分析序列。
1、进入网页:/BLAST/
2、点击Search for short, nearly exact matches
3、在search栏中输入引物系列:
注:文献报道ABCG2的引物为5’-CTGAGATCCTGAGCCTTTGG-3’;
5’-TGCCCATCACAACATCATCT-3’
(1)输入方法可先输入上游引物,进行blast程序,同样方法在进行下游引物的blast程序。
这种方法叫繁琐,而且在结果分析特异性时要看能与上游引物的匹配的系列,还要看与下游引物匹配的系列——之后看两者的交叉。
(2)简便的做法是同时输入上下游引物:有以下两种方法。
输入上下游引物系列都从5’——3’。
A、输入上游引物空格输入下游引物
B、输入上游引物回车输入下游引物
4、在options for advanced blasting中:
select from 栏通过菜单选择Homo sapiens
Expect后面的数字改为10
5、在format中:
select from 栏通过菜单选择Homo sapiens Expect后面的数字填上0 10
6、点击网页中最下面的“BLAST!”
7、出现新的网页,点击Format!
8、等待若干秒之后,出现results of BLAST的网页。
该网页用三种形式来显示blast的结果。
(1)图形格式:
图中①代表这些序列与上游引物匹配、并与下游引物互补的得分值都位于40~50分
图中②代表这些序列与上游引物匹配的得分值位于40~50分,而与下游引物不互补
图中③代表这些序列与下游引物互补的得分值小于40分,而与上游引物不匹配
通过点击相应的bar可以得到匹配情况的详细信息。
(2)结果信息概要:
从左到右分别为:
A、数据库系列的身份证:点击之后可以获得该序列的信息
B、系列的简单描述
C、高比值片段对(high-scoring segment pairs, HSP)的字符得分。
按照得分的高低由大到小排列。
得分的计算公式=匹配的碱基×2+0.1。
举例:如果有20个碱基匹配,则其得分为40.1。
D、E值:代表被比对的两个序列不相关的可能性。
E值最低的最有意义,也就是说序列的相似性最大。
设定的E值是我们限定的上限,E值太高的就不显示了
E、最后一栏有的有UEG的字样,其中:
U代表:Unigene数据库
E代表:GEO profiles数据库
G代表:Gene数据库
(3)结果详细信息:
①圈出来的部分代表序列的信息
②第一个大括号代表上游引物与该序列的正链的匹配情况:
共有21个碱基匹配,得分42.1分,E值为0.020
上游引物与序列的2143~2163位点匹配
③第二个大括号代表下游引物与该序列的负链的匹配情况:
共有20个碱基匹配,得分40.1分,E值为0.077。
下游引物与该序列的29360~29379位点互补
注意点:
①上游引物为20个碱基,为什么会变成21个碱基呢?这是因为下游引物的第一个碱基为T,刚好与系列的2163位点的T匹配,因此下游引物的开头的第一个碱基被当成了上游引物了。
同理,上游引物的最后一个碱基为G,被当成了下游引物了。
通过寻找有没有与1~20位点、20~40位点完全匹配的序列,就可以避免这个因素的干扰了。
②为什么与上下游引物匹配的ABCG2序列有多种?
A、为同一个基因来源的不同的mRNA片段
B、为该基因的DNA系列
C、为同一个基因来源的不同的cDNA片段。
结果判断:
①验证文献报道的引物是否正确:如果你可以在所显示的结果中找出你的目的基因,一般说明你的引物正确性没问题。
如果你blast后没有发现你的目的基因,或者分值很低,该引物就可能不适合用
②检测该对引物是否可与其它序列匹配,引起PCR的非特异性扩增。
如果找到了你的目的基因名称,而且找到了一大批同物种的不同基因,(上下游引物分别搜索到相同的基因),而且分数也较高。
这时表明你的引物设计的特异性不高,极有可能在你的扩增产物中出现非特异性产物。