实验四 分支限界法实现单源最短路径
- 格式:doc
- 大小:100.00 KB
- 文档页数:6

单元最短路径问题分支限界法【序】单元最短路径问题:分支限界法解析【引】在计算机科学中,图论问题一直是研究的热点之一。
而图的最短路径问题更是其中一个经典的困难问题。
在图中,单元最短路径问题就是要找到两个顶点之间的最短路径。
而在解决这个问题的过程中,我们可以借助分支限界法,来帮助我们找到最优的解。
本文将深度分析单元最短路径问题及分支限界法,以帮助读者全面理解并掌握这一问题解决方法。
【1】什么是单元最短路径问题?单元最短路径问题是图论中常见的一个问题,它要求在一个加权有向图或无向图中,找到两个给定顶点之间的最短路径。
该问题的解决方法包括了广度优先搜索、迪杰斯特拉算法等多种方法,其中分支限界法是一种常用的解决方法之一。
【2】分支限界法的基本思想分支限界法是一种通过搜索解空间来找到最优解的方法。
它通过将问题空间划分为一系列子问题,并不断搜索当前最优解的子空间,从而逐渐缩小问题空间,最终找到最优解。
【3】分支限界法在单元最短路径问题中的应用在解决单元最短路径问题时,分支限界法可以通过以下步骤来实施:1. 确定初始解和问题空间:选择一个顶点作为起始点,并设置一个初始解,例如将起始点的路径长度设置为0,其他顶点的路径长度设置为无穷大。
2. 扩展节点:从初始解开始,按照一定的扩展策略选择下一个节点进行扩展。
在单元最短路径问题中,我们可以选择将当前节点的邻接节点添加到解空间中。
3. 更新当前解:根据当前解空间中的节点,更新各节点的路径长度。
4. 剪枝:根据一定的条件,判断是否要剪去一些节点,从而缩小问题空间。
5. 重复上述步骤:不断迭代地重复上述步骤,直到找到最优解或者问题空间为空。
【4】为什么分支限界法适用于单元最短路径问题?分支限界法适用于单元最短路径问题的原因有以下几点:1. 分支限界法能够保证找到最优解。
通过不断地缩小问题空间,分支限界法能够找到最小的路径长度。
2. 分支限界法具有较高的搜索效率。
在每一步中,分支限界法都能够通过剪枝操作,排除一部分不可能达到最优解的节点,从而减少了搜索空间。


实验四分支限界法实现单源最短路径09电信实验班I09660118 徐振飞一、实验名称实现书本P194页所描述的单源最短路径问题二、实验目的(1)掌握并运用分支限界法基本思想(2)运用分支限界法实现单源最短路径问题(3)区分分支限界算法与回溯算法的区别,加深对分支限界法理解三、实验内容和原理(1)实验原理解单源最短路径问题的优先队列式分支限界法用一极小堆(本次实验我采用java.util包中的优先队列类PriorityQueue来实现)来存储活结点表。
其优先级是结点所对应的当前路长。
算法从图G的源顶点s和空优先队列开始。
结点s被扩展后,它的儿子结点被依次插入堆中。
此后,算法从堆中取出具有最小当前路长的结点作为当前扩展结点,并依次检查与当前扩展结点相邻的所有顶点。
如果从当前扩展结点i到顶点j有边可达,且从源出发,途经顶点i再到顶点j的所相应的路径的长度小于当前最优路径长度,则将该顶点作为活结点插入到活结点优先队列中。
这个结点的扩展过程一直继续到活结点优先队列为空时为止。
(2)实验内容测试用例:123456 342761395四、源程序import java.util.*;public class ShortestPath{private int n;private double matrix[][] = null;private double minpath[];public ShortestPath(int n){this.n = n;matrix = new double[n+1][n+1];minpath = new double[n+1];for(int i=1;i<=n;i++){minpath[i] = Double.MAX_VALUE;}//初始化图getGraphMatrix();}public void getGraphMatrix(){//初始化为不能连通for(int i=1;i<=n;i++){for(int j=1;j<=n;j++){matrix[i][j] = Double.MAX_VALUE;}}System.out.println("请输入边总数:");Scanner scan = new Scanner(System.in);int m = scan.nextInt();System.out.println("依次输入两个顶点号(1~"+n+")和边长:例如 1 2 3");for(int i=0;i<m;i++){int a,b;double d;a = scan.nextInt();b = scan.nextInt();d = scan.nextDouble();if(a<1 || b<1){i--;System.out.println("顶点号不能小于1");continue;}if(a>n||b>n){i--;System.out.println("顶点号不能大于"+n);continue;}matrix[a][b] = d;}}/***@param求以第i个节点为起点的单源最短路径*/public void shortpath(int i){minpath[i] = 0;double curlen = 0;PriorityQueue<Node> heap = new PriorityQueue();Node cur = new Node(i,0);heap.add(cur);while(!heap.isEmpty()){for(int j=1;j<=n;j++){if(matrix[cur.i][j]<Double.MAX_VALUE&& cur.len+matrix[cur.i][j]<minpath[j]){minpath[j] = cur.len+matrix[cur.i][j];heap.add(new Node(j,minpath[j]));}}cur = heap.poll();}//打印最短路径结果System.out.println("最短路径:");for(int j=1;j<=n;j++){if(minpath[j]<Double.MAX_VALUE && j!=i){System.out.println(i+"到"+j+":"+minpath[j]);}}}public static void main(String args []){System.out.println("请输入定点总数:");Scanner scan = new Scanner(System.in);int n = scan.nextInt();ShortestPath s = new ShortestPath(n); s.shortpath(1);}}class Node implements Comparable<Node>{int i;double len;public Node(int i,double l){this.i = i;len = l;}public int compareTo(Node o){double dif = len-o.len;if(dif>0){return 1;}else if(dif==0){return 0;}else{return -1;}}}五、实验结果输出结果分析:测试为上述测试用途,输出结果:1到2的最短路径为3,1到3的最短路径为2,1到4的最短路径为3,1到5的最短路径为7,1到6的最短路径为6。

算法分析与设计实验报告分支限界法实现单源最短路径班级:11计算机1学号:110104200109姓名:金李扬日期: 5.221.问题描述以分支限界法实现单源最短路径1.以分支限界实现优先队列2.再以分支限界法的优先队列实现单元最短路径以该图为算法测试数据,获得链接矩阵如下:以-1代表无法到达的点-1 2 3 4 -1 -1 -1 -1 -1 -1 -1-1 -1 3 -1 7 2 -1 -1 -1 -1 -1-1 -1 -1 -1 -1 9 2 -1 -1 -1 -1-1 -1 -1 -1 -1 -1 2 -1 -1 -1 -1-1 -1 -1 -1 -1 -1 -1 3 3 -1 -1-1 -1 -1 -1 -1 -1 1 -1 3 -1 -1-1 -1 -1 -1 -1 -1 -1 -1 5 1 -1-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 3-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 3-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 2-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -12.算法思想分支限界法基本思想:分支限界法常以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。
在分支限界法中,每一个活结点只有一次机会成为扩展结点。
活结点一旦成为扩展结点,就一次性产生其所有儿子结点。
在这些儿子结点中,导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被加入活结点表中。
此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点扩展过程。
这个过程一直持续到找到所需的解或活结点表为空时为止。
算法步骤1.用一极小堆来存储活结点表,其优先级是结点所对应的当前路长。
2.算法从图G的源顶点s和空优先队列开始。
结点s被扩展后,它的儿子结点被依次插入堆中。
此后,算法从堆中取出具有最小当前路长的结点作为当前扩展结点,并依次检查与当前扩展结点相邻的所有顶点。

最短路径问题的分支定界算法最短路径问题是图论中的重要问题之一,它在许多实际应用中具有广泛的意义。
为了解决最短路径问题,我将介绍一种有效的算法——分支定界算法。
一、问题描述最短路径问题是要找到图中两个顶点之间的最短路径。
给定一个带权有向图,其中顶点表示路径上的地点,边表示路径的长度。
我们需要找到从起点到终点的最短路径。
二、分支定界算法原理分支定界算法是一种穷举搜索算法,通过分解问题的解空间,并确定每个子问题的解上下界,以逐步缩小搜索空间。
以下是分治定界算法的基本步骤:1. 初始化a. 定义一个队列,用于存放候选路径;b. 设置初始最短路径长度为正无穷;c. 将起点加入队列。
2. 分支定界a. 从队列中取出当前路径,并计算路径长度;b. 如果当前路径长度大于等于当前最短路径长度,则剪枝,继续下一个路径;c. 如果当前路径的终点是目标终点,则更新最短路径长度和最短路径,继续下一个路径;d. 否则,扩展当前路径,将其邻节点添加到队列中。
3. 终止条件a. 当队列为空时,终止搜索,得到最短路径。
三、算法实现以下是使用分支定界算法解决最短路径问题的伪代码:```初始化队列;初始化最短路径长度为正无穷;将起点加入队列;while (队列非空) {取出当前路径,并计算路径长度;if (当前路径长度大于等于当前最短路径长度) {剪枝,继续下一个路径;}if (当前路径的终点是目标终点) {更新最短路径长度和最短路径;继续下一个路径;}扩展当前路径,将其邻节点添加到队列中;}返回最短路径;```四、案例分析为了更好地理解分支定界算法的应用,我们以一个简单的案例来说明。
假设有一个城市地图,其中包含多个地点,我们需要找到从起点到终点的最短路径。
首先,我们将起点添加到队列,并初始化最短路径长度为正无穷。
然后,通过不断从队列中取出路径,并计算路径长度,进行分支定界操作。
在每一步分支定界操作中,我们根据当前路径长度与最短路径长度的比较,以及当前路径终点是否为目标终点,来进行剪枝或更新最短路径。
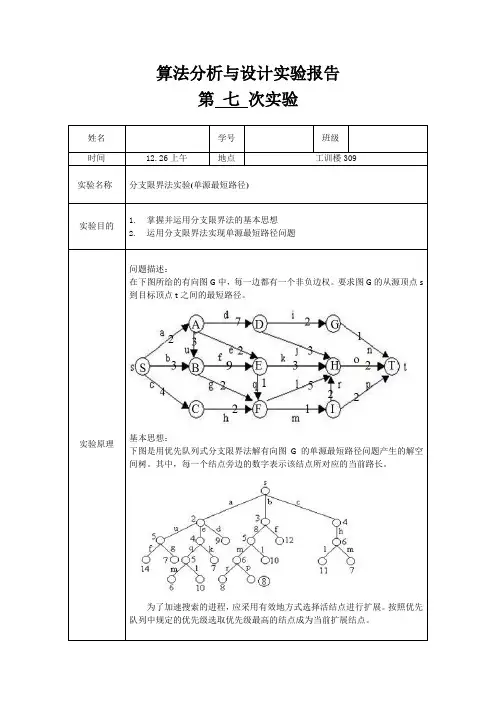
算法分析与设计实验报告第七次实验姓名学号班级时间12.26上午地点工训楼309实验名称分支限界法实验(单源最短路径)实验目的1.掌握并运用分支限界法的基本思想2.运用分支限界法实现单源最短路径问题实验原理问题描述:在下图所给的有向图G中,每一边都有一个非负边权。
要求图G的从源顶点s 到目标顶点t之间的最短路径。
基本思想:下图是用优先队列式分支限界法解有向图G的单源最短路径问题产生的解空间树。
其中,每一个结点旁边的数字表示该结点所对应的当前路长。
为了加速搜索的进程,应采用有效地方式选择活结点进行扩展。
按照优先队列中规定的优先级选取优先级最高的结点成为当前扩展结点。
catch (int){break;}if(H.currentsize==0) //优先队列空{break;}}}上述有向图的结果:测试结果附录:完整代码(分支限界法)Shorest_path.cpp//单源最短路径问题分支限界法求解#include<iostream>#include<time.h>#include<iomanip>#include"MinHeap2.h"using namespace std;template<class Type>class Graph //定义图类{friend int main();public:void shortest_path(int); private:int n, //图的顶点数*prev; //前驱顶点数组Type **c, //图的邻接矩阵*dist; //最短距离数组};template<class Type>class MinHeapNode //最小堆中的元素类型为MinHeapNode{friend Graph<Type>;public:operator int() const{return length;}private:int i; //顶点编号Type length; //当前路长};//单源最短路径问题的优先队列式分支限界法template<class Type>void Graph<Type>::shortest_path(int v){MinHeap<MinHeapNode<Type>> H(1000);//定义最小堆的容量为1000//定义源为初始扩展结点MinHeapNode<Type> E;//初始化源结点E.i=v;E.length=0;dist[v]=0;while(true)//搜索问题的解空间{for(int j=1;j<=n;j++)if((c[E.i][j]!=0)&&(E.length+c[E.i][j]<dist[j])){//顶点i到顶点j可达,且满足控制约束//顶点i和j之间有边,且此路径小于原先从源点i到j的路径长度dist[j]=E.length+c[E.i][j];//更新dist数组prev[j]=E.i;//加入活结点优先队列MinHeapNode<Type> N;N.i=j;N.length=dist[j];H.Insert(N);//插入到最小堆中}try{H.DeleteMin(E); // 取下一扩展结点}catch (int){break;}if(H.currentsize==0)//优先队列空{break;}}}int main(){int n=11;int prev[12]={0,0,0,0,0,0,0,0,0,0,0,0};//初始化前驱顶点数组intdist[12]={1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000 };//初始化最短距离数组cout<<"单源图的邻接矩阵如下:"<<endl;int **c=new int*[n+1];for(int i=1;i<=n;i++) //输入图的邻接矩阵{c[i]=new int[n+1];for(int j=1;j<=n;j++){cin>>c[i][j];}}int v=1; //源结点为1Graph<int> G;G.n=n;G.c=c;G.dist=dist;G.prev=prev;clock_t start,end,over; //计算程序运行时间的算法start=clock();end=clock();over=end-start;start=clock();G.shortest_path(v);//调用图的最短路径查找算法//输出从源结点到目的结点的最短路径cout<<"从S到T的最短路长是:"<<dist[11]<<endl;for(int i=2;i<=n;i++)//输出每个结点的前驱结点{cout<<"prev("<<i<<")="<<prev[i]<<" "<<endl;}for(int i=2;i<=n;i++) //输出从源结点到其他结点的最短路径长度{cout<<"从1到"<<i<<"的最短路长是:"<<dist[i]<<endl;}for(int i=1;i<=n;i++) //删除动态分配时的内存{delete[] c[i];}delete[] c;c=0;end=clock();printf("The time is %6.3f",(double)(end-start-over)/CLK_TCK); //显示运行时间cout<<endl;system("pause");return 0;}MinHeap.h#include<iostream>template<class Type>class Graph;template<class T>class MinHeap //最小堆类{template<class Type>friend class Graph;public:MinHeap(int maxheapsize=10); //构造函数,堆的大小是10~MinHeap(){delete[] heap;} //最小堆的析构函数int Size() const{return currentsize;} //Size()返回最小堆的个数T Max(){if(currentsize) return heap[1];} //第一个元素出堆MinHeap<T>& Insert(const T& x); //最小堆的插入函数MinHeap<T>& DeleteMin(T& x); //最小堆的删除函数void Initialize(T x[],int size,int ArraySize); //堆的初始化void Deactivate();void output(T a[],int n);private:int currentsize,maxsize;T *heap;};template<class T>void MinHeap<T>::output(T a[],int n) //输出函数,输出a[]数组的元素{for(int i=1;i<=n;i++)cout<<a[i]<<" ";cout<<endl;}template<class T>MinHeap<T>::MinHeap(int maxheapsize){maxsize=maxheapsize;heap=new T[maxsize+1]; //创建堆currentsize=0;}template<class T>MinHeap<T>& MinHeap<T>::Insert(const T& x){if(currentsize==maxsize) //如果堆中的元素已经等于堆的最大大小return *this; //那么不能在加入元素进入堆中int i= ++currentsize;while(i!=1 && x<heap[i/2]){heap[i]=heap[i/2];i/=2;}heap[i]=x;return *this;}template<class T>MinHeap<T>& MinHeap<T>::DeleteMin(T& x) //删除堆顶元素{if(currentsize==0){cout<<"Empty heap!"<<endl;return *this;}x=heap[1];T y=heap[currentsize--];int i=1,ci=2;while(ci<=currentsize){if(ci<currentsize && heap[ci]>heap[ci+1])ci++;if(y<=heap[ci])break;heap[i]=heap[ci];i=ci;ci*=2;}heap[i]=y;return *this;}template<class T>void MinHeap<T>::Initialize(T x[],int size,int ArraySize) //堆的初始化{delete[] heap;heap=x;currentsize=size;maxsize=ArraySize;for(int i=currentsize/2;i>=1;i--){T y=heap[i];int c=2*i;while(c<=currentsize){if(c<currentsize && heap[c]>heap[c+1])c++;if(y<=heap[c])break;heap[c/2]=heap[c];c*=2;}heap[c/2]=y;}}template<class T>void MinHeap<T>::Deactivate(){heap=0; }。

一.分支界限法的基本思想分支限界法常以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。
对已处理的各结点根据限界函数估算目标函数的可能取值,从中选取使目标函数取得极值(极大/极小)的结点优先进行广度优先搜索 不断调整搜索方向,尽快找到解。
特点:限界函数常基于问题的目标函数,适用于求解最优化问题。
在分支限界法中,每一个活结点只有一次机会成为扩展结点。
活结点一旦成为扩展结点,就一次性产生其所有儿子结点。
在这些儿子结点中,导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被加入活结点表中。
此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点扩展过程。
这个过程一直持续到找到所需的解或活结点表为空时为止。
二.单源最短路径问题1.问题描述下面以一个例子来说明单源最短路径问题:在下图所给的有向图G 中,每一边都有一个非负边权。
要求图G的从源顶点s到目标顶点t 之间的最短路径。
下图是用优先队列式分支限界法解有向图G的单源最短路径问题产生的解空间树。
其中,每一个结点旁边的数字表示该结点所对应的当前路长。
2. 算法思想解单源最短路径问题的优先队列式分支限界法用一极小堆来存储活结点表。
其优先级是结点所对应的当前路长。
算法从图G的源顶点s和空优先队列开始。
结点s被扩展后,它的儿子结点被依次插入堆中。
此后,算法从堆中取出具有最小当前路长的结点作为当前扩展结点,并依次检查与当前扩展结点相邻的所有顶点。
如果从当前扩展结点i到顶点j有边可达,且从源出发,途经顶点i再到顶点j的所相应的路径的长度小于当前最优路径长度,则将该顶点作为活结点插入到活结点优先队列中。
这个结点的扩展过程一直继续到活结点优先队列为空时为止。
3. 剪枝策略在算法扩展结点的过程中,一旦发现一个结点的下界不小于当前找到的最短路长,则算法剪去以该结点为根的子树。
在算法中,利用结点间的控制关系进行剪枝。
从源顶点s出发,2条不同路径到达图G的同一顶点。

分支限界法求单源最短路径分支限界法是一种求解最优化问题的算法,在图论中,可以用来求解单源最短路径。
本文将介绍分支限界法的基本原理和步骤,并通过一个具体的示例来说明其应用。
一、分支限界法简介分支限界法是一种穷举搜索算法,通过不断地将问题空间划分成更小的子问题,以寻找最优解。
它与传统的深度优先搜索算法相似,但在搜索过程中,通过引入上界(界限)来限制搜索范围,从而有效地剪枝和加速搜索过程。
分支限界法求解单源最短路径问题的基本思想是,首先将源点标记为已访问,然后以源点为根节点构建一棵搜索树,树中的每个节点表示当前访问的顶点,并记录到达该顶点的路径和权值。
通过遍历搜索树,逐步更新最短路径以及当前最优权值,从而找到最短路径。
二、分支限界法的步骤1. 创建搜索树:- 将源点标记为已访问,并将其作为根节点。
- 根据源点与其他顶点之间的边权值构建搜索树的第一层。
- 初始化当前最优路径和权值。
2. 遍历搜索树:- 从当前层中选择一个未访问的顶点作为扩展节点。
- 计算到达该扩展节点的路径和权值,并更新当前最优路径和权值。
- 根据已有的路径和权值,计算该扩展节点的上界,并与当前最优权值进行比较。
若上界小于当前最优权值,则进行剪枝操作,否则继续搜索。
- 将该扩展节点的子节点添加到搜索树中。
3. 更新最短路径:- 当搜索树的所有叶子节点都已遍历时,找到最短路径以及相应的权值。
三、示例分析为了更好地理解分支限界法的运行过程,我们将通过一个具体的示例来进行分析。
假设有一个有向带权图,其中包含5个顶点和6条边。
首先,我们需要构建初始搜索树,将源点A作为根节点。
根据源点与其他顶点之间的边权值,我们可以得到搜索树的第一层B(2)、C(3)、D(4)、E(5)。
接下来,我们从第一层选择一个未访问的顶点作为扩展节点。
假设选择节点B进行扩展。
此时,我们计算到达节点B的路径和权值,并更新当前最优路径和权值。
对于节点B,到达它的路径为AB,权值为2。

单源最短路径问题实验四单源最短路径问题一、实验目的:1、理解分支限界法的剪枝搜索策略;2、掌握分支限界法的算法柜架;3、掌握分支限界法的算法步骤;4、通过应用范例学习动态规划算法的设计技巧与策略;二、实验内容及要求:1、使用分支限界法解决单源最短路径问题。
2、通过上机实验进行算法实现。
3、保存和打印出程序的运行结果,并结合程序进行分析,上交实验报告。
三、实验原理:分支限界法的基本思想:1、分支限界法与回溯法的不同:1)求解目标:回溯法的求解目标是找出解空间树中满足约束条件的所有解,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出在某种意义下的最优解。
2)搜索方式的不同:回溯法以深度优先的方式搜索解空间树,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树。
2、分支限界法基本思想:分支限界法常以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。
在分支限界法中,每一个活结点只有一次机会成为扩展结点。
活结点一旦成为扩展结点,就一次性产生其所有儿子结点。
在这些儿子结点中,导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被加入活结点表中。
此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点扩展过程。
这个过程一直持续到找到所需的解或活结点表为空时为止。
3、常见的两种分支限界法:1)队列式(FIFO)分支限界法按照队列先进先出(FIFO)原则选取下一个节点为扩展节点。
2)优先队列式分支限界法按照优先队列中规定的优先级选取优先级最高的节点成为当前扩展节点。
四、程序代码#includeusing namespace std;int matrix[100][100]; // 邻接矩阵bool visited[100]; // 标记数组int dist[100]; // 源点到顶点i的最短距离int path[100]; // 记录最短路的路径int source; // 源点int vertex_num; // 顶点数int edge_num; // 边数int destination; // 终结点void Dijkstra(int source){memset(visited, 0, sizeof(visited)); // 初始化标记数组visited[source] = true;for (int i = 0; i < vertex_num; i++){dist[i] = matrix[source][i];path[i] = source;}int min_cost; // 权值最小int min_cost_index; // 权值最小的下标for (int i = 1; i < vertex_num; i++) // 找到源点到另外vertex_num-1 个点的最短路径{min_cost = INT_MAX;for (int j = 0; j < vertex_num; j++){if (visited[j] == false && dist[j] < min_cost) // 找到权值最小{min_cost = dist[j];min_cost_index = j;}}visited[min_cost_index] = true; // 该点已找到,进行标记for (int j = 0; j < vertex_num; j++) // 更新 dist 数组{if (visited[j] == false &&matrix[min_cost_index][j] != INT_MAX && // 确保两点之间有边matrix[min_cost_index][j] + min_cost < dist[j]){dist[j] = matrix[min_cost_index][j] + min_cost;path[j] = min_cost_index;}}}}int main(){cout << "请输入图的顶点数(<100):";cin >> vertex_num;cout << "请输入图的边数:";cin >> edge_num;for (int i = 0; i < vertex_num; i++)for (int j = 0; j < vertex_num; j++)matrix[i][j] = (i != j) ? INT_MAX : 0; // 初始化 matrix 数组cout << "请输入边的信息:\n";int u, v, w;for (int i = 0; i < edge_num; i++){cout << "请输入第" << i + 1 << "条边的信息(中间用空格隔开):";cin >> u >> v >> w;matrix[u][v] = matrix[v][u] = w;}cout << "请输入源点(<" << vertex_num << "):";cin >> source;Dijkstra(source);cout << "请输入终结点(<" << vertex_num << "):";cin >> destination;cout << source << "到" << destination << "最短距离是:" << dist[destination] << ",路径是:" << destination;int t = path[destination];while (t != source){cout << "<--" << t;t = path[t];}cout << "<--" << source << endl;return 0;}五、结果运行与分析本例用使迪杰斯特拉算法来求单源最短路径,也即采用优先队列式分支限界法,按照优先队列中规定的优先级选取优先级最高的节点成为当前扩展节点。

实验四:单源最短路径一.问题描述给定带权图G和源点V,对图进行遍历并求从V到G中其余各顶点的最短路径。
二.输入及结果输入:带全图G的各个顶点及各边的权值。
输出:Dijkstra算法的结果(用矩阵表示),并给出各最短路径长度。
三.需求分析1图的深度优先搜索①数组visited[i]用来表示顶点V[i]是否被访问过。
②递归调用函数2图的广度优先搜索①队列操作的相关函数②数组visited[i]用来表示顶点V[i]是否被访问过。
3单源最短路径①需要一个辅助变量D,它的每个分量D[i]表示当前所找到的从始点V到每个终点V[i]的最短路径长度。
它的初态为:若从V到V[i]有弧,则D[i]为弧上的权值;否则置D[i]为INFINITY。
②需要二元数组P[v][w],值为1,则W是V0到V当前球的最短路径上的顶点。
③需要Final[v],值为1当且仅当已经求得V0到V的最短路径。
④用带权的邻接矩阵来表示带权有向图,arcs[i][j]表示弧<vi,vj>上的权值。
⑤函数Locate来确定顶点对应的数组编号。
四.算法描述1图的深度优先搜索深度优先搜索可以从图中的某个顶点V出发,访问此顶点,然后依次从V的未被访问过的邻接点出发深度优先遍历图,直至所有和V有路径相通的顶点都被访问,若此时还有未被访问过的节点,则重复上述过程,开始深度搜索。
2图的广度优先搜索从图中某顶点V出发,在访问了V之后一次访问V的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问他们的邻接点,并使“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问”,直至图中所有被已访问的顶点的邻接点都被访问到。
若此时图中尚有顶点未被访问,则另选图中未被访问的结点作为起始点,重复上述过程,直至图中所有顶点都被访问。
其中要用到队列的有关算法。
3单源最短路径①记S为已经找到的从源点出发的最短路径的点的集合,它的初始状态为空集。
那么,从V出发到图上其余各顶点V[i]可能达到的最短路径的初始值为D[i]=arcs[Locate Vex(G,V)][i].②选择Vj使得:D[j]=Min{D[i] :vi S} ,Vj就是当前求得的一条从V出发的最短路径的终点。

第1篇一、实验目的1. 理解并掌握分枝限界法的基本原理和实现方法。
2. 通过实际编程,运用分枝限界法解决实际问题。
3. 比较分析分枝限界法与其他搜索算法(如回溯法)的优缺点。
4. 增强算法设计能力和编程实践能力。
二、实验内容本次实验主要涉及以下内容:1. 分支限界法的基本概念和原理。
2. 分支限界法在单源最短路径问题中的应用。
3. 分支限界法的实现步骤和代码编写。
4. 分支限界法与其他搜索算法的对比分析。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发环境:PyCharm四、实验步骤1. 算法描述:分支限界法是一种用于解决组合优化问题的算法,其基本思想是在问题的解空间树中,按照一定的搜索策略,优先选择有潜力的节点进行扩展,从而减少搜索空间,提高搜索效率。
2. 程序代码:下面是使用Python实现的分支限界法解决单源最短路径问题的代码示例:```pythonimport heapqclass Node:def __init__(self, vertex, distance, parent): self.vertex = vertexself.distance = distanceself.parent = parentdef __lt__(self, other):return self.distance < other.distancedef branch_and_bound(graph, source):初始化优先队列和已访问节点集合open_set = []closed_set = set()添加源节点到优先队列heapq.heappush(open_set, Node(source, 0, None))主循环,直到找到最短路径while open_set:弹出优先队列中最小距离的节点current_node = heapq.heappop(open_set)检查是否已访问过该节点if current_node.vertex in closed_set:continue标记节点为已访问closed_set.add(current_node.vertex)如果当前节点为目标节点,则找到最短路径if current_node.vertex == target:path = []while current_node:path.append(current_node.vertex)current_node = current_node.parentreturn path[::-1]遍历当前节点的邻居节点for neighbor, weight in graph[current_node.vertex].items():if neighbor not in closed_set:计算新节点的距离distance = current_node.distance + weight添加新节点到优先队列heapq.heappush(open_set, Node(neighbor, distance, current_node))没有找到最短路径return None图的表示graph = {0: {1: 2, 2: 3},1: {2: 1, 3: 2},2: {3: 2},3: {1: 3}}源节点和目标节点source = 0target = 3执行分支限界法path = branch_and_bound(graph, source)print("最短路径为:", path)```3. 调试与测试:在编写代码过程中,注意检查数据结构的使用和算法逻辑的正确性。
分支限界法,运动员最佳配对,实验总结精品文档分支限界法,运动员最佳配对,实验总结课程名称: _算法设计与分析项目名称:_分支限界法实现_姓名:_xxxxx专业:xxxxxxx班级:__xxxxxxx_学号:__xxxxxxxxxxxxxxxxx__ 同组成员____无_______一、课题名称用分枝限界法求解单源最短路径问题二、课题内容和要求设计要求:学习算法设计中分枝限界法的思想,设计算法解决数据结构中求解单源最短路径问题,编程实现:给出指定源点的单源最短路径;说明算法的时间复杂度。
三、需求分析1.实现极小堆的创建,用来存储活结点表。
2.实现循环队列的创建、初始化、入队、出队等操作。
3.实现分支限界法来实现求解单元最短路径的算法。
4.实现最短路径的正确输出。
四、概要设计建立工程MinPath.dsw,加入源文件main.cpp,头文件CirQueue.h,init.h,Minpath.h和output.h. CirQueue.h中实现极小堆的创建,循环队列的创建、初始化、入队、出1 / 23精品文档队等操作,Minpath.h中实现分支限界法来实现求解单元最短路径的算法。
output.h中实现最短路径的正确输出。
如下图所示:实验用例如下,通过邻接矩阵的方式写在init.h中:五、详细设计main函数:#include#include"init.h"#include"CirQueue.h"#include"MinPath.h"#include"output.h"void main{int k; int q; cout cin>>k; cout>q; while{ cout } cin>>k;MinPath;}init.h output;const int size =00;const int inf = 1000; //两点距离上界置为1000const int n = 12; //图顶点个数加12 / 23精品文档int prev[n]; //图的前驱顶点int dist[] ={0,inf,inf,inf,inf,inf,inf,inf,inf,inf,inf,inf}; //最短距离数组int c[n][n] = {{0,0,0,0,0,0,0,0,0,0,0,0},{0,0,2,3,4,inf,inf,inf,inf,inf,inf,inf},{0,inf,0,3,inf,7,2,inf,inf,inf,inf,inf},{0,inf,inf,0,inf,inf,9,2,inf,inf,inf,inf},{0,inf,inf,inf,0,inf,inf,2,inf,inf,inf,inf},{0,inf,inf,inf,inf,0,inf,inf,3,3,inf,inf},{0,inf,inf,inf,inf,inf,0,1,inf,3,inf,inf},{0,inf,inf,inf,inf,inf,inf,0,inf,5,1,inf},{0,inf,inf,inf,inf,inf,inf,inf,0,inf,inf,3},{0,inf,inf,inf,inf,inf,inf,inf,inf,0,inf,2},{0,inf,inf,inf,inf,inf,inf,inf,inf,2,inf,2},{0,inf,inf,inf,inf,inf,inf,inf,inf,inf,inf,0},};//矩阵CirQueue.hclass MinHeapNode//创建极小堆用来存储活结点表{public :int i; //顶点编号3 / 23精品文档int length; //当前路长};class CirQueue//循环队列{private: 图的邻接int front,rear;//头指针和尾指针MinHeapNode data[size];public:CirQueue//初始化建空队列{front = rear = 0;}void queryIn//元素入队操作 {if%size != front)//队列未满 { rear = %size; //插入新的队尾元素 data[rear] = e; //在队尾插入元素 } }void queryOut//元素出队操作{if{front = %size; //删除队头元素 }4 / 23精品文档}MinHeapNode getQuery//读取队头元素,但不出队 {if{return data[%size];}return data[1];运动员最佳配对问题羽毛球队有男女运动员各n人.给定两个n×n得矩阵P和Q.P[i][j]是男运动员i和女运动员j配对组成混合双打的运动员竞赛优势.Q[i][j]是女运动员i和男运动员j配合的女运动员竞赛优势.由于技术配合和心理状态等各种因素影响,P[i][j]不一定等于Q[i][j].男运动员i女运动员j配合组成混合双打的男女双方竞赛优势为P[i][j]×Q[j][i].设计一个算法,计算男女运动员最佳配对法,使各组男女双方竞赛优势的总和达到最大.此题目的解空间显然是一棵排列树,可以套用搜索排列树的回溯法框架:5 / 23精品文档void backtrack{ifcompute;elsefor{swap;backtrack;swap;}}void compute{int temp=0;fortemp+=p[i][r[i]]*q[r[i]][i];if{best=temp;forbestr[i]=r[i];}6 / 23精品文档}无和集问题设S是正整数集合。
0033算法笔记分支限界法分支限界法与单源最短路径问题 0033算法笔记-分支限界法分支限界法与单源最短路径问题1、分支限界法(1)叙述:使用广度优先产生状态空间一棵的结点,并采用剪枝函数的方法称作分枝限界法。
所谓“分支”是采用广度优先的策略,依次生成扩展结点的所有分支(即为:儿子结点)。
所谓“限界”是在结点扩展过程中,计算结点的上界(或下界),边搜索边减去搜寻一棵的某些分支,从而提升搜寻效率。
(2)原理:按照广度优先的原则,一个活结点一旦成为扩展结点(e-结点)r后,算法将依次生成它的全部孩子结点,将那些导致不可行解或导致非最优解的儿子舍弃,其余儿子加入活结点表中。
然后,从活结点表中取出一个结点作为当前扩展结点。
重复上述结点扩展过程,直至找到问题的解或判定无解为止。
(3)分支限界法与回溯法1)解目标:追溯法的解目标就是找到求解空间树中满足用户约束条件的所有求解,而分支限界法的解目标则就是找到满足用户约束条件的一个求解,或是在八十足约束条件的解中找出在某种意义下的最优解。
2)搜寻方式的相同:追溯法以深度优先的方式搜寻求解空间一棵,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树。
(4)常见的分支限界法1)fifo分支限界法(队列式分支限界法)基本思想:按照队列先进先出(fifo)原则选取下一个活结点为扩展结点。
搜寻策略:一已经开始,根结点就是唯一的活结点,根结点入队。
从活结点队中抽出根结点后,做为当前拓展结点。
对当前拓展结点,先从左到右地产生它的所有儿子,用约束条件检查,把所有满足用户约束函数的儿子重新加入活结点队列中。
再从活结点表抽出队首结点(队中最先进去的结点)为当前拓展结点,……,直至找出一个求解或活结点队列入空年才。
2)lc(leastcost)分支限界法(优先队列式分支限界法)基本思想:为了加速搜索的进程,应采用有效地方式选择活结点进行扩展。
按照优先队列中规定的优先级选取优先级最高的结点成为当前扩展结点。
单元最短路径问题分支限界法标题:解密单元最短路径问题:深度探索分支限界法一、引言单元最短路径问题是图论中的一个经典问题,它在实际生活中有着广泛的应用。
而分支限界法则是解决这一问题的重要方法之一。
本文将深入探讨单元最短路径问题,并重点介绍分支限界法在解决该问题中的应用。
二、单元最短路径问题概述单元最短路径问题是指在一个加权有向图中,求出从一个指定起始顶点到其他所有顶点的最短路径。
这个问题可以用于交通规划、网络通信以及物流配送等领域。
在实际生活中,我们经常需要求解单元最短路径问题来优化路线或资源利用。
三、分支限界法介绍分支限界法是一种用于求解最优化问题的通用技术。
它通过不断地扩展候选解空间,并在搜索过程中剪枝,以获得最优解。
在解决单元最短路径问题中,分支限界法可以通过不断地搜索路径长度,并在搜索过程中淘汰一些非最优路径,从而高效地找到最短路径。
四、分支限界法在单元最短路径问题中的应用在实际应用中,我们可以将单元最短路径问题转化为一个树型图的搜索问题,在搜索过程中使用分支限界法来逐步缩小解空间。
通过递归地搜索各条路径,并不断更新最短路径的长度,我们可以最终找到起始顶点到其他所有顶点的最短路径。
分支限界法可以在搜索过程中灵活地调整搜索策略,从而有效地优化解的搜索过程。
五、个人观点和理解我个人认为,分支限界法作为一种智能化的搜索算法,在解决单元最短路径问题时具有独特的优势。
它可以根据实际问题的特点,灵活地调整搜索策略,以获得更高效的搜索结果。
分支限界法也可以在处理大规模数据时,通过剪枝等策略,节省搜索时间和空间成本。
六、总结和回顾通过本文的讨论,我们对单元最短路径问题和分支限界法有了更深入的理解。
分支限界法作为一种重要的搜索算法,在解决单元最短路径问题时发挥着重要作用。
我们希望读者可以通过本文的介绍,对这一话题有更全面、深刻和灵活的理解,以应用于实际问题中。
通过上述深度探索,我们对单元最短路径问题和分支限界法有了更清晰的认识。
分⽀限界法实验(单源最短路径)算法分析与设计实验报告第七次实验基本思想:附录:完整代码(分⽀限界法)Shorest_path.cpp//单源最短路径问题分⽀限界法求解#include#include#include#include"MinHeap2.h"using namespace std;templateclass Graph //定义图类{friend int main();public:void shortest_path(int); private:int n, //图的顶点数*prev; //前驱顶点数组Type **c, //图的邻接矩阵*dist; //最短距离数组};templateclass MinHeapNode //最⼩堆中的元素类型为MinHeapNode{friend Graph;public:operator int() const{return length;}private:int i; //顶点编号Type length; //当前路长};//单源最短路径问题的优先队列式分⽀限界法templatevoid Graph::shortest_path(int v){MinHeap> H(1000);//定义最⼩堆的容量为1000//定义源为初始扩展结点MinHeapNode E;//初始化源结点E.i=v;E.length=0;dist[v]=0;while(true)//搜索问题的解空间{for(int j=1;j<=n;j++)if((c[E.i][j]!=0)&&(E.length+c[E.i][j]{//顶点i到顶点j可达,且满⾜控制约束//顶点i和j之间有边,且此路径⼩于原先从源点i到j的路径长度dist[j]=E.length+c[E.i][j];//更新dist数组prev[j]=E.i;//加⼊活结点优先队列MinHeapNode N;N.i=j;N.length=dist[j];H.Insert(N);//插⼊到最⼩堆中}try{H.DeleteMin(E); // 取下⼀扩展结点}catch (int){break;}if(H.currentsize==0)//优先队列空{break;}}}int main(){int n=11;int prev[12]={0,0,0,0,0,0,0,0,0,0,0,0};//初始化前驱顶点数组intdist[12]={1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000};//初始化最短距离数组cout<<"单源图的邻接矩阵如下:"<int **c=new int*[n+1];for(int i=1;i<=n;i++) //输⼊图的邻接矩阵{c[i]=new int[n+1];for(int j=1;j<=n;j++){cin>>c[i][j];}}int v=1; //源结点为1Graph G;G.n=n;G.c=c;G.dist=dist;G.prev=prev;clock_t start,end,over; //计算程序运⾏时间的算法start=clock();end=clock();over=end-start;start=clock();G.shortest_path(v);//调⽤图的最短路径查找算法//输出从源结点到⽬的结点的最短路径cout<<"从S到T的最短路长是:"<for(int i=2;i<=n;i++)//输出每个结点的前驱结点{cout<<"prev("<}for(int i=2;i<=n;i++) //输出从源结点到其他结点的最短路径长度{cout<<"从1到"<}for(int i=1;i<=n;i++) //删除动态分配时的内存{delete[] c[i];}delete[] c;c=0;end=clock();printf("The time is %6.3f",(double)(end-start-over)/CLK_TCK); //显⽰运⾏时间cout< system("pause");return 0;}MinHeap.h#includetemplateclass Graph;templateclass MinHeap //最⼩堆类{templatefriend class Graph;public:MinHeap(int maxheapsize=10); //构造函数,堆的⼤⼩是10~MinHeap(){delete[] heap;} //最⼩堆的析构函数int Size() const{return currentsize;} //Size()返回最⼩堆的个数T Max(){if(currentsize) return heap[1];} //第⼀个元素出堆MinHeap& Insert(const T& x); //最⼩堆的插⼊函数MinHeap& DeleteMin(T& x); //最⼩堆的删除函数void Initialize(T x[],int size,int ArraySize); //堆的初始化void Deactivate();void output(T a[],int n);private:int currentsize,maxsize;T *heap;};templatevoid MinHeap::output(T a[],int n) //输出函数,输出a[]数组的元素{for(int i=1;i<=n;i++)cout<cout<}templateMinHeap::MinHeap(int maxheapsize){maxsize=maxheapsize;heap=new T[maxsize+1]; //创建堆currentsize=0;}templateMinHeap& MinHeap::Insert(const T& x){if(currentsize==maxsize) //如果堆中的元素已经等于堆的最⼤⼤⼩return *this; //那么不能在加⼊元素进⼊堆中int i= ++currentsize;while(i!=1 && x{heap[i]=heap[i/2];i/=2;}heap[i]=x;return *this;}templateMinHeap& MinHeap::DeleteMin(T& x) //删除堆顶元素{if(currentsize==0){cout<<"Empty heap!"<return *this;}x=heap[1];T y=heap[currentsize--];int i=1,ci=2;while(ci<=currentsize){if(ciheap[ci+1])ci++;if(y<=heap[ci])break;heap[i]=heap[ci];i=ci;ci*=2;}heap[i]=y;return *this;}templatevoid MinHeap::Initialize(T x[],int size,int ArraySize) //堆的初始化{ delete[] heap;heap=x;currentsize=size;maxsize=ArraySize;for(int i=currentsize/2;i>=1;i--){T y=heap[i];int c=2*i;while(c<=currentsize){if(cheap[c+1])c++;if(y<=heap[c])break;heap[c/2]=heap[c];c*=2;}heap[c/2]=y;}}templatevoid MinHeap::Deactivate() {heap=0;}。
一道难题:如何用分支限界法求解单源最短路径单源最短路径问题是图论中的经典问题之一,不仅在实际生活中有广泛应用,而且对于算法设计和分析也有重要价值。
分支限界法是一种解决最短路径问题的强有力工具。
在这篇文章中,我们将详细介绍如何用分支限界法求解单源最短路径问题。
首先,我们需要了解单源最短路径问题的定义。
给定一个有向图和一个起点s,对于图中的每一个顶点v,找到从s到v的最短路径。
这里的最短路径是指从s到v经过的边权之和最小的路径。
接下来,我们可以按照以下步骤实现用分支限界法求解单源最短路径问题:1. 初始化距离数组dist[],将s到其他所有点的距离设置为无穷大,将s到自己的距离设置为0。
2. 将起点s加入优先队列,队列中的元素按照距离dist[]从小到大排序。
3. 从优先队列中取出距离最小的顶点u,并遍历u的邻居节点v。
如果从s到v的距离可以通过从s到u再到v的路径更优,则更新dist[]数组和优先队列中的元素。
4. 重复步骤3,直到队列为空或者找到终点。
如果找到终点,则最优解就是dist[]数组中终点的值。
上述步骤中,第3步的优化是通过分支限界法实现的。
我们利用了贪心策略,并将目标函数设为从s到u的最短路径距离加上从u到v 的边权。
对于每一个节点u,我们只扩展目标函数值最小的那条边。
这样可以大幅度减少搜索空间,提高算法效率。
在实际应用中,分支限界法不仅可以求解单源最短路径问题,还可以应用于其他的组合优化问题中。
希望读者能够在掌握了基本理论和算法之后,加深对于分支限界法的理解,从而更好地解决实际问题。
优先队列式分支限界法求单源最短路径java -回复优先队列式分支限界法(Priority Queue Branch and Bound)是一种用于求解单源最短路径问题的高效算法。
在这篇文章中,我们将详细介绍这个算法的原理和实现步骤。
首先,让我们来了解一下什么是单源最短路径问题。
在一个给定的带权有向图中,单源最短路径问题要求找到一个起始节点到其他所有节点的最短路径。
这个问题在许多实际应用中都非常重要,比如地图导航、网络路由和资源分配等。
要求解单源最短路径问题,通常可以使用著名的Dijkstra算法。
然而,当图中存在负权边时,Dijkstra算法就不再适用。
这时,我们可以使用优先队列式分支限界法,它可以处理负权边,并且有更好的时间复杂度。
优先队列式分支限界法的思想是通过维护一个优先队列(通常使用堆实现),在每一步选择下一个要拓展的节点时,选择当前路径权值最小的节点。
这样,每次拓展节点时,我们都可以保证已经找到的最短路径是全局最优解。
下面,我们将一步一步地介绍如何实现这个算法。
步骤1:初始化数据结构我们首先需要初始化一些数据结构,包括带权有向图的邻接表、一个优先队列和一个距离数组。
其中,邻接表用于存储图的结构信息,优先队列用于选择当前路径权值最小的节点,距离数组用于存储从起始节点到每个其他节点的距离。
步骤2:将起始节点加入到优先队列中我们将起始节点加入到优先队列中,并将起始节点的距离设为0。
步骤3:主循环接下来,我们进入主循环。
在每一次循环中,我们拿出优先队列中权值最小的节点,将其标记为已访问,并更新其周围节点的距离。
步骤4:更新周围节点的距离对于当前节点的每一个相邻节点,我们需要检查是否存在更短的路径。
如果存在更短的路径,则更新该节点的距离,并将其添加到优先队列中,以供下一次循环使用。
步骤5:重复步骤3和步骤4,直到优先队列为空重复执行步骤3和步骤4,直到优先队列为空。
此时,距离数组中存储的就是从起始节点到其他所有节点的最短路径。
实验四分支限界法实现单源最短路径
09电信实验班I09660118 徐振飞
一、实验名称
实现书本P194页所描述的单源最短路径问题
二、实验目的
(1)掌握并运用分支限界法基本思想
(2)运用分支限界法实现单源最短路径问题
(3)区分分支限界算法与回溯算法的区别,加深对分支限界法理解三、实验内容和原理
(1)实验原理
解单源最短路径问题的优先队列式分支限界法用一极小堆(本次实验我采用java.util包中的优先队列类PriorityQueue来实现)来存储活结点表。
其优先级是结点所对应的当前路长。
算法从图G的源顶点s和空优先队列开始。
结点s被扩展后,它的儿子结点被依次插入堆中。
此后,算法从堆中取出具有最小当前路长的结点作为当前扩展结点,并依次检查与当前扩展结点相邻的所有顶点。
如果从当前扩展结点i到顶点j有边可达,且从源出发,途经顶点i再到顶点j的所相应的路径的长度小于当前最优路径长度,则将该顶点作为活结点插入到活结点优先队列中。
这个结点的扩展过程一直继续到活结点优先队列为空时为止。
(2)实验内容测试用例:
1
2
3
4
5
6 3
4
2
7
6
13
9
5
四、源程序
import java.util.*;
public class ShortestPath
{
private int n;
private double matrix[][] = null;
private double minpath[];
public ShortestPath(int n)
{
this.n = n;
matrix = new double[n+1][n+1];
minpath = new double[n+1];
for(int i=1;i<=n;i++)
{
minpath[i] = Double.MAX_VALUE;
}
//初始化图
getGraphMatrix();
}
public void getGraphMatrix()
{
//初始化为不能连通
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
{
matrix[i][j] = Double.MAX_VALUE;
}
}
System.out.println("请输入边总数:");
Scanner scan = new Scanner(System.in);
int m = scan.nextInt();
System.out.println("依次输入两个顶点号(1~"+n+")和边长:例如 1 2 3");
for(int i=0;i<m;i++)
{
int a,b;
double d;
a = scan.nextInt();
b = scan.nextInt();
d = scan.nextDouble();
if(a<1 || b<1)
{
i--;
System.out.println("顶点号不能小于1");
continue;
}
if(a>n||b>n)
{
i--;
System.out.println("顶点号不能大于"+n);
continue;
}
matrix[a][b] = d;
}
}
/**
*@param求以第i个节点为起点的单源最短路径
*/
public void shortpath(int i)
{
minpath[i] = 0;
double curlen = 0;
PriorityQueue<Node> heap = new PriorityQueue();
Node cur = new Node(i,0);
heap.add(cur);
while(!heap.isEmpty())
{
for(int j=1;j<=n;j++)
{
if(matrix[cur.i][j]<Double.MAX_VALUE&& cur.len+matrix[cur.i][j]<minpath[j])
{
minpath[j] = cur.len+matrix[cur.i][j];
heap.add(new Node(j,minpath[j]));
}
}
cur = heap.poll();
}
//打印最短路径结果
System.out.println("最短路径:");
for(int j=1;j<=n;j++)
{
if(minpath[j]<Double.MAX_VALUE && j!=i)
{
System.out.println(i+"到"+j+":"+minpath[j]);
}
}
}
public static void main(String args [])
{
System.out.println("请输入定点总数:");
Scanner scan = new Scanner(System.in);
int n = scan.nextInt();
ShortestPath s = new ShortestPath(n); s.shortpath(1);
}
}
class Node implements Comparable<Node>
{
int i;
double len;
public Node(int i,double l)
{
this.i = i;
len = l;
}
public int compareTo(Node o)
{
double dif = len-o.len;
if(dif>0)
{
return 1;
}
else if(dif==0)
{
return 0;
}
else
{
return -1;
}
}
}
五、实验结果
输出结果分析:测试为上述测试用途,输出结果:1到2的最短路径为3,1到3的最短路径为2,1到4的最短路径为3,1到5的最短路径为7,1到6的最短路径为6。
输出结果正确。
六、实验心得和体会
通过实验,了解了分支限界法的基本思想。
知道了分支限界算法与回溯算法的区别。
由于本次实验利用java.util包下的PriorityQueue代替算法中最小堆,免去了编写实现最小堆的程序代码(但这并不表示我不会编写最小堆程序,在这次实验中,最小堆的实现并不是主要部分),所以本次实验实现的相对顺利。