北航研究生数理统计第二次大作业-聚类分析
- 格式:pdf
- 大小:730.13 KB
- 文档页数:16

聚类分析基本原理及其案例一、相似度的测量聚类分析是分析如何对样品(或变量)进行量化分类的问题。
通常聚类分析分为Q 型聚类和R 型聚类。
Q 型聚类是对样品进行分类处理,R 型聚类是对变量进行分类处理。
1.1 样品相似性的度量在聚类分析之前,首先要分析样品间的相似性。
Q 型聚类分析,常用距离来测度样品之间的相似程度。
每个样品有p 个指标(变量)从不同方面描述其性质,形成一个p 维的向量。
如果把这n 个样品看成p 维空间中的n 个点,则两个样品间的相似程度就可用p 维空间中的亮点距离公式来度量。
两点距离公式可以从不同角度进行定义,令ij d 表示样品i X 与j X 的距离,存在以下的距离公式。
1.1.1 闵科夫斯基距离1/1()(||)pq q ij ik jk k d q X X ==-∑闵科夫斯基距离又称闵氏距离,按q 值的不同又可分成 1)绝对距离(1q =)1(1)||pij ik jk k d X X ==-∑2)欧几里得距离(2q =)21/21(2)(||)pij ik jk k d X X ==-∑3)切比雪夫距离(q =∞)1()max ||ij ik jk k pd X X ≤≤∞=-欧几里得距离较为常用,但在解决多元数据的分析问题时,他就显得不足。
一是他没有考虑到总体变异对“距离”远近的影响,显然一个变异程度大的总体可能与更多样品近些,即使他们的欧几里得距离不一定最近;另外,欧几里得距离收到变量的量纲影响,这对多元数据的处理时不利的。
为了克服这方面的不足,可用“马氏距离“的概念。
1.1.2 马氏距离设i X 与j X 是来自均值向量为μ,协方差为Σ(>0)的总体G 中的p 维样品,则两个样品间的马氏距离为21()()'()ij i j i j d M -=--X X ΣX X马氏距离又称为广义欧几里得距离。
显然,马氏距离与上述各种距离的主要不同时它考虑了观测变量之间的关联性。



应用数理统计作业二学号:姓名:电话:二〇一四年十二月对NBA球队的聚类分析和判别分析摘要:NBA联盟作为篮球的最高殿堂深受广大球迷的喜爱,联盟的30支球队大家也耳熟能详,本文选取NBA联盟30支球队2013-2014常规赛赛季场均数据。
利用spss软件通过聚类分析对27个地区进行实力类型分类,并利用判断分析对其余3支球队对分类结果进行验证。
可以看出各球队实力类型与赛季实际结果相吻合。
关键词:聚类分析,判别分析,NBA目录1. 引言 (4)2、相关统计基础理论 (5)2.1、聚类分析 (5)2.2,判别分析 (6)3.聚类分析 (7)3.1数据文件 (7)3.2聚类分析过程 (9)3.3 聚类结果分析 (11)4、判别分析 (12)4.1 判别分析过程 (12)4.2判别检验 (17)5、结论 (20)参考文献 (21)致谢 (22)1. 引言1896年,美国第一个篮球组织"全国篮球联盟(简称NBL)"成立,但当时篮球规则还不完善,组织机构也不健全,经过几个赛季后,该组织就名存实亡了。
1946年4月6日,由美国波士顿花园老板沃尔特.阿.布朗发起成立了“美国篮球协会”(简称BAA)。
1949年在布朗的努力下,美国两大篮球组织BAA和NBL合并为“全国篮球协会”(简称NBA)。
NBA季前赛是 NBA各支队伍的热身赛,因为在每个赛季结束后,每支球队在阵容上都有相当大的变化,为了让各队磨合阵容,熟悉各自球队的打法,确定各队新赛季的比赛阵容、同时也能增进队员、教练员之间的沟通,所以在每个赛季开始之前,NBA就举办若干场季前赛,使他们能以比较好的状态投入到漫长的常规赛的比赛当中。
为了扩大NBA在全球的影响,季前赛有约三分之一的球队在美国以外的国家举办。
从总体上看,NBA的赛程安排分为常规赛、季后赛和总决赛。
常规赛采用主客场制,季后赛和总决赛采用七场四胜制的淘汰制。
[31]NBA常规赛从每年的11月的第一个星期二开罗,到次年的4月20日左右结束。
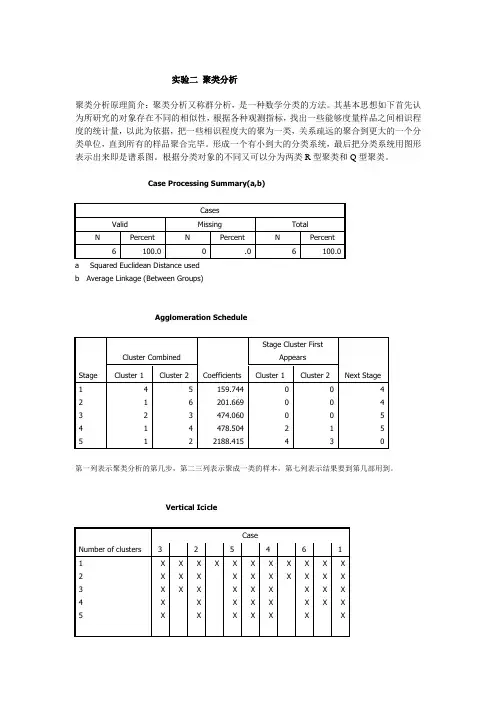
实验二聚类分析
聚类分析原理简介:聚类分析又称群分析,是一种数学分类的方法。
其基本思想如下首先认为所研究的对象存在不同的相似性,根据各种观测指标,找出一些能够度量样品之间相识程度的统计量,以此为依据,把一些相识程度大的聚为一类,关系疏远的聚合到更大的一个分类单位,直到所有的样品聚合完毕。
形成一个有小到大的分类系统,最后把分类系统用图形表示出来即是谱系图。
根据分类对象的不同又可以分为两类R型聚类和Q型聚类。
Case Processing Summary(a,b)
a Squared Euclidean Distance used
b Average Linkage (Between Groups)
Agglomeration Schedule
第一列表示聚类分析的第几步,第二三列表示聚成一类的样本,第七列表示结果要到第几部用到。
Vertical Icicle
样品分类冰柱图
Dendrogram
样品分类谱系图
可知样品分为三类,3、4为第一类,1、2为第二大类,5为孤立元素。

应用数理统计聚类分析与判别分析(第二次作业)学院:姓名:学号:2015年12月目录我国部分城市经济发展水平的聚类分析和判别分析................................. - 1 - 摘要:................................................................... - 1 -1. 引言 ................................................................ - 1 -2. 相关统计基础理论 .................................................... - 1 -2.1 聚类分析......................................................... - 1 -2.2 判别分析......................................................... - 2 -3. 模型建立 ............................................................ - 3 -3.1 设置变量......................................................... - 3 -3.2 数据收集和整理................................................... - 3 -4. 数据结果及分析 ...................................................... - 5 -4.1 聚类分析......................................................... - 5 -4.2 判别分析......................................................... - 7 -5. 结论 ............................................................... - 11 -参考文献................................................................ - 12 -我国部分城市经济发展水平的聚类分析和判别分析摘要:本文基于《中国统计年鉴》(2014年版)统计数据,统计全国各省市居民消费情况,包括各地区农村居民人均纯收入、农村居民人均现金消费、城镇居民人均可支配收入、城镇居民人均现金消费情况共4个指标,利用统计软件SPSS综合考虑各指标,对所选地区进行K-Means 聚类分析,利用Fisher 线性判别待判地区类型,进一步验证所建模型的有效性。

数理统计大作业(2)全国各省、市及自治区产业类型聚类分析和判别分析院(系)名称航空科学与工程学院专业名称飞行器设计与工程学生姓名熊蕾学号ZY15054022015年12月全国各省、市及自治区产业类型聚类分析和判别分析ZY1505402 熊蕾摘要本文从中国统计年鉴(2014)中获得了2013年按三次产业分地区生产总值的数据,按各省的第一产业、第二产业和第三产业产值所占地区生产总值的比值不同,对全国23个省、4个直辖市和5个少数民族自治区进行聚类分析和判别分析。
关键词经济类型聚类分析判别分析一、引言产业是指具有某种同类属性的经济活动的集合或系统,是经济社会的物质生产部门。
世界各国把各种产业划分为三大类:第一产业、第二产业和第三产业。
第一产业是指提供生产资料的产业,包括种植业、林业、畜牧业、水产养殖业等直接以自然物为对象的生产部门。
第二产业是指加工产业,利用基本的生产资料进行加工并出售,包括采矿业、制造业、电力、燃气和水的生产和供应业和建筑业。
第三产业又称服务业,它是指第一、第二产业以外的其他行业。
第三产业行业广泛。
包括交通运输业、通讯业、商业、餐饮业、金融保险业、行政、家庭服务等非物质生产部门。
我国区域经济发展不平衡,各地区的产业类型和产业结构不尽相同,因此可以以各省的第一产业、第二产业和第三产业产值所占地区生产总值的比值对全国的23个省、4个直辖市和5个少数民族自治区进行分类。
二、聚类分析2.1数据输入从中国统计年鉴中得到了2013年按三次产业分地区生产总值的数据,如下表所示,产值单位均为亿元,由于各省经济发展程度不同,地区生产总值有较大的差别,因此要算出各地区三大产业所占的比值来进行聚类和判别分析。
表 1 原始数据2.2聚类分析从表1中选出湖南、安徽和西藏三个地区的数据以待判别,对其余地区的数据进行聚类分析。
表 2 聚类分析数据将表2数据导入SPSS,进行系统聚类分析,得到以下结果:表 3 聚类表阶群集组合系数首次出现阶群集下一阶群集 1 群集 2 群集 1 群集 21 7 13 .052 0 0 92 6 12 .109 0 0 133 14 20 .174 0 0 54 3 21 .244 0 0 95 14 27 .336 3 0 166 5 24 .465 0 0 127 8 23 .602 0 0 198 11 17 .742 0 0 109 3 7 .952 4 1 1510 10 11 1.163 0 8 1711 18 28 1.381 0 0 1812 5 26 1.641 6 0 2013 4 6 1.977 0 2 1614 16 25 2.315 0 0 1815 3 15 2.673 9 0 2016 4 14 3.149 13 5 2317 2 10 3.678 0 10 2318 16 18 4.238 14 11 2119 8 22 4.814 7 0 2120 3 5 5.523 15 12 2521 8 16 6.429 19 18 2422 1 9 7.640 0 0 2623 2 4 9.318 17 16 2524 8 19 11.431 21 0 2625 2 3 14.946 23 20 2726 1 8 20.495 22 24 2727 1 2 26.551 26 25 0表4 群集成员案例8 群集7 群集 6 群集 5 群集 4 群集 3 群集1:北京 1 1 1 1 1 1 2:天津 2 2 2 2 2 2 3:河北 3 3 3 3 3 2 4:山西 4 4 4 2 2 2 5:内蒙古 3 3 3 3 3 2 6:辽宁 4 4 4 2 2 2 7:吉林 3 3 3 3 3 2 8:黑龙江 5 5 5 4 4 3 9:上海 6 6 1 1 1 1 10:江苏 2 2 2 2 2 2 11:浙江 2 2 2 2 2 2 12:福建 4 4 4 2 2 2 13:江西 3 3 3 3 3 2 14:山东 4 4 4 2 2 2 15:河南 3 3 3 3 3 2 16:湖北7 5 5 4 4 3 17:广东 2 2 2 2 2 2 18:广西7 5 5 4 4 3 19:海南8 7 6 5 4 3 20:重庆 4 4 4 2 2 2 21:四川 3 3 3 3 3 2 22:贵州 5 5 5 4 4 3 23:云南 5 5 5 4 4 3 24:陕西 3 3 3 3 3 2 25:甘肃7 5 5 4 4 3 26:青海 3 3 3 3 3 2 27:宁夏 4 4 4 2 2 2 28:新疆7 5 5 4 4 3图1聚类分析树状图从树状图中,我们定下聚类分析最终得到四个组别:1为北京和上海,可以看出这两个直辖市的总产值中,第三产业也就是服务业占有绝对优势,因此可将第一组作为第三产业为主的地区;2为天津、山西、江苏、广东等10个省份,这些省份的第二产业占有较多的比重,而第一产业仅占极少的比重,说明第2组以第二、三产业为主;第三组包括河北、河南、吉林、江西等省份,这些省份虽然也是第二产业占有的比重最大,但它们的第一产业的比重与第1、2组相比更多;第四组的各个地区是传统的鱼米之乡,可以看到它们的第一产业的比重大于其他各组。



数理统计大作业(二)全国各省发展程度的聚类分析及判别分析指导教师院系名称材料科学与工程院学号学生姓名2015 年 12 月21 日目录全国各省发展程度的聚类分析及判别分析 (1)摘要: (1)引言 (1)1实验方案 (2)1.1数据统计 (2)1.2聚类分析 (3)1.3判别分析 (4)2结果分析与讨论 (5)2.1聚类分析结果 (5)2.2聚类分析结果分析: (8)2.3判别分析结果 (9)2.4 Fisher判别结果分析: (11)参考文献: (16)全国各省发展程度的聚类分析及判别分析摘要:利用SPSS软件对全国31个省、直辖市、自治区(浙江、安徽、甘肃除外)的主要经济指标进行多种聚类分析,分析选择最佳聚类类数,并对浙江、湖南、甘肃进行类型判别分析。
通过这两个方法对全国各省进行发展分类。
本文选取了7项社会发展指标作为决定发展程度的影响因素,其中经济因素为主要因素,同时评估城镇化率和人口素质因素。
各项数据均来自2014年国家统计年鉴。
分析结果表明:北京市和上海市和天津市为同一类;江苏省和山东省和广东省为同一类型;河北、湖北、河南、湖南、四川、辽宁为同一类;其余的为另一类。
关键词:聚类分析、判别分析、发展引言聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称。
它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
系统聚类分析又称集群分析,是聚类分析中应用最广的一种方法,它根据样本的多指标(变量)、多个观察数据,定量地确定样品、指标之间存在的相似性或亲疏关系,并据此连结这些样品或指标,归成大小类群,构成分类树状图或冰柱图。
判别分析是根据多种因素(指标)对事物的影响来实现对事物的分类,从而对事物进行判别分类的统计方法。
判别分析适用于已经掌握了历史上分类的每一个类别的若干样品,希望根据这些历史的经验(样品),总结出分类的规律性(判别函数)来指导未来的分类。

北航数值分析大作业第二题本页仅作为文档封面,使用时可以删除This document is for reference only-rar21year.March数值分析第二次大作业史立峰SY1505327一、 方案(1)利用循环结构将sin(0.50.2)()1.5cos( 1.2)(){i j i j ij i j i j a +≠+==(i,j=1,2,……,10)进行赋值,得到需要变换的矩阵A ;(2)然后,对矩阵A 利用Householder 矩阵进行相似变换,把A 化为上三角矩阵A (n-1)。
对A 拟上三角化,得到拟上三角矩阵A (n-1),具体算法如下: 记A(1)=A ,并记A(r)的第r 列至第n 列的元素为()n r r j n i a r ij,,1,;,,2,1)( +==。
对于2,,2,1-=n r 执行 1. 若()n r r i a r ir,,3,2)( ++=全为零,则令A(r+1) =A(r),转5;否则转2。
2. 计算()∑+==nr i r irr a d 12)(()()r r r r r r r r r r d c a d a c ==-=++则取,0sgn )(,1)(,1若 )(,12r rr r r r a c c h +-=3. 令()nTr nrr r r r r r r r R a a c a u ∈-=++)()(,2)(,1,,,,0,,0 。
4. 计算r r T r r h u A p /)(= r r r r h u A q /)(=r r Tr r h u p t /=r r r r u t q -=ωT rr T r r r r p u u A A --=+ω)()1(5. 继续。
(3)使用带双步位移的QR 方法计算矩阵A (n-1)的全部特征值,也是A 的全部特征值,具体算法如下:1. 给定精度水平0>ε和迭代最大次数L 。
北京航空航天大学研究生课程《数理统计B》论文地区生产总值的聚类分析与判别分析姓名:***学号:SY*******授课教师:***日期:2011-1-2地区生产总值的聚类分析与判别分析姓名:王青云学号:SY1001243摘要:为了了解全国各地区的经济类型,需要对地区进行分类,可以利用社会科学统计软件包(简称SPSS)对地区经济情况进行聚类分析和判别分析。
该工作依据地区生产总值、第一产业、工业、建筑业、交通运仓储及邮电通讯业、批发零售贸易及餐饮业、金融保险业、房地产业八个指标对2009年全国31个省和直辖市的经济类型进行了聚类分析,将不同地区的经济类型划分类别;并随机抽取了北京、福建、山东三省进行判别分析。
关键词:经济类型,聚类分析,判别分析,SPSS一引言人们认识事物时往往先把被认识的对象进行分类,以便寻找其中同与不同的特征,因而分类学是人们认识世界的基础科学。
统计学中常用的分类统计方法主要是聚类分析与判别分析。
聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
判别分析则先根据已知类别的事物的性质,利用某种技术建立函数式,然后对未知类别的新事物进行判断以将之归入已知的类别中。
聚类分析与判别分析有很大的不同,聚类分析事先并不知道对象类别的面貌,甚至连共有几个类别也不确定;判别分析事先已知对象的类别和类别数,它正是从这样的情形下总结出分类方法,用于对新对象的分类[1]。
二分析方法问题:根据地区各行业收入对全国各地区经济类型进行分类。
方法:先进行聚类分析,再进行判别分析,采用SPSS软件进行。
2009年全国31个省市的地区总产值、第一产业、工业、建筑业、交通运仓储及邮电通讯业、批发零售贸易及餐饮业、金融保险业、房地产业、其他行业表1所示[2]。
2.1聚类分析(1)在SPSS数据编辑窗口中输入表1中数据:表1 2009年地区生产收入地区地区生第一第二产业第三产业工业建筑业交通运输和邮政业批发和零售业住宿和餐饮业金融业房地产业其他北京12153.03118.292303.08552.47556.641525.03262.511603.631062.474168.91天津7521.85128.853622.11365.73471.01836.84131.84461.2308.731195.54河北17235.482207.347983.86975.971491.921157.8247.14525.67612.42033.38山西7358.31477.593518.88474.92523.38557.86203.58361.64173.311067.15内蒙古9740.25929.64503.33610.67773.29915.89294.73291.1286.651134.99辽宁15212.491414.96925.63980.71790.561410.33318.8560.2605.272206.09吉林7278.75980.573054.6487.32341.76673.12157.73180.83200.141202.68黑龙江85871154.333549.73510.99433.55757.36211227.54301.181441.32上海15046.45113.825408.75593.03635.012183.85238.361804.281237.562831.79江苏34457.32261.8616464.942101.431423.253579.81678.361596.982025.394325.28浙江22990.351163.0810518.211390.28888.022119.39416.841899.331316.833278.36安徽10062.821495.454064.72840.5467.92733.19157.14359.6497.941446.36福建12236.531182.745106.38898.92751.421043.42235.98612.2656.611748.86江西7655.181098.663196.56722.89394.9553.89167.59165.1305.91049.69山东33896.653226.6416896.142005.691742.333106.24594.51044.91329.593950.63河南19480.462769.059900.271110.23823.571057.81526.51499.92622.982170.12湖北12961.11795.95183.68854.4642.72979.14337.81479.11546.112142.23湖南13059.691969.694819.4867.79704.831221.2304.93402.57400.112369.17广东39482.562010.2718091.561328.141595.343907.43945.762283.292470.636850.14广西7759.161458.492863.84517.7378.75551.14208336.82348.981095.45海南1654.21462.19300.63142.888.68168.7560.2265.73121.76243.45重庆6530.01606.82917.4531.37347.98524.36132.88389.97229.09850.16四川14151.282240.615678.241033.63520.71868.98405.45524.63548.142330.89贵州3912.68550.271252.67223.95399.77293.53153.41194.44136.15708.49云南6169.751067.62088.17494.36179.45571.03162.1351.74205.141050.16西藏441.3663.8833.11103.5221.1927.0614.723.1713.28141.45陕西8169.8789.643501.25735.17423.24707.39175.01336.21239.921261.97甘肃3387.56497.051203.7323.54213.64231.2188.5288.27101.37640.26青海1081.27107.4470.3310549.3266.1314.5445.6323.05199.87宁夏1353.31127.25520.38141.94114.7774.5225.5975.5447.56225.76新疆4277.05759.741555.84373.75209.095253.662.25198.87115.23748.67(2)定义聚类类型:在“Analyze”菜单“Classify”中选择Hierarchical命令,在弹出的Hierarchical Cluster Analysis 对话框中,从对话框左侧的变量列表中选择地区变量,使之添加到Lable Cases by框中,同样将指标第一产业,工业,建筑业,交通运仓储及邮电通讯业,批发零售贸易及餐饮业,金融保险业,房地产业,其他行业添加到Variable(s)框中。
数理统计第二次大作业材料行业股票的聚类分析与判别分析2015年12月26日材料行业股票的聚类分析与判别分析摘要1 引言2 数据采集及标准化处理2.1 数据采集本文选取的数据来自大智慧软件的股票基本资料分析数据,从材料行业的股票中选取了30支股票2015年1月至9月的7项财务指标作为分类的自变量,分别是每股收益(单位:元)、净资产收益率(单位:%)、每股经营现金流(单位:元)、主营业务收入同比增长率(单位:%)、净利润同比增长率(单位:%)、流通股本(单位:万股)、每股净资产(单位:元)。
各变量的符号说明见表2.1,整理后的数据如表2.2。
表2.1 各变量的符号说明自变量符号每股收益(单位:元)X1净资产收益率(单位:%)X2每股经营现金流(单位:元)X3主营业务收入同比增长率(单位:%)X4净利润同比增长率(单位:%)X5流通股本(单位:万股)X6每股净资产(单位:元)X7表2.2 30支股票的财务指标股票代码X1 X2 X3 X4 X5 X6 X7 武钢股份600005-0.0990-2.81-0.0237-35.21-200.231009377.98 3.4444宝钢股份6000190.1400 1.980.9351-14.90-55.011642427.88 6.9197山东钢铁600022-0.11650.060.0938-20.5421.76643629.58 1.8734北方稀土6001110.0830 3.640.652218.33-24.02221920.48 2.2856杭钢股份600126-0.4900-13.190.4184-36.59-8191.0283893.88 3.4497抚顺特钢6003990.219310.080.1703-14.26714.18112962.28 1.4667盛和资源6003920.0247 1.84-0.2141-5.96-19.3739150.00 1.2796宁夏建材6004490.04000.510.3795-22.15-92.3447818.108.7321宝钛股份600456-0.2090-2.53-0.3313-14.81-6070.2043026.578.1497山东药玻6005290.4404 5.26 1.2013 6.5016.7825738.018.5230国睿科技6005620.410011.53-0.2949 3.3018.9416817.86 3.6765海螺水泥600585 1.15169.05 1.1960-13.06-25.33399970.2612.9100华建集团6006290.224012.75-0.57877.90-6.4034799.98 1.8421福耀玻璃6006600.790014.250.9015 3.6017.27200298.63 6.2419宁波富邦600768-0.2200-35.02-0.5129 3.1217.8813374.720.5188马钢股份600808-0.3344-11.710.3939-21.85-689.22596775.12 2.6854亚泰集团6008810.02000.600.1400-23.63-68.16189473.21 4.5127博闻科技6008830.503516.71-0.1010-10.992612.8023608.80 3.0126新疆众和6008880.0523 1.04-0.910662.64162.0464122.59 5.0385西部黄金6010690.0969 3.940.115115.5125.5712600.00 2.4965中国铝业601600-0.0700-2.920.2066-9.0882.79958052.19 2.3811明泰铝业6016770.2688 4.66-1.09040.8227.8640770.247.4850金隅股份6019920.1989 3.390.3310-10.05-39.01311140.26 6.7772松发股份6032680.35007.00-0.3195-4.43-9.622200.00 6.0244方大集团0000550.0950 5.66-0.480939.2920.6742017.94 1.6961铜陵有色0006300.0200 1.220.6132 3.23-30.74956045.21 1.5443鞍钢股份000898-0.1230-1.870.7067-27.32-196.21614893.17 6.4932中钢国际0009280.572714.45-0.4048-14.33410.2441286.57 4.2449中材科技0020800.684610.27 1.219547.69282.1740000.00 6.8936中南重工0024450.1100 4.300.340518.8445.0950155.00 2.70302.2 数据的标准化处理由于不同的变量之间存在着较大的数量级的差别,因此要对数据变量进行标准化处理。
对中国各地财政收入情况的聚类分析和判别分析应用数理统计第二次大作业学院名称学号学生姓名摘要我国幅员辽阔,由于人才、地理位置、自然资源等条件的不同,各地区的财政收入类型各自呈现出不一样的发展趋势,通过准确定位中国各地区财政收入情况对于正确认识我国财政收入具有重要的意义。
本文以中国各地财政收入情况为研究对象,从《中国统计年鉴》中选取2011年期间中国各地财政收入情况为因变量,选取国内增值税、营业税、企业所得税、个人所得税、城市维护建设税、土地增值税、契税、专项收入、行政事业性收费收入、国有资本经营收入和国有资源(资产)有偿使用收入11个可能影响中国各地财政收入的因素为自变量,利用统计软件SPSS,对27个地区的财政收入进行了聚类分析,并对另外4个地区的财政收入进行了判别分析,并最终确定了中国各地区根据财政收入类型的分类情况。
关键词:聚类分析,判别分析,SPSS,中国各地财政收入类型1、引言财政收入,是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而筹集的一切资金的总和。
财政收入表现为政府部门在一定时期内(一般为一个财政年度)所取得的货币收入。
财政收入是衡量一国政府财力的重要指标,政府在社会经济活动中提供公共物品和服务的范围和数量,在很大程度上决定于财政收入的充裕状况。
通过准确定位中国各地区财政收入情况对于正确认识我国财政收入具有重要的意义。
本文利用统计软件SPSS,根据各地区的财政收入情况,对北京、天津、河北等27个地区进行聚类分析,并对青海、重庆、四川、贵州4个省市进行判别分析,判断属于聚类分析结果中的哪种财政收入类型。
1.1 聚类分析聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称,它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
本文采用的是系统聚类分析,它又称集群分析,是聚类分析中应用最广的一种方法,其基本思想是:首先将每个聚类对象看作一类,然后根据对象间的相似程度,将相似程度最高的两类进行合并,并计算合并后的类与其他类之间的距离,再选择相近者进行合并,每合并一次减少一类,直至所有的对象都并为一类为止。