北航数理统计大作业(逐步回归)
- 格式:doc
- 大小:319.50 KB
- 文档页数:16

应用数理统计大作业1——逐步回归法分析终应用数理统计多元线性回归分析(第一次作业)学院:机械工程及自动化学院姓名:学号:2014年12月逐步回归法在AMHS物流仿真结果中的应用摘要:本文针对自动化物料搬运系统 (Automatic Material Handling System,AMHS)的仿真结果,根据逐步回归法,使用软件IBM SPSS Statistics 20,对仿真数据进行分析处理,得到多元线性回归方程,建立了工件年产量箱数与EMS 数量、周转箱交换周期以及AGC物料交换服务水平之间的数学模型,并对影响年产量箱数的显著性因素进行了分析,介绍了基本假设检验的情况。
关键词:逐步回归;残差;SPSS;AMHS;物流仿真目录1、引言 (1)2、逐步回归法原理 (4)3、模型建立 (6)3.1确定自变量和因变量 (6)3.2分析数据准备 (6)3.3逐步回归分析 (7)4、结果输出及分析 (9)4.1输入/移去的变量 (9)4.2模型汇总 (10)4.3方差分析 (10)4.4回归系数 (11)4.5已排除的变量 (12)4.6残差统计量 (13)4.7残差分布直方图和观测量累计概率P-P图 (14)5、异常情况说明 (15)5.1异方差检验 (15)5.2残差的独立性检验 (17)5.3多重共线性检验 (17)6、结论 (18)参考文献 (20)1、引言回归被用于研究可以测量的变量之间的关系,线性回归则被用于研究一类特殊的关系,即可用直线或多维的直线描述的关系。
这一技术被用于几乎所有的研究领域,包括社会科学、物理、生物、科技、经济和人文科学。
逐步回归是在剔除自变量间相互作用、相互影响的前提下,计算各个自变量x与因变量y之间的相关性,并在此基础上建立对因变量y有最大影响的变量子集的回归方程。
SPSS(Statistical Package for the Social Science社会科学统计软件包)是世界著名的统计软件之一,目前SPSS公司已将它的英文名称更改为Statistical Product and Service Solution,意为“统计产品与服务解决方案”。

应用数理统计作业二学号:姓名:电话:二〇一四年十二月对NBA球队的聚类分析和判别分析摘要:NBA联盟作为篮球的最高殿堂深受广大球迷的喜爱,联盟的30支球队大家也耳熟能详,本文选取NBA联盟30支球队2013-2014常规赛赛季场均数据。
利用spss软件通过聚类分析对27个地区进行实力类型分类,并利用判断分析对其余3支球队对分类结果进行验证。
可以看出各球队实力类型与赛季实际结果相吻合。
关键词:聚类分析,判别分析,NBA目录1. 引言 (4)2、相关统计基础理论 (5)2.1、聚类分析 (5)2.2,判别分析 (6)3.聚类分析 (7)3.1数据文件 (7)3.2聚类分析过程 (9)3.3 聚类结果分析 (11)4、判别分析 (12)4.1 判别分析过程 (12)4.2判别检验 (17)5、结论 (20)参考文献 (21)致谢 (22)1. 引言1896年,美国第一个篮球组织"全国篮球联盟(简称NBL)"成立,但当时篮球规则还不完善,组织机构也不健全,经过几个赛季后,该组织就名存实亡了。
1946年4月6日,由美国波士顿花园老板沃尔特.阿.布朗发起成立了“美国篮球协会”(简称BAA)。
1949年在布朗的努力下,美国两大篮球组织BAA和NBL合并为“全国篮球协会”(简称NBA)。
NBA季前赛是 NBA各支队伍的热身赛,因为在每个赛季结束后,每支球队在阵容上都有相当大的变化,为了让各队磨合阵容,熟悉各自球队的打法,确定各队新赛季的比赛阵容、同时也能增进队员、教练员之间的沟通,所以在每个赛季开始之前,NBA就举办若干场季前赛,使他们能以比较好的状态投入到漫长的常规赛的比赛当中。
为了扩大NBA在全球的影响,季前赛有约三分之一的球队在美国以外的国家举办。
从总体上看,NBA的赛程安排分为常规赛、季后赛和总决赛。
常规赛采用主客场制,季后赛和总决赛采用七场四胜制的淘汰制。
[31]NBA常规赛从每年的11月的第一个星期二开罗,到次年的4月20日左右结束。

数理统计第一次课程论文广州恒大队在2015赛季亚冠的进球数的多元线性回归模型学号: SY1527205姓名:郭谢有摘要本赛季亚洲冠军联赛,来自中国的球队广州恒大淘宝队最终在决赛中力克阿联酋的迪拜阿赫利队,三年之内第二次夺得亚冠冠军。
为了研究恒大的夺冠过程,本文选取了恒大该赛季亚冠总共15场比赛中的进球数为因变量,对可能影响进球数的射门数、射正数等7个自变量进行统计,并进一步利用统计软件SPSS对以上数据进行了多元逐步线性回归。
最终确定了进球数与各因素之间关系的“最优”回归方程。
关键词:多元线性回归,逐步回归法,广州恒大,SPSS目录摘要 (1)1.引言 (3)2.符号说明 (3)3.数据的采集和整理 (3)3.1数据的采集 (3)3.2建模 (4)4.数据分析及计算 (4)4.结论 (9)参考文献 (10)致谢 (10)1.引言一场足球比赛的进球数说明了一支球队攻击力的强弱,也是决定比赛胜负的至关因素,综合反映出这支球队的实际水平。
而作为竞技体育,足球场上影响进球数的因素很多,为了研究本赛季恒大在亚冠夺冠过程中的14场比赛中进球数与其他一些因素的关系,本论文从搜达足球和新浪体育数据库中查找了进球数和其他7个主要影响因素的数据,包括射门次数、射正次数、传球次数、传中次数、角球次数、抢断次数。
并进一步采用多元逐步回归分析方法对以上因素进行了显著性分析,从而确定了关于恒大在本赛季亚冠中进球数的最优多元线型回归方程。
2.符号说明3.数据的采集和整理3.1数据的采集本文统计数据时,查阅了搜达足球数据库,确定恒大在亚冠14场比赛中的进球数为因变量,并初步选取这14场比赛中的射门次数、射正次数、传球次数、传中次数、角球次数、抢断次数7因素为自变量,具体数据见下表1。
3.2建模本文选取了恒大在亚冠比赛中的进球数作为因变量y,并选取可能对进球数造成影响的因素为自变量,其中对应关系在符号说明中已经列举。
这里构建模型如下:7⋅X i+εy=β0+∑βii=1其中,其中ε为随机误差项,β0为常数项,βi为待估计的参数。

多元线性回归分析摘要:本文查找2011年《中国统计年鉴》,取我国31个省市自治区直辖市2010年的数据,利用SPSS软件对影响居民消费的因素进行讨论构造线性回归模型。
并对模型的回归显著性、拟合度、正态分布等分别进行检验,最终得到最优线性回归模型,寻找影响居民消费的各个因素。
关键字:回归分析;线性;相关系数;正态分布1. 引言变量与变量之间的关系分为确定性关系和非确定性关系,函数表达确定性关系。
研究变量间的非确定性关系,构造变量间经验公式的数理统计方法称为回归分析。
回归分析是指通过提供变量之间的数学表达式来定量描述变量间相关关系的数学过程,这一数学表达式通常称为经验公式。
一方面,研究者可以利用概率统计知识,对这个经验公式的有效性进行判定;另一方面,研究者可以利用经验公式,根据自变量的取值预测因变量的取值。
如果是多个因素作为自变量的时候,还可以通过因素分析,找出哪些自变量对因变量的影响是显著的,哪些是不显著的。
回归分析目前在生物统计、医学统计、经济分析、数据挖掘中得到了广泛的应用。
通过对训练数据进行回归分析得出经验公式,利用经验公式就可以在已知自变量的情况下预测因变量的取值。
实际问题的控制中往往是根据预测结果来进行的,如在商品流通领域,通常用回归分析商品价和与商品需求之间的关系,以便对商品的价格和需求量进行控制。
本文查找2011年《中国统计年鉴》,取我国31个省市自治区直辖市2010年的数据,利用SPSS软件对影响居民消费的因素进行讨论构造多元线性线性回归模型。
以探求影响居民消费水平的各个因素,得到最优线性回归模型。
随后,我们对模型的回归显著性、拟合度、正态分布等分别进行检验,以考察线性回归模型的可信度。
本文将分为5章进行论述。
在第2章,我们介绍多元线性回归模型的概念。
第3章,我们进行模型的建立与数据的收集和整理。
我们在第4章对数据进行处理,得出多元线性回归模型,并对其进行检验。
在第5章,我们进行总结。

北航数理统计答案【篇一:北航数理统计考试题】术部2011年12月2007-2008学年第一学期期末试卷一、(6分,a班不做)设x1,x2,…,xn是来自正态总体n(?,?2)的样本,令t?x?x),试证明t服从t-分布t(2)二、(6分,b班不做)统计量f-f(n,m)分布,证明1f的?(0?1)的分位点x?是1f1??(n,m)。
三、(8分)设总体x的密度函数为?(1??)x?,0?x?1p(x;?)??0,其他?其中???1,是位置参数。
x1,x2,…,xn是来自总体试求参数?的矩估计和极大似然估计。
四、(12分)设总体x的密度函数为?1?x???exp???,x???p(x;?)??????,??0,其它其中???????,?已知,??0,?是未知参数。
x1,x2,…,xn是来自总?体x的简单样本。
(1)试求参数?的一致最小方差无偏估计?;(2)?是否为?的有效估计?证明你的结论。
五、(6分,a班不做)设x1,x2,…,xn是来自正态总体n(?简单样本,y1,y2,…,yn是来自正态总体n(?两样本相互独立,其中?设h0:?1??2,h1:?1??2,1221?,?1)2的,?2)的简单样本,且21,?1,?2,?222是未知参数,???22。
为检验假可令zi?xi?yi, i?1,2,...,n ,???1??2 ,则上述假设检验问题等价于h0:?1?0,h1:?1?0,这样双样本检验问题就变为单检验问题。
基于变换后样本z1,z2,…,zn,在显著性水平?下,试构造检验上述问题的t-检验统计量及相应的拒绝域。
六、(6分,b班不做)设x1,x2,…,xn是来自正态总体n(?简单样本,?0已知,?2未知,试求假设检验问题h0:?2,?)02的??0,h1:?22??02的水平为?的umpt。
七、(6分)根据大作业情况,试简述你在应用线性回归分析解决实际问题时应该注意哪些方面?八、(6分)设方差分析模型为?xij????i??j??ij?2??ij服从正态总体分布n(0,?)且?ij相互独立??i?1,2,...,p;j?1,...,q?pq??和?满足??i?0,??j?0.j?ii?1j?1?总离差平方和pst?sa?sb?se中sa?q?(xi??x),x?i?1x??pqi?1j?11pqij,xi??1qijx?qj?1,且e(se)=(p-1)(q-1)?.?...??p?0的拒绝2试求e(sa),并根据直观分析给出检验假设h0:?1??2域形式。

北京航空航天大事BEIHANG UNIVERSITY应用数理统计第一次大作业学号:______姓名:______________班级: __________20 15年12月民航客运量得多元线性回归分析摘要:本文为建立以民航客运量为因变量得多元线性回归模型,选取了199 6年至2013年得统计数据,包含国民生产总值,民航航线里程,过夜入境旅游人数,城镇居民可支配收入等因素,利用统计•软件SPSS对各因素进行了筛选分析,采用逐步回归法得到最优多元线性回归模型,并对模型得回归显著性、拟合度以及随机误差得正态性进行了检验,并采用201 4年得数据进行检验,得到得结果达到预期,证明该模型建立就是较为成功得.关键词:多元线性回归,逐步回归法,民航客运量0、符号说明变量符号民用航空客运量Y国民生产总值X,民航航线里程X3城镇居民人均可支配收入X51、引言随着社会得进步,人民生活水平得提高,如何获得更快捷方便得交通成为人们日益关注得问题•因为航空得安全性,快速且价格水平越来越倾向大众,越来越多得人们选择航空这种交通方式。
近年来,我国得航空客运量已经进入世界前列,为掌握航空客运得动态,合理安排班机数量•科学地对我国民航客运量得影响因素得分析,并得出其回归方程,进而能够估计航空客运量就是非常有必要得。
本文收集整理了与我国航空客运量相关得历年数据,运用SPSS软件对数据进行分析,研究199 6年起至20 13年我国民航客运量y(万人)与国民生产总值Xi(亿元)、铁路客运量X2(万人)、民航航线里程X3 (万公里)、入境过夜旅游人数X4 (万人)、城镇居民人均可支配 收入X5 (元)得关系。
采用逐步回归法建立线 性模型,选出较优得线性回归模型。
2、数据得统计与分析本文在进行统计时,查阅《中国统计摘要》,《中国统计年鉴2 0 14》以及中国 知网数据查询中得数据,收集了 19 96年至201 3年各个自变量因素得数据,分析它们 之间得联系。

北京市财政收入的逐步回归模型研究摘要:财政收入水平高低是反映一国经济实力的重要标志,关系着一个国家经济的发展和社会的进步。
本文根据北京市2012年度统计年鉴,选取了农林牧渔业总产值、工业总产值、建筑业总产值、常驻总人口数、社会消费品零售总额、入境旅游人数、客运量、货运量、全社会固定资产投资以及第三产业总产值,共10个指标,对北京市财政收入及其可能的影响因素进行了研究。
文中运用逐步线性回归方法建立了多元线性回归模型,分析各因素对该地区财政收入的影响;利用SPSS软件进行求解。
通过分析SPSS软件计算的数据,从相关性检验、多重共线性检验、方差分析以及残差分析四个角度,分别对模型合理性进行了验证。
结果表明,北京市财政收入与建筑业总产值和农林牧渔也总产值呈显著线性关系。
其中与建筑业正相关,与农林牧渔业负相关。
关键字:财政收入,多元,逐步线性回归,SPSS1. 引言财政收入是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而集中的一切资金的综合,包括税收、企事业收入、能源交通重点建设基金收入、债务收入、规费收入、罚没收入等[1]。
财政收入水平高低是反映一国经济实力的重要标志,关系着一个国家经济的发展和社会的进步。
因此,研究财政收入的增长及就显得尤为必要[2]。
一个地区的财政收入可能受到诸多因素的影响,如工业总产值、农业总产值、建筑业总产值、人口数等。
本文以北京市为例,以财政收入为因变量,选取农林牧渔业总产值、工业总产值、建筑业总产值、常驻总人口数、社会消费品零售总额、入境旅游人数、客运量、货运量、全社会固定资产投资以及第三产业总产值这10个指标为自变量,利用SPSS统计软件进行回归分析,建立财政收入影响因素模型,分析影响财政收入的主要因素及其影响程度。
2. 理论概述2.1 多元线性回归[3]在许多实际问题中,影响一个事物的因素常常不止一个,采用多元线性回归分析方法可以找出这些因素与事物之间的数量关系。
北京市农业经济总产值的逐步回归分析姓名:学号:摘要:农业生产和农村经济是国民经济的基础,影响农村经济总产值的因素有多种,主要包括农林牧渔业。
本文以北京市农业生产和农村经济总产值为对象,首先分析了各种因素的线性相关性,建立回归模型,再利用逐步回归法进行回归分析,得到最符合实际情况的回归模型。
以SPSS 17.0为分析工具,给出了实验结果,并用预测值验证了结论的正确性。
关键词:农业生产和农村经济,线性回归模型,逐步回归分析,SPSS1.引言农林牧渔业统计范围包括辖区内全部农林牧渔业生产单位、非农行业单位附属的农林牧渔业生产活动单位以及农户的农业生产活动。
军委系统的农林牧渔业生产(除军马外)也应包括在内,但不包括农业科学试验机构进行的农业生产。
在近几年中国经济快速增长的带动下,各地区农林牧渔业也得到了突飞猛进的发展。
以北京地区为例,2005年的农业总产值为1993年的6倍。
因此用统计方法研究分析农业总产值对指导国民经济生产,合理有效的进行产业布局,提高生产力等有着重要意义。
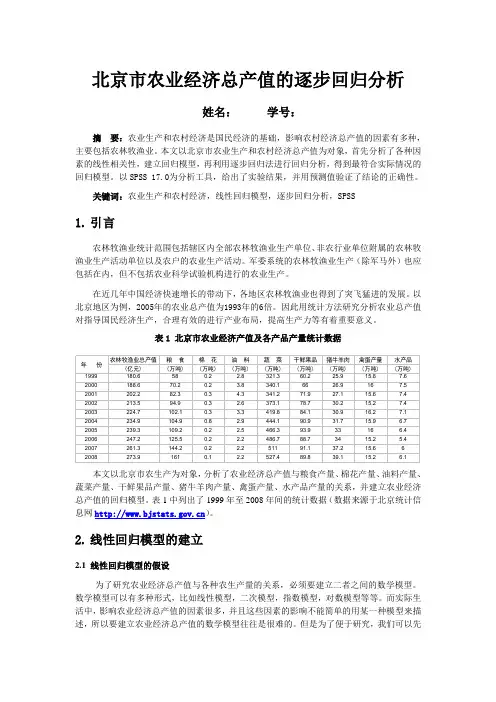
表1 北京市农业经济产值及各产品产量统计数据本文以北京市农生产为对象,分析了农业经济总产值与粮食产量、棉花产量、油料产量、蔬菜产量、干鲜果品产量、猪牛羊肉产量、禽蛋产量、水产品产量的关系,并建立农业经济总产值的回归模型。
表1中列出了1999年至2008年间的统计数据(数据来源于北京统计信息网)。
2.线性回归模型的建立2.1 线性回归模型的假设为了研究农业经济总产值与各种农生产量的关系,必须要建立二者之间的数学模型。
数学模型可以有多种形式,比如线性模型,二次模型,指数模型,对数模型等等。
而实际生活中,影响农业经济总产值的因素很多,并且这些因素的影响不能简单的用某一种模型来描述,所以要建立农业经济总产值的数学模型往往是很难的。
但是为了便于研究,我们可以先假定一些前提条件,然后在这些条件下得到简化后的近似模型。
以下我们假定两个前提条件:1) 农产品的价格是不变的。

应用数理统计第一次大作业学号:姓名:班级:B11班2015年12月民航客运量的多元线性回归分析摘要:本文为建立以民航客运量为因变量的多元线性回归模型,选取了1996年至2013年的统计数据,包含国民生产总值,民航航线里程,过夜入境旅游人数,城镇居民可支配收入等因素,利用统计软件SPSS对各因素进行了筛选分析,采用逐步回归法得到最优多元线性回归模型,并对模型的回归显著性、拟合度以及随机误差的正态性进行了检验,并采用2014年的数据进行检验,得到的结果达到预期,证明该模型建立是较为成功的。
关键词:多元线性回归,逐步回归法,民航客运量0.符号说明变量符号国民生产总值X1铁路客运量X2民航航线里程X3入境过夜旅游人数X4城镇居民人均可支配收入X51.引言随着社会的进步,人民生活水平的提高,如何获得更快捷方便的交通成为人们日益关注的问题。
因为航空的安全性,快速且价格水平越来越倾向大众,越来越多的人们选择航空这种交通方式。
近年来,我国的航空客运量已经进入世界前列,为掌握航空客运的动态,合理安排班机数量。
科学地对我国民航客运量的影响因素的分析,并得出其回归方程,进而能够估计航空客运量是非常有必要的。
本文收集整理了与我国航空客运量相关的历年数据,运用SPSS软件对数据进行分析,研究1996年起至2013年我国民航客运量y(万人)与国民生产总值X1(亿元)、铁路客运量X2(万人)、民航航线里程X3(万公里)、入境过夜旅游人数X4(万人)、城镇居民人均可支配收入X5(元)的关系。
采用逐步回归法建立线性模型,选出较优的线性回归模型。
2.数据的统计与分析本文在进行统计时,查阅《中国统计摘要》,《中国统计年鉴2014》以及中国知网数据查询中的数据,收集了1996年至2013年各个自变量因素的数据,分析它们之间的联系。
整理如表1所示。
表1:2.1模型的建立以民航客运量y为因变量,以上5种影响因素为自变量X i,构建回归方程:y=β0+βi X i+ε其中β0为常数项,ε为误差项。


北航2010《应用数理统计》考试题及参考解答09B一、填空题(每小题3分,共15分) 1,设总体X 服从正态分布(0,4)N ,而1215(,,)X X X 是来自X 的样本,则221102211152()X X U X X ++=++服从的分布是_______ .解:(10,5)F .2,ˆnθ是总体未知参数θ的相合估计量的一个充分条件是_______ . 解:ˆˆlim (), lim Var()0n nn n E θθθ→∞→∞==. 3,分布拟合检验方法有_______ 与____ ___. 解:2χ检验、柯尔莫哥洛夫检验. 4,方差分析的目的是_______ .解:推断各因素对试验结果影响是否显著.5,多元线性回归模型=+Y βX ε中,β的最小二乘估计ˆβ的协方差矩阵ˆβCov()=_______ . 解:1ˆσ-'2Cov(β)=()X X . 二、单项选择题(每小题3分,共15分)1,设总体~(1,9)X N ,129(,,,)X X X 是X 的样本,则___B___ .(A )1~(0,1)3X N -; (B )1~(0,1)1X N -; (C )1~(0,1)9X N -; (D ~(0,1)N . 2,若总体2(,)XN μσ,其中2σ已知,当样本容量n 保持不变时,如果置信度1α-减小,则μ的置信区间____B___ . (A )长度变大; (B )长度变小; (C )长度不变; (D )前述都有可能.3,在假设检验中,就检验结果而言,以下说法正确的是____B___ .(A )拒绝和接受原假设的理由都是充分的;(B )拒绝原假设的理由是充分的,接受原假设的理由是不充分的; (C )拒绝原假设的理由是不充分的,接受原假设的理由是充分的;(D )拒绝和接受原假设的理由都是不充分的.4,对于单因素试验方差分析的数学模型,设T S 为总离差平方和,e S 为误差平方和,A S 为效应平方和,则总有___A___ .(A )T e A S S S =+; (B )22(1)AS r χσ-;(C )/(1)(1,)/()A e S r F r n r S n r ----; (D )A S 与e S 相互独立.5,在多元线性回归分析中,设ˆβ是β的最小二乘估计,ˆˆ=-εY βX 是残差向量,则___B____ . (A )ˆn E ()=0ε; (B )1ˆ]σ-''-εX X 2n Cov()=[()I X X ; (C )ˆˆ1n p '--εε是2σ的无偏估计; (D )(A )、(B )、(C )都对.三、(本题10分)设总体21(,)XN μσ、22(,)Y N μσ,112(,,,)n X X X 和212(,,,)n Y Y Y 分别是来自X 和Y 的样本,且两个样本相互独立,X Y 、和22X Y S S 、分别是它们的样本均值和样本方差,证明12(2)X Y t n n +-,其中2221212(1)(1)2X Yn S n S S n n ω-+-=+-.证明:易知221212(,)X YN n n σσμμ--+,(0,1)X Y U N =.由定理可知22112(1)(1)Xn S n χσ--,22222(1)(1)Yn S n χσ--.由独立性和2χ分布的可加性可得222121222(1)(1)(2)XYn S n S V n n χσσ--=++-.由U 与V 得独立性和t 分布的定义可得12(2)X Yt n n=+-.四、(本题10分)设总体X的概率密度为1, 0,21(;),1,2(1)0,xf x xθθθθθ⎧<<⎪⎪⎪=≤<⎨-⎪⎪⎪⎩其他,其中参数01)θθ<<(未知,12()nX X X,,,是来自总体的一个样本,X是样本均值,(1)求参数;的矩估计量θθˆ(2)证明24X不是2θ的无偏估计量.解:(1)11()(,)22(1)42x xE X xf x dx dx dxθθθθθθ+∞-∞==+=+-⎰⎰⎰,令()X E X=,代入上式得到θ的矩估计量为1ˆ22Xθ=-.(2)222211141(4)44[()]4()424E X EX DX EX DX DXn nθθθ⎡⎤==+=++=+++⎢⎥⎣⎦,因为()00D Xθ≥>,,所以22(4)E Xθ>.故24X不是2θ的无偏估计量.五、(本题10分)设总体X服从[0,](0)θθ>上的均匀分布,12(,,)nX X X是来自总体X的一个样本,试求参数θ的极大似然估计.解:X的密度函数为1,0;(,)0,xf xθθθ≤≤⎧=⎨⎩其他,似然函数为1,0,1,2,,,()0,n ix i nLθθθ<<=⎧⎪=⎨⎪⎩其它显然0θ>时,()Lθ是单调减函数,而{}12max,,,nx x xθ≥,所以{}12ˆmax,,,nX X Xθ=是θ的极大似然估计.六、(本题10分)设总体X服从(1,)B p分布,12(,,)nX X X为总体的样本,证明X是参数p的一个UMVUE.证明:X的分布律为1(;)(1),0,1x x f x p p p x -=-=.容易验证(;)f x p 满足正则条件,于是21()ln (;)(1)I p E f x p p p p ⎡⎤∂==⎢⎥∂-⎣⎦. 另一方面1(1)1Var()Var()()p p X X n n nI p -===, 即X 得方差达到C-R 下界的无偏估计量,故X 是p 的一个UMVUE .七、(本题10分)某异常区的磁场强度服从正态分布20(,)N μσ,由以前的观测可知056μ=.现有一台新仪器, 用它对该区进行磁测, 抽测了16个点, 得261, 400x s ==, 问此仪器测出的结果与以往相比是否有明显的差异(α=0.05).附表如下:t 分布表 χ2分布表解:设0H :560==μμ.构造检验统计量)15(~0t ns X t μ-=, 确定拒绝域的形式2t t α⎧⎫>⎨⎬⎩⎭.由05.0=α,定出临界值1315.2025.02/==t t α,从而求出拒绝域{}1315.2>t .而60,16==x n ,从而 ||0.8 2.1315t ===<,接受假设0H ,即认为此仪器测出的结果与以往相比无明显的差异.八、(本题10分)已知两个总体X 与Y 独立,211~(,)X μσ,222~(,)Y μσ,221212, , , μμσσ未知,112(,,,)n X X X 和212(,,,)n Y Y Y 分别是来自X 和Y 的样本,求2122σσ的置信度为1α-的置信区间.解:设布定理知的样本方差,由抽样分,分别表示总体Y X S S 2221 , []/2121/212(1,1)(1,1)1P F n n F F n n ααα---<<--=-, 则222221211221/2122/212//1(1,1)(1,1)S S S S P F n n F n n αασασ-⎛⎫<<=- ⎪----⎝⎭,所求2221σσ的置信度为α-1的置信区间为 222212121/212/212//, (1,1)(1,1)S S S S F n n F n n αα-⎛⎫ ⎪----⎝⎭.九、(本题10分)试简要论述线性回归分析包括哪些内容或步骤.。
数理统计大作业-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII应用数理统计(论文)国家财政收入的逐步回归分析指导教师院系名称学号学生姓名2012年11月18日摘要财政收入是国民经济基础,是实现国家职能的财力保证。
本文采用SPSS统计软件中的逐步回归分析方法,得出影响我国财政收入的显著性变量,建立国家财政收入回归模型,并将所得的模型给予合理的经济解释。
关键字:国家财政收入,逐步回归,SPSS1 引言财政收入是指国家财政参与社会产品分配所取得到的收入,是实现国家职能的财力保证。
影响财政收入的因素有很多,包括工业总产值、农业总产值、建筑业总产值、社会商品零售总额、人口数、受灾面积等等。
在经济模型的建立中,其中有些自变量对问题的研究可能并不重要,有些自变量数据的质量可能很差,有些变量可能和其它变量有很大程度的重叠。
如果用回归模型把这些变量都包含进来不但会使模型计算复杂,而且往往会扩大估计方差,降低模型精度,直接影响到回归方程的应用。
另外,选进太多的自变量又会造成共线性的存在。
因此,本文采用线性回归中的逐步回归方法,利用SPSS多元统计软件得出影响我国财政收入的显著性变量,剔除了不显著的变量,并且克服了变量间的多重共线性,得出了一个较合理的财政回归模型。
2初始模型的建立及数据分析2.1 自变量与因变量的提出本模型是研究1997年至2011年国家财政收入与主要影响因素之间的定量关系。
本文选取财政收入Y(亿元)为因变量,自变量选取如下:第一产业国内生产总值X1(亿元),第二产业国内生产总值X2(亿元,第三产业国内生产总值X3(亿元),社会消费品零售总额X4(亿元),人口数X5(万人),受灾面积X6(万公顷)。
根据《中国统计年鉴》获取1997-2011年共十五年的统计数据,见表1。
表11997-2011年财政收入与部分项目的统计数据财政收入(亿元)第一产业国内生产总值(亿元)第二产业国内生产总值(亿元)第三产业国内生产总值(亿元)社会商品零售总额(亿元)人口总数(万人)受灾面积(万公顷)1997 8651.14 14441.89 37543.00 26988.15 31252.90 123626.00 5342.70 1998 9875.95 14817.63 39004.19 30580.47 33378.10 124761.00 5014.50 1999 11444.08 14770.03 41033.58 33873.44 35647.90 125786.00 4998.00 2000 13395.23 14944.72 45555.88 38713.95 39105.70 126743.00 5468.80 2001 16386.04 15781.27 49512.29 44361.61 43055.40 127627.00 5221.50 2002 18903.64 16537.02 53896.77 49898.90 48135.90 128453.00 4694.60 2003 21715.25 17381.72 62436.31 56004.73 52516.30 129227.00 5450.60 2004 26396.47 21412.73 73904.31 64561.29 59501.00 129988.00 3710.60 2005 31649.29 22420.00 87598.09 74919.28 67176.60 130756.00 3881.80 2006 38760.20 24040.00 103719.54 88554.88 76410.00 131448.00 4109.10 2007 51321.78 28627.00 125831.36 111351.95 89210.00 132129.00 4899.20 2008 61330.35 33702.00 149003.44 131339.99 114830.10 132802.00 3999.00 2009 68518.30 35226.00 157638.78 148038.04 132678.40 133450.00 4721.40 2010 83101.51 40533.60 187383.21 173595.98 156998.40 134091.00 3742.60 2011 103874.43 47486.20 220412.80 204982.50 183918.60 134735.00 3247.10 2.2 做散点图,设定理论模型作数据散点图,并进行线性拟合,观察因变量与自变量之间关系是否有线性特点。
应用数理统计大作业一学院:XXXXXXX学号:XXXXXXX姓名:XXX指导老师:XXX2014年12月21日国民生产总值增量的多元线性回归模型摘要:国民生产总值一直是衡量国家综合经济水平的重要指标,本文要讨论研究的是国民生产总值的增量趋势与各产业增值趋势间的多元线性关系[1]。
本论文搜集了我国从1998至2012年15年的国民生产与各产业增量指标,拟定数个自变量,代入统计软件SPSS 19.0[2]对各影响因素进行了统计分析,综合分析结果模拟多元线性回归函数。
模型建立之后,又将2013年数据作为测试集测试模型的拟合精确度,得到的结果达到预期值,得出模型建立较为成功。
关键词:逐步回归法,国民生产总值增量,线性拟合一引言国民生产总值(Gross Domestic Product)是在一定时期中,一个国家地区经济生产出的全部最终产品和劳务的价值,被公认为衡量国家经济状况的较佳指标。
它不仅仅反映了一定的经济表现,还可以反映国家的综合国力与经济发展前景,作为经济政策的制定依据,研究我国的国民生产总值的制约因素成为了学者们的热点问题。
下文就以1998年至2012年的统计数据为标准,利用SPSS软件作出了多元线性回归分析。
二统计分析2.1变量说明因变量——国民生产总值增值(亿元);自变量——第一产业增加值(亿元)自变量——第二产业增加值(亿元)自变量——第三产业增加值(亿元)自变量——工业增加值(亿元)自变量——建筑业增加值(亿元)2.2统计数据2000年9537.5 14944.72 45555.88 38713.95 40033.59 5522.29 1999年5274.77 14770.03 41033.58 33873.44 35861.48 5172.1 1998年5429.25 14817.63 39004.19 30580.47 34018.43 4985.76 表格2-11998~2012年训练集数据测试组国民生产总值增值(亿元)第一产业增加值(亿元)第二产业增加值(亿元)第三产业增加值(亿元)工业增加值(亿元)建筑业增加值(亿元)2013年49375.11 56957 249684.4 262203.8 210689.4 38995表格2-22013年测试集数据以上数据来自《中国统计年鉴2013》[3]中收录的近15年全国国民生产总值增值数据,考察与各产业间增量趋势变化中关系密切并且直观上有线性关系的因素,因此选取了第一产业增值、第二产业增值、第三产业增值、工业总产值增值、建筑业增值五大因素为自变量。
应用数理统计作业一学号:姓名:电话:二〇一四年十二月国内生产总值的多元线性回归模型摘要:本文首先选取了选取我国自1978至2012年间的国内生产总值为因变量,并选取了7个主要影响因素,进一步利用统计软件SPSS对以上数据进行了多元逐步线性回归。
从而找到了能反映国内生产总值与各因素之间关系的“最优”回归方程.然后利用多重线性的诊断找出存在共线性的自变量,剔除缺失值较多的因子.再次进行主成份线性回归分析,找出最优回归方程。
所得结论与我国当前形势相印证。
关键词:多元线性回归,逐步回归法,多重共线性诊断,主成份分析目录0符号说明 (1)1 介绍 (2)2 统计分析步骤 (3)2。
1 数据的采集和整理 (3)2。
2采用多重逐步回归分析 (7)2.3进行共线性诊断 (17)2。
4进行主成分分析确定所需主成份 (24)2。
5进行主成分逐步回归分析 (27)3 结论 (30)参考文献 (31)致谢 (32)0符号说明1 介绍文中主要应用逐步回归的主成份分析方法,对数据进行分析处理,最终得出能够反映各个因素对国内生产总值影响的最“优”模型及线性回归方程.国内生产总值是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标.它不但可反映一个国家的经济表现,还可以反映一国的国力与财富。
2012年1月,国家统计局公布2011年重要经济数据,其中GDP增长9.2%,基本符合预期。
2012年10月18日,统计显示,2012年前三季度国内生产总值353480亿元,同比增长7.7%;其中,一季度增长8.1%,二季度增长7。
6%,三季度增长7.4%,三季度增幅创下2009年二季度以来14个季度新低。
中国的GDP核算历史不长,上世纪90年代之前通常用“社会总产值”来衡量经济发展情况。
上世纪80年代初中国开始研究联合国国民经济核算体系的国内生产总值(GDP)指标。
数理统计论文财政收入回归模型的建立与分析学院名称航空科学与工程专业名称飞行器设计学生姓名学生学号2012年11月摘要:本文采用多元线性回归的方法,对河北省1995年到2010年的财政收入数据与第一产业、第二产业中的工业、建筑业和第三产业的总产值进行了相关性分析,并在此基础上采用逐步回归法对影响财政收入的以上各因素进行选择与剔除,得到影响财政收入的主要因素为工业和第三产业,并给出两者与财政收入的计算公式。
最后通过对比公式预测与实际公布的2011年河北省财政收入,验证了公式的准确性与精度,因此,本文的结论可以为河北省将来的财政收入预测提供准确简便的计算方法。
关键词:财政收入多元回归逐步回归法引言财政收入,是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而筹集的一切资金的总和。
财政收入表现为政府部门在一定时期内(一般为一个财政年度)所取得的货币收入。
财政收入是衡量政府财力的重要指标,政府在社会经济活动中提供公共物品和服务的范围和数量,在很大程度上决定于财政收入的充裕状况。
河北濒临渤海湾,自古以来一直都是华北一带经济大省。
改革开放以来,河北省经济和社会发展的各个领域发生了历史性的重大变革,影响财政收入的因素也可能很多,为了研究影响河北省财政收入增长的主要原因,分析财政收入的增长规律,预测河北省财政未来的增长趋势,需要建立计量经济模型。
由于计算机技术的发展,统计软件的使用大大简化了回归分析方法的人工劳动,也因为其较高的计算精度而普遍在统计学中使用。
SAS、SPSS、S-PLUS等成为目前使用最广的统计软件,本文使用了SPSS软件作为计算工具,更加精确、简化的对影响财政收入的各因素进行分析。
正文一、变量选取本文研究的是河北省不同年份的财政收入状况,而影响财政收入状况的因素很多,在不同的参考资料中给出不同的解释,大多数相关的研究文献中都把总税收、地区生产总值这两个指标作为影响财政收入的基本因素,还有一些文献中也提出了其他一些变量,比如就业人员数、固定资产投资等。
对中国各地财政收入情况的聚类分析和判别分析应用数理统计第二次大作业学院名称学号学生姓名摘要我国幅员辽阔,由于人才、地理位置、自然资源等条件的不同,各地区的财政收入类型各自呈现出不一样的发展趋势,通过准确定位中国各地区财政收入情况对于正确认识我国财政收入具有重要的意义。
本文以中国各地财政收入情况为研究对象,从《中国统计年鉴》中选取2011年期间中国各地财政收入情况为因变量,选取国内增值税、营业税、企业所得税、个人所得税、城市维护建设税、土地增值税、契税、专项收入、行政事业性收费收入、国有资本经营收入和国有资源(资产)有偿使用收入11个可能影响中国各地财政收入的因素为自变量,利用统计软件SPSS,对27个地区的财政收入进行了聚类分析,并对另外4个地区的财政收入进行了判别分析,并最终确定了中国各地区根据财政收入类型的分类情况。
关键词:聚类分析,判别分析,SPSS,中国各地财政收入类型1、引言财政收入,是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而筹集的一切资金的总和。
财政收入表现为政府部门在一定时期内(一般为一个财政年度)所取得的货币收入。
财政收入是衡量一国政府财力的重要指标,政府在社会经济活动中提供公共物品和服务的范围和数量,在很大程度上决定于财政收入的充裕状况。
通过准确定位中国各地区财政收入情况对于正确认识我国财政收入具有重要的意义。
本文利用统计软件SPSS,根据各地区的财政收入情况,对北京、天津、河北等27个地区进行聚类分析,并对青海、重庆、四川、贵州4个省市进行判别分析,判断属于聚类分析结果中的哪种财政收入类型。
1.1 聚类分析聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称,它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
本文采用的是系统聚类分析,它又称集群分析,是聚类分析中应用最广的一种方法,其基本思想是:首先将每个聚类对象看作一类,然后根据对象间的相似程度,将相似程度最高的两类进行合并,并计算合并后的类与其他类之间的距离,再选择相近者进行合并,每合并一次减少一类,直至所有的对象都并为一类为止。
全国各地区教育发展水平差异研究摘要:改革开放以来,我国地方教育事业获得了长足发展。
与此同时,区域间教育发展不平衡的问题也日益凸显。
针对这一情况,本文对全国各地教育发展水平的差异进行了研究,以学校数量、学生数量、教职工情况、教育质量、经费投入这几个因素为考量,广泛选取了12个代表性指标,利用SPSS 的聚类分析功能对全国各省份进行聚类,将各省份按教育水平的高低分为五类。
在此基础上,采用逐步判别分析法构造典型判别函数,对这些已知样本进行分类。
通过对判别结果进行分析,改变了聚类数目,极大的提高了正确判断的概率。
最终将全国各地区教育发展水平划分为4类,其中教育水平最为先进的省份为北京、上海、天津,最为落后的地区是西藏。
关键字:教育水平,聚类分析,判别分析,SPSS1. 引言教育和人力资本投资不仅是保持地区综合竞争力的根本,同时也是提升地区综合竞争力的关键[1]。
改革开放以来,我国地方教育事业获得了长足发展。
与此同时,区域间教育发展不平衡的问题也日益凸显,由此导致区域间人力积累水平的差距不断扩大,进一步推动了地区社会经济发展的失衡,成为统筹区域经济协调发展的重要障碍[2]。
本文选取影响地区教育水平的若干因素作为样本,采用聚类分析方法以及判别分析方法,并利用统计分析软件SPSS13.0,对我国各地区教育发展的相似性和差异性进行了初步的研究和分析。
2. 理论概述2.1 聚类分析[3]研究怎样对事物进行合理分类(归类)的统计方法成为聚类分析(clustering)。
聚类分析的基本原理是把某种性质相似的对象归于同一类,而不同的类之间则存在较大差异。
系统聚类法(Hierarchical Clustering Method)是最常用的一种聚类方法。
初始时先把要归类的n个对象各自视为一类,然后逐渐把关系最密切的两个类合并成一个新类,直到最后把n个对象都归为一类时停止。
在系统聚类过程中,为了合并“最接近”的两类,需要规定类与类之间的相似性测度,本文采用组间连接法[4](between-groups linkage),合并两类的结果使所有的两两样品之间的平均距离最小。
应用数理统计第一次大作业
学号:
姓名:
班级:B11班
2015年12月
民航客运量的多元线性回归分析
摘要:本文为建立以民航客运量为因变量的多元线性回归模型,选取了1996年至2013年的统计数据,包含国民生产总值,民航航线里程,过夜入境旅游人数,城镇居民可支配收入等因素,利用统计软件SPSS对各因素进行了筛选分析,采用逐步回归法得到最优多元线性回归模型,并对模型的回归显著性、拟合度以及随机误差的正态性进行了检验,并采用2014年的数据进行检验,得到的结果达到预期,证明该模型建立是较为成功的。
关键词:多元线性回归,逐步回归法,民航客运量
0.符号说明
变量符号
国民生产总值X1
铁路客运量X2
民航航线里程X3
入境过夜旅游人数X4
城镇居民人均可支配收入X5
1.引言
随着社会的进步,人民生活水平的提高,如何获得更快捷方便的交通成为人们日益关注的问题。
因为航空的安全性,快速且价格水平越来越倾向大众,越来越多的人们选择航空这种交通方式。
近年来,我国的航空客运量已经进入世界前列,为掌握航空客运的动态,合理安排班机数量。
科学地对我国民航客运量的影响因素的分析,并得出其回归方程,进而能够估计航空客运量是非常有必要的。
本文收集整理了与我国航空客运量相关的历年数据,运用SPSS软件对数据进行分析,研究1996年起至2013年我国民航客运量y(万人)与国民生产总值X1(亿元)、铁路客运量X2(万人)、民航航线里程X3(万公里)、入境过夜旅游人数X4(万人)、城镇居民人均可支配收入X5(元)的关系。
采用逐步回归法建立线性模型,选出较优的线性回归模型。
2.数据的统计与分析
本文在进行统计时,查阅《中国统计摘要》,《中国统计年鉴2014》以及中国知网数据查询中的数据,收集了1996年至2013年各个自变量因素的数据,分析它们之间的联系。
整理如表1所示。
表1:
201026769397983.5168145276.54753.8419109.4 201129316473104146192349.054924.3221809.8 201231896519470.1189337328.015668.6324564.7 201335397568845.2210597410.65562.3926955.1
2.1模型的建立
以民航客运量y为因变量,以上5种影响因素为自变量X i,构建回归方程:
其中为常数项,为误差项。
先观察自变量与因变量的关系,用SPSS得到各个自变量与因变量的散点图:
图1 民航客运量与国内生产总值散点图
图2 民航客运量与铁路客运量散点图
图3 民航客运量与航线里程散点图
图4 民航客运量与入境过夜人数散点图
图5 民航客运量与人均可支配收入散点图
从以上五张散点图,我们可以看出因变量民航客运量与国内生产总值,入境
过夜旅游人数和城镇居民人均可支配收入均有较好的线性关系
,这说明建立线性模型是有意义的。
继续下一步逐步回归分析,逐步回归的基本思想是将变量逐个引入模型,每引入一个变量后都要进行F检验,并对已经选入的变量逐个进行t检验,当原来引入的变量由于后面变量的引入变得不再显著时,则将其删除。
以确保每次引入新的变量之前回归方程中只包含先主动变量。
这是一个反复的过程,直到既没有显著的变量选入回归方程,也没用不显著的变量从回归方程中剔除为止。
在SPSS 软件中可直接进行逐步回归分析,得出以下结果:
由表2知,逐步回归后得出两个模型,模型1只包含城镇居民可支配收入,其他自变量都没有进入模型,模型2在1的基础上再纳入了过夜入境旅游人数,其他的自变量也都被排除了。
表2
输入/移去的变量a
模型输入的变量移去的变量方法
1 城镇居民人均可支配
收入
. 步进(准则:
F-to-enter 的概率
<= .050,F-to-remove
的概率 >= .100)。
2 过夜游客. 步进(准则:
F-to-enter 的概率
<= .050,F-to-remove
的概率 >= .100)。
a. 因变量: 民用航空客运量表3
2.2拟合度检验
由表4,模型1的决定系数R2=0.992,模型2的决定系数R2=0.995,可以看出回归方程都高度显著,且模型2比模型1更优。
2.3回归方程的显著性检验:
由表5,方差分析表Sig值都<0.05,说明每个模型都拒绝回归系数均为0的假设,每个方程都是显著的。
表5
Anova a
模型平方和df均方F Sig.
1回归1678659397.18411678659397.1842183.841.000b 残差12298767.26116768672.954
总计1690958164.44417
2回归1684069181.3702842034590.6851833.437.000c 残差6888983.0751*******.538
总计1690958164.44417
a. 因变量: 民用航空客运量
b. 预测变量: (常量), 城镇居民人均可支配收入。
c. 预测变量: (常量), 城镇居民人均可支配收入, 过夜游客。
由表6可以得到两个模型的回归方程分别:
1.以城镇居民可支配收入为自变量的拟合函数:
y=-1698.669+1.406X5
2. 以城镇居民可支配收入和过夜入境旅游人数为自变量的拟合函数:
y=-3267.728+0.817X5+2.871X4
且所有系数的显著性水平都小于0.05,每个回归方程都是有意义的。
表6
系数a
模型非标准化系数标准系数t Sig.
B标准误差试用版
1
(常量)-1698.669423.955-4.007.001城镇居民人均可支配收入 1.406.030.99646.732.000
2(常量)-3267.728562.492-5.809.000城镇居民人均可支配收入.817.173.579 4.721.000过夜游客 2.871.837.421 3.432.004
a. 因变量: 民用航空客运量
表7是残差统计结果。
主要显示预测值、标准化预测值、残差和标准化残差等统计量的最大值、最小值、均值和标准差。
残差平方和Q描述的是随机误差
引起因变量Y的分散程度,Q越大分散性也越大,则线性关系越不明显。
由表7
可见标准化残差的最大绝对值为1.758。
而且标准残差的均值为0,说明随机误差对Y值的影响很小。
表7
残差统计量a
极小值极大值均值标准偏差N
预测值4581.80435339.83615600.4449953.034418
残差-1191.5225973.1963.0000636.580218
标准预测值-1.107 1.983.000 1.00018
标准残差-1.758 1.436.000.93918
a. 因变量: 民用航空客运量
2.4多重共线性的诊断
表8是SPSS软件的多重共线性诊断表,它包括3项诊断值:特征值、条件数和方差比率。
特征值表明在自变量中存在多少截然不同的维数,当几个特征值都接近0是,变量是高度相关的。
条件数是最大特征值对每一个连续特征值的比率的平方根,若条件数大于15则表明可能存在多重共线问题,若大于30则表明存在严重的多重共线性问题。
显然表8中变量X4过夜入境旅游人数的条件数大于30,说明回归方程存在多重共线性。
2.5残差检验
如图6是残差分布直方图。
在回归分析中,总是假定残差服从正态分布,这个图就是根据样本数据的计算结果显示残差分析的实际情况。
从图来看标准化残差还是近似服从正态分布的。
图6
如图7残差的积累概率图基本围绕在假设直线(正态分布)周围,说明残差分布基本符合正态分布,说明民航客运量这个因变量基本上可以用线性回归方法建立模型。
3.结论
为了解决多重共线性的问题,排除模型2,考虑到模型1的拟合度也是很好的,综合来看认为模型1为更优。
最终得到的回归方程为:
y=-1698.669+1.406X5
并以2014年的数据检验该回归方程,2014年航空客运量为39195万人,城镇居民人均可支配收入为28843.9,将自变量X5带入回归方程得到y=38855.85万人,与实际的客运量39195万人的误差为0.86%。
因此可以认为该模型基本达到了预期的目标。
通过最优回归方程,我们可以发现航空客运量与城镇居民的可支配收入线性相关十分显著,这是符合常识的,只有居民可支配收入越来越高,才会选择航空这种昂贵的客运方式。
图7
参考文献:
[1] 2015年中国统计年鉴
[2] 孙海燕、周梦、李卫国、冯伟. 应用数理统计.北京航空航天大学出版社,
2009
[3] 朱卫卫. 基于偏最小二乘回归的我国民航客运量影响因素分析[J]. 中国
市场. 2010(41): 110-112
如有侵权请联系告知删除,感谢你们的配合!。