北航数理统计聚类分析大作业
- 格式:doc
- 大小:328.50 KB
- 文档页数:10

应用数理统计第一次大作业学号:姓名:班级:2013年12月国家财政收入的多元线性回归模型摘 要本文以多元线性回归为出发点,选取我国自1990至2008年连续19年的财政收入为因变量,初步选取了7个影响因素,并利用统计软件PASW Statistics 17.0对各影响因素进行了筛选,最终确定了能反映财政收入与各因素之间关系的“最优”回归方程:46ˆ578.4790.1990.733yx x =++ 从而得出了结论,最后我们用2009年的数据进行了验证,得出的结果在误差范围内,表明这个模型可以正确反映影响财政收入的各因素的情况。
关键词:多元线性回归,逐步回归法,财政收入,SPSS0符号说明变 量 符号 财政收入 Y 工 业 X 1 农 业 X 2 受灾面积 X 3 建 筑 业 X 4 人 口 X 5 商品销售额X 6进出口总额X71 引言中国作为世界第一大发展中国家,要实现中华民族的伟大复兴,必须把发展放在第一位。
近年来,随着国家经济水平的飞速进步,人民生活水平日益提高,综合国力日渐强大。
经济上的飞速发展并带动了国家财政收入的飞速增加,国家财政的状况对整个社会的发展影响巨大。
政府有了强有力的财政保证才能够对全局进行把握和调控,对于整个国家和社会的健康快速发展有着重要的意义。
所以对国家财政的收入状况进行研究是十分必要的。
国家财政收入的增长,宏观上必然与整个国家的经济有着必然的关系,但是具体到各个方面的影响因素又有着十分复杂的相关原因。
为了研究影响国家财政收入的因素,我们就很有必要对其财政收入和影响财政收入的因素作必要的认识,如果能对他们之间的关系作一下回归,并利用我们所知道的数据建立起回归模型这对我们很有作用。
而影响财政收入的因素有很多,如人口状况、引进的外资总额,第一产业的发展情况,第二产业的发展情况,第三产业的发展情况等等。
本文从国家统计信息网上选取了1990-2009年这20年间的年度财政收入及主要影响因素的数据,包括工业,农业,建筑业,批发和零售贸易餐饮业,人口总数等。

数理统计第一次课程论文广州恒大队在2015赛季亚冠的进球数的多元线性回归模型学号: SY1527205姓名:郭谢有摘要本赛季亚洲冠军联赛,来自中国的球队广州恒大淘宝队最终在决赛中力克阿联酋的迪拜阿赫利队,三年之内第二次夺得亚冠冠军。
为了研究恒大的夺冠过程,本文选取了恒大该赛季亚冠总共15场比赛中的进球数为因变量,对可能影响进球数的射门数、射正数等7个自变量进行统计,并进一步利用统计软件SPSS对以上数据进行了多元逐步线性回归。
最终确定了进球数与各因素之间关系的“最优”回归方程。
关键词:多元线性回归,逐步回归法,广州恒大,SPSS目录摘要 (1)1.引言 (3)2.符号说明 (3)3.数据的采集和整理 (3)3.1数据的采集 (3)3.2建模 (4)4.数据分析及计算 (4)4.结论 (9)参考文献 (10)致谢 (10)1.引言一场足球比赛的进球数说明了一支球队攻击力的强弱,也是决定比赛胜负的至关因素,综合反映出这支球队的实际水平。
而作为竞技体育,足球场上影响进球数的因素很多,为了研究本赛季恒大在亚冠夺冠过程中的14场比赛中进球数与其他一些因素的关系,本论文从搜达足球和新浪体育数据库中查找了进球数和其他7个主要影响因素的数据,包括射门次数、射正次数、传球次数、传中次数、角球次数、抢断次数。
并进一步采用多元逐步回归分析方法对以上因素进行了显著性分析,从而确定了关于恒大在本赛季亚冠中进球数的最优多元线型回归方程。
2.符号说明3.数据的采集和整理3.1数据的采集本文统计数据时,查阅了搜达足球数据库,确定恒大在亚冠14场比赛中的进球数为因变量,并初步选取这14场比赛中的射门次数、射正次数、传球次数、传中次数、角球次数、抢断次数7因素为自变量,具体数据见下表1。
3.2建模本文选取了恒大在亚冠比赛中的进球数作为因变量y,并选取可能对进球数造成影响的因素为自变量,其中对应关系在符号说明中已经列举。
这里构建模型如下:7⋅X i+εy=β0+∑βii=1其中,其中ε为随机误差项,β0为常数项,βi为待估计的参数。

应用数理统计作业二学号:姓名:电话:二〇一四年十二月对NBA球队的聚类分析和判别分析摘要:NBA联盟作为篮球的最高殿堂深受广大球迷的喜爱,联盟的30支球队大家也耳熟能详,本文选取NBA联盟30支球队2013-2014常规赛赛季场均数据。
利用spss软件通过聚类分析对27个地区进行实力类型分类,并利用判断分析对其余3支球队对分类结果进行验证。
可以看出各球队实力类型与赛季实际结果相吻合。
关键词:聚类分析,判别分析,NBA目录1. 引言 (4)2、相关统计基础理论 (5)2.1、聚类分析 (5)2.2,判别分析 (6)3.聚类分析 (7)3.1数据文件 (7)3.2聚类分析过程 (9)3.3 聚类结果分析 (11)4、判别分析 (12)4.1 判别分析过程 (12)4.2判别检验 (17)5、结论 (20)参考文献 (21)致谢 (22)1. 引言1896年,美国第一个篮球组织"全国篮球联盟(简称NBL)"成立,但当时篮球规则还不完善,组织机构也不健全,经过几个赛季后,该组织就名存实亡了。
1946年4月6日,由美国波士顿花园老板沃尔特.阿.布朗发起成立了“美国篮球协会”(简称BAA)。
1949年在布朗的努力下,美国两大篮球组织BAA和NBL合并为“全国篮球协会”(简称NBA)。
NBA季前赛是 NBA各支队伍的热身赛,因为在每个赛季结束后,每支球队在阵容上都有相当大的变化,为了让各队磨合阵容,熟悉各自球队的打法,确定各队新赛季的比赛阵容、同时也能增进队员、教练员之间的沟通,所以在每个赛季开始之前,NBA就举办若干场季前赛,使他们能以比较好的状态投入到漫长的常规赛的比赛当中。
为了扩大NBA在全球的影响,季前赛有约三分之一的球队在美国以外的国家举办。
从总体上看,NBA的赛程安排分为常规赛、季后赛和总决赛。
常规赛采用主客场制,季后赛和总决赛采用七场四胜制的淘汰制。
[31]NBA常规赛从每年的11月的第一个星期二开罗,到次年的4月20日左右结束。
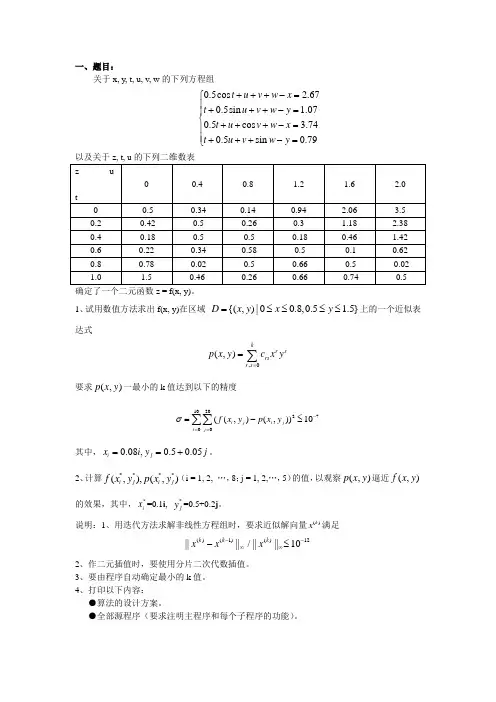
一、题目:关于x, y, t, u, v, w 的下列方程组0.5cos 2.670.5sin 1.070.5cos 3.740.5sin 0.79t u v w x t u v w y t u v w x t u v w y +++-=⎧⎪+++-=⎪⎨+++-=⎪⎪+++-=⎩1、试用数值方法求出f(x, y)在区域 {(,)|00.8,0.5 1.5}D x y x y =≤≤≤≤上的一个近似表达式,0(,)kr s rsr s p x y cx y ==∑要求(,)p x y 一最小的k 值达到以下的精度10202700((,)(,))10i j i j i j f x y p x y σ-===-≤∑∑其中,0.08,0.50.05i j x i y j ==+。
2、计算****(,),(,)i j i j f x y p x y (i = 1, 2, …,8;j = 1, 2,…,5)的值,以观察(,)p x y 逼近(,)f x y 的效果,其中,*i x =0.1i , *j y =0.5+0.2j 。
说明:1、用迭代方法求解非线性方程组时,要求近似解向量()k x 满足()(1)()12||||/||||10k k k x x x --∞∞-≤2、作二元插值时,要使用分片二次代数插值。
3、要由程序自动确定最小的k 值。
4、打印以下内容:●算法的设计方案。
●全部源程序(要求注明主程序和每个子程序的功能)。
●数表:,,i j x y (,)i j f x y (i = 0,1,2,…,10;j = 0,1,2,…,20)。
●选择过程的,k σ值。
●达到精度要求时的,k σ值以及(,)p x y 中的系数rs c (r = 0,1,…,k;s = 0,1,…,k )。
●数表:**,,i j x y ****(,),(,)i j i j f x y p x y (i = 1, 2, ...,8;j = 1, 2, (5)。

北京市财政收入的逐步回归模型研究摘要:财政收入水平高低是反映一国经济实力的重要标志,关系着一个国家经济的发展和社会的进步。
本文根据北京市2012年度统计年鉴,选取了农林牧渔业总产值、工业总产值、建筑业总产值、常驻总人口数、社会消费品零售总额、入境旅游人数、客运量、货运量、全社会固定资产投资以及第三产业总产值,共10个指标,对北京市财政收入及其可能的影响因素进行了研究。
文中运用逐步线性回归方法建立了多元线性回归模型,分析各因素对该地区财政收入的影响;利用SPSS软件进行求解。
通过分析SPSS软件计算的数据,从相关性检验、多重共线性检验、方差分析以及残差分析四个角度,分别对模型合理性进行了验证。
结果表明,北京市财政收入与建筑业总产值和农林牧渔也总产值呈显著线性关系。
其中与建筑业正相关,与农林牧渔业负相关。
关键字:财政收入,多元,逐步线性回归,SPSS1. 引言财政收入是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而集中的一切资金的综合,包括税收、企事业收入、能源交通重点建设基金收入、债务收入、规费收入、罚没收入等[1]。
财政收入水平高低是反映一国经济实力的重要标志,关系着一个国家经济的发展和社会的进步。
因此,研究财政收入的增长及就显得尤为必要[2]。
一个地区的财政收入可能受到诸多因素的影响,如工业总产值、农业总产值、建筑业总产值、人口数等。
本文以北京市为例,以财政收入为因变量,选取农林牧渔业总产值、工业总产值、建筑业总产值、常驻总人口数、社会消费品零售总额、入境旅游人数、客运量、货运量、全社会固定资产投资以及第三产业总产值这10个指标为自变量,利用SPSS统计软件进行回归分析,建立财政收入影响因素模型,分析影响财政收入的主要因素及其影响程度。
2. 理论概述2.1 多元线性回归[3]在许多实际问题中,影响一个事物的因素常常不止一个,采用多元线性回归分析方法可以找出这些因素与事物之间的数量关系。

应用数理统计聚类分析与判别分析(第二次作业)学院:姓名:学号:2015年12月目录我国部分城市经济发展水平的聚类分析和判别分析................................. - 1 - 摘要:................................................................... - 1 -1. 引言 ................................................................ - 1 -2. 相关统计基础理论 .................................................... - 1 -2.1 聚类分析......................................................... - 1 -2.2 判别分析......................................................... - 2 -3. 模型建立 ............................................................ - 3 -3.1 设置变量......................................................... - 3 -3.2 数据收集和整理................................................... - 3 -4. 数据结果及分析 ...................................................... - 5 -4.1 聚类分析......................................................... - 5 -4.2 判别分析......................................................... - 7 -5. 结论 ............................................................... - 11 -参考文献................................................................ - 12 -我国部分城市经济发展水平的聚类分析和判别分析摘要:本文基于《中国统计年鉴》(2014年版)统计数据,统计全国各省市居民消费情况,包括各地区农村居民人均纯收入、农村居民人均现金消费、城镇居民人均可支配收入、城镇居民人均现金消费情况共4个指标,利用统计软件SPSS综合考虑各指标,对所选地区进行K-Means 聚类分析,利用Fisher 线性判别待判地区类型,进一步验证所建模型的有效性。

北航数值分析全部三次大作业第一次大作业是关于解线性方程组的数值方法。
我们被要求实现各种常用的线性方程组求解算法,例如高斯消元法、LU分解法和迭代法等。
我首先学习了这些算法的原理和实现方法,并借助Python编程语言编写了这些算法的代码。
在实验中,我们使用了不同规模和条件的线性方程组进行测试,并比较了不同算法的性能和精度。
通过这个作业,我深入了解了线性方程组求解的原理和方法,提高了我的编程和数值计算能力。
第二次大作业是关于数值积分的方法。
数值积分是数值分析中的重要内容,它可以用于计算曲线的长度、函数的面积以及求解微分方程等问题。
在这个作业中,我们需要实现不同的数值积分算法,例如矩形法、梯形法和辛普森法等。
我学习了这些算法的原理和实现方法,并使用Python编写了它们的代码。
在实验中,我们计算了不同函数的积分值,并对比了不同算法的精度和效率。
通过这个作业,我深入了解了数值积分的原理和方法,提高了我的编程和数学建模能力。
第三次大作业是关于常微分方程的数值解法。
常微分方程是数值分析中的核心内容之一,它可以用于描述众多物理、化学和生物现象。
在这个作业中,我们需要实现不同的常微分方程求解算法,例如欧拉法、龙格-库塔法和Adams法等。
我学习了这些算法的原理和实现方法,并使用Python编写了它们的代码。
在实验中,我们解决了一些具体的常微分方程问题,并比较了不同算法的精度和效率。
通过这个作业,我深入了解了常微分方程的原理和方法,提高了我的编程和问题求解能力。
总的来说,北航数值分析课程的三次大作业非常有挑战性,但也非常有意义。
通过这些作业,我在数值计算和编程方面得到了很大的提升,也更加深入地了解了数值分析的理论和方法。
虽然这些作业需要大量的时间和精力,但我相信这些努力将会对我未来的学习和工作产生积极的影响。
聚类分析
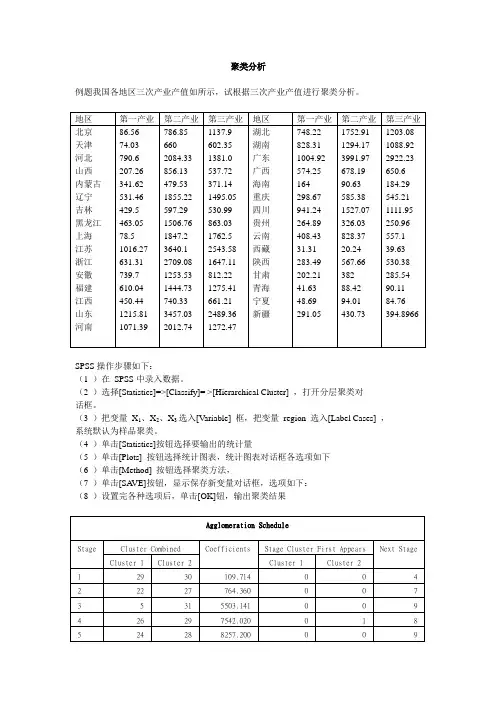
例题我国各地区三次产业产值如所示,试根据三次产业产值进行聚类分析。
SPSS操作步骤如下:
(1 )在SPSS中录入数据。
(2 )选择[Statistics]=>[Classify]= >[Hierarchical Cluster] ,打开分层聚类对
话框。
(3 )把变量X1、X2、X3选入[V ariable] 框,把变量region 选入[Label Cases] ,系统默认为样品聚类。
(4 )单击[Statistics]按钮选择要输出的统计量
(5 )单击[Plots] 按钮选择统计图表,统计图表对话框各选项如下
(6 )单击[Method] 按钮选择聚类方法,
(7 )单击[SA VE]按钮,显示保存新变量对话框,选项如下:
(8 )设置完各种选项后,单击[OK]钮,输出聚类结果
平均距离法
中位数法
最远距离法
质心法
1北京2天津3河北4山西5内蒙6辽宁7吉林8黑龙9上海10江苏11浙江12安徽
13福建14江西15山东16河南17湖北18湖南19广东20广西21海南22重庆23四川24贵州25云南26西藏27陕西28甘肃29青海30宁夏31新疆
由图可知,各大城市三大产业产值大致可以分为三类,
1.广东、山东、江苏;
2.浙江,上海,辽宁、河南、河北,湖北、福建、四川、湖南安徽、黑龙江。
3.北京,云南、广西、江西、吉林、陕西、重庆、山西、天津、甘肃、贵州、新疆、内蒙,
海南、西藏、宁夏、青海。

数理统计大作业(2)全国各省、市及自治区产业类型聚类分析和判别分析院(系)名称航空科学与工程学院专业名称飞行器设计与工程学生姓名熊蕾学号ZY15054022015年12月全国各省、市及自治区产业类型聚类分析和判别分析ZY1505402 熊蕾摘要本文从中国统计年鉴(2014)中获得了2013年按三次产业分地区生产总值的数据,按各省的第一产业、第二产业和第三产业产值所占地区生产总值的比值不同,对全国23个省、4个直辖市和5个少数民族自治区进行聚类分析和判别分析。
关键词经济类型聚类分析判别分析一、引言产业是指具有某种同类属性的经济活动的集合或系统,是经济社会的物质生产部门。
世界各国把各种产业划分为三大类:第一产业、第二产业和第三产业。
第一产业是指提供生产资料的产业,包括种植业、林业、畜牧业、水产养殖业等直接以自然物为对象的生产部门。
第二产业是指加工产业,利用基本的生产资料进行加工并出售,包括采矿业、制造业、电力、燃气和水的生产和供应业和建筑业。
第三产业又称服务业,它是指第一、第二产业以外的其他行业。
第三产业行业广泛。
包括交通运输业、通讯业、商业、餐饮业、金融保险业、行政、家庭服务等非物质生产部门。
我国区域经济发展不平衡,各地区的产业类型和产业结构不尽相同,因此可以以各省的第一产业、第二产业和第三产业产值所占地区生产总值的比值对全国的23个省、4个直辖市和5个少数民族自治区进行分类。
二、聚类分析2.1数据输入从中国统计年鉴中得到了2013年按三次产业分地区生产总值的数据,如下表所示,产值单位均为亿元,由于各省经济发展程度不同,地区生产总值有较大的差别,因此要算出各地区三大产业所占的比值来进行聚类和判别分析。
表 1 原始数据2.2聚类分析从表1中选出湖南、安徽和西藏三个地区的数据以待判别,对其余地区的数据进行聚类分析。
表 2 聚类分析数据将表2数据导入SPSS,进行系统聚类分析,得到以下结果:表 3 聚类表阶群集组合系数首次出现阶群集下一阶群集 1 群集 2 群集 1 群集 21 7 13 .052 0 0 92 6 12 .109 0 0 133 14 20 .174 0 0 54 3 21 .244 0 0 95 14 27 .336 3 0 166 5 24 .465 0 0 127 8 23 .602 0 0 198 11 17 .742 0 0 109 3 7 .952 4 1 1510 10 11 1.163 0 8 1711 18 28 1.381 0 0 1812 5 26 1.641 6 0 2013 4 6 1.977 0 2 1614 16 25 2.315 0 0 1815 3 15 2.673 9 0 2016 4 14 3.149 13 5 2317 2 10 3.678 0 10 2318 16 18 4.238 14 11 2119 8 22 4.814 7 0 2120 3 5 5.523 15 12 2521 8 16 6.429 19 18 2422 1 9 7.640 0 0 2623 2 4 9.318 17 16 2524 8 19 11.431 21 0 2625 2 3 14.946 23 20 2726 1 8 20.495 22 24 2727 1 2 26.551 26 25 0表4 群集成员案例8 群集7 群集 6 群集 5 群集 4 群集 3 群集1:北京 1 1 1 1 1 1 2:天津 2 2 2 2 2 2 3:河北 3 3 3 3 3 2 4:山西 4 4 4 2 2 2 5:内蒙古 3 3 3 3 3 2 6:辽宁 4 4 4 2 2 2 7:吉林 3 3 3 3 3 2 8:黑龙江 5 5 5 4 4 3 9:上海 6 6 1 1 1 1 10:江苏 2 2 2 2 2 2 11:浙江 2 2 2 2 2 2 12:福建 4 4 4 2 2 2 13:江西 3 3 3 3 3 2 14:山东 4 4 4 2 2 2 15:河南 3 3 3 3 3 2 16:湖北7 5 5 4 4 3 17:广东 2 2 2 2 2 2 18:广西7 5 5 4 4 3 19:海南8 7 6 5 4 3 20:重庆 4 4 4 2 2 2 21:四川 3 3 3 3 3 2 22:贵州 5 5 5 4 4 3 23:云南 5 5 5 4 4 3 24:陕西 3 3 3 3 3 2 25:甘肃7 5 5 4 4 3 26:青海 3 3 3 3 3 2 27:宁夏 4 4 4 2 2 2 28:新疆7 5 5 4 4 3图1聚类分析树状图从树状图中,我们定下聚类分析最终得到四个组别:1为北京和上海,可以看出这两个直辖市的总产值中,第三产业也就是服务业占有绝对优势,因此可将第一组作为第三产业为主的地区;2为天津、山西、江苏、广东等10个省份,这些省份的第二产业占有较多的比重,而第一产业仅占极少的比重,说明第2组以第二、三产业为主;第三组包括河北、河南、吉林、江西等省份,这些省份虽然也是第二产业占有的比重最大,但它们的第一产业的比重与第1、2组相比更多;第四组的各个地区是传统的鱼米之乡,可以看到它们的第一产业的比重大于其他各组。


数理统计大作业(二)全国各省发展程度的聚类分析及判别分析指导教师院系名称材料科学与工程院学号学生姓名2015 年 12 月21 日目录全国各省发展程度的聚类分析及判别分析 (1)摘要: (1)引言 (1)1实验方案 (2)1.1数据统计 (2)1.2聚类分析 (3)1.3判别分析 (4)2结果分析与讨论 (5)2.1聚类分析结果 (5)2.2聚类分析结果分析: (8)2.3判别分析结果 (9)2.4 Fisher判别结果分析: (11)参考文献: (16)全国各省发展程度的聚类分析及判别分析摘要:利用SPSS软件对全国31个省、直辖市、自治区(浙江、安徽、甘肃除外)的主要经济指标进行多种聚类分析,分析选择最佳聚类类数,并对浙江、湖南、甘肃进行类型判别分析。
通过这两个方法对全国各省进行发展分类。
本文选取了7项社会发展指标作为决定发展程度的影响因素,其中经济因素为主要因素,同时评估城镇化率和人口素质因素。
各项数据均来自2014年国家统计年鉴。
分析结果表明:北京市和上海市和天津市为同一类;江苏省和山东省和广东省为同一类型;河北、湖北、河南、湖南、四川、辽宁为同一类;其余的为另一类。
关键词:聚类分析、判别分析、发展引言聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称。
它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
系统聚类分析又称集群分析,是聚类分析中应用最广的一种方法,它根据样本的多指标(变量)、多个观察数据,定量地确定样品、指标之间存在的相似性或亲疏关系,并据此连结这些样品或指标,归成大小类群,构成分类树状图或冰柱图。
判别分析是根据多种因素(指标)对事物的影响来实现对事物的分类,从而对事物进行判别分类的统计方法。
判别分析适用于已经掌握了历史上分类的每一个类别的若干样品,希望根据这些历史的经验(样品),总结出分类的规律性(判别函数)来指导未来的分类。
《数值分析》计算实习题第一题姓名:学号:一、 算法的设计方案 ⒈矩阵A 的存储由于A[501][501]是带状矩阵,并且阶数远大于带宽5,为节省内存空间,设置一个二维数组C[5][501]用于存放A 的带内元素。
A 中元素与C 数组中元素的对应关系,即A 的检索方式为: A 的元素ij a =C 中的元素1,i j s j C -++ 2.求解特征值λ1,λ501,λs①由于λ1‹λ2‹…‹λ501,所以在以所有特征值建立的数轴上,λ1、λ50⒊1位于数轴的两端,两者之一必为按模最大。
利用幂法,可以求出来按模最大的特征值λM ,即为λ1和λ501中一个;然后将原矩阵平移λM,再利用幂法求一次平移后矩阵的按模最大的特征值λM ′。
比较λM 和λM+λM ′大小,大者为λ501,小的为λ1。
②利用反幂法,求矩阵A 的按模最小的特征值λs 。
但是反幂法中要用到线性方程组的求解,而原矩阵A 又是带状矩阵,采用LU 分解。
所以在这之前要定义一个LU 分解子程序,将A 矩阵分解为单位下三角矩阵L 和上三角矩阵U 的乘积。
⒊求解A 的与数μk =λ1+k (λ501-λ1)/40的最接近的特征值λik(k=1,2,…,39)。
先使k 从1到39循环,求出μk 的值,然后使用带原点平移的反幂法,令平移量p=μk 。
计算过程需调用LU 分解子程序对A-u k I 矩阵进行LU 分解。
最终反幂法求出的值加上μk 即为与μk 最接近的特征值λik4.求解A的(谱范数)条件数cond(A)2和行列式detAcond(A)2=|λ1/λn|,其中λ1和λn分别是矩阵A的模最大和最小特征值,上边已经求出,可直接调用。
detA等于对A记性LU分解以后U的所有对角线上元素的乘积。
二、全部源程序#include<stdio.h>#include <math.h>/***全局变量、函数申明***/#define N 501#define EMS 1.0e-12double U[N],Y[N];double c[5][N] ;double fuzhi(); /*对A进行压缩存储*/ void DLU(double C[5][N]); /*对矩阵A进行LU分解*/ double pingyi(double C[5][N],double b); /*求矩阵的平移矩阵*/ double mifa(double c[5][N]); /*幂法计算矩阵A按模最大的特征值*/ double fmifa(double c[5][N],double b); /*反幂法求矩阵A按模最小的特征值*/void main(){double lamuda_m1,lamuda_m2,lamuda_max,lamuda_min,lamuda_sum,lamuda_s;fuzhi();lamuda_m1=mifa(c);pingyi(c, lamuda_m1);lamuda_m2 =mifa(c);lamuda_sum= lamuda_m1+ lamuda_m2;if (lamuda_m1>lamuda_sum){lamuda_max=lamuda_m1;lamuda_min=lamuda_sum;}else{lamuda_max=lamuda_sum;lamuda_min=lamuda_m1;}printf("矩阵的最大特征值为:\n lamuda_501=%.11e\n",lamuda_max); printf("矩阵的最小特征值为:\n lamuda_1=%.11e\n",lamuda_min); int i;double conda,u[39];for(i=1;i<40;i++)u[i]=lamuda_min+(lamuda_max-lamuda_min)*i/40;lamuda_s=fmifa(c,0);printf("矩阵的按模最小特征值为:\n lamuda_s=%.11e\n", lamuda_s); printf("与uk最接近的特征值如下:\n");/*求与uk接近的特征值*/for(i=1;i<40;i++)printf("u[%2d]=%.11e 与其最接近的特征值为lamuda_%2d=%.11e\n",i,u[i],i,fmifa(c,u[i]));/*求矩阵A的条件数*/conda=fabs(lamuda_m1/lamuda_s);printf("矩阵A的(谱范数)条件数为:\n cond(A)=%.11e\n", conda); /*求矩阵A的行列式*/fuzhi();double detA=1.0;DLU(c);for(i=0;i<N;i++)detA*=c[2][i];printf("矩阵A的行列式为:\n detA=%.11e\n", detA);}/*建立矩阵A的压缩存储二维数组,并对其赋值*/double fuzhi(){int i;c[0][0]=0;c[0][1]=0;c[1][0]=0;c[3][500]=0;c[4][499]=0;c[4][500]=0;for(i=2;i<N;i++)c[0][i]=-0.064;for(i=1;i<N;i++)c[1][i]=0.16;for(i=1;i<N+1;i++)c[2][i-1]=(1.64-0.024*i)*sin(0.2*i)-0.64*exp(0.1/i); for(i=0;i<N-1;i++)c[3][i]=0.16;for(i=0;i<N-2;i++)c[4][i]=-0.064;return (c[5][N]);}/*求最大值*/int max(int a,int b){if(a>b) return a;else return b;}/*求最小值*/int min(int a,int b){if(a<b) return a;else return b;}/*向量乘以向量*/double xiangliangji(double G[N],double H[N]) {int i;double sum;sum=0;for(i=0;i<N;i++)sum+=G[i]*H[i];return sum;}/*向量除数*/void xlcs (double G[N],double yita){int i;for(i=0;i<N;i++)Y[i]=G[i]/yita;}/*矩阵乘向量*/void juchengxiang(double c[N][N],double G[N])int i,j;double m;for(i=0;i<N;i++)U[i]=0;for(i=0;i<N;i++){m=max(0,i-2);for(j=min(i+2,N-1);j>=m;j--)U[i]+=c[i+2-j][j]*G[j];}}/*矩阵的主对角线元素平移*/ double pingyi(double C[5][N],double b) {int i;for(i=0;i<N;i++)C[2][i]=C[2][i]-b;return C[5][N];}/*幂法求按模最大特征值*/double mifa(double c[5][N])int i,q;double sum,yita,beita,beita1,cancha; beita=0;for(i=0;i<N;i++)U[i]=1;for (q=1;;q++){beita1=beita;sum= xiangliangji(U,U);yita=sqrt(sum);xlcs (U,yita);juchengxiang (c,Y);beita=xiangliangji(Y,U);cancha=fabs((beita1-beita)/beita); if (cancha<EMS) break;}return beita;}/*矩阵的Doolittle分解*/void DLU(double C[5][N]){ int k,i,j,t;int m,l;for(k=0;k<N;k++){m=min(k+2,N-1);for(j=k;j<=m;j++){double sum=0;l=max(max(0,k-2),j-2);for(t=l;t<=k-1;t++)sum+=C[k-t+2][t]*C[t-j+2][j];C[k-j+2][j]=C[k-j+2][j]-sum;}if(k<N-1){m=min(k+2,N-1);for(i=k+1;i<=m;i++){double sum=0;l=max(max(0,i-2),k-2);for(t=l;t<=k-1;t++)sum+=C[i-t+2][t]*C[t-k+2][k];C[i-k+2][k]=(C[i-k+2][k]-sum)/C[2][k];}}}}/*反幂法求按模最小特征值*/double fmifa(double c[5][N],double b){int i,q;int m,t,p;double sum,yita,beita,beita1,cancha,lamuda;double G[N];beita=0;for(i=0;i<N;i++) /*设置初始向量U0*/{U[i]=1;}for (q=1;;q++){beita1=beita;sum=xiangliangji (U,U);yita=sqrt(sum);xlcs (U,yita);fuzhi();pingyi(c,b);DLU(c);for(i=0;i<N;i++)G[i]=Y[i];for(i=1;i<N;i++){double sum=0;m=max(0,i-2);for(t=m;t<=i-1;t++)sum+=c[i-t+2][t]*G[t];G[i]=G[i]-sum;}U[N-1]=G[N-1]/c[2][N-1]; for(i=N-2;i>=0;i--){double sum=0;p=min(i+2,N-1);for(t=i+1;t<=p;t++)sum+=c[i-t+2][t]*U[t];U[i]=(G[i]-sum)/c[2][i]; }beita=xiangliangji(Y,U);lamuda=1/beita+b;cancha=fabs((beita1-beita)/beita);if (cancha<1.0e-12) break;}printf("迭代次数%d\n",q);return lamuda;}三、计算结果矩阵的最大特征值为:lamuda_501=9.72463409878e+000矩阵的最小特征值为:lamuda_1=-1.07001136150e+001迭代次数70, 矩阵的按模最小特征值为:lamuda_s=-5.55791079423e-003与uk最接近的特征值如下:迭代次数7, u[ 1]=-1.01894949222e+001lamuda_1=-1.01829340331e+001 迭代次数226, u[ 2]=-9.67887622933e+000lamuda_ 2=-9.58570742507e+000迭代次数7, u[ 3]=-9.16825753648e+000lamuda_ 3=-9.17267242393e+000迭代次数8, u[ 4]=-8.65763884364e+000lamuda_ 4=-8.65228400790e+000迭代次数118, u[ 5]=-8.14702015079e+000lamuda_ 5=-8.0934*******e+000迭代次数16, u[ 6]=-7.63640145795e+000lamuda_ 6=-7.65940540769e+000迭代次数15, u[ 7]=-7.12578276510e+000lamuda_ 7=-7.11968464869e+000迭代次数19, u[ 8]=-6.61516407226e+000lamuda_ 8=-6.61176433940e+000迭代次数28, u[ 9]=-6.10454537941e+000lamuda_ 9=-6.0661*******e+000迭代次数21, u[10]=-5.59392668657e+000lamuda_10=-5.58510105263e+000lamuda_11=-5.11408352981e+000迭代次数13, u[12]=-4.57268930088e+000 lamuda_12=-4.57887217687e+000迭代次数290, u[13]=-4.06207060803e+000 lamuda_13=-4.09647092626e+000迭代次数13, u[14]=-3.55145191519e+000 lamuda_14=-3.55421121575e+000迭代次数6, u[15]=-3.04083322234e+000 lamuda_15=-3.0410*******e+000迭代次数1606, u[16]=-2.53021452950e+000 lamuda_16=-2.53397031113e+000迭代次数72, u[17]=-2.01959583665e+000 lamuda_17=-2.00323076956e+000迭代次数19, u[18]=-1.50897714381e+000 lamuda_18=-1.50355761123e+000迭代次数17, u[19]=-9.98358450965e-001 lamuda_19=-9.93558606008e-001迭代次数11, u[20]=-4.87739758120e-001 lamuda_20=-4.87042673885e-001迭代次数10, u[21]=2.28789347246e-002 lamuda_21=2.23173624957e-002迭代次数13, u[22]=5.33497627570e-001 lamuda_22=5.32417474207e-001迭代次数15, u[23]=1.04411632041e+000 lamuda_23=1.05289896269e+000迭代次数29, u[24]=1.55473501326e+000 lamuda_24=1.58944588188e+000迭代次数81, u[25]=2.06535370610e+000 lamuda_25=2.06033046027e+000迭代次数40, u[26]=2.57597239895e+000 lamuda_26=2.55807559707e+000迭代次数13, u[27]=3.08659109179e+000 lamuda_27=3.08024050931e+000迭代次数23, u[28]=3.59720978464e+000 lamuda_28=3.61362086769e+000迭代次数16, u[29]=4.10782847748e+000 lamuda_29=4.0913*******e+000迭代次数23, u[30]=4.61844717033e+000 lamuda_30=4.60303537828e+000迭代次数12, u[31]=5.12906586317e+000 lamuda_31=5.132********e+000迭代次数30, u[32]=5.63968455602e+000 lamuda_32=5.59490634808e+000lamuda_33=6.08093385703e+000迭代次数18, u[34]=6.66092194171e+000lamuda_34=6.68035409211e+000迭代次数74, u[35]=7.17154063455e+000lamuda_35=7.29387744813e+000迭代次数30, u[36]=7.68215932740e+000lamuda_36=7.71711171424e+000迭代次数11, u[37]=8.19277802024e+000lamuda_37=8.22522001405e+000迭代次数38, u[38]=8.70339671309e+000lamuda_38=8.64866606519e+000迭代次数10, u[39]=9.21401540593e+000lamuda_39=9.25420034458e+000矩阵A的(谱范数)条件数为:cond(A)=1.92520427390e+003矩阵A的行列式为:detA=2.77278614175e+118四、讨论迭代初始向量的选取对于计算结果的影响:1.影响迭代速度。
数理统计第二次大作业材料行业股票的聚类分析与判别分析2015年12月26日材料行业股票的聚类分析与判别分析摘要1 引言2 数据采集及标准化处理2.1 数据采集本文选取的数据来自大智慧软件的股票基本资料分析数据,从材料行业的股票中选取了30支股票2015年1月至9月的7项财务指标作为分类的自变量,分别是每股收益(单位:元)、净资产收益率(单位:%)、每股经营现金流(单位:元)、主营业务收入同比增长率(单位:%)、净利润同比增长率(单位:%)、流通股本(单位:万股)、每股净资产(单位:元)。
各变量的符号说明见表2.1,整理后的数据如表2.2。
表2.1 各变量的符号说明自变量符号每股收益(单位:元)X1净资产收益率(单位:%)X2每股经营现金流(单位:元)X3主营业务收入同比增长率(单位:%)X4净利润同比增长率(单位:%)X5流通股本(单位:万股)X6每股净资产(单位:元)X7表2.2 30支股票的财务指标股票代码X1 X2 X3 X4 X5 X6 X7 武钢股份600005-0.0990-2.81-0.0237-35.21-200.231009377.98 3.4444宝钢股份6000190.1400 1.980.9351-14.90-55.011642427.88 6.9197山东钢铁600022-0.11650.060.0938-20.5421.76643629.58 1.8734北方稀土6001110.0830 3.640.652218.33-24.02221920.48 2.2856杭钢股份600126-0.4900-13.190.4184-36.59-8191.0283893.88 3.4497抚顺特钢6003990.219310.080.1703-14.26714.18112962.28 1.4667盛和资源6003920.0247 1.84-0.2141-5.96-19.3739150.00 1.2796宁夏建材6004490.04000.510.3795-22.15-92.3447818.108.7321宝钛股份600456-0.2090-2.53-0.3313-14.81-6070.2043026.578.1497山东药玻6005290.4404 5.26 1.2013 6.5016.7825738.018.5230国睿科技6005620.410011.53-0.2949 3.3018.9416817.86 3.6765海螺水泥600585 1.15169.05 1.1960-13.06-25.33399970.2612.9100华建集团6006290.224012.75-0.57877.90-6.4034799.98 1.8421福耀玻璃6006600.790014.250.9015 3.6017.27200298.63 6.2419宁波富邦600768-0.2200-35.02-0.5129 3.1217.8813374.720.5188马钢股份600808-0.3344-11.710.3939-21.85-689.22596775.12 2.6854亚泰集团6008810.02000.600.1400-23.63-68.16189473.21 4.5127博闻科技6008830.503516.71-0.1010-10.992612.8023608.80 3.0126新疆众和6008880.0523 1.04-0.910662.64162.0464122.59 5.0385西部黄金6010690.0969 3.940.115115.5125.5712600.00 2.4965中国铝业601600-0.0700-2.920.2066-9.0882.79958052.19 2.3811明泰铝业6016770.2688 4.66-1.09040.8227.8640770.247.4850金隅股份6019920.1989 3.390.3310-10.05-39.01311140.26 6.7772松发股份6032680.35007.00-0.3195-4.43-9.622200.00 6.0244方大集团0000550.0950 5.66-0.480939.2920.6742017.94 1.6961铜陵有色0006300.0200 1.220.6132 3.23-30.74956045.21 1.5443鞍钢股份000898-0.1230-1.870.7067-27.32-196.21614893.17 6.4932中钢国际0009280.572714.45-0.4048-14.33410.2441286.57 4.2449中材科技0020800.684610.27 1.219547.69282.1740000.00 6.8936中南重工0024450.1100 4.300.340518.8445.0950155.00 2.70302.2 数据的标准化处理由于不同的变量之间存在着较大的数量级的差别,因此要对数据变量进行标准化处理。
应用数理统计大作业一学院:XXXXXXX学号:XXXXXXX姓名:XXX指导老师:XXX2014年12月21日国民生产总值增量的多元线性回归模型摘要:国民生产总值一直是衡量国家综合经济水平的重要指标,本文要讨论研究的是国民生产总值的增量趋势与各产业增值趋势间的多元线性关系[1]。
本论文搜集了我国从1998至2012年15年的国民生产与各产业增量指标,拟定数个自变量,代入统计软件SPSS 19.0[2]对各影响因素进行了统计分析,综合分析结果模拟多元线性回归函数。
模型建立之后,又将2013年数据作为测试集测试模型的拟合精确度,得到的结果达到预期值,得出模型建立较为成功。
关键词:逐步回归法,国民生产总值增量,线性拟合一引言国民生产总值(Gross Domestic Product)是在一定时期中,一个国家地区经济生产出的全部最终产品和劳务的价值,被公认为衡量国家经济状况的较佳指标。
它不仅仅反映了一定的经济表现,还可以反映国家的综合国力与经济发展前景,作为经济政策的制定依据,研究我国的国民生产总值的制约因素成为了学者们的热点问题。
下文就以1998年至2012年的统计数据为标准,利用SPSS软件作出了多元线性回归分析。
二统计分析2.1变量说明因变量——国民生产总值增值(亿元);自变量——第一产业增加值(亿元)自变量——第二产业增加值(亿元)自变量——第三产业增加值(亿元)自变量——工业增加值(亿元)自变量——建筑业增加值(亿元)2.2统计数据2000年9537.5 14944.72 45555.88 38713.95 40033.59 5522.29 1999年5274.77 14770.03 41033.58 33873.44 35861.48 5172.1 1998年5429.25 14817.63 39004.19 30580.47 34018.43 4985.76 表格2-11998~2012年训练集数据测试组国民生产总值增值(亿元)第一产业增加值(亿元)第二产业增加值(亿元)第三产业增加值(亿元)工业增加值(亿元)建筑业增加值(亿元)2013年49375.11 56957 249684.4 262203.8 210689.4 38995表格2-22013年测试集数据以上数据来自《中国统计年鉴2013》[3]中收录的近15年全国国民生产总值增值数据,考察与各产业间增量趋势变化中关系密切并且直观上有线性关系的因素,因此选取了第一产业增值、第二产业增值、第三产业增值、工业总产值增值、建筑业增值五大因素为自变量。
应用数理统计作业一学号:姓名:电话:二〇一四年十二月国内生产总值的多元线性回归模型摘要:本文首先选取了选取我国自1978至2012年间的国内生产总值为因变量,并选取了7个主要影响因素,进一步利用统计软件SPSS对以上数据进行了多元逐步线性回归。
从而找到了能反映国内生产总值与各因素之间关系的“最优”回归方程.然后利用多重线性的诊断找出存在共线性的自变量,剔除缺失值较多的因子.再次进行主成份线性回归分析,找出最优回归方程。
所得结论与我国当前形势相印证。
关键词:多元线性回归,逐步回归法,多重共线性诊断,主成份分析目录0符号说明 (1)1 介绍 (2)2 统计分析步骤 (3)2。
1 数据的采集和整理 (3)2。
2采用多重逐步回归分析 (7)2.3进行共线性诊断 (17)2。
4进行主成分分析确定所需主成份 (24)2。
5进行主成分逐步回归分析 (27)3 结论 (30)参考文献 (31)致谢 (32)0符号说明1 介绍文中主要应用逐步回归的主成份分析方法,对数据进行分析处理,最终得出能够反映各个因素对国内生产总值影响的最“优”模型及线性回归方程.国内生产总值是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标.它不但可反映一个国家的经济表现,还可以反映一国的国力与财富。
2012年1月,国家统计局公布2011年重要经济数据,其中GDP增长9.2%,基本符合预期。
2012年10月18日,统计显示,2012年前三季度国内生产总值353480亿元,同比增长7.7%;其中,一季度增长8.1%,二季度增长7。
6%,三季度增长7.4%,三季度增幅创下2009年二季度以来14个季度新低。
中国的GDP核算历史不长,上世纪90年代之前通常用“社会总产值”来衡量经济发展情况。
上世纪80年代初中国开始研究联合国国民经济核算体系的国内生产总值(GDP)指标。
对中国各地财政收入情况的聚类分析和判别分析应用数理统计第二次大作业学院名称学号学生姓名摘要我国幅员辽阔,由于人才、地理位置、自然资源等条件的不同,各地区的财政收入类型各自呈现出不一样的发展趋势,通过准确定位中国各地区财政收入情况对于正确认识我国财政收入具有重要的意义。
本文以中国各地财政收入情况为研究对象,从《中国统计年鉴》中选取2011年期间中国各地财政收入情况为因变量,选取国内增值税、营业税、企业所得税、个人所得税、城市维护建设税、土地增值税、契税、专项收入、行政事业性收费收入、国有资本经营收入和国有资源(资产)有偿使用收入11个可能影响中国各地财政收入的因素为自变量,利用统计软件SPSS,对27个地区的财政收入进行了聚类分析,并对另外4个地区的财政收入进行了判别分析,并最终确定了中国各地区根据财政收入类型的分类情况。
关键词:聚类分析,判别分析,SPSS,中国各地财政收入类型1、引言财政收入,是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而筹集的一切资金的总和。
财政收入表现为政府部门在一定时期内(一般为一个财政年度)所取得的货币收入。
财政收入是衡量一国政府财力的重要指标,政府在社会经济活动中提供公共物品和服务的范围和数量,在很大程度上决定于财政收入的充裕状况。
通过准确定位中国各地区财政收入情况对于正确认识我国财政收入具有重要的意义。
本文利用统计软件SPSS,根据各地区的财政收入情况,对北京、天津、河北等27个地区进行聚类分析,并对青海、重庆、四川、贵州4个省市进行判别分析,判断属于聚类分析结果中的哪种财政收入类型。
1.1 聚类分析聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称,它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
本文采用的是系统聚类分析,它又称集群分析,是聚类分析中应用最广的一种方法,其基本思想是:首先将每个聚类对象看作一类,然后根据对象间的相似程度,将相似程度最高的两类进行合并,并计算合并后的类与其他类之间的距离,再选择相近者进行合并,每合并一次减少一类,直至所有的对象都并为一类为止。
全国各地区教育发展水平差异研究摘要:改革开放以来,我国地方教育事业获得了长足发展。
与此同时,区域间教育发展不平衡的问题也日益凸显。
针对这一情况,本文对全国各地教育发展水平的差异进行了研究,以学校数量、学生数量、教职工情况、教育质量、经费投入这几个因素为考量,广泛选取了12个代表性指标,利用SPSS 的聚类分析功能对全国各省份进行聚类,将各省份按教育水平的高低分为五类。
在此基础上,采用逐步判别分析法构造典型判别函数,对这些已知样本进行分类。
通过对判别结果进行分析,改变了聚类数目,极大的提高了正确判断的概率。
最终将全国各地区教育发展水平划分为4类,其中教育水平最为先进的省份为北京、上海、天津,最为落后的地区是西藏。
关键字:教育水平,聚类分析,判别分析,SPSS1. 引言教育和人力资本投资不仅是保持地区综合竞争力的根本,同时也是提升地区综合竞争力的关键[1]。
改革开放以来,我国地方教育事业获得了长足发展。
与此同时,区域间教育发展不平衡的问题也日益凸显,由此导致区域间人力积累水平的差距不断扩大,进一步推动了地区社会经济发展的失衡,成为统筹区域经济协调发展的重要障碍[2]。
本文选取影响地区教育水平的若干因素作为样本,采用聚类分析方法以及判别分析方法,并利用统计分析软件SPSS13.0,对我国各地区教育发展的相似性和差异性进行了初步的研究和分析。
2. 理论概述2.1 聚类分析[3]研究怎样对事物进行合理分类(归类)的统计方法成为聚类分析(clustering)。
聚类分析的基本原理是把某种性质相似的对象归于同一类,而不同的类之间则存在较大差异。
系统聚类法(Hierarchical Clustering Method)是最常用的一种聚类方法。
初始时先把要归类的n个对象各自视为一类,然后逐渐把关系最密切的两个类合并成一个新类,直到最后把n个对象都归为一类时停止。
在系统聚类过程中,为了合并“最接近”的两类,需要规定类与类之间的相似性测度,本文采用组间连接法[4](between-groups linkage),合并两类的结果使所有的两两样品之间的平均距离最小。
应用数理统计大作业(二)
部分省市经济类型的聚类和判别分析
学院:学号:姓名:班级:
机械工程及自动化学院
SY1007???
XXXXX
51班
2011年1月7日
目录
摘要 (1)
符号说明 (1)
0 引言 (1)
1 源数据的提取 (1)
2 聚类分析过程 (2)
2.1 基本概念 (2)
2.2 聚类分析过程 (2)
2.3判别分析 (5)
2.4分类结果分析 (7)
3 结论 (7)
参考文献 (8)
部分省市经济类型的聚类和判别分析
摘要
一个省市的经济类型和众多因素比如地理位置、国民生产总值、人口素质等息息相关,本文利用统计软件SPSS,对北京市等13省市2008年的地区生产总值(亿元)、职工人均工资(元)、第一、二、三产业各自在国民生产总值中占的比重作为判别经济类型的五个因素,进行聚类分析,得出了分类结果,分类结果和我们的直观判断相吻合。
本文所进行的分析结果在一定程度上反映了这些省市的经济类型和经济特点。
关键词:经济类型,聚类分析,判别分析,SPSS
符号说明
符号说明
X1 地区生产总值
X2职工人均工资
X3第一产业在国民生产总值中占的比重
X4第二产业在国民生产总值中占的比重
X5第三产业在国民生产总值中占的比重0 引言
随着中国经济迅速发展,各个省市自治区的经济呈现出各自不同的发展态势。
通过研究各省市的经济发展状况和经济类型对于正确认识我国的经济发展情况具有重要意义。
一个省自治区直辖市的经济类型和众多因素比如地理位置、国民生产总值、人口素质等因素息息相关,本文利用功能强大的统计软件SPSS,对北京市、天津市、河北省、辽宁省、江苏省、浙江省、安徽省、湖北省、湖南省、河南省、广东省、四川省和山东省2008年的地区生产总值(亿元)、职工人均工资(元)、第一、二、三产业各自在国民生产总值中占的比重作为判别经济类型的五个因素,进行聚类分析,结果北京市和天津市属于一类,河北省、浙江省和河南省属于一类,辽宁省、安徽省、湖南省、湖北省、四川省属于一类,江苏省、山东省、广东省属于一类,这个结果和我们的直观判断一致。
这个结果也充分说明了本文进行的分析是合理的,具有一定的科学性。
1 源数据的提取
本文所用的数据全来自2009年出版的《中国统计年鉴》,从中提取了有关北京市、天津市、河北省、辽宁省、江苏省、浙江省、安徽省、湖北省、湖南省、
河南省、广东省、四川省和山东省总计13省2008年的五种数据。
分别为:地区生产总值(亿元)X1、职工人均工资(元)X2、第一、二、三产业(X3、X4、X5)各自在国民生产总值中占的比重。
分析用到的源数据如表1所示。
表1 分析用到的源数据
地区生产总值
(亿元)
职工人均工资
(元)
第一产业第二产业第三产业
北京10488.03 56328 1.1 25.7 73.2 天津6354.38 41748 1.9 60.1 37.9 河北16188.61 24756 12.6 54.2 33.2 辽宁13461.57 27729 9.7 55.8 34.5 江苏30312.61 31667 6.9 55.0 38.1 浙江21486.92 34146 5.1 53.9 41.0 安徽8874.17 26363 16.0 46.6 37.4 湖北11330.38 22739 15.7 43.8 40.5 湖南11156.64 24870 18.0 44.2 37.8 河南18407.78 24816 14.4 56.9 28.6 广东35696.46 33110 5.5 51.6 42.9 四川12506.25 25038 18.9 46.3 34.8 山东31072.06 26404 9.7 57.0 33.4
2 聚类分析过程
2.1 基本概念
聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称,它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
本文采用的是系统聚类分析,它又称集群分析,是聚类分析中应用最广的一种方法,它根据样本的多指标(变量)、多个观察数据,定量地确定样品、指标之间存在的相似性或亲疏关系,并据此连结这些样品或指标,归成大小类群,构成分类树状图或冰柱图。
判别分析是根据多种因素(指标)对事物的影响来实现对事物的分类,从而对事物进行判别分类的统计方法。
判别分析适用于已经掌握了历史上分类的每一个类别的若干样品,希望根据这些历史的经验(样品),总结出分类的规律性(判别函数)来指导未来的分类。
2.2 聚类分析过程
进入SPSS18.0程序,选择分析→分类→系统聚类,进行系统聚类分析
(Hierarchical Cluster Analysis),引入的变量是X1至X5。
采取对样品(个案)进行聚类,即Q型聚类分析(对研究对象本身分类)。
聚类方法使用类间平均链锁法,距离测量技术选择距离平方,即两观察单位间的距离为其值差的平方和,该技术用于Q型聚类,得出以下计算结果。
法为默认设置,即欧氏距离平方值。
表3显示了各地区经济类型的相近程度,越接近于1,说明相近程度越高。
表3 相似矩阵
表4所列各项的意义如下:阶-----聚类步骤号;群集组合-----在某步中合并的个案;系数-----距离或相似系数;首次出现阶群集-----新生成聚类;下一阶-----对应步骤生成的新类将在第几步与其它个案或新类合并。
图1 分析得到的树状结构图
图2 聚类分析结果
图2显示了聚类分析结果。
北京市和天津市分为一类,河北省、浙江省和河南省分为一类,辽宁省、安徽省、湖南省、湖北省、四川省分为一类,江苏省、山东省、广东省分为一类。
2.3判别分析
进入SPSS18.0程序,选择分析→分类→判别,采用自变量全进入模型来进行判别分析,由于在聚类分析中将13省市的经济类型分为四类,定义分组变量的取值范围为1~4。
得到以下分析结果。
示。
1234
C1= -720.87-0.001X1+0.021X2+19.11X3+8.617X4
C2= -606.806+0.005X1+0.017X2+18.654X3+7.894X4
C3= -565.325+0.003X1+0.017X2+18.385X3+7.657X4
C4= -680.994-0.009X1+0.016X2+18.963X3+7.858X4
下图显示的是所有组的散点图,显示的分类结果和聚类分析基本相同。
图3 散点图
2.4分类结果分析
北京和天津同为直辖市,经济结构相对于别的省份来说相差不大,从原始数据中可以看到北京和天津虽然在各项因素中与北京有一定的差异,但是别的省和北京比差距更大,所以把北京和天津归到一类还是比较合理的。
广东、江苏和山东同为国内生产值大省,它们的经济结构几乎相同,所以把它们归为一类是十分合理的。
安徽、湖南、湖北、四川同为南方农业大省,国民生产总值中,第一产业(农林牧渔)所占的比重较大,指标相似,但从原始数据也可以看到这几个省份在人均国民生产总值和职工平均工资上都与其它省份有较大差距,经济相对来说与珠三角地区有较大差距,所以把他们归为一类就理所当然了。
河北、河南和浙江的地区生产总值相近,河南、河北第二产业所占比例基本相同,它们的经济也可以归为一类。
从以上可以看出以上得到的聚类分析结果和我们的直观判断相同,说明采用本文的指标和聚类分析的方法来给各省的经济类型分类是正确的。
3 结论
本文通过运用数理统计的聚类分析的基本知识解决了一个实际问题,即运用聚类分析采用自定义的经济指标划分部分省市的经济类型,通过本文可知聚类分析和判别分析的结果和我们的直观判断吻合,这说明本文采用的经济指标和分析方法都是正确的。
参考文献
[1]孙海燕,周梦,李卫国,冯伟. 应用数理统计[M]. 北京:北京航空航天大学数
学系, 1999.
[2]张建同,孙昌言. 以Excel和SPSS为工具的管理统计[M]. 北京:清华大学出
版社,2002.
[3]国家统计局.2009年中国统计年鉴[M]. 中国统计出版社,2009.
[4]戚珉,王霏. 应用聚类分析对部分省市经济类型的分类研究[J]. 科技信息,
2006,(10):70-72.。