互助问答第59问 稳健性检验及地区虚拟变量设置
- 格式:docx
- 大小:15.44 KB
- 文档页数:1


毕业论文中的经济学实证研究方法可靠性检验与结果稳健性分析的敏感性检验在毕业论文中进行经济学实证研究是一项重要的任务。
在实证研究中,经济学家使用各种方法和技术来检验经济理论的有效性,并得出结论。
然而,为了确保研究结果的可靠性和结果的稳健性,经济学实证研究需要进行可靠性检验和敏感性检验。
1. 可靠性检验可靠性检验是通过对数据和模型进行多次重复运算和分析,以确保研究结果的稳定性和一致性。
这是保证经济学实证研究的重要步骤之一。
以下是几种常用的可靠性检验方法:1.1 重复样本验证:对于研究中使用的样本数据,可以进行随机抽样,并进行多次计算和分析,以确保研究结果的一致性和稳定性。
1.2 数据检验:在实证研究中,数据的准确性和完整性是至关重要的。
可以通过检查数据的来源、收集和处理方法,以确保数据的可靠性。
1.3 鲁棒性检验:在经济学实证研究中,模型的稳健性是非常重要的。
可以对模型进行多个方面的鲁棒性检验,包括对异常值和离群值的敏感性检验,以确保研究结果的可靠性。
2. 结果稳健性检验结果稳健性检验是检验研究结果对模型假设和参数估计的敏感性,以确保研究结果的可靠性和鲁棒性。
以下是几种常用的结果稳健性检验方法:2.1 参数估计的稳健性检验:在经济学实证研究中,参数估计的稳健性是保证研究结果可靠性的关键。
可以通过使用不同的估计方法和假设条件,对参数进行多次估计和检验,以确保结果的鲁棒性。
2.2 模型设定的敏感性检验:在经济学实证研究中,模型设定是关键因素之一。
可以通过对模型设定的变化进行敏感性检验,包括引入其他因素、改变变量的测量方法等,以确认研究结果的稳健性。
2.3 样本的敏感性检验:在经济学实证研究中,样本的选择和大小对研究结果影响很大。
可以对研究结果进行样本的敏感性检验,包括增加或减少样本量,对比不同样本的结果等,以确保研究结果的稳健性。
在进行经济学实证研究时,可靠性检验和结果稳健性检验是必不可少的步骤。
只有通过这些检验,研究结果才能够具有可信度和说服力。


互助问答第28期:稳健性检验及地区虚拟变量设置
问题1:我在做联立方程组(reg3)时,更换了核心变量(意思相近的)做robust check,但发现有些控制变量的显著性甚至发生了变化,比如从不显著到1%显著性水平上显著,这应该是说明结果的不稳健吧?所以具体是什么原因造成的呢,重要的是应该怎么解决?另外就是,联立方程中是否要加入地区虚拟变量,比如省份虚拟变量,因为看了一些相关文章都没有说清,如果不要,理由是什么呢?
答案1:
稳健性检验旨在检验核心自变量与因变量的关系是否稳健。
如果核心变量前的系数比较稳定,就可以认为结果比较稳健。
控制变量前的系数是否发生明显变化并不见得是研究者关心的问题,一般情形下无需特别处理。
是否应该加入地区虚拟变量与用什么方法没有必然联系,需要关注计量模型背后的理论逻辑——如果理论上认为地区层面的因素是因变量的决定因素之一,那么就应当纳入地区层面的变量。
地区层面的变量可以是有具体意涵的变量(比如地区GDP),也可以是地区虚拟变量(可以囊括所有地区层面不随时间变化的影响因素)。
当经济理论要求纳入地区层面变量时,在数据结构允许的情况下,一般需要至少控制地区层面的虚拟变量,这样可以避免遗漏某些不随时间变化的地区信息。
学术指导:张晓峒老师
本期解答人:中关村大街
编辑:杨芳Hollian 知我者
统筹:芋头易仰楠
技术:知我者。





稳健性检验的方法是什么_如何进行稳健性检验稳健性检验检验的是实证结果是否随着参数设定的改变而发生变化,如果改变参数设定以后,结果发现符号和显著性发生了改变,说明不是robust的,需要寻找问题的所在。
下面是店铺为您带来稳健性检验的方法,欢迎阅读。
稳健性检验的方法1. 从数据出发,根据不同的标准调整分类,检验结果是否依然显著;2. 从变量出发,从其他的变量替换,如:公司size可以用total assets衡量,也可以用total sales衡量3. 从计量方法出发,可以用OLS, FIX EFFECT, GMM等来回归,看结果是否依然robust;稳健性检验目的为了确定没有随机趋势或确定趋势,否则将会产生“伪回归”问题。
伪回归是说,有时数据的高度相关仅仅是因为二者同时随时间有向上或向下的变动趋势, 并没有真正联系。
这样数据中的趋势项,季节项等无法消除, 从而在残差分析中无法准确进行分析. 平稳性检验的方法可以用PDF检验, 依据模型趋势可以选择3种模型. 消除趋势可以用差分法(比如一阶)模型也只有通过平稳性检验才有统计分析的意义。
会计的稳健性会计稳健性作为一项重要的会计信息质量要求,却经常受到资本市场规制者、准则制定者和实务工作者的批评,理论界对会计稳健性的认识似乎也非常有限。
有鉴于此,为了深入理解会计稳健性,笔者首先对会计稳健性的概念进行梳理,着重分析了条件稳健性和非条件稳健性。
接着。
从契约经济激励、法律和政治制度等方面,对会计稳健性的产生原因进行解读。
最后,对会计稳健性的几种重要的测度方法进行了描述,并对最新进展给予了关注。
稳健性原则稳健性原则是企业会计核算中运用的一项重要原则,《企业会计制度》和已发布的具体会计准则充分体现了这一原则。
稳健性原则又称谨慎性原则,是指在处理企业不确定的经济业务时,应持谨慎的态度。
也就是说,凡是可以预见的损失和费用都应予以记录和确认,而没有十足把握的收入则不能予以确认和入帐。
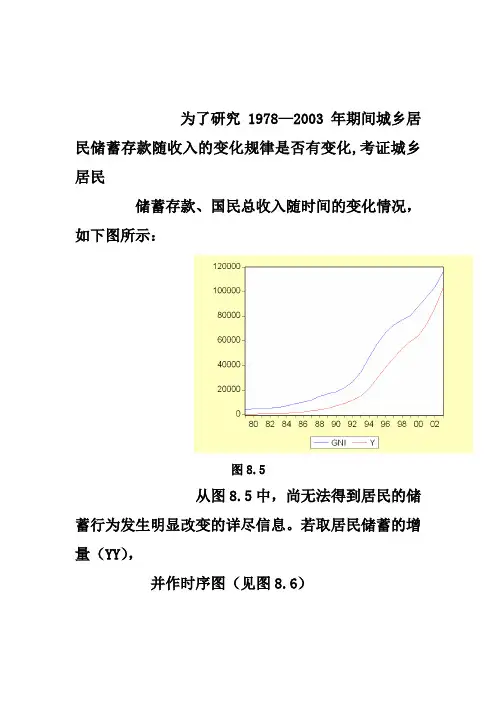
为了研究1978—2003年期间城乡居民储蓄存款随收入的变化规律是否有变化,考证城乡居民
储蓄存款、国民总收入随时间的变化情况,如下图所示:
图8.5
从图8.5中,尚无法得到居民的储蓄行为发生明显改变的详尽信息。
若取居民储蓄的增量(YY),
并作时序图(见图8.6)
图
8.6
图8.7 从居民储蓄增量图可以看出,城乡居民
的储蓄行为表现出了明显的阶段特征:在1996年和2000年有两个明显的转折点。
再从城乡居民储蓄存款增量与国民总收入之间关系的散布图看(见图8.7),也呈现出了相同的阶段性特征。
为了分析居民储蓄行为在1996年前后和
2000年前后三个阶段的数量关系,引入虚拟变量D 1和D 2。
D 1和D 2的选择,是以1996、2000年两个转折点作为依据,1996年的GNI 为66850.50亿元,2000年的GNI 为国为民8254.00亿元,并设定了如下模型:
(123668
t t t YY = +GNI GNI βββ+-其中:
⎩⎨⎧=其他年以前0
199611t D ⎩⎨⎧=其他年以后0
200012t D。
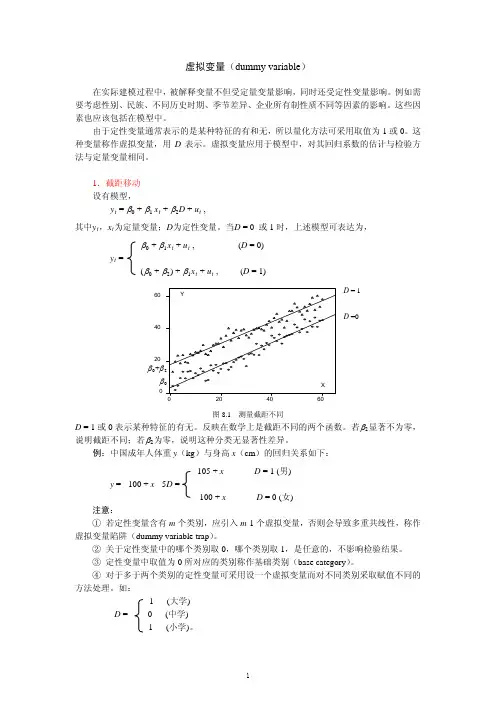
第七章 虚拟变量回归第一节 虚拟变量的性质在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。
例如需要考虑性别、民族、不同历史时期、季节差异、政府的更迭(工党-保守党)、经济体制的改革、固定汇率变为浮动汇率、从战时经济转为和平时期经济等。
这些因素也应该包括在模型中。
一、基本概念由于定性变量通常表示的是某种特征的有和无,所以量化方法可采用取值为1或0。
这种变量称作虚拟变量(dummy variable )。
虚拟变量也称:哑元变量、定性变量等等。
通常用字母D 或DUM 加以表示(英文中虚拟或者哑元Dummy 的缩写)。
用1表示具有某一“品质”或属性,用0表示不具有该“品质”或属性。
虚拟变量使得我们可以将那些无法定量化的变量引入回归模型中。
虚拟变量应用于模型中,对其回归系数的估计与检验方法和定量变量相同。
虚拟变量表示两分性质,即“是”或“否”,“男”或“女”等。
下面给出几个可以引入虚拟变量的例子。
例1:你在研究学历和收入之间的关系,在你的样本中,既有女性又有男性,你打算研究在此关系中,性别是否会导致差别。
例2:你在研究某省家庭收入和支出的关系,采集的样本中既包括农村家庭,又包括城镇家庭,你打算研究二者的差别。
例3:你在研究通货膨胀的决定因素,在你的观测期中,有些年份政府实行了一项收入政策。
你想检验该政策是否对通货膨胀产生影响。
上述各例都可以用两种方法来解决,一种解决方法是分别进行两类情况的回归,然后看参数是否不同。
另一种方法是用全部观测值作单一回归,将定性因素的影响用虚拟变量引入模型。
二、虚拟变量设置规则虚拟变量的设置规则涉及三个方面: 1.“0”和“1”选取原则虚拟变量取“1”或“0”的原则,应从分析问题的目的出发予以界定。
从理论上讲,虚拟变量取“0”值通常代表比较的基础类型;而虚拟变量取“1”值通常代表被比较的类型。
“0”代表基期(比较的基础,参照物);“1”代表报告期(被比较的效应)。
虚拟变量设置原则
虚拟变量在统计学中有着重要的作用,它能够将分类变量转化为数值变量,方便进行回归分析。
但是,在设置虚拟变量的时候需要注意一些原则,以确保回归分析的准确性和可靠性。
首先,需要选择一个基准分类,将其作为参照组。
其他分类则设置对应的虚拟变量,取值为0或1。
这样可以避免多重共线性的问题。
其次,设置虚拟变量的数量应该比分类变量的分类数少1。
这是因为当所有虚拟变量都等于0时,就表示参照组,不需要再设置一个虚拟变量来表示。
还需要注意,虚拟变量的取值应该在不同分类之间具有可比性。
例如,对于“有薪资”的分类变量,虚拟变量可以设置为“有薪资=1,无薪资=0”,而不能设置为“有薪资=1000,无薪资=0”。
最后,应该注意将设置的虚拟变量与原始数据进行验证。
可以通过计算每个分类的均值来检验虚拟变量的正确性,如果虚拟变量的均值与分类变量的均值相同,则说明设置正确。
总之,设置虚拟变量需要根据具体情况进行,并遵循一定的原则,才能保证回归分析的准确性和可靠性。
- 1 -。
《计量经济学》要点一、单项选择题知识点:第一章若干定义、概念时间序列数据定义横截面数据定义1.同一统计指标按时间顺序记录的数据称为( B )。
A、横截面数据B、时间序列数据C、修匀数据D、原始数据2.同一时间,不同单位相同指标组成的观测数据称为( B )A.原始数据B.横截面数据C.时间序列数据D.修匀数据变量定义(被解释变量、解释变量、内生变量、外生变量)单方程中可以作为被解释变量的是(控制变量、内生变量、外生变量);3.在回归分析中,下列有关解释变量和被解释变量的说法正确的有( C )A、被解释变量和解释变量均为随机变量B、被解释变量和解释变量均为非随机变量C、被解释变量为随机变量,解释变量为非随机变量D、被解释变量为非随机变量,解释变量为随机变量什么是解释变量、被解释变量?从变量的因果关系上,模型中变量可分为解释变量(Explanatory variable)和被解释变量(Explained variable)。
在模型中,解释变量是变动的原因,被解释变量是变动的结果。
被解释变量是模型要分析研究的对象,也常称为“应变量”(Dependent variable)、“回归子”(Regressand)等。
解释变量也常称为“自变量”(Independent variable)、“回归元”(Regressor)等,是说明应变量变动主要原因的变量。
因此,被解释变量只能由内生变量担任,不能由非内生变量担任。
4.单方程计量经济模型中可以作为被解释变量的是( C )A、控制变量B、前定变量C、内生变量D、外生变量5.单方程计量经济模型的被解释变量是(A )A、内生变量B、政策变量C、控制变量D、外生变量6.在回归分析中,下列有关解释变量和被解释变量的说法正确的有(C)A、被解释变量和解释变量均为随机变量B、被解释变量和解释变量均为非随机变量C、被解释变量为随机变量,解释变量为非随机变量D、被解释变量为非随机变量,解释变量为随机变量双对数模型中参数的含义;7.双对数模型01ln ln lnY Xββμ=++中,参数1β的含义是(D )A .X的相对变化,引起Y的期望值绝对量变化B.Y关于X的边际变化C.X的绝对量发生一定变动时,引起因变量Y的相对变化率D.Y关于X的弹性8.双对数模型μββ++=XY lnlnln1中,参数1β的含义是( C )A. Y关于X的增长率B .Y关于X的发展速度C. Y关于X的弹性D. Y关于X 的边际变化计量经济学研究方法一般步骤四步12点9.计量经济学的研究方法一般分为以下四个步骤( B )A.确定科学的理论依据、模型设定、模型修定、模型应用B.模型设定、估计参数、模型检验、模型应用C.搜集数据、模型设定、估计参数、预测检验D.模型设定、检验、结构分析、模型应用对计量经济模型应当进行哪些方面的检验?经济意义检验:检验模型估计结果,尤其是参数估计,是否符合经济理论。
互助问答第5期互助问答第5期:Stata中系统GMM模型的稳健性检验和Stata 命令等本期解答人:王群勇赵梦阳吴松彬问:Stata中系统GMM模型的稳健性检验和Stata命令答:模型的稳健性检验可以分为两种,一种是计量方法的稳健性检验,一种是计量数据的稳健性检验。
前者通常适用于所使用的计量方法比较新颖的研究,通常做法就是换计量方法,换一种相对可靠的计量方法。
如果是面板数据的话,可用GMM进行稳健性检验(因为GMM不需要满足经典计量假设)。
后者通常适用于一般性地研究,通常的做法就是换数据。
主要有以下几种方法换数据:1.蒙特卡洛或者拔靴(Bootstrapping),生成新数据或重复取样;2.把原来的样本分组,比如按地区东南西北中分组、按发达国家发展中国家分组、按大中小分组,分别回归;3.重新取样。
稳健性检验最起码需要保证的是:稳健性检验回归系数的正负号要和原研究回归系数的正负号相同。
问:工企库中邮编的位置是红色字体,经过sort ,drop 等命令后,去掉了一些异常值,但destring时仍显示“zipcode contains nonnumeric characters; no replace”,因为有200万+条数据答: install asciiplot, from(/RePEc/bocode/a) replace2.asciiplot3.gen tempvar = postcode4.forvalues i = 0/47 {5.local char=uchar(`i')6.replace tempvar = subinstr(tempvar,`"`char'"',"",.)7.}8.forvalues i = 58/255 {9.local char=uchar(`i')10.replace tempvar = subinstr(tempvar,"`char'","",.)11.}这个问题我需要两个命令即可完成,即subinstr和asciiplot。
问题1:我在做联立方程组(reg3)时,更换了核心变量(意思相近的)做robust check,但发现有些控制变量的显著性甚至发生了变化,比如从不显著到1%显著性水平上显著,这应该是说明结果的不稳健吧?所以具体是什么原因造成的呢,重要的是应该怎么解决?另外就是,联立方程中是否要加入地区虚拟变量,比如省份虚拟变量,因为看了一些相关文章都没有说清,如果不要,理由是什么呢?
答案1:
稳健性检验旨在检验核心自变量与因变量的关系是否稳健。
如果核心变量前的系数比较稳定,就可以认为结果比较稳健。
控制变量前的系数是否发生明显变化并不见得是研究者关心的问题,一般情形下无需特别处理。
是否应该加入地区虚拟变量与用什么方法没有必然联系,需要关注计量模型背后的理论逻辑——如果理论上认为地区层面的因素是因变量的决定因素之一,那么就应当纳入地区层面的变量。
地区层面的变量可以是有具体意涵的变量(比如地区GDP),也可以是地区虚拟变量(可以囊括所有地区层面不随时间变化的影响因素)。
当经济理论要求纳入地区层面变量时,在数据结构允许的情况下,一般需要至少控制地区层面的虚拟变量,这样可以避免遗漏某些不随时间变化的地区信息。
学术指导:张晓峒老师
本期解答人:中关村大街
编辑:杨芳Hollian 知我者
统筹:芋头易仰楠
技术:知我者。