(2)遗传算法作业
- 格式:doc
- 大小:32.00 KB
- 文档页数:1

实验六:遗传算法求解TSP问题实验2篇第一篇:遗传算法的原理与实现1. 引言旅行商问题(TSP问题)是一个典型的组合优化问题,它要求在给定一组城市和每对城市之间的距离后,找到一条路径,使得旅行商能够在所有城市中恰好访问一次并回到起点,并且总旅行距离最短。
遗传算法作为一种生物启发式算法,在解决TSP问题中具有一定的优势。
本实验将运用遗传算法求解TSP问题,以此来探讨和研究遗传算法在优化问题上的应用。
2. 遗传算法的基本原理遗传算法是模拟自然界生物进化过程的一种优化算法。
其基本原理可以概括为:选择、交叉和变异。
(1)选择:根据问题的目标函数,以适应度函数来评估个体的优劣程度,并按照适应度值进行选择,优秀的个体被保留下来用于下一代。
(2)交叉:从选出的个体中随机选择两个个体,进行基因的交换,以产生新的个体。
交叉算子的选择及实现方式会对算法效果产生很大的影响。
(3)变异:对新生成的个体进行基因的变异操作,以保证算法的搜索能够足够广泛、全面。
通过选择、交叉和变异操作,不断迭代生成新一代的个体,遗传算法能够逐步优化解,并最终找到问题的全局最优解。
3. 实验设计与实施(1)问题定义:给定一组城市和每对城市之间的距离数据,要求找到一条路径,访问所有城市一次并回到起点,使得旅行距离最短。
(2)数据集准备:选择适当规模的城市数据集,包括城市坐标和每对城市之间的距离,用于验证遗传算法的性能。
(3)遗传算法的实现:根据遗传算法的基本原理,设计相应的选择、交叉和变异操作,确定适应度函数的定义,以及选择和优化参数的设置。
(4)实验流程:a. 初始化种群:随机生成初始种群,每个个体表示一种解(路径)。
b. 计算适应度:根据适应度函数,计算每个个体的适应度值。
c. 选择操作:根据适应度值选择一定数量的个体,作为下一代的父代。
d. 交叉操作:对父代进行交叉操作,生成新的个体。
e. 变异操作:对新生成的个体进行变异操作,以增加搜索的多样性。

智能优化算法之遗传算法一、智能优化算法智能优化算法又称为现代启发式算法,是一种具有全局优化性能、通用性强、且适合于并行处理的算法。
这种算法一般具有严密的理论依据,而不是单纯凭借专家经验,理论上可以在一定的时间内找到最优解或近似最优解。
定的概率在整个求解空间中探索最优解。
由于它们可以把搜索空间扩展到整个问题空间,因而具有全局优化性能。
二、遗传算法1.遗传算法产生与发展(1) 产生①早在50年代,一些生物学家开始研究运用数字计算机模拟生物的自然遗传与自然进化过程;② 1963年,德国柏林技术大学的I. Rechenberg和H. P. Schwefel,做风洞实验时,产生了进化策略的初步思想;③ 60年代,L. J. Fogel在设计有限态自动机时提出进化规划的思想。
1966年Fogel等出版了《基于模拟进化的人工智能》,系统阐述了进化规划的思想;④ 60年代中期,美国Michigan大学的J. H. Holland教授提出借鉴生物自然遗传的基本原理用于自然和人工系统的自适应行为研究和串编码技术;⑤ 1967年,他的学生J. D. Bagley在博士论文中首次提出“遗传算法(Genetic Algorithms)”一词;⑥1975年,Holland出版了著名的“Adaptation in Natural and Artificial Systems”,标志遗传算法的诞生。
(2) 发展①70年代初,Holland提出了“模式定理”(Schema Theorem),一般认为是“遗传算法的基本定理”,从而奠定了遗传算法研究的理论基础;②1985年,在美国召开了第一届遗传算法国际会议,并且成立了国际遗传算法学会(ISGA,International Society of Genetic Algorithms);③1989年,Holland的学生D. J. Goldherg出版了“Genetic Algorithms in Search, Optimization, and Machine Learning”,对遗传算法及其应用作了全面而系统的论述;④ 1991年,L. Davis编辑出版了《遗传算法手册》,其中包括了遗传算法在工程技术和社会生活中大量的应用实例。

第三章遗传算法习题与答案1.填空题(1)遗传算法的缩写是,它模拟了自然界中过程而提出,可以解决问题。
在遗传算法中,主要的步骤是、、。
(2)遗传算法的三个算子是、、。
解释:本题考查遗传算法的基础知识。
具体内容请参考课堂视频“第3章遗传算法”及其课件。
答案:(1)GA,生物进化,全局优化,编码,计算适应度函数,遗传算子(2)选择,交叉,变异2.对于编码长度为7的二进制编码,判断以下编码的合法性。
(1)[1020110](2)[1011001](3)[0110010](4)[0000000](5)[2134576]解释:本题考查遗传算法的二进制编码的合法性。
具体内容请参考课堂视频“第3章遗传算法”及其课件。
答案:(1)[1020110]不合法,不能出现“2”(2)[1011001]合法(3)[0110010]合法(4)[0000000]合法(5)[2134576]不合法,不能出现0、1以外的数字3.下图能够基本反映生物学遗传与优胜劣汰的过程。
理解该图,联想计算类问题求解,回答下列问题。
(1)下列说法正确的是_____。
(多选)A)任何一个生物个体的性状是由其染色体确定的,染色体是由基因及其有规律的排列所构成的,因此生物个体可由染色体来代表。
B)生物的繁殖过程是通过将父代染色体的基因复制到子代染色体中完成的,在复制过程中会发生基因重组或基因突变。
基因重组是指同源的两个染色体之间基因的交叉组合,简称为“杂交/交配”。
基因突变是指复制过程中基因信息的变异,简称“突变”。
C)不同染色体会产生不同生物个体的性状,其适应环境的能力也不同。
D)自然界体现的是“优胜劣汰,适者生存”的丛林法则。
不适应环境的生物个体将被淘汰,自然界生物的生存能力会越来越强。
解释:本题考核对生物遗传观点以及所给图片的理解。
具体内容请参考课堂视频“第3章遗传算法”及其课件。
答案:A、B、C、D关于生物遗传进化的基本观点如下:(1)生物的所有遗传信息都包含在其染色体中,染色体决定了生物的性状。

遗传算法的C语⾔实现(⼆)-----以求解TSP问题为例上⼀次我们使⽤遗传算法求解了⼀个较为复杂的多元⾮线性函数的极值问题,也基本了解了遗传算法的实现基本步骤。
这⼀次,我再以经典的TSP问题为例,更加深⼊地说明遗传算法中选择、交叉、变异等核⼼步骤的实现。
⽽且这⼀次解决的是离散型问题,上⼀次解决的是连续型问题,刚好形成对照。
⾸先介绍⼀下TSP问题。
TSP(traveling salesman problem,旅⾏商问题)是典型的NP完全问题,即其最坏情况下的时间复杂度随着问题规模的增⼤按指数⽅式增长,到⽬前为⽌还没有找到⼀个多项式时间的有效算法。
TSP问题可以描述为:已知n个城市之间的相互距离,某⼀旅⾏商从某⼀个城市出发,访问每个城市⼀次且仅⼀次,最后回到出发的城市,如何安排才能使其所⾛的路线最短。
换⾔之,就是寻找⼀条遍历n个城市的路径,或者说搜索⾃然⼦集X={1,2,...,n}(X的元素表⽰对n个城市的编号)的⼀个排列P(X)={V1,V2,....,Vn},使得Td=∑d(V i,V i+1)+d(V n,V1)取最⼩值,其中,d(V i,V i+1)表⽰城市V i到V i+1的距离。
TSP问题不仅仅是旅⾏商问题,其他许多NP完全问题也可以归结为TSP问题,如邮路问题,装配线上的螺母问题和产品的⽣产安排问题等等,也使得TSP问题的求解具有更加⼴泛的实际意义。
再来说针对TSP问题使⽤遗传算法的步骤。
(1)编码问题:由于这是⼀个离散型的问题,我们采⽤整数编码的⽅式,⽤1~n来表⽰n个城市,1~n的任意⼀个排列就构成了问题的⼀个解。
可以知道,对于n个城市的TSP问题,⼀共有n!种不同的路线。
(2)种群初始化:对于N个个体的种群,随机给出N个问题的解(相当于是染⾊体)作为初始种群。
这⾥具体采⽤的⽅法是:1,2,...,n作为第⼀个个体,然后2,3,..n分别与1交换位置得到n-1个解,从2开始,3,4,...,n分别与2交换位置得到n-2个解,依次类推。




⼈⼯智能结课作业-遗传算法粒⼦群寻优蚁群算法解决TSP问题代码已经发布到了github:如果帮到你了,希望给个star⿎励⼀下1 遗传算法1.1算法介绍遗传算法是模仿⾃然界⽣物进化机制发展起来的随机全局搜索和优化⽅法,它借鉴了达尔⽂的进化论和孟德尔的遗传学说。
其本质是⼀种⾼效、并⾏、全局搜索的⽅法,它能在搜索过程中⾃动获取和积累有关搜索空间的知识,并⾃适应的控制搜索过程以求得最优解。
遗传算法操作使⽤适者⽣存的原则,在潜在的解决⽅案种群中逐次产⽣⼀个近似最优解的⽅案,在遗传算法的每⼀代中,根据个体在问题域中的适应度值和从⾃然遗传学中借鉴来的再造⽅法进⾏个体选择,产⽣⼀个新的近似解。
这个过程导致种群中个体的进化,得到的新个体⽐原来个体更能适应环境,就像⾃然界中的改造⼀样。
遗传算法具体步骤:(1)初始化:设置进化代数计数器t=0、设置最⼤进化代数T、交叉概率、变异概率、随机⽣成M个个体作为初始种群P(2)个体评价:计算种群P中各个个体的适应度(3)选择运算:将选择算⼦作⽤于群体。
以个体适应度为基础,选择最优个体直接遗传到下⼀代或通过配对交叉产⽣新的个体再遗传到下⼀代(4)交叉运算:在交叉概率的控制下,对群体中的个体两两进⾏交叉(5)变异运算:在变异概率的控制下,对群体中的个体进⾏变异,即对某⼀个体的基因进⾏随机调整(6)经过选择、交叉、变异运算之后得到下⼀代群体P1。
重复以上(1)-(6),直到遗传代数为 T,以进化过程中所得到的具有最优适应度个体作为最优解输出,终⽌计算。
旅⾏推销员问题(Travelling Salesman Problem, TSP):有n个城市,⼀个推销员要从其中某⼀个城市出发,唯⼀⾛遍所有的城市,再回到他出发的城市,求最短的路线。
应⽤遗传算法求解TSP问题时需要进⾏⼀些约定,基因是⼀组城市序列,适应度是按照这个基因的城市顺序的距离和分之⼀。
1.2实验代码import randomimport mathimport matplotlib.pyplot as plt#读取数据f=open("test.txt")data=f.readlines()#将cities初始化为字典,防⽌下⾯被当成列表cities={}for line in data:#原始数据以\n换⾏,将其替换掉line=line.replace("\n","")#最后⼀⾏以EOF为标志,如果读到就证明读完了,退出循环if(line=="EOF"):break#空格分割城市编号和城市的坐标city=line.split("")map(int,city)#将城市数据添加到cities中cities[eval(city[0])]=[eval(city[1]),eval(city[2])]#计算适应度,也就是距离分之⼀,这⾥⽤伪欧⽒距离def calcfit(gene):sum=0#最后要回到初始城市所以从-1,也就是最后⼀个城市绕⼀圈到最后⼀个城市for i in range(-1,len(gene)-1):nowcity=gene[i]nextcity=gene[i+1]nowloc=cities[nowcity]nextloc=cities[nextcity]sum+=math.sqrt(((nowloc[0]-nextloc[0])**2+(nowloc[1]-nextloc[1])**2)/10)return 1/sum#每个个体的类,⽅便根据基因计算适应度class Person:def__init__(self,gene):self.gene=geneself.fit=calcfit(gene)class Group:def__init__(self):self.GroupSize=100 #种群规模self.GeneSize=48 #基因数量,也就是城市数量self.initGroup()self.upDate()#初始化种群,随机⽣成若⼲个体def initGroup(self):self.group=[]i=0while(i<self.GroupSize):i+=1#gene如果在for以外⽣成只会shuffle⼀次gene=[i+1 for i in range(self.GeneSize)]random.shuffle(gene)tmpPerson=Person(gene)self.group.append(tmpPerson)#获取种群中适应度最⾼的个体def getBest(self):bestFit=self.group[0].fitbest=self.group[0]for person in self.group:if(person.fit>bestFit):bestFit=person.fitbest=personreturn best#计算种群中所有个体的平均距离def getAvg(self):sum=0for p in self.group:sum+=1/p.fitreturn sum/len(self.group)#根据适应度,使⽤轮盘赌返回⼀个个体,⽤于遗传交叉def getOne(self):#section的简称,区间sec=[0]sumsec=0for person in self.group:sumsec+=person.fitsec.append(sumsec)p=random.random()*sumsecfor i in range(len(sec)):if(p>sec[i] and p<sec[i+1]):#这⾥注意区间是⽐个体多⼀个0的return self.group[i]#更新种群相关信息def upDate(self):self.best=self.getBest()#遗传算法的类,定义了遗传、交叉、变异等操作class GA:def__init__(self):self.group=Group()self.pCross=0.35 #交叉率self.pChange=0.1 #变异率self.Gen=1 #代数#变异操作def change(self,gene):#把列表随机的⼀段取出然后再随机插⼊某个位置#length是取出基因的长度,postake是取出的位置,posins是插⼊的位置geneLenght=len(gene)index1 = random.randint(0, geneLenght - 1)index2 = random.randint(0, geneLenght - 1)newGene = gene[:] # 产⽣⼀个新的基因序列,以免变异的时候影响⽗种群 newGene[index1], newGene[index2] = newGene[index2], newGene[index1] return newGene#交叉操作def cross(self,p1,p2):geneLenght=len(p1.gene)index1 = random.randint(0, geneLenght - 1)index2 = random.randint(index1, geneLenght - 1)tempGene = p2.gene[index1:index2] # 交叉的基因⽚段newGene = []p1len = 0for g in p1.gene:if p1len == index1:newGene.extend(tempGene) # 插⼊基因⽚段p1len += 1if g not in tempGene:newGene.append(g)p1len += 1return newGene#获取下⼀代def nextGen(self):self.Gen+=1#nextGen代表下⼀代的所有基因nextGen=[]#将最优秀的基因直接传递给下⼀代nextGen.append(self.group.getBest().gene[:])while(len(nextGen)<self.group.GroupSize):pChange=random.random()pCross=random.random()p1=self.group.getOne()if(pCross<self.pCross):p2=self.group.getOne()newGene=self.cross(p1,p2)else:newGene=p1.gene[:]if(pChange<self.pChange):newGene=self.change(newGene)nextGen.append(newGene)self.group.group=[]for gene in nextGen:self.group.group.append(Person(gene))self.group.upDate()#打印当前种群的最优个体信息def showBest(self):print("第{}代\t当前最优{}\t当前平均{}\t".format(self.Gen,1/self.group.getBest().fit,self.group.getAvg())) #n代表代数,遗传算法的⼊⼝def run(self,n):Gen=[] #代数dist=[] #每⼀代的最优距离avgDist=[] #每⼀代的平均距离#上⾯三个列表是为了画图i=1while(i<n):self.nextGen()self.showBest()i+=1Gen.append(i)dist.append(1/self.group.getBest().fit)avgDist.append(self.group.getAvg())#绘制进化曲线plt.plot(Gen,dist,'-r')plt.plot(Gen,avgDist,'-b')plt.show()ga=GA()ga.run(3000)print("进⾏3000代后最优解:",1/ga.group.getBest().fit)1.3实验结果下图是进⾏⼀次实验的结果截图,求出的最优解是11271为避免实验的偶然性,进⾏10次重复实验,并求平均值,结果如下。

跨境电商环境下物流行业仓储与配送优化方案第一章绪论 (3)1.1 跨境电商物流概述 (3)1.2 研究目的与意义 (3)1.3 研究方法与结构安排 (3)第二章:跨境电商物流行业现状分析 (4)第三章:跨境电商物流仓储与配送环节存在的问题及原因分析 (4)第四章:跨境电商物流仓储与配送优化方案 (4)第五章:跨境电商物流仓储与配送优化方案实施与评价 (4)第二章跨境电商物流行业现状分析 (4)2.1 跨境电商物流行业现状 (4)2.2 我国跨境电商物流政策环境 (4)2.3 存在的主要问题 (5)第三章仓储优化方案 (5)3.1 仓储设施布局优化 (5)3.1.1 设施布局原则 (5)3.1.2 设施布局优化措施 (5)3.2 仓储作业流程优化 (6)3.2.1 作业流程优化原则 (6)3.2.2 作业流程优化措施 (6)3.3 仓储信息化管理 (6)3.3.1 信息化管理内容 (6)3.3.2 信息化管理措施 (6)第四章配送网络优化 (6)4.1 配送网络布局优化 (6)4.2 配送中心选址与建设 (7)4.3 配送路径优化 (7)第五章供应链协同优化 (8)5.1 供应链协同管理 (8)5.1.1 概述 (8)5.1.2 需求协同 (8)5.1.3 计划协同 (8)5.1.4 物流协同 (8)5.2 供应商关系管理 (8)5.2.1 概述 (8)5.2.2 供应商选择与评价 (9)5.2.3 供应商合作与退出 (9)5.3 供应链风险防控 (9)5.3.1 概述 (9)5.3.2 风险识别 (9)5.3.4 风险应对 (9)5.3.5 风险监控 (9)第六章包装与装卸优化 (9)6.1 包装材料与方式优化 (9)6.1.1 包装材料的选择 (10)6.1.2 包装方式的优化 (10)6.2 装卸作业流程优化 (10)6.2.1 装卸作业前的准备工作 (10)6.2.2 装卸作业流程 (10)6.3 装卸设备与工具优化 (10)6.3.1 装卸设备的优化 (11)6.3.2 装卸工具的优化 (11)第七章信息管理与数据分析 (11)7.1 物流信息平台建设 (11)7.1.1 平台架构设计 (11)7.1.2 数据集成 (11)7.1.3 功能模块 (11)7.2 数据挖掘与分析 (12)7.2.1 数据挖掘技术 (12)7.2.2 数据分析应用 (12)7.3 物流成本控制 (12)7.3.1 成本核算 (12)7.3.2 成本控制策略 (12)第八章绿色物流与可持续发展 (13)8.1 绿色物流理念 (13)8.2 节能减排技术与应用 (13)8.3 循环经济发展 (14)第九章跨境电商物流行业政策建议 (14)9.1 政策环境优化 (14)9.1.1 完善跨境电商法律法规体系 (14)9.1.2 优化跨境电商通关流程 (14)9.1.3 推动跨境电商综合服务平台建设 (14)9.2 政策支持与补贴 (15)9.2.1 加大财政支持力度 (15)9.2.2 优化融资政策 (15)9.2.3 建立跨境电商物流行业人才培养体系 (15)9.3 行业规范与监管 (15)9.3.1 制定跨境电商物流行业规范 (15)9.3.2 加强行业监管 (15)9.3.3 推动行业自律 (15)第十章结论与展望 (15)10.1 研究结论 (15)10.2 研究局限 (16)第一章绪论1.1 跨境电商物流概述互联网技术的飞速发展,跨境电商逐渐成为我国外贸的重要组成部分。

种群表示和初始化函数 bs2rv: 二进制串到实值的转换Phen=bs2rv(Chrom,FieldD)FieldD=[len, lb, ub, code, scale, lbin, ubin]len是字串的长度,lb和ub是每个变量的下界和上界,lbin和ubin指明表示范围中是否包含边界,0不包括,1包括。
code(i)=1为标准的二进制编码,code(i)=0为格雷编码scale(i)=0为算术刻度,scale(i)=1为对数刻度函数 crtbp: 创建初始种群[Chrom,Lind,BaseV]=crtbp(Nind,Lind)[Chrom,Lind,BaseV]=crtbp(Nind,BaseV)[Chrom,Lind,BaseV]=crtbp(Nind,Lind,BaseV)Nind指定种群中个体的数量,Lind指定个体的长度,Basev与base是一样的,返回的是个体的各个位的进制数函数 crtrp: 创建实值原始种群Chrom=crtrp(Nind,FieldDR)适应度计算函数 ranking: 基于排序的适应度分配(此函数是从最小化方向对个体进行排序的)FitV=ranking(ObjV)FitV=ranking(ObjV, RFun)FitV=ranking(ObjV, RFun, SUBPOP)Rfun(1)线性排序标量在[1 2]间,代表的是选择压差,比如压差为2,那就限制了Objv的结果fitv在0-2之间,如果是1.5,就在0.5-1.5之间,结果的最大值与最小值加起来就是2,非线性排序在[1 length(ObjV)-2]Rfun(2)指定排序方法,0为线性排序,1为非线性排序SUBPOP指明ObjV中子种群的数量,默认为1其实我对这个函数没了解得太深刻,不过我觉得这是一种变比技术。
将原先的适应度值压缩到一定的范围,而且目标值越大,分配的适应度值越小。
例如 A=[1;2;3;4;2;3];ranking(A)= 2.0000 1.4000 0.6000 0 1.4000 0.6000,所以如果是求最大值,就得-A,求最小值就直接A就可以了,因为目标值越大分配的适应度越小,目标值越小,分配的适应度越大。
关于遗传算法得实验报告一、实验目得:ﻩ理解与掌握遗传算法得应用及意义,能用一门自己擅长得语言实现遗传算法得基本功能,在此基础上进一步理解与巩固对遗传算法得重要,以便在今后得学习与工作中能有效得运用与借鉴!需要指出得就是遗传算法并不就是能保证所得到得就就是最佳得答案但通过一定得方法可以将误差控制在一定得范围内!二、实验原理与题目:1、遗传算法就是一种基于空间搜索得算法,它通过自然选择、遗传、变异等操作以及达尔文得适者生存得理论,模拟自然进化过程来寻找所求问题得答案。
其求解过程就是个最优化得过程。
一般遗传算法得主要步骤如下:(1)随机产生一个确定长度得特征字符串组成得初始种群。
(2)对该字符串种群迭代地执行下面得步骤a与步骤b,直到满足停止准则为止:a计算种群中每个个体字符串得适应值;b应用复制、交叉与变异等遗传算子产生下一代种群。
(3)把在后代中表现得最好得个体字符串指定为遗传算法得执行结果,即为问题得一个解。
2、通过编码、设置种群、设置适应度函数、遗传操作、解码产生需要得解。
f(x)=x*sin(x)+1,x∈[0,2π],求解f(x)得最大值与最小值。
三、实验条件硬件:微型计算机。
ﻩ语言:本实验选用得为C++语言。
四、实验内容:建造针对f(x)得遗传算法程序,然后进行运行求解。
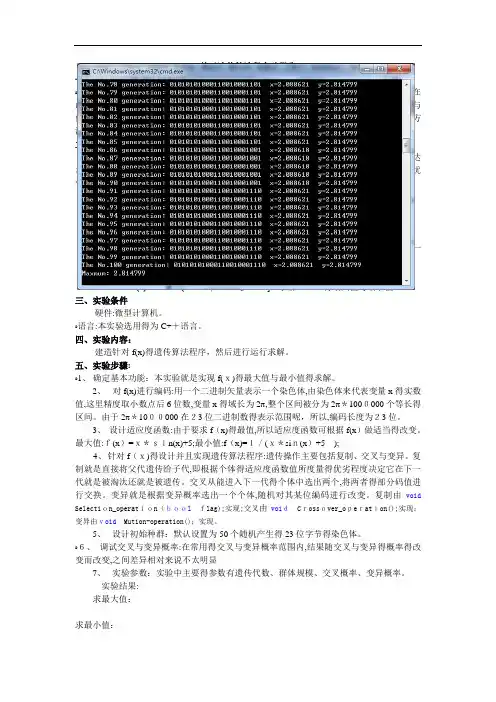
五、实验步骤:ﻩ1、确定基本功能:本实验就是实现f(x)得最大值与最小值得求解。
2、对f(x)进行编码:用一个二进制矢量表示一个染色体,由染色体来代表变量x得实数值,这里精度取小数点后6位数,变量x得域长为2π,整个区间被分为2π*1000000个等长得区间。
由于2π*1000000在23位二进制数得表示范围呢,所以,编码长度为23位。
3、设计适应度函数:由于要求f(x)得最值,所以适应度函数可根据f(x)做适当得改变。
最大值:f(x)=x*sin(x)+5;最小值:f(x)=1/(x*sin(x)+5);4、针对f(x)得设计并且实现遗传算法程序:遗传操作主要包括复制、交叉与变异。
yjl.m :简单一元函数优化实例,利用遗传算法计算下面函数的最大值f (x) =xsin( 10 二* x) 2.0,x • [-1,2]选择二进制编码,种群中个体数目为40,每个种群的长度为20,使用代沟为0.9,最大遗传代数为25len lbub scale lbin译码矩阵结构: FieldD code译码矩阵说明:len -包含在Chrom中的每个子串的长度,注意sum(len)=length(Chrom);lb、ub -行向量,分别指明每个变量使用的上界和下界;code -二进制行向量,指明子串是怎样编码的,code(i)=1为标准二进制编码,code(i)=0则为格雷编码;scale -二进制行向量,指明每个子串是否使用对数或算术刻度,scale(i)=0为算术刻度,scale(i)=1则为对数刻度;lbin、ubin -二进制行向量,指明表示范围中是否包含每个边界,选择lbin=0或ubin=0,表示从范围中去掉边界;lbin=1或ubin=1则表示范围中包含边界;注:增加第22 行:variable=bs2rv(Chrom, FieldD);否则提示第26 行plot(variable(l), Y, 'bo');中variable(I)越界yj2.m :目标函数是De Jong函数,是一个连续、凸起的单峰函数,它的M文件objfun1包含在GA工具箱软件中,De Jong函数的表达式为:n2f (x) = ' X j , 一512 乞X j E 512i d这里n是定义问题维数的一个值,本例中选取n=20,求解min f (x),程序主要变量:NIND (个体的数量):=40;MAXGEN (最大遗传代数):=500;NVAR (变量维数):=20 ;PRECI (每个变量使用多少位来表示):=20;GGAP (代沟):=0.9注:函数objfun1.m 中switch改为switch1,否则提示出错,因为switch为matlab保留字,下同!yj3.m :多元多峰函数的优化实例,Shubert函数表达式如下,求min f (x)【shubert.m 】f(x 「X 2)= 7 i cos[( i T)*X t i]*7 i cos[( i ■ 1) * x 2 - i] ,- 10 乞 X t , x 2 乞 10i丄i注:第10行各变量的上下限改为[-10;10],原来为[-3;3];第25行改为:[Y, l]=min(ObjV);原来为[Y, I]=min(ObjVSel);以此将染色体的个 体值与shubert()函数值对应起来, 原表达式不具有 shubert()函数自变量和应变量的对应关系yj4.m :收获系统最优控制,收获系统(Harvest)是一个一阶的离散方程,表达式为x(k T) = a*x(k) - u (k) , k =1, 2,…,N-s.t. x(0)为初始条件x(k)三R 为状态变量u(k 厂R ■为控制输入变量精确优化解:用遗传算法对此问题求解, x(0) =100 , > -1.1,控制步骤N=20 ,决策变量u (k) 个数 NVAR=20, u(k) •二[0,200 ]注:第 20行语句原为:Chrom=crtrp(NIND,FieldDD);改为:Chrom=crtrp(SUBPOP*NIND,FieldDD);运行提示:Warning: File: D:\MA TLAB6p5\toolbox\gatbx\CRTRP .M Line: 34 Column: 19 Variable 'nargin' has bee n previously used as a function n ame. (Type "warni ngoff MATLAB:mir_warni ng_variable_used_as_fu nctio n"tosuppress this warnin g.)yj5.m :装载系统的最优问题,装载系统是一个二维系统,表达式如下X 1 ( k ' 1) = X 2 (k)丄 丄1x 2(k -1) =2 * x 2 (k) —X t (k)^u(k)N目标函数: 1Nf (x,u) - -X t (N 1)u (k)2N k 亠N _1理论最优解: min f (x, u) = _ 1 ■_ - — k 23 6N 2 N k 二目标函数: Nf(x,u)工 J u(k)k40.4 20x( N ) - x(0)k =1, 2,…,Nmax f (x)=Nx(0)(a -1) ~N 」 a (a -1)用遗传算法对此问题求解,x(0) =[0 0],控制步骤N=20,决策变量u(k)个数NVAR=20 , u(k)三[0,10]注:增加第32-35行语句,功能为实现每隔MIGGEN=20代,以迁移率MIGR=0.2在子种群之间迁移个体,增加这几行语句之前求得目标函数最小值为-0.1538,增加这几行语句之后求得目标函数最小值为-0.1544,目标函数理论最优值为-0.1544.yj6.m :离散二次线性系统最优控制问题,其一维二阶线性系统表达式如下:x(k 1)=a*x(k) b*u(k) , k =1, 2,…,N目标函数:N2 2 2f(x,u) =q*x(n 亠1)亠二[s * x( k)亠r*u(k)]k z1参数设置:求min f (x, u)yj7.m :目标分配问题描述为:m个地空导弹火力单元对n批空袭目标进行目标分配。
遗传算法例子2篇遗传算法是一种受自然演化启发的优化算法,可以用来解决各种优化问题。
它通过模拟自然选择、遗传和突变等进化过程来不断搜索最优解。
在实际应用中,遗传算法可以被用于求解函数优化、组合优化、约束优化等问题。
下面我将为你介绍两个关于遗传算法的例子。
第一篇:基于遗传算法的旅行商问题求解旅行商问题(Traveling Salesman Problem, TSP)是计算机科学中经典的组合优化问题之一。
其目标是找到一条最短路径,使得一个旅行商可以经过所有城市,最终返回起始城市。
这个问题在实际应用中经常遇到,比如物流配送、电路布线等。
遗传算法可以用来求解旅行商问题。
首先,我们需要定义一种编码方式来表示旅行路径。
通常采用的是二进制编码,每个城市用一个二进制位来表示。
接下来,我们需要定义适应度函数,也就是评估每个个体的优劣程度,可以使用路径上所有城市之间的距离之和作为适应度值。
在遗传算法的执行过程中,首先创建一个初始种群,然后通过选择、交叉和变异等操作对种群进行迭代优化。
选择操作基于适应度值,较优秀的个体有更高的概率被选中。
交叉操作将两个个体的基因片段进行交换,以产生新的个体。
变异操作则在个体的基因中引入一些随机变动。
通过不断迭代,遗传算法能够逐渐找到一个接近最优解的解。
当然,由于旅行商问题属于NP-hard问题,在某些情况下,遗传算法可能无法找到全局最优解,但它通常能够找到质量较高的近似解。
第二篇:遗传算法在神经网络结构搜索中的应用神经网络是一种强大的机器学习模型,它具备非常大的拟合能力。
然而,在设计神经网络结构时,选择合适的网络层数、每层的神经元数量和连接方式等是一个非常复杂的问题。
传统的人工设计方法通常需要进行大量的尝试和实验。
遗传算法可以应用于神经网络结构搜索,以实现自动化的网络设计。
具体来说,遗传算法中的个体可以被看作是一种神经网络结构,通过遗传算法的进化过程可以不断优化网络结构。
在神经网络结构搜索的遗传算法中,个体的基因表示了网络的结构和参数。
遗传、蚁群算法作业1、利用遗传算法求出下面函数的极小值:z=2-exp[-(x 2+y2)], x,y [-5,+5] 解:第一步确定决策变量及其约束条件:x,y [-5,+5]第二步建立优化模型:min z ( x,y)=2-exp[-(x 2+y2)]第三步确定编码方法。
用长度为50位的二进制编码串来表示决策变量x,y。
第四步确定解码方法。
解码时将50位长的二进制编码前25位转换为对应的十进制整数代码,记为x,后25位转换后记为y。
第五步确定个体评价方法。
第六步设计遗传算子。
选择运算用比例选择算子,交叉运算使用单点交叉算子,变异运算使用基本位变异算子。
第七步确定遗传算法的运行参数。
实现代码:% n ——种群规模% ger ---- 迭代次数% pc ---- 交叉概率% pm ---- 变异概率% v ---- 初始种群(规模为n)% f ---- 目标函数值% fit ---- 适应度向量% vx ---- 最优适应度值向量% vmfit ---- 平均适应度值向量clear all;close all;clc;tic;n=30;ger=200;pc=0.65;pm=0.05;%生成初始种群v=ini t_populati on(n, 50);[N,L]=size(v);disp(spri ntf('Number of gen erati on s:%d',ger));disp(sprintf('Population size:%d',N));disp(sprintf('Crossover probability:%.3f,pc));disp(spri ntf('Mutation probability:%.3f,pm));% 待优化问题xmin=-5;xmax=5;ymin=-5;ymax=5;f='-(2-exp(-(x.A2+y.A2)))';[x,y]=meshgrid(xmin:0.1:xmax,ymin:0.1:ymax); vxp=x;vyp=y;vzp=eval(f);figure(1);mesh(vxp,vyp,-vzp);hold on;grid on;% 计算适应度,并画出初始种群图形x=decode(v(:,1:25),xmin,xmax); y=decode(v(:,26:50),ymin,ymax);fit=eval(f);plot3(x,y,-fit,'k*');title('(a) 染色体的初始位置');xlabel('x');ylabel('y');zlabel('f(x,y)');% 迭代前的初始化vmfit=[];vx=[];it=1; % 迭代计数器% 开始进化while it<=ger% Reproduction(Bi-classist Selection) vtemp=roulette(v,fit);% Crossover v=crossover(vtemp,pc);% MutationM=rand(N,L)<=pm;%M(1,:)=zeros(1,L);v=v-2.*(v.*M)+M;% Resultsx=decode(v(:,1:25),xmin,xmax); y=decode(v(:,26:50),ymin,ymax); fit=eval(f);[sol,indb]=max(fit); % v(1,:)=v(indb,:);fit_mean=mean(fit); % vx=[vx sol];vmfit=[vmfit fit_mean]; it=it+1; 每次迭代中最优目标函数值每次迭代中目标函数值的平均值end%%%%最后结果disp(sprintf('\n')); % 空一行% 显示最优解及最优值disp(sprintf('Maximumfound[x,f(x)]:[%.4f,%.4f,%.4f]',x(indb),y(indb),-sol)); % 图形显示最优结果figure(2);mesh(vxp,vyp,-vzp);hold on;grid on;plot3(x,y,-fit,'r*');title(' 染色体的最终位置');xlabel('x');ylabel('y');zlabel('f(x,y)');% 图形显示最优及平均函数值变化趋势figure(3);plot(-vx);%title(' 最优, 平均函数值变化趋势');xlabel('Generations');ylabel('f(x)');hold on;plot(-vmfit,'r');hold off;runtime=toc结果:Number of gen erati on s:200Populati on size:30Crossover probability:0.650Mutatio n probability:0.050Maximum foun d[x,f(x)]:[-0.0091,0.0099,1.0002] run time =5.2720 故最优解为x=-0.0091,y=0.0099,z=1.0002第八步结果分析图1原始函数图形图2染色体的最终位置0 刘40 60 80 100 120 U0 160 180 2C0Generations1.6171.61.5$ 1.41.31.21.11图3个体适应度的最大值和平均值2、利用蚁群算法求出下面函数的极小值:z=2-exp[-(x 2+y2)], x,y [-5,+5] 解:实现代码如下: % Ant main program clear all; close all; clc;tic;An t=100;Ger=50;xmin=-5; xmax=5; ymin=-5; ymax=5; tcl=0.05;f='-(2-exp(-(x.A2+y.A2)))'; % 待优化的目标函数[x,y]=meshgrid(xmi n:tcl:xmax,ymi n:tcl:ymax); vxp=x;vyp=y;vzp=eval(f);figure(1); mesh(vxp,vyp,-vzp); hold on;%初始化蚂蚁位置for i=1:A ntX(i,1)=(xm in+(xmax-xm in )*ra nd(1));X(i,2)=(ymi n+(ymax-ymi n)*ra nd(1));% TO---- 信息素,函数值越大,信息素浓度越大T0(i)=exp(-(X(i,1)A2+X(i,2)A2))-2;end plot3(X(:,1),X(:,2),-T0,'k*'); hold on;grid on;title(' 蚂蚁的初始分布位置');xlabel('x'); ylabel('y'); zlabel('f(x,y)'); % 开始寻优P0=0.2; % P0 P=0.8; % P lamda=1/i_ger; %全局转移选择因子信息素蒸发系数转移步长参数[T_Best(i_ger),BestIndex]=max(T0);for j_g=1:Ant % 求取全局转移概率r=T0(BestIndex)-T0(j_g);Prob(i_ger,j_g)=r/T0(BestIndex);endfor j_g_tr=1:Antif Prob(i_ger,j_g_tr)<P0 temp1=X(j_g_tr,1)+(2*rand(1)-1)*lamda;temp2=X(j_g_tr,2)+(2*rand(1)-1)*lamda;else temp1=X(j_g_tr,1)+(xmax-xmin)*(rand(1)-0.5); temp2=X(j_g_tr,2)+(ymax-ymin)*(rand(1)-0.5);endif temp1<xmin temp1=xmin;endif temp1>xmax temp1=xmax;endif temp2<ymin temp2=ymin;endif temp2>ymax temp2=ymax;endif-(2-exp(-(temp1.A2+temp2.A2)))>-(2-exp(-(X(j_g_tr,1)A2+X(j_g_tr,2)A2)))X(j_g_tr,1)=temp1;X(j_g_tr,2)=temp2;endend% 信息素更新for t_t=1:AntT0(t_t)=(1-P)*T0(t_t)-(2-exp(-(X(t_t,1)A2+X(t_t,2)A2)));end[c_iter,i_iter]=max(T0); maxpoint_iter=[X(i_iter,1),X(i_iter,2)];max_local(i_ger)=-(2-exp(-(X(i_iter,1).A2+X(i_iter,2)42)));% 将每代全局最优解存到max_global 矩阵中if i_ger>=2if max_local(i_ger)>max_global(i_ger-1) max_global(i_ger)=max_local(i_ger);elsemax_global(i_ger)=max_global(i_ger-1);endelsemax_global(i_ger)=max_local(i_ger);endend% % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % figure(2);mesh(vxp,vyp,-vzp);hold on;x=X(:,1);y=X(:,2);plot3(x,y,-eval(f),'b*');hold on;grid on;title(' 蚂蚁的最终分布位置');xlabel('x');ylabel('y');zlabel('f(x,y)');figure(3);plot(1:Ger,-max_global,'b-')hold on;title(' 最优函数值变化趋势');xlabel('iteration');ylabel('f(x)');grid on;[c_max,i_max]=max(TO);maxpoi nt=[X(i_max,1),X(i_max,2)]maxvalue=(2-exp(-(X(i_max,1).A2+X(i_max,2)42))) run time=toc结果:maxpoi nt = 0.0033 -0.0035maxvalue = 1.0000run time = 0.9855图1原始函数图形=1 ” ■图2染色体的最终位置= 14」-5 -5图3个体适应度的最大值和平均值3、利用蚁群算法求下面加权有向图中从A到G的最短路解:分析:将点1~16是否在路径分别取值为0或1,这样就形成了16位的0,1 序列,从而计算这条路径的距离。
习题二:利用遗传算法求使22=----达到最大值时的100(15)(250)Q x xx1和x2的值一、原理步骤:1、根据题意确立寻优区间,取1(0,10)x∈x∈,2(30,80)2、确立优化模型及目标函数3、确定编码方法:用长度为10位的二进制编码串来分别表示两个决策变量x1a,x2a。
编码可以表示1024个区域,可以把选定区间离散化为1024个区域。
4、确定遗传算法的运行参数,如:群体大小80、迭代次数500、交叉概率0.6、变异概率0.0015、确定解码方法:解码时需要将20位二进制编码切断,前10位和后10位分别转化为十进制整数代码,分别记为x1和x2。
6、通过解码公式,x=(max-min)*y/1023+min通过公式计算,把代码x1a和x2a转化为x1和x2。
7、进行复制运算,交叉运算,变异运算,寻找最优结果。
二、程序:clear;clc;m=80;T=500;%迭代次数pc=0.6;%交叉概率pm=0.001;%变异概率%选择初始种群for i=1:mpop(i)=floor(rand(1)*1024*1024);end%寻优开始for j=1:Tfor i=1:mx1a=floor(pop(i)/1024);x2a=(pop(i)/1024-floor(pop(i)/1024))*1024;x1=0+x1a*10/1023;x2=30+x2a*50/1023;q(i)=100-(x1-5)^2-(x2-50)^2;end%求取适应度,把坏值用好值代替[q0,flag0]=max(q);[q1,flag1]=min(q);if j==1px=pop(flag0);x1a=floor(px/1024);x2a=(px/1024-floor(px/1024))*1024;x1=0+x1a*10/1023;x2=30+x2a*50/1023;pq=100-(x1-5)^2-(x2-50)^2;elseif q0>pqpx=pop(flag0);x1a=floor(px/1024);x2a=(px/1024-floor(px/1024))*1024;x1=0+x1a*10/1023;x2=30+x2a*50/1023;pq=100-(x1-5)^2-(x2-50)^2;endend% 把这一代中最差的用所有代中最好的数代替;pop(flag1)=px;%交叉for i=1:mp=rand(1);index=floor(rand(1)*(m-1)+1);if p<pcprint=floor(rand(1)*20);xa1=floor(pop(i)/(2^print));xa2=(pop(i)/(2^print)-floor(pop(i)/(2^print)))*2^print;xb1=floor(pop(index)/(2^print));xb2=(pop(index)/(2^print)-floor(pop(index)/(2^print)))*2^print;pop(i)=xa1*2^print+xb2;endend%变异for i=1:msumpop=0;for j=0:19p=rand(1);bitj=bitand(pop(i),2^j)/(2^j);if p<pmbitj=1-bitj;endsumpop=sumpop+bitj*(2^j);endpop(i)=sumpop;endend%寻优结果为[Q,index0]=sort(q);x1a=floor(pop(index0(m))/1024);x2a=(pop(index0(m))/1024-floor(pop(index0(m))/1024))*1024; x1=0+x1a*10/1023x2=30+x2a*50/1023Qmax=Q(m)三、结论:x1 =5.0049 x2 =49.9902 Qmax =99.9999。
汽车线束装配线平衡问题优化与仿真摘要:装配线是国内外企业广泛采用的一种制造系统。
在装配线生产的模式下,装配线的平衡问题一直是装配线设计与管理过程中的一个重要问题,通过提升装配线的平衡性能够有效地提高装配线的整体效率和减少工序间在制品数量,从而降低产品的生产成本,进而为企业赢得竞争优势。
本文主要分析了汽车线束装配线平衡问题及其优化策略。
关键字:汽车;线束;平衡;优化在汽车装配线上,为了方便各零部件接线,以及保护绝缘层不易损坏,汽车上都将不同规格、不同工作用途的导线包扎成束,称为电子线束,简称线束。
汽车线束由电线、接插件和传感器以及其他器件组成。
在进行线束装配时要注意装配线平衡的问题,所谓的平衡问题就是指要在满足一定工艺条件的前提下减少工作站闲置和超载的时间。
汽车线束预装配线平衡问题实质是组合优化问题,产品设计工艺和制造过程技术决定的作业子任务之间先后关系的多种变化,使平衡问题变得更加复杂。
笔者结合实际经验,从汽车线束装配流程及特点汽车分析入手,对如何优化汽车线束装配流程及特点汽车提出了几点思考。
1汽车线束装配流程及特点汽车线束生产主要包括两部分,第一部分是压接,其中包括全自动压接和半自动压接两种形式。
第二部分是装配。
装配工艺也可以分成两种,首先介绍的是预装工艺。
在汽车线束装配前需要将其分成子线束,子线束的个数应根据实际情况而定。
而所谓的预装就是指对子线束进行装配。
在进行预装时需要考虑到各方面因素的影响,例如要考虑零件的存放问题、子线束的运输问题等。
其次,介绍的是总装工艺。
在进行总装时大多采用的是流水线作业的方式。
在进行总装前要做好准备工作,要将布线图板提前准备好,布线图板上应包括各种类型的模块。
然后再根据作业指导书进行装配。
在完成线束装配工作以后要进行质量检测,只有检测合格后才可以包装入箱。
目前,汽车线束装配线的自动化程度还比较低,在装配过程中必须要投入较大的劳动力,大部分的工作仍需要人工完成。
正是因为如此,在进行线束装配的过程中不可避免的会存在一定的波动。