第2章 统计数据的描述
- 格式:ppt
- 大小:1.04 MB
- 文档页数:11

统计学简答题参考答案第一章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.简要说明统计数据的来源。
答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
3.简要说明抽样误差和非抽样误差。
答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
4.解释描述统计和推断统计的概念?(P5)答:描述统计是用图形、表格和概括性的数字对数据进行描述的统计方法。
推断统计是根据样本信息对总体进行估计、假设检验、预测或其他推断的统计方法。
第二章统计数据的描述1描述次数分配表的编制过程。
答:分二个步骤:(1)按照统计研究的目的,将数据按分组标志进行分组。
按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。
按数量标志进行分组,可分为单项式分组与组距式分组单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。
统计分组应遵循“不重不漏”原则(2)将数据分配到各个组,统计各组的次数,编制次数分配表。
2. 一组数据的分布特征可以从哪几个方面进行测度?答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。
常用的指标有均值、中位数、众数、极差、方差、标准差、离散系数、偏态系数和峰度系数。
3.怎样理解均值在统计中的地位?答:均值是对所有数据平均后计算的一般水平的代表值,数据信息提取得最充分,具有良好的数学性质,是数据误差相互抵消后的客观事物必然性数量特征的一种反映,在统计推断中显示出优良特性,由此均值在统计中起到非常重要的基础地位。
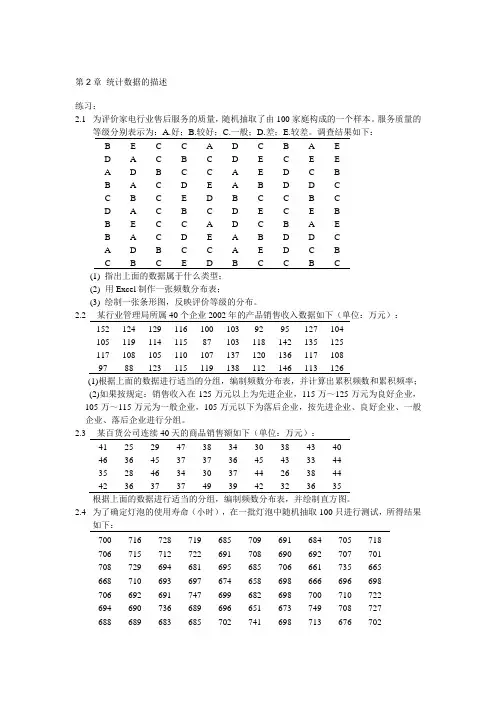
第2章统计数据的描述练习:2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
2.2某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元):152 124 129 116 100 103 92 95 127 104105 119 114 115 87 103 118 142 135 125117 108 105 110 107 137 120 136 117 10897 88 123 115 119 138 112 146 113 126(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
2.3某百货公司连续40天的商品销售额如下(单位:万元):41 25 29 47 38 34 30 38 43 4046 36 45 37 37 36 45 43 33 4435 28 46 34 30 37 44 26 38 4442 36 37 37 49 39 42 32 36 35根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。


第2章统计数据的描述练习:2.1为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下:700 716 728 719 685 709 691 684 705 718706 715 712 722 691 708 690 692 707 701708 729 694 681 695 685 706 661 735 665668 710 693 697 674 658 698 666 696 698706 692 691 747 699 682 698 700 710 722694 690 736 689 696 651 673 749 708 727688 689 683 685 702 741 698 713 676 702701 671 718 707 683 717 733 712 683 692693 697 664 681 721 720 677 679 695 691713 699 725 726 704 729 703 696 717 688(1)利用计算机对上面的数据进行排序;(2)以组距为10进行等距分组,整理成频数分布表,并绘制直方图;(3)绘制茎叶图,并与直方图作比较。
2.2某百货公司6月份各天的销售额数据如下(单位:万元):257 276 297 252 238 310 240 236 265 278271 292 261 281 301 274 267 280 291 258272 284 268 303 273 263 322 249 269 295(1)计算该百货公司日销售额的均值、中位数和四分位数;(2)计算日销售额的标准差。
2.3在某地区抽取的120家企业按利润额进行分组,结果如下:按利润额分组(万元)企业数(个)200~300 19300~400 30400~500 42500~600 18600以上11合计120计算120家企业利润额的均值和标准差。

第二章统计数据的描述一、单项选择题1.下列中,最粗略、计量层次最低的计量尺度是()A.间隔尺度B.顺序尺度C.比例尺度D.列名尺度2.将全国人口按“民族”划分为汉、白、彝、回、藏…..,这里使用的计量尺度是()A.比例尺度B.列名尺度C.间隔尺度D.顺序尺度3.某个人对某一事物的态度可以划分为非常同意、同意、保持中立、不同意、非常不同意,这里使用的计量尺度是()A.列名尺度B.间隔尺度C.顺序尺度D.比例尺度4.下列中,计量层次的最高、最精确的计量尺度是()A.比例尺度B.间隔尺度C.顺序尺度D.列名尺度5.下列调查方式中,只能调查一些最基本、最一般现象的调查方式是()A.抽样调查B.重点调查和典型调查C.统计报表D.普查6.实际中应用最为广泛的一种调查方式是()A.重点调查B.统计报表C.普查D.抽样调查7.某城市拟对占全市储蓄额4/5的几个大储蓄所进行调查,以了解全市储蓄的一般情况,则这种调查方式是()A.抽样调查B.典型调查C.重点调查D.普查8.一次性调查是指()A.只做过一次的调查B.调查一次以后不再调查C.间隔一段时间在进行一次调查D.只隔一年就进行一次的调查9.在统计分析中,对累积的次数分配用得最直接的是()A.供给曲线B.需求曲线C.洛伦茨曲线D.边际需求曲线10.专门用来衡量和反映收入分配平均程度的统计指标是()A.基尼系数B.可决系数C.相关系数D.离散系数11.一般认为,基尼系数在()之间是比较恰当的。
A.0.1—0.2B.0.2—0.4C.0.4—0.6D.0.6—0..812.一般认为,基尼系数等于()是收入分配不公平的警戒线。
A.0.2B.0.6C.0.4D.0.813.利用公式计算众数的基本假定之一是众数组的频数在该组内呈()A.正态分布B.t分布C.均匀分布D.偏态分布14.计算中位数时,假定中位数所在组的频数在该组内呈()A.左偏分布B.正态分布C.右偏分布D.均匀分布15.反映数据分布集中趋势的最主要的测度值是()A.众数B.中位数C.均值D.几何平均数16.各个变量值与均值的离差之和()A.大于0B.小于0C.等于0D.等于一个不为0的常数17.各个变量值与均值的离差平方和()A.为最大B.为最小C.为0D.为一个不为0的常数18.下列中,专门用来衡量众数代表性大小的离散程度测度值是()A.异众比率B.四分位差C.方差或标准差D.极差19.下列中,专门用来衡量中位数代表性大小的离散程度测度值是()A.方差和标准差B.内距C.异众比率D.平均差20.下列中,适用于列名数据的集中趋势测度值是( )A.众数B.中位数C.均值D.几何均值21.描述数据离散程度最简单的测度值是( )A.平均差B.方差和标准差C.极差D.四分位差22.经验法则表明,当一组数据呈对称分布时,大约有95%的数据在( )范围之内。





第2章统计数据的描述●9.某百货公司6月份各天的销售额数据如下(单位:万元):257 276 297 252 238 310 240 236 265 278271 292 261 281 301 274 267 280 291 258272 284 268 303 273 263 322 249 269 295(1)计算该百货公司日销售额的均值、中位数和四分位数;(2)计算日销售额的标准差。
解:(1)将全部30个数据输入Excel表中同列,点击列标,得到30个数据的总和为8223,于是得该百货公司日销售额的均值:(见Excel练习题2.9)x=xn∑=822330=274.1(万元)或点选单元格后,点击“自动求和”→“平均值”,在函数EVERAGE()的空格中输入“A1:A30”,回车,得到均值也为274.1。
在Excel表中将30个数据重新排序,则中位数位于30个数据的中间位置,即靠中的第15、第16两个数272和273的平均数:M e=2722732+=272.5(万元)由于中位数位于第15个数靠上半位的位置上,所以前四分位数位于第1~第15个数据的中间位置(第8位)靠上四分之一的位置上,由重新排序后的Excel表中第8位是261,第15位是272,从而:Q L=261+2732724-=261.25(万元)同理,后四分位数位于第16~第30个数据的中间位置(第23位)靠下四分之一的位置上,由重新排序后的Excel表中第23位是291,第16位是273,从而:Q U=291-2732724-=290.75(万元)。
(2)未分组数据的标准差计算公式为:s =302 1()1iix xn=--∑利用上公式代入数据计算是个较为复杂的工作。
手工计算时,须计算30个数据的离差平方,并将其求和,()再代入公式计算其结果:得s=21.1742。
(见Excel练习题2.9)我们可以利用Excel表直接计算标准差:点选数据列(A列)的最末空格,再点击菜单栏中“∑”符号右边的小三角“▼”,选择“其它函数”→选择函数“STDEV”→“确定”,在出现的函数参数窗口中的Number1右边的空栏中输入:A1:A30,→“确定”,即在A列最末空格中出现数值:21.17412,即为这30个数据的标准差。

统计学第三版答案第一章1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.简要说明统计数据的来源答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
3.简要说明抽样误差和非抽样误差答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
4.答:(1)有两个总体:A品牌所有产品、B品牌所有产品(2)变量:口味(如可用10分制表示)(3)匹配样本:从两品牌产品中各抽取1000瓶,由1000名消费者分别打分,形成匹配样本。
(4)从匹配样本的观察值中推断两品牌口味的相对好坏。
第二章、统计数据的描述思考题1描述次数分配表的编制过程答:分二个步骤:(1)按照统计研究的目的,将数据按分组标志进行分组。
按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。
按数量标志进行分组,可分为单项式分组与组距式分组单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。
统计分组应遵循“不重不漏”原则(2)将数据分配到各个组,统计各组的次数,编制次数分配表。
2.解释洛伦兹曲线及其用途答:洛伦兹曲线是20世纪初美国经济学家、统计学家洛伦兹根据意大利经济学家帕累托提出的收入分配公式绘制成的描述收入和财富分配性质的曲线。
洛伦兹曲线可以观察、分析国家和地区收入分配的平均程度。
统计学习题(抽样分布、参数估计)练习题第1章绪论(略)第2章统计数据的描述2.1某家商场为了解前来该商场购物的顾客的学历分布情况,随机抽取了100名顾客。
其学历表示为:1.初中;2.高中/中专;3•大专;4.本科及以上学历。
调查结果如下:4 2 2 2 4 3 4 4 1 42 2 4 4 43 24 2 23 1 2 14 4 1 4 2 42 3 3 2 1 3 4 3 4 43 3 1 24 2 4 3 2 4 2 3 2 2 2 1 2 2 4 4 2 1 2 3 3 3 3 3 3 4 2 3 4 3 3 1 3 2 3 2 4 3 1 3 4 3 4 2 1 4 2 2 4 2 3 3 4 1 2 1(1) 制作一张频数分布表。
(2) 绘制一张条形图,反映学历分布。
7437 77744326 2783 53250962 967 594 942 99 651984073 77 118 116 00 34 43 444 803 1 1 7 25 928 101 06 57 769 6 79 64 63 138 957 29 09 43 11474 4 0 6 86 85 85 69 121 699 599 69381 58 86 86 352 2202 46 3618 65 534 324 60 02 64 5 53852508832 66672 52 68 01 4 1 89 612 64 54 1 59 702 81 09 7 77 645 09 44 8 3511666 269 289 887 34 98 12.2在一项研究中,某调查公司为了解某品牌变 速箱是否存在缺陷,从一家该汽车的维修公司 获得该汽车变速箱失效前行驶的实际里程数 的资料数据如下:(1) 对以上数据进行适当的分组并编制频 数分布表和累积频数分布表。
(2) 用直方图来表现数据的分布特征 64 850 39334 92 2322.3为了解某电信客户对该电信公司的服务的满意度情况,某调查公司分别对两个地区的电信用户在以下五个方面对受访用户的满意情况进行了问卷调查得到的数据如下(表中数据为平均满意度打分,从1分到10分满意度依次递增):地区企业形象客户期望质量感知价值感知客户总体满意度A 8.26950 9.26241 7.91489 8.411344 7.51773 1 4 8B 7.44736 8.36842 8.97368 8.10526 7.394738 1 4 3 7试用条形图反映将两地区的满意度情况2.4下面是一个班50个学生的经济学考试成88 56 91 79 69 90 88 71 82 79 98 85 34 74 48 100 75 95 60 92 83 64 65 69 99 64 45 76 63 69 68 74 94 81 67 81 84 53 91 2484 62 81 83 69 84 29 66 75 94(1)对这50名学生的经济学考试成绩进行分组并将其整理成频数分布表,绘制直方图。
第2章 描述性统计分析实例 当进行数据分析时,如果研究者得到的数据量很小,那么就可以通过直接观察原始数据来获得所有的信息;如果得到的数据量很大,那么就必须借助各种描述指标来完成对数据的描述工作。
用少量的描述指标来概括大量的原始数据,对数据展开描述的统计分析方法被称为描述性统计分析。
常用的描述性统计分析有频数分析、描述性分析、探索分析、列联表分析。
下面我们将一一介绍这几种方法在实例中的应用。
2.1 实例1——频数分析SPSS的频数分析(Frequencies)是描述性统计分析中比较常用的方法之一。
通过频数分析,我们可以得到详细的频数表以及平均值、最大值、最小值、方差、标准差、极差、平均数标准误、偏度系数和峰度系数等重要的描述统计量,还可以通过分析得到合适的统计图。
所以进行频数分析不仅可以方便地对数据按组进行归类整理,还可以对数据的分布特征形成初步的认识。
下载资源\video\chap02\...下载资源\sample\2\正文\原始数据文件\案例2.1.sav【例2.1】表2.1给出了山东省某学校50名高二学生的身高。
试分析这50名学生的身高分布特征,计算平均值、最大值、最小值、标准差等统计量,并绘制频数表、直方图。
表2.1 山东省某学校50名高二学生的身高编号身高(cm)001 175002 163003 156004 174005 167… …048 158049 164050 16315在用SPSS 进行分析之前,我们要把数据录入到SPSS 中。
本例中有两个变量,分别是编号和身高。
我们把编号定义为字符型变量,把身高定义为数值型变量,然后录入相关数据。
录入完成后,数据如图2.1所示。
图2.1 案例2.1数据先做一下数据保存,然后开始展开分析,步骤如下:进入SPSS 24.0,打开相关数据文件,选择“分析”|“描述统计”|“频率”命令,弹出如图2.2所示的对话框。
选择进行频数分析的变量。
在“频率”对话框的左侧列表框中选择“身高”选项,单击中间的按钮使之进入“变量”列表框。