高级计量经济学练习试题精编版63137
- 格式:doc
- 大小:300.00 KB
- 文档页数:10

计量经济学题库一、单项选择题(每小题1分)1.计量经济学是下列哪门学科的分支学科(C)。
A.统计学B.数学C.经济学D.数理统计学2.计量经济学成为一门独立学科的标志是(B)。
A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来3.外生变量和滞后变量统称为(D)。
A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。
A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。
A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。
A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是()。
A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型8.经济计量模型的被解释变量一定是()。
A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是()。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值B.1991-2003年各年某地区20个乡镇企业各镇的工业产值C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是()。
A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型11.将内生变量的前期值作解释变量,这样的变量称为()。

计量经济学题库超完整版及答案Company number【1089WT-1898YT-1W8CB-9UUT-92108】计量经济学题库一、单项选择题(每小题1分)1.计量经济学是下列哪门学科的分支学科(C)。
A.统计学 B.数学 C.经济学D.数理统计学2.计量经济学成为一门独立学科的标志是(B)。
A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来3.外生变量和滞后变量统称为(D)。
A.控制变量 B.解释变量 C.被解释变量D.前定变量4.横截面数据是指(A)。
A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。
A.时期数据 B.混合数据 C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。
A.内生变量 B.外生变量 C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。
A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型D.应用计量经济模型8.经济计量模型的被解释变量一定是( C )。
A.控制变量 B.政策变量 C.内生变量D.外生变量9.下面属于横截面数据的是( D )。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值B.1991-2003年各年某地区20个乡镇企业各镇的工业产值C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是( A )。
A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型11.将内生变量的前期值作解释变量,这样的变量称为()。


计量经济学习题集(精炼版)(1)第一章绪论一、单项选择题1、变量之间的关系可以分为两大类,它们是【】A 函数关系和相关关系B 线性相关关系和非线性相关关系C 正相关关系和负相关关系D 简单相关关系和复杂相关关系2、相关关系是指【】A 变量间的依存关系B 变量间的因果关系C 变量间的函数关系D 变量间表现出来的随机数学关系3、进行相关分析时,假定相关的两个变量【】A 都是随机变量B 都不是随机变量C 一个是随机变量,一个不是随机变量D 随机或非随机都可以4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】A 总量数据B 横截面数据C平均数据 D 相对数据5、横截面数据是指【】A 同一时点上不同统计单位相同统计指标组成的数据B 同一时点上相同统计单位相同统计指标组成的数据C 同一时点上相同统计单位不同统计指标组成的数据D 同一时点上不同统计单位不同统计指标组成的数据6、下面属于截面数据的是【】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值7、同一统计指标按时间顺序记录的数据列称为【】A 横截面数据B 时间序列数据C 修匀数据D原始数据8、经济计量分析的基本步骤是【】A 设定理论模型收集样本资料估计模型参数检验模型B 设定模型估计参数检验模型应用模型C 个体设计总体设计估计模型应用模型D 确定模型导向确定变量及方程式估计模型应用模型9、计量经济模型的基本应用领域有【】A 结构分析、经济预测、政策评价B 弹性分析、乘数分析、政策模拟C 消费需求分析、生产技术分析、市场均衡分析D 季度分析、年度分析、中长期分析10、计量经济模型是指【】A 投入产出模型B 数学规划模型C 包含随机方程的经济数学模型D 模糊数学模型11、设M为货币需求量,Y为收入水平,r为利率,流动性偏好函数为:M=a+bY+cr+u,b’和c’分别为b、c的估计值,根据经济理论,有【】A b’应为正值,c’应为负值B b’应为正值,c’应为正值C b’应为负值,c’应为负值D b’应为负值,c’应为正值12、回归分析中定义【】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量13、线性模型的影响因素【】A 只能是数量因素B 只能是质量因素C 可以是数量因素,也可以是质量因素D 只能是随机因素14、下列选项中,哪一项是统计检验基础上的再检验(亦称二级检验)准则【】A. 计量经济学准则 B 经济理论准则C 统计准则D 统计准则和经济理论准则15、理论设计的工作,不包括下面哪个方面【】A 选择变量B 确定变量之间的数学关系C 收集数据D 拟定模型中待估参数的期望值16、计量经济学模型成功的三要素不包括【】A 理论B 应用C 数据D 方法17、在模型的经济意义检验中,不包括检验下面的哪一项【】A 参数估计量的符号B 参数估计量的大小C 参数估计量的相互关系D 参数估计量的显著性18、计量经济学模型用于政策评价时,不包括下面的那种方法【】A 工具变量法B 工具—目标法C 政策模拟D 最优控制方法19、在经济学的结构分析中,不包括下面那一项【】A 弹性分析B 乘数分析C 比较静力分析D 方差分析二、填空题计量经济学是_________的一个分支学科,是以揭示_________中的客观存在的_______ 为内容的分支学科。

计量经济学题库一、单项选择题(每小题1分)1.计量经济学是下列哪门学科的分支学科()。
A.统计学 B.数学 C.经济学 D.数理统计学2.计量经济学成为一门独立学科的标志是()。
A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来3.外生变量和滞后变量统称为()。
A.控制变量 B.解释变量 C.被解释变量 D.前定变量4.横截面数据是指()。
A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是()。
A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。
A.内生变量 B.外生变量 C.滞后变量 D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是()。
A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型8.经济计量模型的被解释变量一定是()。
A.控制变量 B.政策变量 C.内生变量 D.外生变量9.下面属于横截面数据的是()。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值B.1991-2003年各年某地区20个乡镇企业各镇的工业产值C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是()。
A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型11.将内生变量的前期值作解释变量,这样的变量称为()。

综合练习题1.多元线性回归模型:i ki k i i i X X X Y μββββ++⋅⋅⋅+++=22110 ),0(~2σμN i n i ,2,1 =模型设定是正确的。
如果遗漏了显著的变量k X ,构成一个新模型i i k k i i i X X X Y εββββ++⋅⋅⋅+++=--1122110试回答:⑴ 如果k X 与其它解释变量完全独立,用OLS 分别估计原模型和新模型,110,,,-k βββ 的估计结果是否变化?为什么?⑵ 如果k X 与其它解释变量线性相关,用OLS 分别估计原模型和新模型,110,,,-k βββ 的估计结果是否变化?为什么?⑶ 如果k X 是确定性变量,写出新模型中i ε的分布。
()2i i ,~σβμεk k X N +⑷ 如果k X 是随机变量,且服从正态分布,指出新模型中的i ε是否服从正态分布?为什么? ⑸ 如果k X 是随机变量,且服从正态分布,指出新模型是否存在异方差性?为什么?2. 多元线性回归模型:i ki k i i i X X X Y μββββ++⋅⋅⋅+++=22110 ),0(~2σμN i n i ,2,1 =现有n 组样本观测值,其中b Y a i <<(n i ,2,1 =),将它们看着是在以下3种不同的情况下抽取获得的:①完全随机抽取,②被解释变量被限制在大于a 的范围内随机抽取,③被解释变量被限制在大于a 小于b 的范围内随机抽取。
⑴ 用OLS 分别估计3种情况下的模型,结构参数估计量是否等价?为什么?⑵ 用ML 分别估计3种情况下的模型,结构参数估计量是否等价?为什么?⑶ 用ML 分别估计3种情况下的模型,比较3种情况的似然函数值。
3. 回答以下问题:⑴ 一位同学在综合练习中根据需求法则建立中国食品需求模型,以31个省会城市2006年数据为样本,以人均年食品消费量为被解释变量,以食品价格指数为解释变量,建立一元回归模型,估计得到食品价格指数的参数为正,于是发现“需求法则不适用于中国”。

计量经济学题库三、名词解释(每小题3分)1.经济变量 2.解释变量3.被解释变量4.内生变量 5.外生变量 6.滞后变量7.前定变量 8.控制变量9.计量经济模型10.函数关系 11.相关关系 12.最小二乘法13.高斯-马尔可夫定理 14.总变量(总离差平方和)15.回归变差(回归平方和) 16.剩余变差(残差平方和)17.估计标准误差 18.样本决定系数 19.点预测 20.拟合优度21.残差 22.显著性检验23.回归变差 24.剩余变差 25.多重决定系数26.调整后的决定系数27.偏相关系数 28.异方差性 29.格德菲尔特-匡特检验 30.怀特检验 31.戈里瑟检验和帕克检验32.序列相关性 33.虚假序列相关 34.差分法 35.广义差分法 36.自回归模型 37.广义最小二乘法38.DW 检验 39.科克伦-奥克特跌代法40.Durbin 两步法41.相关系数 42.多重共线性 43.方差膨胀因子 44.虚拟变量 45.模型设定误差 46.工具变量 47.工具变量法 48.变参数模型 49.分段线性回归模型50.分布滞后模型 51.有限分布滞后模型52.无限分布滞后模型 53.几何分布滞后模型54.联立方程模型 55.结构式模型 56.简化式模型 57.结构式参数 58.简化式参数 59.识别 60.不可识别 61.识别的阶条件 62.识别的秩条件63.间接最小二乘法四、简答题(每小题5分)1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。
2.计量经济模型有哪些应用?3.简述建立与应用计量经济模型的主要步骤。
4.对计量经济模型的检验应从几个方面入手?5.计量经济学应用的数据是怎样进行分类的?6.在计量经济模型中,为什么会存在随机误差项?7.古典线性回归模型的基本假定是什么?8.总体回归模型与样本回归模型的区别与联系。
9.试述回归分析与相关分析的联系和区别。
10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质? 11.简述BLUE 的含义。
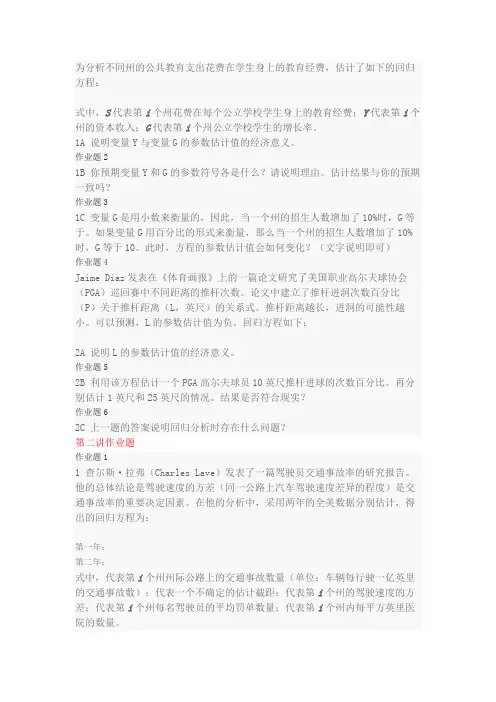
为分析不同州的公共教育支出花费在学生身上的教育经费,估计了如下的回归方程:式中,S代表第i个州花费在每个公立学校学生身上的教育经费;Y代表第i个州的资本收入;G代表第i个州公立学校学生的增长率。
1A 说明变量Y与变量G的参数估计值的经济意义。
作业题21B 你预期变量Y和G的参数符号各是什么?请说明理由。
估计结果与你的预期一致吗?作业题31C 变量G是用小数来衡量的,因此,当一个州的招生人数增加了10%时,G等于。
如果变量G用百分比的形式来衡量,那么当一个州的招生人数增加了10%时,G等于10。
此时,方程的参数估计值会如何变化?(文字说明即可)作业题4Jaime Diaz发表在《体育画报》上的一篇论文研究了美国职业高尔夫球协会(PGA)巡回赛中不同距离的推杆次数。
论文中建立了推杆进洞次数百分比(P)关于推杆距离(L,英尺)的关系式。
推杆距离越长,进洞的可能性越小。
可以预测,L的参数估计值为负。
回归方程如下:2A 说明L的参数估计值的经济意义。
作业题52B 利用该方程估计一个PGA高尔夫球员10英尺推杆进球的次数百分比。
再分别估计1英尺和25英尺的情况。
结果是否符合现实?作业题62C 上一题的答案说明回归分析时存在什么问题?第二讲作业题作业题11 查尔斯·拉弗(Charles Lave)发表了一篇驾驶员交通事故率的研究报告。
他的总体结论是驾驶速度的方差(同一公路上汽车驾驶速度差异的程度)是交通事故率的重要决定因素。
在他的分析中,采用两年的全美数据分别估计,得出的回归方程为:第一年:第二年:式中,代表第i个州州际公路上的交通事故数量(单位:车辆每行驶一亿英里的交通事故数);代表一个不确定的估计截距;代表第i个州的驾驶速度的方差;代表第i个州每名驾驶员的平均罚单数量;代表第i个州内每平方英里医院的数量。
1a.考察变量的理论依据,给出其参数符号的预期。
作业题21b.这两年的参数估计的差异是否值得重视?请说出你的理由。

高级计量经济学练习试题精编版63137work Information Technology Company.2020YEAR第一讲作业题为分析不同州的公共教育支出花费在学生身上的教育经费,估计了如下的回归方程:式中,S代表第i个州花费在每个公立学校学生身上的教育经费;Y代表第i个州的资本收入;G代表第i个州公立学校学生的增长率。
1A 说明变量Y与变量G的参数估计值的经济意义。
作业题21B 你预期变量Y和G的参数符号各是什么请说明理由。
估计结果与你的预期一致吗作业题31C 变量G是用小数来衡量的,因此,当一个州的招生人数增加了10%时,G等于0.1。
如果变量G用百分比的形式来衡量,那么当一个州的招生人数增加了10%时,G等于10。
此时,方程的参数估计值会如何变化(文字说明即可)作业题4Jaime Diaz发表在《体育画报》上的一篇论文研究了美国职业高尔夫球协会(PGA)巡回赛中不同距离的推杆次数。
论文中建立了推杆进洞次数百分比(P)关于推杆距离(L,英尺)的关系式。
推杆距离越长,进洞的可能性越小。
可以预测,L的参数估计值为负。
回归方程如下:2A 说明L的参数估计值的经济意义。
作业题52B 利用该方程估计一个PGA高尔夫球员10英尺推杆进球的次数百分比。
再分别估计1英尺和25英尺的情况。
结果是否符合现实?作业题62C 上一题的答案说明回归分析时存在什么问题?第二讲作业题作业题11 查尔斯·拉弗(Charles Lave)发表了一篇驾驶员交通事故率的研究报告。
他的总体结论是驾驶速度的方差(同一公路上汽车驾驶速度差异的程度)是交通事故率的重要决定因素。
在他的分析中,采用两年的全美数据分别估计,得出的回归方程为:第一年:第二年:式中,代表第i个州州际公路上的交通事故数量(单位:车辆每行驶一亿英里的交通事故数);代表一个不确定的估计截距;代表第i个州的驾驶速度的方差;代表第i个州每名驾驶员的平均罚单数量;代表第i个州内每平方英里医院的数量。

第一讲作业题为分析不同州的公共教育支出花费在学生身上的教育经费,估计了如下的回归方程:式中,S代表第i个州花费在每个公立学校学生身上的教育经费;Y代表第i个州的资本收入;G代表第i个州公立学校学生的增长率。
1A 说明变量Y与变量G的参数估计值的经济意义。
作业题21B 你预期变量Y和G的参数符号各是什么?请说明理由。
估计结果与你的预期一致吗?作业题31C 变量G是用小数来衡量的,因此,当一个州的招生人数增加了10%时,G等于0.1。
如果变量G用百分比的形式来衡量,那么当一个州的招生人数增加了10%时,G等于10。
此时,方程的参数估计值会如何变化?(文字说明即可)作业题4Jaime Diaz发表在《体育画报》上的一篇论文研究了美国职业高尔夫球协会(PGA)巡回赛中不同距离的推杆次数。
论文中建立了推杆进洞次数百分比(P)关于推杆距离(L,英尺)的关系式。
推杆距离越长,进洞的可能性越小。
可以预测,L的参数估计值为负。
回归方程如下:2A 说明L的参数估计值的经济意义。
作业题52B 利用该方程估计一个PGA高尔夫球员10英尺推杆进球的次数百分比。
再分别估计1英尺和25英尺的情况。
结果是否符合现实?作业题62C 上一题的答案说明回归分析时存在什么问题?第二讲作业题作业题11 查尔斯·拉弗(Charles Lave)发表了一篇驾驶员交通事故率的研究报告。
他的总体结论是驾驶速度的方差(同一公路上汽车驾驶速度差异的程度)是交通事故率的重要决定因素。
在他的分析中,采用两年的全美数据分别估计,得出的回归方程为:第一年:第二年:式中,代表第i个州州际公路上的交通事故数量(单位:车辆每行驶一亿英里的交通事故数);代表一个不确定的估计截距;代表第i个州的驾驶速度的方差;代表第i个州每名驾驶员的平均罚单数量;代表第i个州内每平方英里医院的数量。
1a.考察变量的理论依据,给出其参数符号的预期。
作业题21b.这两年的参数估计的差异是否值得重视?请说出你的理由。

计量经济学题库一、单项选择题(每小题1分)1.计量经济学是下列哪门学科的分支学科(C)。
A.统计学B.数学C.经济学D.数理统计学2.计量经济学成为一门独立学科的标志是(B)。
A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来3.外生变量和滞后变量统称为(D)。
A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。
A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。
A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。
A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。
A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型8.经济计量模型的被解释变量一定是( C )。
A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是( D )。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值B.1991-2003年各年某地区20个乡镇企业各镇的工业产值C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是( A )。
A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型11.将内生变量的前期值作解释变量,这样的变量称为( D )。
计量经济学题库一、单项选择题(每小题1分)1.计量经济学是下列哪门学科的分支学科(C)。
A.统计学B.数学C.经济学D.数理统计学2.计量经济学成为一门独立学科的标志是(B)。
A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来3.外生变量和滞后变量统称为(D)。
A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。
A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。
A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。
A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是()。
A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型8.经济计量模型的被解释变量一定是()。
A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是()。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值B.1991-2003年各年某地区20个乡镇企业各镇的工业产值C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是()。
A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型11.将内生变量的前期值作解释变量,这样的变量称为()。
计量经济学题库一、单项选择题(每小题1分)1.计量经济学是下列哪门学科的分支学科(C)。
A.统计学B.数学C.经济学D.数理统计学2.计量经济学成为一门独立学科的标志是(B)。
A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来3.外生变量和滞后变量统称为(D)。
A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。
A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。
A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。
A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是()。
A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型8.经济计量模型的被解释变量一定是()。
A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是()。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值B.1991-2003年各年某地区20个乡镇企业各镇的工业产值C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是()。
A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型11.将内生变量的前期值作解释变量,这样的变量称为()。
综合练习题1.多元线性回归模型:i ki k i i i X X X Y μββββ++⋅⋅⋅+++=22110 ),0(~2σμN i n i ,2,1 =模型设定是正确的。
如果遗漏了显著的变量k X ,构成一个新模型i i k k i i i X X X Y εββββ++⋅⋅⋅+++=--1122110试回答:⑴ 如果k X 与其它解释变量完全独立,用OLS 分别估计原模型和新模型,110,,,-k βββ 的估计结果是否变化?为什么?⑵ 如果k X 与其它解释变量线性相关,用OLS 分别估计原模型和新模型,110,,,-k βββ 的估计结果是否变化?为什么?⑶ 如果k X 是确定性变量,写出新模型中i ε的分布。
()2i i ,~σβμεk k X N +⑷ 如果k X 是随机变量,且服从正态分布,指出新模型中的i ε是否服从正态分布?为什么? ⑸ 如果k X 是随机变量,且服从正态分布,指出新模型是否存在异方差性?为什么?2. 多元线性回归模型:i ki k i i i X X X Y μββββ++⋅⋅⋅+++=22110 ),0(~2σμN i n i ,2,1 =现有n 组样本观测值,其中b Y a i <<(n i ,2,1 =),将它们看着是在以下3种不同的情况下抽取获得的:①完全随机抽取,②被解释变量被限制在大于a 的范围内随机抽取,③被解释变量被限制在大于a 小于b 的范围内随机抽取。
⑴ 用OLS 分别估计3种情况下的模型,结构参数估计量是否等价?为什么?⑵ 用ML 分别估计3种情况下的模型,结构参数估计量是否等价?为什么?⑶ 用ML 分别估计3种情况下的模型,比较3种情况的似然函数值。
3. 回答以下问题:⑴ 一位同学在综合练习中根据需求法则建立中国食品需求模型,以31个省会城市2006年数据为样本,以人均年食品消费量为被解释变量,以食品价格指数为解释变量,建立一元回归模型,估计得到食品价格指数的参数为正,于是发现“需求法则不适用于中国”。
四、简答题(每小题5分)1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。
2.计量经济模型有哪些应用?3.简述建立与应用计量经济模型的主要步骤。
4.对计量经济模型的检验应从几个方面入手?5.计量经济学应用的数据是怎样进行分类的? 6.在计量经济模型中,为什么会存在随机误差项?7.古典线性回归模型的基本假定是什么? 8.总体回归模型与样本回归模型的区别与联系。
9.试述回归分析与相关分析的联系和区别。
10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质? 11.简述BLUE 的含义。
12.对于多元线性回归模型,为什么在进行了总体显著性F 检验之后,还要对每个回归系数进行是否为0的t 检验?13.给定二元回归模型:01122t t t t y b b x b x u =+++,请叙述模型的古典假定。
14.在多元线性回归分析中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度?15.修正的决定系数2R 及其作用。
16.常见的非线性回归模型有几种情况?17.观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。
①t t t u x b b y ++=310 ②t t t u x b b y ++=log 10③ t t t u x b b y ++=log log 10 ④t t t u x b b y +=)/(1018. 观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。
①t t t u x b b y ++=log 10 ②t t t u x b b b y ++=)(210③ t t t u x b b y +=)/(10 ④t b t t u x b y +-+=)1(11019.什么是异方差性?试举例说明经济现象中的异方差性。
20.产生异方差性的原因及异方差性对模型的OLS 估计有何影响。
21.检验异方差性的方法有哪些?22.异方差性的解决方法有哪些? 23.什么是加权最小二乘法?它的基本思想是什么?24.样本分段法(即戈德菲尔特——匡特检验)检验异方差性的基本原理及其使用条件。
第一讲作业题为分析不同州的公共教育支出花费在学生身上的教育经费,估计了如下的回归方程:式中,S代表第i个州花费在每个公立学校学生身上的教育经费;Y代表第i个州的资本收入;G代表第i个州公立学校学生的增长率。
1A 说明变量Y与变量G的参数估计值的经济意义。
作业题21B 你预期变量Y和G的参数符号各是什么请说明理由。
估计结果与你的预期一致吗作业题31C 变量G是用小数来衡量的,因此,当一个州的招生人数增加了10%时,G等于。
如果变量G用百分比的形式来衡量,那么当一个州的招生人数增加了10%时,G等于10。
此时,方程的参数估计值会如何变化(文字说明即可)作业题4Jaime Diaz发表在《体育画报》上的一篇论文研究了美国职业高尔夫球协会(PGA)巡回赛中不同距离的推杆次数。
论文中建立了推杆进洞次数百分比(P)关于推杆距离(L,英尺)的关系式。
推杆距离越长,进洞的可能性越小。
可以预测,L的参数估计值为负。
回归方程如下:2A 说明L的参数估计值的经济意义。
作业题52B 利用该方程估计一个PGA高尔夫球员10英尺推杆进球的次数百分比。
再分别估计1英尺和25英尺的情况。
结果是否符合现实作业题62C 上一题的答案说明回归分析时存在什么问题第二讲作业题作业题11 查尔斯·拉弗(Charles Lave)发表了一篇驾驶员交通事故率的研究报告。
他的总体结论是驾驶速度的方差(同一公路上汽车驾驶速度差异的程度)是交通事故率的重要决定因素。
在他的分析中,采用两年的全美数据分别估计,得出的回归方程为:第一年:第二年:式中,代表第i个州州际公路上的交通事故数量(单位:车辆每行驶一亿英里的交通事故数);代表一个不确定的估计截距;代表第i个州的驾驶速度的方差;代表第i个州每名驾驶员的平均罚单数量;代表第i个州内每平方英里医院的数量。
1a.考察变量的理论依据,给出其参数符号的预期。
作业题21b.这两年的参数估计的差异是否值得重视请说出你的理由。
在什么情况下,应该关注这些差异呢作业题31c.通过比较两个方程的调整的判定系数,哪一个方程具有更高的判定系数调整的判定系数越高,回归方程越好吗为什么作业题4假定你决定建一个离你学校最近的冷冻酸奶商店的销售量模型。
店主很乐意帮助收集数据,因为她相信你们学校的学生是她的主要顾客。
经过长时间的数据收集以及无限量的冷冻酸奶供给之后,你估计得到以下回归方程:式中,代表第t个两周内冷冻酸奶的销售总量;代表t期的平均温度(单位:华氏温度);代表t期该商店冷冻酸奶价格(单位:美元);代表反映是否在学校报纸发布广告的虚拟变量(1=店主在学校报纸上做了广告);代表反映是否为学校学期时间的虚拟变量(1=t期是学校学期时间,即9月初到12月初、1月初到5月底)。
2a.为什么要假定“无限量的冷冻酸奶供给”(提示:考虑模型是否满足经典假设)作业题52b.说明变量和变量的参数估计值的经济含义。
作业题62c.你和店主对变量C的参数符号都很惊讶。
你能解释为什么吗第三讲作业题作业题1假想现在要估计一个关于房价的模型,来推断面朝海滩的环境对房屋价值的影响。
由于一系列理论和数据的可获得性等方面的原因,所以,经过一番研究,决定使用地皮的面积而不是房屋本身的面积作为其中一个变量。
分析结果如下(括号内的数值为标准误):式中,代表第i幢房子的价格(单位:1000万美元);代表第i幢房子所占地皮面积(单位:1000万平方米);代表第i幢房子的已建年限;代表第i幢房子里的房间数目;代表虚拟变量,若第i幢房子有壁炉则为1,否则为0;代表虚拟变量,若第i幢房子朝向海滩则为1,否则为0。
自由度单侧:10%5%%24251a. 对变量LOT、BED的参数建立适当的假设,并在5%的显着性水平下进行检验。
作业题21b.壁炉可能增加房屋的价值,但你的一个朋友说壁炉太脏不利于保持室内整洁,使你不能确定它的参数符号。
请建立适当的假设,并在5%的显着性水平下进行检验。
作业题31c. 回归结果是否出现与预期不符的情形(提示:考虑参数的显着性)作业题41d. 请写出关于方程总体显着性的F检验的原假设和备择假设。
作业题5为研究医生建议病人减少饮酒对个人饮酒量的作用,建立回归模型,选取500个观察值作为样本,估计结果如下(括号中的数值为标准误):式中,DRINKS代表第i个人过去两周的饮酒量;ADVICE代表虚拟变量,医生建议第i个人减少饮酒则为1,否则为0;EDUC代表第i个人受教育的年限;DIVSEP代表虚拟变量,第i 个人离婚或者分居则为1,否则为0;UNEMP代表虚拟变量,第i个人失业则为1,否则为0。
自由度单侧:10%5%%1202a. 变量DIVSEP和UNEMP的参数按常理来说应为正。
建立变量DIVSEP和UNEMP的参数的适当假设,并在5%的显着性水平下进行检验(提示:使用自由度为120下的t统计量临界值)。
作业题62b.对变量EDUC的参数建立以0为中心的双侧假设,在1%显着性水平下进行检验。
为何这个参数适合采用双侧检验作业题72c. 大多数医生希望经过他们的劝说,病人能够减少饮酒量,这也是经过劝说之后病人们通常会做的(假定方程中其他因素是固定的)。
建立适当的假设,并在10%的显着性水平下进行检验。
作业题82d. 若变量ADVICE的参数符号不符合预期,是否应该改变你的预期为什么第四讲作业题作业题11.假设你已经被提升为“Amish”公司速溶麦片粥的产品经理,你的首项任务是决定下一年度是否要提价。
(速溶麦片粥是一种用热水冲泡之后就可以作为谷类早餐的很好选择,比普通麦片冲泡时间短。
)为了保持你作为Amish Oats公司计量经济学家的声誉,你决定建立关于销售价格对销售量影响的模型,并且估计了如下假设方程(括号内的数值为标准误):式中,OAT代表第t年Amish公司速溶麦片粥在美国的销售量;PR代表第t年Amish公司速溶麦片粥在美国的销售价格;PRCOMP代表第t年作为竞争品的速溶燕麦粥在美国的价格;ADS代表第t年Amish公司速溶麦片粥的广告投入;YD代表第t年美国的可支配收入。
自由度单侧:5%%241a.建立PR 的斜率参数的适当假设,并在5%的显着性水平下进行检验。
作业题21b. 这个方程是否存在计量经济学问题是否能看出有变量被遗漏的迹象有没有迹象表明该方程有不相干变量作业题31c.如果可以给方程中加入一个变量,你建议加入什么变量作业题4什么样的汽车加速最快大多数人都会回答,高功率的、轻型的、流线型的汽车加速最快。
为检验这种说法是否正确,利用2009年模型车数据估计了如下方程:式中,TIME 代表第i辆车的速度从0加速到每小时60英里所需要的时间(单位:秒);TOP代表虚拟变量,如果第i辆车是手动挡则为1,否则为0;WEIGHT代表第i辆车的重量(单位:磅);HP代表第i辆车的马力。
2a. 假设你的邻居是物理学专业的,他告诉你马力可以表示为:。
其中,M表示质量,D表示距离,A表示加速度。
那么,你认为方程存在怎样的计量经济学问题作业题52b.你决定将TIME和HP之间的函数形式改为反函数形式。
新方程的回归结果如下:你认为哪一个方程更恰当为什么作业题62c. 既然这两个方程选用的是两种不同的函数形式,那么,它们的调整的判定系数可以用来比较吗为什么第五讲作业题作业题1你受雇于学生辅导办公室,帮助减少调皮学生对宿舍的破坏。
你要做的第一步就是建立一个截面模型,该模型把上学期每个宿舍的破坏损失作为宿舍成员特征的函数(括号中的数值为标准误):式中,D代表上学期第i个宿舍的破坏损失(单位:美元);F代表在第i个宿舍中大一新生的入住百分比;S代表第i个宿舍的学生人数;A代表上学期第i个宿舍向学生辅导办公室报告的涉及酗酒事件的次数。
自由度单侧:5%%2930a. 针对变量S的参数做出适当假设,并在5%的显着性水平下进行检验。
作业题2b. 该方程存在什么问题(从遗漏变量、不相干变量或多重共线性中选择)为什么作业题3c. 假定你现在得知,变量S和A之间的简单相关系数为,这会改变你在b中的答案吗如果改变的话,怎样改变的作业题4d. 参数估计值的符号与预期不一致,这可能是由多重共线性引起的吗为什么第六讲作业题第一讲回归分析概述测试题问题1判断题(1分)计量经济学可用于描述商品需求曲线,即需求量与价格的关系。
问题2判断题(1分)计量经济学只能做定量研究,不能做定性研究,如个人的职业选择。
问题3判断题(1分)回归分析考察的是解释变量与被解释变量之间的函数关系。
问题4判断题(1分)回归方程中,被解释变量等于其估计值与随机误差项之和。
问题5判断题(1分)残差指的是被解释变量的真实值与估计值之差。
问题6判断题(1分)数据不准确可能导致回归分析的结论存在偏误。
问题7单选(2分)回归分析中关于解释变量X和被解释变量Y的说法正确的是:问题8单选(2分)以下模型属于线性回归模型的是:问题9单选(2分)在回归方程中,G代表性别虚拟变量,男性则为1,否则为0。
若G的定义改变为女性为1,否则为0,则回归方程应为:问题10多选(3分)以下关于计量经济学用途的说法正确的有:第二讲普通最小二乘法测试题问题1单选(2分)讨论回归结果时不用花费太多时间去分析常数项的估计值,这主要依据的假设是:A误差项总体均值为0。
(√)B所有解释变量与误差项都不相关。
C误差项与观测值互不相关。
D误差项具有同方差。
E模型设定无误。
问题2判断题(1分)最小二乘法的目标是误差项之和最小。
问题3判断题(1分)若所有解释变量对被解释变量没有影响,回归方程的判定系数一定为0。
问题4判断题(1分)若某解释变量在理论上对被解释变量没有影响,该解释变量的参数估计值一定为0.问题5多选(3分)以下关于最小二乘法的说法正确的有:A最小二乘法的目标是残差平方和最小。
(√)B所估计的对象是方程中的参数。
(√)C最小二乘法的目标是残差之和最小。
D判定系数可以为负数E判定系数越大,模型越好。
问题6单选(2分)在关于身高和体重的模型中,新增QQ号码这个变量后,以下说法错误的是:A身高的参数估计值可能发生变化。
B判定系数可能减小。
(√)C调整的判定系数可能减小。
D QQ号码的参数估计值一定为0. (√)E常数项的估计值可能发生变化。
问题7判断题(1分)若采用两组样本估计同一回归方程,参数估计值的差异体现了数据的随机性。
问题8判断题(1分)若解释变量之间存在完全多重共线性,则参数估计值无法获得。
问题9单选(2分)一元回归方程的样本回归线必然通过的点为:对对问题10判断题(1分)随机误差项的总体均值为0以及随机误差项与解释变量不相关保证了参数估计量的无偏性。
问题11判断题(1分)若随机误差项服从t分布,则OLS估计量不再具有BLUE性质。