第章Meta分析思考与练习参考答案
- 格式:doc
- 大小:82.00 KB
- 文档页数:6

《思考与练习》参考答案第1章数据库系统概述一、选择题1. B2. D二、填空题1. 有组织的、可共享的2. 文件系统、数据库系统3. 关系4. 数据库管理系统第2章关系数据库一、选择题1. C2. D二、填空题1. 投影、选择2. K1×K2、m+n第3章关系数据库规范化理论一、选择题1. B2. B二、填空题1.2. 插入异常、删除异常三、简答题1.(1)基本的FD有两个:(S#,C#)→TNAME和C#→TNAME。
R的主码为(S#,C#)。
(2)根据上述两个FD,可知(S#,C#)→TNAME是一个部分依赖,因此R不是2NF模式。
(3)把R分解成R1(S#,C#)和R2(C#,TNAME),此时R1和R2都是2NF模式。
2.(1)关系模式的主码:(图书编号,读者编号,借阅日期)(2)存在部分函数依赖,例:−p书名(图书编号,读者编号,借阅日期)−→−p读者姓名(图书编号,读者编号,借阅日期)−→(3)由于存在部分函数依赖,因此该关系模式最高满足第二范式。
(4)−p书名(图书编号,读者编号,借阅日期)−→−p作者名(图书编号,读者编号,借阅日期)−→−p出版社(图书编号,读者编号,借阅日期)−→−p读者姓名(图书编号,读者编号,借阅日期)−→−f归还日期(图书编号,读者编号,借阅日期)−→将该关系模式一分为三,得:R1(图书编号,书名,作者名,出版社)R2(读者编号,读者姓名)R3(图书编号,读者编号,借阅日期,归还日期)第4章数据库设计一、选择题1. C2.D二、填空题1. 物理结构设计2. 关系规范化、E-R图三、简答题3.(1)E-R图为:(2)商店(商店编号,商店名,地址,电话)顾客(顾客编号,姓名,性别,出生年月,家庭地址)购买(商店编号,顾客编号,消费金额)第5章SQL Server 2005 系统入门一、选择题1.B 2.C二、填空题1.Windows身份验证模式、混合模式(Windows身份验证和SQL Server身份验证)2.企业管理器三、简答题4.说明为什么需要在停止运行SQL Server 前先暂停SQL Server 服务。
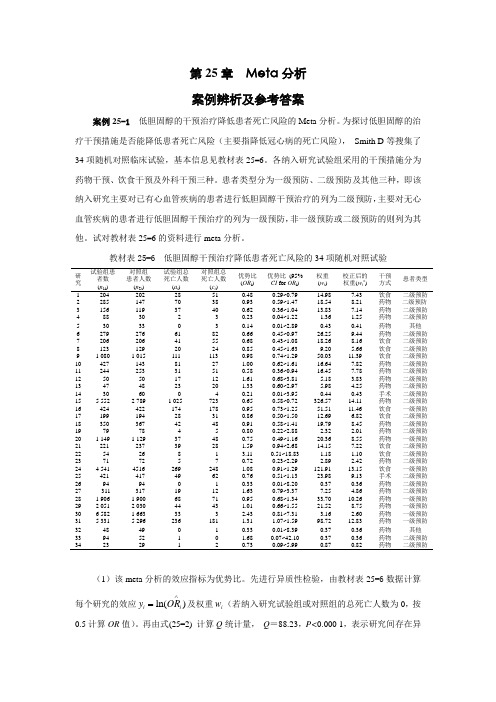
第25章 Meta 分析 案例辨析及参考答案案例25-1 低胆固醇的干预治疗降低患者死亡风险的Meta 分析。
为探讨低胆固醇的治疗干预措施是否能降低患者死亡风险(主要指降低冠心病的死亡风险), Smith D 等搜集了34项随机对照临床试验,基本信息见教材表25-6。
各纳入研究试验组采用的干预措施分为药物干预、饮食干预及外科干预三种。
患者类型分为一级预防、二级预防及其他三种,即该纳入研究主要对已有心血管疾病的患者进行低胆固醇干预治疗的列为二级预防,主要对无心血管疾病的患者进行低胆固醇干预治疗的列为一级预防,非一级预防或二级预防的则列为其他。
试对教材表25-6的资料进行meta 分析。
教材表25-6 低胆固醇干预治疗降低患者死亡风险的34项随机对照试验研究 试验组患者数 (n 1i ) 对照组 患者人数 (n 2i ) 试验组总死亡人数 (a i ) 对照组总死亡人数 (c i ) 优势比 (OR i ) 优势比 (95% CI for OR i ) 权重(w i ) 校正后的权重(w i *) 干预方式 患者类型 1 204 202 28 51 0.48 0.29~0.79 14.98 7.43 饮食 二级预防 2 285 147 70 38 0.93 0.59~1.47 18.54 8.21 药物 二级预防 3 156 119 37 40 0.62 0.36~1.04 13.83 7.14 药物 二级预防 4 88 30 2 3 0.23 0.04~1.22 1.36 1.25 药物 二级预防 5 30 33 0 3 0.14 0.01~2.89 0.43 0.41 药物 其他 6 279 276 61 82 0.66 0.45~0.97 26.25 9.44 药物 二级预防 7 206 206 41 55 0.68 0.43~1.08 18.26 8.16 饮食 二级预防 8 123 129 20 24 0.85 0.45~1.63 9.20 5.66 饮食 二级预防 9 1 080 1 015 111 113 0.98 0.74~1.29 50.03 11.39 饮食 二级预防 10 427 143 81 27 1.00 0.62~1.61 16.64 7.82 药物 二级预防 11 244 253 31 51 0.58 0.36~0.94 16.45 7.78 药物 二级预防 12 50 50 17 12 1.61 0.68~3.81 5.18 3.83 药物 二级预防 13 47 48 23 20 1.33 0.60~2.97 5.98 4.25 药物 二级预防 14 30 60 0 4 0.21 0.01~3.95 0.44 0.43 手术 二级预防 15 5 552 2 789 1 025 723 0.65 0.58~0.72 326.57 14.11 药物 二级预防 16 424 422 174 178 0.95 0.73~1.25 51.51 11.46 饮食 一级预防 17 199 194 28 31 0.86 0.50~1.50 12.69 6.82 饮食 二级预防 18 350 367 42 48 0.91 0.58~1.41 19.79 8.45 药物 二级预防 19 79 78 4 5 0.80 0.22~2.88 2.32 2.01 药物 二级预防 20 1 149 1 129 37 48 0.75 0.49~1.16 20.36 8.55 药物 一级预防 21 221 237 39 28 1.59 0.94~2.68 14.15 7.22 饮食 二级预防 22 54 26 8 1 3.11 0.51~18.83 1.18 1.10 饮食 二级预防 23 71 72 5 7 0.72 0.23~2.29 2.89 2.42 药物 二级预防 24 4 541 4516 269 248 1.08 0.91~1.29 121.91 13.15 饮食 一级预防 25 421 417 49 62 0.76 0.51~1.13 23.98 9.13 手术 二级预防 26 94 94 0 1 0.33 0.01~8.20 0.37 0.36 药物 二级预防 27 311 317 19 12 1.63 0.79~3.37 7.25 4.86 药物 二级预防 28 1 906 1 900 68 71 0.95 0.68~1.34 33.70 10.26 药物 一级预防 29 2 051 2 030 44 43 1.01 0.66~1.55 21.52 8.75 药物 一级预防 30 6 582 1 663 33 3 2.43 0.81~7.31 3.16 2.60 药物 一级预防 31 5 331 5 296 236 181 1.31 1.07~1.59 98.72 12.83 药物 一级预防 32 48 49 0 1 0.33 0.01~8.39 0.37 0.36 药物 其他 33 94 52 1 0 1.68 0.07~42.10 0.37 0.36 药物 二级预防 342329120.730.09~5.990.870.82药物二级预防(1)该meta 分析的效应指标为优势比。

第章M e t a分析思考与练习参考答案TTA standardization office【TTA 5AB- TTAK 08- TTA 2C】第25章M e t a分析思考与练习参考答案一、最佳选择题1. Meta分析中,如果异质性检验不拒绝H0,一般采用(A)进行效应合并。
A.随机效应模型 B. 固定效应模型 C.混合效应模型D. 回归模型E. 贝叶斯模型2. 关于meta分析,以下(C)说法不正确。
A.meta分析本质上是一种观察性研究,因而可能存在各种偏倚B.meta分析是用定量的方法综合同类研究结果的一种系统评价C.采用随机效应模型能使meta分析的结果更加可靠D.meta分析时,如果研究间异质性很大,应认真考察异质性的来源,并考虑这些研究的可合并性E.亚组分析能使meta分析的结果更有针对性3. 对连续型变量资料的meta分析,如果各纳入研究的测量单位不同,应采用(A)作为效应合并指标。
A.标准化均数差 B. 加权均数差 C.均数差D. 标准化P值E. 危险度差值4. 异质性检验采用的统计量是(B)。
A.F统计量 B. Q统计量 C.t统计量D.H统计量 E. Z统计量5. 关于发表偏移,以下说法(C)不正确。
A.通过漏斗图可大致判断是否存在发表偏倚B.产生发表偏倚的主要原因是作者往往只把统计学上有意义的阳性研究结果拿来写文章并投稿C.若发表偏倚对meta分析的影响较大,则需要增加很多个研究,才能使meta分析的结果被逆转D.尽量搜集未发表的阴性研究结果,可减少发表偏倚E.漏斗图的基本思想是纳入研究效应的精度随着样本含量的增加而增加二、思考题1. Meta分析的基本步骤有哪些?答:Meta分析的基本步骤包括:提出问题,制定研究计划;检索相关文献;选择符合要求的纳入文献;提取纳入文献的数据信息;纳入研究的质量评价;资料的统计学处理;敏感性分析;结果的分析和讨论。
2. Meta分析的目的和意义是什么?答:通过meta分析能增加统计功效,评价研究结果的一致性,增强结论的可靠性和客观性,通过亚组分析,得出新结论,寻找新的假说和研究思路。

精心整理第25章Meta分析思考与练习参考答案一、最佳选择题1. Meta分析中,如果异质性检验不拒绝H0,一般采用(A)进A.标准化均数差 B. 加权均数差C.均数差D. 标准化P值E. 危险度差值4. 异质性检验采用的统计量是(B)。
A.F统计量 B. Q统计量C.t统计量D.H统计量 E. Z统计量5. 关于发表偏移,以下说法(C)不正确。
A.通过漏斗图可大致判断是否存在发表偏倚B.产生发表偏倚的主要原因是作者往往只把统计学上有意义的2. Meta分析的目的和意义是什么?答:通过meta分析能增加统计功效,评价研究结果的一致性,增强结论的可靠性和客观性,通过亚组分析,得出新结论,寻找新的假说和研究思路。
3. Meta分析时,固定效应模型和随机效应模型有什么不同?如果研究间有异质性,应如何处理?答:Meta分析进行效应合并时的变异可能来源于两个部分,一是研究内变异,二是研究间变异。
采用固定效应模型只考虑研究内变异,即认为研究间的差别只是抽样引起,纳入meta分析的各个独立研究来自一个相同的总体,各个独立研究的效应是效应合并值这一总弃meta分析,只对结果进行定性分析。
4. Meta分析有哪些常见的偏倚?答:Meta分析本质上是一种观察性研究,在meta分析的各个步骤中均有可能产生偏倚。
偏倚的存在对meta分析的结果产生较大影响。
偏倚的类型主要包括文献发表偏倚、文献查找偏倚和文献筛选偏倚。
三、计算题:教材表25-9给出了20世纪70年代到80年代完成的有关阿司匹林降低心肌梗死后死亡风险的7个临床试验的研究结果。
试分别用固定效应模型Peto法及随机效应模型D-L法进行效应合并,给出效由Peto法的异质性检验公式计算统计量Q。
首先计算每个研究的期望E i、方差V i、优势比OR i以及处理组实际阳性数与期望之差O i-E i、(O i-V i)2/V i,结果见练习表25-1。
本例df=6, 2(0.1,6)=10.6>10.1,P>0.1,不拒绝H0,即认为7个研究间异质性不大,可以采用固定效应模型。

2021临床考前练习预防医学您的姓名: [填空题] *_________________________________电话: [填空题] *_________________________________班级: [填空题] *_________________________________1、Meta分析中中常见的偏倚不包括 [单选题] *A.引用偏倚B.发表偏倚C.文献库偏倚D.失访偏倚(正确答案)E.多次发表偏倚答案解析:Meta分析是对先前研究结果进行统计合并和评述的一种新方法,在文献查找和选择过程中,如果处理不当,会引入偏倚,导致合并后的结果歪曲了真实的情况。
Meta分析过程中引入的偏倚有:发表偏倚(B对)、定位偏移、引用偏倚(A对)、多次发表偏倚(E对)和有偏倚的入选标准。
其中定位偏倚又包括英语偏倚和文献库偏倚(C对)。
失访偏倚只发生于随访性质的研究中,如队列研究、实验研究、预后观察等。
失访原因主要是:有人不能坚持而退出队列(D错,为本题正确答案)。
2、Meta分析中异质性检验的目的是检验各个独立研究结果的 [单选题] *A.真实性B.同质性(正确答案)C.代表性D.敏感性E.可靠性答案解析:本题考查Meta分析相关考点。
异质性一般指meta分析中,纳入文献之间的存在的异质性,其目的是检查各个独立研究结果的同质性,B项正确。
A、C、D、E四项:为干扰项,排除。
故正确答案为B。
3、以强制参保为原则,参保范围涵盖城镇所有用人单位和职工的保险为 [单选题] *A.城镇职工基本医疗保险(正确答案)B.补充医疗保险C.城镇居民基本医疗保险D.社会医疗救助E.商业医疗保险答案解析:参保范围涵盖城镇所有用人单位和职工的保险为城镇职工基本医疗保险,包括企业、机关、事业单位、社会团体、民办非企业单位的职工,属于社会医疗保险范畴,由国家通过立法强制实施(A对)。
补充医疗保险是由单位、企业或特定人群,根据自己的经济承担能力,在基本医疗保险制度基础上自愿参加的各种辅助性的医疗保险,其主要解决参保人员基本医疗保险支付范围以外的医疗费用(B错)。

第25章Meta分析思考与练习参考答案一、最佳选择题1. Meta分析中,如果异质性检验不拒绝H0,一般采用(A)进行效应合并。
A.随机效应模型 B. 固定效应模型C.混合效应模型D. 回归模型E. 贝叶斯模型2. 关于meta分析,以下(C)说法不正确。
A.meta分析本质上是一种观察性研究,因而可能存在各种偏倚B.meta分析是用定量的方法综合同类研究结果的一种系统评价C.采用随机效应模型能使meta分析的结果更加可靠D.meta分析时,如果研究间异质性很大,应认真考察异质性的来源,并考虑这些研究的可合并性E.亚组分析能使meta分析的结果更有针对性3. 对连续型变量资料的meta分析,如果各纳入研究的测量单位不同,应采用(A)作为效应合并指标。
A.标准化均数差 B. 加权均数差C.均数差D. 标准化P值E. 危险度差值4. 异质性检验采用的统计量是(B)。
A.F统计量 B. Q统计量C.t统计量D.H统计量 E. Z统计量5. 关于发表偏移,以下说法(C)不正确。
A.通过漏斗图可大致判断是否存在发表偏倚B.产生发表偏倚的主要原因是作者往往只把统计学上有意义的阳性研究结果拿来写文章并投稿C.若发表偏倚对meta分析的影响较大,则需要增加很多个研究,才能使meta分析的结果被逆转D.尽量搜集未发表的阴性研究结果,可减少发表偏倚E.漏斗图的基本思想是纳入研究效应的精度随着样本含量的增加而增加二、思考题1. Meta分析的基本步骤有哪些?答:Meta分析的基本步骤包括:提出问题,制定研究计划;检索相关文献;选择符合要求的纳入文献;提取纳入文献的数据信息;纳入研究的质量评价;资料的统计学处理;敏感性分析;结果的分析和讨论。
2. Meta分析的目的和意义是什么?答:通过meta分析能增加统计功效,评价研究结果的一致性,增强结论的可靠性和客观性,通过亚组分析,得出新结论,寻找新的假说和研究思路。
3. Meta分析时,固定效应模型和随机效应模型有什么不同?如果研究间有异质性,应如何处理?答:Meta分析进行效应合并时的变异可能来源于两个部分,一是研究内变异,二是研究间变异。
Meta分析:解读森林图和漏斗图前面已经介绍过二分类资料的Meta分析,今天给大家介绍连续性资料的Meta分析实现步骤,解读森林图和漏斗图。
1数据整理对于连续性资料,效应量有均数差(MD)和标准化均数差(SMD),原始资料的数据我们需要提取试验组和对照组的均数,标准差和样本量。
数据整理成上面的形式。
02连续性资料的Meta分析在Reman上的步骤纳入研究和添加比较的过程和二分类资料的过程一样,我就不再介绍了。
接下来直接介绍添加结局指标和添加结局指标数据的步骤:(1)添加结局指标(2)添加结局指标数据按照上述步骤纳入所有的研究:将纳入的研究的数据添加到相应的位置,结果如下:(3)解读森林图图中的点代表单个研究的效应量,点的大小代表该研究的权重,即该项研究对Meta分析的贡献度;横线代表该效应值的可信区间;图中的菱形则代表合并后的结果。
图中的直线是无效线,用于判定合并效应量有无统计学意义。
若菱形与该直线相交,则代表两组的差异没有统计学意义。
从上图也能看出异质性检验结果,在Revman中,主要通过Q统计量和I2统计量进行异质性检验。
Q统计量是服从自由度为K-1的卡方分布,本质是卡方检验,属于异质性定性分析的方法,一般认为当P<0.1时,表明各研究间存在异质性。
I2值是根据Q统计量转换而得到的,一般认为,当I2≥50%时提示存在异质性。
上图的异质性检验结果为:Q检验:P=0.02(<0.1); I2=67% 说明各研究存在异质性。
注意纳入的研究较少时,Q检验法的检验效能过低,纳入的研究很多时,它的检验效能又过高。
I2值是消除了纳入的研究数目对检验效能的影响后,通过Q转换得到的,一般认为I2统计量较Q统计量敏感。
(4)解读漏斗图漏斗图是一种以视觉观察来识别是否存在发表偏倚的方法,该法以效应量为横坐标,纵坐标为标准误。
小样本所得的离散度较大,因此常处于漏斗图的底部,大样本离散度则较小,因此处于顶部。
第25章Meta分析思考与练习参考答案一、最佳选择题1、Meta分析中,如果异质性检验不拒绝H0,一般采用(A)进行效应合并。
A.随机效应模型B、固定效应模型 C.混合效应模型D、回归模型E、贝叶斯模型2、关于meta分析,以下(C)说法不正确。
A.meta分析本质上就是一种观察性研究,因而可能存在各种偏倚B.meta分析就是用定量得方法综合同类研究结果得一种系统评价C.采用随机效应模型能使meta分析得结果更加可靠D.meta分析时,如果研究间异质性很大,应认真考察异质性得来源,并考虑这些研究得可合并性E.亚组分析能使meta分析得结果更有针对性3、对连续型变量资料得meta分析,如果各纳入研究得测量单位不同,应采用( A)作为效应合并指标。
A.标准化均数差B、加权均数差 C.均数差D、标准化P值E、危险度差值4、异质性检验采用得统计量就是( B)。
A.F统计量B、Q统计量 C.t统计量D.H统计量E、Z统计量5、关于发表偏移,以下说法(C)不正确。
A.通过漏斗图可大致判断就是否存在发表偏倚B.产生发表偏倚得主要原因就是作者往往只把统计学上有意义得阳性研究结果拿来写文章并投稿C.若发表偏倚对meta分析得影响较大,则需要增加很多个研究,才能使meta分析得结果被逆转D.尽量搜集未发表得阴性研究结果,可减少发表偏倚E.漏斗图得基本思想就是纳入研究效应得精度随着样本含量得增加而增加二、思考题1、Meta分析得基本步骤有哪些?答:Meta分析得基本步骤包括:提出问题,制定研究计划;检索相关文献;选择符合要求得纳入文献;提取纳入文献得数据信息;纳入研究得质量评价;资料得统计学处理;敏感性分析;结果得分析与讨论。
2、Meta分析得目得与意义就是什么?答:通过meta分析能增加统计功效,评价研究结果得一致性,增强结论得可靠性与客观性,通过亚组分析,得出新结论,寻找新得假说与研究思路。
3、Meta分析时,固定效应模型与随机效应模型有什么不同?如果研究间有异质性,应如何处理?答:Meta分析进行效应合并时得变异可能来源于两个部分,一就是研究内变异,二就是研究间变异。
第25章Meta分析思考与练习参考答案一、最佳选择题1. Meta分析中,如果异质性检验不拒绝H0,一般采用(A)进行效应合并。
A.随机效应模型 B. 固定效应模型 C.混合效应模型D. 回归模型E. 贝叶斯模型2. 关于meta分析,以下(C)说法不正确。
A.meta分析本质上是一种观察性研究,因而可能存在各种偏倚B.meta分析是用定量的方法综合同类研究结果的一种系统评价C.采用随机效应模型能使meta分析的结果更加可靠D.meta分析时,如果研究间异质性很大,应认真考察异质性的来源,并考虑这些研究的可合并性E.亚组分析能使meta分析的结果更有针对性3. 对连续型变量资料的meta分析,如果各纳入研究的测量单位不同,应采用(A)作为效应合并指标。
A.标准化均数差 B. 加权均数差 C.均数差D. 标准化P值E. 危险度差值4. 异质性检验采用的统计量是(B)。
A.F统计量 B. Q统计量 C.t统计量D.H统计量 E. Z统计量5. 关于发表偏移,以下说法(C)不正确。
A.通过漏斗图可大致判断是否存在发表偏倚B.产生发表偏倚的主要原因是作者往往只把统计学上有意义的阳性研究结果拿来写文章并投稿C.若发表偏倚对meta分析的影响较大,则需要增加很多个研究,才能使meta分析的结果被逆转D.尽量搜集未发表的阴性研究结果,可减少发表偏倚E.漏斗图的基本思想是纳入研究效应的精度随着样本含量的增加而增加1. Meta分析的基本步骤有哪些?答:Meta分析的基本步骤包括:提出问题,制定研究计划;检索相关文献;选择符合要求的纳入文献;提取纳入文献的数据信息;纳入研究的质量评价;资料的统计学处理;敏感性分析;结果的分析和讨论。
2. Meta分析的目的和意义是什么?答:通过meta分析能增加统计功效,评价研究结果的一致性,增强结论的可靠性和客观性,通过亚组分析,得出新结论,寻找新的假说和研究思路。
3. Meta分析时,固定效应模型和随机效应模型有什么不同?如果研究间有异质性,应如何处理?答:Meta分析进行效应合并时的变异可能来源于两个部分,一是研究内变异,二是研究间变异。
第章M e t a分析思考与练习参考答案TYYGROUP system office room 【TYYUA16H-TYY-TYYYUA8Q8-第25章M e t a分析思考与练习参考答案一、最佳选择题1. Meta分析中,如果异质性检验不拒绝H0,一般采用(A)进行效应合并。
A.随机效应模型 B. 固定效应模型 C.混合效应模型D. 回归模型E. 贝叶斯模型2. 关于meta分析,以下(C)说法不正确。
A.meta分析本质上是一种观察性研究,因而可能存在各种偏倚B.meta分析是用定量的方法综合同类研究结果的一种系统评价C.采用随机效应模型能使meta分析的结果更加可靠D.meta分析时,如果研究间异质性很大,应认真考察异质性的来源,并考虑这些研究的可合并性E.亚组分析能使meta分析的结果更有针对性3. 对连续型变量资料的meta分析,如果各纳入研究的测量单位不同,应采用(A)作为效应合并指标。
A.标准化均数差 B. 加权均数差 C.均数差D. 标准化P值E. 危险度差值4. 异质性检验采用的统计量是(B)。
A.F统计量 B. Q统计量 C.t统计量D.H统计量 E. Z统计量5. 关于发表偏移,以下说法(C)不正确。
A.通过漏斗图可大致判断是否存在发表偏倚B.产生发表偏倚的主要原因是作者往往只把统计学上有意义的阳性研究结果拿来写文章并投稿C.若发表偏倚对meta分析的影响较大,则需要增加很多个研究,才能使meta分析的结果被逆转D.尽量搜集未发表的阴性研究结果,可减少发表偏倚E.漏斗图的基本思想是纳入研究效应的精度随着样本含量的增加而增加二、思考题1. Meta分析的基本步骤有哪些?答:Meta分析的基本步骤包括:提出问题,制定研究计划;检索相关文献;选择符合要求的纳入文献;提取纳入文献的数据信息;纳入研究的质量评价;资料的统计学处理;敏感性分析;结果的分析和讨论。
2. Meta分析的目的和意义是什么?答:通过meta分析能增加统计功效,评价研究结果的一致性,增强结论的可靠性和客观性,通过亚组分析,得出新结论,寻找新的假说和研究思路。
第25章Meta分析思考与练习参考答案一、最佳选择题1. Meta分析中,如果异质性检验不拒绝H0,一般采用(A)进行效应合并。
A.随机效应模型 B. 固定效应模型 C.混合效应模型D. 回归模型E. 贝叶斯模型2. 关于meta分析,以下(C)说法不正确。
A.meta分析本质上是一种观察性研究,因而可能存在各种偏倚B.meta分析是用定量的方法综合同类研究结果的一种系统评价C.采用随机效应模型能使meta分析的结果更加可靠D.meta分析时,如果研究间异质性很大,应认真考察异质性的来源,并考虑这些研究的可合并性E.亚组分析能使meta分析的结果更有针对性3. 对连续型变量资料的meta分析,如果各纳入研究的测量单位不同,应采用(A)作为效应合并指标。
A.标准化均数差 B. 加权均数差 C.均数差D. 标准化P值E. 危险度差值4. 异质性检验采用的统计量是(B)。
A.F统计量 B. Q统计量 C.t统计量D.H统计量 E. Z统计量5. 关于发表偏移,以下说法(C)不正确。
A.通过漏斗图可大致判断是否存在发表偏倚B.产生发表偏倚的主要原因是作者往往只把统计学上有意义的阳性研究结果拿来写文章并投稿C.若发表偏倚对meta分析的影响较大,则需要增加很多个研究,才能使meta分析的结果被逆转D.尽量搜集未发表的阴性研究结果,可减少发表偏倚E.漏斗图的基本思想是纳入研究效应的精度随着样本含量的增加而增加二、思考题1. Meta分析的基本步骤有哪些?答:Meta分析的基本步骤包括:提出问题,制定研究计划;检索相关文献;选择符合要求的纳入文献;提取纳入文献的数据信息;纳入研究的质量评价;资料的统计学处理;敏感性分析;结果的分析和讨论。
2. Meta分析的目的和意义是什么?答:通过meta分析能增加统计功效,评价研究结果的一致性,增强结论的可靠性和客观性,通过亚组分析,得出新结论,寻找新的假说和研究思路。
3. Meta分析时,固定效应模型和随机效应模型有什么不同?如果研究间有异质性,应如何处理?答:Meta分析进行效应合并时的变异可能来源于两个部分,一是研究内变异,二是研究间变异。
采用固定效应模型只考虑研究内变异,即认为研究间的差别只是抽样引起,纳入meta分析的各个独立研究来自一个相同的总体,各个独立研究的效应是效应合并值这一总体参数的估计值。
采用随机效应模型则同时考虑了研究内变异和研究间变异,即认为研究间的差异不仅仅是抽样引起的,纳入meta 分析的各个独立研究分别来自不同但互有关联的一些总体,每个研究有其相应的总体参数,meta分析的效应合并值是多个不同总体参数的加权平均。
Meta分析时,如果异质性检验的结果不拒绝H0,即研究间的差异没有统计学意义,可采用固定效应模型得到效应合并值。
如果拒绝H0,则认为研究间存在异质性,此时应考察异质性来源,并通过敏感性分析或亚组分析等异质性处理方法,使之达到同质后,再采用固定效应模型。
若经异质性分析和处理后,多个独立研究的结果仍然不具有同质性,可选择随机效应模型、meta回归及混合效应模型进行效应合并。
如果异质性很大,应考虑这些研究结果的可合并性,或放弃meta分析,只对结果进行定性分析。
4. Meta分析有哪些常见的偏倚?答:Meta分析本质上是一种观察性研究,在meta分析的各个步骤中均有可能产生偏倚。
偏倚的存在对meta分析的结果产生较大影响。
偏倚的类型主要包括文献发表偏倚、文献查找偏倚和文献筛选偏倚。
三、计算题:教材表25-9给出了20世纪70年代到80年代完成的有关阿司匹林降低心肌梗死后死亡风险的7个临床试验的研究结果。
试分别用固定效应模型Peto 法及随机效应模型D -L 法进行效应合并,给出效应合并值的点估计及区间估计,并比较两种方法得到的合并效应值。
教材表25-9 阿司匹林降低心肌梗死后死亡风险的7个随机临床试验资料研究 阿司匹林安慰剂死亡数 病例数 死亡数 病例数 1 49 615 67 624 2 44 758 64 771 3 102 832 126 850 4 32 317 38 309 5 85 810 52 406 6 246 2 267 219 2 257 71 5708 5871 7208 600解:(1)Peto 法 1)异质性检验H 0:7个研究来自同一总体,即效应的总体水平相同。
H 1:7个研究来自不同总体,即效应的总体水平不全相同。
由Peto 法的异质性检验公式计算统计量Q 。
首先计算每个研究的期望E i 、方差V i 、优势比OR i 以及处理组实际阳性数与期望之差O i -E i 、(O i -V i )2/V i ,结果见练习表25-1。
1.107.912)4.99(8.20)]([)(222=--=---=∑∑∑ii i i i i V E O V E O Q本例df=6,χ2(0.1,6)=10.6>10.1,P>0.1,不拒绝H 0,即认为7个研究间异质性不大,可以采用固定效应模型。
2)计算合并OR 及其95%CI 合并OR :90.0)7.9124.99exp())(exp(=-=-=∑∑ii iVE O OR 合并合并OR 的95%CI :)96.0,84.0()7.9127.91296.14.99ex p()96.1)(ex p(=±-=±-∑∑∑iii iVVE O3)合并OR 的检验H 0: OR 合并=1。
H 1:OR 合并≠1。
采用χ2检验,8.107.912)4.99()]([222=-=-=∑∑ii i VE O χdf=1,χ2(0.05,1)=3.64<10.8,P <0.05,拒绝 H 0,即阿司匹林能减少患者心肌梗死后死亡的风险。
练习表25-1 阿司匹林预防心肌梗死后死亡的7个临床试验及meta 分析(Peto 法)研究阿司匹林安慰剂 E iO i -E iV i OR i(O i -E i )2/V i死亡 病例死亡 病例1 49 61567 62457.6-8.6 26.30.720 2.82 44 75864 77153.5-9.5 25.10.681 3.63 102 832126 850 112.8-10.449.3 0.803 2.44 32 31738 309 35.4-3.4 15.50.801 0.75 85 81052 40691.3-6.327.10.798 1.56 246 2 267 219 2 257 233.0 13.0104.3 1.133 1.6 71 570 8 587 1 720 8 600 1643.8-73.8 665.1 0.8958.2合计 ... ... ... ... (99)912.7 … 20.84(2)D-L 法Peto 法进行异质性检验时,Q 检验在界值附近,为保证结论的可靠,用D-L 法进行效应合并,比较效应合并值的差异。
先求D 值。
计算OR 、ln(OR )及权重w i ,结果见练习表25-2。
77009.069.284456559.910559.910)17(0.10)()1(22=-⨯--=---=∑∑∑i i iw w w k Q D由D 值求w i *,)/1(1*i i w D w +=,结果见练习表25-2。
合并OR 及其95%CI 为880)71320()1324906133())ln((..exp ..exp w OR w exp OR *ii *i=-=-==∑∑合并)13.249/96.17132.0exp(/96.1exp(ln *±-=±∑iwOR 合并=(0.77, 0.99)比较一下固定效应模型和随机效应模型的结果:OR 合并值的点估计很接近(分别为0.90和0.88);95%CI 的宽度,随机效应模型 (0.99-0.77=0.22)大于固定效应模型(0.96-0.84=0.12)。
因此,随机效应模型的结果趋向保守,但两种方法得出的结论是一致的,即平均而言,阿司匹林能使心肌梗死的死亡风险降低10%。
练习表25-2 阿司匹林预防心肌梗死后死亡的7个临床试验及Meta 分析(D-L 法) 研究 y i =ln(OR i )w iw i 2w i *w i *y i1 -0.328 5 25.710 661.004 20.54 -6.7472 -0.384 2 24.291 590.053 19.63 -7.542 3 -0.2194 48.801 2381.538 33.04 -7.219 4 -0.219 4 15.440 238.394 13.42 -2.9445 -0.233 2 28.409 807.071 22.24 -5.186 6 0.124 9 103.985 10 812.880 51.58 -6.442 7-0.110 9663.92344 0793.75088.68-9.835合计…910.559 45 6284.690 249.13 -33.061(周旭毓)。