meta分析的统计学方法-2014.8.11
- 格式:ppt
- 大小:1.54 MB
- 文档页数:51





Meta分析在医学研究中,绝大多数的医学现象都呈一定的随机性,因此医学研究的结果都受随机抽样误差影响而有所差异。
所以对于同一研究问题的多个研究结果往往不全相同,有些研究的结论甚至相反。
因此如何从结果不一的同类研究中综合出一个较为可靠的结论是医学研究中常常需要面临的问题。
Meta分析就是研究如何综合同类研究结果的一种统计分析方法。
Meta分析就是把相同研究问题的多个研究结果视为一个多中心研究的结果,运用多中心研究的统计方法进行综合分析。
Meta统计分析可以分为确定性模型分析方法和随机模型分析方法。
较常用的确定性模型Meta分析有Mantel-Haeszel统计方法(仅适用于效应指标为OR)和General-Variance-Based统计方法。
然而所有的确定性模型统计方法都要求Meta分析中的各个研究的总体效应指标(如:两组均数的差值等)是相等的,并称为齐性的(Homogeneity),而随机模型对效应指标没有齐性要求。
因此Meta分析可以采用下列分析策略:1)如果各个研究的效应指标是齐性的,则选用确定性模型统计方法:●效应指标为OR,则采用Mantel-Haeszel统计方法●效应指标为两个均数的差值、两个率的差值、回归系数、对数RR等近似服从正态分布的效应指标,则采用General-Variacne-Based方法进行Meta统计分析。
2)如果各个研究的效应指标不满足齐性条件或者研究背景无法用确定性模型进行解释的,则采用随机模型进行Meta 统计分析。
为了使读者较容易地掌握Meta 分析方法,以下将结合STATA软件的Meta 分析操作命令,通过实例介绍Meta 分析步骤和软件操作以及相应的统计分析结果解释,然后对Meta 分析中所涉及的统计公式进行分类汇总小结。
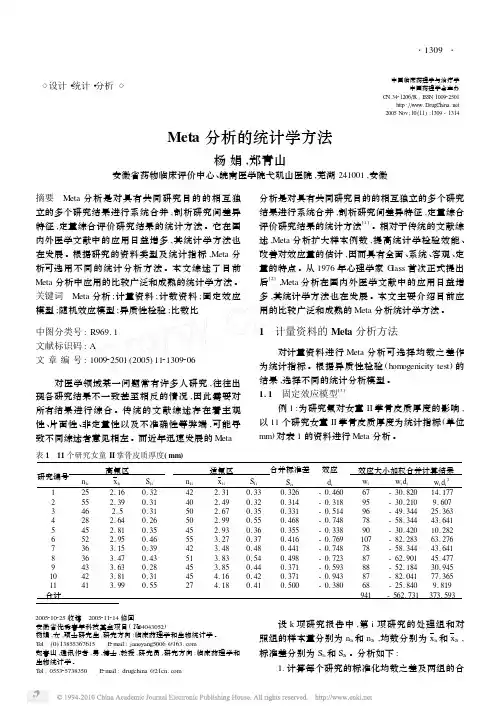
确定性模型的Meta 分析方法例1:为了研究Aspirin 预防心肌梗塞(MI)后死亡的发生,美国在1976年-1988年间进行了7个关于Aspirin 预防MI 后死亡的研究,其结果见表1,其中6次研究的结果表明Aspirin 组与安慰剂组的MI 后死亡率的差别无统计意义,只有一个研究的结果表明Aspirin 在预防MI 后死亡有效并且差别有统计意义。

M e t a分析的思想及步骤Meta分析的前身源于Fisher1920年“合并P值”的思想,1955年由Beecher 首次提出初步的概念,1976年心理学家Glass进一步按照其思想发展为“合并统计量”,称之为Meta分析;1979年英国临床流行病学家ArchieCochrane提出系统评价systematicreview,SR的概念,并发表了激素治疗早产孕妇降低新生儿死亡率随机对照试验的系统评价,对循证医学的发展起了举足轻重的作用;Meta分析国内翻译为“荟萃分析”,定义是“Thestatisticalanalysisoflargecollectionofanalysisresultsfromindivi dualstudiesforthepurposeofintegratingthefindings.”亦即“对具备特定条件的、同课题的诸多研究结果进行综合的一类统计方法;”Meta从字源来说据考证有“Metalogic:abranchofanalyticphilosophythatdealswiththecriticalexaminationoftheb asicconceptsoflogic”;“Metamathematics:thephilosophyofmathematics,especially,thelogicalsyntaxofmathematics.”其中最简洁并且一语中的的是Metascience::atheoryorscienceofscience,atheoryconcernedwiththeinvestigationanalys isordescriptionoftheoryitself.”意为一种科学中的科学或理论,一种对原理本身进行调查、分析和描述的原理;Meta分析有广义和狭义两种概念:前者指的是一个科学的临床研究活动,指全面收集所有相关研究并逐个进行严格评价和分析,再用定量合成的方法对资料进行统计学处理得出综合结论的整个过程;后者仅仅是一种单纯的定量合成的统计学方法;目前国内外文献中以广义的概念应用更为普遍,系统评价常和Meta分析交叉使用,当系统评价采用了定量合成的方法对资料进行统计学处理时即称为Meta-分;因此,系统评价可以采用Meta-分析quantitativesystematicreview 定量系统评价,也可以不采用Meta-分析non-quantitativesystematicreview,定性系统评价;参照Cochrane协作网系统评价工作手册CochraneReviewers’Handbook制定的统一标准;Meta分析的基本步骤如下:1明确简洁地提出需要解决的问题;2制定检索策略,全面广泛地收集随机对照试验;3确定纳入和排除标准,剔除不符合要求的文献;4资料选择和提取;5各试验的质量评估和特征描述;6统计学处理;a.异质性检验齐性检验;b.统计合并效应量加权合并,计算效应尺度及95%的置信区间并进行统计推断;c.图示单个试验的结果和合并后的结果;d.敏感性分析;e.通过“失安全数”的计算或采用“倒漏斗图”了解潜在的发表偏倚;7结果解释、作出结论及评价;8维护和更新资料;临床医生只需要知道Meta分析的基本思想,具体的统计学方法让统计学家研究,让统计学软件帮我们完成;ReviewManagerRevMan是Cochrane协作网提供给评价者准备和维护更新Cochrane系统评价而设计的软件,也可以说是专门为临床医生度身订做,用于完成Meta分析的软件,它不仅可以协助我们完成Meta 分析的计算过程,还可以帮助我们了解Meta分析的架构并学习系统评价的分析方法,最后把完成的系统评价制作成易于通过电子转换的文件以标准统一的格式发送到Cochrane系统评价资料库TheCochraneDatabaseofSystematicReviews,CDSR,便于电子出版和日后更新;充分利用RevMan软件对初次从事系统评价的人员获得方法学上的指导有很大的裨益;系统评价有多种类型,如病因研究、诊断性试验的评价、预后及流行病学研究等;Cochrane系统评价目前主要限于随机对照试验;非随机对照试验的系统评价方法学还处于不太完善的阶段,需要进行更多的相关研究;诊断试验的Meta 分析方法与一般的随机对照试验Meta分析不同,需要同时考虑敏感性与特异性,采用综合接受者工作特征summaryreceiveroperatingcharacteristiccurve,SROC的分析,但RevMan4.2未提供Meta分析的完整步骤,根据个人的体会,结合战友的经验总结而成,meta的精髓就是对文献的二次加工和定量合成,所以这个总结也算是对战友经验的meta分析吧;一、选题和立题一形成需要解决的临床问题:系统评价可以解决下列临床问题:1.病因学和危险因素研究;2.治疗手段的有效性研究;3.诊断方法评价;4.预后估计;5.病人费用和效益分析等;进行系统评价的最初阶段就应对要解决的问题进行精确描述,包括人群类型疾病确切分型、分期、治疗手段或暴露因素的种类、预期结果等,合理选择进行评价的指标;二指标的选择直接影响文献检索的准确性和敏感性,关系到制定检索策略;三制定纳入排除标准;二、文献检索一检索策略的制定这是关键,要求查全和查准;推荐Mesh联合freeword检索;二文献检索,获取摘要和全文国内的有维普全文VIP,CNKI,万方数据库,外文的有medline,SD,OVID等;三文献管理强烈推荐使用endnote,procite,noteexpress等文献管理软件进行检索和管理文献;查找文献全文的途径:在这里,讲一下找文献的过程,以请后来的战友们参考不包括网上有电子全文的:1.查找免费全文:1在pubmedcenter中看有无免费全文;有的时候虽然没有显示freefulltext,但是点击进去看全文链接也有提供免费全文的;我就碰到几次;2在google中搜一下;少数情况下,NCBI没有提供全文的,google有可能会找到,使用“学术搜索”;本人虽然没能在google中找到一篇所需的文献,但发现了一篇非常重要的综述,里面包含了所有我需要的文献当然不是数据,但起码提供了一个信息,所需要的文献也就这么多了,因为老外的综述也只包含了这么多的内容;这样,到底找多少文献,找什么文献,心里就更有底了;3免费医学全文杂志网站;;提供很过超过收费期的免费全文;2.图书馆查馆藏目录:包括到本校的,当然方便,使用pubmed的linkout看文献收录的数据库,就知道本校的是否有全文;其它国内高校象复旦、北大、清华等医学院的全文数据库都很全,基本上都有权限;上海的就有华东地区联目、查国内各医学院校的图书馆联目;这里给出几个:1中国高等院校医药图书馆协会的地址:,进入左侧的“现刊联目”,可以看到有“现刊联目查询”和“过刊联目查询”,当然,查询结果不可全信,里面有许多错误;本人最难找的两篇文章全部给出了错误的信息后来电话联系证实的;2再给出两个比较好的图书馆索要文献的email地址有偿服务,但可以先提供文献,后汇钱,当然做为我们,一定要讲信誉吆;一是解放军医学图书馆信息部:,电话:;3二是复旦大学医科图书馆原上医:i,联系人,周月琴,王蔚之,郑荣,电话,,需下载文献传递申请表;其他的图书馆要么要求先交开户费,比如协和500元,要么嫌麻烦,虽然网上讲过可提供有偿服务,在这里我就不一一列出了;3.请DXY战友帮忙,在馆藏文献互助站中发帖,注意格式正确,最好提供linkout 的多个数据库的全文链接,此时为帮助的人着想,就是帮助自己;自己也同时帮助别人查文献,一来互相帮助,我为人人,人人为我;二则通过帮助别人可以积分,同时学会如何发帖和下载全文,我就感觉通过帮助别人收获很大,自己积分越高,获助的速度和机会也就相应增加;现在不少免费的网络空间我常用爱存,比发邮件简便很多;所以如果你求助以后,要及时去“我的论坛”中查看帖子,有的很快就把下载链接发过来了,不要一味只看邮箱;4.实在不行,给作者发email;这里给出一个查作者email的方法,先在NCBI中查出原文献作者的所有文章,注意不要只限于第一作者,display,abstract,并尽可能显示多的篇数,100,200,500;然后在网页内查找“”,一般在前的字母会与人名有些地方相似;再根据地址来确定是否是同一作者;5.查找杂志的网址,给主编发信求取全文;这里我就不讲查找的方法了,DXY中有许多帖子;我的一篇全文就是这样得到的;6.向国外大学里的朋友求助;国外大学的图书馆一般会通过馆际互借来查找非馆藏文献,且获得率非常高;我的三篇文献是通过这一途径得到的;如果还是找不到,那就……我也没辙了,还有朋友如有其他的方法,不妨来这里交流;难度不小吧,比起做实验来如何三、对文献的质量评价和数据收集一研究的质量评价对某一试验研究的质量评价主要是评价试验结果是否有效,结果是什么该结果是否适用于当地人群;下面一系列问题可以帮助研究者进行系统的质量评价:①该研究的试验设计是否明确,包括研究人群、治疗手段和结果判定方法;②试验对象是否随机分组;③病人的随访率是否理想及每组病人是否经过统计分析;④受试对象、研究人员及其它研究参与者是否在研究过程中实行“盲法”;⑤各组病人的年龄、性别、职业等是否相似;⑥除进行研究的治疗手段不同外,其它的治疗是否一致;⑦治疗作用大小;⑧治疗效果的评价是否准确;⑨试验结果是否适用于当地的人群,种族差异是否影响试验结果;⑩是否描述了所有重要的治疗结果;治疗取得的效益是否超过了治疗的危险性和费用;系统评价者应根据上述标准进行判断,不满足标准的文献应剔除或区别对待数据合并方法不同,以保证系统评价的有效性;二、数据收集研究者应设计一个适合本研究的数据收集表格;许多电子表格制作软件如Excel、Access,和数据库系统软件如FoxPro等,可以用于表格的制作;表格中应包括分组情况、每组样本数和研究效应的测量指标;根据研究目的不同,测量指标可以是率差、比数odds、相对危险度relativerisk,包括RR和OR;各研究间作用测量指标不一致,需转化为统一指标;常用的统一指标是作用大小EffectSize,ES,ES是两比较组间作用差值除以对照组或合并组的标准差;ES无单位是其优点;三、数据分析系统评价过程中,对上述数据进行定量统计合并的流行病学方法称为Meta分析Metaanalysis;Meta意思是morecomprehensive,即更加全面综合;通过Meta分析可以达到以下目的:1.提高统计检验效能;2.评价结果一致性,解决单个研究间的矛盾;3.改进对作用效应的估计;4.解决以往单个研究未明确的新问题;统计分析的指标一、异质性检验1.检验原理:meta分析的原理首先是假定各个不同研究都是来自非同一个总体H0:各个不同样本来自不同总体,存在异质性,备择假设H1,如果p>0.1,拒绝H0,接受H1,,即来自同一总体这样就要求不同研究间的统计量应该接近总体参数真实值,所以各个不同文献研究结果是比较接近,就是要符合同质性,这时候将所有文献的效应值合并可以采用固定效应模型的有些算法,如倒方差法,mantelhaenszel法,peto法等.2.分类:异质性检验,包括三个方面:临床异质性,统计学异质性和方法学异质性,作meta分析首先应当保证临床同质性,比如研究的设计类型、实验目的、干预措施等相同,否则就要进入亚组分析,或者取消合并,在满足临床同质性的前提下非常重要,不能一味追求统计学同质性,首先考虑专业和临床同质性,我们进一步观测统计学同质性;临床异质性较大时不能行meta分析,随机效应模型也不行.只能行描述性系统综述systemicreviews,SR或分成亚组消除临床异质性.解决临床异质后再考虑统计学异质性的问题.如果各个文献研究间结果不存在异质性p>0.1,选用固定效应模型fixedmodel,这时其实选用随即效应模型的结果与固定效应模型相同;如果不符合同质性要求,即异质性检验有显着性意义p<0.1,这时候固定效应模型的算法来合并效应值就是有偏倚,合并效应值会偏离真实值.所以,异质性存在时候要求采用随机模型,主要是矫正合并效应值的算法,使得结果更加接近无偏估计,即结果更为准确.此外,这里要说明的是,采用的模型不同,和合并效应值的方法不同,都会导致异质性检验P值存在变动,这个可以从算法原理上证明,不过P值变动不会很大,一般在小数点后第三位的改变.异质性检验的Q值在固定模型中采用倒方差法和Mantel-haenszel法中也会不同;随机效应模型是不需要假定各个研究来自同一个总体为前提,本来就是对总体参数的近似无偏估计,这个与固定模型不一样必须要同质为基础,所以随机模型来作异质性检验简直是“画蛇添足”,无奈之举因此,随机模型异质性检验是否有统计学意义都是可以用,而固定模型必须要求无异质性;可以证明和实践,如果无异质性存在的时候,随机模型退化为固定,即固定模型的结果于随机模型的合并效应值是相等的具体见下图:目前,国内外对meta分析存在异质性,尤其是异质性检验P值很小的时候具体范围我不清楚,是0.05~0.1吗请版主补充,学术界有着不同的争论,很多人认为这个时候做meta分析是没有意义,相当于合并了一些来自不同总体的统计结果,也有人认为,这些异质性的存在可能是由于文献发表的时间,研究的分组,研究对象的特征等因素引起,只要采用亚组分析或meta回归分析可以将异质性进行控制或解释,还是可以进行meta分析,至少运用随机效应模型可以相对无偏的估计总体.这里要强调的是,异质性检验P值较小时候,最好能对异质性来源进行分析和说明;合理进行解释,同时进行亚组分析,相当于分层分析,消除混杂因素造成的偏倚bias;3.衡量异质性的指标一个有用的定量衡量异质性的指标是I2,I2=Q–df/Qx100%,此处的Q是卡方检验的统计值,df是其自由度Higgins2003,Higgins2002;这个I2值代表了由于异质性而不是抽样误差机会导致的效应占总效应估计值的百分率;I2值大于50%时,可以认为有明显的异质性;参考二、敏感性分析:1.敏感性分析的含义:改变纳入标准特别是尚有争议的研究、排除低质量的研究、采用不同统计方法/模型分析同一资料等,观察合并指标如OR,RR的变化,如果排除某篇文献对合并RR有明显影响,即认为该文献对合并RR敏感,反之则不敏感,如果文献之间来自同一总体,即不存在异质性,那么文献的敏感性就低,因而敏感性是衡量文献质量纳入和排除文献的证据和异质性的重要指标;敏感性分析主要针对研究特征或类型如方法学质量,通过排除某些低质量的研究、或非盲法研究探讨对总效应的影响;王吉耀第二版P76中“排除某些低质量的研究,再评价,然后前后对比,探讨剔除的试验与该类研究特征或类型对总效应的影响”;王家良第一版八年制P66、154敏感性分析是从文献的质量上来归类,亚组分析主要从文献里分组病例特征分类;敏感性分析是排除低质量研究后的meta分析,或者纳入排除研究后的meta分析;亚组分析是根据纳入研究的病人特点适当的进行分层,过多的分层和过少的分层都是不好的;例如在排除某个低质量研究后,重新估计合并效应量,并与未排除前的Meta分析结果进行比较,探讨该研究对合并效应量影响程度及结果稳健性;若排除后结果未发生大的变化,说明敏感性低,结果较为稳健可信;相反,若排除后得到差别较大甚至截然相反结论,说明敏感性较高,结果的稳健性较低,在解释结果和下结论的时候应非常慎重,提示存在与干预措施效果相关的、重要的、潜在的偏倚因素,需进一步明确争议的来源;2.衡量方法和措施其实常用的就是选择不同的统计模型或进行亚组分析,并探讨可能的偏倚来源,慎重下结论;亚组分析通常是指针对研究对象的某一特征如性别、年龄或疾病的亚型等进行的分析,以探讨这些因素对总效应的影响及影响程度;而敏感性分析主要针对研究特征或类型如方法学质量,通过排除某些低质量的研究、或非盲法的研究以探讨对总效应的影响;建议可以看参考王吉耀主编,科学出版社出版的循证医学与临床实践;敏感性分析只有纳入可能低质量文献时才作,请先保证纳入文献的质量纳入文献的质量评价方法,如果是RCT,可选用JADAD评分;如果病因学研究,我认为使用敏感性分析是评价文献质量前提是符合纳入标准的较为可行的方法;敏感性分析是分析异质性的一种间接方法;有些系统评价在进行异质性检验时发现没有异质性,这时还需不需要作敏感性分析我的看法是需要,因为我觉得异质性也是可以互相抵消的,有时候作出来没有异质性,但经过敏感性分析之后,结果就会有变化;三对入选文献进行偏倚估计发表偏倚publicationbias评估包括作漏斗图,和对漏斗图的对称性作检验;可以用stata软件进行egger检验;人是活的,软件是死的,临床是相对的,统计学是绝对的;四、总结:一结果的解释Meta-分析结果除要考虑是否有统计学意义外,还应结合专业知识判断结果有无临床意义;若结果仅有统计学意义,但合并效应量小于最小的有临床意义的差值时,结果不可取;若合并效应量有临床意义,但无统计学意义时,不能定论,需进一步收集资料;不能推荐没有Meta-分析证据支持的建议;在无肯定性结论时,应注意区别两种情况,是证据不充分而不能定论,还是有证据表明确实无效;二结果的推论Meta-分析的结果的外部真实性如何在推广应用时,应结合该Meta-分析的文献纳入/排除标准,考虑其样本的代表性如何,特别应注意研究对象特征及生物学或文化变异、研究场所、干预措施及研究对象的依从性、有无辅助治疗等方面是否与自己的具体条件一致;理想的Meta-分析应纳入当前所有相关的、高质量的同质研究,无发表性偏倚,并采用合适的模型和正确统计方法;三系统评价的完善与应用系统评价完成后,还需要在实际工作中不断完善,包括:①接受临床实践的检验和临床医师的评价;②接受成本效益评价;③关注新出现的临床研究,要及时对系统评价进行重新评价;临床医师只有掌握了系统评价的方法,才能为本专业的各种临床问题提供证据,循证医学才能够顺利发展;。



系统评价与Meta分析统计学原理概述一、Meta分析的统计学过程◆Meta‐Analysis is statistical technique for assembling the resultsof several studies in a review into a single numerical estimate.◆Meta分析是文献评价中,将若干个研究结果合并成一个单独数字估计的统计学方法。
——《The Cochrane Library》第3页的定义。
一、Meta分析的统计学过程◆主要内容:◆计算合并效应量θ◆合并效应量的检验(Z检验、可信区间)◆异质性检验(Q, I2)1、计算合并效应量多个实验效应的合并将多个独立研究的结果合并成一个汇总统计量(overalleffect, effect size)或效应尺度(effect magnitude),即用多个独立研究的某个指标的合并统计量反映其试验效应。
1、计算合并效应量◆合并统计量的两种统计模型◆固定效应模型( fixed effect model):若多个研究具有同质性(无异质性)时,可使用,可使用固定效应模型。
◆随机效应模型(random effect model ):若多个研究不具有同质性时,先对异质原因进行处理,若异质性分析与处理后仍无法解决异质性时,可使用随机效应模型。
1、计算合并效应量-分类变量◆分类变量的Meta分析可选择的统计学指标:◆RD、RR和OR◆固定效应模型(fixed effect model)◆(1) Mantel-Haenzel法◆(2) Peto 法◆(3) Inverse Variance(反推方差法)◆随机效应模型(random effects model)◆DerSimonian&Laird(D-L)法1、计算合并效应量-连续变量◆数值变量的Meta分析可选择的统计学指标:◆(1) MD法(均数差法,Mean Difference)◆(2) SMD法(标准化均数差法,Standardised Mean Difference)◆固定效应模型(fixed effect model)◆Inverse Variance(倒方差法)◆随机效应模型(random effects model)◆DerSimonian&Laird(D-L)法2、合并效应量的假设检验◆具体含义:◆用假设检验(hypothesis test )的方法检验多个独立研究的总效应量(效应尺度)是否具有统计学意义,其原理与常规的假设检验完全相同。
Meta-分析 ,又称荟萃分析荟萃分析,又称“Meta-分析”,Meta意指较晚出现的更为综合的事物,而且通常用于命名一个新的相关的并对原始学科进行评论的学问,不但包括数据结合,而且包括结果的流行病学探索和评价,以原始研究的发现取代个体作为分析实体。
荟萃分析产生的主要的理由是:对于多个单独进行的研究而言,许多观察组样本过小,难以产生任何明确意见。
根据荟萃分析所依据的基础或数据来源可以将其分为三类:文献结果荟萃分析(Meta-analysis based on literature, MAL);综合或合并数据荟萃分析(Meta-analysis based on summary data, MAS);独立研究原始数据荟萃分析(Meta-analysis based on individual patient data, MAP or IPD Meta-analysis)。
目录• 1 概述• 2 荟萃分析的分类• 3 IPD 荟萃分析的步骤• 4 荟萃分析的优劣• 5 荟萃分析的未来•荟萃分析 - 概述荟萃分析的概念最早是由Light 和Smith 于1971 年提出的。
当时针对大量发表的科学论文中,对于同样的研究却得出截然不同的结果的问题,他们提出应该在全世界范围内收集对某一疾病各种疗法的小样本、单个临床试验的结果,对其进行系统评价和统计分析,将尽可能真实的科学结论及时提供给社会和临床医师,以促进推广真正有效的治疗手段,摈弃尚无依据的无效的甚至是有害的方法。
1976 年Glass 首次将这一概念命名为Meta-analysis(荟萃分析),并定义为一种对不同研究结果进行收集、合并及统计分析的方法。
这种方法逐渐发展成为一门新兴学科--“循证医学”的主要内容和研究手段。
荟萃分析的主要目的是将以往的研究结果更为客观的综合反映出来。
研究者并不进行原始的研究,而是将研究已获得的结果进行综合分析。
荟萃分析 - 荟萃分析的分类通常概念下的文献综述是对有关文献的内容或结果进行罗列、简单的描述和初步的讨论,而荟萃分析则完全上了一个台阶。