blast中文教程--参数
- 格式:pdf
- 大小:793.03 KB
- 文档页数:58

NCBI在线BLAST使用方法与结果详解BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
下面是具体操作方法1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
没啥好说的。
6,blast结果的描述区域。

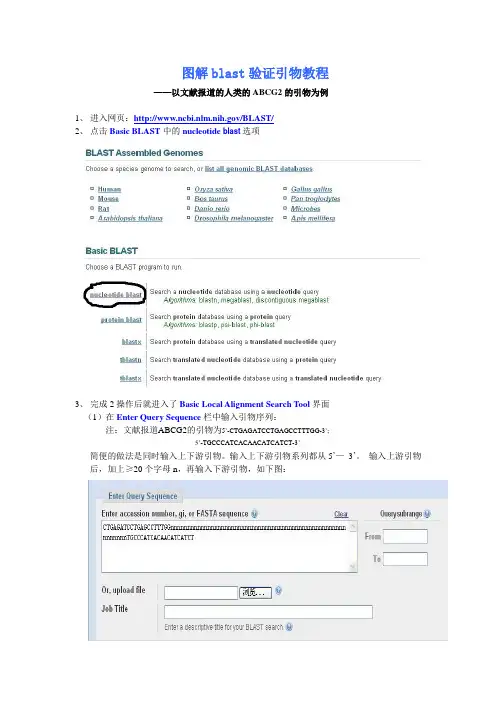
图解blast验证引物教程——以文献报道的人类的ABCG2的引物为例1、进入网页:/BLAST/2、点击Basic BLAST中的nucleotide blast选项3、完成2操作后就进入了Basic Local Alignment Search Tool界面(1)在Enter Query Sequence栏中输入引物序列:注:文献报道ABCG2的引物为5’-CTGAGATCCTGAGCCTTTGG-3’;5’-TGCCCATCACAACATCATCT-3’简便的做法是同时输入上下游引物。
输入上下游引物系列都从5’—3’。
输入上游引物后,加上≥20个字母n,再输入下游引物,如下图:(2)在Choose Search Set栏中:Database根据预操作基因的种属定了,本引物可选Human genomic + transcript或Others (nr etc.)。
本人倾向于选后者,觉得此库信息更多。
如下图:(3)在Program Selection中:选择Somewhat similar sequences (blastn)项,如下图:(4)在此界面最下面:如下图Show results in a new window项是显示界面的形式,可选可不选,在此我们选上了。
关键要点击Algorithm parameters参数设置,进入参数设置界面。
4. 参数设置:(1)在General Parameters中:Expect thresshold期望阈值须改为1000,大于1000也可以;在Word size的下拉框将数字改为7。
如下图:(2)Scoring Parameters无须修改(3)Filters and Masking中,一般来说也没有必要改5.点击最下面一栏的BLAST按钮,如图:6.点击BLAST按钮后,跳转出现如下界面:7. 等待若干秒之后,自动跳转出现显示BLAST结果的网页。
该网页用三种形式来显示blast的结果。

NCBI在线BLAST使用方法与结果详解BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
下面是具体操作方法1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
没啥好说的。
6,blast结果的描述区域。

NCBI在线BLAST使用方法与结果详解BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
下面是具体操作方法1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
没啥好说的。
6,blast结果的描述区域。

Blast:大神教你轻松搞定序列比对Blast (Basic Local Alignment Search T ool) 作为一种序列相似性比对工具,被认为是生物信息分析必须掌握的一款软件。
不管你是做两序列相似性的简单比对,还是引物特异性、基因组成环等个性化分析。
因此,许多看似高大上的基因分析,都可归类于序列间的比较,因此Blast是生信分析中基础性的工具。
今天小编要放大招了,重中之重,送给还在捶胸顿足被一堆数据吓哭的你。
本地Blast本地Blast是该款软件的本地模式,用户可在离线状态下完成目标序列的相似性比对分析。
此种模式不仅可以避免在线提交序列的繁琐和不稳定性,更重要的是能够为用户提供个性化的服务。
若用户需要指定特殊数据库或大量序列的比对,本地Blast则是最优选择。
那么,如何进行本地Blast呢?接下来小编为您献上做本地Blast的基本原则,若您能掌握以下要点,不管对快速应用本地blast还是未来拓展个性化都有很大帮助。
1掌握三个基本要素分别是数据库(database)、待比对序列(query)和目标序列(subject)。
基于这三个基本元素,本地Blast运行方式即是用户选定目标序列(subject)并将其构建成数据库,然后用待比对序列(query)在数据库中搜索,待比对序列遍历数据库中的每一条目标序列后得到最终比对结果。
本地Blast概述:本地Blast是一款集成软件,其中包括blastp、blastx和blastn等模块,通过调用不同的比对模块,blast 实现了五种可能的序列比方式:blastp:蛋白序列与蛋白库作比对,直接比对蛋白序列的同源性。
blastx:核酸序列与蛋白库作比对,将核酸序列先翻译成蛋白序列,再将其与蛋白库作比对。
blastn:核酸序列与核酸库的比对,直接比对核酸序列的同源性。
tblastn:蛋白序列对核算库的比对,现将核酸库翻译成蛋白库,再将蛋白序列与翻译后的蛋白库进行比对。

NCBI在线BLAST使⽤⽅法与结果详解NCBI在线BLAST使⽤⽅法与结果详解BLAST(Basic Local Alignment Search Tool)是⼀套在蛋⽩质数据库或DNA数据库中进⾏相似性⽐较的分析⼯具。
BLAST程序能迅速与公开数据库进⾏相似性序列⽐较。
BLAST结果中的得分是对⼀种对相似性的统计说明。
BLAST 采⽤⼀种局部的算法获得两个序列中具有相似性的序列。
Blast中常⽤的程序介绍:1、BLASTP是蛋⽩序列到蛋⽩库中的⼀种查询。
库中存在的每条已知序列将逐⼀地同每条所查序列作⼀对⼀的序列⽐对。
2、BLASTX是核酸序列到蛋⽩库中的⼀种查询。
先将核酸序列翻译成蛋⽩序列(⼀条核酸序列会被翻译成可能的六条蛋⽩),再对每⼀条作⼀对⼀的蛋⽩序列⽐对。
3、BLASTN是核酸序列到核酸库中的⼀种查询。
库中存在的每条已知序列都将同所查序列作⼀对⼀地核酸序列⽐对。
4、TBLASTN是蛋⽩序列到核酸库中的⼀种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋⽩序列,再同所查序列作蛋⽩与蛋⽩的⽐对。
5、TBLASTX是核酸序列到核酸库中的⼀种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋⽩(每条核酸序列会产⽣6条可能的蛋⽩序列),这样每次⽐对会产⽣36种⽐对阵列。
下⾯是具体操作⽅法1,进⼊在线BLAST界⾯,可以选择blast特定的物种(如⼈,⼩⿏,⽔稻等),也可以选择blast所有的核酸或蛋⽩序列。
不同的blast程序上⾯已经有了介绍。
这⾥以常⽤的核酸库作为例⼦。
2,粘贴fasta格式的序列。
选择⼀个要⽐对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
⼀般的话参数默认。
3,blast参数的设置。
注意显⽰的最⼤的结果数跟E值,E值是⽐较重要的。
筛选的标准。
最后会说明⼀下。
4,注意⼀下你输⼊的序列长度。
注意⼀下⽐对的数据库的说明。
5,blast结果的图形显⽰。

NCBI在线BLAST使用方法与成果详解之袁州冬雪创作BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中停止相似性比较的分析工具.BLAST程序能迅速与公开数据库停止相似性序列比较.BLAST成果中的得分是对一种对相似性的统计说明. BLAST 采取一种部分的算法获得两个序列中具有相似性的序列.Blast中常常使用的程序先容:1、BLASTP是蛋白序列到蛋白库中的一种查询.库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对.2、BLASTX是核酸序列到蛋白库中的一种查询.先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成能够的六条蛋白),再对每条作一对一的蛋白序列比对.3、BLASTN是核酸序列到核酸库中的一种查询.库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对.4、TBLASTN是蛋白序列到核酸库中的一种查询.与BLASTX 相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对.5、TBLASTX是核酸序列到核酸库中的一种查询.此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会发生6条能够的蛋白序列),这样每次比对会发生36种比对阵列.下面是详细操纵方法1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列.分歧的blast程序上面已经有了先容.这里以常常使用的核酸库作为例子.2,粘贴fasta格式的序列.选择一个要比对的数据库.关于数据库的说明请看NCBI在线blast数据库的简要说明.一般的话参数默许.3,blast参数的设置.注意显示的最大的成果数跟E值,E 值是比较重要的.筛选的尺度.最后会说明一下.4,注意一下你输入的序列长度.注意一下比对的数据库的说明.5,blast成果的图形显示.没啥好说的.6,blast成果的描绘区域.注意分值与E值.分值越大越靠前了,E值越小也是这样.7,blast成果的详细比对成果.注意比对到的序列长度.评价一个blast成果的尺度主要有三项,E值(Expect),一致性(Identities),缺失或拔出(Gaps).加上长度的话,就有四个尺度了.如图中显示,比对到的序列长度为1405,看Identities这一值,才匹配到1344bp,而输入的序列长度也是为1344bp(看上面的图),就说明比对到的序列要长一点.由Qurey(起始1)和Sbjct(起始35)的起始位置可知,5'端是是多了一段的.有时也要注意3'端的.附:E值(Expect):暗示随机匹配的能够性,E值越大,随机匹配的能够性也越大.E值接近零或为零时,具本上就是完全匹配了.一致性(Identities):或相似性.匹配上的碱基数占总序列长的百分数.缺失或拔出(Gaps):拔出或缺失.用"—"来暗示.。

NCBI在线BLAST使用方法与结果详解BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
下面是具体操作方法1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
没啥好说的。
6,blast结果的描述区域。

NCBI在线BLAST使用方法与结果详解BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
下面是具体操作方法1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
没啥好说的。
6,blast结果的描述区域。

N C B I在线B L A S T使用方法与结果详解BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、3、4、5、NCBI1blast 2,粘贴blast 3,blast4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
没啥好说的。
6,blast结果的描述区域。
注意分值与E值。
分值越大越靠前了,E值越小也是这样。
7,blast结果的详细比对结果。
注意比对到的序列长度。
评价一个blast结果的标准主要有三项,E值(Expect),一致性(Identities),缺失或插入(Gaps)。
加上长度的话,就有四个标准了。
如图中显示,比对到的序列长度为1405,看Identities这一值,才匹配到1344bp,而输入的序列长度也是为1344bp(看上面的图),就说明比对到的序列要长一点。
由Qurey(起始1)和Sbjct(起始35)的起始位置可知,5'端是是多了一段的。
有时也要注意3'端的。
附:来源于网络E值(Expect):表示随机匹配的可能性,E值越大,随机匹配的可能性也越大。
E值接近零或为零时,具本上就是完全匹配了。
一致性(Identities):或相似性。
匹配上的碱基数占总序列长的百分数。
缺失或插入(Gaps):插入或缺失。
用"—"来表示。
来源于网络。
NCBI在线BLAST使用方法与结果详解BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
下面是具体操作方法1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
没啥好说的。
6,blast结果的描述区域。
formatdb -i month.nt -p F -o T
-i input file 参数用于指定需要格式的数据库
-p type of file 用于指定文件类型,T 为蛋白质,F为核酸,默认为 T
-o parse options 用于指定是否解析序列ID并创建索引 T 为创建,F为不创建,默认为F。
blastall -p blastn -d month.nt -i test.txt -o out.txt –m 8 –e 10e-20
-p program name 为需要使用的程序名
blastn 为核酸序列对比搜索
blastp 为蛋白质序列对比搜索
blastx 为用被翻译的核酸序列在蛋白质数据库中搜索
tblastn 为用蛋白质序列在 [核酸序列翻译后数据库] [**1]中搜索
tblastx 为用翻译后的核酸序列在核酸序列翻译后数据库中搜索
-d database name 指定所使用的数据库名称
-i input file 待搜索的序列文件
-o output file 指定保存结果的文件
-m 8 表格形式输出
-e 10e-20 设置e value的值
即可在out.txt中得到相应的结果。
此外,之前由于在使用formatdb.exe 使没有使用 -o T 参数,导致没有生成索引文件,出现了以下错误提示:
WARNING: Test: Could not find index files for database month.nt
一个正确的解决办法,那就是在使用formatdb.exe时,不要忘了-o 参数,因为这个参数默认是不创建索引的,另外数据库的类型不要弄错了!。
BLAST (Basic Local Alignment Search Tool)NCBI采用的一套对蛋白质数据库或DNA数据库中进行相似性比较的分析工具(当然很多其它生物学数据库都提供了BLAST检索入口)。
您只需提交您的序列,通过BLAST查询就顷刻间从公开数据库中无数的的序列里找到相似序列。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
如果您想进一步了解BLAST算法,您可以参考NCBI的BLAST Course ,该页有BLAST算法的介绍。
BLAST功能是什么?BLAST对一条或多条序列(可以是任何形式的序列)在一个或多个核酸或蛋白序列库中进行比对。
BLAST还能发现具有缺口的能比对上的序列。
BLAST是基于Altschul等人在J.Mol.Biol上发表的方法(J.Mol.Biol.215:403-410(1990)),在序列数据库中对查询序列进行同源性比对工作。
从最初的BLAST发展到现在NCBI提供的BLAST2.0,已将有缺口的比对序列也考虑在内了。
BLAST可处理任何数量的序列,包括蛋白序列和核算序列;也可选择多个数据库但数据库必须是同一类型的,即要么都是蛋白数据库要么都是核酸数据库。
所查询的序列和调用的数据库则可以是任何形式的组合,既可以是核酸序列到蛋白库中作查询,也可以是蛋白序列到蛋白库中作查询,反之亦然。
GCG及EMBOSS等软件包中包含有五种BLAST:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。