八爪鱼如何通过xpath实现自定义定位元素
- 格式:docx
- 大小:798.99 KB
- 文档页数:12

淘宝店铺采集软件使用方法淘宝上有很多店铺数据,比如销量,主营产品,宝贝数量,店铺评分等等,合理的利用好这些数据,有助于找到自己的竞争对手,了解自身与竞争对手的差别,那么应该如何去采集这些店铺数据呢。
在这里为大家推荐一款采集软件八爪鱼,只需简单配置规则,就能实现自定义采集任何网站数据,包括淘宝店铺的各种数据,下面介绍八爪鱼采集软件采集淘宝店铺的使用方法。
采集网站:https:///search?app=shopsearch&q=%E6%B1%9F%E5%B0%8F%E7%99% BD&imgfile=&commend=all&ssid=s5-e&search_type=shop&sourceId=tb.index&spm=a21bo.2017 .201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306步骤1:创建淘宝店铺信息采集任务1)进入主界面,选择“自定义采集”淘宝店铺信息采集步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”淘宝店铺信息采集步骤2步骤2:创建翻页循环1)打开网页之后,找到页面最下方的“下一页”创建翻页循环,如下图淘宝店铺信息采集步骤3点击下一页,在操作提示中选择循环点击下一页,以此生成循环翻页。
注意:有时点击下一页并不会出现循环点击下一页,但若此时出现循环点击单个链接,则可以选则循环点击单个链接(或元素),其功能和循环点击下一页相同。
淘宝店铺信息采集步骤4步骤3:创建循环列表1)将鼠标移动到页面上方(蓝色表示点击后会选中的元素),选择页面某一行数据(包含的字段进可能全),如图蓝色部分,然后点击。
淘宝店铺信息采集步骤52)点击后继续选择下一行同类型的数据,如图:淘宝店铺信息采集步骤6再次点击,操作提示中出现已选中XX个元素,以下是列表。


xpath入门教程以及定位元素实例本文用来讲解xpath的入门基础,本教材是xpath入门2,建议大家从入门1教程开始学习Xpath的教程适合对八爪鱼已经有一些基础的用户来学习。
示例地址/tutorial?type=0&page=0&tag=%E8%BF%9B%E9%98%B6&version=otherXpath:是一种路径查询语言,简单的说就是利用一个路径表达式找到我们需要的数据位置。
Html:超文本标记语言,是用来描述网页的一种语言。
主要用于控制数据的显示和外观。
HTML文档也被称为网页。
Xpath专用于xml中沿着路径查找数据用的,但是八爪鱼采集器内部有一套针对Html的Xpath引擎,使得直接用Xpath就能精准的查找定位网页里面的数据。
xpath入门2-图1例如下图通过火狐的firebug、firepath查看网页源码。
查看方法参考“xpath入门1”教程xpath入门2-图2完整的HTML文件至少包括<HTML>标签、<HEAD>标签、<TITLE>标签和<BODY>标签,并且这些标签都是成对出现的,开头标签为<>,结束标签为</>,在这两个标签之间添加内容。
通过这些标签中的相关属性可以设置页面的背景色、背景图像等。
Html标签作为开始和结束的标记由尖括号包围的关键词,比如 <html>标签对中,第一个标签是开始标签,第二个标签是结束标签元素HTML的网页内容是由元素组成的,从开始标签到结束标签的所有代码。
元素的开始和结束都使用标签作为开始和结束的标记节点所有事物都是节点整个文档是一个文档节点每个 HTML 元素是元素节点HTML元素内的文本是文本节点每个 HTML 属性是属性节点注释是注释节点Html常见标签<a></a> 定义超链接,用于从一张页面链接到另一张页面<h1></h1> 文本标题标签,最大的标签。
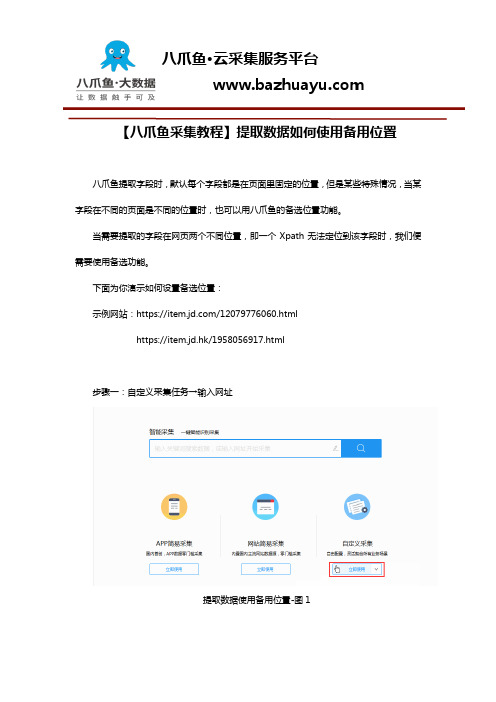
【八爪鱼采集教程】提取数据如何使用备用位置八爪鱼提取字段时,默认每个字段都是在页面里固定的位置,但是某些特殊情况,当某字段在不同的页面是不同的位置时,也可以用八爪鱼的备选位置功能。
当需要提取的字段在网页两个不同位置,即一个Xpath无法定位到该字段时,我们便需要使用备选功能。
下面为你演示如何设置备选位置:示例网站:https:///12079776060.htmlhttps://item.jd.hk/1958056917.html步骤一:自定义采集任务→输入网址提取数据使用备用位置-图1提取数据使用备用位置-图2步骤二:提取元素字段(商品名、店铺名)提取数据使用备用位置-图3步骤三:保存并启动 直接单机运行可以看到第二个网页店铺名空白,提取不到提取数据使用备用位置-图4这时我们回到流程界面,手动运行一下规则。
提取数据使用备用位置-图5提取数据使用备用位置-图6发现第一个网页的字段2可以提取到,第二个网页则为空白,提取不到。
说明两个网页店铺名的字段Xpath不一样,我们用第一个网页的Xpath提取不到第二个网页的信息。
这时我们需要用到备用位置。
步骤四:选中店铺名字段→点击自定义字段→自定义定位元素方式→设置备用位置提取数据使用备用位置-图7 提取数据使用备用位置-图8提取数据使用备用位置-图9提取数据使用备用位置-图10说明:点击需要设置备用位置的元素,选择将这个元素设为备选即可。
也可以自己通过Xpath 进行修改。
提取数据使用备用位置-图11提取数据使用备用位置-图12单机运行一次,发现可以采集到,设置备用位置成功。
提取数据使用备用位置-图13相关采集教程:淘宝评论采集新浪微博数据采集搜狗微信文章采集八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
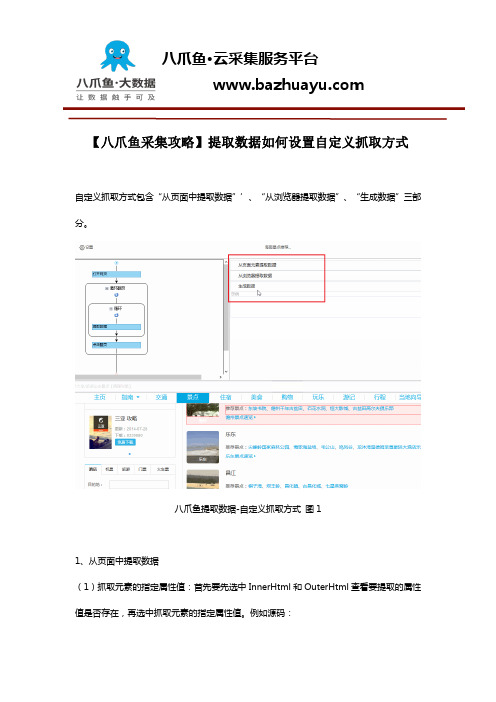
【八爪鱼采集攻略】提取数据如何设置自定义抓取方式自定义抓取方式包含“从页面中提取数据”’、“从浏览器提取数据”、“生成数据”三部分。
八爪鱼提取数据-自定义抓取方式图11、从页面中提取数据(1)抓取元素的指定属性值:首先要先选中InnerHtml和OuterHtml查看要提取的属性值是否存在,再选中抓取元素的指定属性值。
例如源码:<a id="hot-comments-tab" class="on" href="comments">热门</a> 中,id、class、href就是A标签的属性,在下拉选项中选取要提取的属性名称,即可提取到该属性的属性值,演示如下:八爪鱼提取数据-自定义抓取方式图2八爪鱼提取数据-自定义抓取方式图3(2)抓取文本:提取网页中展示的内容,可见的文字信息。
(3)抓取地址:一般用于抓取图片地址或Iframe地址,首先字段的Xpath定位到的是IMG标签或者Iframe标签,提取其中的src属性值。
(4)抓取选中项的文本:配合循环下拉框试用,提取当前选中项的文本(5)抓取这个元素的OuterHtml,InnerHtml:提取网页源码(6)抓取值:一般用于抓取输入框的文字,首先字段的Xpath定位到的是input 标签,提取其中的value值,演示如下:八爪鱼提取数据-自定义抓取方式图4八爪鱼提取数据-自定义抓取方式图5(7)抓取超链接:首先字段的Xpath定位到的是A标签,从A标签中提取href的属性值。
演示如下:八爪鱼提取数据-自定义抓取方式图6八爪鱼提取数据-自定义抓取方式 图7 2、从浏览器提取数据八爪鱼提取数据-自定义抓取方式图8(1)页面网址:同添加其他特殊字段中的抓取当前页面的网址效果(2)页面标题:同添加其他特殊字段中的抓取当前页面的标题效果(3)从页面源码里抓取:可直接用正则表达式提取网页源码里匹配到的数据3、生成数据八爪鱼提取数据-自定义抓取方式图9(1)生成固定的值:同添加其他特殊字段中的生成固定值效果,常用于发布到网站时设置发布的用户名,发布到的版块等固定字段(2)使用当前时间:同添加其他特殊字段中的使用当前时间效果,用于记录采集时间,此设置有可能会导致八爪鱼采集器去重功能检测失效相关采集教程:美团商家信息采集1688热门商品采集搜狗微信文章采集八爪鱼——70万用户选择的网页数据采集器。

如何利用八爪鱼爬虫抓取数据听说很多做运营的同学都用八爪鱼采集器去抓取网络数据,最新视频,最热新闻等,但还是有人不了解八爪鱼爬虫工具是如何使用的。
所以本教程以百度视频为例,为大家演示如何采集到页面上的视频,方便工作使用。
常见场景:1、遇到需要采集视频时,可以采集视频的地址(URL),再使用网页视频下载器下载视频。
2、当视频链接在标签中,可切换标签进行采集。
3、当视频链接在标签中,也可采集源码后进行格式化数据。
操作示例:采集要求:采集百度视频上综艺往期视频示例网址:/show/list/area-内地+order-hot+pn-1+channel-tvshow操作步骤:1、新建自定义采集,输入网址后点击保存。
注:点击打开右上角流程按钮。
2、创建循环翻页,找到采集页面中下一页按钮,点击,执行“循环点击下一页”。
在流程中的点击翻页勾选Ajax加载数据,时间设置2-3秒。
3、创建循环点击列表。
点击第一张图片,选择“选中全部”(由于标签可能不同,会导致无法选中全部,可以继续点击没被选中的图片)继续选择循环点击每个元素4、进入详情页后,点击视频标题(从火狐中可以看到视频链接在A标签中,如图所示),所以需要手动更换到相应的A标签。
手动更换为A标签:更换为A标签后,选择“选中全部”,将所有视频标题选中,此时就可以采集视频链接地址。
5、所有操作设置完毕后,点击保存。
然后进行本地采集,查看采集结果。
6、采集完成后将URL导出,使用视频URL批量下载工具将视频下载出来就完成了。
相关采集教程:公告信息抓取/tutorial/hottutorial/qita/gonggao网站源码抓取/tutorial/hottutorial/qita/qitaleixing网页抓取工具新手入门/tutorial/xsksrm八爪鱼网站抓取入门功能介绍/tutorial/xsksrm/rmgnjsajax网页数据抓取/tutorial/gnd/ajaxlabel模拟登录并识别验证码抓取数据/tutorial/gnd/dlyzmxpath抓取网页文字/tutorial/gnd/xpath八爪鱼抓取AJAX滚动页面爬虫教程/tutorial/ajgd_7网页采集提取数据教程,以自定义抓取方式为例/tutorial/zdytq_7八爪鱼——90万用户选择的网页数据采集器。
微信文章爬虫实现方法如今越来越多的优质内容发布在微信公众号中,对这些内容,有些朋友会有采集下来的需求,下面为大家介绍使用八爪鱼爬虫工具去抓取采集微信文章信息。
本文将以搜狗微信文章为例,介绍使用八爪鱼采集网页文章正文的方法。
文章正文里一般包括文本和图片两种。
本文将采集文章正文中的文本+图片URL。
将采集以下字段:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方式”功能,请大家注意)。
同时,采集文章正文中的文本+图片URL,将用到“判断条件”,“判断条件”的使用,有很多需要注意的地方。
以下两个教程,大家可先熟悉一下。
“自定义数据合并方式”详解教程:“判断条件”详解教程:采集网站:/步骤1:创建采集任务1)进入主界面,选择“自定义模式”微信文章爬虫实现方法步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”微信文章爬虫实现方法步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
网页打开后,默认显示“热门”文章。
下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”微信文章爬虫实现方法步骤32)选择“循环点击单个元素”,以创建一个翻页循环微信文章爬虫实现方法步骤4由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。
选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”微信文章爬虫实现方法步骤5注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
验证方式:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或者转圈状态。
拼多多采集软件使用方法2018年你绝对被拼多多刷过屏,犹如自媒体的爆文一般一夜之间就火了,出现在微信群、朋友圈、各大新闻头条,成为了全民APP。
拼多多的商业模式很简单就是通过团购低价购买某件商品。
月流水能达到400亿的规模也是惊人的,那么里面稍纵即逝的拼团信息如何快速获取呢,学习拼多多采集软件的使用方法能让你总是快人一步。
本文介绍使用八爪鱼采集拼多多商品(限时秒杀)的方法。
本文仅以限时秒杀这个栏目做举例说明,大家在采集的时候也可以采集其他栏目。
采集内容包括:商品标题、商品图片、商品价格,商品原价、商品销量使用功能点:●提取数据●修改Xpath步骤1:创建拼多多商品采集任务1)进入主界面,选择“自定义采集”2)将要采集的网站URL复制粘贴到输入框中,点击“保存网址”步骤2:提取拼多多数据字段1)鼠标选中要采集的数据,比如我选的是商品标题、商品图片、商品价格,商品原价、商品销量,商品在右面的提示框中选择“选中全部”拼多多商品采集-提取数据字段2)随后点击“采集数据”,接下来点击“保存并开始采集”3)打开右上角流程按钮,观察发现图片地址是默认扫码的按钮,并不是我们想要的。
3)选中拼多多商品图片这个字段,依次点击自定义数据字段->自定义定位元素方式,按下图进行“自定义定位元素设置图”设置。
元素匹配的xpath://body/section[1]/div[4]/div[1]/ul[1]/li[1]/div[1]/DIV[1]/IMG[1]相对xpath:/DIV[1]/IMG[1]修改好后点击确定自定义数据字段自定义定位元素设置图步骤5:拼多多商品数据采集及导出 1)修改采集字段名称,点击“保存并开始采集”启动本地采集采集完成后,会跳出提示,选择“导出数据”选择“合适的导出方式”,将采集好的数据导出,这里我们选择excel作为导出为格式,一份完好的拼多多商品数据就导出好了,数据导出后如下图本文来自于:/tutorialdetail-1/pddspcj.html相关采集教程:拼多多商品数据抓取:/tutorial/pddspcj网页数据爬取教程:/tutorial/hottutorial电商爬虫:/tutorial/hottutorial/dianshang淘宝数据采集:/tutorial/hottutorial/dianshang/taobao京东爬虫:/tutorial/hottutorial/dianshang/jd天猫爬虫:/tutorial/hottutorial/dianshang/tmall阿里巴巴数据采集:/tutorial/hottutorial/dianshang/alibaba亚马逊爬虫:/tutorial/hottutorial/dianshang/amazon电商爬虫教程:/tutorial/hottutorial/dianshang/dsqita八爪鱼——90万用户选择的网页数据采集器。
八爪鱼如何通过xpath实现自定义定位元素
定位元素:八爪鱼通过Xpath来实现元素的定位。
适用情况:八爪鱼自动定位方式不能满足需求的情况。
下面演示如何通过自定义定位元素方式来修改元素匹配的Xpath,借此修改提取元素步骤采集到的数据。
示例网址:
/guide/demo/genremoviespage1.html 步骤一:点击自定义采集下的立即使用→输入网址并保存
自定义定位元素方式-图1
自定义定位元素方式-图2
步骤二:点击采集位置→循环采集元素→补充并修改提取元素步骤
自定义定位元素方式-图3
自定义定位元素方式-图4
说明:循环采集元素会采集所有信息,我们在补充并修改提取元素步骤进行了删除第一个字段操作,同时添加了我们需要的正确字段。
步骤三:修改自定义定位元素方式
选中要修改的字段→点击高级选项中自定义数据字段(如下图)
→点击自定义定位元素方式
进入自定义定位元素方式后,我们在下图红框处修改Xpath
自定义定位元素方式-图6
其中元素匹配的Xpath是指可以通过这个Xpath路径在网页中直接找到所需数据的路径;相对Xpath指相对于循环Xpath的路径,将循环中的Xpath接上相对Xpath路径就可以生成一条直接匹配元素的路径。
下面进行演示。
演示中使用了火狐浏览器的Firebug插件,详细使用情况请到Xpath使用教程中查看。
自定义定位元素方式-图7
自定义定位元素方式-图8
自定义定位元素方式-图9
自定义定位元素方式-图10
如图,示例中将循环中的Xpath和字段对应的相对Xpath接在一起,在浏览器中可以查找到所有的标题。
假如我们想通过Xpath 的修改采集其他的字段怎么采集呢?
下面演示如何通过自定义定位元素方式修改标题字段的Xpath 使之采集的内容变成类型中的内容
步骤1:找出类型所在的Xpath 是怎样的
自定义定位元素方式
-
图11
自定义定位元素方式-图12
自定义定位元素方式-图13
说明:我们知道循环中的内容为每个需要采集的内容所在的位置,我们将循环中的Xpath 复制进入浏览器也看到匹配到了所有电影的框。
随后我们查看类型所在的Xpath,可以看到如下图:
自定义定位元素方式-图14
查看到的Xpath为html/body/div/div/ul/li[1]/span[2]/span/span
步骤2:修改Xpath 使之定位到所有的电影类型。
因为我们知道LI 元素定位三个电影整体的框,所以我们将循环中的//LI[@class='movie']替换到类型所在的Xpath 中,形成Xpath 为://LI[@class='movie']/span[2]/span/span 元素前//表示不论LI 在何处都匹配,所以可以省掉前面所有的元素。
此时我们的得到的Xpath 就可以匹配所有的电影类型
自定义定位元素方式
-图15
可以看到该Xpath 可以定位到红色箭头位置所示的3个元素,红框中也标出了类型,我们
一共在该页只有三个电影,所以我们就得到了所有电影类型的Xpath 。
步骤3:将得到的Xpath 放入自定义定位元素方式中
自定义定位元素方式-图16
自定义定位元素方式
-图
17
自定义定位元素方式-图18
自定义定位元素方式-图19
说明:复制元素匹配Xpath后,因为我们知道循环Xpath为LI元素,所以我们复制LI元素后的部分进入相对Xpath中。
通过手动运行三个电影验证标题是否改为类型,确定改变,会跟着变化,修改完成。
步骤四:保存并启动→数据导出
自定义定位元素方式-图20
自定义定位元素方式-图21
相关采集教程:
京东商品信息采集
58同城信息采集
搜狗微信文章采集
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。