汉明码编译码
- 格式:doc
- 大小:495.00 KB
- 文档页数:11

汉明码编译码课程设计一、课程目标知识目标:1. 学生能理解汉明码的基本概念,掌握编码和译码的原理;2. 学生能够运用汉明码进行信息编码和错误检测与纠正;3. 学生了解汉明码在通信和计算机科学中的应用,理解其重要性。
技能目标:1. 学生能够运用所学知识,独立完成汉明码的编码和译码过程;2. 学生能够通过实际案例分析,提高问题解决和逻辑思维能力;3. 学生能够运用合作学习的方式,进行小组讨论和成果分享。
情感态度价值观目标:1. 学生培养对信息科学的兴趣,激发学习热情;2. 学生认识到团队合作的重要性,培养协作精神;3. 学生通过学习汉明码,认识到科技对社会发展的贡献,增强社会责任感。
课程性质:本课程属于信息技术学科,以实际应用为导向,注重理论与实践相结合。
学生特点:六年级学生具备一定的信息科学基础和逻辑思维能力,对新鲜事物充满好奇心,但注意力集中时间有限。
教学要求:结合学生特点,教师应采用生动形象的教学方法,注重启发式教学,引导学生主动参与,提高课堂互动性。
同时,将课程目标分解为具体的学习成果,以便在教学过程中进行有效评估。
1. 汉明码基本概念:介绍汉明码的定义、原理及其在通信和计算机科学中的应用。
教材章节:第三章第三节2. 汉明码编码过程:讲解如何利用汉明码进行信息编码,包括奇偶校验位的添加方法。
教材章节:第三章第四节3. 汉明码译码过程:介绍汉明码的译码原理,以及如何检测和纠正错误。
教材章节:第三章第五节4. 案例分析与实操:通过实际案例,分析汉明码在信息传输中的应用,并进行编码和译码实操。
教材章节:第三章第六节5. 小组合作与讨论:分组进行讨论,分享学习心得,培养学生的团队合作精神。
教材章节:第三章实践活动教学安排与进度:第一课时:汉明码基本概念及编码过程第二课时:汉明码译码过程及案例分析第三课时:实操练习,小组合作与讨论第四课时:总结与评价,巩固所学知识教学内容确保科学性和系统性,结合课程目标进行详细的教学大纲制定,以便教师有序开展教学活动,帮助学生更好地掌握汉明码相关知识。

汉明码(Hamming)的编码和译码算法本文所讨论的汉明码是一种性能良好的码,它是在纠错编码的实践中较早发现的一类具有纠单个错误能力的纠错码,在通信和计算机工程中都有应用。
例如:在“计算机组成原理”课程中,我们知道当计算机存储或移动数据时,可能会产生数据位错误,这时可以利用汉明码来检测并纠错。
简单的说,汉明码是一个错误校验码码集,由Bell实验室的R.W.Hamming发明,因此定名为汉明码。
如果对汉明码作进一步推广,就得出了能纠正多个错误的纠错码,其中最典型的是BCH码,而且汉明码是只纠1bit错误的BCH码,可将它们都归纳到循环码中。
各种码之间的大致关系显示如下。
一、汉明码的编码算法输入:信源消息u(消息分组u)输出:码字v处理:信源输出为一系列二进制数字0和1。
在分组码中,这些二进制信息序列分成固定长度的消息分组(message blocks)。
每个消息分组记为u,由k个信息位组成。
因此共有2k种不同的消息。
编码器按照一定的规则将输入的消息u转换为二进制n 维向量v ,这里n >k 。
此n 维向量v 就叫做消息u 的码字(codeword )或码向量(code vector )。
因此,对应于2k 种不同的消息,也有2k 种码字。
这2k 个码字的集合就叫一个分组码(block code )。
若一个分组码可用,2k 个码字必须各不相同。
因此,消息u 和码字v 存在一一对应关系。
由于n 符号输出码字只取决于对应的k 比特输入消息,即每个消息是独立编码的,从而编码器是无记忆的,且可用组合逻辑电路来实现。
定义:一个长度为n ,有2k 个码字的分组码,当且仅当其2k 个码字构成域GF(2)上所有n 维向量组成的向量空间的一个K 维子空间时被称为线性(linear )(n, k)码。
汉明码(n ,k ,d )就是线性分组(n, k)码的一种。
其编码算法即为使用生成矩阵G :v = u ·G 。

(7,4)汉明码编译码原理程序说明书1、线性分组码假设信源输出为一系列二进制数字0和1.在分组码中,这些二进制信息序列分成固定长度的消息分组(message blocks )。
每个消息分组记为u ,由k 个信息位组成。
因此共有2k种不同的消息。
编码器按照一定的规则将输入的消息u 转换为二进制n 维向量v ,这里n>k 。
此n 维向量v 就叫做消息u 的码字(codeword )或码向量(code vector )。
因此,对应于2k种不同的消息,也有2k种码字。
这2k个码字的集合就叫一个分组码(block code )。
一个长度为n ,有2k个码字的分组码,当且仅当其2k个码字构成域GF (2)上所有n维向量空间的一个k 维子空间时被称为线性(linear )(n ,k )码。
对于线性分组码,希望它具有相应的系统结构(systematic structure ),其码字可分为消息部分和冗余校验部分两个部分。
消息部分由k 个未经改变的原始信息位构成,冗余校验部分则是n-k 个奇偶校验位(parity-check )位,这些位是信息位的线性和(linear sums )。
具有这样的结构的线性分组码被称为线性系统分组码(linear systematic block code )。
本实验以(7,4)汉明码的编译码来具体说明线性系统分组码的特性。
其主要参数如下:码长:21mn =- 信息位:21m k m =-- 校验位:m n k =-,且3m ≥ 最小距离:min 03d d ==由于一个(n ,k )的线性码C 是所有二进制n 维向量组成的向量空间n V 的一个k 维子空间,则可以找到k 个线性独立的码字,0,1,1k g g g -…… ,使得C 中的每个码字v 都是这k 个码字的一种线性组合。
(7,4)汉明码的生成矩阵如下,前三位为冗余校验部分,后四位为消息部分。
0123 1 1 0 1 0 0 00 1 1 0 1 0 01 1 1 0 0 1 01 0 1 0 0 0 1g g G g g ⎧⎫⎧⎫⎪⎪⎪⎪⎪⎪⎪⎪==⎨⎬⎨⎬⎪⎪⎪⎪⎪⎪⎪⎪⎩⎭⎩⎭如果()0123u u u u u =是待编码的消息序列,则相应的码字可如下给出:()0101230011223323g g v u G u u u u u g u g u g u g g g ⎧⎫⎪⎪⎪⎪===+++⎨⎬⎪⎪⎪⎪⎩⎭编码结构即码字()0123456v v v v v v v v =,对于(7,4)线性分组码汉明码而言,3456,,,v v v v 为所提供的消息序列,而0356v v v v =⊕⊕,1345v v v v =⊕⊕,2456v v v v =⊕⊕。

《数据通信原理》实验报告实验题目:汉明码的编译码专业班级:信息工程2班姓名学号:赵星敏201342351 李明阳201342300指导教师:刘钰实验五 汉明码的编译码一、实验目的1、理解汉明码的编码原理2、掌握利用simulink 进行汉明码编译码仿真的方法3、掌握利用matlab 指令进行汉明码编译码的方法 二、实验原理在数字通信系统中,为了实现信息的可靠传输,需要采用差错控制来发现并纠正错误。
进行差错控制的方法就是对信息进行差错控制编码,差错控制编码种类较多,其中线性分组码是常用的一类编码,具有编码效率高,实现较简单以及检纠错能力较强等特点。
一般数字通信系统模型由信源信宿、加解密、编解码、调制解调等模块组成,其中有些通信模块是组成整个通信系统所必不可少的,有些模块是可以不需要的。
差错控制编解码属于编解码器通信模块,为了方便分析差错控制编码性能,通过将通信系统简化为如图5-1所示的信息传输系统来搭建仿真实验平台进行分析研究。
图5-1编码,有时也称为纠错编码。
不同的编码方法,有不同的检错或纠错能力,有的编码只能检错,不能纠错。
一般说来,付出的代价越大,检纠错的能力就越强。
在选择差错控制编码时需要考虑到编码效率、检纠错的能力等方面因素的影响。
按照是否将信息码元进行分组可以将差错控制编码分为分组码和非分组码,线性码是指信息位和监督位满足一组线性方程的码,任一(n,k)线性分组码的编码效率为k/n 。
Simulink 通信模块中提供了二进制线性分组码编解码器:Binary Linear Encoder 和Binary Linear Decoder 。
汉明码是汉明(Hamming)于1950年提出的能纠正一位错码且编码效率较高的线性分组码,它可以用一种简洁有效的方法进行解码。
汉明码不是仅指某一种码,而是指一类码。
二进制汉明码应满足条件:2n-k =1+n,令m=n-k,汉明码n 和k 服从关系式:码长n=2m -1;信息位k=2m -1-m ;最小距离dmin=3(指汉明距离)。

汉明码编译码及纠错性能验证目录一、实验目的 (2)二、实验原理 (2)1.汉明编译码介绍 (2)2.汉明编译码原理 (2)3.举例说明 (3)4.实验框图说明 (3)5.框图中各个测量点说明 (4)三、实验任务 (5)四、实验步骤 (5)1. 实验准备 (5)2.汉明码编码原理验证 (5)3.汉明译码观测及纠错能力验证 (8)4.实验结束 (10)五、实验分析 (11)一、实验目的1.学习汉明码编译码的基本概念;2.掌握汉明码的编译码方法;3.验证汉明码的纠错能力。
二、实验原理1.汉明编译码介绍汉明码(Hamming Code)是一个可以有多个校验位,具有检测并纠正一位错误代码的纠错码,所以它也仅用于信道特性比较好的环境中,如以太局域网中,因为如果信道特性不好的情况下,出现的错误通常不是一位。
汉明码的检错、纠错基本思想是将有效信息按某种规律分成若干组,每组安排一个校验位进行奇偶性测试,然后产生多位检测信息,并从中得出具体的出错位置,最后通过对错误位取反(也是原来是 1 就变成 0,原来是 0 就变成 1)来将其纠正。
2.汉明编译码原理●汉明码编码采用(4,7)汉明码,信息位数k=4,监督位数r=n-k=3,可以纠一位错码,生成矩阵G=[1 0 0 0 1 1 10 1 0 0 1 1 00 0 1 0 1 0 10 0 0 1 0 1 1],编码情况见表格1。
表格1 (7,4)Hamming编码表●汉明码译码计算校正子S=[S1,S2,S3],其中S1=a6⨁a5⨁a4⨁a2S2=a6⨁a5⨁a3⨁a1S3=a6⨁a4⨁a3⨁a0校正子S 的值决定了接收码元中是否有错码,并且指出错码的位置,见表格 2。
表格 2 错码位置示意3.举例说明信息位a6a5a4a3=1001,根据表格 1(4,7) Hamming 编码表,编码为1001100,如果在信道传输的过程中产生一位误码,编码接收时变为1101100 ,我们计算校正子:S1=a6⨁a5⨁a4⨁a2=1S2=a6⨁a5⨁a3⨁a1=1S3=a6⨁a4⨁a3⨁a0=0校正子S=110,查找表格 2 错码位置示意,a5产生误码,则译码输出信息位1001。

自主设计实验二.汉明码编译码121180165赵博睿一.实验原理汉明码是差错控制编码的一种,是一种线性分组码,可以纠一位错,利用监督位和信息位的线性方程关系实现监督。
满足n=k+r,n=2^r-1的关系,本次实验采用的是(7,4)汉明码。
二.设计思路本次实验可以分为6个模块:m序列产生模块、汉明编码模块、编码输出模块、信道加错模块、接收译码模块、译码输出模块。
1.m序列产生模块:上次实验做过,因此不赘述设计思路;2.汉明码编码模块:需要将m序列缓冲到一个寄存器中进行汉明编码,编码方法由生成矩阵G决定,需要将编码数据放入到另一个寄存器中。
3.编码输出模块:将寄存器中编好的数据输出,需要另一个寄存器进行并行存储到串行输出的转换,并且需要一个同步计数器跟踪串行输出的首位。
4.信道加错模块:需要一个计数器来进行固定频率的加错,需要一个寄存器进行汉明码串行输出到并行存储的转换。
5.译码输出模块:将加错后的汉明码进行纠错译码并且输出,需要一个同步信号查找首位,需要一个寄存器进行译码,需要一个寄存器进行译码后数据并行存储到串行输出的转换。
从技术层面来讲,需要三种技术:同步技术、串/并行转换技术、编译码技术。
三.Verilog代码module hanmingma(clk,mout,hout,tout);input clk;//晶振clk信号//output reg mout;//m序列输出//output reg hout;//汉明码输出//reg mclk;//m序列clk//reg hclk;//汉明码clk//reg [3:0] mreg;//m序列寄存器//reg [6:0] hreg;//用来汉明码编码的汉明码寄存器//reg [6:0] hreg2;//用来输出的汉明码寄存器//reg [6:0] rereg;//接收端汉明码寄存器//reg [3:0] m;//m序列产生寄存器//reg [7:0] count1;//mclk计数器//reg [7:0] count2;//hclk计数器//reg [1:0] mcount;//m序列同步计数器//reg [2:0] hcount;//汉明码同步计数器//reg [6:0] ecount;//加错计数器//reg [3:0] rem;//用来译码的译码m序列寄存器//output reg tout;//译码输出//reg [3:0 ]rem2;//用来输出的译码m序列寄存器//reg[2:0] tcount;//译码输出同步计数器//reg [2:0] a1;//接收端同步寄存器1//reg[2:0] a2;//接收端同步寄存器2//reg [3:0] acount;//接收端同步计数器//always @(posedge clk)beginif(count1==223)//分频产生32khz时钟信号mclk// beginmclk<=~mclk;count1<=0;endelsecount1<=count1+1;if(count2==127)//分频产生56khz的时钟信号hclk// beginhclk<=~hclk;count2<=0;endelsecount2<=count2+1;endalways @(posedge mclk)//产生m序列并且输出到mout// beginif(m==0)m=1;elsebeginm[0]<=m[0]^m[3];m[1]<=m[0];m[2]<=m[1];m[3]<=m[2];mout<=m[3];endendalways @(posedge mclk)//将mout输入到mreg寄存器中并且计数,每当存入4个数据时进行汉明码编码并存储到hreg寄存器中,并且重新开始计数//beginmreg[3:1]<=mreg[2:0];mreg[0]<=mout;if(mcount==2)beginhreg[6:3]<=mreg[3:0];hreg[2]<=mreg[3]^mreg[2]^mreg[1];hreg[1]<=mreg[1]^mreg[2]^mreg[0];hreg[0]<=mreg[3]^mreg[0]^mreg[2];mcount<=mcount+1;endelsemcount<=mcount+1;endalways @(posedge hclk)//将hreg中的汉明码存入hreg2中用以输出,hreg2中的最高位输出到hout并且进行移位,同时进行计数,输出7个数据之后重新将hreg中的数据存入hreg2中并且重复上述输出过程//beginhout<=hreg2[6];hreg2[6:1]<=hreg2[5:0];if(hcount==6)beginhreg2<=hreg;hcount<=0;endelsehcount<=hcount+1;endalways @(posedge hclk)//模拟加错信道,将hout输入到接收端汉明码寄存器,并将接收端寄存器数据移位,同时进行错码周期计数,当传输18个数据时,将当前数据取反输入给接收端//beginrereg[6:1]<=rereg[5:0];if(ecount==17)beginrereg[0]<=~hout;ecount<=0;endelsebeginrereg[0]<=hout;ecount<=ecount+1;endendalways @(posedge hclk)//进行接收端汉明码首位寻址,若两个同步监督寄存器中有一个为0,即连续两个7位序列中有一个无错误,视为同步成功,将同步计数器归0,否则同步计数器数值不变,继续寻找满足条件的首位//beginif(acount==6)beginif(a2==0||a1==0)acount<=0;elseacount<=6;endelseacount<=acount+1;endalways @(posedge hclk)//接收端纠错译码和监督,寻找首位时进行同步监督,并将同步监督寄存器1值赋给同步监督寄存器2,以实现监督连续两组汉明码的目的,与上一个模块共同作用保证同步,并同时进行纠错译码,将译码后的结果放到译码m序列寄存器中// beginif(acount==6)begina1[2]<=rereg[6]^rereg[5]^rereg[4]^rereg[2];a1[1]<=rereg[5]^rereg[4]^rereg[3]^rereg[1];a1[0]<=rereg[6]^rereg[5]^rereg[3]^rereg[0];a2<=a1;rem[3]<=((~(rereg[5]^rereg[3]^rereg[4]^rereg[1]))&(rereg[6] ^rereg[5]^rereg[3]^rereg[0])&(rereg[6]^rereg[5]^rereg[4]^re reg[2]))^rereg[6];rem[2]<=((rereg[5]^rereg[3]^rereg[4]^rereg[1])&(rereg[6]^re reg[5]^rereg[3]^rereg[0])&(rereg[6]^rereg[5]^rereg[4]^rereg [2]))^rereg[5];rem[1]<=((rereg[5]^rereg[3]^rereg[4]^rereg[1])&(~(rereg[6] ^rereg[5]^rereg[3]^rereg[0]))&(rereg[6]^rereg[5]^rereg[4]^r ereg[2]))^rereg[4];rem[0]<=((rereg[5]^rereg[3]^rereg[4]^rereg[1])&(rereg[6]^re reg[5]^rereg[3]^rereg[0])&(~(rereg[6]^rereg[5]^rereg[4]^rer eg[2])))^rereg[3];endendalways @(posedge mclk)//译码后的m序列输出,将译码m序列寄存器中的数据存入rem2中,rem2中最高位输出到tout并进行移位,并同时进行计数,输出4个数据后将m序列寄存器中的数据再次存入rem2中,重复上述输出过程//begintout<=rem2[3];rem2[3:1]<=rem2[2:0];if(tcount==3)beginrem2<=rem;tcount<=0;endelsetcount<=tcount+1;endendmodule四.实验结果分析1.程序仿真结果分析:图1.汉明码编码仿真分析:图中的hout为..1110100 1011000 0010110 0011101.., 经查表(此表格在报告最后附录给出)可知分为别1110,1011,0010,0011的汉明码编码,而1110-1011-0010-0011也符合mout的输出,所以这个仿真结果表明编码成功。


汉明码(Hamming)的编码和译码算法本文所讨论的汉明码是一种性能良好的码,它是在纠错编码的实践中较早发现的一类具有纠单个错误能力的纠错码,在通信和计算机工程中都有应用。
例如:在“计算机组成原理”课程中,我们知道当计算机存储或移动数据时,可能会产生数据位错误,这时可以利用汉明码来检测并纠错。
简单的说,汉明码是一个错误校验码码集,由Bell实验室的R.W.Hamming发明,因此定名为汉明码。
如果对汉明码作进一步推广,就得出了能纠正多个错误的纠错码,其中最典型的是BCH码,而且汉明码是只纠1bit错误的BCH码,可将它们都归纳到循环码中。
各种码之间的大致关系显示如下。
一、汉明码的编码算法输入:信源消息u(消息分组u)输出:码字v处理:信源输出为一系列二进制数字0和1。
在分组码中,这些二进制信息序列分成固定长度的消息分组(message blocks)。
每个消息分组记为u,由k个信息位组成。
因此共有2k种不同的消息。
编码器按照一定的规则将输入的消息u转换为二进制n 维向量v ,这里n >k 。
此n 维向量v 就叫做消息u 的码字(codeword )或码向量(code vector )。
因此,对应于2k 种不同的消息,也有2k 种码字。
这2k 个码字的集合就叫一个分组码(block code )。
若一个分组码可用,2k 个码字必须各不相同。
因此,消息u 和码字v 存在一一对应关系。
由于n 符号输出码字只取决于对应的k 比特输入消息,即每个消息是独立编码的,从而编码器是无记忆的,且可用组合逻辑电路来实现。
定义:一个长度为n ,有2k 个码字的分组码,当且仅当其2k 个码字构成域GF(2)上所有n 维向量组成的向量空间的一个K 维子空间时被称为线性(linear )(n, k)码。
汉明码(n ,k ,d )就是线性分组(n, k)码的一种。
其编码算法即为使用生成矩阵G :v = u ·G 。

汉明码编译码实验报告引言:汉明码是一种检错纠错编码方法,常用于数字通信和计算机存储中。
它通过在数据中插入冗余位,以检测和纠正错误,提高数据传输的可靠性。
本实验旨在通过编写汉明码的编码和解码程序,对汉明码的编译码原理进行实际验证,并分析其性能。
一、实验目的:1. 了解汉明码的编码和解码原理;2. 掌握汉明码编码和解码的具体实现方法;3. 验证汉明码在检测和纠正错误方面的有效性;4. 分析汉明码的性能及其应用范围。
二、实验原理:1. 汉明码编码原理:汉明码的编码过程主要包括以下几个步骤:(1)确定数据位数和冗余位数:根据要传输的数据确定数据位数n,并计算冗余位数m。
(2)确定冗余位的位置:将数据位和冗余位按照特定规则排列,确定冗余位的位置。
(3)计算冗余位的值:根据冗余位的位置和数据位的值,计算每个冗余位的值。
(4)生成汉明码:将数据位和冗余位按照一定顺序排列,得到最终的汉明码。
2. 汉明码解码原理:汉明码的解码过程主要包括以下几个步骤:(1)接收数据:接收到经过传输的汉明码数据。
(2)计算冗余位的值:根据接收到的数据,计算每个冗余位的值。
(3)检测错误位置:根据冗余位的值,检测是否存在错误,并确定错误位的位置。
(4)纠正错误:根据错误位的位置,纠正错误的数据位。
(5)输出正确数据:输出经过纠正后的正确数据。
三、实验过程:1. 编码程序设计:根据汉明码编码原理,编写编码程序,实现将输入的数据进行编码的功能。
2. 解码程序设计:根据汉明码解码原理,编写解码程序,实现将输入的汉明码进行解码的功能。
3. 实验数据准备:准备一组数据,包括数据位和冗余位,用于进行编码和解码的实验。
4. 编码实验:将准备好的数据输入编码程序,得到编码后的汉明码。
5. 传输和接收实验:将编码后的汉明码进行传输,模拟数据传输过程,并接收传输后的数据。
6. 解码实验:将接收到的数据输入解码程序,进行解码,检测和纠正错误。
7. 实验结果分析:分析编码和解码的正确性,检测和纠正错误的能力,并对汉明码的性能进行评估。

实验三汉明码编译码实验
汉明码编译码实验
一、实验目的
1、了解信道编码在通信系统中的重要性。
2、掌握汉明码编译码的原理。
3、掌握汉明码检错纠错原理。
4、理解编码码距的意义。
二、实验原理
1、实验原理框图汉明码编译码实验框图汉明码编码过程:数字终端的信号经过串并变换后,进行分组,分组后的数据再经过汉明码编码,数据由4bit变为7bit。
三、实验器材
1、主控&信号源、6号、2号模块各一块
2、双踪示波器一台
3、连接线若干
四、实验步骤汉明码编码规则验证连线汉明码1、2号模块的拨码开关S12#拨为 S22#、S32#、S42#均拨为;2、6号模块的拨码开关S16#拨为0001, S36#拨为0000按下6号模块S2系统复位键。
3、此时2号模块提供32K编码输入数据,6号模块进行汉明编译码,无差错插入模式。
4、用示波器观测6号模块TH5处编码输出波形。
汉明码检纠错性能检验1、6号模块S3拨成0001
按下6号模块S2系统复位。
2、对比观测译码结果与输入信号,验证汉明码的纠错能力。
3、对比观测插错指示与误码指示,验证汉明码的检错能力。
4、、6号模块S3按照插错控制表中的拨码方式,逐一插入不同错误,按下6号模块S2系统复位。
重复步骤2,验证汉明码的检纠错能力。
5、将示波器触发源通道接TP2帧同步信号,示波器另外一个通道接TP1插错指示,可以观测插错的位置。
五、实验数据错2位码时错码检测指示输出波形汉明译码纠错性能检验六、实验分析开头数字序号1。
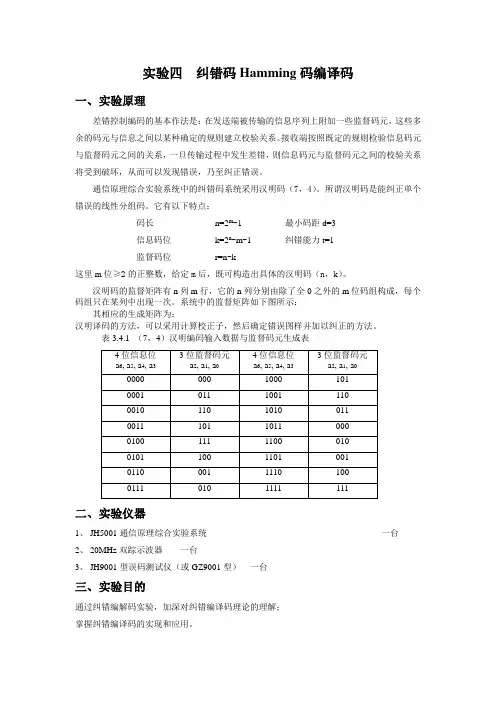
实验四纠错码Hamming码编译码一、实验原理差错控制编码的基本作法是:在发送端被传输的信息序列上附加一些监督码元,这些多余的码元与信息之间以某种确定的规则建立校验关系。
接收端按照既定的规则检验信息码元与监督码元之间的关系,一旦传输过程中发生差错,则信息码元与监督码元之间的校验关系将受到破坏,从而可以发现错误,乃至纠正错误。
通信原理综合实验系统中的纠错码系统采用汉明码(7,4)。
所谓汉明码是能纠正单个错误的线性分组码。
它有以下特点:码长n=2m-1 最小码距d=3信息码位k=2n-m-1 纠错能力t=1监督码位r=n-k这里m位≥2的正整数,给定m后,既可构造出具体的汉明码(n,k)。
汉明码的监督矩阵有n列m行,它的n列分别由除了全0之外的m位码组构成,每个码组只在某列中出现一次。
系统中的监督矩阵如下图所示:其相应的生成矩阵为:汉明译码的方法,可以采用计算校正子,然后确定错误图样并加以纠正的方法。
表3.4.1 (7,4)汉明编码输入数据与监督码元生成表二、实验仪器1、JH5001通信原理综合实验系统一台2、20MHz双踪示波器一台3、JH9001型误码测试仪(或GZ9001型)一台三、实验目的通过纠错编解码实验,加深对纠错编译码理论的理解;掌握纠错编译码的实现和应用。
AS CVSD四、 实验内容准备工作:(1)首先通过菜单将调制方式设置为BPSK 或DBPSK 方式;将汉明编码模块内工作方式选择开关SWC01中,编码使能开关插入(H_EN ),ADPCM 数据断开(ADPCM );将输入数据选择开关KC01设置在m 序列(DT_M )位置;设置m 序列方式为(00:M_SEL2和M_SEL1拔下),此时m 序列输出为1/0码。
(2)将汉明译码模块内输入信号和时钟选择开关KW01、KW02设置在LOOP 位置(右端),输入信号直接来自汉明编码模块;将译码器使能开关KW03设置在工作位置0N (左端)。
通信原理实验——汉明编码和译码实验学生:XX学号:******XX指导教师:**同组成员:00日期: 2014年12月上课时间:星期三第四大节14:00—16:00目录一、实验目的 (1)二、实验仪器 (1)三、实验原理 (1)1、汉明码的编码规则和纠错能力 (1)四、汉明编译码实验电路的构成 (3)汉明编码模块实验电路工作原理描述如下: (4)1、输入数据 (4)2、m序列发生器 (4)3、编码使能开关 (4)4、错码产生 (4)汉明译码模块实验电路工作原理描述如下: (5)1、输入信号选择开关 (5)2、汉明译码器 (5)3、汉明译码使能开关 (5)五、实验内容 (6)(一)准备工作 (6)(二)编码规则验证 (6)(三)译码数据输出测试 (8)(五)发端加错信号和汉明译码检错能力观测 (10)(六)汉明译码纠错性能测量 (12)六、思考题 (14)1、汉明编码器模块的使能开关、译码器模块的使能开关(H_EN断路器)起什么作用? (14)2、根据实验数据分析汉明码的纠错功能。
(14)3、本实验中汉明编码器的输入数据速率为32kbps,输出数据速率为多少?为什么? (14)参考文献 (14)姓名:XX 学号:122110XX 班级:通信120X第十五周星期三第四大节得分实验名称:汉明编码和译码实验一、实验目的1、掌握汉明码编译码原理。
2、掌握汉明码纠错检错原理。
3、通过纠错编解码实验,加深对纠错编解码理论的理解。
二、实验仪器1、ZH5001A通信原理综合实验系统一台2、20MHz双踪示波器一台三、实验原理1、汉明码的编码规则和纠错能力一般来说,若码长为n,信息位数为k,记作(n,k)码,则监督位数r=n-k。
如果希望用r 个监督位构造出r个监督关系式来指示一位错码的n种可能位置,则要求通信原理综合实验系统中的纠错码系统采用(7,4)汉明码。
用表示这7个码元,用表示3个监督关系式中的校正子,则的值与码元间构成偶数监督关系:在发送端编码时,信息位的值决定于输入信号,因此它们是随机的。
实验三汉明码编译码实验
汉明码编译码实验
一、实验目的
1、了解信道编码在通信系统中的重要性。
2、掌握汉明码编译码的原理。
3、掌握汉明码检错纠错原理。
4、理解编码码距的意义。
二、实验原理
1、实验原理框图汉明码编译码实验框图汉明码编码过程:数字终端的信号经过串并变换后,进行分组,分组后的数据再经过汉明码编码,数据由4bit变为7bit。
三、实验器材
1、主控&信号源、6号、2号模块各一块
2、双踪示波器一台
3、连接线若干
四、实验步骤汉明码编码规则验证连线汉明码1、2号模块的拨码开关S12#拨为 S22#、S32#、S42#均拨为;2、6号模块的拨码开关S16#拨为0001, S36#拨为0000按下6号模块S2系统复位键。
3、此时2号模块提供32K编码输入数据,6号模块进行汉明编译码,无差错插入模式。
4、用示波器观测6号模块TH5处编码输出波形。
汉明码检纠错性能检验1、6号模块S3拨成0001
按下6号模块S2系统复位。
2、对比观测译码结果与输入信号,验证汉明码的纠错能力。
3、对比观测插错指示与误码指示,验证汉明码的检错能力。
4、、6号模块S3按照插错控制表中的拨码方式,逐一插入不同错误,按下6号模块S2系统复位。
重复步骤2,验证汉明码的检纠错能力。
5、将示波器触发源通道接TP2帧同步信号,示波器另外一个通道接TP1插错指示,可以观测插错的位置。
五、实验数据错2位码时错码检测指示输出波形汉明译码纠错性能检验六、实验分析开头数字序号1。
汉明码编译码一设计思想汉明码是一种常用的纠错码,具有纠一位错误的能力。
本实验使用Matlab平台,分别用程序语言和simulink来实现汉明码的编译码。
用程序语言实现就是从原理层面,通过产生生成矩阵,错误图样,伴随式等一步步进行编译码。
用simulink实现是用封装好的汉明码编译码模块进行实例仿真,从而验证程序语言中的编译码和误码性能分析结果。
此外,在结合之前信源编码的基础上,还可实现完整通信系统的搭建。
二实现流程1.汉明码编译码图 1 汉明码编译码框图1)根据生成多项式,产生指定的生成矩阵G2)产生随机的信息序列M得到码字3)由C MG4)进入信道传输S RH得到伴随式5)计算=T6)得到解码码流7)得到解码信息序列2.汉明码误码性能分析误码率(SER)是指传输前后错误比特数占全部比特数的比值。
误帧率(FER)是指传输前后错误码字数占全部码字数的比值。
通过按位比较、按帧比较可以实现误码率和误帧率的统计。
3. 构建完整通信系统图 2 完整通信系统框图三 结论分析1. 汉明码编译码编写了GUI 界面方便呈现过程和结果。
图 3 汉明码编译码演示GUI 界面以产生(7,4)汉明码为例说明过程的具体实现。
1) 根据生成多项式,产生指定的生成矩阵G用[H,G,n,k] = hammgen(3,'D^3+D+1')函数得到系统码形式的校验矩阵H 、G 以及码字长度n 和信息位数k100101101011100010111H ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦1101000011010011100101010001G ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦ 2) 产生随机的信息序列M输入信息序列Huffman 编码Hamming 编码信道Hamming 译码Huffman 译码输出信息序列噪声0010=01000111M ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦3) 由C MG =得到码字010001101101000010111C ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦4) 进入信道传输假设是BSC 信道,错误转移概率设定为0.1 传输后接收端得到的码流为000011110100000111101R ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦红色表示错误比特。
汉明码(Hamming)的编码和译码算法本文所讨论的汉明码是一种性能良好的码,它是在纠错编码的实践中较早发现的一类具有纠单个错误能力的纠错码,在通信和计算机工程中都有应用。
例如:在“计算机组成原理”课程中,我们知道当计算机存储或移动数据时,可能会产生数据位错误,这时可以利用汉明码来检测并纠错。
简单的说,汉明码是一个错误校验码码集,由Bell实验室的R.W.Hamming发明,因此定名为汉明码。
如果对汉明码作进一步推广,就得出了能纠正多个错误的纠错码,其中最典型的是BCH码,而且汉明码是只纠1bit错误的BCH码,可将它们都归纳到循环码中。
各种码之间的大致关系显示如下。
一、汉明码的编码算法输入:信源消息u(消息分组u)输出:码字v处理:信源输出为一系列二进制数字0和1。
在分组码中,这些二进制信息序列分成固定长度的消息分组(message blocks)。
每个消息分组记为u,由k个信息位组成。
因此共有2k种不同的消息。
编码器按照一定的规则将输入的消息u转换为二进制n 维向量v ,这里n >k 。
此n 维向量v 就叫做消息u 的码字(codeword )或码向量(code vector )。
因此,对应于2k 种不同的消息,也有2k 种码字。
这2k 个码字的集合就叫一个分组码(block code )。
若一个分组码可用,2k 个码字必须各不相同。
因此,消息u 和码字v 存在一一对应关系。
由于n 符号输出码字只取决于对应的k 比特输入消息,即每个消息是独立编码的,从而编码器是无记忆的,且可用组合逻辑电路来实现。
定义:一个长度为n ,有2k 个码字的分组码,当且仅当其2k 个码字构成域GF(2)上所有n 维向量组成的向量空间的一个K 维子空间时被称为线性(linear )(n, k)码。
汉明码(n ,k ,d )就是线性分组(n, k)码的一种。
其编码算法即为使用生成矩阵G :v = u ·G 。
汉明码编译码实验一、实验目的1.掌握汉明码2的编解码原理。
掌握汉明码的纠错和检测原理二、实验内容1.汉明码编码实验。
2.汉明码译码实验。
3、汉明码纠错检错能力验证实验。
三、实验设备lte-tx-02e通信原理综合实验系统----------------------------------------------模块8四、实验原理在随机信道中,错码的出现是随机的,且错码之间是统计独立的。
例如,由高斯白噪声引起的错码就具有这种性质。
因此,当信道中加性干扰主要是这种噪声时,就称这种信道为随机信道。
由于信息码元序列是一种随机序列,接收端是无法预知的,也无法识别其中有无错码。
为了解决这个问题,可以由发送端的信道编码器在信息码元序列中增加一些监督码元。
这些监督码元和信码之间有一定的关系,使接收端可以利用这种关系由信道译码器来发现或纠正可能存在的错码。
在信息码元序列中加入监督码元就称为差错控制编码,有时也称为纠错编码。
不同的编码方法有不同的检错或纠错能力。
有的编码就只能检错不能纠错。
那么,为了纠正一个错位码,至少应该向块码中添加多少监督位?编码效率可以提高吗?基于这一思想的研究催生了汉明码。
汉明码是一种线性分组码,它能纠正位错码,编码效率高。
接下来,我们介绍了汉明码的构造原理。
一般说来,若码长为n,信息位数为k,则监督位数r=n?k。
如果希望用r个监督位构造出r个监督关系式来指示一位错码的n种可能位置,则要求2r?1.≥ n或2R≥ K+R+1下面我们通过一个例子来说明如何具体构造这些监督关系式。
在分组码(n,k)中设k=4。
为了纠正错位代码,从公式(14-1)中可以看出,监管数字R需要≥ 3.如果r=3,那么n=K+r=7。
我们用α6α5?α0代表这七个符号,S1、S2和S3代表三种监督关系中的校正器。
然后可以指定s1s2s3的值与错误代码位置之间的对应关系,如表14-1所示。
表14-1(14-1)s1s2s3001010100011错码位置αααα0123s1s2s3101110111000错码位置α4α5α6无错由表中规定可见,仅当一错码位置在α2、α4、α5或α6时,校正子s1为1;否则s1为0。
第一章 绪论1.1差错控制编码差错控制编码 1.1 1.1 概述概述数字信号在传输过程中,数字信号在传输过程中,由于受到干扰的影响,由于受到干扰的影响,码元波形将变坏。
码元波形将变坏。
接收端收接收端收到后可能发生错误判决。
到后可能发生错误判决。
由于乘性干扰引起的码间串扰,由于乘性干扰引起的码间串扰,可以采用均衡的办法来可以采用均衡的办法来纠正。
纠正。
而加性干扰的影响则需要用其他办法解决。
而加性干扰的影响则需要用其他办法解决。
在设计数字通信系统时,在设计数字通信系统时,应该应该首先从合理选择调制制度,首先从合理选择调制制度,解调方法以及发送功率等方面考虑,解调方法以及发送功率等方面考虑,使加性干扰不足使加性干扰不足以影响到误码率要求。
在仍不能满足要求时,就要考虑采用差错控制措施了。
从差错控制角度看,按加性干扰引起的错码分布规律不同,信道可以分为3类,即随机信道,突发信道和混合信道。
在随机信道中,错码的出现是随机的,而且错码之间是统计独立的。
而且错码之间是统计独立的。
在突发信道中,在突发信道中,错码是成串集中出现的,错码是成串集中出现的,而且在短而且在短促的时间段之间存在较长的无错码区间。
把既存在随机错码又存在突发错码的的信道称为混合信道。
对于不同类型的信道,应该采用不同的差错控制技术。
1.2 1.2 纠错编码原理纠错编码原理我们把信息码分组,为每组信息码附加若干监督码的编码称为分组码为每组信息码附加若干监督码的编码称为分组码(block (block code).code).在分组码中,在分组码中,监督码元仅监督本码组中的信息码元。
分组码一般用符号(n ,k )表示,其中n 是码组的总位数,又称为码组的长度(码长),k 是码组中信息码元的数目,码元的数目,n-k=r n-k=r 为码组中的监督码元的数目,或者称为监督位数目,分组码的结构如图2示,图中前k 位为信息位,后面附加r 个监督位。
其中a n-1到a r 为k 个信息位,个信息位,a a r-1到a 0为r 个监督位。
汉明码编译码一设计思想汉明码是一种常用的纠错码,具有纠一位错误的能力。
本实验使用Matlab平台,分别用程序语言和simulink来实现汉明码的编译码。
用程序语言实现就是从原理层面,通过产生生成矩阵,错误图样,伴随式等一步步进行编译码。
用simulink实现是用封装好的汉明码编译码模块进行实例仿真,从而验证程序语言中的编译码和误码性能分析结果。
此外,在结合之前信源编码的基础上,还可实现完整通信系统的搭建。
二实现流程1.汉明码编译码图 1 汉明码编译码框图1)根据生成多项式,产生指定的生成矩阵G2)产生随机的信息序列M得到码字3)由C MG4)进入信道传输S RH得到伴随式5)计算=T6)得到解码码流7)得到解码信息序列2.汉明码误码性能分析误码率(SER)是指传输前后错误比特数占全部比特数的比值。
误帧率(FER)是指传输前后错误码字数占全部码字数的比值。
通过按位比较、按帧比较可以实现误码率和误帧率的统计。
3. 构建完整通信系统图 2 完整通信系统框图三 结论分析1. 汉明码编译码编写了GUI 界面方便呈现过程和结果。
图 3 汉明码编译码演示GUI 界面以产生(7,4)汉明码为例说明过程的具体实现。
1) 根据生成多项式,产生指定的生成矩阵G用[H,G,n,k] = hammgen(3,'D^3+D+1')函数得到系统码形式的校验矩阵H 、G 以及码字长度n 和信息位数k100101101011100010111H ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦1101000011010011100101010001G ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦2) 产生随机的信息序列M输入信息序列Huffman 编码Hamming 编码信道Hamming 译码Huffman 译码输出信息序列噪声0010=01000111M ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦3) 由C MG =得到码字010001101101000010111C ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦4) 进入信道传输假设是BSC 信道,错误转移概率设定为0.1 传输后接收端得到的码流为000011110100000111101R ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦红色表示错误比特。
5) 计算=TS RH 得到伴随式011=100001S ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦查表可知第一行码字错误图样为0100000,第二行码字错误图样为1000000,第三行码字错误图样为0000001。
进行ˆˆ=+CR E 即可得到纠错解码的码字C2。
6) 得到解码码流0110100200000001110010C ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦7) 得到解码信息序列0100200000010M ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦可以看出解码信息序列与原信息序列一样,体现了汉明码的纠错能力。
2.性能分析1)BSC信道仿真设置BSC错误转移概率Pe从0到1变化,步进为0.01,在每个Pe值进行1000次蒙特卡洛仿真,得到图4所示误码率随Pe变化曲线图和图5所示误帧率随Pe变化曲线图。
图 6误码率随Pe变化曲线图图中绿线为BSC信道误码率,红线为设定Pe值,蓝线为Hamming码解码误码率。
由图线可以看出仿真的BSC信道误码率与Pe一致。
在Pe<0.2时, Hamming码的解码误码率随着BSC信道错误传输概率Pe的减小而减小。
Hamming码的解码误码率显著下降,约为Pe的1/2。
Hamming码的纠1位错起到了很好的效果。
0.2<Pe<0.5时,Hamming码的解码误码率大于Pe。
这是因为在Pe>0.2时,传一个码字错误比特数近似为2,而Hamming码只能纠一位错,两位同时出错时会纠成另一个码字,这样就可能增加误比特数,使得“越纠越错”。
Pe>0.5时,情况恰好相反。
图 7误帧率随Pe变化曲线图可以看出随着Pe增加,BSC传输误帧率和Hamming译码误帧率成S曲线上升达到1。
Hamming译码误帧率要低于BSC传输误帧率,体现了其纠错能力使得码字错误减少这一效果。
与误码率的图对比可以发现,误帧率要比误比特率高。
为了进一步验证结果的正确性,进行了simulink仿真。
图 8 BSC信道仿真框图用伯努利二进制发生器产生随机序列,进行汉明码编码,进入BSC信道传输,之后进行汉明码译码,用Error Rate Calculation模块统计误码率,结果如下:图 9 simulink仿真BER随Pe变化曲线图与程序实现仿真的结果几乎一样。
2)AWGN信道仿真AWGN信道仿真直接用simulink实现。
图 10 AWGN信道仿真框图设置系统的数字调制方式为2FSK,设定AWGN信道的SNR从0到8dB以1dB步进变化,得到误码率统计图。
图 11 simulink仿真BER随SNR变化曲线图图中绿线为2FSK调制误码率,是由于AWGN带来的。
蓝线为汉明码解码后误码率。
可以看出,汉明码能够很好的降低误码率。
在SNR达到5dB时错误概率降低为0.001.3.完整通信系统的构建以传输图片为例,信道设置为BSC信道。
在不加入汉明码和加入汉明码两种情况下观察传输后图像的情况。
结果如下表所示。
BSC错误转0.1 0.05 0.01 0.001 0移概率PeBSC传输图像加汉明码误0.0652 0.02 0.0006 0 0码率加汉明码传输图像由结果可以看出,加入信道编码后,当BSC错误转移概率Pe<0.01后,图像恢复性能有明显的改善。
这体现了汉明码虽然只有纠一位错的能力,但由于一般信道的Pe不会很大,其纠错的实用性和效果还是很好的。
四 思考题解答1.采用循环Hamming 码在硬件实现中的优点?与普通的线性分组码译码电路相比,循环汉明码不需要存储伴随式及错误图样,显著的节省了寄存器的使用,起到简化电路的作用。
2.Hamming 码如何改进可提高纠检错性能?可以在H 校验矩阵基础上进行扩展,最后一行为全1行,最后一列矢量为[00…1]T 。
这样任何3列是线性无关的,d min =4,进行奇偶校验,纠错能力为1,检错能力为2。
即下面通过实例的方式说明扩展H 校验矩阵的检错性能。
首先在(7,4)汉明码的基础上进行扩展,得到(8,4)扩展汉明码的生成矩阵H 。
1110100001110100=1101001011111111H ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦简化译码表如下:说明对于错码个数为1的,既可以检错也可以纠错; 错码个数为2的,可以检错,但不能纠错;错码个数大于2的,被认为是错码个数为1,纠成其他码字。
0'=0111H H ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦M L附录clear all[H,G,n,k] = hammgen(3,'D^3+D+1');%%[H,G,n,k] = hammgen(3,'D^4+D^2+D+1');%[H,G,n,k] = hammgen(4,'D^4+D+1');%%[H,G,n,k] = hammgen(5,'D^5+D^2+1');%%%产生校验矩阵E=[zeros(1,n);fliplr(eye(n,n))];%产生错误图样一共是n+1个S=mod(H*E',2);%生成错误图样的伴随式%%产生消息序列%二进制随机矩阵%M= randi([0,1],1,k);%产生4位消息列nm=3;M= randi([0,1],nm,k);%产生4位消息列%消息序列code=mod(M*G,2);%对消息序列编码%BSC信道进入Pe=0.1;for j=1:nmfor i=1:ncode_bsc(j,i)=mod(code(j,i)+(unidrnd(round(1/Pe))==1),2);%模2加得到传输后的编码delta(j,i)=code_bsc(j,i)-code(j,i);%作差来计算错误位置endendep=find(delta~=0);%error positiondisplay(length(ep),'BSC错误位数')display(length(ep)/(nm*n),'BSC误比特率');Scode=mod(code_bsc*H',2 )'; %Scode=[1 1 0]';errow2=0;for i=1:nmif sum(code_bsc(i,:)-code(i,:))~=0errow2=errow2+1;endenddisplay(errow2,'BSC错误码字数');% display(errow2/nm,'BSC误码率');for m=1:nmfor i=1:n+1if S(:,i)==Scode(:,m)j=i;endend %找到对应的伴随式的位置dcode(m,:)=mod(code_bsc(m,:)+E(j,:),2);ender=length(find(dcode-code~=0));%计算误比特的个数enta=er/(nm*n);display(code,'信息序列码字')display(code_bsc,'BSC传输后的信息序列码字') display(dcode,'解码后的信息序列')% display(errow2/nm,'解码后误码率');% display(er,'解码后错误比特数');m2=dcode(:,n-k+1:end);display(dcode,'解码后信息序列');errow2=0;for i=1:nmif sum(dcode(i,:)-code(i,:))~=0errow2=errow2+1;endend% display(errow2,'解码后错误码字数');% display(errow2/nm,'解码后误码率');。
Welcome !!!欢迎您的下载,资料仅供参考!精选资料,欢迎下载。