EVIEWS中的模型操作
- 格式:ppt
- 大小:894.50 KB
- 文档页数:55

计量经济学》实验报告一元线性回归模型-、实验内容(一)eviews基本操作(二)1、利用EViews软件进行如下操作:(1)EViews软件的启动(2)数据的输入、编辑(3)图形分析与描述统计分析(4)数据文件的存贮、调用2、查找2000-2014年涉及主要数据建立中国消费函数模型中国国民收入与居民消费水平:表1年份X(GDP)Y(社会消费品总量)200099776.339105.72001110270.443055.42002121002.048135.92003136564.652516.32004160714.459501.02005185895.868352.62006217656.679145.22007268019.493571.62008316751.7114830.12009345629.2132678.42010408903.0156998.42011484123.5183918.62012534123.0210307.02013588018.8242842.82014635910.0271896.1数据来源:二、实验目的1.掌握eviews的基本操作。
2.掌握一元线性回归模型的基本理论,一元线性回归模型的建立、估计、检验及预测的方法,以及相应的EViews软件操作方法。
三、实验步骤(简要写明实验步骤)1、数据的输入、编辑2、图形分析与描述统计分析3、数据文件的存贮、调用4、一元线性回归的过程点击view中的Graph-scatter-中的第三个获得在上方输入Isycx回车得到下图DependsntVariable:Y Method:LeastSquares□ate:03;27/16Time:20:18 Sample:20002014 Includedobservations:15VariableCoefficientStd.Errort-StatisticProb.C-3J73.7023i820.535-2.1917610.0472X0416716 0.0107S838.73S44 a.ooao R-squared0.991410 Meandependentwar119790.2 AdjustedR.-squared 0.990750 S.D.dependentrar 7692177 S.E.ofregression 7J98.292 Akaike infocriterion20.77945 Sumsquaredresid 7;12E^-08 Scliwarz 匚「爬伽20.37386 Loglikelihood -1&3.3459Hannan-Quinncriter. 20.77845 F-statistic 1I3&0-435 Durbin-Watsonstat0.477498Prob(F-statistic)a.oooooo在上图中view 处点击view-中的actual ,Fitted ,Residual 中的第一 个得到回归残差打开Resid 中的view-descriptivestatistics 得到残差直方图/icw Proc Qtjject PrintN^me FreezeEstimateForecastStatsResids凹Group:UNIIILtD Worktile:UN III LtLJ::Unti1DependentVariablesMethod;LeastSquares□ate:03?27/16Time:20:27Sample(adjusted):20002014Includedobservations:15afteradjustmentsVariable Coefficient Std.Errort-Statistic ProtJ.C-3373.7023^20.535-2.191761 0.0472X0.4167160.01075S38.735440.0000R-squared0.991410 Meandependeniwar1-19790.3 AdjustedR-squa.red0990750S.D.dependentvar 76921.77 SE.ofregre.ssion 7J98.292 Akaike infacriterion20.77945 Sumsquaredresid 7.12&-0S Schwarzcriterion 20.S73S6 Laglikelihood -153.84&9Hannan-Quinncrite匚20.77545 F-statistic1I3&0.435Durbin-Watsonstat 0.477498 ProbCF-statistic) a.ooaooo在回归方程中有Forecast,残差立为yfse,点击ok后自动得到下图roreestYFM J訓YForea空巾取且:20002015 AdjustedSErmpfe:2000231i mskJddd obaerratire:15Roof kter squa red Error理l%2Mean/^oLteError畐惯啟iJean Afe.PereersErro r5.451SSQThenhe鼻BI附GKWCE口.他腐4Prop&niwi□ooooooVactaree Propor^tori0.001^24G M『倚■底Props^lori09®475在上方空白处输入lsycs…之后点击proc中的forcase根据公式Y。


eviews固定效应模型步骤Running fixed effects models in Eviews can be a useful tool for analyzing panel data. 固定效应模型是面板数据分析中一种有用的工具。
This type of model takes into account individual-specific effects that are constant over time, allowing for a more accurate estimation of parameters. 这种模型考虑了随时间恒定的个体特定影响,可以更准确地估计参数。
By controlling for these individual effects, researchers can better understand the true relationship between variables in their data. 通过控制这些个体效应,研究人员可以更好地了解数据中变量之间的真实关系。
One important step in running a fixed effects model in Eviews is to properly set up your panel data. 在Eviews中运行固定效应模型的一个重要步骤是正确设置面板数据。
Panel data refers to data that includes observations on multiple entities over time. 面板数据是指包含多个实体随时间观察的数据。
To run a fixed effects model, you will need to make sure that your data is structured in a panel format with individual identifiers and time identifiers. 要运行固定效应模型,您需要确保数据以带有个体标识符和时间标识符的面板格式结构化。
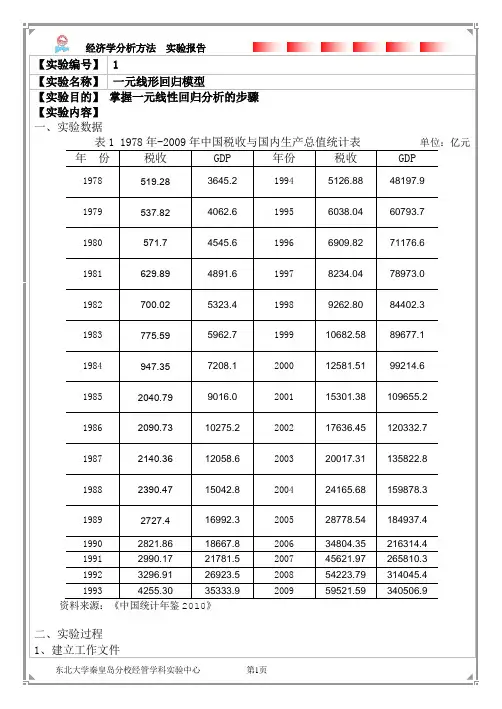
【实验编号】 1【实验名称】一元线形回归模型【实验目的】掌握一元线性回归分析的步骤【实验内容】一、实验数据表1 1978年-2009年中国税收与国内生产总值统计表单位:亿元年份税收GDP 年份税收GDP1978 519.28 3645.2 1994 5126.88 48197.91979 537.82 4062.6 1995 6038.04 60793.71980 571.7 4545.6 1996 6909.82 71176.61981 629.89 4891.6 1997 8234.04 78973.01982 700.02 5323.4 1998 9262.80 84402.31983 775.59 5962.7 1999 10682.58 89677.11984 947.35 7208.1 2000 12581.51 99214.61985 2040.79 9016.0 2001 15301.38 109655.21986 2090.73 10275.2 2002 17636.45 120332.71987 2140.36 12058.6 2003 20017.31 135822.81988 2390.47 15042.8 2004 24165.68 159878.31989 2727.4 16992.3 2005 28778.54 184937.41990 2821.86 18667.8 2006 34804.35 216314.41991 2990.17 21781.5 2007 45621.97 265810.31992 3296.91 26923.5 2008 54223.79 314045.41993 4255.30 35333.9 2009 59521.59 340506.9 资料来源:《中国统计年鉴2010》二、实验过程1、建立工作文件(1)点击桌面Eviews5.0图标,运行Eviews软件。




在EViews中的操作步骤为:STEP1:建立工作文件:启动EViews,点击File=〉New=〉Workfile,在对话框“Workfile Range”。
在“Workfile frequency”中选择“Annual”(年度),并在“Start date”中输入开始时间“1998”,在“end date”中输入最后时间“2009”,点击“ok”,出现“Workfile UNTITLED”工作框。
其中已有变量:“c”—截距项“resid”—剩余项。
在“Objects”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK”出现数据编辑窗口。
STEP2:输入数据:点击“Quik”下拉菜单中的“Empty Group”,出现“Group”窗口数据编辑框,点第一列与“obs”对应的格,在命令栏输入“Y”,点下行键“↓”,即将该序列命名为Y,并依此输入Y的数据。
用同样方法在对应的列命名X2、X3、X4…,并输入相应的数据。
STEP3:点击Eviews主画面上的quick/estima equation,弹出Equation specification框(图3-10),在Equation specification 下的空框中输入“Y C X2”,在“Estimation Settings”栏中选择“Least Sqares”(最小二乘法),点“ok”,即出现X2回归结果如图3-16所示。
若在“Equation Specification”栏中键入“Y C X2 X3”则出现X2、X3回归结果。
STEP4:在命令行中键入“expand 1998 2015”,之后点击回车。
STEP5:在命令行中键入“smpl 1998 2015”,之后点击回车。
STEP6:在命令行中键入“data 2X 3X 4X 11X 12X ”,点击回车,之后输入2010、2011、2012、2013、2014、2015年相应指标的数据。



eviews向量自回归操作方法标题:Eviews中向量自回归(VAR)模型的操作方法向量自回归(VAR)模型是宏观经济研究中常用的时间序列分析方法,尤其在分析多变量之间的动态关系时具有重要作用。
Eviews作为专业的经济计量分析软件,为用户提供了简便高效的VAR模型操作接口。
以下将详细介绍在Eviews中构建和操作VAR模型的具体步骤。
一、数据准备在开始VAR模型分析之前,需要收集并整理相关的宏观经济时间序列数据。
以河源市1988年至2014年的地区生产总值(GDP)和公路通车里程(GL)数据为例,首先将数据导入Eviews中,并对数据进行预处理,如取对数以消除数据的异方差性。
二、单位根检验为了确保时间序列数据的平稳性,需对数据进行ADF单位根检验。
在Eviews中,可以通过以下步骤进行操作:1.选择“Quick”菜单下的“Unit Root Test”;2.在弹出的对话框中,输入需要检验的变量名称,如LogGDP和LogGL;3.选择合适的检验类型,如“ADF test”;4.设置显著性水平,如1%、5%、10%;5.点击“OK”,Eviews将输出单位根检验的结果。
三、构建VAR模型在确认数据为平稳序列或经过差分后为平稳序列后,可以开始构建VAR模型:1.在Eviews菜单中选择“Quick”下的“Vector Autoregression”;2.在弹出的对话框中,输入参与模型构建的变量,并设置滞后阶数;3.点击“OK”,Eviews将输出VAR模型的估计结果。
四、最优滞后阶数确定为了确定VAR模型的最优滞后阶数,可以通过以下方法:1.利用信息准则(如AIC、SC等)选择滞后阶数;2.在Eviews中,通过“View”菜单下的“Lag Length Criteria”查看不同滞后阶数下的信息准则值,选择最小的信息准则值对应的滞后阶数。
五、脉冲响应和方差分解在构建VAR模型后,可以进一步进行脉冲响应和方差分解分析:1.脉冲响应分析:在Eviews中,通过“Quick”菜单下的“Impulse Response”功能,选择相应的变量和脉冲响应期数,进行脉冲响应分析;2.方差分解:在Eviews中,通过“Quick”菜单下的“Variance Decomposition”功能,选择相应的变量和分解期数,进行方差分解分析。
eviews实验指导ARIMA模型建模与预测在当今的数据分析领域,时间序列分析是一项至关重要的技术。
而ARIMA 模型(自回归移动平均模型)作为一种常用且有效的时间序列预测方法,在经济、金融、气象等众多领域都有着广泛的应用。
Eviews 作为一款功能强大的统计分析软件,为我们进行 ARIMA 模型的建模与预测提供了便捷的工具和环境。
接下来,让我们一起深入了解如何使用 Eviews 来构建和应用 ARIMA 模型。
一、ARIMA 模型的基本原理ARIMA 模型由三个部分组成:自回归(AR)部分、差分(I)部分和移动平均(MA)部分。
自回归部分表示当前值与过去若干个值之间存在线性关系。
例如,如果一个时间序列具有显著的自回归特征,那么当前的值可能受到过去几个值的影响。
差分部分用于处理非平稳的时间序列。
如果时间序列的均值、方差等统计特性随时间变化而不稳定,通过对其进行差分操作,可以使其变得平稳,从而满足建模的要求。
移动平均部分则反映了随机误差项的线性组合对当前值的影响。
二、数据准备在使用 Eviews 进行 ARIMA 模型建模之前,首先需要准备好数据。
数据的质量和特征对模型的效果有着重要的影响。
我们通常要求数据是时间序列形式,且具有一定的连续性和周期性。
同时,需要对数据进行初步的观察和分析,了解其趋势、季节性等特征。
在 Eviews 中,可以通过导入外部数据文件(如 Excel、CSV 等格式)或者直接在软件中输入数据来建立数据集。
三、平稳性检验平稳性是时间序列建模的一个重要前提。
如果时间序列不平稳,直接使用 ARIMA 模型可能会导致不准确的结果。
常见的平稳性检验方法有单位根检验,如 ADF 检验(Augmented DickeyFuller Test)。
在 Eviews 中,可以通过相应的命令和操作来进行ADF 检验。
如果检验结果表明时间序列不平稳,就需要对其进行差分处理,直到序列达到平稳状态。
四、模型识别与定阶在确定时间序列平稳后,接下来需要确定 ARIMA 模型的阶数,即AR 项的阶数(p)、MA 项的阶数(q)和差分的次数(d)。
eviews实验指导ARIMA模型建模与预测在数据分析和时间序列预测的领域中,ARIMA 模型是一种非常强大且实用的工具。
通过eviews 软件来实现ARIMA 模型的建模与预测,可以帮助我们更高效地处理和分析数据,做出更准确的预测。
接下来,让我们逐步深入了解如何使用eviews 进行ARIMA 模型的建模与预测。
首先,我们要明白什么是 ARIMA 模型。
ARIMA 全称为自回归移动平均整合模型(Autoregressive Integrated Moving Average Model),它由三个部分组成:自回归(AR)部分、差分(I)部分和移动平均(MA)部分。
自回归(AR)部分是指当前值与过去若干个值之间存在线性关系。
例如,如果说一个时间序列在 AR(2)模型下,那么当前值就与前两个值有关。
移动平均(MA)部分则表示当前值受到过去若干个随机误差项的线性影响。
差分(I)部分用于将非平稳的时间序列转化为平稳序列。
平稳序列在统计特性上,如均值、方差等,不随时间变化而变化。
在 eviews 中进行 ARIMA 模型建模与预测,第一步是数据的导入和预处理。
打开 eviews 软件后,选择“File”菜单中的“Open”选项,找到我们要分析的数据文件。
数据的格式通常可以是 Excel、CSV 等常见格式。
导入数据后,需要对数据进行初步的观察和分析,了解其基本特征,比如均值、方差、趋势等。
接下来,判断数据的平稳性。
这是非常关键的一步,因为 ARIMA 模型要求数据是平稳的。
我们可以通过绘制时间序列图、计算自相关函数(ACF)和偏自相关函数(PACF)来直观地判断数据的平稳性。
如果时间序列图呈现明显的趋势或周期性,或者自相关函数和偏自相关函数衰减缓慢,那么很可能数据是非平稳的。
对于非平稳的数据,我们需要进行差分处理。
在 eviews 中,可以通过“Quick”菜单中的“Generate Series”选项来实现差分操作。
sgmm模型的eviews操作以SGMM模型的Eviews操作为标题,本文将介绍如何在Eviews 软件中使用SGMM模型进行分析和预测。
SGMM模型是一种结构性时间序列模型,可以用于分析和预测具有异方差和序列相关性的数据。
在Eviews中建立一个新的工作文件,导入需要分析的数据。
可以使用Eviews提供的数据导入功能,将数据从Excel或其他数据源导入到Eviews中。
接下来,我们需要创建SGMM模型。
在Eviews的“对象”菜单中,选择“估计方程”选项。
在弹出的对话框中,选择“SGMM”作为估计方法,并选择要包含在模型中的变量。
在SGMM模型中,我们需要指定两个方面的参数。
首先是结构方程的形式,通常可以选择自回归过程(AR)或移动平均过程(MA)。
其次是异方差模型的形式,可以选择ARCH、GARCH等形式。
在Eviews中,我们可以通过添加额外的方程来指定结构方程和异方差模型。
在“估计方程”对话框中,选择“添加”按钮,然后选择“方程”选项。
在弹出的对话框中,选择AR或MA作为结构方程,并选择ARCH或GARCH作为异方差模型。
然后,输入相应的参数和变量。
在设置完模型参数后,我们需要选择估计方法和估计样本。
在“估计方程”对话框中,选择“估计”按钮,并选择所需的估计方法和样本范围。
常用的估计方法包括最小二乘法(OLS)、广义最小二乘法(GLS)和极大似然法(MLE)。
在SGMM模型中,由于存在异方差和序列相关性,通常使用广义最小二乘法(GLS)或极大似然法(MLE)进行估计。
选择合适的估计方法后,点击“确定”按钮开始估计。
估计完成后,Eviews会自动输出估计结果,包括参数估计值、标准误差、t值和p值等。
可以根据这些结果进行模型的解释和分析。
除了估计结果,Eviews还提供了一系列模型诊断工具,用于检验模型的拟合度和稳健性。
可以使用Eviews的诊断功能,对模型进行残差分析、异方差检验、序列相关检验等。
eviews广义矩估计法步骤
Eviews中的广义矩估计法(GMM)是一种用于估计经济模型参数的方法,它可以通过最大化矩条件函数来估计参数。
下面是Eviews中使用广义矩估计法的步骤:
1. 数据准备,首先,你需要在Eviews中导入你的数据,并确保数据的准确性和完整性。
这包括变量的选择和数据的时间范围。
2. 模型设定,在Eviews中,你需要设定你的经济模型,包括模型的方程和变量。
确保你的模型符合广义矩估计法的假设,比如模型的误差项是零均值和同方差的。
3. 估计参数,在Eviews中,选择“估计”菜单下的“广义矩估计”选项。
在弹出的对话框中,你需要输入你的条件矩阵和权重矩阵。
条件矩阵是用来估计参数的函数,而权重矩阵是用来考虑不同条件矩阵的重要性。
4. 模型诊断,一旦估计完成,你需要对你的模型进行诊断,检查模型的拟合程度和参数估计的显著性。
Eviews提供了各种诊断工具,比如残差分析和假设检验,来帮助你进行模型诊断。
5. 结果解释,最后,你需要解释你的估计结果,包括参数的估计值、标准误、置信区间和显著性水平。
你可以使用Eviews的报告功能来生成估计结果的报告,以便于你的进一步分析和解释。
总的来说,Eviews中使用广义矩估计法的步骤包括数据准备、模型设定、参数估计、模型诊断和结果解释。
通过严格按照这些步骤进行分析,你可以得到可靠和有效的参数估计结果。