一种数字人脑部切片图像分割新方法
- 格式:pdf
- 大小:341.60 KB
- 文档页数:4

像分割中的UNet模型AI技术的精细化像处理像分割中的UNet模型:AI技术的精细化图像处理近年来,随着人工智能(AI)技术的快速发展,图像处理领域也得到了重大突破。
而在图像分割任务中,UNet模型因其出色的性能和精细化处理特点而备受关注。
本文将对像分割中的UNet模型进行详细探讨,分析其在AI技术的精细化图像处理中的应用。
一、UNet模型简介UNet模型是一种基于深度学习的图像分割框架,于2015年由Ronneberger等人提出。
其结构主要包括编码器和解码器两部分,通过上采样和下采样过程实现图像的多尺度特征提取和合并。
与其他传统的图像分割方法相比,UNet模型具有更好的边缘保留能力和细节还原能力,使得分割结果更加精细化。
二、AI技术在图像处理中的应用AI技术在图像处理领域的应用广泛,包括图像分类、图像检测、图像分割等。
其中,图像分割技术对于各种应用场景具有重要意义,如医学影像分析、无人驾驶、智能监控等。
AI技术能够快速准确地提取图像中的感兴趣区域,提高图像处理的效率和质量。
三、UNet模型在图像分割中的优势UNet模型在图像分割任务中具有以下几个优势:1. 多尺度特征提取:UNet模型通过编码器和解码器的结构,能够同时获取图像中的全局信息和局部细节,从而提高分割结果的精确性和细节还原能力。
2. 边缘保持能力:UNet模型在特征提取过程中采用了跳跃连接,能够有效保留图像中的细微边缘信息,使得分割结果更加准确,边界更加清晰。
3. 少样本学习:由于UNet模型具有大容量和较少的参数,能够在少样本的情况下进行训练,适用于各种场景下的图像分割任务。
四、UNet模型的应用案例UNet模型在各个领域的图像分割任务中都取得了显著的成果。
以下是几个典型的应用案例:1. 医学影像分割:UNet模型在医学影像分析中的应用非常广泛,能够快速准确地提取出病变区域,辅助医生进行诊断和治疗。
2. 自动驾驶:UNet模型在自动驾驶领域的应用也备受关注,能够对驾驶场景进行实时感知和分割,提高车辆的安全性和行驶效率。

人脑MRI影像的分割与标注方法研究一、前言人脑MRI影像的分割与标注是医学影像分析领域中的一个重要研究方向,其意义在于为医疗诊断、治疗和研究提供了有力的基础支持。
本文将介绍目前人脑MRI影像分割与标注的主要方法和技术,并分析其优缺点和未来发展方向。
二、人脑MRI影像分割方法1. 基于阈值分割的方法基于阈值分割的方法是将人脑MRI影像转化为二值图像,通过设置不同的阈值进行分割。
这种方法简单快速,但是对于复杂的影像难以处理,分割精度较低,特别是在边缘处容易出现欠分割或者过分割等情况。
2. 基于区域生长和分水岭的方法基于区域生长和分水岭的方法是通过对相邻像素之间的相似度进行计算,将相似度高的像素组成一类,从而实现图像分割的目的。
这种方法可以有效克服基于阈值分割的方法中欠分割或者过分割等问题,但是在处理噪声较多和影像特征不明显的影像时存在困难。
3. 基于边缘检测的方法基于边缘检测的方法是通过计算图像像素点的梯度值进行边缘检测,整合边缘检测结果,从而得到分割图像。
这种方法可以有效的减少噪声的干扰,但是边缘浮动和断裂等问题也会导致分割结果不准确。
4. 基于机器学习的方法基于机器学习的方法利用人工智能技术,通过大量样本的训练,建立分割模型。
这种方法可以在一定程度上提高分割精度,但是需要大量的数据和计算资源。
5. 基于卷积神经网络的方法基于卷积神经网络的方法是利用深度学习技术,将大量人脑MRI影像样本输入到深度神经网络中,通过神经网络自动学习影像特征进行分割。
这种方法可以有效提高分割精度,但是需要大量的训练数据和计算资源。
三、人脑MRI影像标注方法1. 手动标注法手动标注法是一种需要专业医生对影像进行解读和标注的方法,标注精度较高。
但是手动标注过程繁琐耗时,而且标注结果可能存在主观性,经常需要多个医生复核才能得到客观准确的标注。
2. 自动标注法自动标注法是利用计算机视觉和图像处理技术,为人脑MRI影像自动标注出不同脑元素的区域。
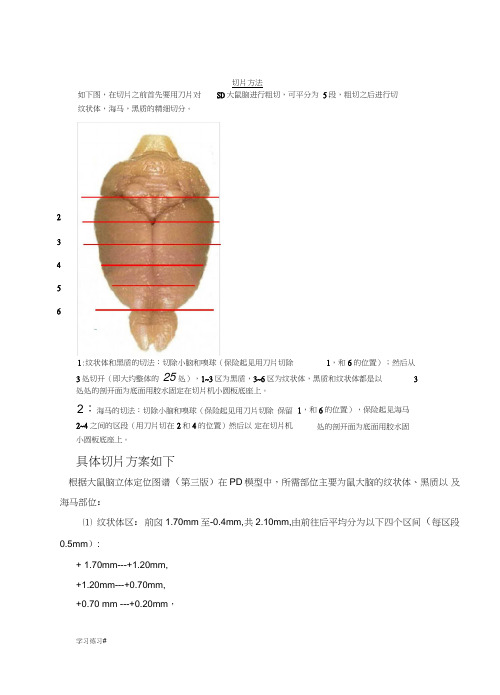
切片方法如下图,在切片之前首先要用刀片对 SD 大鼠脑进行粗切,可平分为 5段,粗切之后进行切纹状体,海马,黑质的精细切分。
3处切开(即大约整体的 25处),1~3区为黑质,3~6区为纹状体,黑质和纹状体都是以 3处处的剖开面为底面用胶水固定在切片机小圆板底座上。
2:海马的切法:切除小脑和嗅球(保险起见用刀片切除 保留2~4之间的区段(用刀片切在 2和4的位置)然后以 定在切片机小圆板底座上。
具体切片方案如下根据大鼠脑立体定位图谱(第三版)在PD 模型中,所需部位主要为鼠大脑的纹状体、黑质以 及海马部位:⑴ 纹状体区:前囟1.70mm 至-0.4mm,共2.10mm,由前往后平均分为以下四个区间(每区段 0.5mm ):+ 1.70mm---+1.20mm, +1.20mm---+0.70mm, +0.70 mm ---+0.20mm ,学习练习#1,和6的位置);然后从1,和6的位置),保险起见海马处的剖开面为底面用胶水固2 3 4 5 61:纹状体和黑质的切法:切除小脑和嗅球(保险起见用刀片切除蕊丸1乂供参肴,豆僭旋脚可测除+0.20mm ——0.40mm ,可分为四个小瓶来装片,于10ml 的棕色玻璃瓶中(内盛6ml 的0.01mM PBS,pH7.4配制 的5%多聚甲醛溶液),每个区段长度为0.50mm ,理论上可切30卩m 的脑片16张,实际保留 时至少保证12张脑片。
并从前到后标明区段1(+1.70mm-+1.20mm),区段2(+1.20mm-+0.70mm), 区段 3(+0.70mm-+0.2mm),区段 4(+0.2mm-- -0.4mm ).⑵ 黑质区:前囟-4.52mm 至-6.04mm,共1.52mm,理论上一共可切 56张30卩m 的脑片。
进入 脑区-4.16mm 后先连续切100卩m 的脑片共3片,接着切30卩m 的脑片共2张,均不保存,理论 上此时已到-4.52mm 的脑区位置。

3dunet的原理-回复3D UNet是一种先进的深度学习架构,广泛应用于医学图像分割任务中,如人脑、肺部、心脏等。
一、背景介绍医学图像分割是一项具有挑战性的任务,旨在从医学图像中准确地识别和分割出感兴趣的结构或器官。
然而,由于医学图像通常具有复杂的结构和噪声,传统的图像分割方法往往存在一些局限性。
而深度学习技术在医学图像分割中取得了巨大的突破,尤其是基于卷积神经网络(CNN)的方法。
二、基本原理3D UNet是基于FCN(Fully Convolutional Network)的改进,其主要包括编码器和解码器两个部分。
编码器用来提取图像的高级特征,而解码器则用来还原分割结果。
1. 编码器编码器由多个卷积层和池化层组成,用来逐步缩小输入图像的尺寸并提取特征。
每个卷积层后都经过非线性激活函数(如ReLU)进行激活,以增强网络的非线性能力。
编码器通过堆叠多个卷积层和池化层,在逐步缩小图像尺寸的同时逐步提取抽象的特征。
2. 解码器解码器由多个上采样和卷积层组成,用来逐步恢复特征图的空间分辨率,并生成最终的分割结果。
每个上采样层通常使用反卷积操作,可以将特征图的分辨率放大一倍。
在每个上采样层之后,还会将来自编码器相同尺寸的低级特征与解码器的高级特征进行融合,以保留更多的细节信息。
三、损失函数在3D UNet中,通常使用交叉熵损失函数来度量预测分割结果与真实分割结果之间的差异。
交叉熵损失函数在深度学习中被广泛应用,可以有效地表示预测结果的概率分布与真实结果的差异程度。
为了解决样本不平衡问题,还可以在交叉熵损失函数中引入权重因子,以平衡正负样本之间的数量差异。
四、网络训练3D UNet的训练过程通常分为两个阶段:网络初始化和后续微调。
在网络初始化阶段,通常使用一些常见的医学图像分割数据集进行预训练,以使网络具有良好的初值。
在后续微调阶段,使用目标任务的特定数据集对网络进行进一步训练,并通过反向传播算法优化网络的参数,以最大限度地减小预测结果与真实结果之间的差异。

monai分割方法
Monai是一个用于医学图像处理的开源深度学习框架。
它提供了一些用于图像分割的算法和工具,其中包括基于卷积神经网络(CNN)的方法、U-Ne.t结构、以及一些后处理技术等。
以下是Monai中常用的几种分割方法:
U-Ne.t:U-Ne.t是一种经典的医学图像分割网络,由德国的一组研究者提出。
它由一个收缩路径(编码器)和一个扩展路径(解码器)组成,形状类似于字母“U”,因此得名。
在Monai中,可以使用预训练的U-Ne.t模型进行图像分割。
3D U-Ne.t:3D U-Ne.t是一种基于3D卷积的U-Ne.t,可以处理三维的医学图像数据。
在Monai中,可以使用预训练的3D U-Ne.t模型进行三维图像分割。
Mask R-CNN:Mask R-CNN是一种基于Faster R-CNN的目标检测网络,可以同时进行目标检测和像素级图像分割。
在Monai中,可以使用预训练的Mask R-CNN模型进行图像
分割。
DeepLab:DeepLab是一种基于深度卷积神经网络的图像分割方法,可以用于处理语义分割任务。
在Monai中,可以使用预训练的DeepLab模型进行图像分割。
PSPNe.t:PSPNe.t是一种基于金字塔池化模块的图像分割方法,可以处理不同尺度的目标分割任务。
在Monai中,可以使用预训练的PSPNe.t模型进行图像分割。
以上是Monai中常用的几种分割方法,具体使用哪种方法需要根据实际任务和数据来选择。

医疗影像处理中的脑部分割技术随着计算机科学和医疗技术的不断发展,医疗影像处理在临床诊断和治疗中扮演着越来越重要的角色。
脑部分割技术作为医疗影像处理的重要应用之一,能够对脑部影像进行分割和定量分析,提供临床医生和研究人员准确的解剖结构信息,帮助诊断和治疗。
本文将介绍脑部分割技术的原理、方法和应用。
一、脑部分割技术的原理脑部分割技术是指将脑部影像分割为不同的结构或组织区域的过程。
根据影像的特点和分割的目标,脑部分割技术可以采用多种方法。
其中,常用的方法包括基于阈值的分割、区域生长法、边缘检测法和基于机器学习的分割。
基于阈值的分割是最简单常用的方法之一。
它基于图像中灰度值的不同,将图像分割为多个区域。
此法适用于影像中不同组织结构具有不同的密度和灰度值的情况。
区域生长法是基于种子点的生长过程。
从种子点开始,逐渐生长连接到相邻像素,并且满足一定灰度值条件的区域。
这种方法适用于图像中组织结构边界清晰的情况。
边缘检测法是基于图像中边缘信息的分割方法。
利用图像中灰度值的变化,检测出不同组织结构之间的边缘,并将其分割为不同区域。
这种方法适用于图像中组织结构边界明显的情况。
基于机器学习的分割是目前较为先进和常用的方法之一。
通过训练样本建立分类模型,对图像中每个像素进行分类,将其分割为不同的区域。
这种方法适用于图像中结构边界不明显的情况。
二、脑部分割技术的方法脑部分割技术的方法多种多样,根据不同的需求和具体情况选择适合的方法非常重要。
下面将介绍几种常用的脑部分割技术方法。
1. 基于体素的分割方法基于体素的分割方法是将脑部影像划分为立体体素网格,根据每个体素的特征进行分类和分割。
这种方法适用于大量数据的处理,能够准确地划分不同的脑部结构。
2. 基于曲面的分割方法基于曲面的分割方法是将脑部影像转化为曲面模型,根据曲面的形状和几何特征进行分割。
这种方法适用于需要精确描述脑部各个结构边界的情况。
3. 基于纹理的分割方法基于纹理的分割方法是根据脑部影像中组织结构的纹理特征进行分割。
专利名称:一种用于脑肿瘤图像分割的方法及系统
专利类型:发明专利
发明人:李登旺,张焱,宋卫清,黄浦,寻思怡,王建波,朱慧,柴象飞,章桦
申请号:CN202111178058.1
申请日:20211009
公开号:CN114066908A
公开日:
20220218
专利内容由知识产权出版社提供
摘要:本发明属于医学图像分割技术领域,提供了一种用于脑肿瘤图像分割的方法及系统。
其中,该方法包括提取脑肿瘤图像的多尺度信息;基于所述多尺度信息分别对脑肿瘤图像进行编码操作,以提取对应尺度信息的高语义特征并生成对应尺度信息的图像表示;从多尺度信息的图像表示中提取低语义特征,分别与所述高语义特征结合;基于空间‑通道注意力机制分别对结合的特征进行空间和通道维度的加权重标定,得到相应注意力特征;将所述注意力特征还原到原始分辨率,通过图像的特征表示得到脑肿瘤图像分割结果。
申请人:山东师范大学
地址:250014 山东省济南市历下区文化东路88号
国籍:CN
代理机构:济南圣达知识产权代理有限公司
代理人:张庆骞
更多信息请下载全文后查看。
计算机视觉中的图像分割算法与应用场景图像分割是计算机视觉领域的重要任务,其目标是将图像分割成具有语义意义的局部区域,可以理解为将图像中的物体或者物体的不同部分进行分割和识别。
图像分割广泛应用于许多领域,包括医学影像处理、工业检测、自动驾驶以及图像编辑等。
在医学影像处理中,图像分割可以通过将医学图像中的不同组织或病变区域提取出来,帮助医生进行疾病的诊断和治疗。
例如,在肺部CT图像中,通过图像分割可以准确提取出病变区域,帮助医生判断病灶的大小、位置和形状,从而更好地制定治疗方案。
在这个应用场景下,图像分割算法需要具备对病变区域和周围背景进行准确分割的能力。
在工业检测中,图像分割可以用于检测和识别产品的缺陷、异物或者其他不良情况。
例如,对于电子产品的生产线上,通过图像分割可以将产品的不良区域从正常区域分割出来,帮助生产线监测和排除次品产品。
在这个应用场景下,图像分割算法需要具备对不同种类的不良区域进行准确分割和分类的能力。
在自动驾驶中,图像分割可以帮助车辆感知道路和周围环境,从而实现自动驾驶的功能。
例如,通过图像分割可以将道路、行人、车辆等不同的物体或者区域分割出来,帮助车辆进行路径规划和行为预测。
在这个应用场景下,图像分割算法需要具备对复杂场景中的不同物体和区域进行准确分割和识别的能力。
在图像编辑中,图像分割可以用于图像的前景和背景的分离,从而方便进行图像的编辑和合成。
例如,通过图像分割可以将人物的轮廓从背景中分割出来,使得可以方便地将人物放置到不同的背景中,实现图像的合成效果。
在这个应用场景下,图像分割算法需要具备对复杂图像的前景和背景进行准确分割的能力。
图像分割算法有很多种,常见的包括基于阈值的方法、基于边缘的方法、基于区域的方法、基于图论的方法以及基于深度学习的方法等。
这些算法各有优势和适用范围。
例如,基于阈值的方法简单直观,但对于复杂图像和场景效果不佳;基于边缘的方法可以提取物体的边缘信息,但对于图像噪声和纹理复杂的区域效果不好;基于区域的方法基于对像素的相似度进行分割,效果相对较好,但对于前景和背景颜色相近或者纹理复杂的情况容易出现错误分割等。
图像语义分割算法最新发展趋势近年来,随着计算机视觉和深度学习的快速发展,图像语义分割算法也取得了显著的进展。
图像语义分割是指将图像中的每个像素标记为属于特定类别的过程,其在自动驾驶、智能辅助医疗、人机交互等领域具有重要的应用价值。
以下将介绍图像语义分割算法的最新发展趋势。
1. 基于深度学习的图像语义分割算法深度学习在图像语义分割任务中取得了巨大的成功。
传统的图像分割算法主要基于手工设计的特征和机器学习算法,而深度学习算法则通过神经网络自动学习特征和分类器。
最新的基于深度学习的图像语义分割算法采用了各种类型的神经网络结构,包括全卷积网络(Fully Convolutional Network, FCN)、编码器-解码器网络(Encoder-Decoder Network)、空洞卷积网络(Dilated Convolutional Network)等。
这些网络结构能够在不同尺度上有效地提取图像的语义信息,从而实现更准确的分割结果。
2. 融合多模态信息的图像语义分割算法除了利用图像本身的信息进行分割,最新的图像语义分割算法还试图将多模态信息(如深度图像、红外图像、激光雷达等)融合到分割过程中。
这种融合可以提供更丰富的输入特征,从而改善分割结果的准确性。
同时,多模态信息的融合也有助于解决部分单模态图像难以分割的问题。
例如,在自动驾驶领域,融合激光雷达和图像信息可以帮助精确分割道路和障碍物。
3. 弱监督学习的图像语义分割算法传统的图像语义分割算法通常需要大量标注的像素级标签数据来训练模型。
然而,标注大规模图像数据是一项耗时费力的工作。
最新的图像语义分割算法开始探索利用弱监督学习方法来降低对标注数据的依赖性。
弱监督学习方法通过利用较低精度的标签或辅助信息来训练模型,例如图像级标签、边界框或图像级标签估计。
这样可以大幅降低标注数据的需求,并且保持分割结果的准确性。
4. 增强学习在图像语义分割中的应用增强学习是指智能体通过与环境的交互来学习如何做出决策以最大化累积奖励的过程。
医学物理与工程学A ne w segmentation method for slice im ages of digital hum an brainL UO Hong 2y an13,L I Mi n 1,TA N L i 2wen 2,Z H EN G X i ao 2li n 1,Z HA N G S hao 2x iang 2,HOU Wen 2sheng1(1.B ioengineering College ,Chongqing Universit y ,Chongqing 400030,China;2.De partment of A natom y ,T hi rd M ilitary Medical Universit y ,Chongqing 400038,China )[Abstract] Objective To present a new automatic segmentation algorithm for human slice images ,in order to reduce the massive manual intervention in the existing segmentation methods 1Methods According to the features of slice images of digital human brain ,a segmentation algorithm based on the theory of region growing and threshold in normal gray histogram was proposed 1More exactly ,the slice images were initially segmented coarsely by means of the region growing 1Then the method of threshold in normal gray histogram was adopted to refine the segmentation 1R esults White matter and cerebral cortex were segmented accurately and effectively with this method 1Conclusion This algorithm characterized by the combi 2nation of global information and local information of a slice image for automatic segmentation exhibits good performance 1[K ey w ords] Slice image segmentation ;White matter ;Cerebral cortex ;Region growing[基金项目]国家自然科学基金(60771025)。
[作者简介]罗洪艳(1976—),女,四川泸州人,博士,讲师。
研究方向:医学图像处理。
[通讯作者]罗洪艳,重庆大学生物工程学院,4000030。
E 2mail :cqu_lhy @1631com[收稿日期]2009202227 [修回日期]2009203224一种数字人脑部切片图像分割新方法罗洪艳13,李 敏1,谭立文2,郑小林1,张绍祥2,侯文生1(1.重庆大学生物工程学院,重庆 400030;2.第三军医大学基础部解剖学教研室,重庆 400038)[摘 要] 目的 提出一种人脑切片图像自动分割算法,以克服现有的方法对大量人工参与的依赖。
方法 针对人脑切片图像的特征,提出一种基于区域生长的灰度直方图阈值化分割算法。
首先通过区域生长过程对图像进行初始的粗分割,再用直方图阈值化方法进行二次细分割提取目标区域。
结果 采用此方法准确有效地分割出了大脑白质和大脑皮质。
结论 此算法结合切片图像的全局信息和局部信息应用于分割,是一种比较好的分割方法。
[关键词] 切片图像分割;白质;皮质;区域生长[中图分类号] TP391 [文献标识码] A [文章编号] 100323289(2009)0821488204 人脑是人体内结构和功能最复杂的器官,是人类认识自己、了解自己的最后一座有待攻克的堡垒。
继基因组计划之后,全球启动了“人类脑计划”的国际性科研合作,我国已加入该计划并承担东方人脑的结构功能图谱研究。
该项研究的首要任务是要基于人脑切片建立精确的、可视化的数字人脑模型[1],而切片图像分割作为三维重建的基础是其中的核心步骤。
数字人研究的先驱者Victor Spitzer 曾说过,数字人研究具有三个挑战性的问题,即分割,分割,再分割[2]。
目前,对于切片图像分割,国内外多采用手工分割的方法实现,严重制约了分割的精度和速度。
彩色图像自动分割的算法很多[3],但对医学图像的分割,目前尚无一个公认的最好方法[4]。
因此,针对具体彩色图像特征开发自动化程度较高、更为准确的分割算法来实现人体切片中各解剖结构的分割,对人的结构功能图谱研究和数字人的研究具有重大的意义。
本文主要探讨人脑切片图像上的大脑白质和大脑皮质的自动分割和提取,针对其具有结构均匀、灰度对比明显等特征,提出了一种二次分割算法,即基于区域生长的灰度直方图阈值化分割算法。
此算法首先使用区域生长法对图像进行初始分割,获得较粗糙的分割结果;然后根据粗分割后图像的灰度直方图,通过设计灰度阈值的方法进行二次分割获得目标区域。
1 数据来源 本文切片图像源于第三军医大学的原创性科研成果“中国数字化可视人体数据集”。
原始切片每层厚度为011mm ,每张切片图像的记录像素为4064×2704,图片大小为6219MB ,24位真彩色图像。
脑部切片图像由香港中文大学进行了去背景处理,处理后每张图片尺寸为3872×2048,所占空间为2216M ,以bmp 格式存储。
2 分割算法算法的基本实现过程如图1所示,主要分为图像预处理、初始分割和二次分割三个部分。
所有程序的运行环境均为MA TL AB 710。
211图像预处理 首先将图像由bmp 格式转换为png 格式,再对图片进行裁减,只保留前景和部分背景。
裁剪后图像大小为426×439,所占空间为548K ,大大减少了数据量和运算量。
由于人体自身组织的影响,拍摄的图像含有较多的区域噪声[5],为降低噪声提高图像的信噪比,综合运用线性滤波和非线性滤波[6]的方法进行图像预处理。
具体方法是将彩色切片图转化为灰度图,再进行超限邻域滤波[7]、高频增强滤波[8]和中值滤波[9],这样不仅降低了噪声,而且提高了图像的边缘清晰度。
212区域生长初始分割 区域生长法的基本思想[10]是将具有相似性质的像素集合起来构成区域。
首先在目标区域内找到生长点,即种子点。
然后将生长点邻域像素中与其具有相同或相似性质的像素合并,再将这些新像素当作新的种子点继续进行判断与合并,直到所有满足条件的像素点都被合并为止。
区域生长过程中一个很大的难点就是种子点的选取,种子点选择的准确与否直接影响分割的效果。
本文将种子点分为中心种子点和辅助种子点两类:中心种子点对应目标区域中大范围的连通区域,在灰度直方图中表现为聚集在峰值周围的像素点,所以,中心种子点的选择由目标区域灰度直方图的峰值位置确定;辅助种子点的选择考虑区域的个数和连通性大小,选择典型区域内部中心位置的像素。
生长标准中阈值的选择是一个比较复杂的问题,对于不同的图像需要选择不同的阈值。
阈值选取过大,会导致区域越过目标边界,形成对前景的侵蚀或是背景残留,即造成过分割现象;如选取得太小,会导致区域生长过程停止过早,即出现欠分割的现象。
通过在区域生长准则中加入阈值条件,可以使在生长过程中灰度值差大于此阈值的像素排除在外,从而较好地解决生长过程中阈值选择困难的问题。
设f (x 0,y 0)为已生长区域S 的一个种子点像素的灰度值,f (x ,y )为图片上任意一点像素的灰度值,T 0表示选择的阈值。
当且仅当:f (x ,y )-f (x 0,y 0)<T 0(1) 可将该点(x ,y )加入区域S 中,即S =S ∪{(x ,y )}。
实验选取了若干种子点,对每一个种子点(x i ,y i )都有一个对应的阈值T i ,公式(1)改写为:f (x ,y )-f (x i ,y i )<T i (2) 对实验使用的脑部切片图像,经实验分析设定灰度阈值T =30提取大脑白质,设定灰度阈值T =15提取大脑皮质。
区域生长初始分割的过程以形态重构[11]方式辅助实现。
该方式根据一幅图像(掩模图像mask )的特征对另外一幅图像(标记图像mark )进行重复膨胀。
设计区域生长初始分割算法的主要步骤如下: (1)通过分析图像灰度直方图,交互式确定种子点像素(x i ,y i ); (2)以与种子点灰度值相同的像素点构成标记图像(mark ); (3)扫描图像,寻找满足生长条件|f (x ,y )-f (x i ,y i )|<T i 的像素点构成掩模图像(mask ); (4)根据掩模图像(mask )的特征对标记图像(mark )进行邻域膨胀,膨胀处理从标记图像的峰值点开始,进行8邻域膨胀; (5)重复膨胀过程,直到图像的像素值不再发生变化[14]。
区域生长初始分割的结果如图2所示。
由图可以看出,大脑白质和皮质的生长结果中均存在周边颅骨等多余物质的残留。
因此,必须进一步去除多余的干扰区域,才能达到比较准确地提取目标区域的目的。
213直方图阈值化二次分割 灰度直方图是将数字图像中的所有像素,按照灰度值的大小,统计其所出现的频度。
对区域生长初始分割后的图像进行灰度直方图统计,可获得其总体灰度的分布信息。
大脑白质和皮质初分割结果的灰度直方图如图3所示。
由图3可看出,区域生长后的图像用灰度直方图表示非常直观、明了。
白质初分割后的直方图,灰度级基本分布在0,012,014,016,018,110六个值上。
对比观察生长后的初分割灰度图像(图2A),可知道灰度级0对应于整个图片的黑色背景;016对应于外周的颅骨部分;而所要提取的白质目标区域主要分布在012,014,018,110这几个灰度级上。
同样,由图3B也可看出在灰度级0和0116处的像素最多,灰度级0对应于整个图像的黑色背景,而目标区域大脑皮质分布的灰度级集中于0116附近,而其余那些只集中了很少像素的灰度级则对应于大脑皮质生长过程中多余的颅骨及其他干扰物质区域。