9 最近邻元素
- 格式:ppt
- 大小:1.01 MB
- 文档页数:40
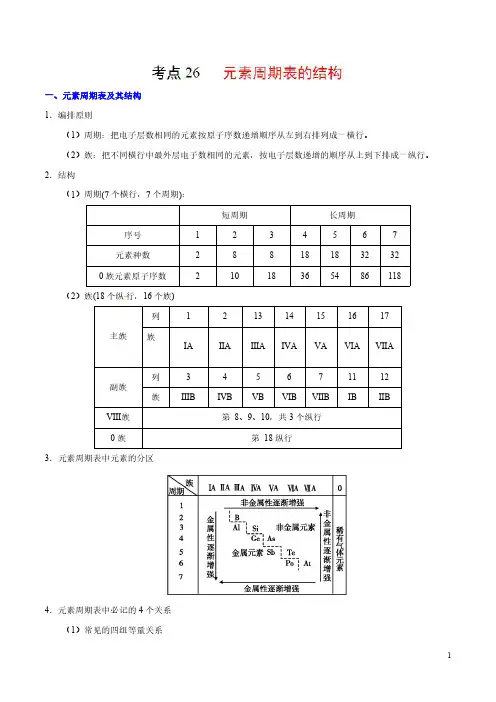
一、一、元素周期表及其结构1.编排原则(1)周期:把电子层数相同的元素按原子序数递增顺序从左到右排列成一横行。
(2)族:把不同横行中最外层电子数相同的元素,按电子层数递增的顺序从上到下排成一纵行。
2.结构(1)周期(7个横行,7个周期):短周期长周期序号1234567元素种数288181832320族元素原子序数21018365486118(2)族(18个纵行,16个族)主族列121314151617族ⅠA ⅡA ⅢA ⅣA ⅤA ⅥA ⅦA 副族列345671112族ⅢBⅣBⅤBⅥBⅦBⅠBⅡBⅧ族第8、9、10,共3个纵行0族第18纵行3.元素周期表中元素的分区4.元素周期表中必记的4个关系(1)常见的四组等量关系①核电荷数=质子数=原子序数;②核外电子层数=周期序数;③主族序数=最外层电子数=最高正价;④非金属元素:最低负价=最高正价−8。
(2)同主族元素的原子序数差的关系①位于过渡元素左侧的主族元素,即第ⅠA、第ⅡA族,同主族、邻周期元素原子序数之差为上一周期元素所在周期所含元素种数;②位于过渡元素右侧的主族元素,即第ⅢA~第ⅦA族,同主族、邻周期元素原子序数之差为下一周期元素所在周期所含元素种数。
例如,氯和溴的原子序数之差为35−17=18(溴所在第四周期所含元素的种数)。
(3)同周期第ⅡA族和第ⅢA族元素原子序数差的关系周期序数1234567原子序数差无1111112525增加了过渡元素和原因——增加了过渡元素镧系或锕系元素(4)奇偶关系①原子序数是奇数的主族元素,其所在主族序数必为奇数;②原子序数是偶数的主族元素,其所在主族序数必为偶数。
二、元素周期表的应用考向一元素周期表的结构典例1如图为元素周期表中前四周期的一部分,若B元素的核电荷数为x,则这五种元素的核电荷数之和为A.5x+10B.5x C.5x+14D.5x+16【解析】【答案】A【规律总结】同主族、邻周期元素的原子序数差的关系①ⅠA族元素,随电子层数的增加,原子序数依次相差2、8、8、18、18、32。



全国各地区消费价格增长水平的聚类分析摘要:针对我国各省(直辖)市的2009年度消费价格增长水平数据,选取9个经济指标进行系统聚类分析,得到我国3类不同的地区消费价格增长水平类型。
聚类结果为制订有针对性的地区消费市场战略提供依据。
关键词:SPSS;聚类分析;消费水平。
1.引言由于传统的经济发展起点不同,加上地域、资源、技术和政策等条件的差异,各个地区的经济发展水平高低不齐,导致各地区的工资水平和消费价格增长水平的不同。
因此,对各地区消费价格增长水平进行分类、比较和研究,总结出有助于市场调节和商业发展的对策,有针对性地制订地区经济发展战略,对促进国民经济协调发展有重要意义。
聚类分析和判别分析是是进行以上分析的两个重要的方法。
1.1聚类分析[1]定义:聚类分析又称群分析、点群分析。
根据研究对象特征对研究对象进行分类的一种多元分析技术,把性质相近的个体归为一类,使得同一类中的个体都具有高度的同质性,不同类之间的个体具有高度的异质性。
聚类分析的基本思想:我们所研究的样品或指标(变量)之间存在程度不同的相似性(亲疏关系),于是根据一批样品的多个观测指标,具体找出一些能够度量样品或指标之间相似程度的统计量,以这些统计量作为划分类型的依据,把一些相似程度较大的样品(或指标)聚合为一类,把另外一些相似程度较大的样品(或指标)又聚合为另一类;关系密切的聚合到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到把所有的样品(或指标)聚合完毕。
1.1.1 系统聚类法系统聚类法的基本原理:首先将一定数量的样本或指标各自看成一类,然后根据样本(或指标)的亲疏程度,将亲疏程度最高的两类进行合并,然后考虑合并后的类与其他类之间的亲疏程度,再进行合并。
重复这一过程,直到将所有的样本(或指标)合并为一类。
系统聚类分为Q型聚类和R型聚类两种:Q型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来;R型聚类是对变量进行聚类,它使差异性大的变量分离开来,相似的变量聚集在一起,这样就可以在相似变量中选择少数具有代表性的变量参与其他分析,实现减少变量个数、降低变量维度的目的。

第3课时元素周期表一、元素周期表的结构1.元素周期表的编排原则(1)横行原则:把电子层数目相同的元素,按原子序数递增的顺序从左到右排列。
(2)纵行原则:把不同横行中最外层电子数相同的元素,按电子层数递增的顺序由上而下排列。
2.元素周期表的结构(1)周期①数目:元素周期表有7个横行,即有7个周期。
②分类短周期:第1、2、3周期,每周期所含元素的种类数分别为2、8、8。
长周期:第4、5、6、7周期,每周期所含元素的种类数分别为18、18、32、32。
③周期数=电子层数。
(2)族①数目:元素周期表有18个纵行,但只有16个族。
②分类主族,共7个(由长、短周期元素构成,族序数后标A)。
副族,共7个(只由长周期元素构成,族序数后标B)。
第Ⅷ族,包括8、9、10三个纵行。
0族,最外层电子数是8(He是2)。
③主族序数=最外层电子数。
(3)过渡元素元素周期表中从ⅢB到ⅡB共10个纵行,包括了第Ⅷ族和全部副族元素,共60多种元素,全部为金属元素,统称为过渡元素。
(1)元素周期表的结构(2)列序数与族序数的关系①列序数<8,主族和副族的族序数=列序数;②列序数=8或9或10,为第Ⅷ族;③列序数>10,主族和副族的族序数=列序数-10(0族除外)。
例1下列关于元素周期表的说法正确的是()A.在元素周期表中,每一纵行就是一个族B.主族元素都是短周期元素C.副族元素都是金属元素D.元素周期表中每个长周期均包含32种元素考点元素周期表的结构题点元素周期表的结构答案 C解析A项,第8、9、10三个纵行为第Ⅷ族;B项,主族元素由短周期元素和长周期元素共同组成。
例2(2017·聊城高一检测)若把元素周期表原先的主副族及族号取消,由左至右改为18列,如碱金属元素为第1列,稀有气体元素为第18列。
按此规定,下列说法错误的是() A.只有第2列元素的原子最外层有2个电子B.第14列元素形成的化合物种数最多C.第3列元素种类最多D.第18列元素都是非金属元素考点元素周期表的结构题点元素周期表的结构答案 A解析周期表中各族元素的排列顺序为ⅠA、ⅡA、ⅢB→ⅦB、Ⅷ、ⅠB、ⅡB、ⅢA→ⅦA、0族,18列元素与以上对应,所以A项中为ⅡA族,最外层有2个电子,但He及多数过渡元素的最外层也是2个电子,故A项错误;第14列为碳族元素,形成化合物种类最多,故B项正确;第3列包括镧系和锕系元素,种类最多,故C项正确;第18列为稀有气体元素,全部为非金属元素,故D项正确。

实验三主成分分析、聚类分析和判别分析学院:地理科学学院专业:自然地理学姓名:郭国洋实验内容(1)中国31个省份、直辖市、自治区(不包括港澳台)经济状况的7项指标。
(2)用主成分分析剖析出影响中国大陆经济状况的主要指标,并对中国大陆的经济综合实力进行排序。
(3)用主成分剖析出的指标,用聚类分析对中国大陆的经济状况进行评价,并对每类的经济综合状况进行评价。
(4)结合本题,谈谈聚类分析和主成分分析两种方法如何结合使用来分析问题。
实验目的(1)巩固主成分和聚类分析的基本原理和方法步骤以及在实际分析中的意义。
(2)用SPSS软件完成地理的主成分分析和聚类分析。
第一部分主成分分析1 实验数据查阅2012年中国统计年鉴,数据表示2011年的指标。
得到中国31个省份、直辖市、自治区(不含港澳台)的7项经济统计指标数据,包括:总人口/10^4人,城镇人口比例/%,第一产业总产值/10^8元,工业生产总值/10^8元,公共财政预算收入/10^8元,城乡居民储蓄余额/10^8元,城镇单位就业人员工资总额/10^8元。
样本容量:31,变量:7,如图1。
2 实验步骤及分析(1)点击“分析”—“降维”—“因子分析”,将上述的7个指标选择为变量。
SPSS中的“主成分分析”嵌入到“因子分析”中,因此在操作的过程中我们要先进行因子分析。
如2。
图2 选择因子分析变量(2)依次点击“因子分析”框中的“描述”、“抽取”、“旋转”、“得分”、“选项”,勾选相应的选项,如图3、4、5、6、7所示图3抽取图4 旋转图4描述统计图5因子得分图6选项图7旋转(3)点击“确定”,得到相应的结果并分析。
图8 KMO和Bartlett检验分析:图8中,在进行因子分析之前,需要检验变量之间是否具备进行分析的条件。
由图中可知KMO值为0.787>0.5,说明数据变量之间具有结构效度,Sig<0.05,说明可以进行因子分析。
图9 公因子方差分析:图9是指全部公共因子对于变量的总方差做所的贡献,说明了全部公共因子反映出的原变量的信息的百分比。

第一章 材料科学根底1.作图表示立方晶体的()()()421,210,123晶面及[][][]346,112,021晶向。
2.在六方晶体中,绘出以下常见晶向[][][][][]0121,0211,0110,0112,0001等。
3.写出立方晶体中晶面族{100},{110},{111},{112}等所包括的等价晶面。
4.镁的原子堆积密度和所有hcp 金属一样,为。
试求镁单位晶胞的体积。
Mg 的密度3Mg/m 74.1=m g ρ,相对原子质量为,原子半径。
5.当CN=6时+Na 离子半径为,试问:1) 当CN=4时,其半径为多少?2) 当CN=8时,其半径为多少?6. 试问:在铜〔〕的<100>方向及铁(bcc,a=0.286nm)的<100>方向,原子的线密度为多少?7.镍为面心立方构造,其原子半径为nm 1246.0=Ni r 。
试确定在镍的〔100〕,〔110〕及〔111〕平面上12mm 中各有多少个原子。
8. 石英()2SiO 的密度为3Mg/m 。
试问: 1) 13m 中有多少个硅原子〔与氧原子〕?2) 当硅与氧的半径分别为与时,其堆积密度为多少〔假设原子是球形的〕?9.在800℃时1010个原子中有一个原子具有足够能量可在固体内移动,而在900℃时910个原子中那么只有一个原子,试求其激活能〔J/原子〕。
10.假设将一块铁加热至850℃,然后快速冷却到20℃。
试计算处理前后空位数应增加多少倍〔设铁中形成一摩尔空位所需要的能量为104600J 〕。
11.设图1-18所示的立方晶体的滑移面ABCD 平行于晶体的上、下底面。
假设该滑移面上有一正方形位错环,如果位错环的各段分别与滑移面各边平行,其柏氏矢量b ∥AB 。
1) 有人认为“此位错环运动移出晶体后,滑移面上产生的滑移台阶应为4个b ,试问这种看法是否正确?为什么?2)指出位错环上各段位错线的类型,并画出位错运动出晶体后,滑移方向及滑移量。

固体物理概念总结——期末考试、考研必备!!第一章1、晶体-----内部组成粒子(原子、离子或原子团)在微观上作有规则的周期性重复排列构成的固体。
晶体结构——晶体结构即晶体的微观结构,是指晶体中实际质点(原子、离子或分子)的具体排列情况。
金属及合金在大多数情况下都以结晶状态使用。
晶体结构是决定固态金属的物理、化学和力学性能的基本因素之一。
2、晶体的通性------所有晶体具有的共通性质,如自限性、最小内能性、锐熔性、均匀性和各向异性、对称性、解理性等。
3、单晶体和多晶体-----单晶体的内部粒子的周期性排列贯彻始终;多晶体由许多小单晶无规堆砌而成。
4、基元、格点和空间点阵------基元是晶体结构的基本单元,格点是基元的代表点,空间点阵是晶体结构中等同点(格点)的集合,其类型代表等同点的排列方式。
倒易点阵——是由被称为倒易点或倒易点的点所构成的一种点阵,它也是描述晶体结构的一种几何方法,它和空间点阵具有倒易关系。
倒易点阵中的一倒易点对应着空间点阵中一组晶面间距相等的点格平面。
5、原胞、WS原胞-----在晶体结构中只考虑周期性时所选取的最小重复单元称为原胞;WS原胞即Wigner-Seitz原胞,是一种对称性原胞。
6、晶胞-----在晶体结构中不仅考虑周期性,同时能反映晶体对称性时所选取的最小重复单元称为晶胞。
7、原胞基矢和轴矢----原胞基矢是原胞中相交于一点的三个独立方向的最小重复矢量;晶胞基矢是晶胞中相交于一点的三个独立方向的最小重复矢量,通常以晶胞基矢构成晶体坐标系。
8、布喇菲格子(单式格子)和复式格子------晶体结构中全同原子构成的晶格称为布喇菲格子或单式格子,由两种或两种以上的原子构成的晶格称为复式格子。
9、简单格子和复杂格子(有心化格子)------一个晶胞只含一个格点则称为简单格子,此时格点位于晶胞的八个顶角处;晶胞中含不只一个格点时称为复杂格子,其格点除了位于晶胞的八个顶角处外,还可以位于晶胞的体心(体心格子)、一对面的中心(底心格子)和所有面的中心(面心格子)。



韦特塔罗牌宝剑九(正位逆位)牌面解析1、元素:风2、占星连结:火星在双子座3、数字编号:94、生命树位置:Yesod,基础与潜意识心智的萨弗洛斯5、关键牌义:忧心焦虑一、牌面解析宝剑九,跟这个牌组其他大多数牌一样,一看就能明白其牌义。
午夜时分,一人从噩梦中惊醒,笔直坐在床上,他把脸埋在手中,显得非常痛苦。
这人身后墙上横挂着九把剑,看起来像是窗户的横条窗棂。
剑代表智慧和思想,而这里的九把剑,却象征着限制;九把剑柄交错相叠,像无用的念头挤满了整个空间。
从底端算来第三把剑,刚好横过此人的顶轮位置,对他形成一种压力;底端算来第二把剑正好刺过他的头部,最底端那把剑则刺穿他的心脏。
先从头脑思维开始,现在伤害已经深及内心,他平日慰藉的来源已经被切断,内在冲突让他感到无比痛苦。
床垫是代表直觉的浅紫色,呼应这张塔罗牌的生命树位置Yesod,受到掌管潜意识心智的月亮所主宰。
床铺或卧榻的侧面雕刻着一幅田园风景,代表他的梦境,但是风景里面的两个人物似乎并不安宁;整幅画显得气势汹汹,充满侵略意味。
其中一人挥舞着他手上的工具,似乎在对另一人进行攻击,这幅景象显示出,这位做梦者正是他本身意念思维的牺牲者。
床上的被子颜色非常鲜艳美丽,跟这张塔罗牌的黑色背景形成强烈对比,而且上面还绘有黄道十二宫星座的十二个象征符号,跟红色玫瑰共同组成一块块鲜艳的补丁图案。
这些星座符号同时出现,意指多数,而非单指个别事件,因此我们知道,此人内心的忧虑可能遍及他生命的每一个层面。
红色玫瑰是爱与希望的象征。
但是这位做噩梦的人现在看不到这些花朵,因为他用双手遮住了自己的眼睛,很像钱币五当中的那两位乞丐,他们也看不见他们头顶上方那面彩绘玻璃窗上的金钱树。
这张塔罗牌的编号是九,也是三组三的总和。
三是一个动态数字,三的倍数就是象征产量密集。
不过,在宝剑牌组当中,心智头脑的运转如果太过旺盛,则代表过度顾虑,很容易充斥担忧和负面想法。
宝剑九的占星连结是火星落在双子座,这是一个强而有力的占星组合。
第2课时元素周期表课题元素周期表课型新授课素养目标1.初步认识元素周期表,知道它是学习和研究化学的工具,能根据原子序数,在元素周期表中找到指定元素和有关该元素的一些其他信息。
2.通过展示元素周期表,让学生进一步了解元素的有关知识,并能根据原子序数在元素周期表中找到指定元素和有关该元素的一些其他的信息。
3.使学生感受到元素在人类发展中的重要作用,感受到化学学科的实践价值。
教学重点元素周期表的认识。
教学难点利用元素周期表查取一些简单信息。
课前预习1.元素周期表共有7个横行,18个纵行,每一个横行叫作一个周期,每一个纵行叫作一个族(8、9、10三个纵列共同组成一个族)。
2.元素周期表按元素原子核电荷数递增的顺序给元素编的序号,叫作原子序数。
元素的原子序数与原子的核电荷数在数值上相同。
新课导入超市中的商品成千上万种,为了便于顾客选购,必须将商品分门别类、有序地摆放。
同样组成物质的一百多种元素,为了便于研究元素的性质和用途,也需将它们按其内在规律排列。
那么这一百多种元素是按怎样的规律排列的呢?进行新课知识点一、元素周期表[简介]许多化学家致力于元素周期表的创作,尤其是俄国化学家门捷列夫。
他在前人工作的基础上,提出了独到的见解,为元素周期表的完成作出了巨大的贡献。
我们现在就来学习有关元素周期表的知识。
[提问]元素周期表中每一格所含有的信息有哪些?[回答]在元素周期表中,每一种元素均占据一格。
对于每一格,均包含元素的原子序数、元素符号、元素名称、相对原子质量等内容。
备课笔记课堂拓展:随着原子序数的递增,原子最外层上的电子数由1递增到8(或2),达到稀有气体原子的相对稳定结构,然后又重新出现原子最外层电子数从1递增到8的变化规律,这种呈规律性的变化就是“元素周期表”名称的来源。
进行新课[提问]关于核电荷数我们学过什么等量关系?[回答]核电荷数=核内质子数=核外电子数[分析]原子序数和核电荷数在数值上相等,所以我们可将以上等量关系拓展为如下等量关系:原子序数=核电荷数=核内质子数=核外电子数[提问]在元素周期表中有几个横行和纵行,分别叫什么?[回答]元素周期表每一横行叫作一个周期,每一个纵行叫作一族。
最近邻体距离法matlab最近邻体距离法(Nearest Neighbor Distance Method)是一种用来确定点的空间聚集程度的方法。
该方法最初由Ripley(1979)提出,被广泛应用于点模式分析中,以确定地理空间上某一区域内点的密度和集聚程度。
在Matlab中,实现最近邻体距离法十分简单,下面我们来一步步讲解。
1. 数据准备首先,需要准备数据,这里我们用一个二维矩阵来存储数据。
假设我们有50个点,每个点有x、y坐标,那么可以这样定义矩阵:``` matlabdata = rand(50,2); % 随机生成50个点,每个点有两个坐标```上面的代码中,rand函数生成一个50行2列的随机矩阵,每个元素的值在0~1之间。
2. 计算最近邻距离接下来,我们需要计算每个点的最近邻距离。
在Matlab中,可以使用pdist2函数来计算每个点对之间的欧几里得距离,并找到每个点最近的一个邻居。
``` matlabD = pdist2(data,data); % 计算每个点对之间的欧几里得距离D(logical(eye(size(D)))) = Inf; % 将自身到自身的距离设为无限大[minDist,~] = min(D); % 找到每个点的最近邻距离```上面的代码中,我们调用pdist2函数计算任意两个点之间的欧几里得距离,并将自身到自身的距离设为无限大。
然后使用min函数找到每个点到其最近邻的距离。
3. 绘制分布函数最后,我们可以使用hist函数绘制最近邻距离的分布函数。
分布函数是指对数据进行积累分析并绘制出得到的分布图形,可以帮助我们更直观地观察数据的分布情况。
``` matlabbins = [0.05:0.1:1]; % 设置分组范围和间隔[counts,~] = histcounts(minDist,bins); % 统计最近邻距离在各分组的出现次数F = cumsum(counts) / sum(counts); % 计算分布函数plot(bins(2:end),F); % 绘制分布函数曲线xlabel('最近邻距离'); % 设置x轴标签ylabel('分布函数'); % 设置y轴标签```上面的代码中,我们使用histcounts函数统计最近邻距离在各个分组中的出现次数,并计算积累次数占比。
使⽤KNN(邻近算法)进⾏模型评估(实战篇-1)之所以想写这篇⽂章,是我许久以来⼀直想把Modeler和SPSS应⽤在⽬前的玩家数据分析和购买充值分析⽅⾯,游戏数据分析针对的群体其实和电信,互联⽹,电⼦商务很像,属于虚拟经济的分⽀,并且要通过数据化的⼿段,结合企业⾃⾝的BI建设及企业数据分析⼈员的研究解决⼀些棘⼿的问题。
KNN作为⼀种分类算法的应⽤领域很宽,很⼴,尽管没有归纳树,后向传播等那么得⼼应⼿,不过还是要学习的和使⽤的。
KNN可以应⽤在对新⽅案的评估和预测⽅⾯,当然要结合已有的样本(训练数据)进⾏对测试数据的分类和预测,这样就能够完成诸如电信新增套餐的制定,FPS同系列武器的更新把握和销售预计等等。
KNN(k-Nearest Neighbor algorithm )分类算法是最简单的机器学习算法之⼀,采⽤向量空间模型来分类,概念为相同类别的案例,彼此的相似度⾼,⽽可以借由计算与已知类别案例之相似度,来评估未知类别案例可能的分类。
KNN根据某些样本实例与其他实例之间的相似性进⾏分类。
特征相似的实例互相靠近,特征不相似的实例互相远离。
因⽽,可以将两个实例间的距离作为他们的“不相似度”的⼀种度量标准。
KNN模型可以⽀持两种⽅法计算实例间距离,他们分别是:Euclidean Distance( 欧⽒距离法 ) 和 City-block Distance(城区距离法)。
百度百科:如果⼀个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别。
KNN算法中,所选择的邻居都是已经正确分类的对象。
该⽅法在定类决策上只依据最邻近的⼀个或者⼏个样本的类别来决定待分样本所属的类别。
KNN⽅法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。
由于KNN⽅法主要靠周围有限的邻近的样本,⽽不是靠判别类域的⽅法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN⽅法较其他⽅法更为适合。