最近邻方法与KNN
- 格式:ppt
- 大小:217.00 KB
- 文档页数:8

最近邻算法
最近邻算法(k-Nearest Neighbor Algorithm,KNN)是一种基于实例的学习或懒惰学习算法,它允许计算机系统“学习”在给定的训练集上的输入实例的属性与相应的类标号之间的关系,从而实现对新的数据实例进行分类。
KNN算法是一种被称作非参数学习法的监督学习方法,该方法不需要事先对数据进行定量化和标准化处理,也不涉及参数估计,大大简化了模型的构建过程。
KNN算法的基本思想十分简单:给定一个新的实例,将其与训练样本中的所有数据进行比较,然后依据一定的距离度量准则将新的实例分配给与其最为相似的那些训练样本所对应的类别。
KNN算法的实现原理很容易理解,但是在实际应用中,它却是一种高效的分类算法。
该算法能够从无序的、高维度的数据集中提取出有用的类别信息,使用者只需少量参数调节以及短暂的训练过程便可得到一个完整的建模。
KNN算法是一种基于实例的学习,主要由两步组成:第一步是计算两个实例之间的“距离”,第二步是根据距离选取“k”个最邻近的实例,并将其类标号合并以形成最终的预测类标号。
当新的数据实例到达时,KNN算法可以计算与该实例的每一个已知实例的距离,选择与该实例距离最近的K个实例来投票确定该新实例的类别标号。
KNN算法具有训练速度快、容易理解、可解释性高、支持多样性等优点,因此近年来得到了越来越多的应用。
然而,KNN算法也存在一些缺点,如计算复杂度高、空间开销不稳定以及容易受到噪声影响等。

1.简述k最近邻算法的原理、算法流程以及优缺点一、什么是K近邻算法k近邻算法又称knn算法、最近邻算法,是一种用于分类和回归的非参数统计方法。
在这两种情况下,输入包含特征空间中的k个最接近的训练样本,这个k可以由你自己进行设置。
在knn分类中,输出是一个分类族群。
一个对象的分类是由其邻居的“多数表决”确定的,k个最近邻居(k为正整数,通常较小),所谓的多数表决指的是,在k个最近邻中,取与输入的类别相同最多的类别,作为输入的输出类别。
简而言之,k近邻算法采用测量不同特征值之间的距离方法进行分类。
knn算法还可以运用在回归预测中,这里的运用主要是指分类。
二、k近邻算法的优缺点和运用范围优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用范围:数值型和标称型、如手写数字的分类等。
三、k近邻算法的工作原理假定存在一个样本数据集合,并且样本集中的数据每个都存在标签,也就是说,我们知道每一个样本数据和标签的对应关系。
输入一个需要分类的标签,判断输入的数据属于那个标签,我们提取出输入数据的特征与样本集的特征进行比较,然后通过算法计算出与输入数据最相似的k个样本,取k个样本中,出现次数最多的标签,作为输入数据的标签。
四、k近邻算法的一般流程(1)收集数据:可以使用任何方法,可以去一些数据集的网站进行下载数据。
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式(3)分析数据:可以使用任何方法(4)训练算法:此步骤不适用于k近邻算法(5)测试算法:计算错误率(6)使用算法:首先需要输入样本数据和结构化的输出结构(统一数据格式),然后运行k近邻算法判定输入数据属于哪一种类别。
五、k近邻算法的实现前言:在使用python实现k近邻算法的时候,需要使用到Numpy科学计算包。
如果想要在python中使用它,可以按照anaconda,这里包含了需要python需要经常使用到的科学计算库,如何安装。

什么是计算机模式识别请解释几种常见的算法什么是计算机模式识别?请解释几种常见的算法计算机模式识别是一种利用计算机技术来识别和分类不同模式的方法。
模式是指事物之间的某种形式、结构、特征或行为的概念。
计算机模式识别广泛应用于图像识别、语音识别、文字识别等领域,对人类视觉、听觉和认知等感知过程进行仿真,以实现机器对模式的自动识别和理解。
计算机模式识别中常见的算法有:1. 最近邻算法(K-Nearest Neighbors, KNN)最近邻算法是一种基本的分类算法。
它的思想是如果一个样本在特征空间中的K个最相似的样本中的大多数属于某个类别,那么该样本也可以划分为这个类别。
最近邻算法主要通过计算样本之间的距离来进行分类决策,距离可以使用欧氏距离、曼哈顿距离等。
2. 决策树算法(Decision Tree)决策树算法是一种基于树形结构的分类算法。
它通过一系列的判断问题构建一棵树,每个内部节点代表一个问题,每个叶子节点代表一个类别。
决策树算法通过划分样本空间,使得每个子空间内样本的类别纯度最大化。
常用的决策树算法包括ID3算法、C4.5算法、CART 算法等。
3. 支持向量机算法(Support Vector Machines, SVM)支持向量机算法是一种二类分类算法。
它通过构建一个超平面,使得离该超平面最近的一些样本点(即支持向量)到超平面的距离最大化。
支持向量机算法可以用于线性可分问题和非线性可分问题,通过核函数的引入可以将低维特征空间映射到高维特征空间,提高模型的表达能力。
4. 朴素贝叶斯算法(Naive Bayes)朴素贝叶斯算法是一种基于贝叶斯定理和特征条件独立性假设的分类算法。
它通过计算样本的后验概率来进行分类决策,选择后验概率最大的类别作为样本的分类结果。
朴素贝叶斯算法在文本分类、垃圾邮件过滤等任务中得到了广泛应用。
5. 神经网络算法(Neural Networks)神经网络算法是一种模拟人类神经系统进行学习和决策的模式识别算法。
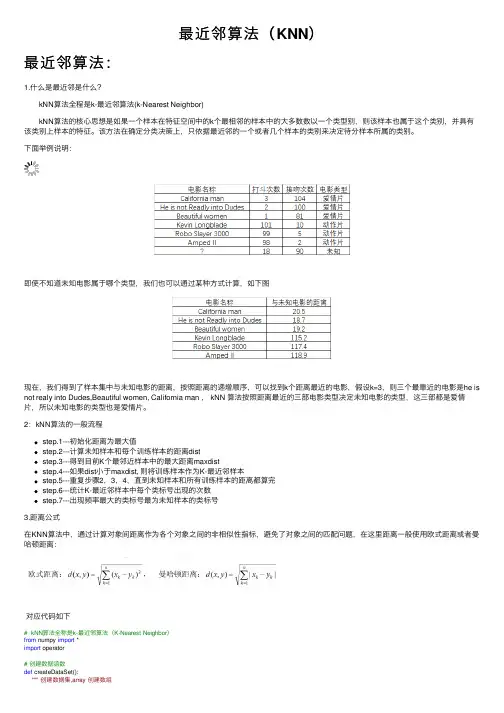
最近邻算法(KNN)最近邻算法:1.什么是最近邻是什么? kNN算法全程是k-最近邻算法(k-Nearest Neighbor) kNN算法的核⼼思想是如果⼀个样本在特征空间中的k个最相邻的样本中的⼤多数数以⼀个类型别,则该样本也属于这个类别,并具有该类别上样本的特征。
该⽅法在确定分类决策上,只依据最近邻的⼀个或者⼏个样本的类别来决定待分样本所属的类别。
下⾯举例说明:即使不知道未知电影属于哪个类型,我们也可以通过某种⽅式计算,如下图现在,我们得到了样本集中与未知电影的距离,按照距离的递增顺序,可以找到k个距离最近的电影,假设k=3,则三个最靠近的电影是he is not realy into Dudes,Beautiful women, California man , kNN 算法按照距离最近的三部电影类型决定未知电影的类型,这三部都是爱情⽚,所以未知电影的类型也是爱情⽚。
2:kNN算法的⼀般流程step.1---初始化距离为最⼤值step.2---计算未知样本和每个训练样本的距离diststep.3---得到⽬前K个最邻近样本中的最⼤距离maxdiststep.4---如果dist⼩于maxdist, 则将训练样本作为K-最近邻样本step.5---重复步骤2,3,4,直到未知样本和所有训练样本的距离都算完step.6---统计K-最近邻样本中每个类标号出现的次数step.7---出现频率最⼤的类标号最为未知样本的类标号3.距离公式在KNN算法中,通过计算对象间距离作为各个对象之间的⾮相似性指标,避免了对象之间的匹配问题,在这⾥距离⼀般使⽤欧式距离或者曼哈顿距离:对应代码如下# kNN算法全称是k-最近邻算法(K-Nearest Neighbor)from numpy import *import operator# 创建数据函数def createDataSet():""" 创建数据集,array 创建数组array数组内依次是打⽃次数, 接吻次数group⼩组, labels标签"""group = array([[3, 104], [2, 100], [1, 81], [101, 10], [99, 5], [98, 2]])labels = ["爱情⽚", "爱情⽚", "爱情⽚", "动作⽚", "动作⽚", "动作⽚"]return group, labels# 归类函数def classify(inX, dataSet, labels, k):""" 获取维度,inX 待测⽬标的数据,dataSet 样本数据,labels 标签,k 设置⽐较邻近的个数"""dataSetSize = dataSet.shape[0] # 训练数据集数据⾏数print(dataSetSize)print(tile(inX, (dataSetSize, 1)))diffMat = tile(inX, (dataSetSize, 1)) - dataSet # 测试数据,样本之间的数据矩阵偏差print(diffMat)sqDiffMat = diffMat**2 # 平⽅计算,得出每个距离的值print(sqDiffMat)sqDistance = sqDiffMat.sum(axis=1) # 输出每⾏的值print(sqDistance)distances = sqDistance**0.5 # 开⽅计算print(distances)sortedDistances = distances.argsort() # 排序按距离从⼩到⼤输出索引print(sortedDistances)classCount = {}for i in range(k):voteIlabel = labels[sortedDistances[i]] + 1.0 # 按照排序,获取k个对应的标签classCount[voteIlabel] = classCount.get(voteIlabel, 0) # 在字典中添加距离最近的k个对应标签 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0]group, labels = createDataSet()res = classify([18, 90], group, labels, 3)print(res)运⾏结果:知识扩展:。

knn算法的分类规则目录1.KNN 算法简介2.KNN 算法的分类规则3.KNN 算法的优缺点4.KNN 算法的应用实例正文1.KNN 算法简介KNN(k-Nearest Neighbors,k-近邻)算法是一种基于距离度量的分类和回归方法。
该算法的基本思想是:在一个数据集中,每个数据点根据其距离其他数据点的距离进行分类。
具体而言,KNN 算法会找到距离目标数据点最近的 k 个数据点,然后根据这些邻居的数据类别决定目标数据点的类别。
2.KNN 算法的分类规则KNN 算法的分类规则非常简单,可以概括为以下三个步骤:(1)计算数据点之间的距离:首先,需要计算数据集中每个数据点之间的距离。
通常使用欧氏距离、曼哈顿距离等度量方法。
(2)确定邻居数据点:根据距离度量,找到距离目标数据点最近的 k 个数据点。
这里 k 是一个超参数,可以根据实际问题和数据集的特点进行选择。
(3)决定目标数据点的类别:根据邻居数据点的类别,决定目标数据点的类别。
如果邻居数据点的类别多数为某一类别,则目标数据点也被划分为该类别;否则,目标数据点不被划分为任何类别。
3.KNN 算法的优缺点KNN 算法的优点包括:简单易懂、易于实现、对数据集的噪声不敏感、能够很好地处理不同密度的数据等。
然而,KNN 算法也存在一些缺点,如计算量大、需要存储所有数据点、对 k 的选择敏感等。
4.KNN 算法的应用实例KNN 算法在许多领域都有广泛的应用,例如文本分类、图像分类、生物信息学、金融风险管理等。
例如,在文本分类任务中,可以将文本表示为特征向量,然后使用 KNN 算法根据特征向量的距离对文本进行分类。
总之,KNN 算法是一种简单且易于实现的分类方法,适用于各种数据集和领域。

算法,可以说是很多技术的核心,而数据挖掘也是这样的。
数据挖掘中有很多的算法,正是这些算法的存在,我们的数据挖掘才能够解决更多的问题。
如果我们掌握了这些算法,我们就能够顺利地进行数据挖掘工作,在这篇文章我们就给大家简单介绍一下数据挖掘的经典算法,希望能够给大家带来帮助。
1.KNN算法KNN算法的全名称叫做k-nearest neighbor classification,也就是K最近邻,简称为KNN算法,这种分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:如果一个样本在特征空间中的k个最相似,即特征空间中最邻近的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法常用于数据挖掘中的分类,起到了至关重要的作用。
2.Naive Bayes算法在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBC)。
朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。
同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
理论上,NBC模型与其他分类方法相比具有最小的误差率。
但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。
而在属性相关性较小时,NBC模型的性能最为良好。
这种算法在数据挖掘工作使用率还是挺高的,一名优秀的数据挖掘师一定懂得使用这一种算法。
3.CART算法CART 也就是Classification and Regression Trees。
就是我们常见的分类与回归树,在分类树下面有两个关键的思想。
第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。

机器学习--K近邻(KNN)算法的原理及优缺点⼀、KNN算法原理 K近邻法(k-nearst neighbors,KNN)是⼀种很基本的机器学习⽅法。
它的基本思想是:在训练集中数据和标签已知的情况下,输⼊测试数据,将测试数据的特征与训练集中对应的特征进⾏相互⽐较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
由于KNN⽅法主要靠周围有限的邻近的样本,⽽不是靠判别类域的⽅法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN⽅法较其他⽅法更为适合。
KNN算法不仅可以⽤于分类,还可以⽤于回归。
通过找出⼀个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
更有⽤的⽅法是将不同距离的邻居对该样本产⽣的影响给予不同的权值(weight),如权值与距离成反⽐。
KNN算法的描述: (1)计算测试数据与各个训练数据之间的距离; (2)按照距离的递增关系进⾏排序; (3)选取距离最⼩的K个点; (4)确定前K个点所在类别的出现频率 (5)返回前K个点中出现频率最⾼的类别作为测试数据的预测分类。
算法流程: (1)准备数据,对数据进⾏预处理。
(2)选⽤合适的数据结构存储训练数据和测试元组。
(3)设定参数,如k。
(4)维护⼀个⼤⼩为k的的按距离由⼤到⼩的优先级队列,⽤于存储最近邻训练元组。
随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存⼊优先级队列。
(5)遍历训练元组集,计算当前训练元组与测试。
元组的距离,将所得距离L 与优先级队列中的最⼤距离Lmax。
(6)进⾏⽐较。
若L>=Lmax,则舍弃该元组,遍历下⼀个元组。
若L < Lmax,删除优先级队列中最⼤距离的元组,将当前训练元组存⼊优先级队列。
(7)遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。

13种ai智能算法以下是13种常见的AI智能算法:1.K-近邻算法(K-Nearest Neighbors,KNN):根据周围K个最近邻的类别来预测未知数据的类别。
K值的选择和距离度量方式对结果影响较大。
2.决策树算法(Decision Trees):通过将数据集划分为若干个子集,并根据每个子集的特征进行进一步的划分,从而构建一棵树状结构。
决策树的分支准则通常基于信息增益或信息熵等指标。
3.随机森林算法(Random Forests):通过构建多个决策树,并对它们的预测结果进行投票来预测未知数据的类别。
随机森林算法能够提高预测的准确性和稳定性。
4.梯度提升树算法(Gradient Boosting Trees,GBRT):通过迭代地添加新的决策树来优化损失函数,从而逐步提高预测的准确性。
梯度提升树算法通常能够处理非线性关系和解决过拟合问题。
5.支持向量机算法(Support Vector Machines,SVM):通过将数据映射到高维空间中,并寻找一个超平面将不同类别的数据分隔开来。
SVM算法通常用于分类和回归任务。
6.线性回归算法(Linear Regression):通过拟合一个线性模型来预测连续数值型数据的目标变量。
线性回归算法可以解决回归问题,即预测数值型目标变量。
7.逻辑回归算法(Logistic Regression):通过拟合一个逻辑函数来预测离散二元型数据的目标变量。
逻辑回归算法可以解决分类问题,即预测离散二元型目标变量。
8.朴素贝叶斯算法(Naive Bayes):基于贝叶斯定理和特征条件独立假设来预测未知数据的类别。
朴素贝叶斯算法通常用于文本分类和垃圾邮件过滤等任务。
9.集成学习算法(Ensemble Learning):通过将多个学习模型(如决策树、SVM等)的预测结果进行集成,从而提高预测的准确性和稳定性。
常见的集成学习算法有Bagging和Boosting两种类型。
10.决策树桩算法(Decision Stump):通过对每个特征进行一次划分来构建一个单层决策树,从而简化决策树的构建过程。

KNN(K近邻法)算法原理⼀、K近邻概述k近邻法(k-nearest neighbor, kNN)是⼀种基本分类与回归⽅法(有监督学习的⼀种),KNN(k-nearest neighbor algorithm)算法的核⼼思想是如果⼀个样本在特征空间中的k(k⼀般不超过20)个最相邻的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
简单地说,K-近邻算法采⽤测量不同特征值之间的距离⽅法进⾏分类。
通常,在分类任务中可使⽤“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;在回归任务中可使⽤“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;还可基于距离远近进⾏加权平均或加权投票,距离越近的实例权重越⼤。
k近邻法不具有显式的学习过程,事实上,它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进⾏处理K近邻算法的优缺点:优点:精度⾼、对异常值不敏感、⽆数据输⼊假定缺点:计算复杂度⾼、空间复杂度⾼适⽤数据范围:数值型和标称型⼆、K近邻法的三要素距离度量、k值的选择及分类决策规则是k近邻法的三个基本要素。
根据选择的距离度量(如曼哈顿距离或欧⽒距离),可计算测试实例与训练集中的每个实例点的距离,根据k值选择k个最近邻点,最后根据分类决策规则将测试实例分类。
根据欧⽒距离,选择k=4个离测试实例最近的训练实例(红圈处),再根据多数表决的分类决策规则,即这4个实例多数属于“-类”,可推断测试实例为“-类”。
k近邻法1968年由Cover和Hart提出1.距离度量特征空间中的两个实例点的距离是两个实例点相似程度的反映。
K近邻法的特征空间⼀般是n维实数向量空间Rn。
使⽤的距离是欧⽒距离,但也可以是其他距离,如更⼀般的Lp距离或Minkowski距离Minkowski距离(也叫闵⽒距离):当p=1时,得到绝对值距离,也称曼哈顿距离(Manhattan distance),在⼆维空间中可以看出,这种距离是计算两点之间的直⾓边距离,相当于城市中出租汽车沿城市街道拐直⾓前进⽽不能⾛两点连接间的最短距离,绝对值距离的特点是各特征参数以等权参与进来,所以也称等混合距离当p=2时,得到欧⼏⾥德距离(Euclidean distance),就是两点之间的直线距离(以下简称欧⽒距离)。

最近邻算法(KNN)
KNN算法的步骤如下:
1.计算距离:计算测试样本与训练样本之间的距离,常用的距离度量
方法有欧氏距离、曼哈顿距离、余弦相似度等,选择合适的距离度量方法
是KNN算法的重要一环。
2.选择K值:确定K的取值,即选择最近的K个邻居来进行分类或回归。
K的取值通常是根据实际应用和数据集来确定的,一般选择较小的K
值会使模型更复杂,较大的K值会使模型更简单。
3.排序:根据计算得到的距离,对训练样本进行排序,选择距离最近
的K个邻居。
KNN算法的优点包括简单易懂、不需要训练过程、适用于多分类和回
归问题。
然而,KNN算法也有一些缺点。
首先,KNN算法需要计算测试样
本和所有训练样本之间的距离,当训练样本很大时,计算量可能会很大。
其次,KNN算法对于样本不平衡的数据集可能会造成预测结果偏向多数类别。
此外,KNN算法对于特征空间的密度变化敏感,如果样本分布不均匀,可能会影响预测结果。
为了提高KNN算法的性能,可以采取一些优化措施。
例如,可以使用
特征选择或降维方法来减少特征维度,以降低计算复杂度。
此外,可以使
用KD树、球树等数据结构来存储训练样本,以加速近邻的过程。
还可以
使用加权投票或距离加权的方法来考虑邻居之间的权重,使得距离更近的
邻居具有更大的影响力。
总之,最近邻算法(KNN)是一种简单而有效的分类和回归算法,具有广泛的应用。
虽然KNN算法有一些缺点,但通过适当的优化和改进,可以提高其性能并有效解决实际问题。

r语言knn近邻算法填补缺失值在R语言中,K最近邻(KNN)算法可以用来填补缺失值。
KNN 算法是一种监督学习算法,它通过计算特征空间中样本点之间的距离来进行分类或回归。
在填补缺失值的情况下,KNN算法可以根据样本点之间的相似性来估计缺失值。
首先,我们需要加载相关的R包,比如"impute"或者"caret"。
这些包中包含了KNN算法的实现。
接下来,我们需要准备包含缺失值的数据集。
假设我们有一个数据框df,其中包含了缺失值。
我们可以使用以下代码来填补缺失值:R.library(impute) # 加载impute包。
# 假设df是包含缺失值的数据框。
# 使用KNN算法填补缺失值。
df_filled <impute.knn(df)。
另一种方法是使用"caret"包中的KNN算法来填补缺失值。
下面是一个示例:R.library(caret) # 加载caret包。
# 创建一个预处理对象。
preProcessObj <preProcess(df, method = "knnImpute")。
# 使用预处理对象来填补缺失值。
df_filled <predict(preProcessObj, newdata = df)。
在这两个示例中,我们使用了KNN算法来填补缺失值。
需要注意的是,KNN算法的性能可能会受到K值的影响,因此在实际应用中需要进行参数调优。
另外,KNN算法对数据的标准化也很敏感,因此在使用KNN填补缺失值之前,通常需要对数据进行标准化处理。
总的来说,使用R语言中的KNN算法来填补缺失值是一种常见且有效的方法。
通过计算样本点之间的相似性,KNN算法可以很好地估计缺失值,从而提高数据集的完整性和可用性。
最近邻算法计算公式最近邻算法(K-Nearest Neighbors algorithm,简称KNN算法)是一种常用的分类和回归算法。
该算法的基本思想是:在给定一个新的数据点时,根据其与已有的数据点之间的距离来判断其类别或预测其数值。
KNN算法的计算公式可以分为两个部分:距离计算和分类预测。
一、距离计算:KNN算法使用欧氏距离(Euclidean Distance)来计算数据点之间的距离。
欧氏距离是指在m维空间中两个点之间的直线距离。
假设有两个数据点p和q,p的坐标为(p1, p2, ..., pm),q的坐标为(q1, q2, ..., qm),则p和q之间的欧氏距离为:d(p, q) = sqrt((p1-q1)^2 + (p2-q2)^2 + ... + (pm-qm)^2)其中,sqrt表示求平方根。
二、分类预测:KNN算法通过比较距离,根据最近的K个邻居来进行分类预测。
假设有N个已知类别的数据点,其中k个属于类别A,另外K个属于类别B,要对一个新的数据点p进行分类预测,KNN算法的步骤如下:1.计算p与每个已知数据点之间的距离;2.根据距离的大小,将距离最近的K个邻居选取出来;3.统计K个邻居中每个类别的数量;4.根据数量的大小,将p分为数量最多的那个类别。
如果数量相同,可以通过随机选择或其他规则来决定。
其中,K是KNN算法的一个参数,表示选取最近的K个邻居进行分类预测。
K的选择通常是基于经验或交叉验证等方法来确定的。
较小的K值会使模型更加灵敏,但也更容易受到噪声的影响,较大的K值会使模型更加稳健,但也更容易混淆不同的类别。
总结起来,KNN算法的计算公式可以表示为:1.距离计算公式:d(p, q) = sqrt((p1-q1)^2 + (p2-q2)^2 + ... + (pm-qm)^2)2.分类预测步骤:1)计算p与每个已知数据点之间的距离;2)根据距离的大小,选取距离最近的K个邻居;3)统计K个邻居中每个类别的数量;4)将p分为数量最多的那个类别。
knn算法的基本原理
knn算法是一种基于实例的学习算法,也被称为最近邻算法。
其基本原理是:给定一个测试样本,从训练数据集中找到与之最相似的k个样本,然后通过对这k 个样本的标签进行综合评价,来确定该测试样本的类别。
具体实现步骤如下:
1. 将训练样本和测试样本表示为向量。
2. 根据所采用的距离度量方法,计算测试样本与训练样本之间的距离。
3. 选出距离测试样本最近的k个训练样本。
4. 对这k个样本的标签进行统计分析,选出出现次数最多的标签作为测试样本的预测标签。
5. 输出测试样本的预测标签。
knn算法的关键在于距离的计算和k值的确定。
距离计算通常采用欧几里得距离、曼哈顿距离等。
k值的确定要根据数据集的特点和实际需求进行调整。
在k过小时,会产生过拟合的现象;而当k过大时,又会产生欠拟合的现象。
因此,k值的选择需要平衡过拟合和欠拟合之间的关系。
机器学习中常用的监督学习算法介绍机器学习是人工智能领域的一个重要分支,它致力于研究如何使计算机具有学习能力,从而从数据中获取知识和经验,并用于解决各种问题。
监督学习是机器学习中最常见和基础的学习方式之一,它通过将输入数据与对应的输出标签进行配对,从而训练模型以预测新数据的标签。
在本文中,我们将介绍几种常用的监督学习算法及其特点。
1. 决策树(Decision Tree)决策树是一种基于树状结构来进行决策的监督学习算法。
在决策树中,每个节点表示一个特征,每个分支代表该特征的一个可能取值,而每个叶子节点则代表一个类别或输出。
决策树的优点是易于理解和解释,同时可以处理具有离散和连续特征的数据。
然而,它容易产生过拟合问题,需要进行剪枝等处理。
2. 朴素贝叶斯(Naive Bayes)朴素贝叶斯是一种基于贝叶斯定理和特征条件独立假设的分类算法。
它假设特征之间相互独立,并根据已知数据计算后验概率,从而进行分类。
朴素贝叶斯算法具有较好的可扩展性和高效性,并且对于处理大规模数据集非常有效。
然而,它的假设可能与实际数据不符,导致分类结果不准确。
3. 最近邻算法(K-Nearest Neighbors,KNN)最近邻算法是一种基于实例的学习算法,它通过计算新数据点与训练样本集中各个数据点的距离,然后将新数据点分类为距离最近的K个数据点中的多数类别。
最近邻算法简单易懂,并且可以用于处理多类别问题。
然而,它的计算复杂度高,对于大规模数据集的处理效率较低。
4. 逻辑回归(Logistic Regression)逻辑回归是一种广义线性模型,主要用于解决二分类问题。
它通过将输入数据进行映射,并使用逻辑函数(常用的是sigmoid函数)将输入与输出进行转换。
逻辑回归模型可以用于预测某个样本属于某个类别的概率,并进行分类。
逻辑回归具有较好的可解释性和预测性能,同时支持处理连续和离散特征。
5. 支持向量机(Support Vector Machines,SVM)支持向量机是一种常用的二分类算法,其目标是找到一个可以将不同类别的数据最大程度地分离的超平面。
基于邻域的算法基于邻域的算法是一种常用的数据挖掘和机器学习方法,它主要是基于某个样本的邻居来推断该样本的特征或标签。
在实际应用中,基于邻域的算法被广泛应用于分类、聚类、推荐系统等领域。
基于邻域的算法有很多种,其中最常见的包括k最近邻算法、均值漂移算法和DBSCAN算法等。
下面将分别介绍这几种算法的原理和应用。
1. k最近邻算法(k-Nearest Neighbor,简称kNN)是最简单、最常用的基于邻域的算法之一。
其基本原理是通过计算待分类样本与训练集中各个样本之间的距离,找出距离最近的k个邻居,然后根据这k个邻居的标签来预测待分类样本的标签。
kNN算法适用于多分类和二分类问题,且对样本的分布情况没有太高要求。
2. 均值漂移算法(Mean Shift)是一种基于邻域密度的密度估计方法。
其原理是通过计算样本点周围邻域内点的密度分布情况,将样本点向密度高的方向移动,直到达到局部最大密度。
均值漂移算法的应用比较广泛,包括图像分割、无监督聚类等。
3. DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,可以自动发现具有各种形状的聚类,并能够将孤立点(噪声)排除在外。
该算法的核心是通过计算样本点周围邻域内的密度,并通过设置一定的密度阈值和最小样本数来划分聚类。
DBSCAN算法广泛应用于图像分割、异常检测等领域。
基于邻域的算法有以下几个特点:1. 算法简单易于实现:基于邻域的算法通常基于简单的原理,易于理解和实现,不需要太多的数学基础。
2. 高效处理大规模数据:由于基于邻域的算法主要关注于局部信息,而不需要全局计算,因此适用于处理大规模数据。
3. 对数据分布要求较低:基于邻域的算法对数据的分布情况没有太高要求,可以处理各种形状和密度的数据。
在实际应用中,基于邻域的算法被广泛应用于各个领域。
例如,在推荐系统中,可以利用基于邻域的算法来为用户推荐相似的商品或用户;在文本分类中,可以利用kNN算法来根据文本的内容将其分类至相应的类别;在图像处理中,可以利用均值漂移算法来实现图像分割等。
k 最近邻(knn)算法可用于分类问题和回归问题
K最近邻(K-最近邻)算法是一种基于距离度量的机器学习算法,常用于分类问题和回归问题。
该算法的基本思想是将输入特征映射到类别或回归标签。
在分类问题中,K最近邻算法将输入特征映射到K个最近邻的类别,即对于每个输入特征,选择距离该特征最近的类别作为它的输出结果。
该算法通常用于卷积神经网络(CNN)和循环神经网络(RNN)等深度学习模型中,可以用于分类、聚类和序列生成等任务。
在回归问题中,K最近邻算法将输入特征映射到K个最近的回归结果,即对于每个输入特征,选择距离该特征最近的回归结果作为它的输出结果。
该算法通常用于预测连续值预测、时间序列预测和回归分析等任务。
K最近邻算法不仅可以用于分类问题,还可以用于回归问题。
在分类问题中,该算法通常需要大量的训练样本来训练模型,而在回归问题中,由于每个预测值都是对输入数据的加权和,因此可以使用K最近邻算法来快速预测模型。
此外,K 最近邻算法还可以通过添加正则化项来减少过拟合现象。
K最近邻算法是一种简单而有效的机器学习算法,可以用于分类问题和回归问题。
在实际应用中,该算法可以与其他机器学习算法和深度学习模型相结合,以提高模型的准确性和鲁棒性。
肌电信号knn算法肌电信号(EMG)是由肌肉活动产生的电信号,通常用于识别肌肉的运动意图或控制外部设备,如假肢或电子游戏。
K最近邻(KNN)算法是一种常见的监督学习算法,用于分类和回归。
在肌电信号处理中,KNN算法可以用于模式识别和分类,以便识别不同的肌肉动作或运动意图。
KNN算法的工作原理是基于特征空间中的邻近点的概念。
对于肌电信号处理,首先需要提取一些特征,比如时域特征(如均值、方差)、频域特征(如功率谱密度)或时频特征(如小波变换系数)。
然后,KNN算法通过计算新样本与训练集中已知样本的距离,来确定新样本所属的类别。
具体来说,对于肌电信号,KNN算法可以根据不同肌肉动作的特征向量来对其进行分类,从而实现肌肉动作的识别和分类。
然而,肌电信号处理中使用KNN算法也面临一些挑战和限制。
例如,KNN算法对于大规模数据集的计算开销较大,需要存储所有训练样本,并且对于高维特征空间的处理效果可能不佳。
此外,KNN算法对于噪声和异常值较为敏感,需要进行适当的数据预处理和特征选择。
除了KNN算法外,肌电信号处理还可以采用其他机器学习算法,如支持向量机(SVM)、决策树、随机森林等,以及深度学习方法,如卷积神经网络(CNN)和循环神经网络(RNN)。
这些方法都有各自的优缺点,可以根据具体应用场景和数据特点进行选择。
总之,KNN算法在肌电信号处理中可以用于模式识别和分类,但需要注意其计算开销和对数据特征的敏感性,同时也需要考虑其他机器学习算法和深度学习方法的应用。
希望这些信息能够对你有所帮助。