第5章 自底向上优先分析
- 格式:pptx
- 大小:479.72 KB
- 文档页数:85






第6 章自底向上优先分析第1 题已知文法G[S]为:S→a|∧|(T)T→T,S|S(1) 计算G[S]的FIRSTVT 和LASTVT。
(2) 构造G[S]的算符优先关系表并说明G[S]是否为算符优先文法。
(3) 计算G[S]的优先函数。
(4) 给出输入串(a,a)#和(a,(a,a))#的算符优先分析过程。
答案:文法展开为:S→aS→∧S→(T)T→T,ST→S(1) FIRSTVT - LASTVT 表:(2) 算符优先关系表:表中无多重人口所以是算符优先(OPG)文法。
友情提示:记得增加拓广文法S`→#S#,所以# FIRSTVT(S),LASTVT(S) #。
(3)对应的算符优先函数为:a(),^# f212221g331131(4)对输入串(a,a)#的算符优先分析过程为Success!对输入串(a,(a,a))# 的算符优先分析过程为:第 2 题已知文法 G[S]为: S →a|∧|(T)T →T ,S|S(1) 给出(a,(a,a))和(a,a)的最右推导,和规范归约过程。
(2) 将(1)和题 1 中的(4)进行比较给出算符优先归约和规范归约的区别。
答案:(1)(a,a)的最右推导过程为: S (T) (T,S)(T,a) (S,a) (a,a)(a,(a,a))的最右推导过程为: S (T) (T,S) (T,(T))(T,(T,S))(T,(T,a))(T,(S,a))(T,(a,a))(S,(a,a))(a,(a,a))(a,(a,a))的规范归约过程:(a,a)的规范归约过程:(2)算符优先文法在归约过程中只考虑终结符之间的优先关系从而确定可归约串,而与非终结符无关,只需知道把当前可归约串归约为某一个非终结符,不必知道该非终结符的名字是什么,因此去掉了单非终结符的归约。
规范归约的可归约串是句柄,并且必须准确写出可归约串归约为哪个非终结符。
第3题:有文法G[S]:SÆVVÆT|ViTTÆF|T+FFÆ)V*|((1) 给出(+(i(的规范推导。

编译原理LR分析法编译原理中的LR分析法是一种自底向上的语法分析方法,用于构建LR语法分析器。
LR分析法将构建一个识别句子的分析树,并且在分析过程中动态构建并操作一种非常重要的数据结构,称为句柄(stack)。
本文将详细介绍LR分析法的原理、算法以及在实际应用中的一些技巧。
1.LR分析法的原理LR分析法是从右向左(Right to Left)扫描输入串,同时把已处理的输入串的右侧部分作为输入串的前缀进行分析的。
它的核心思想是利用句柄来识别输入串中的语法结构,从而构建分析树。
为了实现LR分析法,需要识别和操作两种基本的语法结构:可规约项和可移近项。
可规约项指的是已经识别出的产生式右部,可以用产生式左部进行规约。
可移近项指的是当前正在处理的输入符号以及已处理的输入串的右侧部分。
2.LR分析法的算法LR分析法的算法包括以下几个步骤:步骤1: 构建LR分析表,LR分析表用于指导分析器在每个步骤中的动作。
LR分析表包括两个部分:动作(Action)表和状态(Goto)表。
步骤2: 初始化分析栈(stack),将初始状态压入栈中。
步骤3:从输入串中读取一个输入符号,并根据该符号和当前状态查找LR分析表中的对应条目。
步骤4:分析表中的条目可能有以下几种情况:- 移进(shift):将输入符号移入栈中,并将新的状态压入栈中。
- 规约(reduce):将栈中符合产生式右部的项规约为产生式左部,并将新的状态压入栈中。
- 接受(accept):分析成功,结束分析过程。
- 错误(error):分析失败,报告错误。
步骤5:重复步骤3和步骤4,直到接受或报错。
3.LR分析法的应用技巧在实际应用中,为了提高LR分析法的效率和准确性,一般会采用以下几种技巧:-使用LR分析表的压缩表示:分析表中的大部分条目具有相同的默认动作(通常是移进操作),因此可以通过压缩表示来减小分析表的大小。
-使用语法冲突消解策略:当分析表中存在冲突时,可以使用优先级和结合性规则来消解冲突,以确定应该选择的操作。

第一章:编译系统概述一.单选题1.编译程序前三个阶段完成的工作是( C )。
A.词法分析、语法分析和代码优化B.代码生成、代码优化和词法分析C.词法分析、语法分析、语义分析和中间代码生成D.词法分析、语法分析和代码优化2.编译程序绝大多数时间花在(D )上。
A.出错处理B.词法分析C.目标代码生成D.表格管理3.编译程序是对(C )。
A.汇编程序的翻译B.高级语言程序的解释执行C.高级语言的翻译D.机器语言的执行4.在使用高级语言编程时,首先可通过编译程序发现源程序的全部( A )错误。
A.语法B.语义C.语用D.运行二.填空题1.编译程序首先要识别出源程序中每个( 单词),然后再分析每个( 句子)并翻译其意义。
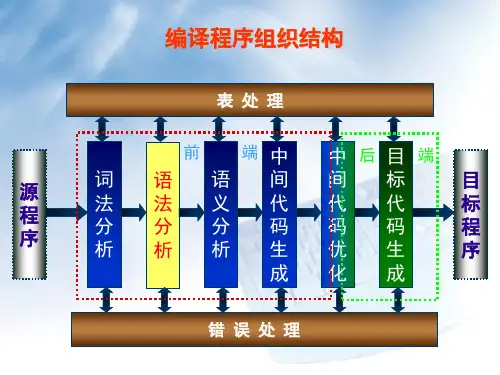
2.通常把编译过程分为分析前端与后端两大阶段。
词法、语法和语义分析是对源程序的( 分析),中间代码生成、代码优化与目标代码的生成则是对源程序的(综合)。
3.对编译程序而言,输入数据是( 源程序),输出结果是( 目标程序)。
4.对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、代码生成)报告的。
(1)else 没有匹配的if (语法分析)(2)数组下标越界(语义分析)(3)使用的函数没有定义(语法分析)(4)在数中出现非数字字符(词法分析)5.如果编译程序生成的目标程序是机器代码程序,则源程序的执行分为两大阶段:(编译阶段)和(运行阶段)。
如果编译程序生成的目标程序是汇编语言程序,则源程序的执行方式分成三个阶段:(编译阶段)(汇编阶段)和(运行阶段)。
6.编译程序在其工作过程使用最多的数据结构是(表),它记录着源程序中各种信息,以便查询或修改,在这些(表)中,尤以(符号表)最重要,它的生存期最长,使用也最频繁。
三.简述题:1.编译程序的工作分为那几个阶段?答:词法分析、语法分析和语义分析是对源程序进行的分析(称为编译程序的前端),而中间代码生成、代码优化和代码生成三个阶段合称为对源程序进行综合(称为编译程序的后端),它们从源程序的中间表示建立起和源程序等价的目标程序。


简单优先和算符优先分析方法简单优先分析(Simple Precedence Parsing)和算符优先分析(Operator Precedence Parsing)是两种常用的自底向上的语法分析方法。
它们是基于符号优先级的理念,通过比较符号之间的优先级关系,来进行语法分析。
1.简单优先分析简单优先分析是一种自底向上的语法分析方法,它利用一个优先级表来确定符号之间的优先关系。
简单优先分析的算法如下:(1)将输入串和符号栈初始化为空。
(2)从输入串中读入第一个输入符号a。
(3)将a与栈顶的符号进行比较:a.如果a的优先级大于栈顶符号的优先级,将a推入符号栈,并读入下一个输入符号。
b.如果a的优先级小于栈顶符号的优先级,将栈中的符号做规约操作,直到栈顶的符号优先级不小于a。
然后,将a推入符号栈。
c.如果a和栈顶符号优先级相等,栈顶的符号出栈,并将a推入符号栈。
(4)重复步骤(3)直到输入串为空。
(5)如果符号栈中只有一个符号且为文法的开始符号,则分析成功。
简单优先分析的优先级表一般由语法规则和符号之间的优先关系组成。
我们可以通过构造优先级关系表来实现简单优先分析。
2.算符优先分析算符优先分析是一种自底向上的语法分析方法,它也是基于符号优先级的理念,但是相对于简单优先分析,算符优先分析更加灵活,并且允许处理左递归的文法。
算符优先分析的算法如下:(1)将输入串和符号栈初始化为空。
(2)从输入串中读入第一个输入符号a。
(3)将a与栈顶的符号进行比较:a.如果a的优先级大于栈顶符号的优先级,将a推入符号栈,并读入下一个输入符号。
b.如果a的优先级小于栈顶符号的优先级,将栈中的符号做规约操作,直到栈顶的符号优先级不小于a。
然后,将a推入符号栈。
c.如果a和栈顶符号优先级相等,根据符号栈中符号的类型执行相应的操作(如归约、移进等)。
(4)重复步骤(3)直到输入串为空。
(5)如果符号栈中只有一个符号且为文法的开始符号,则分析成功。
第6章自底向上优先分析法概述•自底向上分析法,也称移进-归约分析法,或自下而上分析。
•自底向上分析的移进-归约过程是自顶向下最右推导的逆过程,而最右推导为规范推导,自左向右的归约过程也称规范归约。
例6.1 G[S]:(1) S→aAcBe (2) A→b (3) A→Ab (4) B→d 对输入串abbcde#进行分析,检查该符号串是否是G[S]的句子。
容易看出对输入串abbcde的最右推导是:S=>aAcBe=>aAcde => aAbcde => abbcde 。
它的逆过程即归约过程。
基本问题•如何找出进行直接归约的简单短语?•将找到的简单短语归约到哪个非终结符号?基本方法•基本都采用移入-归约方法。
•使用一个栈来存放归约得到的符号。
•在分析的过程中,识别程序不断地移入符号。
移入的符号暂时存放在一个栈中。
一旦在已经移入的(和归约得到的)符号串中包含了一个句柄时,将这个句柄归约成为相应的非终结符号。
基本方法(续)•归约中的动作有4类–移入:读入一个符号并把它归约入栈。
–归约:当栈中的部分形成一个句柄(栈顶的符号序列)时,对句柄进行归约。
–接受:当栈中的符号仅有#和识别符号的时候,输入符号也到达结尾的时候,执行接受动作。
–当识别程序觉察出错误的时候,表明输入符号串不是句子。
进行错误处理。
例 子i *i+ii*i+i i E::=i E *i+iE*i+i E* i+iE*i+i E*i +iE*i+i i E::=i E*E +iE*E+i E*E E::=E*E E +iE+i E+iE+i i E::=i E+EE+E E+E E::=E+EE 文法G E [E]: E::=E+E|E*E|(E)输入符号串:i*i+i已处理 未处理 句型 句柄 规则例子的解释•当栈中的符号的栈顶部分还不能形成句柄时,进行移入操作。
•一旦发现栈顶部分形成了句柄的时候,对该句柄进行归约。
第一章编译原理概论(了解)1、什么是编译程序,编译程序与翻译程序的异同。
(掌握)编译程序是一种将一种语言等价地转换为另一种语言的程序和编译方式不同,解释方式并不先产生目标程序然后再执行之,而是对源程序边翻译边执行。
按解释方式进行翻译的翻译程序称为解释程序。
解释方式的主要优点是便于对源程序进行调试和修改,但其加工处理过程的速度较慢。
适用于交互式语言。
2、编译的主要过程。
(掌握)一个编译过程主要由以下部分组成:词法分析、语法分析、语义分析、中间代码生成、代码优化和代码生成。
以上过程都涉及到两个问题:表格管理和出错处理3、词法分析阶段的主要工作。
主要负责对构成源程序的字符流顺序(按文件的自然顺序)进行扫描和分析,从中识别出每个单词,并确定这些单词是否符合相应语言的词法规则,同时确定哪些是保留字、哪些是变量、哪些是常量、哪些是函数名、哪些是过程名、哪些是界符等,然后生成相应的单词序列代码。
4、语法分析阶段的主要工作。
根据各种语言的语法规则对词法分析阶段生成的单词序列进行组合,构造出各类语法短语(也称为语法单位),通常以语法树的形式表示。
5、词法分析与语法分析的区别。
词法分析和语法分析本质上都是对源程序的结构进行分析。
但词法分析的任务仅对源程序进行线性扫描即可完成,比如识别标识符,因为标识符的结构是字母打头的字母和数字串,这只要顺序扫描输入流,遇到既不是字母又不是数字字符时,将前面所发现的所有字母和数字组合在一起而构成单词标识符。
但这种线性扫描则不能用于识别递归定义的语法成分,比如就不能用此办法去匹配表达式中的括号6、语义分析阶段的主要工作。
根据语法分析阶段生成的各种语法短语,审查源程序是否有语义错误,并作相应的语义处理。
7、中间代码生成阶段的主要工作。
根据语义分析阶段生成的结果,生成中间代码(这是一种结构简单、含义明确的记号系统,它既不是高级语言,也非机器语言,但可以是汇编语言)。
8、代码优化阶段的主要工作。
第六章自下而上分析和优先分析法1、教学目的及要求:要求理解算符优先文法、最左素短语、有效项目的基本概念;掌握算符优先分析方法。
◇ 对给定的文法能够判断该文法是否是算符文法◇ 对给定的算符文法能够判断该文法是否是算符优先文法◇ 对给定的算符文法能构造算符优先关系表,并能利用算符优先关系表判断该文法是否是算符优先文法。
◇ 能应用算符优先分析算法对给定的输入串进行移进-归约分析,在分析的每一步能确定当前应移进还是归约,并能判断所给的输入串是否是该文法的句子。
◇ 了解算符优先分析法的优缺点和实际应用中的局限性。
2、教学内容:自下而上语法分析(算符优先分析法),算符优先分析。
3、教学重点:归约,算符优先表构造。
4、教学难点:◇ 通过本章学习后,学员应该能知道算符文法的形式。
◇ 对一个给定的算符文法能构造算符优先关系分析表,并能判别所给文法是否为算符优先文法。
◇ 分清规范句型的句柄和最左素短语的区别,进而分清算符优先归约和规范归约的区别。
◇算符优先分析的可归约串是句型的最左素短语,在分析过程中如何寻找可归约串是算符优先分析的关键问题。
对一个给定的输入串能应用算符优先关系分析表给出分析(归约)步骤,并最终判断所给输入串是否为该文法的句子。
5、课前思考◇ 什么是自下而上语法分析的策略?◇ 什么是移进-归约分析?◇ 移进-归约过程和自顶向下最右推导有何关系?◇ 自下而上语法分析成功的标志是什么?◇ 什么是可归约串?◇ 移进-归约过程的关键问题是什么?◇ 如何确定可归约串?◇ 如何决定什么时候移进,什么时候归约?◇ 什么是算符文法?什么是算符优先文法?◇ 算符优先分析是如何识别可归约串的?◇ 算符优先分析法的优缺点和局限性有哪些?6、章节内容第一节自下而上语法分析第二节算符优先分析法6.1 自下而上语法分析自底向上的语法分析是从给定的符号串本身出发,试图逐步将它归约为文法的开始符号,由于在进行自底向上的语法分析时,通常所采用的是最左归约,即规范归约,因此实现此种语法分析的关键,是在分析的每一步,如何寻找或确定当前句型的句柄以及确定将句柄归约为什么非终结符号。