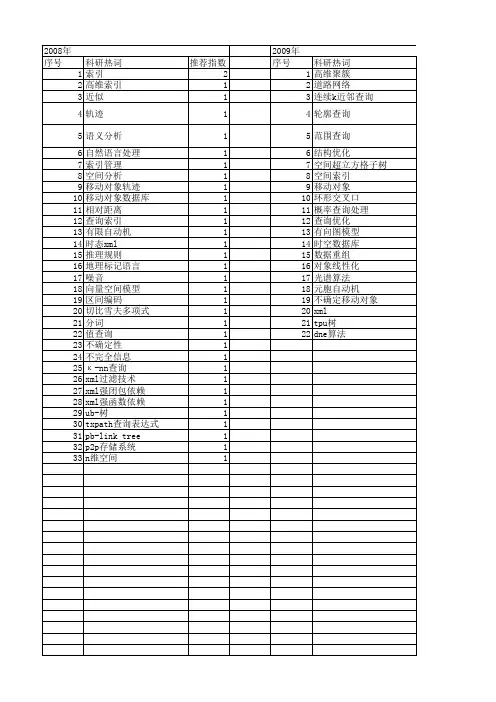
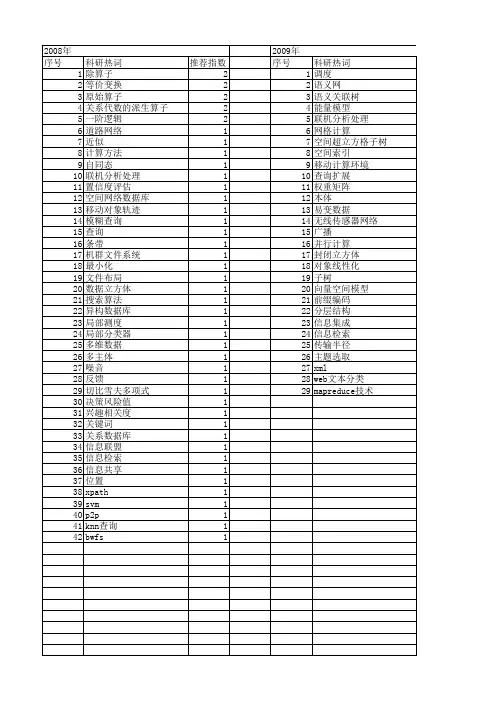
Rtop-k基于结构松弛的XML关键字近似查询方法
- 格式:pdf
- 大小:343.77 KB
- 文档页数:6

IRST(k,l)-Index:一种支持分支路径查询的高效XML结构
索引
范颖捷;张成洪;王述云;胡运发
【期刊名称】《小型微型计算机系统》
【年(卷),期】2009(030)008
【摘要】为快速准确地查询图结构XML文档,本文在互关联后继树(IRST)的基础上,引入结构索引的相似性归并思想,提出一种基于互关联后继树且支持分支路径查询的高效XML结构索引-IRST(k,l)-index,并给出该索引的快速创建和查询算法.经实验验证,与国际上同类索引相比,该索引的创建速度更快、查询效率更高、空间开销更小.
【总页数】9页(P1546-1554)
【作者】范颖捷;张成洪;王述云;胡运发
【作者单位】复旦大学,计算机与信息技术系,上海,200433;解放军南京政治学院,上海分院,训练部,上海,200433;复旦大学,信息管理与信息系统系,上海,200433;复旦大学,计算机与信息技术系,上海,200433;复旦大学,计算机与信息技术系,上海,200433【正文语种】中文
【中图分类】TP311
【相关文献】
1.一种XML多分支路径索引查询算法 [J], 吉根林;肖袁
2.一种高效的XML路径查询索引 [J], 韩恺;蔡荣峰;岳丽华;龚育昌
3.一种高效的XML多分支路径查询算法 [J], 肖袁
4.一种支持高效XML路径查询的自适应结构索引 [J], 张博;耿志华;周傲英
5.一种支持动态XML文档上关键字查询的索引结构 [J], 缪丰羽;林宏康
因版权原因,仅展示原文概要,查看原文内容请购买。

一种改进的XML关键字查询算法
吴海涛
【期刊名称】《南京工程学院学报(自然科学版)》
【年(卷),期】2011(009)002
【摘要】为了使XML关键字查询中的查询结果更有意义,首先研究针对XML的各种经典关键字查询算法,然后根据XML文档的结构特征,定义几种结构类型,在此基础上,提出了一种改进的SLCA算法.该算法不仅解决了在XKSearch中存在的查询结果返回无意义信息的问题,而且与XSEEK中的返回有意义信息的算法相比,有效提高了查询效率.试验结果表明,该算法在查询质量和查询效率上都有较大提高.
【总页数】5页(P33-37)
【作者】吴海涛
【作者单位】南京工程学院通信工程学院,江苏南京211167
【正文语种】中文
【中图分类】TP391
【相关文献】
1.POTwigStack:一种改进的XML小枝模式匹配算法 [J], 石隽锋;张剑妹
2.FastMatch:一种高效的XML关键字查询算法 [J], 崔健;周军锋;郭景峰
3.一种基于区间预留编码的XML关键字查询算法 [J], 魏东平; 罗丹
4.一种基于节点语义相关性的XML关键字查询算法 [J], 曾晓宁; 蔺旭东; 李密生; 裴彩燕; 薄静仪
5.PrList:一种高效的不确定XML关键字查询算法 [J], 张晓琳;苏龙超;韩雨童;刘立新
因版权原因,仅展示原文概要,查看原文内容请购买。


基于x-tuple的概率阈值top-k查询算法黄冬梅;舒博;王建;熊中敏【期刊名称】《计算机工程》【年(卷),期】2013(39)4【摘要】不确定数据库中的概率阈值top-k查询是计算元组排在前k位的概率和,返回概率和不小于p的元组,但现有的查询语义没有将x-tuple内的元组进行整体处理.针对该情况,定义一种新的查询语义——概率阈值x-top-k查询,并给出查询处理算法.在该查询语义下采用动态规划方法求取x-tuple内每个元组排在前k位的概率和,对其进行聚集后做概率阈值top-k查询,并利用观察法、最大上限值等剪枝方法进行优化.实验结果表明,该算法平均扫描全体数据集中60%的数据即可返回正确结果集,证明其查询处理效率较高.%Probabilistic threshold top-k query calculation stu of the probability of the tuple ranked top-k and return the tuples whose sum of the probability are at least p.But top-k query does not take x-tuple as a whole,thus a new top-k query semantic probabilistic threshold x-top-k query is defined and an algorithm is given to process it,which uses dynamic method to acquire sum of the probability of the tuple,then process aggregate probabilities with top-k query.It uses several pruning methods like the upper bound method and so on to optimize the algorithm.Experimental result shows that the algorithm return the answer set for scanning about 60% of data set,and it demonstrates that the algorithm is efficient.【总页数】4页(P44-47)【作者】黄冬梅;舒博;王建;熊中敏【作者单位】上海海洋大学信息学院,上海201306;上海海洋大学信息学院,上海201306;上海海洋大学信息学院,上海201306;上海海洋大学信息学院,上海201306【正文语种】中文【中图分类】TP393【相关文献】1.基于滑动窗口的Top-K概率频繁项查询算法研究 [J], 王爽;王国仁2.基于概率信息抽取模型的Top-k查询 [J], 何明;李薇3.不确定数据库中基于x-tuple的高效Top-k查询处理算法 [J], 刘德喜;万常选;刘喜平4.不确定数据库中概率top-k和排序查询算法 [J], 周帆;李树全;肖春静;吴跃5.基于阈值的快速启动Top-k查询处理算法 [J], 江宇;宋省身;杨岳湘;姜琨因版权原因,仅展示原文概要,查看原文内容请购买。

简述空间索引的类型空间索引是一种用于加快空间数据查询的技术。
它能够将空间数据按照特定的规则进行组织和排序,以便快速检索和访问。
在地理信息系统、数据库和数据挖掘等领域中广泛应用。
一、R树索引R树是一种常用的空间索引方法,它是一种多叉树结构,每个节点代表一个矩形范围。
树的叶子节点保存了实际的空间对象,而非叶子节点保存了其子节点所代表的矩形范围。
通过不断调整节点的位置和大小,R树能够保持树的平衡性和紧凑性,提高查询效率。
二、Quadtree索引Quadtree是一种将二维空间划分为多个象限的树状结构。
每个节点代表一个象限,而非叶子节点代表的象限又被划分为更小的象限,最终形成一棵树。
Quadtree适用于对空间数据进行递归划分和查询,能够有效地处理空间数据的分布不均匀情况。
三、Grid索引Grid索引将空间数据划分为规则的网格单元,每个单元代表一个空间范围。
每个单元可以存储多个空间对象,通过网格索引可以快速定位到包含目标对象的单元,进而加快查询速度。
Grid索引适用于对空间数据进行分区和统计分析。
四、kd树索引kd树是一种二叉树结构,用于对k维空间数据进行划分和查询。
树的每个节点代表一个k维空间范围,非叶子节点按照某个维度的值进行划分,形成左右子树。
kd树索引能够高效地处理高维空间数据的查询问题。
五、R*-tree索引R*-tree是对R树的改进和优化,通过引入一系列策略和算法,提高了R树的查询性能和存储效率。
R*-tree索引在处理大规模和高维空间数据时表现出色,被广泛应用于地理信息系统和数据库领域。
六、Hilbert R树索引Hilbert R树是一种基于Hilbert曲线的空间索引方法,通过将空间数据映射到一条曲线上,实现对空间数据的排序和查询。
Hilbert R 树索引能够有效地处理多维空间数据的查询问题,具有较好的查询性能和存储效率。
空间索引是空间数据处理和查询的重要工具,能够提高数据查询的效率和准确性。

RRTA:一种基于顺序读取的有效Top-K查询算法周腾腾;陈林祥;胡奥【期刊名称】《计算机工程与应用》【年(卷),期】2013(000)017【摘要】To p-K查询是一种被广泛应用的操作,它根据给定的评分函数在潜在的海量数据中返回k个分值最高的元组。
传统的TA算法要求能够支持随机读,NRA 算法虽然放宽了对随机读的限制,但是增长阶段需要在内存中维护大量的元组,运行时将占用大量的内存资源。
提出的RRTA算法相比NRA算法对数据的存储进行了重新的规划,创建一个新的表将内存上的开销转换到较廉价的外存开销,只需顺序读取就可以进行有效的To p-K查询,同时将表进行了划分,在并行处理的情况下更能提高程序的效率,能够很好地运行在内存有限的环境中。
%Top-K query is a widely used operation, which can return the highest score of the tuple in specialized massive data-bases, according to the given monotone aggregation function. Traditional TA algorithm requires the ability to support random access, NRA algorithm although relaxes the restrictions on the random access, it is found that in massive data context, NRA needs to maintain large quantity of candidate tuples in memory in the increasing phase, it will also use up a lot of memory resources in runtime. Compared with the NRA algorithm, the RRTA(Round-Robin ThresholdAlgorithm)which proposed in this paper replants the data storage mode, which creats a new table to switch the memory overhead to the cheaper external memory over-head, so just sorted access is also able to doefficient top-k query. Meanwhile, the table has been divided, which makes the algo-rithm more efficient and smoother even with limited memory, in the case of parallel processing.【总页数】5页(P116-120)【作者】周腾腾;陈林祥;胡奥【作者单位】中国矿业大学计算机科学与技术学院计算机科学与技术系,江苏徐州 221000;中国矿业大学理学院数学系,江苏徐州 221000;中国矿业大学计算机科学与技术学院计算机科学与技术系,江苏徐州 221000【正文语种】中文【中图分类】TP311【相关文献】1.一种有效的不确定数据流Top-K查询算法 [J], 梁银双;苏玉;卢印举2.一种有效的海量数据Top-k Dominating查询算法 [J], 韩希先;李建中;高宏EP:海量数据上一种有效的Top-K查询处理算法 [J], 韩希先;杨东华;李建中4.基于顺序读取的分布式top-k查询算法 [J], 毕方明;陈伟;杨魁;车奔5.一种基于Jetson-TK1的Top-k查询算法 [J], 李靓琦;黄玉龙;谢绍国因版权原因,仅展示原文概要,查看原文内容请购买。

不确定数据库中基于x-tuple的高效Top-k查询处理算法刘德喜;万常选;刘喜平【期刊名称】《计算机研究与发展》【年(卷),期】2010(047)008【摘要】Top-k查询由于其广泛的应用而倍受欢迎.不确定数据库中通常考虑的两条生成规则是:独立和互斥,一个x-tuple是由一些互斥的元组组成的,构成一个x-tuple的各个元组称为该x-tuple的可选元组.U-kRanks查询考虑x-tuple中每个可选元组排在前k的概率,并返回最可能排在前k的k个元组.已有的Top-k语义都没有将x-tuple作为一个整体,因此,定义了一种新的Top-k查询语义,不确定x-kRanks查询 (U-x-kRanks),该Top-k语义返回最可能排在前k的k个x-tuple而非元组.新语义考虑x-tuple中的每个可选元组位于前k的概率,并将之汇集,得到整个x-tuple位于前k的概率.提出了一种基于动态规划的有效算法处理U-x-kRanks 查询,在最小的搜索空间内完成查询处理过程.不同数据集合上的综合实验显示,所提出的算法是高效的.【总页数】9页(P1415-1423)【作者】刘德喜;万常选;刘喜平【作者单位】江西财经大学信息管理学院,南昌,330013;江西财经大学信息管理学院,南昌,330013;江西财经大学信息管理学院,南昌,330013【正文语种】中文【中图分类】TP311.13【相关文献】1.基于x-tuple的概率阈值top-k查询算法 [J], 黄冬梅;舒博;王建;熊中敏2.不确定图上的高效top-k近邻查询处理算法 [J], 张海杰;姜守旭;邹兆年3.传感器网络中基于卡尔曼滤波的能量高效Top-k查询处理技术 [J], 宋保利;郑吉平;王海翔4.不确定数据库中概率top-k和排序查询算法 [J], 周帆;李树全;肖春静;吴跃5.基于阈值的快速启动Top-k查询处理算法 [J], 江宇;宋省身;杨岳湘;姜琨因版权原因,仅展示原文概要,查看原文内容请购买。

第1章绪论内容提要:◆数据结构研究的内容。
针对非数值计算的程序设计问题,研究计算机的操作对象以及它们之间的关系和操作。
数据结构涵盖的内容:◆基本概念:数据、数据元素、数据对象、数据结构、数据类型、抽象数据类型。
数据——所有能被计算机识别、存储和处理的符号的集合。
数据元素——是数据的基本单位,具有完整确定的实际意义。
数据对象——具有相同性质的数据元素的集合,是数据的一个子集。
数据结构——是相互之间存在一种或多种特定关系的数据元素的集合,表示为:Data_Structure=(D, R)数据类型——是一个值的集合和定义在该值上的一组操作的总称。
抽象数据类型——由用户定义的一个数学模型与定义在该模型上的一组操作,它由基本的数据类型构成。
◆算法的定义及五个特征。
算法——是对特定问题求解步骤的一种描述,它是指令的有限序列,是一系列输入转换为输出的计算步骤。
算法的基本特性:输入、输出、有穷性、确定性、可行性◆算法设计要求。
①正确性、②可读性、③健壮性、④效率与低存储量需求◆算法分析。
时间复杂度、空间复杂度、稳定性学习重点:◆数据结构的“三要素”:逻辑结构、物理(存储)结构及在这种结构上所定义的操作(运算)。
◆用计算语句频度来估算算法的时间复杂度。
第二章线性表内容提要:◆线性表的逻辑结构定义,对线性表定义的操作。
线性表的定义:用数据元素的有限序列表示◆线性表的存储结构:顺序存储结构和链式存储结构。
顺序存储定义:把逻辑上相邻的数据元素存储在物理上相邻的存储单元中的存储结构。
链式存储结构: 其结点在存储器中的位置是随意的,即逻辑上相邻的数据元素在物理上不一定相邻。
通过指针来实现!◆线性表的操作在两种存储结构中的实现。
数据结构的基本运算:修改、插入、删除、查找、排序1)修改——通过数组的下标便可访问某个特定元素并修改之。
核心语句:V[i]=x;顺序表修改操作的时间效率是O(1)2)插入——在线性表的第i个位置前插入一个元素实现步骤:①将第n至第i 位的元素向后移动一个位置;②将要插入的元素写到第i个位置;③表长加1。
