
检验变量检验类型ADF统计值10%临界值5%临界值结论LNY (0,01)-0.42906 -1.60661 -1.96141 不平稳DLNY (c,t,1)-2.75590 -4.61621 -3.71048 不平稳D(D(LNY)) (0,02)-2.55383 -2.72825 -1.96627 平稳LNX1(0,02) 3.551647 -2.70809 -1.96281 不平稳DLNX1(0,0,1)-1.107310 -2.70809 -1.96281 不平稳D(D(LNX1) (0,0,2)-4.86780 -2.72825 -1.96627 平稳LNX2(c,t,2)-1.99875 -3.71048 -3.29780 不平稳DLNX2(c,0,1)-2.70719 -3.88675 -3.05217 不平稳D(D(LNX2) (0,0,2)-3.62840 -2.71511 -1.96642 平稳
检验变量检验类型ADF统计值10%临界值5%临界值结论LNY (0,0,1)-0.42906 -1.60661 -1.96141 不平稳DLNY (c,t,1)-2.75590 -4.61621 -3.71048 不平稳D(D(LNY)) (0,0,2)-2.55383 -2.72825 -1.96627 平稳LNX1(0,0,2) 3.551647 -2.70809 -1.96281 不平稳DLNX1(0,0,1)-1.107310 -2.70809 -1.96281 不平稳D(D(LNX1) (0,0,2)-4.86780 -2.72825 -1.96627 平稳LNX2(c,t,2)-1.99875 -3.71048 -3.29780 不平稳DLNX2(c,0,1)-2.70719 -3.88675 -3.05217 不平稳D(D(LNX2) (0,0,2)-3.62840 -2.71511 -1.96642 平稳
以中国2001——2015年各季度GDP 为例。 时间 GDP 时间 GDP 时间 GDP 时间 GDP 2001年Q1 23,299.5000 2004年Q4 159,878.0000 2008年Q3 228,935.4229 2012年Q2 246,913.7330 2001年Q2 48,950.9000 2005年Q1 38,848.6000 2008年Q4 314,045.4271 2012年Q3 383,636.6047 2001年Q3 75,818.2000 2005年Q2 81,422.5000 2009年Q1 73,283.6275 2012年Q4 519,470.0992 2001年Q4 109,655.0000 2005年Q3 125,984.9000 2009年Q2 156,897.8212 2013年Q1 128,083.5340 2002年Q1 25,375.7000 2005年Q4 183,867.9000 2009年Q3 245,821.2738 2013年Q2 271,115.3226 2002年Q2 53,341.0000 2006年Q1 46,678.2949 2009年Q4 340,902.8126 2013年Q3 421,835.1222 2002年Q3 83,056.7000 2006年Q2 99,238.7117 2010年Q1 86,684.3479 2013年Q4 588,019.0000 2002年Q4 120,333.0000 2006年Q3 154,706.4747 2010年Q2 185,744.1504 2014年Q1 138,737.9662 2003年Q1 28,861.8000 2006年Q4 216,314.4259 2010年Q3 290,694.7860 2014年Q2 293,938.9812 2003年Q2 59,868.9000 2007年Q1 56,686.6255 2010年Q4 401,512.7952 2014年Q3 457,405.9484 2003年Q3 93,329.3000 2007年Q2 121,335.5172 2011年Q1 103,456.8650 2014年Q4 636,138.7325 2003年Q4 135,823.0000 2007年Q3 190,125.0432 2011年Q2 221,921.8620 2015年Q1 147,961.7996 2004年Q1 33,420.6000 2007年Q4 265,810.3058 2011年Q3 347,201.1732 2015年Q2 314,178.2215 2004年Q2 70,405.9000 2008年Q1 68,778.3523 2011年Q4 473,104.0486 2015年Q3 487,773.5083 2004年Q3 109,967.6000 2008年Q2 147,315.9722 2012年Q1 116,147.8983 在eviews 中输入数据,双击序列名,选择View ——Unit Root Test ,得到下对话框: 这里做的选择是(1)ADF 检验,(2)对原序列yt 做单位根检验,(3)检验式中不包括趋势项和截距项。点击OK 键。得ADF 检验结果如下。 注意: (1)Test type (选择检验类型) (2)Test for unit root in (选择差分形式) Level (原序列)、一阶差分、二阶差分 (3)选择不同检验式(缺省选择是检验式中只包括截距项。其他两种选择是检验式中包括趋势项和截距项,检验式中不包括趋势项和截距项。 (4)ADF 检验式中选择差分项的最大滞后期数。
目录 附表一:随机数表 _________________________________________________________________________ 2附表二:标准正态分布表 ___________________________________________________________________ 3附表三:t分布临界值表____________________________________________________________________ 4 附表四: 2 分布临界值表 __________________________________________________________________ 5 附表五:F分布临界值表(α=0.05)________________________________________________________ 7附表六:单样本K-S检验统计量表___________________________________________________________ 9附表七:符号检验界域表 __________________________________________________________________ 10附表八:游程检验临界值表 _________________________________________________________________ 11附表九:相关系数临界值表 ________________________________________________________________ 12附表十:Spearman等级相关系数临界值表 ___________________________________________________ 13附表十一:Kendall等级相关系数临界值表 ___________________________________________________ 14附表十二:控制图系数表 __________________________________________________________________ 15
1.ADF单位根检验 2.Engle-Granger协整检验 3.Da-vdson误差修正模型 4.Granger因果关系检验 1、简单回归; 2、工具变量回归; 3、面板固定效应回归; 4、差分再差分回归(difference in differnece); 5、狂忒二回归(Quantile)。 大杀器就这几种,破绽最少,公认度最高,使用最广泛。真是所谓的老少皆宜、童叟无欺。其他的方法都不会更好,只会招致更多的破绽。你在STATA 里面还可以看到无数的其他方法,例如GMM、随机效应等。GMM其实是一个没有用的忽悠,例如估计动态面板的diffGMM,其关键思想是当你找不到工具变量时,用滞后项来做工具变量。结果你会发现令人崩溃的情况:不同滞后变量的阶数,严重影响你的结果,更令人崩溃的是,一些判断估计结果优劣的指标会失灵。这GMM的唯一价值在于理论价值,而不在于实践价值。你如果要玩计量,你就可以在GMM的基础上进行修改(玩计量的方法后面讲)。 有人会问:简单回归会不会太简单?我只能说你真逗。STATA里面那么多选项,你加就是了。什么异方差、什么序列相关,一大堆尽管加。如果你实在无法确定是否有异方差和序列相关,那就把选项都加上。反正如果没有异方差,结果是一样的。有异方差,软件就自动给你纠正了。这不很爽嘛。如果样本太少,你还能加一个选项:bootstrap来估计方差。你看爽不爽!bootstrap就是自己把脚抬起来扛在肩上走路,就这么牛。这个bootstrap就是用30个样本能做到30万样本那样的效果。有吸引力吧。你说这个简单回归简单还是不简单!很简单,就是加选项。可是,要理论推导,就不简单了。我估计国内能推导的没几
自由度自由度(df )0.100.05 0.01 (df )0.100.05 0.01 n -m -1n -m -11 6.31412.70663.657301 1.650 1.968 2.5922 2.920 4.3039.925302 1.650 1.968 2.5923 2.353 3.182 5.841303 1.650 1.968 2.5924 2.132 2.776 4.604304 1.650 1.968 2.5925 2.015 2.571 4.032305 1.650 1.968 2.5926 1.943 2.447 3.707306 1.650 1.968 2.5927 1.895 2.365 3.499307 1.650 1.968 2.5928 1.860 2.306 3.355308 1.650 1.968 2.5929 1.833 2.262 3.250309 1.650 1.968 2.59210 1.812 2.228 3.169310 1.650 1.968 2.59211 1.796 2.201 3.106311 1.650 1.968 2.59212 1.782 2.179 3.055312 1.650 1.968 2.59213 1.771 2.160 3.012313 1.650 1.968 2.59214 1.761 2.145 2.977314 1.650 1.968 2.59215 1.753 2.131 2.947315 1.650 1.968 2.59216 1.746 2.120 2.921316 1.650 1.967 2.59117 1.740 2.110 2.898317 1.650 1.967 2.59118 1.734 2.101 2.878318 1.650 1.967 2.59119 1.729 2.093 2.861319 1.650 1.967 2.59120 1.725 2.086 2.845320 1.650 1.967 2.59121 1.721 2.080 2.831321 1.650 1.967 2.59122 1.717 2.074 2.819322 1.650 1.967 2.59123 1.714 2.069 2.807323 1.650 1.967 2.59124 1.711 2.064 2.797324 1.650 1.967 2.59125 1.708 2.060 2.787325 1.650 1.967 2.59126 1.706 2.056 2.779326 1.650 1.967 2.59127 1.703 2.052 2.771327 1.650 1.967 2.59128 1.701 2.048 2.763328 1.650 1.967 2.59129 1.699 2.045 2.756329 1.649 1.967 2.59130 1.697 2.042 2.750330 1.649 1.967 2.59131 1.696 2.040 2.744331 1.649 1.967 2.59132 1.694 2.037 2.738332 1.649 1.967 2.59133 1.692 2.035 2.733333 1.649 1.967 2.59134 1.691 2.032 2.728334 1.649 1.967 2.59135 1.690 2.030 2.724335 1.649 1.967 2.59136 1.688 2.028 2.719336 1.649 1.967 2.59137 1.687 2.026 2.715337 1.649 1.967 2.59038 1.686 2.024 2.712338 1.649 1.967 2.59039 1.685 2.023 2.708339 1.649 1.967 2.59040 1.684 2.021 2.704340 1.649 1.967 2.59041 1.683 2.020 2.701341 1.649 1.967 2.59042 1.682 2.018 2.698342 1.649 1.967 2.59043 1.681 2.017 2.695343 1.649 1.967 2.59044 1.680 2.015 2.692 344 1.649 1.967 2.590 显著性水平(a )显著性水平(a )T 检验临界值表
引自Ruey S. Tsay著,王辉、潘家柱译《金融时间序列分析》(第2版) DF检验 为了检验资产的对数价格p t是否服从一个随机游动或一个带漂移的随机游动,对模型 p t=?1p t?1+e t (1) p t=?0+?1p t?1+e t (2) 其中e t为误差项。考虑原假设H0:?1=1;H1:?1<1,即是一个单位根检验问题。一个方便的检验统计量就是在原假设下?1的最小二乘估计的t?比。对(1)式,由最小二乘法得 ?1= p t?1p t T t=1 t?1 T t=1 ,σe2= p t??1p t?12 T t=1 其中p0=0,T为样本容量。t?比为 DF≡t?比= ?1?1 ?1的标准差 = p e T σe p t?12 T t=1 这个t?比检验通常称为DF检验。若e t为一个白噪声序列,其稍高于二阶的矩是有限的,则当T?∞时DF统计量趋于一个标准布朗运动的函数。如果?0=0但我们采用了(2)式,则所得的检验?1=1的t?比将趋于另一种非标准的渐进分布。上述两种情形都是用模拟方法来得到检验统计量的临界值。然而如果?0≠0且使用的是(2)式,则用来检验?1=1的t?比是渐进正态的,但此时将需要很大的样本容量来保证渐进正态分布的使用。 ADF检验 用x t表示一个AR(p)时间序列,为了验证序列是否存在单位根,通常人们采用ADF检验来验证,即可以用如下回归来进行假设检验(H0:β=1;H1:β<1): x t=c t+βx t?1+?iΔx t?i+e t p?1 i=1 其中c t是关于时间t的确定性函数,Δx j=x j?x j?1是x t的差分序列。在实际中,c t可以是常数或者c t=ω0+ω1t。β?1的t?比为
附录 附表一:随机数表 _________________________________________________________________________ 2附表二:标准正态分布表 ___________________________________________________________________ 3附表三:t分布临界值表____________________________________________________________________ 4 附表四: 2 分布临界值表 __________________________________________________________________ 5 附表五:F分布临界值表(α=0.05)________________________________________________________ 7附表六:单样本K-S检验统计量表___________________________________________________________ 9附表七:符号检验界域表 __________________________________________________________________ 10附表八:游程检验临界值表 _________________________________________________________________ 11附表九:相关系数临界值表 ________________________________________________________________ 12附表十:Spearman等级相关系数临界值表 ___________________________________________________ 13附表十一:Kendall等级相关系数临界值表 ___________________________________________________ 14附表十二:控制图系数表 __________________________________________________________________ 15
附表一:随机数表_____________________________________________________________________________ 2附表二:标准正态分布表______________________________________________________________________ 3附表三:t分布临界值表________________________________________________________________________ 4 2 附表四:分布临界值表_____________________________________________________________________ 5附表五:F分布临界值表(a =0.05)7附表六:单样本K-S检验统计量表_______________________________________________________________ 9附表七:符号检验界域表______________________________________________________________________ 10附表八:游程检验临界值表___________________________________________________________________ 11附表九:相关系数临界值表____________________________________________________________________ 12附表十:Spearman等级相关系数临界值表 _____________________________________________________ 13附表十一:Kendall等级相关系数临界值表_______________________________________________________ 14附表十二:控制图系数表_____________________________________________________________________ 15
特征根迹统计量 (P值)5%临界值λ_max统计量 (P值) 5%临界值原假设 0.786230 43.63(0.02) 40.17 23.14(0.06) 24.16 0个协整向量 0.659057 20.49(0.14) 24.28 16.14(0.09) 17.8 至少1个协整向量0.249925 4.35(0.66) 12.32 4.31(0.58) 11.22 至少2个协整向量0.002389 0.0023(0.88) 4.13 0.036(0.88) 4.13 至少3个协整向量正确的计算以1978年为100的定基指数的方法为: 如果有以上一年为100的GDP指数,如何计算以某固定年份为100的GDP指数? 以北京1978年为100的定基指数计算为例: 第一步: (1)将1978年的GDP指数定义为100,这样,1978年定基指数(1978=100)=100. 第二步:(2)那么1979年的定基(1978=100)就等于当年的同比指数,即 1979年GDP定基指数(1978=100)=1979年GDP指数(以上一年为100) 第三步(最关键):1980年GDP指数(1978=100)=1979年GDP指数(1978=100)*1980年GDP指数(以上一年为100)/100。 第四步:自1981年起重复第三步,即以各上年定基指数(1978=100)分别乘以当年 同比指数(上年=100的指数)再除以100,就依次可以得到所有年份以1978年为100 的定基指数。EXCEL直接复制第三步的公式就可以计算出来。 本文来自: 人大经济论坛数据交流中心版,详细出处参考: 定基指数 编辑 目录 1定基指数与环比指数的关系 2定基指数的分类 3定基指数与环比指数的区别 定基指数即定比指数。定基指数是指在指数数列中,各期指数都以某—固定 时期为基期。定基指数说明现象在较长时期内的发展变化情况。
1.3.4 ADF检验 仍以日本人口序列y t为例(数据见3.3)。在工作文件窗口中双击y t序列,从而打开y t数据窗口。点击View键,选择Unit Root Test功能,如下图, 则会弹出一个单位根检验对话框。 其中共有4种选项。(1)检验方法(缺省选择是ADF检验),(2)所检验的序列(缺省选择是对原序列(Level)做单位根检验)。(3)选择不同检验式(缺省选择是检验式中只包括截距项。其他两种选择是检验式中包括趋势项和截距项,检验式中不包括趋势项和截距项。(4)ADF检验式中选择差分项的最大滞后期数。这里做的选择是(1)ADF 检验,(2)对原序列y t做单位根检验,(3)检验式中不包括趋势项和截距项。点击OK 键。得ADF检验结果如下。
相应的检验式是 ?= 0.0041 y t-1 + 0.2197? y t-1 + 0.1366? y t-1 + 0.2159? y t-1 (2.9) (2.4) (1.4) (2.3) DW = 2.05 输出的最上部分给出了检验结果。因为ADF = 2.9283,分别大于不同检验水平的三个临界值,所以日本人口序列y t是一个非平稳序列。在此情形下,应该继续对y t的差分序列进行单位根检验。 在序列y t窗口(即显示单位根检验结果的窗口)中,点击View键,选择Unit Root Test 功能,再次得到单位根检验对话框。这时第二项选择应选1st difference,即检验?y t。第三项选择含截距项,第四项选择滞后2期。
点击OK键。得ADF检验结果如下。 见输出结果的最上部分。因为ADF = 3.5602,分别小于不同检验水平的三个临界值,所以日本人口差分序列? y t是一个平稳序列。因此y t~ (1)。
回归: Dependent Variable: Y Method: Least Squares Date: 04/09/14 Time: 20:40 Sample: 2003 2012 Included observations: 10 Variable Coefficient Std. Error t-Statistic Prob. L -7.584788 2.987176 -2.539116 0.0441 K 0.627143 0.208381 3.009604 0.0237 I -0.131563 0.070898 -1.855656 0.1129 C 82.50331 31.82297 2.592571 0.0411 R-squared 0.992831 Mean dependent var 7.271989 Adjusted R-squared 0.989246 S.D. dependent var 0.387985 S.E. of regression 0.040234 Akaike info criterion -3.299031 Sum squared resid 0.009713 Schwarz criterion -3.177997 Log likelihood 20.49515 Hannan-Quinn criter. -3.431805 F-statistic 276.9743 Durbin-Watson stat 1.920806 Prob(F-statistic) 0.000001 变量Y的ADF检验 Null Hypothesis: Y has a unit root Exogenous: Constant Lag Length: 1 (Fixed) t-Statistic Prob.* Augmented Dickey-Fuller test statistic 0.745045 0.9832 Test critical values: 1% level -4.582648 5% level -3.320969 10% level -2.801384 *MacKinnon (1996) one-sided p-values. Warning: Probabilities and critical values calculated for 20 observations and may not be accurate for a sample size of 8 变量L的ADF检验 Null Hypothesis: L has a unit root Exogenous: Constant Lag Length: 1 (Fixed) t-Statistic Prob.* Augmented Dickey-Fuller test statistic -2.149207 0.2335
ADF-situation1-statistic1-2.m %ADF检验法p取2. %AR(2)过程临界值的确定 T=5000; N=200; w1=zeros(1,T); w2=zeros(1,T); for t=1:T sita1=0.7; sita2=0.3; ru=sita1+sita2; labuda1=-sita2; %p=2; e=randn(1,N); y1(1)=e(1); y1(2)=sita1*y1(1)+e(2); for j=3:N y1(j)=sita1*y1(j-1)+sita2*y1(j-2)+e(j); end dertay1(1)=y1(1); for i=2:N dertay1(i)=y1(i)-y1(i-1); end %数据的生成过程 y(1)=e(1); for k=2:N y(k)=ru*y(k-1)+labuda1*dertay1(k-1)+e(k); end dertay(1)=y(1); for h=2:N dertay(h)=y(h)-y(h-1); end A=[sum(dertay(1,1:N-1).^2) sum(dertay(1,1:N-1).*y(1,1:N-1));
sum(dertay(1,1:N-1).*y(1,1:N-1)) sum(y(1,1:N-1).^2)]; B=[sum(dertay(1,1:N-1).*y(1,2:N)) sum(y(1,1:N-1).*y(1,2:N))]'; C=inv(A)*B; ruhat=C(2,1); labuda1hat=C(1,1); w1(t)=N*(ruhat-1)/(1-labuda1hat); %样本方差计算SigmaSquare episilon1(1)=y(1)-arfahat; for i1=2:N episilon1(i1)=y(i1)-ruhat*y(i1-1)-labuda1hat*dertay1(i1-1);%Situation1与Situation2再此处不一样。 end SigmaSquare=(N-3)^(-1)*sum(episilon1(1,1:N).^2);%有三个参数需要估计,所以是N-3。 YitahatSquare=SigmaSquare.*[0 1]*inv(A)*[0 1]';%在计算YitaSquare时采用了《小书》p66结论。 %SigmaSquare/sum(y(1,1:N-1).^2); %Statistic2 w2(t)=(ruhat-1)/(YitahatSquare^(1/2)); end a1=sort(w1); a2=sort(w2); b1=a1(fix(T*0.05)) b2=a2(fix(T*0.05)) %在备择假设下的检验 for t=1:T sita1=0.3; sita2=0.3; ru=sita1+sita2; labuda1=-sita2; %p=2; e=randn(1,N); y1(1)=e(1); y1(2)=sita1*y1(1)+e(2);
实验一时间序列数据平稳性检验实验指导 一、实验目的: 理解经济时间序列存在的不平稳性,掌握对时间序列平稳性检验的步骤和各种方法,认识利用不平稳的序列进行建模所造成的影响。 二、基本概念: 如果一个随机过程的均值和方差在时间过程上都是常数,并且在任何两时期的协方差值仅依赖于该两个时期间的间隔,而不依赖于计算这个协方差的实际时间,就称它是宽平稳的。 时序图 ADF检验 PP检验 三、实验容及要求: 1、实验容: 用Eviews5.1来分析1964年到1999年中国纱产量的时间序列,主要容: (1)、通过时序图看时间序列的平稳性,这个方法很直观,但比较粗糙; (2)、通过计算序列的自相关和偏自相关系数,根据平稳时间序列的性质观察其平稳性;(3)、进行纯随机性检验; (4)、平稳性的ADF检验; (5)、平稳性的pp检验。 2、实验要求: (1)理解不平稳的含义和影响; (2)熟悉对序列平稳化处理的各种方法; (2)对相应过程会熟练软件操作,对软件分析结果进行分析。 四、实验指导 (1)、绘制时间序列图 时序图可以大致看出序列的平稳性,平稳序列的时序图应该显示出序列始终围绕一个常数值波动,且波动的围不大。如果观察序列的时序图显示出该序列有明显的趋势或周期,那它通常不是平稳序列,现以1964-1999年中国纱年产量序列(单位:万吨)来说明。 在EVIEWS中建立工作文件,在“Workfile structure type”栏中选择“Dated-regular frequency”,在右边的“Date specification”中输入起始年1964,终止年1999,点击ok 则建立了工作文件。找到中国纱年产量序列的excel文件并导入命名该序列为sha,见图1-2。 图1-1 建立工作文件
时间序列数据平稳性检验实验 指导(总6页) -CAL-FENGHAI.-(YICAI)-Company One1 -CAL-本页仅作为文档封面,使用请直接删除
实验一时间序列数据平稳性检验实验指导 一、实验目的: 理解经济时间序列存在的不平稳性,掌握对时间序列平稳性检验的步骤和各种方法,认识利用不平稳的序列进行建模所造成的影响。 二、基本概念: 如果一个随机过程的均值和方差在时间过程上都是常数,并且在任何两时期的协方差值仅依赖于该两个时期间的间隔,而不依赖于计算这个协方差的实际时间,就称它是宽平稳的。 时序图 ADF检验 PP检验 三、实验内容及要求: 1、实验内容: 用来分析1964年到1999年中国纱产量的时间序列,主要内容: (1)、通过时序图看时间序列的平稳性,这个方法很直观,但比较粗糙;(2)、通过计算序列的自相关和偏自相关系数,根据平稳时间序列的性质观察其平稳性; (3)、进行纯随机性检验; (4)、平稳性的ADF检验; (5)、平稳性的pp检验。 2、实验要求: (1)理解不平稳的含义和影响; (2)熟悉对序列平稳化处理的各种方法; (2)对相应过程会熟练软件操作,对软件分析结果进行分析。 四、实验指导 (1)、绘制时间序列图 时序图可以大致看出序列的平稳性,平稳序列的时序图应该显示出序列始终围绕一个常数值波动,且波动的范围不大。如果观察序列的时序图显示出该序列有明显的趋势或周期,那它通常不是平稳序列,现以1964-1999年中国纱年产量序列(单位:万吨)来说明。 在EVIEWS中建立工作文件,在“Workfile structure type”栏中选择“Dated-regular frequency”,在右边的“Date specification”中输入起始年1964,终止年1999,点击ok则建立了工作文件。找到中国纱年产量序列的excel文件并导入命名该序列为sha,见图1-2。
t -分布临界值表 ()(){}1P t n t n αα?=> n α=0.25 0.10 0.05 0.025 0.01 0.005 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 1.0000 0.8165 0.7649 0.7407 0.7267 0.7176 0.7111 0.7064 0.7027 0.6998 0.6974 0.6955 0.6938 0.6924 0.6912 0.6901 0.6892 0.6884 0.6876 0.6870 0.6864 0.6858 0.6853 0.6848 0.6844 0.6840 0.6837 0.6834 0.6830 0.6828 3.0777 1.8856 1.6377 1.5332 1.4759 1.4398 1.4149 1.3968 1.3830 1.3722 1.3634 1.3562 1.3502 1.3450 1.3406 1.3368 1.3334 1.3304 1.3277 1.3253 1.3232 1.3212 1.3195 1.3178 1.3163 1.3150 1.3137 1.3125 1.3114 1.3104 6.3138 2.9200 2.3534 2.1318 2.0150 1.9432 1.8946 1.8595 1.8331 1.8125 1.7959 1.7823 1.7709 1.7613 1.7531 1.7459 1.7396 1.7341 1.7291 1.7247 1.7207 1.7171 1.7139 1.7109 1.7081 1.7056 1.7033 1.7011 1.6991 1.6973 12.7062 4.3207 3.1824 2.7764 2.5706 2.4469 2.3646 2.3060 2.2622 2.2281 2.2010 2.1788 2.1604 2.1448 2.1315 2.1199 2.1098 2.1009 2.0930 2.0860 2.0796 2.0739 2.0687 2.0639 2.0595 2.0555 2.0518 2.0484 2.0452 2.0423 31.8207 6.9646 4.5407 3.7469 3.3649 3.1427 2.9980 2.8965 2.8214 2.7638 2.7181 2.6810 2.6503 2.6245 2.6025 2.5835 2.5669 2.5524 2.5395 2.5280 2.5177 2.5083 2.4999 2.4922 2.4851 2.4786 2.4727 2.4671 2.4620 2.4573 63.6574 9.9248 5.8409 4.6041 4.0322 3.7074 3.4995 3.3554 3.2498 3.1693 3.1058 3.0545 3.0123 2.9768 2.9467 2.9028 2.8982 2.8784 2.8609 2.8453 2.8314 2.8188 2.8073 2.7969 2.7874 2.7787 2.7707 2.7633 2.7564 2.7500
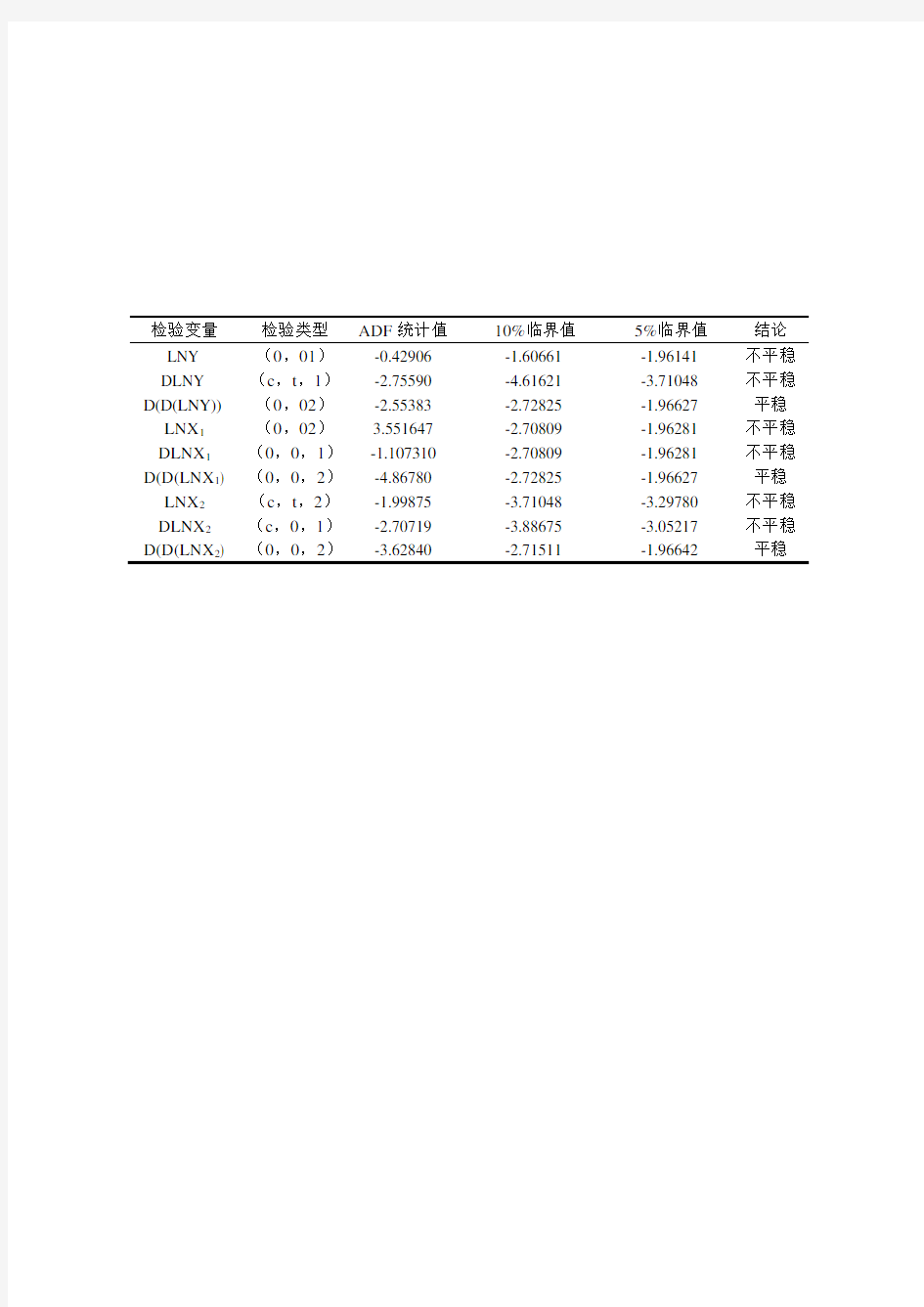
检验变量检验类型ADF统计值10%临界值5%临界值结论LNY(0,01)-0.42906-1.60661-1.96141不平稳 DLNY(c,t,1)-2.75590-4.61621-3.71048不平稳D(D(LNY))(0,02)-2.55383-2.72825-1.96627平稳LNX1(0,02)3.551647-2.70809-1.96281不平稳DLNX1(0,0,1)-1.107310-2.70809-1.96281不平稳D(D(LNX1)(0,0,2)-4.86780-2.72825-1.96627平稳LNX2(c,t,2)-1.99875-3.71048-3.29780不平稳DLNX2(c,0,1)-2.70719-3.88675-3.05217不平稳D(D(LNX2)(0,0,2)-3.62840-2.71511-1.96642平稳
检验变量检验类型ADF统计值10%临界值5%临界值结论LNY(0,0,1)-0.42906-1.60661-1.96141不平稳DLNY(c,t,1)-2.75590-4.61621-3.71048不平稳D(D(LNY))(0,0,2)-2.55383-2.72825-1.96627平稳LNX1(0,0,2)3.551647-2.70809-1.96281不平稳DLNX1(0,0,1)-1.107310-2.70809-1.96281不平稳D(D(LNX1)(0,0,2)-4.86780-2.72825-1.96627平稳LNX2(c,t,2)-1.99875-3.71048-3.29780不平稳DLNX2(c,0,1)-2.70719-3.88675-3.05217不平稳D(D(LNX2)(0,0,2)-3.62840-2.71511-1.96642平稳
临界: 临界是指由某一种状态或物理量转变为另一种状态或物理量的最低转化条件;或者由一种状态或物理量转变为另一种状态或物理量。 ①每种物质都有一个特定的温度,在这个温度以上,无论怎样增大压强,气态物质不会液化,这个温度就是临界温度。 ②通常把在临界温度以上的气态物质叫做气体,把在临界温度以下的气态物质叫做汽体。 导体由普通状态向超导态转变时的温度称为为超导体的转变温度,或临界温度,用Tc 表示. 生态学释义:在生态学中指生物进行正常生命活动(生长、发育和生殖等)所需的环境温度的上限或下限。 临界值: 临界值是指物体从一种物理状态转变到另外一种物理状态时,某一物理量所要满足的条件,相当于数学中常说的驻点。因此利用临界状态求解物理量的最大值与最小值,就成了物理中求解最值的一种重要的方法。有人认为利用临界状态求解最值应谨慎,首先须分清两状态之间的关系。 f检验临界值表怎么查: 1、首先我要拿出F检验表了解自由度是多少,例如当a=0.01时,找到a=0.01的表; 2、下图红线所圈出的是以分位数为0.90,自由度为(6,8)的F 分布为例。首先选择分位数为0.90的分位数表,然后找到上方一行
的6,对应6下方的一列。 3、然后我们还要找到左侧一列中的8,对应8的那一行。 4、最后两者相交的那个数字就是需要查找的分位数为0.90,自由度为(6,8)的F分布的值。 需要注意的是:F是一种非对称分布,有两个自由度,且位置不可互换。F分布表横坐标是x,纵坐标是y,一个分位点一张表,F0.05(7,9)就查分位点是0.05的那张表横坐标为7,纵坐标为9处的值。 首先计算出大方差数据的自由度和小方差数据的自由度 然后计算出F值 查F表 表中横向为大方差数据的自由度;纵向为小方差数据的自由度。 将自己计算出来的F值与查表得到的F表值比较,如果 F < F表表明两组数据没有显著差异; F ≥ F表表明两组数据存在显著差异
卡方检验临界值表 自由度显著性水平(a ) 0.50 0.25 0.10 0.05 0.03 0.01 1 0.455 1.323 2.706 3.841 5.024 6.635 2 1.386 2.77 3 4.605 5.991 7.378 9.210 3 2.366 4.108 6.251 7.815 9.348 11.345 4 3.357 5.38 5 7.779 9.488 11.143 13.277 5 4.351 6.62 6 9.236 11.070 12.833 15.086 6 5.348 7.841 10.645 12.592 14.449 16.812 7 6.346 9.037 12.017 14.067 16.013 18.475 8 7.344 10.219 13.362 15.507 17.535 20.090 9 8.343 11.389 14.684 16.919 19.023 21.666 10 9.342 12.549 15.987 18.307 20.483 23.209 11 10.341 13.701 17.275 19.675 21.920 24.725 12 11.340 14.845 18.549 21.026 23.337 26.217 13 12.340 15.984 19.812 22.362 24.736 27.688 14 13.339 17.117 21.064 23.685 26.119 29.141 15 14.339 18.245 22.307 24.996 27.488 30.578 16 15.338 19.369 23.542 26.296 28.845 32.000 17 16.338 20.489 24.769 27.587 30.191 33.409 18 17.338 21.605 25.989 28.869 31.526 34.805 19 18.338 22.718 27.204 30.144 32.852 36.191 20 19.337 23.828 28.412 31.410 34.170 37.566 21 20.337 24.935 29.615 32.671 35.479 38.932 22 21.337 26.039 30.813 33.924 36.781 40.289 23 22.337 27.141 32.007 35.172 38.076 41.638 24 23.337 28.241 33.196 36.415 39.364 42.980 25 24.337 29.339 34.382 37.652 40.646 44.314 26 25.336 30.435 35.563 38.885 41.923 45.642 27 26.336 31.528 36.741 40.113 43.195 46.963 28 27.336 32.620 37.916 41.337 44.461 48.278 29 28.336 33.711 39.087 42.557 45.722 49.588 30 29.336 34.800 40.256 43.773 46.979 50.892 31 30.336 35.887 41.422 44.985 48.232 52.191 32 31.336 36.973 42.585 46.194 49.480 53.486
第4节 PP 单位根检验法与ADF 单位根检验法 DF 检验要求模型的随机扰动项t ε独立同分布。但在实际应用中这一条件往往不能满足(如上一节中的有关例子)。一般来说,如果估计模型的DW 值偏离2较大,表明随机扰动项是序列相关的,在这种情况下使用DF 检验可能会导致偏误,需要寻找新的检验方法。本节我们将介绍在随机扰动项服从一般平稳过程的情况下,检验单位根的PP 检验法和ADF 检验法。 一、 PP (Phillips&Perron )检验 首先考虑上一节情形二中扰动项为一平稳过程的单位根检验。假设数据由(真实过程) φφ∑∞ t t -1t t t j t -j j =0 y =ρy +u ,u =(B )ε= ε (1) 产生,其中{}t ε独立同分布,∞ <==2 )(,0)(σ εεt t D E 。∑∞ ==0 )(j j j B B ??,其中B 为 滞后算子,其系数满足条件∞ <∑ ∞ =0j j j ? 。在回归模型t t t u y y ++=-1ρα中检验假设: 0; 1:0==αρH 与DF 检验(情形二)一样,模型参数的OLS 估计为: ??? ? ????? ? ??=???? ??∑∑∑ ∑∑-----t t t t t t y y y y y y N 11 211 1? ?ρα 在1,0:0==ραH 成立时,上式可改写为:
1 12 1111t t t t t t ?T y u ?y y y u αρ-----?? ????= ? ? ? ? ?-???? ?? ∑ ∑∑∑∑ 以矩阵 ( )1 2 A diag T ,T =左乘上式两端,得 ()1 2 3122 3 2 1 111121111 112 2 11111 t t t t t t t t t t t t ?T y u T A A A ?y y y u T T y T u T y u T y T y αρ------------------???????????? ?? = ? ? ????? ? ? ?-??????????? ?? ? ???? ?= ? ? ??? ?? ∑ ∑∑∑ ∑∑ ∑∑∑∑ 利用有关单位根过程的极限分布(参见第2节),可得 ()1 21 1 0221122 00 011 1112 L W ()W (r )dr ?T ?T [W ()]W (r )dr W (r )dr λλαρλγλλ-??? ??? ? ???→ ? ? ? ?-- ? ? ?? ?? ?? ??? 其中)1(σ?λ=,∑∞ ==0 2 2 s s ?σ γ 。经过化简,可将统计量1?T ()ρ -的极限分离出来如下: ()(){}()()()()()()()12 12 2 1 2 2 00 11112 2 2 2 1111W W W r dr /?T W r dr [W r dr ] W r dr [W r dr ] λ γλ ρ ??---??-?+ ????--?? ?? ? ? ? ? ? (2) 此式表明,1?T ()ρ -的极限为两项之和,其中第一项是t u 为独立同分布时1?T ()ρ-的极限分布;第二项是由t u 的自相关性产生的,当t u 独立时,它等于零。说明上式是DF 分布的推广。 可以证明,统计量22??T ρσ有以下极限分布: