ADF检验和协整检验
- 格式:docx
- 大小:25.14 KB
- 文档页数:3

协整检验公式协整检验公式是用来检验两个时间序列之间是否存在协整关系的。
协整关系指的是两个变量虽然彼此相关,但是它们的差值却是(弱)平稳的。
广义上的协整关系可以用多个变量进行检验,但是在本文中我们主要关注两个变量的情况。
协整检验的基本思想是将两个变量进行线性组合,然后检验该线性组合是否是平稳的。
如果该线性组合是平稳的,那么就说明这两个变量之间存在协整关系。
协整关系一般分为一阶协整和二阶协整,即线性组合的阶数。
下面是协整检验的公式:1. 单位根检验公式(Augmented Dickey-Fuller Test):ADF(t_{y_{t}}) = \delta_{0} + \delta_{1}t_{y_{t}} + \sum_{i = 1}^{p} \gamma_{i}\Delta{y_{t-i}} + \epsilon_{t}其中,ADF(t_{y_{t}})表示单位根检验的统计量,\delta_{0} 和 \delta_{1}是回归系数, \sum_{i = 1}^{p}\gamma_{i}\Delta{y_{t-i}}表示滞后差分项,\epsilon_{t}表示残差。
2. 极小二乘法估计公式:\widehat{\mathbf{X}}(t_{k}) = \mathbf{c} +\widehat{\mathbf{V}}\mathbf{y}_{k-1} +\widehat{\boldsymbol{\alpha}}\mathbf{X}(t_{k-1}) +\delta\widehat{\mathbf{R}}^{-1}\widehat{\mathbf{U}}(t_{k-1})其中,\widehat{\mathbf{X}}(t_{k})表示对变量X在时间点t_{k}的估计,\mathbf{c}是常数项,\widehat{\mathbf{V}}是回归系数,\widehat{\boldsymbol{\alpha}} 是滞后相关系数,\delta\widehat{\mathbf{R}}^{-1} 是滞后误差关联系数,\widehat{\mathbf{U}}(t_{k-1})表示第k-1个时间点之前的累积残差。

1.ADF单位根检验2.Engle-Granger协整检验3.Da-vdson误差修正模型4.Granger因果关系检验1、简单回归;2、工具变量回归;3、面板固定效应回归;4、差分再差分回归(difference in differnece);5、狂忒二回归(Quantile)。
大杀器就这几种,破绽最少,公认度最高,使用最广泛。
真是所谓的老少皆宜、童叟无欺。
其他的方法都不会更好,只会招致更多的破绽。
你在STATA里面还可以看到无数的其他方法,例如GMM、随机效应等。
GMM其实是一个没有用的忽悠,例如估计动态面板的diffGMM,其关键思想是当你找不到工具变量时,用滞后项来做工具变量。
结果你会发现令人崩溃的情况:不同滞后变量的阶数,严重影响你的结果,更令人崩溃的是,一些判断估计结果优劣的指标会失灵。
这GMM的唯一价值在于理论价值,而不在于实践价值。
你如果要玩计量,你就可以在GMM的基础上进行修改(玩计量的方法后面讲)。
有人会问:简单回归会不会太简单?我只能说你真逗。
STATA里面那么多选项,你加就是了。
什么异方差、什么序列相关,一大堆尽管加。
如果你实在无法确定是否有异方差和序列相关,那就把选项都加上。
反正如果没有异方差,结果是一样的。
有异方差,软件就自动给你纠正了。
这不很爽嘛。
如果样本太少,你还能加一个选项:bootstrap来估计方差。
你看爽不爽!bootstrap就是自己把脚抬起来扛在肩上走路,就这么牛。
这个bootstrap就是用30个样本能做到30万样本那样的效果。
有吸引力吧。
你说这个简单回归简单还是不简单!很简单,就是加选项。
可是,要理论推导,就不简单了。
我估计国内能推导的没几个人。
那些一流期刊上论文作者,最多只有5%的人能推导,而且大部分是海龟。
所以,你不需要会推导,也能把计量做的天花乱坠。
工具变量(IV)回归,这不用说了,有内生性变量,就用这个吧。
一旦有内生性变量,你的估计就有问题了。

伪回归:如果一组非平稳时间序列之间不存在协整关系,则这一组变量构造的回归模型就是伪回归。
残差序列是一个非平稳序列的回归被称为伪回归,这样的一种回归有可能拟合优度、显著性水平等指标都很好,但是由于残差序列是一个非平稳序列,说明了这种回归关系不能够真实的反映因变量和解释变量之间存在的均衡关系,而仅仅是一种数字上的巧合而已。
伪回归的出现说明模型的设定出现了问题,有可能需要增加解释变量或者减少解释变量,抑或是把原方程进行差分,以使残差序列达到平稳。
伪回归是回归方程时间序列数据中涉及的一个概念。
该问题通俗来讲,就是:本来两个变量之间是不存在任何经济关系的,但是因为这两个时间序列数据表现出的变化趋势是一致的,所以,当你对其进行回归时候会得到一个很高的可决系数,让你误以为这一回归关系显著成立。
其实这一回归关系是错的,即伪回归。
要想避免伪回归,应首先对变量进行平稳性检验,接下联进行协整检验。
若变量之间存在协整关系,这一回归才算成立。
负相关negative correlation在回归与相关分析中,因变量值随自变量值的增大(减小)而减小(增大)的现象。
在这种情况下,表示相关程度的相关系数为负值。
相关程度用相关系数r表示,-1≤r<1,r的绝对值越大,表示变量之间的相关程度越高,r为负数时,表示一个变量的增加可能引起另一个变量的减少,此时,叫做负相关。
统计学中常用相关系数r来表示两变量之间的相关关系。
r的值介于-1与1之间,r为正时是正相关,反映当x增加(减少)时,y随之相应增加(减少);呈正相关的两个变量之间的相关系数一定为正值,这个正值越大说明正相关的程度越高。
当这个正值为1时就是完全正相关的情形,如点子排为一条直线,为完全正相关。
正相关虽然意思明确,其实是个模糊的概念,不可以量化,只是定性说法。
如果有明确的关系,例如y=2x,这叫y与x成正比,如果只是大体上,x、y的变化方向一样,例如x上升,y也上升或者x下降,y也下降,那么,这叫正相关。

正确的计算以年为的定基指数的方法为:如果有以上一年为100的GDP指数,如何计算以某固定年份为100的GDP指数?以北京1978年为100的定基指数计算为例:第一步:(1 )将1978年的GDP指数定义为100,这样,1978年定基指数(1978=100) = 100.第二步:(2)那么1979年的定基(1978 = 100)就等于当年的同比指数,即1979年GDP定基指数(1978=100) =1979年GDP指数(以上一年为100)第三步(最关键):1980 年GDP 指数(1978=100)=1979 年GDP 指数(1978 = 100)*1980年GDP指数(以上一年为100) /100o第四步:自1981年起重复第三步,即以各上年定基指数(1978=100)分别乘以当年同比指数(上年=100的指数)再除以100,就依次可以得到所有年份以1978年为100 的定基指数。
EXCEL直接复制第三步的公式就可以计算出来。
本文来自:人大经济论坛数据交流中心版,详细出处参考:定基指数编辑1定基指数与环比指数的关系2定基指数的分类3定基指数与环比指数的区别團定基鯉即定比指数。
定基指数是指在指数数列中,各期指数都以某一固定时期为基期。
定基担数说明现象在较长时期内的发展变化情况。
定基指数与环比指数的关系编辑定基指数与环比指数可以相互换算。
定基指数等于相应时期环比指数的连乘积。
这种关系的存在要求在以下条件下:各个指数釆用的权数不变,指数值中不出现零和负数的情况。
定基指数的分类绽1.数量指标定基指数数列2.质屋指标定基指数数列定基指数与环比指数的区别编辑环比指数数列和定基指数数列各有不同用途。
若要说明各时期的现象与其前一时期对比变动的情况时,可采用环比指数数列加以分析:而要说明各时期的现象与某一固定时期对比变动情况时,就应采用定基指数数列加以分析。
根据需求约朿型经济态势下影响经济快速增长的主要是消费需求列如:消费、出口等,在此经济态势下我们构造了如下的函数:根据上表可知数据是平稳的,通过了单根检验。


15.协整检验16.协整检验⼀、⽅法介绍基本思路:20世纪80年代,Engle 和Granger 等⼈提出了协整(Co-integration )的概念,指出两个或多个⾮平稳(non-stationary )的时间序列的线性组合可能是平稳的或是较低阶单整1的。
有些时间序列,虽然它们⾃⾝⾮平稳,但其线性组合却是平稳的。
⾮平稳时间序列的线性组合如果平稳,则这种组合反映了变量之间长期稳定的⽐例关系,称为协整关系。
协整关系表达的是两个线性增长量的稳定的动态均衡关系,更是多个线性增长的经济量相互影响及⾃⾝演化的动态均衡关系。
协整分析是在时间序列的向量⾃回归分析的基础上发展起来的空间结构与时间动态相结合的建模⽅法与理论分析⽅法。
理论模型:如果时间序列nt t t Y Y Y ,,,21都是d 阶单整,即)(d I ,存在⼀个向量)(21n αααα,,,=使得)(b d I Y t -'~α,这⾥)(21nt t t t Y Y Y Y ,,,=,0≥≥b d 。
则称序列nt t t Y Y Y ,,,21是),(b d 阶协整,记为),(b d CI Y t ~,α为协整向量。
⼀般情况下,协整检验有EG 两步法与JJ 的多变量极⼤似然法。
步骤⼀:为检验序列t Y 和t X 的),(b d CI 阶协整关系。
⾸先对每个变量进⾏单位根检验,得出每个变量均为)(d I 序列,然后选取变量t Y 对t X 进⾏OLS 回归,即有协整回归⽅程:1 如果⼀个⾮平稳时间序列经过差分变换变成平稳的,称其为单整过程,经过⼀次差分变换的称为⼀阶单整,记为I(1),n 次差分变换的称为n 阶单整,记为I(n)。
t t t X Y εβα++= (1)式中⽤α?和β?表⽰回归系数的估计值,则模型残差估计值为:t t X Y βαε--=(2)步骤⼆:对(1)式中的残差项t ε进⾏单位根检验,⼀般采⽤ADF 检验。
若检验结果表明t ε是)(0I 序列,即)(0~?I ε,则说明t ε是平稳序列,可得出t Y 和tX 是),(b d CI 阶协整的,其协整向量为),(β?1-。

常用的协整检验方法(一)常用的协整检验方法协整检验在时间序列分析中扮演着重要的角色,它用于检测多个非平稳时间序列之间是否存在长期的关系。
本文将介绍几种常用的协整检验方法,以帮助读者更好地理解和运用这些方法。
1. 单位根检验单位根检验是协整检验的基础,常用的方法有ADF(Augmented Dickey-Fuller)检验和PP(Phillips-Perron)检验。
它们都可以用来判断一个时间序列是否是平稳的。
•ADF检验:基本思想是通过引入滞后差分来构建一个扩展的Dickey-Fuller统计量,然后进行假设检验。
•PP检验:是对ADF检验的改进,它考虑了残差自相关的情况,减少了误检的可能性。
2. Johansen检验Johansen检验是用来检验时间序列之间是否存在协整关系的方法,它基于向量自回归(VAR)模型。
Johansen检验的原假设是存在r个协整关系,其中r是一个确定的非负整数。
Johansen检验有两个主要统计量:Trace统计量和Eigenvalue统计量。
通过比较这两个统计量和对应的临界值,可以判断时间序列之间是否存在协整关系以及协整关系的个数。
3. Engle-Granger检验Engle-Granger检验是一种基于OLS回归的协整检验方法。
它首先通过引入滞后差分将非平稳时间序列转化为平稳序列,然后利用最小二乘法建立回归模型,检验残差是否平稳。
Engle-Granger检验分为两个步骤:回归阶数的确定和残差的平稳性检验。
在回归阶数的确定中,可以采用信息准则(如AIC、BIC)来选择最佳的阶数。
在残差的平稳性检验中,可以使用ADF检验或PP 检验来判断。
4. 可视化方法除了以上的统计方法,还可以运用可视化方法来辅助协整检验。
常用的可视化方法包括散点图、路径图和回归图等。
散点图可以用来观察两个时间序列之间的关系,如果它们呈现出一种趋势性的关系,可能存在协整关系。
路径图可以展示多个时间序列之间的协整关系,有助于形象地理解协整关系的存在和特征。

计量经济学所有检验方法一、拟合优度检验可决系数TSS RSS TSS ESS R -==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。
该统计量越接近于1,模型的拟合优度越高。
调整的可决系数)1/()1/(12----=n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方和的自由度。
将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。
二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。
原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0统计量)1/(/--=k n RSS kESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。
三、变量的显著性检验(t 检验)对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。
原假设与备择假设:H0:βi =0 (i=1,2…k );H1:βi ≠0给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1)来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。
四、参数的置信区间参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。
统计量)1(~1ˆˆˆ----'--=k n t k n c S t iiii ii ie e βββββ在(1-α)的置信水平下βi 的置信区间是( , ) ββααββi i t s t s ii-⨯+⨯22,其中,t α/2为显著性水平为α、自由度为n-k-1的临界值。

面板数据的协整检验与协整回归1、前提:待检验的两个或多个变量之间(自变量与因变量),(单整:单个变量的差分平稳,一阶平稳:差分一次;二阶级平稳:差分两次;,,,,)必须是同阶单整。
原因:只有同阶单整,变量之间才有共同的增长趋势,才能同涨同落。
时间序列的协整检验:先做回归,后做协整检验。
2、面板数据的协整检验:先做协整检验,后做回归。
协整:变量之间的长期的稳定的协调关系。
3、面板数据的协整回归:(1)不变系数模型(各单位之间的回归系数大体相同)(2)变系数模型(各单位之间的回归系数大体不同)F检验:略。
(1)固定影响模型(总体数据)(2)随机影响模型(样本数据)三大回归:1、截面数据的回归(1)异方差(穷人的额外消费与富人的额外消费差距甚大:收入作为自变量;消费作为因变量)影响:自变量“纳伪”消除:WLS(2)自相关(时间序列的残差之间相互关联)如果模型成功,残差之间应该无自相关。
白噪声WN。
影响:自变量“纳伪”消除:广义差分法:既对因变量进行差分,也对自变量进行差分。
(狭义差分:只对因变量进行差分)。
(3)共线性信息重叠。
VIF:大于10剔除法(剔点)。
2、时间序列ARMA模型(自回归移动平均模型)平稳性检验:单位根检验ADF (1)等均值(实际:等观测值,08年GDP与09年GDP相等)(2)同方差(实际:同残差,08年残差与09年的残差相同)(3)协方差(相关系数):只与时间跨度的长短有关。
时间间隔越长,相互影响越弱。
随机漫步:(random walk)ut t Y Y Y E u Y E Y E u Y Y u u u Y u Y Y u u Y u Y Y u Y Y t t t tt ====+=+=+++=+=++=+=+=∑∑200003210323210212101)var()()()(......σ 随机漫步:方差变得无穷大,均值变得无意义。
“单位”根:回归系数为1. 。
,则此过程为平稳过程小于反之,若位根检验。
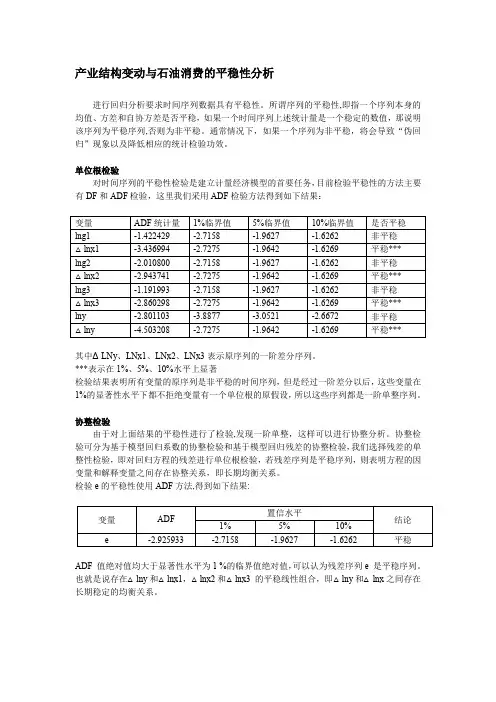
产业结构变动与石油消费的平稳性分析进行回归分析要求时间序列数据具有平稳性。
所谓序列的平稳性,即指一个序列本身的均值、方差和自协方差是否平稳,如果一个时间序列上述统计量是一个稳定的数值,那说明该序列为平稳序列,否则为非平稳。
通常情况下,如果一个序列为非平稳,将会导致“伪回归”现象以及降低相应的统计检验功效。
单位根检验对时间序列的平稳性检验是建立计量经济模型的首要任务,目前检验平稳性的方法主要有DF 和ADF 检验,这里我们采用ADF 检验方法得到如下结果:变量 ADF 统计量 1%临界值 5%临界值 10%临界值 是否平稳 lng1 -1.422429 -2.7158 -1.9627 -1.6262 非平稳 △lnx1 -3.436994 -2.7275 -1.9642 -1.6269 平稳*** lng2 -2.010800 -2.7158 -1.9627 -1.6262 非平稳 △lnx2 -2.943741 -2.7275 -1.9642 -1.6269 平稳*** lng3 -1.191993 -2.7158 -1.9627 -1.6262 非平稳 △lnx3 -2.860298 -2.7275 -1.9642 -1.6269 平稳*** lny -2.801103 -3.8877 -3.0521 -2.6672 非平稳 △lny-4.503208-2.7275-1.9642-1.6269平稳***其中ΔLNy 、LNx1、LNx2、LNx3表示原序列的一阶差分序列。
***表示在1%、5%、10%水平上显著检验结果表明所有变量的原序列是非平稳的时间序列,但是经过一阶差分以后,这些变量在1%的显著性水平下都不拒绝变量有一个单位根的原假设,所以这些序列都是一阶单整序列。
协整检验由于对上面结果的平稳性进行了检验,发现一阶单整,这样可以进行协整分析。
协整检验可分为基于模型回归系数的协整检验和基于模型回归残差的协整检验,我们选择残差的单整性检验,即对回归方程的残差进行单位根检验,若残差序列是平稳序列,则表明方程的因变量和解释变量之间存在协整关系,即长期均衡关系。

单位根检验和协整检验单位根检验和协整检验是时间序列分析中常用的两种方法。
本文将分别介绍这两种检验方法的概念、原理和应用。
一、单位根检验1.概念单位根检验,又称为ADF(Augmented Dickey-Fuller)检验,是一种用于判断时间序列是否具有平稳性的方法。
它的基本原理是通过对时间序列进行一定程度的差分,使得序列变得平稳,从而判断序列是否具有单位根。
2.原理在时间序列中,如果一个变量具有单位根,则说明它在长期内存在趋势或者周期性波动。
而如果一个变量具有平稳性,则说明它在长期内不存在趋势或者周期性波动。
因此,通过对时间序列进行差分,可以消除其中的趋势或者周期性波动,使得序列变得平稳。
ADF检验的基本原理就是通过比较差分后的时间序列与原始时间序列之间的关系来判断是否存在单位根。
具体地说,在ADF检验中,我们需要假设一个线性回归模型:ΔYt = α + βt + γYt-1 + δ1ΔYt-1 + … + δpΔYt-p + εt其中,Δ表示差分符号;Yt表示时间序列;α、β、γ、δ1~δp和εt分别表示回归系数和误差项。
如果该模型中的γ等于0,则说明时间序列具有单位根,即存在趋势或者周期性波动;如果γ小于0,则说明时间序列具有平稳性,即不存在趋势或者周期性波动。
3.应用ADF检验通常用于判断时间序列是否具有平稳性。
在金融领域中,它常被用于股票价格的分析和预测。
例如,通过对股票价格进行ADF检验,可以判断该股票是否处于上涨或下跌趋势,并进一步预测未来的走势。
二、协整检验1.概念协整检验是一种用于判断两个或多个时间序列之间是否存在长期稳定的关系的方法。
它的基本原理是通过构建线性组合,使得两个或多个时间序列之间的关系变得平稳。
2.原理在协整检验中,我们需要假设一个线性组合模型:Yt = α + βXt + εt其中,Yt和Xt分别表示两个时间序列;α、β和εt分别表示回归系数和误差项。
如果该模型中的β等于0,则说明Yt和Xt之间不存在长期稳定的关系;如果β不等于0,则说明Yt和Xt之间存在长期稳定的关系,即它们是协整的。
ADF检验通俗解释
ADF检验,全名为Augmented DickeyFuller检验,是一种用于检验时间序列数据中单位根存在性的统计检验方法。
单位根表示时间序列数据具有非平稳性,即均值或方差可能随时间变化。
以下是对ADF检验的通俗解释:
单位根的概念:在时间序列中,如果一个变量具有单位根,意味着它的变化随时间的推移而保持在某一水平上。
这使得时间序列变量呈现出一种趋势,而不是随机波动。
平稳性的重要性:在统计学和经济学中,我们通常假设数据是平稳的,即它们的均值和方差在时间上是恒定的。
如果时间序列具有单位根,就可能导致违反这个平稳性假设。
ADF检验的目的:ADF检验的目的是确定一个时间序列是否具有单位根,从而判断该序列是否是平稳的。
如果序列是平稳的,就更容易应用许多统计方法,因为这些方法通常基于数据的稳定性。
检验的步骤:
提出假设:ADF检验的零假设是序列具有单位根,即非平稳。
备择假设是序列是平稳的。
进行统计检验:通过比较计算出的检验统计量与临界值,来判断是否拒绝零假设。
如果拒绝了零假设,就认为序列是平稳的。
ADF统计量的解释:ADF检验的统计量反映了单位根的存在性。
如果ADF统计量的值小于某个阈值(即临界值),那么我们可能拒绝
零假设,认为序列是平稳的。
总体而言,ADF检验是一种用于检验时间序列平稳性的工具,它帮助我们判断一个变量是否随时间保持在某一水平上,从而影响到我们在统计建模和分析中如何处理这个变量。
单位根检验和协整检验一、单位根检验的概念和原理单位根检验是时间序列分析的重要工具,在经济学中广泛应用于研究时间序列数据的平稳性。
它用来判断一个时间序列是否具有单位根的存在,单位根表示一个时间序列具有非平稳的特性。
单位根检验的原理是基于自回归模型(Autoregressive Model,简称AR模型)。
AR模型是一种常用的时间序列分析模型,它假设当前观测值与过去的p个观测值存在线性关系。
在单位根检验中,通常使用的是ADF检验(Augmented Dickey-Fuller Test)和KPSS检验(Kwiatkowski-Phillips-Schmidt-Shin Test)。
ADF检验是一种常用的单位根检验方法,它基于Dickey-Fuller单位根检验,并对原检验方法进行扩展和改进。
ADF检验的原假设是存在单位根,备择假设是不存单位根。
通过ADF检验的结果,可以判断一个时间序列是否平稳。
KPSS检验是另一种常用的单位根检验方法,它的原假设是存在单位根,备择假设是不存单位根。
KPSS检验的结果与ADF检验相反,当p值小于显著性水平时,拒绝存在单位根的原假设,即序列是平稳的。
二、单位根检验的应用场景单位根检验在经济学中有着广泛的应用场景。
以下是一些常见的应用场景:1.金融市场:单位根检验可用于判断金融市场的收益率时间序列数据是否具有平稳性。
平稳的收益率序列可以用于构建有效的投资组合和预测股票价格。
2.宏观经济:在宏观经济分析中,单位根检验可用于判断经济增长率、失业率等变量是否具有平稳性。
平稳的经济变量序列可以提供有效的经济政策参考。
3.国际贸易:单位根检验可用于判断国际贸易量和汇率等变量是否具有平稳性。
平稳的贸易量和汇率序列对于制定贸易政策和汇率政策具有重要意义。
三、协整检验的概念和原理协整检验是单位根检验的一种推广,它用于判断两个或多个时间序列之间是否存在长期均衡关系。
协整关系表示两个或多个时间序列的线性组合是平稳的,即它们在长期内是相互影响的。
实验报告6单位根检验和协整检验(验证性实验)实验原理:1、给定实际问题的时间序列,利用DF检验及ADF检验,检验时间序列的平稳性以及判断模型的生成形式。
2、给定两个非平稳时间序列,利用EG检验,检验它们之间是否存在协整关系。
实验题目:某地区过去38年谷物产量序列如下表所示:24.5 33.7 27.9 27.5 21.7 31.9 36.8 29.9 30.2 32.0 34.019.4 36.0 30.2 32.4 36.4 36.9 31.5 30.5 32.3 34.9 30.136.9 26.8 30.5 33.3 29.7 35.0 29.9 35.2 38.3 35.2 35.536.7 26.8 38.0 31.7 32.6这些年该地区相应的降雨量序列如下表所示:9.6 12.9 9.9 8.7 6.8 12.5 13.0 10.1 10.1 10.1 10.87.8 16.2 14.1 10.6 10.0 11.5 13.6 12.1 12.0 9.3 7.711.0 6.9 9.5 16.5 9.3 9.4 8.7 9.5 11.6 12.1 8.010.7 13.9 11.3 11.6 10.4(1)使用单位根检验,分别考察这两个序列的平稳性。
(2)选择适当模型,分别拟合这两个序列的发展。
(3)确定这两个序列之间是否具有协整关系。
(4)如果这两个序列之间有协整关系,请建立适当的模型拟合谷物产量序列的发展。
实验要求:第一步:编程建立R数据集;第二步:调用plot.ts程序对两组数据绘制时序图。
第三步:利用adf.test和pp.test检验这两个时间序列是否存在单位根?分别对这两个时间序列进行建模。
第四步:利用po.test对这对数据进行分析,考察它们是否具有协整关系。
第五步:根据这两个时间序列的相关性,利用lm建立这两个时间序列之间的回归模型。
第六步:根据输出的残差序列,判断是否平稳?同时对残差序列进行单位根检验,以验证判断是否正确,若残差序列平稳,则两个时间序列之间存在协整关系,可以建立动态回归模型。
计量经济学协整检验方法协整检验(cointegration test)是计量经济学中用于检验变量之间是否存在长期稳定的均衡关系的方法。
它的主要目的是确定变量之间的长期关系,即是否存在一个稳定的均衡关系,从而可以进行有效的经济分析和预测。
本文将介绍几种常用的协整检验方法。
1. 单位根检验方法(Unit root test)单位根检验用于检验时间序列数据是否具有非平稳性。
一般来说,如果变量是非平稳的,那么它们之间就不可能存在长期稳定的均衡关系。
常用的单位根检验方法有ADF检验(Augmented Dickey-Fuller test)和KPSS检验(Kwiatkowski–Phillips–Schmidt–Shin test)等。
ADF检验是一种参数统计方法,可以用来检验变量是否是单位根过程,从而判断是否存在协整关系;KPSS检验则是一种非参数统计方法,用于检验变量是否是平稳的。
2. Johansen协整检验方法(Johansen cointegration test)Johansen协整检验方法是一种常用的多变量协整检验方法,可以同时检验多个变量之间的协整关系。
该方法基于向量自回归模型(vector autoregressive model,VAR),通过对向量误差修正模型(vectorerror correction model,VECM)的估计,检验向量自回归参数的协整关系。
Johansen协整检验方法具有较强的参数估计效率和较好的统计性质,被广泛应用于实证研究中。
3. Engle-Granger两步法(Engle-Granger two-step method)Engle-Granger两步法是一种常用的两步骤协整检验方法。
首先,通过对变量进行单位根检验,确定哪些变量是非平稳的;然后,对非平稳变量进行协整关系的估计和检验。
该方法的优点是简单易行,适用于小样本情况,但它的估计效率相对较低。
4. 引导回归法(Bootstrap method)引导回归法是一种非参数的协整检验方法,用于解决传统统计方法在小样本情况下可能存在的偏误和低功效问题。
单位根与协整检验实验心得
1、单位根检验:单位根检验用于判断时间序列数据是否具有非平稳性。
常用的单位根检验方法有ADF(Augmented Dickey-Fuller)检验和KPSS(Kwiatkowski-Phillips-Schmidt-Shin)检验等。
通过单位根检验,可以确定时间序列数据是否需要进行差分操作以实现平稳性。
2、协整检验:协整检验用于判断多个时间序列之间是否存在长期稳定的关系。
当变量之间存在协整关系时,它们的误差项会相互修正,从而保持一个稳定的平衡状态。
常用的协整检验方法有Johansen 检验和Engle-Granger检验等。
协整关系的存在说明变量之间存在长期的均衡关系,可以应用于建立有效的统计模型。
3、实验设计:在进行单位根和协整检验前,请确保选择适当的样本时间范围和取样频率,以获取可靠的结果。
同时,还要注意样本量的充分性,样本量较小可能导致检验结果不准确。
4、结果解释:根据单位根和协整检验的结果,可以得出相应的统计量和p值。
通常,在统计显著水平(如0.05)下,如果p值小于显著性水平,则可以拒绝原假设,认为序列是平稳的或存在协整关系。
协整检验的实施步骤1. 引言协整检验是时间序列分析中常用的方法之一,用于检测两个或多个非平稳时间序列之间的长期关系。
本文将介绍协整检验的实施步骤,帮助读者对该方法有一个全面的了解。
2. 协整检验的基本概念在进行协整检验之前,首先需要了解协整的基本概念。
协整是指两个或多个时间序列之间存在长期稳定的关系,即它们的线性组合是平稳的。
而非协整的时间序列之间则没有这种长期关系。
3. 协整检验的实施步骤3.1 数据准备进行协整检验前,需要准备两个或多个时间序列的数据。
这些时间序列通常需要满足平稳性的要求,在实际应用中,常常使用对数差分后的数据进行分析。
3.2 计算线性组合在协整检验中,需要计算时间序列的线性组合,即对时间序列进行加权求和。
这些权重可以通过最小二乘法来估计。
3.3 构建伪显著性检验协整检验的核心是构建伪显著性检验,用于判断时间序列是否存在协整关系。
常用的伪显著性检验方法有ADF检验和PP检验。
3.4 进行检验在构建好伪显著性检验后,可以进行协整检验。
这一步骤通常需要计算相应的检验统计量,并将其与临界值比较,以判断时间序列是否存在协整关系。
3.5 结果解释最后,根据协整检验的结果,可以解释时间序列之间的关系。
如果检验结果表明存在协整关系,说明这些时间序列之间存在长期稳定的关系;如果检验结果表明不存在协整关系,说明这些时间序列之间没有长期关系。
4. 实例应用以下是一个实例应用的协整检验步骤:1.收集两支股票的收盘价数据并进行平稳性检验;2.对股票收盘价数据进行对数差分;3.估计股票收盘价数据的线性组合权重;4.构建ADF检验和PP检验的伪显著性检验;5.进行协整检验,计算检验统计量;6.将检验统计量与临界值进行比较;7.根据检验结果解释股票之间的关系。
5. 总结本文介绍了协整检验的实施步骤,包括数据准备、线性组合计算、伪显著性检验的构建、检验的实施以及结果的解释。
通过掌握这些步骤,读者能够更好地理解和应用协整检验方法。
回归:
Dependent Variable: Y
Method: Least Squares
Date: 04/09/14 Time: 20:40
Sample: 2003 2012
Included observations: 10
Variable Coefficient Std. Error t-Statistic Prob.
L -7.584788 2.987176 -2.539116 0.0441
K 0.627143 0.208381 3.009604 0.0237
I -0.131563 0.070898 -1.855656 0.1129
C 82.50331 31.82297 2.592571 0.0411
R-squared 0.992831 Mean dependent var 7.271989 Adjusted R-squared 0.989246 S.D. dependent var 0.387985 S.E. of regression 0.040234 Akaike info criterion -3.299031 Sum squared resid 0.009713 Schwarz criterion -3.177997 Log likelihood 20.49515 Hannan-Quinn criter. -3.431805 F-statistic 276.9743 Durbin-Watson stat 1.920806 Prob(F-statistic) 0.000001
变量Y的ADF检验
Null Hypothesis: Y has a unit root
Exogenous: Constant
Lag Length: 1 (Fixed)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic 0.745045 0.9832 Test critical values: 1% level -4.582648
5% level -3.320969
10% level -2.801384
*MacKinnon (1996) one-sided p-values.
Warning: Probabilities and critical values calculated for 20 observations
and may not be accurate for a sample size of 8
变量L的ADF检验
Null Hypothesis: L has a unit root
Exogenous: Constant
Lag Length: 1 (Fixed)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -2.149207 0.2335
Test critical values: 1% level -4.582648
5% level -3.320969
10% level -2.801384
变量K的ADF检验
Null Hypothesis: K has a unit root
Exogenous: Constant
Lag Length: 1 (Fixed)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic 1.366096 0.9953 Test critical values: 1% level -4.582648
5% level -3.320969
10% level -2.801384
变量I的ADF检验
Null Hypothesis: I has a unit root
Exogenous: Constant, Linear Trend
Lag Length: 1 (Fixed)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -1.035819 0.8697 Test critical values: 1% level -5.835186
5% level -4.246503
10% level -3.590496
协整检验
Null Hypothesis: RESID01 has a unit root
Exogenous: None
Lag Length: 1 (Automatic based on SIC, MAXLAG=1)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -3.175517 0.0060 Test critical values: 1% level -2.886101
5% level -1.995865
10% level -1.599088
*MacKinnon (1996) one-sided p-values.
Warning: Probabilities and critical values calculated for 20 observations
and may not be accurate for a sample size of 8。