词性标注
- 格式:doc
- 大小:26.50 KB
- 文档页数:3

实现spaCy训练词性标注模型词性标注是指为输⼊⽂本中的单词标注对应词性的过程。
词性标注的主要作⽤在于预测接下来⼀个词的词性,并为句法分析、信息抽取等⼯作打下基础。
通常地,实现词性标注的算法有HMM(隐马尔科夫)和深度学习(RNN、LSTM等)。
然⽽,在中⽂中,由于汉语是⼀种缺乏词形态变化的语⾔,没有直接判断的依据,且常⽤词兼类现象严重,研究者主观原因造成的不同都给中⽂词性标注带来了很⼤的难点。
本⽂将介绍如何通过Python程序实现词性标注,并运⽤spaCy训练中⽂词性标注模型:1、对训练集⽂本内容进⾏词性标注⾸先,对于给定的训练集数据:利⽤spaCy模块进⾏nlp处理,初始化⼀个标签列表和⽂本字符串,将⽂本分词后⽤“/”号隔开,并储存⽂本的词性标签到标签列表中,代码如下:def train_data(train_path):nlp = spacy.load('zh_core_web_sm')train_list = []for line in open(train_path,"r",encoding="utf8"):train_list.append(line)#print(train_list)result = []train_dict = {}for i in train_list:doc = nlp(i)label = []text = ""#print(doc)for j in doc:text += j.text+"/"#result.append(str(j.text))#print(text)label.append(j.pos_[0])#print(result)train_dict[j.pos_[0]] = {"pos":j.pos_}#print(train_dict)result.append((text[:-1],{'tags':label}))return result,train_dict⼤致会得到如下结果:2、利⽤spaCy训练模型然后,进⾏模型训练:@plac.annotations(lang=("ISO Code of language to use", "option", "l", str),output_dir=("Optional output directory", "option", "o", Path),n_iter=("Number of training iterations", "option", "n", int))def main(lang='zh', output_dir=None, n_iter=25):nlp = spacy.blank(lang) ##创建⼀个空的模型,en表⽰是英⽂的模型tagger = nlp.add_pipe('tagger')# Add the tags. This needs to be done before you start training.for tag, values in train_dict.items():print("tag:",tag)print("values:",values)#tagger.add_label(tag, values)tagger.add_label(tag)#tagger.add_label(values['pos'])#nlp.create_pipe(tagger)print("3:",tagger)#nlp.add_pipe(tagger)optimizer = nlp.begin_training() ##模型初始化for i in range(n_iter):random.shuffle(result) ##打乱列表losses = {}for text, annotations in result:example = Example.from_dict(nlp.make_doc(text), annotations)#nlp.update([text], [annotations], sgd=optimizer, losses=losses)nlp.update([example], sgd=optimizer, losses=losses)print(losses)运⾏结果如下:3、测试集验证模型最后,同样过程处理测试数据:代码如下:test_path = r"E:\1\Study\⼤三下\⾃然语⾔处理\第五章作业\test.txt" test_list = []for line in open(test_path,"r",encoding="utf8"):test_list.append(line)for z in test_list:txt = nlp(z)test_text = ""for word in txt:test_text += word.text+"/"print('test_data:', [(t.text, t.tag_, t.pos_) for t in txt])# save model to output directoryif output_dir is not None:output_dir = Path(output_dir)if not output_dir.exists():output_dir.mkdir()nlp.to_disk(output_dir)print("Saved model to", output_dir)# test the save modelprint("Loading from", output_dir)nlp2 = spacy.load(output_dir)doc = nlp2(test_text)print('Tags', [(t.text, t.tag_, t.pos_) for t in doc])验证结果如下:。

中⽂词性标注与viterbi算法⼀、viterbi算法原理及适⽤情况当事件之间具有关联性时,可以通过统计两个以上相关事件同时出现的概率,来确定事件的可能状态。
以中⽂的词性标注为例。
中⽂中,每个词会有多种词性(⽐如"希望"即是名字⼜是动词),给出⼀个句⼦后,我们需要给这个句⼦的每个词确定⼀个唯⼀的词性,实际上也就是在若⼲词性组合中选择⼀个合适的组合。
动词、名词等词类的搭配是具有规律性的,⽐如动词+名词的形式是⼤量存在的,当我们看到句⼦"存在希望",如果确定了"存在"是动词,那么由于动名词组合的概率较⼤,我们就会认定"希望"是名词。
viterbi算法的原理就是基于此。
我们需要计算所有的名词+动词,名词+名词,动词+形容词。
等各种种词性搭配的出现概率,然后从中选出最⼤概率的组合。
⼆、操作步骤1、需要准备⼀个语料库,包含已经正确标注了词性的⼤量语句。
2、对语料库的内容进⾏统计。
需要得到以下数据。
(1)所有可能的词性。
(2)所有出现的词语。
(3)每个词语以不同词性出现的次数。
(4)记录句⾸词为不同词性的次数。
(5)记录句⼦中任⼀两种词性相邻的次数(如遇到:"看电影"这个句⼦,则有[动词][名词]的值加⼀。
3、针对前⾯统计的结果,进⾏分析计算。
需计算以下数据。
(1)计算每类词性作为句⾸出现的⽐例(⽐如:动词为句⾸,占所有不同词性为句⾸中的⽐例),记录到fstart[TYPE_NUM]。
(2)计算后词固定为词性[n]时,前词为词性[x]占总情况的⽐例(如:后词固定为[动词]时,前词[名词]出现的次数占所有[x][动词]的⽐例),记录到fshift[TYPE_NUM][TYPE_NUM];(3)计算每⼀个词作为不同类词性出现的次数,占所有该类词出现总数的⽐例(如:"中国"作为名词出现的次数占所有名词的⽐例),记录到ffashe[TYPE_NUM][60000]4、输⼊句⼦进⾏词性标注输⼊的句⼦中每个词有多个词性。

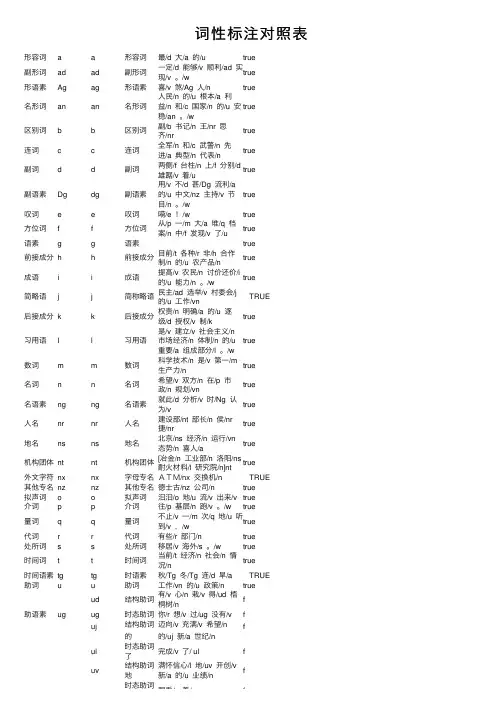
词性标注对照表形容词a a形容词最/d ⼤/a 的/u true副形词ad ad副形词⼀定/d 能够/v 顺利/ad 实现/v 。
/wtrue形语素Ag ag形语素喜/v 煞/Ag ⼈/n true名形词an an名形词⼈民/n 的/u 根本/a 利益/n 和/c 国家/n 的/u 安稳/an 。
/wtrue区别词b b区别词副/b 书记/n 王/nr 思齐/nrtrue连词c c连词全军/n 和/c 武警/n 先进/a 典型/n 代表/ntrue副词d d副词两侧/f 台柱/n 上/f 分别/d雄踞/v 着/utrue副语素Dg dg副语素⽤/v 不/d 甚/Dg 流利/a的/u 中⽂/nz 主持/v 节⽬/n 。
/wtrue叹词e e叹词嗬/e !/w true⽅位词f f⽅位词从/p ⼀/m ⼤/a 堆/q 档案/n 中/f 发现/v 了/utrue语素g g语素 true前接成分h h前接成分⽬前/t 各种/r ⾮/h 合作制/n 的/u 农产品/ntrue成语i i成语提⾼/v 农民/n 讨价还价/i的/u 能⼒/n 。
/wtrue简略语j j简称略语民主/ad 选举/v 村委会/j的/u ⼯作/vnTRUE后接成分k k后接成分权责/n 明确/a 的/u 逐级/d 授权/v 制/ktrue习⽤语l l习⽤语是/v 建⽴/v 社会主义/n市场经济/n 体制/n 的/u重要/a 组成部分/l 。
/wtrue数词m m数词科学技术/n 是/v 第⼀/m⽣产⼒/ntrue名词n n名词希望/v 双⽅/n 在/p 市政/n 规划/vntrue名语素ng ng名语素就此/d 分析/v 时/Ng 认为/vtrue⼈名nr nr⼈名建设部/nt 部长/n 侯/nr捷/nrtrue地名ns ns地名北京/ns 经济/n 运⾏/vn态势/n 喜⼈/atrue机构团体nt nt机构团体[冶⾦/n ⼯业部/n 洛阳/ns耐⽕材料/l 研究院/n]nttrue外⽂字符nx nx字母专名ATM/nx 交换机/n TRUE 其他专名nz nz其他专名德⼠古/nz 公司/n true拟声词o o拟声词汩汩/o 地/u 流/v 出来/v true介词p p介词往/p 基层/n 跑/v 。


CTB词性标注指南第一章引言中文几乎没有屈折语素。
譬如,词语不随时态、格、人称和数量而曲折变化。
因此,对特定文本中的词进行词性标注往往都很困难。
这个文件是专为宾州中文树库项目[XPS+00]所设计的。
这个项目的目标是构建一个十万词的有语法托架的中文官话文本语料库。
标注包括两个步骤:第一阶段是中文分词和词性标注,第二阶段是句法托架。
每个步骤包括至少两个经过,即数据库由一个标注者标注,结果文件由另一个标注者检查。
词性标注指南,就如分词指南和托架指南,在项目进行过程中已经修订了多次。
到目前为止,我们已经在我们的网站上发行了三个版本:第一部草作完成于1998年12月,在第一个中文分词和词性标注文件发行后;第二部草作完成于1999年3月,在第二个中文分词和词性标注文件发行后;这个文件,是第三部草作,修订于第二个托架文件发行后。
在这个第三部草作中,与前两部草作相比,主要改变在于:(1)我们增加了一章引言来解释指南中存在的一些基本原理;(2)我们增加了对中文词语的注释;(3)我们把这个指南写成了一个技术性报告,报告被发表于宾夕法尼亚大学认知科学研究机构(IRCS)。
1.1 标注标准词性标注(POS)的核心问题是词性标注是否应该基于意义或者句法分布来标注。
这个问题自1950年以来就被热烈争论到现在,并且始终存在两种不同的观点。
譬如,中文词“毁灭”可以被翻译为英文中的destroy或destroys或destroyed或destroying或destruction,并且如它英文所对应的词一样使用。
根据第一种观点,词性标注应该只基于意义。
因为词的意义在它所有的用法中基本都是一样的,它就应该总是被标注为一个动词。
第二种观点是词性标注应该由词的句法分布来决定。
当“毁灭”是一个名词短语的首词,它在那个文本中就应该被标注为一个名词;当“毁灭”是一个动词短语的首词,它就应该被标注为一个动词。
我们选择了句法分布作为我们词性标注的主要标准,因为这与当代语言学理论所采纳的原则一致,譬如X-bar理论和GB理论中的首字投射概念。
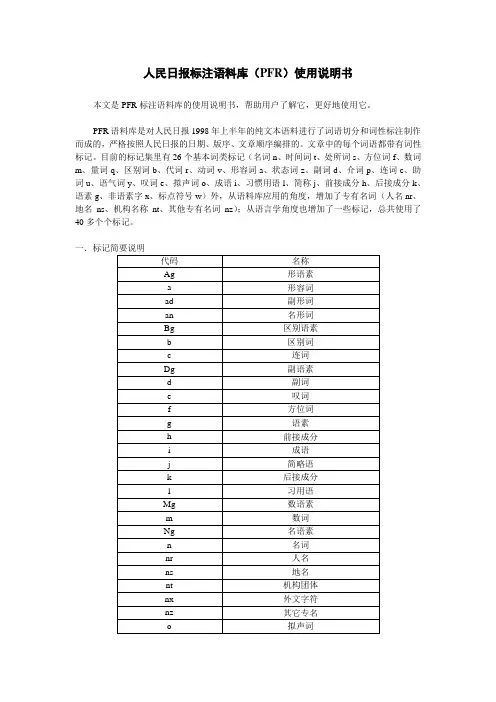
人民日报标注语料库(PFR)使用说明书本文是PFR标注语料库的使用说明书,帮助用户了解它,更好地使用它。
PFR语料库是对人民日报1998年上半年的纯文本语料进行了词语切分和词性标注制作而成的,严格按照人民日报的日期、版序、文章顺序编排的。
文章中的每个词语都带有词性标记。
目前的标记集里有26个基本词类标记(名词n、时间词t、处所词s、方位词f、数词m、量词q、区别词b、代词r、动词v、形容词a、状态词z、副词d、介词p、连词c、助词u、语气词y、叹词e、拟声词o、成语i、习惯用语l、简称j、前接成分h、后接成分k、语素g、非语素字x、标点符号w)外,从语料库应用的角度,增加了专有名词(人名nr、地名ns、机构名称nt、其他专有名词nz);从语言学角度也增加了一些标记,总共使用了40多个个标记。
二.格式说明1.语料是纯文本文件,文件中每一行代表一自然段或者一个标题,一篇文章有若干个自然段,因此在语料中一篇文章是由多行组成的。
2.文件名格式为“月-日-版号-篇章号”。
3.一篇文章里面的段落之间是不空行的,在两篇文章之间,会有一个空行,表示文章的分界线,同时,下一篇文章的“篇章号-段号”都会有所改变。
4.标号之后,是2个单字节空格,然后开始正文。
5.正文部分按照规范已经切分成词,并且加上标注,标注的格式为“词语/词性”,即词语后面加单斜线,再紧跟词性标记。
词与词之间用2个单字节空格隔开。
每段最后的词,在标记之后也有2个单字节空格,保持格式一致。
6.语料中除了词性标记以外,还有“短语标记”,这种情况一般出现在机构团体名称、成语等情况中。
如“通过/p [中央/n 人民/n 广播/vn 电台/n]nt 、/w”中,用“[ ]”合起来的部分是一个完整的机构团体名称,方括号后面紧跟标注nt,nt之后空两个单字节空格,保持了格式的一致。
三.例子迈向/v 充满/v 希望/n 的/u 新/a 世纪/n ——/w 一九九八年/t 新年/t 讲话/n (/w 附/v 图片/n 1/m 张/q )/w……在/p 1998年/t 来临/v 之际/f ,/w 我/r 十分/m 高兴/a 地/u 通过/p [中央/n 人民/n 广播/vn 电台/n]nt 、/w [中国/ns 国际/n 广播/vn 电台/n]nt 和/c [中央/n电视台/n]nt ,/w 向/p 全国/n 各族/r 人民/n ,/w 向/p [香港/ns 特别/a 行政区/n]ns 同胞/n 、/w 澳门/ns 和/c 台湾/ns 同胞/n 、/w 海外/s 侨胞/n ,/w 向/p 世界/n 各国/r 的/u 朋友/n 们/k ,/w 致以/v 诚挚/a 的/u 问候/vn 和/c 良好/a 的/u 祝愿/vn !/w。

民国时期汉语语文辞书词性标注研究随着社会的不断发展,语言文字的研究也逐渐引起人们的关注,其中词性标注是语言文字研究的重要内容之一。
而在民国时期,中国的语文辞书对于词性标注也有着一定的研究和探索,这为今后的语言文字研究提供了一定的参考价值。
本文将对民国时期汉语语文辞书词性标注进行研究和分析。
一、民国时期的语文辞书民国时期是中国近现代史上一个重要的历史时期,也是中国语文教育发展的重要时期。
在这个时期,中国的语文辞书经历了不少的变革和创新,其对于中国语文教育的影响也是深远的。
在民国时期,词典、辞书等语文资料开始逐渐系统化,编纂工作也逐渐进入了专业化的轨道,这为词性标注的研究提供了一定的基础。
二、民国时期汉语词性标注在民国时期的语文辞书中,对于词性的标注多集中在词典的解释部分。
有的辞书会在解释某个词语的时候,顺带标注上该词语的词性,比如动词、名词、形容词等。
虽然在当时并没有形成明确的规范,而且也没有系统的方法和标准来进行词性标注,但是这种初步的尝试已经为后来的词性标注研究奠定了基础。
在民国时期的一些语文辞书中也开始出现了对于词性的分类和归纳。
比如有的辞书会对名词、动词、形容词等词性进行简单的分类和概括,虽然这种分类并不够细致和系统,但是这为后来的词性标注研究提供了一些思路和启发。
民国时期的汉语词性标注虽然并不够完善和系统,但是它在一定程度上为后来的词性标注研究提供了一些参考和启发。
我们需要意识到词性标注对于语言文字研究的重要性。
在当代,词性标注已经成为了语言分析的重要手段之一,它可以帮助我们更准确地理解和分析语言文字,对于语言文字的教学和研究有着重要的意义。
我们需要借鉴民国时期的词性标注经验,这其中包括民国时期的词典、辞书等语文资料,以及一些学者在词性标注研究方面的探索和尝试。
尽管民国时期的词性标注并不够完善和系统,但是其中也包含了一些宝贵的经验和启发,我们可以从中吸取一些有益的经验和教训。
我们应该在民国时期的基础上进行更深入更系统的词性标注研究。

基于错误驱动的汉语词性标注研究的开题报告一、选题背景随着自然语言处理技术的发展,汉语词性标注已经成为其重要的基础与核心技术之一。
在汉语文本处理过程中,词性标注有助于从文本中提取出语言学上的有意义的信息,为后续的自然语言处理任务提供支持。
因此,汉语词性标注在中文信息处理中具有重要的价值。
然而,现有的汉语词性标注系统仍然存在着一些问题,比如低准确率、不完整的标注信息等。
为了解决这些问题,很多学者致力于研究词性标注算法,但大多数研究都是基于大量的正确标注数据,很少有研究是基于错误驱动的。
实际上,错误驱动的方法可以提高标注系统的鲁棒性,使得标注系统在遇到错误数据时能够更好地处理。
二、研究目的本研究将基于错误驱动的方法,研究汉语词性标注,通过分析和研究错误标注数据,探索有效的汉语词性标注算法和模型。
本研究旨在提高汉语词性标注系统的准确率和鲁棒性,为后续的自然语言处理任务提供更好的支持。
三、研究内容和方法1. 收集和整理汉语标注数据。
本研究将收集并整理汉语词性标注数据,包括正确标注数据和错误标注数据。
2. 分析错误标注数据。
通过对错误标注数据的分析,研究错误标注的原因,探索有效的错误处理策略。
3. 研究基于错误驱动的汉语词性标注算法和模型。
基于错误标注数据的研究结果,本研究将设计并实现基于错误驱动的汉语词性标注算法和模型,并进行评估和比较。
4. 优化汉语词性标注系统。
根据研究结果,本研究将优化已有的汉语词性标注系统,并提出改进意见和建议。
四、研究意义本研究旨在探索基于错误驱动的汉语词性标注方法,通过分析错误标注数据,提高汉语词性标注系统的准确率和鲁棒性,为自然语言处理提供更好的支持。
此外,本研究还有助于优化现有的汉语词性标注系统,为后续的语料库构建、机器翻译等自然语言处理任务提供更好的基础支持。
五、论文结构本文将包括以下几个部分:1. 绪论:介绍研究的背景和意义,同时介绍本文的研究目的和内容。
2. 相关研究:介绍当前汉语词性标注研究的现状,包括基于机器学习和基于知识库的方法等。

民国时期汉语语文辞书词性标注研究民国时期汉语语文辞书是研究民国时期汉语语言和文化的重要资料之一。
其中辞书词性标注的准确性和规范性对于研究民国时期汉语语言的语法和用法具有重要的影响。
本文将从历史背景、标注方法和标注质量三个方面较为全面地探讨民国时期汉语语文辞书的词性标注问题。
一、民国时期的历史背景民国时期指的是1912年至1949年间的中国历史时期。
这时期的汉语语言和文化发生了较大的变革和发展。
一方面,从清末到民初,中国社会和文化开始受到了西方现代化的影响,这对汉语语言的演变和文化交流产生了深远的影响。
另一方面,民国时期为了推进“国语运动”,普及国语,对汉语语文进行了规范化的努力。
这些因素都对民国时期汉语语文辞书的编纂和标注产生了重要的影响。
二、标注方法民国时期的汉语语文辞书的词性标注方法主要有原《广韵》方法、宋代词义排列法和训诂体系三种。
原《广韵》方法原《广韵》方法是指按照《广韵》字音表的音序排列法来进行词汇的编排。
这种方法应用较广,尤其在字音图书和韵部词典中应用比较多。
这种方法标注的依据是音韵体系和字义。
它的优点是规范、严密,能够反映汉语语音的演变和发展。
但缺点在于,容易将同一词的不同词性归为同一条目,并且不能充分反映语言的语法和用法。
宋代词义排列法训诂体系训诂体系是指标注词汇词性时按照注解和注释来确定词汇的用法和语义。
这种方法运用比较广泛,主要应用于诗词、小说和文学作品的注解和研究中。
这种方法标注的依据是注释和翻译。
它的优点是能够充分反映文字的用法和语义,但缺点是标注不够规范、统一,并且标注的质量不够稳定。
三、标注质量民国时期的汉语语文辞书的词性标注质量在一定程度上受到标识方法的影响。
但是总体来说,该时期汉语语文辞书的词性标注质量相对较差,存在着以下几个问题。
首先,标注不够规范,标注内容、方法和标注标准缺乏统一性和规范性,容易造成对同一词汇的不同词性标注混淆。
其次,缺乏标注质量的监督和检验机制,标注标准和标注质量容易受到类别、地区和个人习惯的影响,标注结果不够稳定和统一。

民国时期汉语语文辞书词性标注研究1. 引言1.1 研究背景在民国时期,中国正处在民主革命的风起云涌之际,社会政治变革与文化发展迅速推动着中华民族向前。
在这一时期,汉语语文辞书的编纂、出版与研究也随之迅速发展。
民国时期的汉语语文辞书在构建现代汉语规范体系和促进语言文字的规范化方面发挥了重要作用。
研究背景中的关键问题在于现代汉语的发展与演变,以及汉语词性标注技术的提升和应用。
通过对民国时期汉语语文辞书的特点进行深入研究,可以更好地了解当时汉语规范化的历史进程和语言文化的融合发展。
对汉语词性标注技术的发展历程和现代汉语语料库的应用进行分析,有助于提升研究者对汉语语言特色和词性规律的认识和理解。
对民国时期汉语语文辞书词性标注研究的重要性在于促进汉语语言研究的深入发展,挖掘和传承民国时期汉语规范化的成果,为现代汉语语料库的建设和词性标注技术的不断完善提供有益借鉴。
的探究将为本文的研究内容提供必要的理论支持和学术视野。
1.2 研究意义民国时期汉语语文辞书词性标注研究具有重要的意义。
这项研究有助于深入了解民国时期汉语语文辞书的编纂特点和语言规范,从而帮助我们更好地理解当时人们的语言运用习惯和语言观念。
通过对民国时期汉语语文辞书的词性标注实践进行探究,可以为我们揭示该时期语言发展的规律和特点,为语言学研究提供宝贵的实证资料。
将现代汉语语料库应用于该项研究,可以为我们提供更为全面和准确的语言数据,有助于提高标注方法的效率和准确性。
通过对民国时期汉语语文辞书词性标注研究的总结和展望,有助于我们更好地把握历史语言文化的传承和发展,为促进汉语语言学的研究和传承做出贡献。
深入研究民国时期汉语语文辞书的词性标注技术,对于推动中国语言学研究的发展具有重要的理论和实践意义。
2. 正文2.1 民国时期汉语语文辞书的特点一、文风古雅。
民国时期是中国语文发展的重要时期,许多辞书在文字表达上追求古朴雅致,注重字形和笔法的工整,使得词条的阅读具有一种古典气息。
POS使用方法什么是POS?POS(Part-of-Speech)指的是词性标注,是自然语言处理中重要的一个任务。
它的目标是对给定的文本中的每个单词进行词性的标注,如名词、动词、形容词等。
词性标注是自然语言处理中的基础任务,对于语义分析、信息抽取、机器翻译等应用都具有重要作用。
POS的作用POS的主要作用是用于语言理解和语言生成。
通过对文本中每个单词的词性进行标注,可以帮助理解句子的结构和语义,从而更好地进行文本分析和处理。
POS还可以用于文本分类、信息抽取、句法分析等任务。
POS的常见标记集POS的标记集因应用和语言而异,常见的标记集包括以下几种:•英文标记集:常见的英文标记集包括Penn Treebank标记集和Brown标记集。
Penn Treebank标记集包括名词(NN)、动词(VB)、形容词(JJ)等。
Brown标记集则将单词分为名词(NN)、动词(VB)、形容词(JJ)、副词(RB)等。
•中文标记集:中文标记集通常使用国际通用的标记集,如Universal POS标记集。
其中常见的标记有名词(NOUN)、动词(VERB)、形容词(ADJ)等。
POS的常见算法POS的算法主要分为基于规则和基于统计的方法。
•基于规则的方法:基于规则的方法使用人工定义的规则来进行词性标注。
这种方法的好处是可以利用专家知识,但缺点是规则的定义和调整比较困难,并且难以处理一些复杂的语言现象。
•基于统计的方法:基于统计的方法使用机器学习算法来进行词性标注。
常见的统计模型包括隐马尔可夫模型(HMM)和条件随机场(CRF)。
这种方法的好处是可以根据大量的标注数据自动学习模型,但需要足够的训练数据和特征工程的支持。
POS的使用方法POS的使用方法主要包括数据准备、模型训练和标注预测三个步骤。
数据准备首先需要准备标注好词性的训练数据。
训练数据应包括一系列句子和对应的词性标注。
可以使用已有的标注数据集,如Penn Treebank数据集,也可以通过人工标注或半自动标注的方式获得训练数据。
基于隐马尔可夫模型的词性标注方法研究一、引言词性标注是自然语言处理中的一个重要任务,其主要目的是确定一串单词在语法上的类别,即将每个单词标注为名词、动词、形容词、副词等。
为了实现自然语言处理的自动化,许多基于机器学习的词性标注方法已经被提出。
其中,基于隐马尔可夫模型的词性标注方法被证明是非常有效的。
二、隐马尔可夫模型介绍隐马尔可夫模型是一种统计模型,通常用于对时间序列数据进行建模。
在自然语言处理中,隐马尔可夫模型可以用来进行词性标注。
在该模型中,可以将词汇序列视为观察序列,将词性序列视为隐状态序列。
模型的主要目标是对给定的观察序列来推断出最可能的隐状态序列,即最可能的词性序列。
三、隐马尔可夫模型在词性标注中的应用1. 模型训练模型训练通常分为两个步骤:参数估计和模型选择。
在参数估计中,通常使用最大似然估计或最大后验概率估计来计算模型参数。
在模型选择中,通常使用交叉验证等技术来确定最优的模型结构。
2. 模型评估模型评估主要用于评估模型的性能。
通常使用精确度、召回率、F1 值等指标来评估模型的性能。
3. 模型应用在应用过程中,隐马尔可夫模型的主要任务是对给定的词汇序列进行标注,从而得到其词性序列并进行后续处理。
四、隐马尔可夫模型的优势相对于传统的基于规则的词性标注方法,隐马尔可夫模型具有以下优势:1. 隐马尔可夫模型可以自动从数据中学习模型参数,从而提高标注的准确性;2. 隐马尔可夫模型可以根据数据自动调整模型结构,从而使模型更加精确;3. 隐马尔可夫模型可以应对词汇数量增加或减少的情况,从而提高模型的鲁棒性。
五、总结基于隐马尔可夫模型的词性标注方法已经被证明是一种非常有效的自然语言处理方法。
通过对词汇序列和词性序列进行模型训练和评估,并结合模型优势,该方法可以实现更加准确的词性标注,从而为自然语言处理提供强有力支持。
从句法分析看词性标注 口牛雅娴 刘丙丽 万红雅董艺 摘要:词性标注是语言研究者进行句法分析和其他研究的基础,其划分是否得当直接影响着语料库的下一 步建设。本文从句法分析实际操作的角度对国内几个常用分词系统的词性标记问题进行了对比分析,着重探讨了 其中一些标记给句法标注带来的问题,如习用语和简称、前接成分和后接成分。针对这些问题,本文从实用的角 度,在参考多方建议的基础上,提出了相应的标注策略。 关键词:词性标注句法分析习用语词缀语素字
一、
引言
对语料进行词性标注,只是语料库建设的初期阶段, 也是进行下一步句法标注的基础。我们在对语料进行句法 标注的过程中发现,分词系统中一些不恰当的词类标记不 仅影响到句法标注的效率,也影响到标注的准确性和一致 性。因此,本着节省人力、物力的原则,在综合考虑词类 标记对句法层面的影响之后,本文力图在词性标注这一问 题上提出更加科学的可行性建议,以促进基于语料库的进 一步的语言研究。 首先,分词类别(或POS标记)应该在句法上有功能意 义,例如名词、动词等。不是从句法层面划分出来的标记 即使标示出来也无法在句法分析中进行处理。 私聊”。“挖坑”用来指“设陷井使人中计”,“小虾” 用来指“网络新手”。类似的还有“造砖、灌水、楼上 (前个帖子)、隔壁、病毒”等等。 2.感情色彩的变化,许多由旧词产生的新义,感情色 彩发生了明显地改变,主要有两种情况: (1)由感情色彩不明显变为具有明显的感情色彩。 有些词本来并不具有明显的感情色彩,产生新义后,具有 了或贬或褒的感情色彩,如“病毒”由一种病原体变为指 “具有破坏性的计算机程序”,由原来的中性变为贬义 词;“白菜”这个本来不具有感情色彩的现用来指“美丽 漂亮的女孩子”的词语,具有了明显的褒义。另外还有 “面、黑(用黑客的手段袭击)、挖坑”等等,这些词语 的固有意义都没有明显的感情色彩,而产生新义后则都具 有了明显的感情色彩。 (2)感情色彩发生了明显改变。如“坏女孩”(具 有叛逆、野性、豪爽、率真、顽劣、任性、动感、生猛等 特点的新一代女孩),由原来的贬义词变为中性词, “恶 (极其、非常)”也由原来的贬义变为中性,“后起之 秀”(爱睡懒觉,最迟起床的住校生)则由原来的褒义变 为贬义。 “变异是普遍存在的一种社会语言现象”,“可以 说,没有变异就没有语言的发展”_5]。“旧词赋新义”是 在网络环境下产生的语言变体,它给语言带来了新鲜活 力,使人耳目一新。随着网络的发展,有的新义已固定 下来,成为新的一项,有的甚至已跨出网络,进入其他的 使用领域。如“防火墙”一词,它的比喻最先应用于网络 语言中,现在又可用于金融业中指防止风险的蔓延,还可 用于指经济贸易的保护措施,用于社会生活中指防止各种 造假、制假、欺骗行为的产生。再如“网络”的新义“在 电的系统中,由若干元件组成的用来使电信号按一定要求 传输的电路或其中的一部分”已被收录进《现代汉语词 典》,成为“网络”的第三个义项。但是,应该看到,大 多数固有词形赋予的新义具有极大的随意性与不稳定性, 它们的应用范围目前主要局限在网络环境中,虽然有的新 义已为越来越多的人理解和使用,但哪些新义和有多少新 义最终能固定下来,从而成为汉语词语的固定义位,仍有 待时间的检验。
《古代汉语虚词词典》词性标注的问题《古代汉语虚词词典》(中国社会科学院语言研究所古代汉语研究室编,商务印书馆,1999年第1版,以下简称《词典》)是目前最新、也是印数最多的虚词词典,它代表了古汉语虚词研究的最高水平。
《词典》将虚词研究纳入汉语史研究的轨道,它在描写虚词的意义和用法的同时,也对虚词进行历时研究,探求每个虚词的历史演变轨迹。
此外,它还明确区分了虚词结构的语法层级单位:单音虚词、复合虚词、惯用词组、固定格式,对所收词条一一标注词性。
标注词性是虚词词典的本职工作,但词性标注不一致也是个普遍存在的问题,主要是对性质相同(意义和用法相同)的词条词性标注不一致。
《词典》也存在这个问题。
下面仅以“安、何、曷、胡、乌、恶、奚、焉”为例,就《词典》代词与副词的词性标注问题来讨论。
一单音虚词相关词条词性标注不一致,出现了两种标准的交叉。
⒈用于动词前作状语,询问原因的词,有的标为代词,有的标为副词。
(1)标为代词的,如:安代词(义项四):问方法和原因,可译为“怎么”等,一般只作状语。
沛公曰:“君安与项伯有故?”(《史记·项羽本纪》)曷疑问代词(义项四):代原因,在动词或主语前作状语,可译为“为什么”。
汝曷弗告朕,而胥动以浮言,恐沈于众?(《尚书·盘庚》)(2)标为副词的,如:何副词(义项一):用在谓语前,用来询问原因,可译为“为什么”“干吗”等。
子有酒食,何不日鼓瑟?(《诗·唐风·山有枢》)奚副词(义项一):用于动词前,表示对原因的询问,可译为“怎么”“为什么”等。
子奚乘是车也?(《韩非子·外储说左上》)⒉在谓语前,与助动词“能”“敢”“足”等连用,表示反诘的词,有的标为代词,有的标为副词。
(1)标为代词的有“安”“曷”“胡”:安代词(义项五):表示反诘。
可译为“怎么”。
后面常有助动词“得”“敢”“可”“肯”“能”“足”等。
段干木盖贤者也,吾安敢不轼?且吾闻段干木尝肯以己易寡人也。
ICTCLAS汉语词性标注汉语⽂本词性标注标记集Ag 形语素形容词性语素。
形容词代码为a,语素代码g前⾯置以A。
a 形容词取英语形容词adjective的第1个字母。
ad 副形词直接作状语的形容词。
形容词代码a和副词代码d并在⼀起。
an 名形词具有名词功能的形容词。
形容词代码a和名词代码n并在⼀起。
b 区别词取汉字“别”的声母。
c 连词取英语连词conjunction的第1个字母。
Dg 副语素副词性语素。
副词代码为d,语素代码g前⾯置以D。
d 副词取adverb的第2个字母,因其第1个字母已⽤于形容词。
e 叹词取英语叹词exclamation的第1个字母。
f ⽅位词取汉字“⽅”g 语素绝⼤多数语素都能作为合成词的“词根”,取汉字“根”的声母。
h 前接成分取英语head的第1个字母。
i 成语取英语成语idiom的第1个字母。
j 简称略语取汉字“简”的声母。
k 后接成分l 习⽤语习⽤语尚未成为成语,有点“临时性”,取“临”的声母。
m 数词取英语numeral的第3个字母,n,u已有他⽤。
Ng 名语素名词性语素。
名词代码为n,语素代码g前⾯置以N。
n 名词取英语名词noun的第1个字母。
nr ⼈名名词代码n和“⼈(ren)”的声母并在⼀起。
ns 地名名词代码n和处所词代码s并在⼀起。
nt 机构团体 “团”的声母为t,名词代码n和t并在⼀起。
nz 其他专名 “专”的声母的第1个字母为z,名词代码n和z并在⼀起。
o 拟声词取英语拟声词onomatopoeia的第1个字母。
p 介词取英语介词prepositional的第1个字母。
q 量词取英语quantit的第1个字母。
r 代词取英语代词pronoun的第2个字母,因p已⽤于介词。
s 处所词取英语space的第1个字母。
Tg 时语素时间词性语素。
时间词代码为t,在语素的代码g前⾯置以T。
t 时间词取英语time的第1个字母。
u 助词取英语助词auxiliaryVg 动语素动词性语素。
在词性标记集已确定,并且词典中每个词都有确定词性的基础上,对一个输入词串转换成相应词性标记串的过程叫做词性标注。
词性标注需要解决的问题
如何判定兼类词在具体语境中的词性。
对未登录词需要猜测其词
兼类词对句法分析的影响:尽管兼类词在词汇中所占比例并不很高,但由于它们出现的比例较高,因而对于句法分析会造成直接影响。
词性标注方法:
概率方法
基于隐马尔可夫模型的词性标注方法
机器学习规则的方法
基于转换的错误驱动词性标注方法
从统计模型角度考虑词性标注问题
1给定一个词串W=w1w2...wn,如果T=t1t2...tn是W对应的词性标记串。
所谓对W进行词性标注就是在给定W和带有词性标注信息的词表条件下,求T的过程。
2假设W存在多个可能的词性标记串T1,T2,...Ti,对W进行词性标注就是在已知W的条件下求使P(T|W)最大的词性标注串T',即求:
3T'=argmax P(T|W)
例如词串“把/ 这/ 篇/ 报道/ 编辑/ 一/ 下/”中有些词有多个词性标记(兼类词),因此该词串对应的词性标注串有多个。
全部标记结果等于各个词的词性标注数目的乘积,即4×1×1×2×2×2×3=96。
词性标注的任务就是从多个可能性中找出可能性最高的词性标注串T’
上例中对应的词性标注串是“prvnvmq”
对于一个词性标注系统来说,它所“认为”的可能性最高的词性标注串T'可能是正确的,也有可能是错误的。
为了表示方便,做如下约定:
Wi:表示一个词串;
wi:表示一个具体词语;
Ti:表示一个词性标注串;
ti:表示一个具体词性标记;
隐马尔可夫模型(Hidden Markov Model,HMM)是描述连续符号序列的条件概率统计模型,可定义为五元组λ=(S,V,A,B,π),其中
S代表一个状态集合S={1,2,...,N}
V代表一个可观察符号的集合V={v1,v2,...,vM}
A代表状态转移矩阵(N行×N列)A=[aij],其中
aij=P(qt+1=j | qt=i), 1≤i,j≤N,即从状态i转移到下一个状态j的概率
B是可观察符号的概率分布B={bj(k)},其中bj(k)是在状态j是输出观察符号vk的概率,即bj(k)=P(vk | j),1≤j≤N, 1≤k≤M.
π代表初始状态的概率分布π={πi},表示在时刻1选择状态i的概率,即πi=P(q1=i)
一个确定的HMM,其状态数是确定的,每个状态可能输出的观察值数目也是确定的,参数A,B,π可通过统计样本得到。
词性标注和HMM之间的关系
1词性序列相当于HMM的状态序列
2给定词串是可观察符号的序列
在给定观察值W和模型参数λ的情况下,求状态序列T,使该状态序列T“最好地解释”观察值序列W
T' = argmax P(T|W,λ) (公式1)
根据条件概率公式可知:
P(T|W,λ)=P(T,W|λ)/P(W|λ) (公式2)
对所有情况,λ是一样的,因此可省略λ,故得P(T|W)=P(T,W)/P(W)=P(T)P(W|T)/P(W) (公式3)
公式3中P(W)是词串的概率,对所有可能的词性标注结果来说P(W)都是一样的,对P(T|W)的值的比较没有影响,因此可忽略P(W),故公式1可演化为:
T' = argmax P(T|W,λ)=argmax P(T)P(W|T)(公式4)
其中:
P(T)=P(t1|t0)P(t2|t1,t0)P(t3|t2,t1,t0)...P(ti|ti-1,ti-2,...,t0) (公式5)
根据一阶马尔可夫假设,当前词性标记只和它之前的一个词性标记有关,于是得到:P(T)=P(t1|t0)P(t2|t1)P(t3|t2)...P(ti|ti-1) (公式6)
公式6表明P(T)实际上是词性标注串中两两相邻的词性标注的转移概率的乘积。
两个词性标记之间的转移概率P(ti|ti-1) 可通过训练语料库中词性频度估算(HMM中的参数A)
P(ti|ti-1) =训练语料中ti在ti-1之后出现的次数/ 训练语料中ti-1出现的总次数(公式7)
P(W|T)是已知词性标注串T的条件下词串W的概率,即
P(W|T)=P(w1|t1)P(w2|t2,t1,w2,w1)...P(wi|ti,ti-1,...,t1,wi,wi-1,...,w1) (公式8) 根据独立性假设,已知词性标注串的条件下词串的条件概率只跟各个词和对应的词性标注有关,则公式8可简化为:
P(W|T)=P(w1|t1)P(w2|t2)...P(wi|ti) (公式9)
P(wi|ti) 可根据训练语料中的词性频度和词语频度估算:
P(wi|ti) =训练语料中wi的词性被标记为ti的次数/ 训练语料中ti出现的总次数(公式10)
根据以上公式,可求所有的P(T|W)=P(T)P(W|T),比较P(T|W)可得使P(T|W)最大的词性标注串T'
计算效率分析:
1针对一个给定词串W,计算所有的P(T|W),其效率很低
2假设词性标注数目为N(对应于HMM的状态个数),给定词串W有M个词,考虑最坏的可能性,则全部可能的词性标注串(对应于HMM的状态序列)有NM个
3随着词串的增加,计算复杂性呈“指数”增长
4VOLSUNGA算法和Viterbi算法采用动态规划的方法大大提高了词性标注的效率
基于转换的错误驱动的词性标注方法:一种基于规则的词性标注方法。
通过机器学习的方法学习“改错”规则。
转换规则的组成
改写规则:将一个词性转换成另一个词性
激活环境:激发改写规则的条件
转换规则(T1)
改写规则:将一个词性从动词(v)改为名词(n);
激活环境:该词左边第一个词的词性是量词(q),第二个词的词性是数词(m);
转换举例
改写之前的带有词性标注的句子:
他/r 做/v 了/u 一/m 个/q 报告/v
使用规则T1改写之后的句子
他/r 做/v 了/u 一/m 个/q 报告/n
基于转换的错误驱动词性标注方法根据转换规则将错误的词性改为正确词性。
需要注意的是转换规则是有确定顺序的,当使用这些规则去标注新的语料时,也是按照该顺序进行标注。
转换规则模板是用于生成具体的转换规则的模板。
开始时,由人来定义转换规则模板,并根据该模板生成一条条用于词性标记的转换规则。
所谓机器学习就是从这些转换规则中学习有助于提高词性标注正确率的那些规则。
基于转换的词性标注所需的前提条件:
1词性标记集
2转换规则模板及一系列转换规则
3一个达到一定规模的已标注语料库C0
4语料库C0对应的未标注版本C0_raw(生语料库)
5一个用于初始词性标注器
初始词性标注器可以是任意的词性标注器,其词性标注的正确率并不重要。
因为基于转换的词性标注器将会根据转换规则去改正错误的词性标记。
如基于HMM的词性标注器
或简单词性标注器(只取频度最高的词性标记)
甚至可以将所有词性都标记为名词
基于转换的词性标注的核心是学习转换规则
基于转换的错误驱动的词性标注方法:
(1) 一个事先标注好词性标记的语料库C0作为学习时的训练语料库;
(2) 一个词性标记集和一套转换规则模板;
(3) 一组候选转换规则;
(4) 一个初始标注器;
(5) 一个以评价函数为核心的学习器;
(6) 通过学习得到一个有序转换规则集;
(7) 首先用初始标注器对生语料库进行初始标注,然后用学到的规则集修改标注结果。