词性标注
- 格式:pdf
- 大小:670.67 KB
- 文档页数:54

词性标注的名词解释词性标注是自然语言处理中的一项重要任务,其主要目的是确定文本中每个单词的词性。
在计算机领域中,词性标注通常被称为词性标签或词类标签。
它是自然语言处理技术的基础,对于诸如机器翻译、文本分类、信息检索等任务具有重要的影响。
词性是语法学中的一个概念,用于描述一个单词在句子中的语法属性和词义特征。
在英语中,常用的词性包括名词、动词、形容词、副词、代词、冠词、连词、介词和感叹词等。
而在中文中,常见的词性有名词、动词、形容词、副词、量词、代词、连词、介词、助词、语气词和标点符号等。
词性标注的目标是为每个词汇选择正确的词性。
这个过程通常涉及到构建一个标注模型,在已知的语料库中学习每个词汇的词性,并根据上下文的语法规则判断未知词汇的词性。
词性标记常用的方法有规则匹配、基于统计的方法和机器学习方法。
规则匹配是最简单的词性标注方法之一,它基于事先定义好的语法规则。
通过匹配文本中的规则模式,为每个单词分配一个预设的词性。
尽管规则匹配的方法简单易行,但它的局限性在于无法充分利用上下文信息,难以处理歧义问题。
基于统计的方法则通过统计大规模语料库中词汇在不同上下文环境中出现的概率,来预测词性。
这种方法基于频率统计的结果,假设一个单词在给定上下文中具有最大概率的词性,从而进行标注。
其中,隐马尔可夫模型(HMM)是最常用的统计方法之一。
HMM模型通过学习词性之间的转移概率和词性与单词之间的发射概率,来进行词性标注。
与基于统计的方法相比,机器学习方法更加灵活。
机器学习方法通过训练样本学习词汇和其对应的词性之间的潜在关系,并根据这种关系对未知词汇进行标注。
常见的机器学习方法包括最大熵模型、条件随机场(CRF)等。
这些方法通过结合上下文信息和词汇特征,提高了标注的准确性和泛化能力。
词性标注在自然语言处理中具有广泛的应用。
在机器翻译中,词性标注的结果能帮助翻译系统区分单词的不同含义,提高翻译质量。
在文本分类中,词性标注可以辅助判断文本的属性或情感倾向。
词法分析:词性标注词法分析(lexical analysis):将字符序列转换为单词(Token)序列的过程分词,命名实体识别,词性标注并称汉语词法分析“三姐妹”。
在线演⽰平台:词性标注(Part-Of-Speech tagging, POS tagging)也被称为语法标注(grammatical tagging)或词类消疑(word-category disambiguation)是语料库语⾔学(corpus linguistics)中将语料库内单词的词性按其含义和上下⽂内容进⾏标记的⽂本数据处理技术。
语料库(corpus,复数corpora)指经科学取样和加⼯的⼤规模电⼦⽂本库。
所谓词性标注就是根据句⼦的上下⽂信息给句中的每个词确定⼀个最为合适的词性标记。
⽐如,给定⼀个句⼦:“我中了⼀张彩票”。
对其的标注结果可以是:“我/代词中/动词了/助词/ ⼀/数词/ 张/量词/ 彩票/名词。
/标点”词性标注的难点主要是由词性兼类所引起的。
词性兼类是指⾃然语⾔中⼀个词语的词性多余⼀个的语⾔现象。
(⼀词多性)常⽤的词性标注模型有 N 元模型、隐马尔科夫模型、最⼤熵模型、基于决策树的模型等。
其中,隐马尔科夫模型是应⽤较⼴泛且效果较好的模型之⼀。
【jieba】import jieba.posseg as psegwords = pseg.cut("⽼师说⾐服上除了校徽别别别的")for word, flag in words:print('%s %s' % (word, flag))⽼师 n 说 v ⾐服 n 上 f 除了 p 校徽 n 别 d 别 d 别的 r【hanLP】from pyhanlp import *content = "⽼师说⾐服上除了校徽别别别的"print(HanLP.segment(content))⽼师/nnt, 说/v, ⾐服/n, 上/f, 除了/p, 校徽/n, 别/d, 别/d, 别的/rzv ref:。
![词性标注简介_精通Python自然语言处理_[共6页]](https://uimg.taocdn.com/7900ae87ad02de80d5d84024.webp)
第4章词性标注:单词识别词性(Parts-of-speech,POS)标注是NLP中的众多任务之一。
它被定义为将特定的词性标记分配给句中每个单词的过程。
词性标记可以识别一个单词是否为名词、动词还是形容词等等。
词性标注有着广泛的应用,例如信息检索、机器翻译、NER、语言分析等。
本章将包含以下主题:•创建词性标注语料库。
•选择一种机器学习算法。
•涉及n-gram的统计建模。
•使用词性标注数据开发分块器。
4.1 词性标注简介词性标注是一个对句中的每个标识符分配词类(例如名词、动词、形容词等)标记的过程。
在NLTK中,词性标注器存在于nltk.tag包中并被TaggerIbase类所继承。
考虑一个NLTK中的例子,它为指定的句子执行词性标注:>>> import nltk>>> text1=nltk.word_tokenize("It is a pleasant day today")>>> nltk.pos_tag(text1)[('It', 'PRP'), ('is', 'VBZ'), ('a', 'DT'), ('pleasant', 'JJ'),('day', 'NN'), ('today', 'NN')]我们可以在TaggerI的所有子类中实现tag()方法。
为了评估标注器,TaggerI提4.1词性标注简介 63供了evaluate()方法。
标注器的组合可用于形成回退链,如果其中一个标注器无法完成词性标注时,则可以使用下一个标注器进行词性标注。
让我们看看由Penn Treebank提供的那些可用的标记列表(https://www.ling. /courses/Fall_2003/ling001/penn_treebank_pos.html):CC - Coordinating conjunctionCD - Cardinal numberDT - DeterminerEX - Existential thereFW - Foreign wordIN - Preposition or subordinating conjunctionJJ - AdjectiveJJR - Adjective, comparativeJJS - Adjective, superlativeLS - List item markerMD - ModalNN - Noun, singular or massNNS - Noun, pluralNNP - Proper noun, singularNNPS - Proper noun, pluralPDT - PredeterminerPOS - Possessive endingPRP - Personal pronounPRP$ - Possessive pronoun (prolog version PRP-S)RB - AdverbRBR - Adverb, comparativeRBS - Adverb, superlativeRP - ParticleSYM - SymbolTO - toUH - InterjectionVB - Verb, base formVBD - Verb, past tenseVBG - Verb, gerund or present participleVBN - Verb, past participleVBP - Verb, non-3rd person singular presentVBZ - Verb, 3rd person singular presentWDT - Wh-determinerWP - Wh-pronounWP$ - Possessive wh-pronoun (prolog version WP-S)WRB - Wh-adverb。

自然语言处理中的词性标注技术词性标注技术是自然语言处理中的一项基础技术,指的是将一段文本中的每个词汇标注上其所属的词性,如名词、动词、形容词等。
在自然语言处理中,词性标注技术是信息提取、信息检索、机器翻译等任务的基础。
本文将从词性标注技术的定义、应用、算法原理和评价指标等方面进行介绍。
一、词性标注技术的定义和应用词性标注技术是自然语言处理中的一项基础技术,它是将自然语言文本转化为计算机可识别的形式的一种重要手段。
从应用的角度看,词性标注技术被广泛应用在信息提取、信息检索、机器翻译、文本分类、情感分析、自动问答等领域。
以信息检索为例,词性标注技术可以用于区分文本中的不同单词,根据文本的关键词进行搜索和排序,提高搜索引擎的准确性和效率。
在机器翻译领域中,词性标注技术可以帮助解决不同语言之间的词性差异,从而提高翻译品质。
二、词性标注技术的算法原理词性标注技术的算法原理是基于统计机器学习方法的。
它将自然语言文本转换为计算机可以理解的数字表示,并基于这些数字进行词性标注。
常见的词性标注算法有基于规则的算法和基于统计学习的算法。
基于规则的算法是基于语言学规则的,它通过先定义词性的特征和规则,然后根据这些规则对文本进行标注。
这种算法的优点是易于掌握,但是难以处理不确定的情况,并且需要手动编写大量规则,工作量大。
因此,随着机器学习技术的发展,基于规则的算法逐渐被基于统计学习的算法所取代。
基于统计学习的算法是通过分析大量人工标注的语料库,自动学习每个词性的统计特征,并根据这些特征进行标注。
这种算法的优点是可以处理不确定性的情况,并且算法的规则可以自动学习。
但是,这种算法需要大量的人工标注语料库,并且对于稀有词汇的标注效果不太好。
三、词性标注技术的评价指标词性标注技术的评价指标主要包括标注准确率、标注精度、标注召回率和标注F1值。
标注准确率是指标注正确的单词数与总单词数的比值,反映了标注算法的整体性能。
标注精度是指标注正确的单词数与标注的总单词数的比值,反映了标注算法的精度。
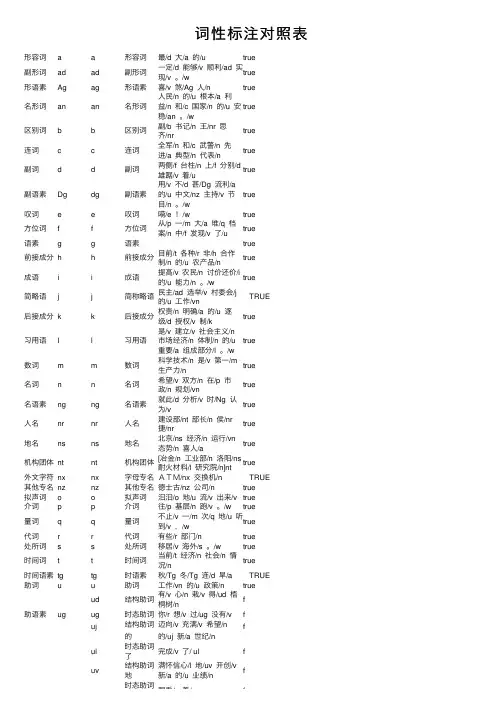
词性标注对照表形容词a a形容词最/d ⼤/a 的/u true副形词ad ad副形词⼀定/d 能够/v 顺利/ad 实现/v 。
/wtrue形语素Ag ag形语素喜/v 煞/Ag ⼈/n true名形词an an名形词⼈民/n 的/u 根本/a 利益/n 和/c 国家/n 的/u 安稳/an 。
/wtrue区别词b b区别词副/b 书记/n 王/nr 思齐/nrtrue连词c c连词全军/n 和/c 武警/n 先进/a 典型/n 代表/ntrue副词d d副词两侧/f 台柱/n 上/f 分别/d雄踞/v 着/utrue副语素Dg dg副语素⽤/v 不/d 甚/Dg 流利/a的/u 中⽂/nz 主持/v 节⽬/n 。
/wtrue叹词e e叹词嗬/e !/w true⽅位词f f⽅位词从/p ⼀/m ⼤/a 堆/q 档案/n 中/f 发现/v 了/utrue语素g g语素 true前接成分h h前接成分⽬前/t 各种/r ⾮/h 合作制/n 的/u 农产品/ntrue成语i i成语提⾼/v 农民/n 讨价还价/i的/u 能⼒/n 。
/wtrue简略语j j简称略语民主/ad 选举/v 村委会/j的/u ⼯作/vnTRUE后接成分k k后接成分权责/n 明确/a 的/u 逐级/d 授权/v 制/ktrue习⽤语l l习⽤语是/v 建⽴/v 社会主义/n市场经济/n 体制/n 的/u重要/a 组成部分/l 。
/wtrue数词m m数词科学技术/n 是/v 第⼀/m⽣产⼒/ntrue名词n n名词希望/v 双⽅/n 在/p 市政/n 规划/vntrue名语素ng ng名语素就此/d 分析/v 时/Ng 认为/vtrue⼈名nr nr⼈名建设部/nt 部长/n 侯/nr捷/nrtrue地名ns ns地名北京/ns 经济/n 运⾏/vn态势/n 喜⼈/atrue机构团体nt nt机构团体[冶⾦/n ⼯业部/n 洛阳/ns耐⽕材料/l 研究院/n]nttrue外⽂字符nx nx字母专名ATM/nx 交换机/n TRUE 其他专名nz nz其他专名德⼠古/nz 公司/n true拟声词o o拟声词汩汩/o 地/u 流/v 出来/v true介词p p介词往/p 基层/n 跑/v 。


机器学习知识:机器学习中的词性标注在自然语言处理中,词性标注是一项重要的任务。
它是指给定一句话中的每一个词语分配一个对应的词性,如名词、动词、形容词、副词等。
这个任务对于各种应用都很关键,比如情感分析、机器翻译、自动问答等等。
词性标注的基本思想是利用一些已经标注好的句子作为训练集,通过机器学习算法来学习词性标注的规则,然后应用到未标注的句子上。
下面将从算法、应用、发展等方面介绍词性标注的知识点。
一、算法(一)规则算法最早的词性标注算法是规则算法。
这种算法是基于已知的语言规则,对每个词语进行分类。
规则算法虽然直观易懂,但它的可扩展性和泛化性都很差,不适用于大规模的语料库。
(二)统计算法随着机器学习技术的发展,统计算法逐渐成为词性标注的主流算法。
统计算法的思路是观察已经标注好的词性,从这些数据中学习词性标注的规律。
常用的统计算法包括HMM(隐马尔可夫模型)、CRF (条件随机场)等等。
HMM是一种基于概率的词性标注算法,它的核心思想是词性标记是句子中每个词的一个隐藏状态,通过已知的观察值来对这些隐藏状态进行推断。
HMM首先需要确定一个初始参数,例如,学习每个词的词性和每个词性出现的概率。
然后利用已知词性标注的语料库,通过极大似然方法学习模型参数。
CRF是一种基于概率的判别式模型,与HMM不同之处在于CRF直接对给定句子的标注结果建模,而HMM只考虑了参数之间的联合分布。
CRF模型也需要从已知的语料库中学习参数,并通过最大化对数似然函数得到最优参数值。
二、应用(一)文本分类词性标注可以作为文本分类的预处理步骤。
文本分类是将文本数据划分到预定义的类别中的任务。
这个任务在垃圾邮件过滤、文本检索和情感分析等领域得到广泛应用。
在分类之前,需要对文本进行预处理,其中词性标注是一个重要的预处理步骤。
(二)情感分析情感分析是指识别文本中的情感色彩,例如,正面情感、中性情感和负面情感等。
这个任务对于企业的公关、社交媒体和市场调查等领域都很关键。

自然语言处理的词性标注方法自然语言处理(Natural Language Processing,简称NLP)是计算机科学与人工智能领域中的一个重要研究方向,其目标是使计算机能够理解和处理人类语言。
而词性标注则是NLP中的一个基础任务,它的主要目的是为文本中的每个词汇赋予一个正确的词性标签,以便进一步的语义分析和语法处理。
词性标注是一种基于统计和规则的方法,通过对大规模带有标注的语料库进行学习,从而建立一个能够自动标注词性的模型。
下面将介绍几种常见的词性标注方法。
1. 基于规则的方法基于规则的词性标注方法是最早出现的一种方法,它通过人工定义一系列规则来判断每个词汇的词性。
这些规则可以基于词汇的形态、上下文信息等进行判断。
然而,由于人工定义规则的复杂性和主观性,这种方法往往需要大量的人工参与,并且对于不同语言和领域的文本适应性较差。
2. 基于统计的方法基于统计的词性标注方法通过对大规模语料库进行统计分析,学习每个词汇在不同上下文环境下的词性分布概率,从而为每个词汇赋予一个最可能的词性标签。
这种方法不需要人工定义规则,而是通过机器学习算法自动学习词性分布模型。
常见的统计学习算法包括隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)等。
3. 基于深度学习的方法随着深度学习的兴起,基于深度学习的词性标注方法也得到了广泛的应用。
深度学习模型如循环神经网络(Recurrent Neural Network,RNN)和长短时记忆网络(Long Short-Term Memory,LSTM)等可以自动学习词汇和上下文之间的复杂关系,从而提高词性标注的准确性。
此外,还可以通过引入预训练的词向量模型(如Word2Vec和GloVe)来进一步提升模型性能。
4. 基于半监督学习的方法传统的词性标注方法通常需要大量带有标注的语料库进行训练,但是标注大规模语料库是一项耗时耗力的工作。

汉语教材中词性标注的实践与探究汉语作为世界上使用人数最多的一种语言,拥有着丰富的词汇和语法结构。
然而,在汉语学习者看来,汉语的语法结构是比较复杂和繁琐的,需要对各种语法概念和语法术语有较全面的了解,并且要能够将其应用到实际语言交际中。
因此,在汉语教学中,语法教学是非常重要的一部分,而词性标注则是语法教学的基础和前提。
一、词性标注在汉语教学中的意义词性标注是指对词汇的语法属性进行标注,例如给定一个汉字或单词,标注它是名词、动词或形容词等。
词性标注是语法分析和语言学习的基础,对于语言的正确使用和理解至关重要。
在汉语教学中,词性标注具有如下几个重要意义:1、帮助学生建立语法意识。
词性标注能够促进学生对词汇的形态、语法结构和语义的深入了解,有助于学生理解和掌握汉语的语法规则。
2、促进词汇积累和记忆。
词性标注能够让学生更好地了解和记忆汉语中的词汇,有助于增强他们的词汇积累和运用能力。
3、加强口语表达和写作能力。
词性标注能够让学生掌握汉语基本的句法结构,有助于他们在口语表达和写作中运用更准确、更丰富的语言表达方式。
二、汉语教材中词性标注的实践1、新华字典作为汉语学习者的必备工具书,新华字典对于词性标注是非常重视的。
在新华字典中,每个词汇都会有一个词性标注,例如:“自然”词语后面标注了“形容词”、“名词”和“副词”等不同的词性,让人一目了然。
学生可以通过新华字典来查找新词汇和生词的含义和词性,有助于他们掌握汉语的基本语言知识和用法。
2、中华新华字典中华新华字典是一本新华字典的增强版,它在词性标注方面更加细致和全面。
例如,中华新华字典不仅标注了“自然”词的常见词性,还细分了它的不同用法和含义,如:自然1. 【形容词】(1) 大自然的。
如:自然景观。
(2)不经人为改变的。
如:自然条件2. 【名词】(1) 指大自然界;自然界。
如:人与自然的关系。
(2) 宇宙间、天体的作用。
如:自然现象。
3. 【副词】(1) 漫不经心,任其自然。

如何利用自然语言处理进行词性标注自然语言处理(Natural Language Processing,NLP)是一门涉及人类语言与计算机之间交互的学科,而词性标注(Part-of-Speech Tagging)则是其中的一个重要任务。
词性标注是将自然语言文本中的每个词语标注为相应的词性,如名词、动词、形容词等,以便计算机能够更好地理解和处理文本。
本文将探讨如何利用自然语言处理进行词性标注,以及其在实际应用中的意义和挑战。
一、词性标注的基本概念和方法词性标注是自然语言处理中的一个经典任务,其目标是为文本中的每个词语赋予一个正确的词性标签。
词性标签通常由一系列预定义的标签集合构成,如名词(Noun)、动词(Verb)、形容词(Adjective)等。
词性标注的方法主要分为基于规则的方法和基于统计的方法。
基于规则的方法通过人工定义一系列规则来进行词性标注。
这些规则可以基于语言学知识和语法规则,如名词通常出现在动词前面等。
这种方法的优点是可解释性强,但缺点是需要大量的人工劳动和专业知识,并且对于复杂的语言现象往往难以适用。
基于统计的方法则是利用大规模的语料库进行训练,通过统计学模型来预测每个词语的词性标签。
常用的统计模型包括隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)。
这种方法的优点是能够自动学习语言规律,但缺点是对于缺乏训练数据的语言或特定领域的文本效果可能不佳。
二、自然语言处理中的词性标注应用词性标注在自然语言处理中有着广泛的应用。
首先,词性标注是很多自然语言处理任务的基础,如句法分析、语义角色标注等。
通过将每个词语标注为相应的词性,可以为后续任务提供更准确的输入。
其次,词性标注在信息检索和文本分类等领域也起着重要的作用。
通过对文本进行词性标注,可以提取出文本中的关键词和短语,从而改善信息检索的效果。
同时,词性标注也可以用于文本分类中的特征提取,帮助机器学习算法更好地理解文本。

词性标注实验报告词性标注实验报告引言:词性标注是自然语言处理中的一项重要任务,它的目标是将给定的文本中的每个词语赋予相应的词性。
词性标注在许多自然语言处理任务中起着关键作用,如文本分类、机器翻译、信息检索等。
本文将介绍我们进行的词性标注实验,包括实验设计、数据集选择、模型选择和实验结果分析等。
实验设计:为了进行词性标注实验,我们选择了一份中文新闻语料作为实验数据集。
该数据集包含了大量的新闻文本,涵盖了各种不同的主题和领域。
我们将数据集按照80%的比例划分为训练集和20%的比例划分为测试集。
在实验中,我们采用了基于深度学习的词性标注模型进行实验。
数据集选择:选择合适的数据集对于实验的准确性和可靠性至关重要。
我们选择了这份中文新闻语料作为我们的实验数据集,原因有以下几点:首先,新闻语料通常具有较高的质量和丰富的领域覆盖范围,能够有效地评估模型的泛化能力。
其次,中文新闻语料在词性分布上具有一定的规律性,有助于模型学习和预测。
最后,该数据集的规模适中,既能满足实验需求,又能保证实验的可行性。
模型选择:在词性标注任务中,我们选择了基于深度学习的模型进行实验。
深度学习在自然语言处理领域取得了显著的成果,其强大的模型表达能力和自动特征学习能力使得其在词性标注任务中具有优势。
我们选择了基于循环神经网络(RNN)的模型,因为RNN能够有效地处理序列数据,并且能够捕捉到词语之间的上下文信息,有助于提升词性标注的准确性。
实验结果分析:我们使用了准确率作为评估指标来评估我们的词性标注模型的性能。
在实验中,我们得到了约90%的准确率,这表明我们的模型在词性标注任务上取得了较好的效果。
通过对实验结果的分析,我们发现模型在一些常见的词性上表现较好,如名词、动词等,但在一些特殊的词性上表现较差,如助词、连词等。
这可能是因为这些特殊的词性在数据集中的分布较少,导致模型学习不充分。
因此,在未来的研究中,我们可以考虑增加这些特殊词性的样本数量,以提升模型在这些词性上的性能。
自然语言处理中的词性标注与句法分析自然语言处理(Natural Language Processing,简称NLP)是人工智能领域中的一个重要分支,主要研究如何让计算机能够理解、处理和生成人类语言。
在NLP领域中,词性标注与句法分析是两个重要的任务,它们可以帮助计算机更好地理解和处理自然语言。
本文将介绍词性标注与句法分析的基本概念、常见方法以及应用场景,并探讨它们在NLP领域的意义和作用。
一、词性标注词性标注(Part-of-Speech Tagging,简称POS Tagging)是NLP领域中的一个基础任务,其主要目标是为一个句子中的每个单词确定其词性。
词性标注可以帮助计算机理解句子的结构和含义,从而更好地进行后续处理和分析。
词性标注通常使用词性标记集合(如标注集)来标注每个单词的词性,常见的标注集包括Penn Treebank标注集、Universal标注集等。
词性标注的方法主要包括基于规则的方法和基于统计的方法。
基于规则的方法通过定义一系列的语法规则和模式来确定单词的词性,但这种方法需要大量的人工设置和维护规则,且适用性有限。
而基于统计的方法则是通过学习语料库中单词与其词性之间的统计关系来确定单词的词性,常见的统计方法包括隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)等。
词性标注在NLP领域中有着广泛的应用,例如在文本分类、信息检索和机器翻译等任务中都需要对文本进行词性标注来帮助计算机理解和处理文本。
此外,词性标注也可以作为更复杂的NLP任务的预处理步骤,如句法分析、语义分析等。
二、句法分析句法分析(Syntactic Parsing)是NLP领域中的另一个重要任务,其主要目标是确定一个句子的句法结构,即句子中单词之间的语法关系。
句法分析可以帮助计算机理解句子的结构和含义,从而更好地进行后续处理和分析。
如何使用机器学习技术进行词性标注词性标注(Part-of-Speech Tagging,简称POS Tagging)是自然语言处理中的一个重要任务,它的目标是为给定的句子中的每个单词确定词性标签。
在过去的几十年里,机器学习技术已经成为该任务的核心方法之一。
本文将介绍如何使用机器学习技术进行词性标注。
首先,让我们了解一下什么是词性。
词性是语法中用来描述词语在句子中所起的作用的类别。
常见的词性包括名词、动词、形容词、副词、介词等。
词性标注的任务就是为给定的句子中的每个单词赋予对应的词性标签。
机器学习技术可以应用于词性标注任务的两个主要方面:特征提取和模型训练。
在特征提取阶段,我们需要将每个单词转化为机器学习算法可以理解的特征向量。
常用的特征包括单词本身、前一个单词、后一个单词、前一个词性标签、后一个词性标签等。
这些特征可以使用one-hot编码表示,也可以使用词嵌入表示(如Word2Vec和GloVe)。
通过提取这些特征,我们可以将句子中的每个单词表示为一个特征向量。
在模型训练阶段,我们使用机器学习算法来学习一个将输入的特征向量映射到对应词性标签的模型。
常用的机器学习算法包括朴素贝叶斯、决策树、最大熵模型和隐马尔可夫模型(Hidden Markov Model,简称HMM)等。
这些算法可以根据输入的特征向量预测单词的词性标签。
在训练过程中,我们使用有标注的语料库来训练模型,并通过交叉验证等技术来评估模型的性能。
除了传统的机器学习方法,近年来深度学习方法也在词性标注任务中取得了显著的进展。
深度学习模型可以通过多层神经网络来建模复杂的特征之间的关系。
其中,循环神经网络(Recurrent Neural Network,简称RNN)和长短期记忆网络(Long Short-Term Memory,简称LSTM)是常用的深度学习模型。
这些模型可以处理变长的输入序列,并且在输入序列中的上下文信息上具有较强的建模能力。
自然语言处理中的词性标注与句法分析
词性标注是自然语言处理中的一项任务,其目标是对文本中的每
个词语进行词性标记,即确定该词语属于哪一类词性,如名词、动词、形容词等。
通过词性标注可以帮助计算机理解文本的语法结构和句子
的含义,从而能够更好地进行自然语言处理任务。
句法分析是自然语言处理中的另一项重要任务,其目标是分析句
子中的词语之间的语法关系,确定句子的结构和语法成分之间的依存
关系。
句法分析可以帮助计算机理解句子的语法结构,从而能够更准
确地理解句子的意思,进行语义分析和其他自然语言处理任务。
这两项任务在自然语言处理中扮演着重要角色,例如在文本分类、信息抽取、语义分析等任务中都需要用到词性标注和句法分析的结果。
同时,词性标注和句法分析也是自然语言处理中的基础任务,为其他
高级自然语言处理任务如机器翻译、问答系统等提供了基础支持。
因此,词性标注和句法分析是自然语言处理领域中不可或缺的两项任务。
在词性标记集已确定,并且词典中每个词都有确定词性的基础上,对一个输入词串转换成相应词性标记串的过程叫做词性标注。
词性标注需要解决的问题如何判定兼类词在具体语境中的词性。
对未登录词需要猜测其词兼类词对句法分析的影响:尽管兼类词在词汇中所占比例并不很高,但由于它们出现的比例较高,因而对于句法分析会造成直接影响。
词性标注方法:概率方法基于隐马尔可夫模型的词性标注方法机器学习规则的方法基于转换的错误驱动词性标注方法从统计模型角度考虑词性标注问题1给定一个词串W=w1w2...wn,如果T=t1t2...tn是W对应的词性标记串。
所谓对W进行词性标注就是在给定W和带有词性标注信息的词表条件下,求T的过程。
2假设W存在多个可能的词性标记串T1,T2,...Ti,对W进行词性标注就是在已知W的条件下求使P(T|W)最大的词性标注串T',即求:3T'=argmax P(T|W)例如词串“把/ 这/ 篇/ 报道/ 编辑/ 一/ 下/”中有些词有多个词性标记(兼类词),因此该词串对应的词性标注串有多个。
全部标记结果等于各个词的词性标注数目的乘积,即4×1×1×2×2×2×3=96。
词性标注的任务就是从多个可能性中找出可能性最高的词性标注串T’上例中对应的词性标注串是“prvnvmq”对于一个词性标注系统来说,它所“认为”的可能性最高的词性标注串T'可能是正确的,也有可能是错误的。
为了表示方便,做如下约定:Wi:表示一个词串;wi:表示一个具体词语;Ti:表示一个词性标注串;ti:表示一个具体词性标记;隐马尔可夫模型(Hidden Markov Model,HMM)是描述连续符号序列的条件概率统计模型,可定义为五元组λ=(S,V,A,B,π),其中S代表一个状态集合S={1,2,...,N}V代表一个可观察符号的集合V={v1,v2,...,vM}A代表状态转移矩阵(N行×N列)A=[aij],其中aij=P(qt+1=j | qt=i), 1≤i,j≤N,即从状态i转移到下一个状态j的概率B是可观察符号的概率分布B={bj(k)},其中bj(k)是在状态j是输出观察符号vk的概率,即bj(k)=P(vk | j),1≤j≤N, 1≤k≤M.π代表初始状态的概率分布π={πi},表示在时刻1选择状态i的概率,即πi=P(q1=i)一个确定的HMM,其状态数是确定的,每个状态可能输出的观察值数目也是确定的,参数A,B,π可通过统计样本得到。
什么是词性标注(POStagging)词性标注也叫词类标注,POS tagging是part-of-speech tagging的缩写。
对POS Tagging的定义:In corpus linguistics, part-of-speech tagging (POS tagging or POST), also called grammatical tagging or word-category disambiguation, is the process of marking up the words in a text (corpus) as corresponding to a particular part of speech, based on both its definition, as well as its context —ie. relationship with adjacent and related words in a phrase, sentence, or paragraph. A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc.百度百科的词条提到了中⽂分词和词类标注的关系:另⼀种⽅法是将分词和词类标注结合起来,利⽤丰富的词类信息对分词决策提供帮助,并且在标注过程中⼜反过来对分词结果进⾏检验、调整,从⽽极⼤地提⾼切分的准确率。
并给出了⼏个中⽂分词软件:SCWS:Hightman开发的⼀套基于词频词典的机械中⽂分词引擎,它能将⼀整段的汉字基本正确的切分成词。
采⽤的是采集的词频词典,并辅以⼀定的专有名称,⼈名,地名,数字年代等规则识别来达到基本分词,经⼩范围测试⼤概准确率在 90% ~ 95% 之间,已能基本满⾜⼀些⼩型搜索引擎、关键字提取等场合运⽤。
第七章词汇分析(二)——从词串到词性标记串詹卫东/doubtfire/提纲1 词性标注与兼类词2 隐马尔可夫模型(HMM)3Viterbi算法4 基于转换的错误驱动的词性标注方法5 小结1 词性标注(pos tagging)语法体系——词性标记集的确定一词多类现象•Time flies like an arrow.Time/n-v flies/v-n like/p-v an/Det arrow/n•把这篇报道编辑一下把/q-p-v-n 这/r 篇/q 报道/v-n 编辑/v-n 一/m-c 下/f-q-v规则方法进行词性标注示例@@ 信(n-v)CONDITION FIND(L,NEXT,X){%X.yx=的|封|写|看|读} SELECT n OTHERWISE SELECT v-n@@ 一边(c-s)CONDITION FIND(LR,FAR,X) {%X.yx= 一边} SELECT cOTHERWISE SELECT s词性标注问题:寻找最优路径4×1×1×2×2×2×3=96种可能性,哪种可能性最大?2 隐马尔可夫模型(Hidden Markov Model)Andrei Andreyevich Markov (1856-1922)/~history/Mathematicians/Markov.html有关马尔可夫过程(Markov Process)、隐马尔可夫模型(Hidden Markov Model)更详细的介绍,参见:陈小荷(2000),第1章;翁富良(1998),第8章第2节;HMM 的形式描述1 状态集合S={a 1,a 2,…,a N },一般以q t 表示模型在t时刻的状态;2 输出符号集合O={O 1,O 2,…O M };3 状态转移矩阵 A = a ij (a ij 是从i状态转移到j状态的概率),其中:4 可观察符号的概率分布 B = b j (k),表示在状态j时输出符号v k 的概率,其中:5 初始状态概率分布,一般记做π= {πi }, 其中:N j i i q j q P a t t ij ≤≤===+,1),|(10≥ij a ∑==N j ij a11MK N j S q v O P k b j t k t j ≤≤≤≤===1,1),|()(0)(≥k b j 1)(1=∑=k b M k j N i S q P i i ≤≤==1),(1π0≥i π∑==N i i 11π基于HMM进行词性标注两个随机过程:1 选择罐子——上帝按照一定的转移概率随机地选择罐子2 选择彩球——上帝按照一定的概率随机地从一个罐子中选择一个彩球输出人只能看到彩球序列(词汇序列,记做W=w1w2…w n),需要去猜测罐子序列(隐藏在幕后的词性标记序列,记做T=tt2…t n)1已知词串W(观察序列)和模型λ情况下,求使得条件概率P(T|W, λ)值最大的那个T’,一般记做:TWP=公式1'λT),|(argmaxT效率问题假定有N个词性标记(罐子),给定词串中有M个词(彩球)考虑最坏的情况:每个词都有N个可能的词性标记,则可能的状态序列有N M个随着M(词串长度)的增加,需要计算的可能路径数目以指数方式增长,即算法复杂性为指数级需要寻找更有效的算法……3 Veterbi算法——提高效率之道Veterbi算法是一种动态规划方法(dynamic programming)假定一个词串W 中每个词都个词性标记,那么从词串中第m 个词(w m )到第m+1个词(w m+1)的第j 个词性标记就有N 条可能的路径。
这N 条路经中存在一条概率最大的路径,假定为t i t j定义与记号1.从第m 个词(w m )的各个词性标记向第m+1个词(w m+1)的各个词性标记转移的概率,可以记作 1 i N; 1 j N 第1个词(w 1)前面没有词,w 1的各个词性标记也满足一定的概率分布,可以记作2.第m 个词(w m )的各个词性标记取词语w m 的条件概率可以记作1 i N3.从起点词到第m 个词的第i 个词性标记的各种可能路径(即各种可能的词性标记串)中,必有一条路经使得W m 概率最大,可以用一个变量来对这一过程加以刻画,这个变量即Viterbi 变量,记作)|(i j ij t t P a =≤≤≤≤iπ)|()(i m m i t w P w b =≤≤ 1 m M; 1 i N ≤≤≤≤)|,...,,,,...,,(max )(2121,...,,121λδm m t t t m w w w i t t t P i m ==−定义与记号(续)4HMM 的状态从第m 个词转移到第m+1个词,整个路径的概率可以通过HMM 在前一个状态(第m 个词)时的最大概率来求得,即Viterbi 变量可以递归求值5当扫描过第m 个词,状态转移到第m+1个词时,需要有一个变量记录已经走过的路径中,哪一条是最佳路径,即记住该路径上w m 的最佳词性标记,这个变量可以记作)(])(max [)(111+≤≤+×=m j ij m Ni m w b a i j δδ 1 m M-1, 1 j N ≤≤≤≤)(])([max arg )(11m i ji m Nj m w b a j i ×=∆−≤≤δ 2 m M, 1 i N ≤≤≤≤Veterbi 算法(1)初始化:(2)递归计算通向每个词( )的每个词性标记( )的最佳路径m w )()(11w b i i i πδ=0)(1=∆i 1 i N ≤≤(3)到达最后一个词( )时,计算这个词的最佳词性标记M w (4)从的最佳词性标记开始,顺次取得每个词的最佳词性标记M w 2 m M , 1 i N 2 m M , 1 i N ≤≤≤≤≤≤≤≤)]([max 1i P M N i δ≤≤∗=)]([max arg 1i t M Ni Mδ≤≤∗=)(∗∗∆=tt m = M-1, M-2, …, 2,1j t )(])(max [)(11m j ij m Ni m w b a i j ×=−≤≤δδ)(])([max arg )(11m j ij m Ni m w b a i j ××=∆−≤≤δVeterbi算法的复杂度假定有N个词性标记(罐子),给定词串中有M个词(彩球)考虑最坏的情况,扫描到每一个词时,从前一个词的各个词性标记(N个)到当前词的各个词性标记(N个),有N×N=N2条路经,即N2次运算,扫描完整个词串(长度为M),计算次数为M个N2相加,即N2×M。
对于确定的词性标注系统而言,N是确定的,因此,随着M长度的增加,计算时间以线性方式增长。
也就是说,Veterbi算法的计算复杂性是线性的。
用Veterbi算法进行词性标注示例Veterbi算法词性标注过程示例把/p-q-n-v 这/r 篇/q 报道/v-n 编辑/v-n 一/m-c 下/v-q-f把-> 这Delta(这/r)1 = a12(把/p -> 这/r) * b2(这/r) = (27249 / 269186) * (21990 / 214942) = 0.01036 Delta(这/r)2 = a12(把/q -> 这/r) * b2(这/r) = (760 / 155374) * (21990 / 214942) = 5e-4 Delta(这/r)3 = a12(把/n -> 这/r) * b2(这/r) = (9769 / 1539367) * (21990 / 214942) = 6.49e-4 Delta(这/r)4 = a12(把/v -> 这/r) * b2(这/r) = (46697 / 1193317) * (21990 / 214942) = 0.004Veterbi算法词性标注过程示例(续)篇-> 报道Delta(篇) 只有一个,略去。
Delta(报道/n)1 = a12(篇/q -> 报道/n) * b2(报道/n) = (52310 / 155374) * (420 / 1539367) = 9.1857e-5 Delta(报道/v)1 = a12(篇/q -> 报道/v) * b2(报道/v) = (13288 / 155374) * (4040 / 1193317) = 2.8954e-4Veterbi算法词性标注过程示例(续)报道-> 编辑Delta(编辑/n)1 = Delta(报道/n)1 * a23(报道/n -> 编辑/n) * b3(编辑/n)= 9.1857e-5 * (277181 / 1539367) * (243 / 1539367) = 2.6e-9Delta(编辑/n)2 = Delta(报道/v)1 * a23(报道/v -> 编辑/n) * b3(编辑/n)= 2.8954e-4 * (221796 / 1193317) * (243 / 1539367) = 8.49e-9Delta(编辑/v)1 = Delta(报道/n)1 * a23(报道/n -> 编辑/v) * b3(编辑/v)= 9.1857e-5 * (221776 / 1539367) * (100 / 1193317) = 1.1e-9Delta(编辑/v)2 = Delta(报道/v)1 * a23(报道/v -> 编辑/v) * b3(编辑/v)= 2.8954e-4 * (191967 / 1193317) * (100 / 1193317) = 3.9e-9Veterbi算法词性标注过程示例(续)编辑-> 一Delta(一/m)1 = Delta(编辑/n)2 * a34(编辑/n -> 一/m) * b4(一/m)= 8.49e-9 * (27918 / 1539367) * (20672 / 270381) = 1.18e-11Delta(一/m)2 = Delta(编辑/v)2 * a34(编辑/v -> 一/m) * b4(一/m)= 3.9e-9 * (70914 / 1193317) * (20672 / 270381) = 1.77e-11Delta(一/c)1 = Delta(编辑/n)2 * a34(编辑/n -> 一/c) * b4(一/c)= 8.49e-9 * (55177 / 1539367) * (2229 / 168350) = 4e-12Delta(一/c)2 = Delta(编辑/v)2 * a34(编辑/v -> 一/c) * b4(一/c)= 3.9e-9 * (13715 / 1193317) * (2229 / 168350) = 5.9e-13Veterbi算法词性标注过程示例(续)一-> 下Delta(下/v)1 = Delta(一/m)2 * a45(一/m -> 下/v) * b5(下/v)= 1.77e-11 * (13778 / 270381) * (2271 / 1193317) = 1.7e-15Delta(下/v)2 = Delta(一/c)1 * a45(一/c -> 下/v) * b5(下/v)= 4e-12 * (40148 / 168350) * (2271 / 1193317) = 1.8e-15Delta(下/q)1 = Delta(一/m)2 * a45(一/m -> 下/q) * b5(下/q)= 1.77e-11 * (139653 / 270381) * (161 / 155374) = 9.47e-15Delta(下/q)2 = Delta(一/c)1 * a45(一/c -> 下/q) * b5(下/q)= 4e-12 * (53 / 168350) * (161 / 155374) = 1.3e-18Delta(下/f)1 = Delta(一/m)2 * a45(一/m -> 下/f) * b5(下/f)= 1.77e-11 * (1470 / 270381) * (6313 / 110878) = 5.47e-15Delta(下/f)2 = Delta(一/c)1 * a45(一/c -> 下/f) * b5(下/f)= 4e-12 * (700 / 168350) * (6313 / 110878) = 9.47e-16估算HMM 的参数(Baum-Welch 算法)i π)|(i j ij t t P a =)|()(i m m i t w P w b =从生语料库估算用于词性标注的HMM 的参数:(1)初始状态的概率分布;(2)词性转移概率;(3)已知词性条件下词语的输出概率;参看:翁富良,1998,第8章第2节L.Rabiner, 19894 基于转换的错误驱动的词性标注方法Eric Brill (1992,1995)Transformation-based error-driven part of speech tagging基本思想:(1)正确结果是通过不断修正错误得到的(2)修正错误的过程是有迹可循的(3)让计算机学习修正错误的过程,这个过程可以用转换规则(transformation)形式记录下来,然后用学习得到转换规则进行词性标注下载Brill’s tagger: /~brill/根据模板可能学到的转换规则T 1:当前词的前一个词的词性标记是量词(q )时,将当前词的词性标记由动词(v )改为名词(n );T 2:当前词的后一个词的词性标记是动词(v )时,将当前词的词性标记由动词(v )改为名词(n );T 3:当前词的后一个词的词性标记是形容词(a )时,将当前词的词性标记由动词(v )改为名词(n );T 4:当前词的前面两个词中有一个词的词性标记是名词(n )时,将当前词的词性标记由形容词(v )改为数词(m );……C掉正确标注后转换规则学习器算法描述1)首先用初始标注器对C 0_raw 进行标注,得到带有词性标记的语料C i (i =1);2)将C i 跟正确的语料标注结果C 0比较,可以得到C i 中总的词性标注错误数;3)依次从候选规则中取出一条规则T m (m=1,2,…),每用一条规则对C i 中的词性标注结果进行一次修改,就会得到一个新版本的语料库,不妨记做(m=1,2,3,…),将每个跟C 0比较,可计算出每个中的词性标注错误数。