推荐系统手册
- 格式:doc
- 大小:58.50 KB
- 文档页数:9

推荐系统概述(个性化推荐)推荐系统概述(个性化推荐)核⼼:通过发现数据集中的模式,为⽤户提供与之最为相关的信息。
1.从⼀个例⼦出发两名⽤户都在某电商⽹站购买了A、B两种产品。
当他们产⽣购买这个动作的时候,两名⽤户之间的相似度便被计算了出来。
其中⼀名⽤户除了购买了产品A和B,还购买了C产品,此时推荐系统会根据两名⽤户之间的相似度会为另⼀名⽤户推荐项⽬C。
2.应⽤现状推荐系统可以说是⽆处不在了,⽐如:电商的猜你喜欢,浏览器右侧的推送消息,包括搜索结果的排序,⼴义来说都算推荐系统的⼀部分。
⽬前推荐系统给亚马逊带来了35%的销售收⼊,给Netflix带来了⾼达75%的消费,并且Youtube主页上60%的浏览来⾃推荐服务。
⾳乐软件如Spotify及Deezer也使⽤推荐系统进⾏⾳乐推荐。
3.推荐算法协同过滤的推荐⼜可以分为两类:1. 启发式推荐算法(Merhory-based algorithms)启发式推荐算法易于实现,并且推荐结果的可解释性强。
启发式推荐算法⼜可以分为两类:基于⽤户的协同过滤(User-based collaborative filtering):主要考虑的是⽤户和⽤户之间的相似度,只要找出相似⽤户喜欢的物品,并预测⽬标⽤户对对应物品的评分,就可以找到评分最⾼的若⼲个物品推荐给⽤户。
举个例⼦,李⽼师和闫⽼师拥有相似的电影喜好,当新电影上映后,李⽼师对其表⽰喜欢,那么就能将这部电影推荐给闫⽼师。
基于物品的协同过滤(ltem-based collaborative filtering):主要考虑的是物品和物品之间的相似度,只有找到了⽬标⽤户对某些物品的评分,那么就可以对相似度⾼的类似物品进⾏预测,将评分最⾼的若⼲个相似物品推荐给⽤户。
举个例⼦,如果⽤户A、B、C给书籍X、Y的评分都是5分,当⽤户D想要买Y书籍的时候,系统会为他推荐X书籍,因为基于⽤户A、B、C的评分,系统会认为喜欢Y书籍的⼈在很⼤程度上会喜欢X书籍。


推荐系统计划书1. 引言随着互联网的快速发展,人们对信息的获取越来越依赖于推荐系统。
推荐系统可以根据用户的需求、兴趣和行为,对用户进行个性化的信息推荐。
因此,推荐系统在电子商务、社交媒体、新闻资讯等领域中起着关键作用。
本计划书旨在设计和实现一个高性能的推荐系统,以满足用户对个性化推荐的需求。
下面将介绍推荐系统的目标、功能和实施计划。
2. 目标本推荐系统的目标是提供准确、可靠、高效的个性化推荐服务,以提升用户体验和增加网站的用户粘性。
具体的目标包括: - 准确性:推荐系统应该能够根据用户的兴趣和行为精确地推荐适合的信息。
- 可靠性:推荐系统应该具备良好的稳定性和鲁棒性,能够处理大量并发请求,并保证推荐结果的准确性和一致性。
- 高效性:推荐系统应该具备高性能和低延迟的特点,能够在短时间内生成推荐结果并响应给用户。
3. 功能本推荐系统将实现以下主要功能:3.1 用户画像构建推荐系统将根据用户行为和兴趣构建用户画像,包括用户的基本信息、兴趣爱好、行为偏好等。
通过分析这些信息,推荐系统能够更好地理解用户的需求,并生成针对性的推荐结果。
3.2 物品推荐推荐系统将根据用户的兴趣和行为,为用户推荐符合其喜好的物品。
推荐算法将综合考虑用户的历史行为、相似用户的行为以及物品的特征等因素,生成个性化的推荐结果。
3.3 推荐结果展示推荐系统将会以易读、清晰的方式展示推荐结果给用户。
推荐结果的展示界面将设计简洁、直观,并提供用户反馈和调整推荐策略的功能。
3.4 推荐策略优化本推荐系统将不断优化推荐策略,通过分析用户的反馈数据和推荐效果,调整推荐算法的参数和模型,提升推荐系统的准确性和用户满意度。
4. 实施计划4.1 系统架构设计推荐系统将采用分布式架构,包括数据层、计算层和应用层。
数据层负责数据的存储和管理,计算层负责推荐算法的计算和结果生成,应用层负责用户接口的实现和推荐结果的展示。
4.2 数据采集与处理推荐系统将从各类数据源中采集用户和物品的相关信息,包括用户行为日志、物品特征数据等。

人工智能开发技术中的推荐系统搭建指南随着互联网的发展,数据量的爆炸式增长,人们在获取信息和产品时面临着严重的信息过载问题。
针对这个问题,推荐系统应运而生。
推荐系统通过分析用户的历史行为和个人喜好,为用户推荐可能感兴趣的信息和产品。
在人工智能开发中,搭建一个高效的推荐系统是非常重要的,下面将介绍一些关键的技术和步骤。
1. 数据收集与处理推荐系统的搭建首先要解决的问题就是数据的收集与处理。
通过分析用户的历史行为,我们可以获取到大量的用户行为数据,包括浏览记录、购买记录、评分记录等。
为了更好地分析这些数据,我们需要进行数据清洗和预处理,包括去除重复数据、标准化数据、处理缺失数据等。
2. 特征工程在推荐系统中,特征工程是至关重要的一步。
通过对用户和物品的特征进行提取和组合,可以更好地描述用户的个性化需求和物品的特性。
特征工程的过程中,可以使用各种技术,如独热编码、TF-IDF、Word2Vec等。
同时,在进行特征工程时,还需要注意特征的选择和筛选,以避免维度灾难和过拟合问题。
3. 算法选择与模型设计推荐系统的核心是算法选择和模型设计。
目前较常用的推荐算法包括基于内容的推荐、协同过滤、深度学习等。
在选择算法时,需要根据实际情况和需求进行权衡,同时还要考虑算法的效率和可扩展性。
在进行模型设计时,要结合推荐系统的具体应用场景和目标,合理设计模型的输入和输出。
4. 模型训练与优化模型训练是搭建推荐系统的重要环节。
在进行模型训练时,需要选择合适的训练数据和损失函数,并利用合适的优化算法进行参数优化。
同时,为了提高模型的准确性和泛化能力,需要进行交叉验证和调参等工作。
此外,还可以考虑引入集成学习和迁移学习等技术,进一步提升模型的性能。
5. 实时推荐与反馈推荐系统的一个重要特点是实时性。
用户的兴趣和需求是不断变化的,因此推荐系统需要能够实时地跟踪用户的行为,并根据用户的反馈不断优化推荐结果。
实时推荐的关键在于快速的数据处理和模型更新,可以利用分布式计算和增量学习等技术来实现。
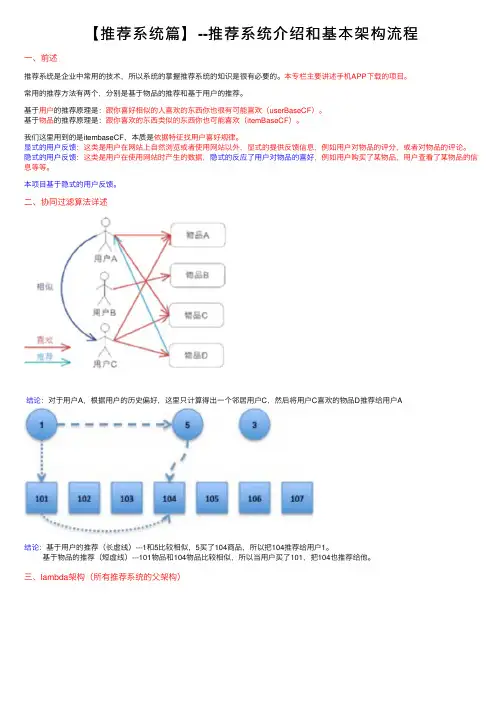
【推荐系统篇】--推荐系统介绍和基本架构流程⼀、前述推荐系统是企业中常⽤的技术,所以系统的掌握推荐系统的知识是很有必要的。
本专栏主要讲述⼿机APP下载的项⽬。
常⽤的推荐⽅法有两个,分别是基于物品的推荐和基于⽤户的推荐。
基于⽤户的推荐原理是:跟你喜好相似的⼈喜欢的东西你也很有可能喜欢(userBaseCF)。
基于物品的推荐原理是:跟你喜欢的东西类似的东西你也可能喜欢(itemBaseCF)。
我们这⾥⽤到的是itembaseCF,本质是依据特征找⽤户喜好规律。
显式的⽤户反馈:这类是⽤户在⽹站上⾃然浏览或者使⽤⽹站以外,显式的提供反馈信息,例如⽤户对物品的评分,或者对物品的评论。
隐式的⽤户反馈:这类是⽤户在使⽤⽹站时产⽣的数据,隐式的反应了⽤户对物品的喜好,例如⽤户购买了某物品,⽤户查看了某物品的信息等等。
本项⽬基于隐式的⽤户反馈。
⼆、协同过滤算法详述结论:对于⽤户A,根据⽤户的历史偏好,这⾥只计算得出⼀个邻居⽤户C,然后将⽤户C喜欢的物品D推荐给⽤户A结论:基于⽤户的推荐(长虚线)---1和5⽐较相似,5买了104商品,所以把104推荐给⽤户1。
基于物品的推荐(短虚线)---101物品和104物品⽐较相似,所以当⽤户买了101,把104也推荐给他。
三、lambda架构(所有推荐系统的⽗架构)四、本⽂系统架构lmbda架构(⼿机APP下载)解释:1.选⽤逻辑回归算法原因是⽤户要么下载,要么不下载。
2.⽣成特征索引(实际上是⼀个⽂本⽂件)的原因是格式化测试数据,也是相当于降维,当⼀个userId进来时找到推荐服务,然后通过服务路由去查找HBase中的数据,并根据特征索引来取对应的特征,所以这⼀步相当于⼀个降维。
线上架构(测试集架构):关联特征:保存的是同现矩阵。
流程:核⼼思想(计算⽤户对所有APP(除去历史下载部分)的评分,按分值排序,然后取topn)问题:五、需求分析(架构推荐⽅案)1、数据清洗(得到训练数据)2、算法建模(得到模型结果)3、模型使⽤(得到推荐结果)4、结果评估(推荐结果评估)。

Python技术与推荐系统开发指南现代社交网络的兴起以及互联网时代的到来,导致了海量的信息和选择的过载。
在这个信息爆炸的时代,推荐系统逐渐成为了互联网平台的核心功能之一。
Python作为一种简单易用且功能强大的编程语言,成为了许多推荐系统开发者的首选。
本文将为大家介绍Python技术在推荐系统开发中的应用以及一些实用的指南。
一、Python在推荐系统开发中的应用1.数据处理和分析:推荐系统的核心是数据处理和分析。
Python提供了许多强大的数据处理和分析库,如NumPy、Pandas和Scikit-learn等。
NumPy是一个开源的数值计算库,提供了高效的数组运算和数学函数。
Pandas是基于NumPy的开源数据处理和分析工具,它提供了灵活的数据结构和数据处理的功能。
Scikit-learn是一个机器学习库,提供了丰富的机器学习算法和模型。
借助这些工具,开发者可以方便地进行数据处理、特征提取和模型训练。
2.推荐算法实现:Python中有许多专门用于推荐系统的库,如Surprise和LightFM等。
Surprise是一个用于构建和评估推荐系统的Python库,提供了多种经典推荐算法的实现。
LightFM是一个基于Python的推荐系统库,支持显式和隐式反馈数据,同时提供了混合模型和多样性等高级功能。
这些库的存在使得推荐算法的实现变得简单且高效。
二、推荐系统开发的指南1.数据收集和特征选择:推荐系统的性能和质量直接受到数据的影响。
在数据收集阶段,开发者需要收集用户、物品和交互行为等数据。
此外,还需要进行数据清洗和预处理,以去除异常值和噪声。
在特征选择阶段,需要根据实际情况选择有意义的特征,并利用领域知识进行特征工程。
2.模型选择和实验设计:推荐系统的性能与模型的选择密切相关。
在模型选择阶段,应根据问题的具体需求选择适当的模型。
例如,如果推荐系统的目标是提高推荐的准确性,可以选择基于协同过滤的模型;如果目标是提高推荐的多样性,可以选择基于内容的推荐模型。

电子商务平台中用户推荐系统的使用方法电子商务平台是一个以互联网为基础,通过电子技术实现商务活动的平台。
随着技术的发展和消费者需求的变化,用户推荐系统在电子商务平台中发挥着越来越重要的作用。
本文将详细介绍电子商务平台中用户推荐系统的使用方法,帮助用户更好地利用推荐系统提供的个性化推荐服务。
首先,用户需要注册和登录电子商务平台。
注册账号后,用户可以通过用户名和密码登录,然后开始使用电子商务平台的服务。
登录之后,用户即可享受到推荐系统为其提供的个性化推荐服务。
其次,通过浏览和搜索商品来获取个性化推荐。
当用户进入电子商务平台后,可以通过浏览不同类别的商品,这些商品将根据用户的浏览记录和行为进行个性化推荐。
同时,用户也可以通过搜索功能直接搜索自己感兴趣的商品。
无论是浏览还是搜索,推荐系统都会根据用户的历史行为和偏好,运用算法来为用户推荐适合他们的商品。
第三,评价已购买的商品以提高推荐准确度。
在使用电子商务平台的过程中,用户通过购买商品可以为推荐系统提供反馈。
用户可以对已购买的商品进行评价和评论,这些评价和评论将被推荐系统用来不断优化个性化推荐算法,提高推荐准确度。
此外,用户还可以对推荐的商品进行评分,以便推荐系统更好地了解用户的兴趣和偏好。
第四,关注和使用推荐系统的相关功能。
电子商务平台的推荐系统通常还提供一些其他的功能,如关注、收藏、购物车等。
用户可以通过关注自己感兴趣的品牌或商家,推荐系统将根据用户的关注信息推荐相应的商品。
同时,用户还可以将自己喜欢的商品加入收藏夹,以便稍后查看和购买。
购物车功能则可以帮助用户将多个商品保存在一个地方,方便用户统一结算。
最后,根据实际需求使用推荐系统的设置功能。
电子商务平台的推荐系统通常还提供一些个性化设置,用户可以根据自己的实际需求进行设置。
例如,用户可以设置推荐默认排序方式,调整推荐的商品数量,屏蔽某些不感兴趣的品类等等。
通过合理地设置推荐系统,用户可以获得更符合自己需求的个性化推荐服务。

基于支持向量机的推荐系统设计与实现指南 引言 随着互联网的迅速发展和数据的爆炸性增长,推荐系统在各个领域中扮演着越来越重要的角色。推荐系统通过分析用户的历史行为和偏好,为用户提供个性化的推荐,从而提高用户体验和满意度。在推荐系统的设计与实现中,支持向量机(Support Vector Machine,SVM)作为一种强大的机器学习算法,具有较高的准确性和可解释性,因此被广泛应用于推荐系统中。
一、推荐系统概述 推荐系统是一种信息过滤技术,通过分析用户的历史行为和偏好,为用户推荐可能感兴趣的物品。推荐系统可以应用于电子商务、社交媒体、音乐和电影等领域。推荐系统的核心任务是预测用户对物品的评分或偏好,并根据预测结果进行推荐。
二、支持向量机简介 支持向量机是一种监督学习算法,可以用于分类和回归任务。其基本思想是通过构建一个最优的超平面,将不同类别的样本分开。支持向量机通过最大化间隔来提高分类的准确性,并且具有较好的泛化能力。
三、支持向量机在推荐系统中的应用 1. 特征提取:在推荐系统中,特征提取是一个关键的步骤。支持向量机可以通过构建合适的特征向量来描述用户和物品的特征,从而提高推荐的准确性。例如,可以使用用户的购买记录、点击行为和社交关系等信息作为特征,以预测用户对物品的喜好程度。
2. 用户分类:支持向量机可以将用户分为不同的类别,从而实现个性化的推荐。例如,可以将用户分为喜欢音乐、电影或图书的不同群体,并为每个群体提供相应的推荐。 3. 物品推荐:支持向量机可以通过分析用户的历史行为和偏好,为用户推荐可能感兴趣的物品。例如,可以根据用户的购买记录和评分,预测用户对其他物品的评分,并为用户推荐评分较高的物品。
四、支持向量机推荐系统的设计与实现 1. 数据收集与预处理:首先,需要收集用户的历史行为数据和物品的相关信息。然后,对数据进行预处理,包括数据清洗、特征提取和数据转换等操作。
2. 模型选择与训练:根据实际需求和数据特点,选择适合的支持向量机模型,并使用训练数据对模型进行训练。在训练过程中,需要选择合适的核函数和正则化参数,并进行交叉验证来评估模型的性能。

青岛市科学技术奖励推荐系统操作手册编写单位:青岛方天科技开发编写人:鞠瑞楼编写时间:2005-12-14目录1引言 (3)编写目的 (3)背景 (3)参考资料 (3)重要声明 (3)2系统总体描述 (4)前台总体描述 (4)后台总体描述 (4)3系统详细描述 (6)前台详细描述 (6)功能区 (6)推荐书内容区 (7)工程〔人或组织〕列表区 (7)工程信息展示区 (7)联机信息提示区 (7)时间显示区 (7)用户信息提示区 (7)辅助功能区 (7)后台详细描述 (8)功能区 (8)管理主题信息区 (8)主题信息展示区 (9)时间显示区 (9)用户信息提示区 (9)辅助功能区 (9)4系统各操作区域关联关系描述 (10)5实例演示 (10)审核一个工程 (10)推荐一个工程 (11)折回一个工程 (12)后台管理 (13)6运行环境 (13)效劳器 (13)客户端 (13)1引言1、明确系统所包含的功能。
2、明确用户所能够进行的操作范围和操作步骤。
3、结合详细的联机帮助,给用户在操作过程中无法理解的地方给出更加确切的解说和支持,以到达用户能够在无需培训的根底上即可自己动手,对系统所提供的功能进行灵活运用,提高工作效率,尽快完成各项奖励推荐工作。
4、通过对各个模块的细化,梳理出各个模块之间的关系,以便到达使用用户知道处于当前流程的数据流的走向。
4、通过实例操作流程介绍,简要告知用户操作方法。
5、本操作手册读者为所有使用本系统的推荐单位。
系统名称:青岛市科学技术奖励推荐系统提出对象:青岛市科技成果管理处开发单位:青岛方天科技开发公司使用对象:各成果推荐单位工程负责人:鞠瑞楼A、?山东省科学技术奖励推荐系统?B、?国家科学技术奖励推荐系统?C、?国家科学技术奖励专家推荐系统?系统中演示所有用到的数据均为虚构,与任何单位无关。
2系统总体描述前台总体描述本系统为各推荐单位提供了一个通用的、标准的数据输入窗口,用户无需不断切换操作即可完成各类成果的推荐工作。

Package‘recosystem’May5,2023Type PackageTitle Recommender System using Matrix FactorizationVersion0.5.1Date2023-05-05Author Yixuan Qiu,David Cortes,Chih-Jen Lin,Yu-Chin Juan,Wei-Sheng Chin, Yong Zhuang,Bo-Wen Yuan,Meng-Yuan Yang,and othercontributors.Seefile AUTHORS for details.Maintainer Yixuan Qiu<*******************>Description R wrapper of the'libmf'library<https://.tw/~cjlin/libmf/>for recommendersystem using matrix factorization.It is typically used toapproximate an incomplete matrix using the product of twomatrices in a latent space.Other common names for this taskinclude``collaborativefiltering'',``matrix completion'',``matrix recovery'',etc.High performance multi-core parallelcomputing is supported in this package.License BSD_3_clause+file LICENSECopyright seefile COPYRIGHTSURL https:///yixuan/recosystemBugReports https:///yixuan/recosystem/issuesDepends R(>=3.3.0),methodsImports Rcpp(>=0.11.0),floatSuggests knitr,rmarkdown,prettydoc,MatrixLinkingTo Rcpp,RcppProgressVignetteBuilder knitrRoxygenNote7.2.3NeedsCompilation yesRepository CRANDate/Publication2023-05-0510:40:02UTC1R topics documented:data_source (2)output (4)output_format (5)predict (6)Reco (8)train (8)tune (11)Index14 data_source Specifying Data SourceDescriptionFunctions in this page are used to specify the source of data in the recommender system.They are intended to provide the input argument of functions such as$tune(),$train(),and$predict().Currently three data formats are supported:datafile(via function data_file()),data in mem-ory as R objects(via function data_memory()),and data stored as a sparse matrix(via function data_matrix()).Usagedata_file(path,index1=FALSE,...)data_memory(user_index,item_index,rating=NULL,index1=FALSE,...)data_matrix(mat,...)Argumentspath Path to the datafile.index1Whether the user indices and item indices start with1(index1=TRUE)or0 (index1=FALSE)....Currently unused.user_index An integer vector giving the user indices of rating scores.item_index An integer vector giving the item indices of rating scores.rating A numeric vector of the observed entries in the rating matrix.Can be specified as NULL for testing data,in which case it is ignored.mat A dgTMatrix(if it has ratings/values)or ngTMatrix(if it is binary)sparse ma-trix,with users corresponding to rows and items corresponding to columns.DetailsIn$tune()and$train(),functions in this page are used to specify the source of training data.data_file()expects a textfile that describes a sparse matrix in triplet form,i.e.,each line in the file contains three numbersrow col valuerepresenting a number in the rating matrix with its location.In real applications,it typically looks likeuser_index item_index ratingThe‘smalltrain.txt’file in the‘dat’directory of this package shows an example of training data file.If the sparse matrix is given as a dgTMatrix or ngTMatrix object(triplets/COO format defined in the Matrix package),then the function data_matrix()can be used to specify the data source.If user index,item index,and ratings are stored as R vectors in memory,they can be passed to data_memory()to form the training data source.By default the user index and item index start with zeros,and the option index1=TRUE can be set if they start with ones.From version0.4recosystem supports two special types of matrix factorization:the binary matrix factorization(BMF),and the one-class matrix factorization(OCMF).BMF requires ratings to take value from−1,1,and OCMF requires all the ratings to be positive.In$predict(),functions in this page provide the source of testing data.The testing data have the same format as training data,except that the value(rating)column is not required,and will be ignored if it is provided.The‘smalltest.txt’file in the‘dat’directory of this package shows an example of testing datafile.ValueAn object of class"DataSource"as required by$tune(),$train(),and$predict().Author(s)Yixuan Qiu<https://statr.me>See Also$tune(),$train(),$predict()4output output Exporting Factorization MatricesDescriptionThis method is a member function of class"RecoSys"that exports the user score matrix P and the item score matrix Q.Prior to calling this method,model needs to be trained using member function$train().The common usage of this method isr=Reco()r$train(...)r$output(out_P=out_file("mat_P.txt"),out_Q=out_file("mat_Q.txt"))Argumentsr Object returned by Reco().out_P An object of class Output that specifies the output format of the user matrix, typically returned by function out_file(),out_memory()or out_nothing().out_file()writes the matrix into afile,with each row representing a user andeach column representing a latent factor.out_memory()exports the matrix intothe return value of$output().out_nothing()means the matrix will not beexported.out_Q Ditto,but for the item matrix.ValueA list with components P and Q.They will befilled with user or item matrix if out_memory()isused in the function argument,otherwise NULL will be returned.Author(s)Yixuan Qiu<https://statr.me>ReferencesW.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Fast Parallel Stochastic Gradient Method for Matrix Factorization in Shared Memory Systems.ACM TIST,2015.W.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Learning-rate Schedule for Stochastic Gradient Methods to Matrix Factorization.PAKDD,2015.W.-S.Chin,B.-W.Yuan,M.-Y.Yang,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.LIBMF:A Library for Parallel Matrix Factorization in Shared-memory Systems.Technical report,2015.See Also$train(),$predict()output_format5 Examplestrain_set=system.file("dat","smalltrain.txt",package="recosystem")r=Reco()set.seed(123)#This is a randomized algorithmr$train(data_file(train_set),out_model=file.path(tempdir(),"model.txt"),opts=list(dim=10,nmf=TRUE))##Write P and Q matrices to filesP_file=out_file(tempfile())Q_file=out_file(tempfile())r$output(P_file,Q_file)head(read.table(P_file@dest,header=FALSE,sep=""))head(read.table(Q_file@dest,header=FALSE,sep=""))##Skip P and only export Qr$output(out_nothing(),Q_file)##Return P and Q in memoryres=r$output(out_memory(),out_memory())head(res$P)head(res$Q)output_format Specifying Output FormatDescriptionFunctions in this page are used to specify the format of output results.They are intended to provide the argument of functions such as$output()and$predict().Currently there are three types of output:out_file()indicates that the result should be written into afile,out_memory()makes the result to be returned as R objects,and out_nothing()means the result is not needed and will not be returned.Usageout_file(path,...)out_memory(...)out_nothing(...)Argumentspath Path to the outputfile....Currently unused.ValueAn object of class"Output"as required by$output()and$predict().Author(s)Yixuan Qiu<https://statr.me>See Also$output(),$predict()predict Recommender Model PredictionsDescriptionThis method is a member function of class"RecoSys"that predicts unknown entries in the rating matrix.Prior to calling this method,model needs to be trained using member function$train().The common usage of this method isr=Reco()r$train(...)r$predict(test_data,out_pred=out_file("predict.txt")Argumentsr Object returned by Reco().test_data An object of class"DataSource"that describes the source of testing data,typi-cally returned by function data_file(),data_memory(),or data_matrix().out_pred An object of class Output that specifies the output format of prediction,typ-ically returned by function out_file(),out_memory()or out_nothing().out_file()writes the result into afile,out_memory()exports the vector of pre-dicted values into the return value of$predict(),and out_nothing()meansthe result will be neither returned nor written into afile(but computation willstill be conducted).Author(s)Yixuan Qiu<https://statr.me>ReferencesW.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Fast Parallel Stochastic Gradient Method for Matrix Factorization in Shared Memory Systems.ACM TIST,2015.W.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Learning-rate Schedule for Stochastic Gradient Methods to Matrix Factorization.PAKDD,2015.W.-S.Chin,B.-W.Yuan,M.-Y.Yang,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.LIBMF:A Library for Parallel Matrix Factorization in Shared-memory Systems.Technical report,2015.See Also$train()Examples##Not run:train_file=data_file(system.file("dat","smalltrain.txt",package="recosystem")) test_file=data_file(system.file("dat","smalltest.txt",package="recosystem"))r=Reco()set.seed(123)#This is a randomized algorithmopts_tune=r$tune(train_file)$minr$train(train_file,out_model=NULL,opts=opts_tune)##Write predicted values into fileout_pred=out_file(tempfile())r$predict(test_file,out_pred)##Return predicted values in memorypred=r$predict(test_file,out_memory())##If testing data are stored in memorytest_df=read.table(test_file@source,sep="",header=FALSE)test_data=data_memory(test_df[,1],test_df[,2])pred2=r$predict(test_data,out_memory())##Compare resultsprint(scan(out_pred@dest,n=10))head(pred,10)head(pred2,10)##If testing data are stored as a sparse matrixif(require(Matrix)){mat=Matrix::sparseMatrix(i=test_df[,1],j=test_df[,2],x=-1,repr="T",index1=FALSE)test_data=data_matrix(mat)pred3=r$predict(test_data,out_memory())print(head(pred3,10))}##End(Not run)Reco Constructing a Recommender System ObjectDescriptionThis function simply returns an object of class"RecoSys"that can be used to construct recom-mender model and conduct prediction.UsageReco()ValueReco()returns an object of class"RecoSys"equipped with methods$train(),$tune(),$output() and$predict(),which describe the typical process of building and tuning model,exporting fac-torization matrices,and predicting results.See their help documents for details.Author(s)Yixuan Qiu<https://statr.me>ReferencesW.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Fast Parallel Stochastic Gradient Method for Matrix Factorization in Shared Memory Systems.ACM TIST,2015.W.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Learning-rate Schedule for Stochastic Gradient Methods to Matrix Factorization.PAKDD,2015.W.-S.Chin,B.-W.Yuan,M.-Y.Yang,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.LIBMF:A Library for Parallel Matrix Factorization in Shared-memory Systems.Technical report,2015.See Also$tune(),$train(),$output(),$predict()train Training a Recommender ModelDescriptionThis method is a member function of class"RecoSys"that trains a recommender model.It will read from a training data source and create a modelfile at the specified location.The modelfile contains necessary information for prediction.The common usage of this method isr=Reco()r$train(train_data,out_model=file.path(tempdir(),"model.txt"),opts=list())Argumentsr Object returned by Reco().train_data An object of class"DataSource"that describes the source of training data,typi-cally returned by function data_file(),data_memory(),or data_matrix().out_model Path to the modelfile that will be created.If passing NULL,the model will bestored in-memory,and model matrices can then be accessed under r$model$matrices.opts A number of parameters and options for the model training.See section Param-eters and Options for details.Parameters and OptionsThe opts argument is a list that can supply any of the following parameters:loss Character string,the loss function.Default is"l2",see below for details.dim Integer,the number of latent factors.Default is10.costp_l1Numeric,L1regularization parameter for user factors.Default is0.costp_l2Numeric,L2regularization parameter for user factors.Default is0.1.costq_l1Numeric,L1regularization parameter for item factors.Default is0.costq_l2Numeric,L2regularization parameter for item factors.Default is0.1.lrate Numeric,the learning rate,which can be thought of as the step size in gradient descent.Default is0.1.niter Integer,the number of iterations.Default is20.nthread Integer,the number of threads for parallel computing.Default is1.nbin Integer,the number of bins.Must be greater than nthread.Default is20.nmf Logical,whether to perform non-negative matrix factorization.Default is FALSE.verbose Logical,whether to show detailed information.Default is TRUE.The loss option may take the following values:For real-valued matrix factorization,"l2"Squared error(L2-norm)"l1"Absolute error(L1-norm)"kl"Generalized KL-divergenceFor binary matrix factorization,"log"Logarithmic error"squared_hinge"Squared hinge loss"hinge"Hinge lossFor one-class matrix factorization,"row_log"Row-oriented pair-wise logarithmic loss"col_log"Column-oriented pair-wise logarithmic lossAuthor(s)Yixuan Qiu<https://statr.me>ReferencesW.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Fast Parallel Stochastic Gradient Method for Matrix Factorization in Shared Memory Systems.ACM TIST,2015.W.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Learning-rate Schedule for Stochastic Gradient Methods to Matrix Factorization.PAKDD,2015.W.-S.Chin,B.-W.Yuan,M.-Y.Yang,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.LIBMF:A Library for Parallel Matrix Factorization in Shared-memory Systems.Technical report,2015.See Also$tune(),$output(),$predict()Examples##Training model from a data filetrain_set=system.file("dat","smalltrain.txt",package="recosystem")train_data=data_file(train_set)r=Reco()set.seed(123)#This is a randomized algorithm#The model will be saved to a filer$train(train_data,out_model=file.path(tempdir(),"model.txt"),opts=list(dim=20,costp_l2=0.01,costq_l2=0.01,nthread=1) )##Training model from data in memorytrain_df=read.table(train_set,sep="",header=FALSE)train_data=data_memory(train_df[,1],train_df[,2],rating=train_df[,3])set.seed(123)#The model will be stored in memoryr$train(train_data,out_model=NULL,opts=list(dim=20,costp_l2=0.01,costq_l2=0.01,nthread=1) )##Training model from data in a sparse matrixif(require(Matrix)){mat=Matrix::sparseMatrix(i=train_df[,1],j=train_df[,2],x=train_df[,3],repr="T",index1=FALSE)train_data=data_matrix(mat)r$train(train_data,out_model=NULL,opts=list(dim=20,costp_l2=0.01,costq_l2=0.01,nthread=1)) }tune11 tune Tuning Model ParametersDescriptionThis method is a member function of class"RecoSys"that uses cross validation to tune the model parameters.The common usage of this method isr=Reco()r$tune(train_data,opts=list(dim=c(10L,20L),costp_l1=c(0,0.1),costp_l2=c(0.01,0.1),costq_l1=c(0,0.1),costq_l2=c(0.01,0.1),lrate=c(0.01,0.1)))Argumentsr Object returned by Reco().train_data An object of class"DataSource"that describes the source of training data,typi-cally returned by function data_file(),data_memory(),or data_matrix().opts A number of candidate tuning parameter values and extra options in the model tuning procedure.See section Parameters and Options for details.ValueA list with two components:min Parameter values with minimum cross validated loss.This is a list that can be passed to the opts argument in$train().res A data frame giving the supplied candidate values of tuning parameters,and one column show-ing the loss function value associated with each combination.Parameters and OptionsThe opts argument should be a list that provides the candidate values of tuning parameters and some other options.For tuning parameters(dim,costp_l1,costp_l2,costq_l1,costq_l2,and lrate),users can provide a numeric vector for each one,so that the model will be evaluated on each combination of the candidate values.For other non-tuning options,users should give a single value.If a parameter or option is not set by the user,the program will use a default one.See below for the list of available parameters and options:dim Tuning parameter,the number of latent factors.Can be specified as an integer vector,with default value c(10L,20L).12tune costp_l1Tuning parameter,the L1regularization cost for user factors.Can be specified as a numeric vector,with default value c(0,0.1).costp_l2Tuning parameter,the L2regularization cost for user factors.Can be specified as a numeric vector,with default value c(0.01,0.1).costq_l1Tuning parameter,the L1regularization cost for item factors.Can be specified as a numeric vector,with default value c(0,0.1).costq_l2Tuning parameter,the L2regularization cost for item factors.Can be specified as a numeric vector,with default value c(0.01,0.1).lrate Tuning parameter,the learning rate,which can be thought of as the step size in gradient descent.Can be specified as a numeric vector,with default value c(0.01,0.1).loss Character string,the loss function.Default is"l2",see section Parameters and Options in $train()for details.nfold Integer,the number of folds in cross validation.Default is5.niter Integer,the number of iterations.Default is20.nthread Integer,the number of threads for parallel computing.Default is1.nbin Integer,the number of bins.Must be greater than nthread.Default is20.nmf Logical,whether to perform non-negative matrix factorization.Default is FALSE.verbose Logical,whether to show detailed information.Default is FALSE.progress Logical,whether to show a progress bar.Default is TRUE.Author(s)Yixuan Qiu<https://statr.me>ReferencesW.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Fast Parallel Stochastic Gradient Method for Matrix Factorization in Shared Memory Systems.ACM TIST,2015.W.-S.Chin,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.A Learning-rate Schedule for Stochastic Gradient Methods to Matrix Factorization.PAKDD,2015.W.-S.Chin,B.-W.Yuan,M.-Y.Yang,Y.Zhuang,Y.-C.Juan,and C.-J.Lin.LIBMF:A Library for Parallel Matrix Factorization in Shared-memory Systems.Technical report,2015.See Also$train()Examples##Not run:train_set=system.file("dat","smalltrain.txt",package="recosystem")train_src=data_file(train_set)r=Reco()set.seed(123)#This is a randomized algorithmres=r$tune(train_src,tune13 opts=list(dim=c(10,20,30),costp_l1=0,costq_l1=0,lrate=c(0.05,0.1,0.2),nthread=2))r$train(train_src,opts=res$min)##End(Not run)Index∗modelsReco,8data_file,6,9,11data_file(data_source),2data_matrix,6,9,11data_matrix(data_source),2data_memory,6,9,11data_memory(data_source),2data_source,2out_file,4,6out_file(output_format),5out_memory,4,6out_memory(output_format),5out_nothing,4,6out_nothing(output_format),5output,4,5,6,8,10output_format,5predict,2–6,6,8,10Reco,4,6,8,9,11train,2–4,6–8,8,11,12tune,2,3,8,10,1114。

电子商务平台中的推荐系统算法使用教程随着电子商务的迅速发展,推荐系统算法在电商平台中扮演着越来越重要的角色。
通过使用推荐系统算法,电商平台能够向用户提供个性化的推荐,提高用户体验并增加销售额。
本文将介绍电子商务平台中常用的推荐系统算法,以及它们的使用方法和注意事项。
一、基于内容的推荐算法基于内容的推荐算法通过分析用户对商品的行为数据,提取商品的相关特征,然后根据用户的兴趣偏好,推荐与这些特征相似的商品给用户。
这种算法比较适合于商品具备明确的特征描述的情况,例如图书、音乐、电影等。
使用基于内容的推荐算法需要注意以下几点:1. 数据预处理:对商品的相关特征进行提取和清洗,确保数据的准确性和一致性。
2. 特征表示:使用合适的特征表示方法,例如将文本数据转化为向量表示、将图像数据转化为特征向量等。
3. 相似性计算:根据特征向量计算商品之间的相似度,常用的计算方法有余弦相似度、欧氏距离等。
4. 推荐结果生成:根据用户的兴趣偏好,选择与用户喜好相似度较高的商品推荐给用户。
二、协同过滤推荐算法协同过滤推荐算法是根据用户的历史行为数据,例如购买记录、评价等,找到与用户兴趣相似的其他用户或商品,然后将这些用户或商品的行为推荐给目标用户。
这种算法不依赖于商品的特征描述,适用于各种类型的商品。
使用协同过滤推荐算法需要注意以下几点:1. 用户行为数据收集:收集用户的历史行为数据,包括购买记录、收藏、评价、浏览等。
2. 用户相似度计算:根据用户的历史行为数据,计算用户之间的相似度,常用的计算方法有余弦相似度、皮尔逊相关系数等。
3. 推荐结果生成:根据用户之间的相似度,找出与目标用户兴趣相似的其他用户,然后将这些用户喜欢的商品推荐给目标用户。
三、混合推荐算法混合推荐算法将基于内容的推荐算法和协同过滤推荐算法结合起来,综合利用它们的优点,提高推荐的准确性和个性化程度。
在混合推荐算法中,可以根据实际情况,权衡使用各种推荐算法的比例。
电子商务平台中的推荐系统使用方法随着电子商务的快速发展,越来越多的人开始在电子商务平台上购物。
然而,众多的商品和信息往往会让消费者感到困惑,不知道选择哪个产品更好。
为了解决这个问题,电子商务平台引入了推荐系统。
推荐系统是一种利用机器学习和数据分析技术,根据用户的历史购买记录、浏览行为、兴趣爱好等信息,提供个性化推荐的信息过滤系统。
它能够帮助消费者发现他们可能感兴趣的商品,提高购物体验,同时也能帮助电子商务平台增加销售额。
在电子商务平台中使用推荐系统可以带来很多好处。
首先,推荐系统可以为用户节省时间和精力。
在海量的商品中寻找合适的产品是一项繁琐的任务,而推荐系统能够通过分析用户的喜好,将可能感兴趣的产品展示在用户面前,大大减少了用户搜索的时间。
其次,推荐系统可以为用户提供个性化的推荐。
每个人的喜好都不尽相同,传统的广告宣传往往难以达到用户的期望。
而推荐系统可以根据用户的兴趣爱好,为其推荐符合其口味的商品,提供更好的购物体验。
最后,推荐系统还可以帮助电子商务平台提高产品的曝光率。
通过将商品展示在用户可能看到的位置,推荐系统能够增加用户的点击率和转化率,进一步提高平台的销售额。
那么,在电子商务平台中如何使用推荐系统呢?首先,用户需要注册一个账号。
注册时,平台会询问用户一些基本信息,如性别、年龄、地区等。
这些信息在后续的推荐过程中将起到重要作用。
接下来,用户可以根据自己的兴趣爱好进行浏览和搜索。
当用户浏览或搜索商品时,推荐系统会记录用户的历史行为,并根据这些信息进行分析和推荐。
用户也可以通过标记喜欢或不喜欢的商品,帮助推荐系统更好地了解自己的喜好。
推荐系统通常会提供多种推荐方式,包括基于内容的推荐、协同过滤推荐和混合推荐等。
基于内容的推荐是根据商品的特征和用户的喜好进行匹配推荐的,而协同过滤推荐是根据用户历史行为和其他用户的行为进行推荐的。
混合推荐则是将不同的推荐算法进行融合,提供更多样化的推荐结果。
此外,推荐系统还可以提供用户评价和评论功能。
人工智能在电子商务中的推荐系统教程在当今高度数字化和互联网化的商业环境中,电子商务已经成为了人们购物和交易的主要方式之一。
为了提供更好的用户体验和推动销售增长,电子商务平台采用了各种推荐系统来帮助用户发现和购买感兴趣的商品。
其中,人工智能技术在电子商务推荐系统的发展中发挥了重要作用。
本文将介绍人工智能在电子商务中的推荐系统,并提供一些教程和指导。
一、什么是推荐系统?推荐系统是一种利用算法和技术为用户提供个性化的商品、服务或信息推荐的系统。
通过分析用户的历史行为、偏好和兴趣,推荐系统可以预测用户可能喜欢的商品,并将相关的推荐结果呈现给用户。
推荐系统不仅可以提高用户购物体验,还可以增加电子商务平台的销售量。
二、人工智能在推荐系统中的应用1. 数据收集和分析:人工智能技术通过大数据的处理和分析,可以获取用户的历史购买记录、浏览行为和偏好信息等。
这些数据被用来训练算法,为用户提供更准确的推荐结果。
2. 协同过滤算法:协同过滤是推荐系统中应用最广泛的算法之一。
它基于用户或商品之间的相似度,来为用户推荐他人或他们可能喜欢的商品。
通过分析大量数据,人工智能能够更好地计算相似度,并提供个性化的推荐。
3. 推荐模型的优化:人工智能技术可以帮助推荐系统优化推荐模型。
通过机器学习算法的训练和优化,推荐系统能够提供更准确、更实时和更个性化的推荐结果。
4. 多样性和个性化平衡:推荐系统需要在提供个性化推荐的同时,注重推荐结果的多样性。
人工智能技术可以帮助平衡个性化和多样性之间的关系,以确保用户在推荐结果中能够发现新的、多样的商品。
三、创建一个基于人工智能的电子商务推荐系统的步骤为了构建一个基于人工智能的电子商务推荐系统,您可以按照以下步骤进行操作:1. 数据准备:收集和整理用户的历史购买记录、浏览行为和偏好信息等。
这些数据需要被清洗和预处理,以便用于后续的推荐算法训练。
2. 选择合适的推荐算法:根据您的具体应用场景和需求选择合适的推荐算法。
旅游景区智慧导览系统手册第一章概述 (3)1.1 系统简介 (3)1.2 功能特点 (3)1.2.1 实时导航 (3)1.2.2 智能推荐 (3)1.2.3 语音解说 (4)1.2.4 虚拟现实体验 (4)1.2.5 互动交流 (4)1.2.6 信息推送 (4)1.2.7 数据分析 (4)1.2.8 安全保障 (4)第二章系统安装与配置 (4)2.1 硬件设备要求 (4)2.2 软件安装流程 (5)2.3 系统配置 (5)第三章用户注册与登录 (6)3.1 用户注册 (6)3.1.1 注册流程 (6)3.1.2 注册注意事项 (6)3.2 用户登录 (6)3.2.1 登录流程 (6)3.2.2 登录方式 (6)3.3 密码找回 (7)3.3.1 找回密码流程 (7)3.3.2 密码找回注意事项 (7)第四章导览地图 (7)4.1 地图展示 (7)4.1.1 地图类型 (7)4.1.2 地图操作 (7)4.1.3 地图标注 (7)4.2 搜索与定位 (7)4.2.1 搜索功能 (8)4.2.2 定位功能 (8)4.2.3 导航功能 (8)4.3 路线规划 (8)4.3.1 自定义路线 (8)4.3.2 智能推荐路线 (8)4.3.3 实时路线调整 (8)4.3.4 路线分享 (8)第五章景点介绍 (8)5.1 景点信息展示 (8)5.3 景点图片浏览 (9)第六章互动体验 (10)6.1 虚拟现实体验 (10)6.1.1 概述 (10)6.1.2 技术原理 (10)6.1.3 应用场景 (10)6.2 互动游戏 (10)6.2.1 概述 (10)6.2.2 游戏类型 (10)6.2.3 应用场景 (10)6.3 用户互动 (11)6.3.1 概述 (11)6.3.2 互动方式 (11)6.3.3 应用场景 (11)第七章智能导航 (11)7.1 实时导航 (11)7.1.1 概述 (11)7.1.2 功能特点 (11)7.1.3 使用方法 (12)7.2 导航提示 (12)7.2.1 概述 (12)7.2.2 功能特点 (12)7.2.3 使用方法 (12)7.3 导航历史 (12)7.3.1 概述 (12)7.3.2 功能特点 (12)7.3.3 使用方法 (13)第八章个性化推荐 (13)8.1 智能推荐 (13)8.1.1 推荐系统概述 (13)8.1.2 推荐算法 (13)8.2 用户偏好设置 (13)8.2.1 偏好设置界面 (13)8.2.2 偏好设置应用 (13)8.3 推荐效果评估 (14)8.3.1 评估指标 (14)8.3.2 评估方法 (14)8.3.3 持续优化 (14)第九章安全保障 (14)9.1 数据安全 (14)9.1.1 数据加密 (14)9.1.2 数据备份 (14)9.1.3 数据访问控制 (14)9.2 用户隐私保护 (15)9.2.1 隐私政策 (15)9.2.2 用户信息保护 (15)9.2.3 用户权限管理 (15)9.2.4 用户隐私投诉处理 (15)9.3 系统防护 (15)9.3.1 安全防护策略 (15)9.3.2 系统更新与维护 (15)9.3.3 网络安全监控 (15)9.3.4 应急预案 (15)第十章客户服务与反馈 (15)10.1 客服服务 (15)10.1.1 服务宗旨 (15)10.1.2 服务内容 (16)10.1.3 服务方式 (16)10.2 用户反馈 (16)10.2.1 反馈渠道 (16)10.2.2 反馈内容 (16)10.3 意见建议处理 (16)10.3.1 反馈收集与整理 (16)10.3.2 反馈处理与回复 (17)10.3.3 反馈结果公示 (17)第一章概述1.1 系统简介旅游景区智慧导览系统是一种集成了现代信息技术、地理信息系统、智能识别技术等高科技手段的综合性导览平台。
机器学习中的推荐系统技术介绍推荐系统是指根据用户的偏好和行为,为用户提供个性化的信息或产品推荐。
在现代互联网时代,推荐系统已经成为各种在线平台的重要功能之一,如电商平台、社交媒体、音乐和视频流媒体服务等。
推荐系统的核心是利用机器学习技术来分析用户的行为和偏好,从而提供个性化的推荐,为用户提供更好的体验。
本文将介绍机器学习中的推荐系统技术,并探讨其在不同领域的应用。
1. 推荐系统的基本原理推荐系统的基本原理是通过分析用户的历史行为和偏好,来预测用户对新内容的喜好程度。
推荐系统通常包括两个主要的部分:用户模型和物品模型。
用户模型用于描述用户的偏好和行为,通常采用用户特征向量来表示,这些特征可以包括用户的年龄、性别、地理位置、历史行为等。
物品模型则用于描述物品的特征,通常采用物品特征向量来表示,这些特征可以包括物品的类别、标签、关键词等。
推荐系统的目标是通过用户模型和物品模型来预测用户对物品的喜好程度,从而为用户提供个性化的推荐。
2. 推荐系统的算法推荐系统的算法主要包括协同过滤、内容-based 推荐、矩阵分解等。
协同过滤是推荐系统中最常用的算法之一,它通过分析用户的历史行为来发现用户之间的相似性,从而为用户提供相似用户喜好的物品。
内容-based 推荐则是通过分析物品的特征来为用户推荐相似特征的物品,这种方法通常适用于物品的特征比较明确的场景。
矩阵分解是一种基于矩阵分解技术的推荐算法,它通过分解用户-物品交互矩阵来发现用户和物品的隐含特征,从而提高推荐的准确性。
3. 推荐系统的应用推荐系统在各种在线平台上都有广泛的应用,如电商平台、社交媒体、音乐和视频流媒体服务等。
在电商平台上,推荐系统可以根据用户的购物历史和行为,为用户推荐个性化的商品。
在社交媒体上,推荐系统可以根据用户的兴趣和关系,为用户推荐朋友的动态和内容。
在音乐和视频流媒体服务上,推荐系统可以根据用户的听歌和观看历史,为用户推荐相似风格的音乐和视频。
推荐系统的使用方法及性能分析推荐系统是一种基于用户兴趣和行为数据的智能化工具,旨在帮助用户发现并获得个性化的推荐内容。
随着互联网的快速发展,推荐系统已经广泛应用于各个领域,如电子商务、社交媒体、音乐和视频流媒体等。
本文将介绍推荐系统的使用方法,并对其性能进行分析。
首先,推荐系统的使用方法主要包括以下几个步骤:1. 数据收集:推荐系统依赖于用户的兴趣和行为数据来生成个性化推荐结果。
因此,首先需要收集和整理用户的数据,包括浏览记录、购买记录、评价和评论等。
2. 数据预处理:在将数据输入推荐系统之前,需要进行一些预处理工作,例如去重、数据清洗和特征提取等。
这有助于提高数据的质量和系统的性能。
3. 算法选择:推荐系统通常采用各种不同的算法来生成推荐结果,如基于内容的推荐、协同过滤和深度学习等。
在选择算法时,需要考虑数据量、数据类型和系统需求等因素。
4. 模型训练:选择算法后,需要使用训练数据对模型进行训练。
这包括参数的优化和模型的调整,以提高模型的准确性和推荐效果。
5. 推荐生成:一旦模型训练完成,就可以使用系统来生成个性化的推荐结果。
推荐结果可以以列表、矩阵或流的形式呈现给用户。
6. 反馈和评估:推荐系统需要不断优化和改进,以满足用户的需求。
因此,反馈和评估是非常重要的步骤。
可以通过用户调查、A/B测试和离线评估等方式进行推荐系统的性能评估。
其次,推荐系统的性能分析主要关注以下几个指标:1. 准确性:推荐系统的准确性是衡量其性能的重要指标之一。
可以通过计算推荐结果与用户真实行为之间的差异来评估准确性。
2. 覆盖率:覆盖率是指推荐系统在所有物品范围内能够推荐的物品比例。
较高的覆盖率意味着推荐系统能够涵盖更多不同类型的物品。
3. 多样性:多样性是指推荐结果的差异化程度。
推荐系统应该能够提供不同类型和风格的推荐结果,以满足不同用户的需求。
4. 实时性:实时性是指推荐系统生成推荐结果的速度。
对于一些需要实时推荐的场景,快速生成推荐结果是非常重要的。
推荐系统手册(0)--前言 推荐系统是近几年比较新的一个领域,目前比较完整的介绍这个领域的资料,主要是一些综述性paper。这些paper往往都各有侧重点,大多比较偏重推荐算法这一个层面,不够全面。 2011年的时候,国外一些在个性化推荐领域浸淫多年的人合作写了《Recommender System Handbook》一书,弥补了这方面的一个空白。其实这个东西与其说是一本书,不如说是一个资料集。它的写作方式看起来是几个大牛先拍下来应该包含哪几部分,每一部分包括哪些topic,然后把每一个topic分给对应的人写命题作文。这样的后果就是这本手册的每一章都是不同的作者写的,导致全书的连贯性和一致性较差,也就不够权威了。 然而尽管权威性不足,这本书仍然是目前能够找到的最全面的推荐系统方面的资料。鉴于此,我决定通读一遍这本书。在阅读的过程中,对每一章结合自己的理解,写一篇读书笔记。 以此作为前言。
推荐系统手册(1)—简介 现代生活带来的一个深刻改变是:人们的选择越来越多。我们选择看哪部电影,买哪个手机,看哪条新闻,租哪处房子…我们拥有的决策自由越来越多,随之而来的是,我们为这些决策付出的代价越来越多。相信大家都有过同样的经历,为了买一样东西,将网上琳琅满目的商品页面从第一页翻到最后一页,最后精疲力竭,还是购买了最初看中的那一个。有句俗话说得好:只有一个选择的人是最幸福的。 1. 推荐系统 推荐系统的兴起,即是为了把人们从信息过载的陷阱中解决出来,帮助人们进行简单决策。它的主要原理是根据用户过去的行为(比如购买、评分、点击等)来为用户建立兴趣模型,并利用一定的推荐算法,把用户最可能感兴趣的内容推荐给用户,如下图。
图1 推荐系统简图 2. 数据 为了完成上面的计算,我们需要三部分数据: (1)用户数据:用户数据用来建立用户模型,这些数据根据不同的推荐算法而不同,典型的数据包括用户兴趣点、用户profile、用户的社交好友关系等。 (2)内容数据:内容数据是用来描述一个被推荐内容主要属性的数据,这些属性主要都是跟具体的内容相关的,如一部电影的导演、演员、类型和风格等。 (3)用户--内容数据:用户--内容交互是能反映用户与内容内在联系的数据,其分为隐式和显式两种。显式主要是指评价、打分、购买等能明显反映用户对内容兴趣的交互数据,隐式指的是用户的点击、搜索记录等间接反映用户对内容兴趣的交互数据。 3. 算法 有了基础数据之后,我们可以考虑不同的推荐算法。根据数据和利用数据的方式的不同,当前主流的推荐算法可以分为以下六类(不是主流的划分方法): (1)基于内容的推荐(content-based):根据用户过去喜欢的内容,推荐相似的内容 (2)基于协同过滤的推荐(collaborative filtering ):根据与当前用户相似的用户的兴趣点,给当前用户推荐相似的内容 (3)基于人口统计学的推荐(demographic-based):根据用户共同的年龄、地域等人口统计学信息进行共同的推荐 (4)基于知识的推荐(knowledge-based):根据对用户和内容的特定领域知识,给特定的用户推荐特定的内容 (5)基于团体的推荐(community-based):根据用户的社交好友关系,给用户推荐其好友感兴趣的内容 (6)混合推荐(hybrid recommender system):以上各种推荐算法的特定组合 有了基础数据和算法选择后,我们在理解了特定领域知识、可用数据、应用需求的基础上,分析潜在的挑战和限制后,才能选择合适的推荐算法进行推荐系统的开发。 4. 相关领域 推荐系统(RS)是一个较新的领域,它利用并结合了多个领域的技术,其中最主要的包括信息检索(IR)、机器学习(ML)和人机交互(HCI)。 RS和IR同是为了解决人们面对信息过载的解决方法,它们有很多共同点。它们利用的很多技术,如相关性计算、多样性页面展现等,都是可以互为借鉴的。同时,它们会遇到很多类似的问题,如关联计算的规模过大,在IR中是通过倒排索引来减小计算规模,这一点在IR中同样可以借用。不同的是信息检索是利用显式的query来表达用户的需求,而推荐系统是利用机器隐式分析用户的兴趣来表达用户的需求。这一点决定了RS是一个比IR更难的问题,一是用户的兴趣比query更难准确的表达;二是用户的规模往往比query的规模要大几个数量级。 RS利用了ML中的很多算法和思想,如KNN聚类、机器学习点击率预估等,都是RS中常用的机器学习方法。 在推荐系统开发完成后,我们还需要考虑人机交互接口的问题。第一,系统要建立用户对推荐系统的信任;除了给用户靠谱的推荐结果外,我们从界面设计上要给出推荐的解释,即告诉用户系统为什么给他推荐某项内容,以此来说服用户信任推荐系统;第二,系统要给用户反馈的机制。当某项推荐靠谱并得到用户行为的证实(购买、评价高分等)时,系统要从用户的行为中得到正反馈来增进系统的准确性;同时,当某项推荐不靠谱时,我们要给用户提供一个负反馈的界面,来对推荐结果进行批评。第三,推荐的展现效果要满足用户的视觉需求,堆积的过满或者过松,字体太大或者太小,有没有缩略图等,都会对用户对推荐的满意度产生一定的影响。
推荐系统手册(2)—推荐系统的数据挖掘方法 引言 通常来说,数据挖掘(Data Mining,DM)最早是机器学习(Machine Learning,ML)算法在具体领域中的应用。后来,在这些具体应用过程中逐渐总结出一套通用的流程,和数据挖掘一起形成了一个新的领域,叫数据库中的知识发现(Knowledge Discovery in Database),其主要流程:
推荐系统算法策略通常会用到数据挖掘、机器学习、信息检索和自然语言处理等领域中的很多知识,尤其是数据挖掘。 1. 数据预处理 推荐系统相关的数据预处理技术除了通常的归一化、变量替换等以外,最主要的是相似度计算、抽样和维度规约。 (1). 相似度计算 相似度通常有两种衡量方式,一是直接计算相似度,二是计算距离,距离是本质上是相异程度的度量,距离越小,相似度越高。 1) 相似度度量 l 余弦相似度
其中,数据预处理主要是针对原始数据中的一些问题,如噪声、离群点、遗漏值、不一致值和重复值等数据质量的问题,通过抽样、维度规约、归一化、离散化和变量变换等方式,将数据转换成为适合数据挖掘直接利用的数据。数据挖掘即是机器学习算法在具体问题中的应用,通常包括分类、聚类和异常检测等。数据后处理是数据挖掘后的结果进行进一步的处理,使得数据挖掘的结果应用到问题的解决之中。 相似度计算最常见的方式是余弦相似度,对于n维空间的两个向量,通过以下公式计算相似度。其几何意义就是两个向量的空间夹角的余弦值,取值范围在-1到1之间。取值为-1表示完全相反,取值为1表示完全相同,其余值表示介于二者之间。
l 皮尔逊相关系数 相似度计算的另一种常见方式时皮尔逊相关系数。皮尔逊相关系数的实际意义是两个随机变量x和y之间的线性相关性,取值范围在-1和1之间。-1表示负线性相关,1表示正线性相关,其余值表示介于二者之间。
l Jaccard相关系数(Jaccard Coefficient) Jaccard用于集合相似度的一种方式。
2) 距离度量 l 欧几里得距离(Euclidean Distance) 距离度量最常见的是欧几里得距离,计算多位空间中两个点之间的绝对距离。
l 曼哈顿距离(Manhattan Distance) 曼哈顿距离也称为城市块距离,是将多个维度的直线距离求和后的结果。
l 切比雪夫距离(Chebyshev Distance) l 闵可夫斯基距离(Minkowski Distance) Minkowski距离是欧氏距离(p=2)、曼哈顿距离(p=1)和切比雪夫距离(p=无穷)的推广。
l 标准化欧氏距离(Standardized Euclidean Distance) 标准化欧氏距离是为了解决以上四种距离的一个重要不足而产生的,即以上四种距离把不同维度指标的差异视为相同的。标准欧式距离则通过每一维的标准差,对该维度进行一个标准化后再进行计算。
l 马哈拉诺比斯距离(Mahalanobis Distance) Mahalanobis距离是标准化欧氏距离的推广,在协方差矩阵是对角阵时,Mahalanobis距离就变成了标准化欧氏距离。
(2).抽样 抽样技术在数据挖掘中主要用在两个地方:一是在数据预处理和后处理阶段,为了避免计算规模过大,进行抽样计算。二是在数据挖掘阶段,通常会对训练出来的模型进行交叉验证,需要抽样将所有样本划分为训练集和测试集。 通常所说的抽样都是随机抽样(random sampling),主要用于所有样本点都可以认为没有区分时适用。还有一种分层抽样(striated sampling),在样本需要显著的分为不同的子集时,针对每个子集分别进行抽样。 (3). 维度规约(dimensionality reduction) 在统计学习理论中,当样本的维度增加的时候,待学习的模型的复杂性是随着维度呈指数增长的,这种现象通常称为“维灾难(curse of dimensionality)”。这也就意味着,如果我们想在高维空间中学到和在低维空间中精度一样高的模型,所需要的样本数是呈指数增长的。 维度规约通常是用来处理维灾难问题的。通常维度规约有两种思路,一是从高维数据中选出最能表达数据的一些维度,并用这些维度来代表数据,称为特征选择(feature selection)。另一种是将高维数据通过某种trick变换映射到低维空间,称为特征构造(feature extraction)。 主成分分析(PCA,Principal Component Analysis)是最主要的一种特征选择方式。它通过特征分解能够得到每一个维度对于整个数据的最小均方差的贡献程度,从而定量判断每一维对于数据所包含信息的贡献度。然后保留最主要的一些维度,抛弃一些不显著的维度,对数据进行降维。 奇异值分解(SVD,singular value decomposition)是主要的特征构造方式。它通过矩阵分解的方式,将数据从高维空间映射到低维空间,对数据进行降维。 2.数据挖掘-分类 分类是数据挖掘的主要内容,方法众多,各自都有不同数据假设和理论支持。下面简单列举最有代表性的一些算法。 (1).KNN(k-nearest neighbour) KNN是最容易理解的分类器,它不训练任何模型。当有一个未知样本需要预测时,它从已知样本中找到与这个未知样本距离最近的K个点,根据这K个点的类别来预测未知样本的类别。 它最主要的不足在于它需要的样本量非常大,同时因为它没有任何训练的模型,每一次预测都要计算k次距离,计算量非常大。 (2).决策树(Decision tree) 决策树将分类过程抽象为一颗树,它通过最大化信息增益的方式对树的分支进行划分,最终通过设置不纯度的阈值来停止树的划分,形成最终的决策树。 它的主要优点在于模型的训练和预测都非常快,不足在于模型的精度有时会低于其它分类器。不过,通过集群学习(ensemble learning)的方式能够极大的克服这一点,如采用bagging思想的random forest和采用boosting思想的GBDT,都是决策树的延伸,它们综合多棵决策树的分类结果来组合出更精确的分类器。 (3).基于规则的分类器(rule-based classifier) 基于规则的分类器通常都是利用“如果…则…”一类的规则来进行分类。其适用性有限,且要获得靠谱的规则比较困难,一般用的较少。 (4).贝叶斯分类器 贝叶斯分类器其实是一类分类器,主要是利用贝叶斯公式,通过估计先验概率和似然概率,并利用一部分先验信息,来计算给定样本的各维度数据值的情况下,样本属于某个类别的概率。 (5).人工神经网络 这个真心没弄懂,占座以后补上。 (6).支持向量机(supporting vector machine) 支持向量机是线性分类器的代表。与贝叶斯分类器先估计概率密度然后计算判别函数不同,线性分类器都是直接估计线性判别式,并最小化某个目标函数,利用某种凸优化方法求解得到最终的线性判别式。 这是最流行的分类器之一,通常认为它训练、预测速度快,而且精度靠谱,所以在各种领域广泛使用。 (7).组合分类器(ensemble learning) 组合分类器的想法是集合若干个弱分类器来组合成一个强分类器,通常有bagging和boosting两种思路。 (8).分类器评估 分类器评估是对一个分类器性能进行评价的重要一步,其主要有一些一些标准