使用 Oracle 数据库 11g管理非结构化数据
- 格式:pdf
- 大小:471.82 KB
- 文档页数:12

Orcale数据库中非结构化数据的存储方法作者:李福存姜跃文楚怀远来源:《电子技术与软件工程》2016年第23期摘要随着企业信息化应用程度的提升,企业会产生大量的信息化数据,这些数据既有传统的结构化数据,更有众多新型的非结构数据,诸如图像、音频、视频、办公文档等。
利用主流数据管理系统Oracle所提供的新方法,可有效构建非结构化数据的存储模型,从而使得非结构化数据的存储更高效,检索更快捷。
【关键词】非结构化数据存储 Oralce SecureFile1 前言随着信息技术的广泛普及和充分应用,企业在日常业务活动中会产生各种各样的信息化数据。
这些数据既有传统的结构化数据,更有大量的非结构化数据,诸如音频、视频、图像、办公文档等。
据IDC统计,在企业产生的全部数据中,约有80%都是非结构化数据,且每年按60%的指数增长。
在未来15年中,互联网和多媒体应用的数字非结构化数据量将超过6.023x1023 (阿伏加德罗常数),因此非结构化数据的高效存储和快速检索成为非结构化数据存储方案所面临的关键挑战。
2 数据存储结构与数据存储方法传统的结构化数据可以用二维表结构来逻辑表达,因此可以用关系型数据库来管理,而非结构化数据无法用二维表结构来表达,因此需要采用新的方法来存储和管理。
在大数据时代,主流的商业数据库软件如Oracle在对传统的结构化数据提供更先进的管理技术的同时,也对非结构化数据提供了有效的管理方法,能整合有关联性和结构化的数据及非结构化数据,从而给用户提供无缝的使用体验。
2.1 非结构化数据分类非结构化的数据可以分成几种不同的类型,比较常见的就是多媒体或富媒体文件,如数字化影像、音频文件、视频文件。
其分类如下:2.1.1 照片用二维方式来表示所有内容,如照片、素描、绘画、图标。
2.1.2 基于字符的文档由一个或多个明确定义的字符集中的字符所组成的集合,如Word文档、电子邮件、PDF 文件等。
2.1.3 音频基于时间的声音的集合,如WAV文件、MP3文件等。

oracle11g还原数据库步骤概述说明以及解释引言部分的内容可以按照如下方式撰写:1. 引言1.1 概述引言部分将介绍本篇文章的主题,即Oracle 11g数据库还原步骤。
数据库还原是一项至关重要的任务,它可以帮助恢复丢失或损坏的数据,并确保系统的连续性和可靠性。
在本文中,我们将深入探讨Oracle 11g数据库还原的步骤和过程,以及执行还原操作前需要注意的准备工作。
1.2 文章结构在本文中,我们将按照以下顺序来讨论Oracle 11g数据库还原:- 首先,我们将介绍Oracle 11g数据库还原的重要性,阐述为什么必须进行数据库还原操作。
- 其次,我们将概述Oracle 11g数据库还原的步骤,并列出每个步骤的简要说明。
- 第三部分我们将详细描述执行数据库还原操作前所需进行的准备工作。
- 接下来,我们将提供执行数据库还原操作的详细步骤,包括必要时涉及到的命令和工具。
- 最后,我们将讨论完成数据库还原后进行验证和测试的方法与技巧。
1.3 目的本文旨在为读者提供有关Oracle 11g数据库还原的全面指南。
通过学习本文,读者将能够了解数据库还原的重要性、掌握进行数据库还原操作的步骤和技巧,并且能够有效地验证和测试还原后的数据库。
我们希望这篇文章能够帮助读者在数据库还原过程中避免常见错误,并提供相关提示和建议。
2. 正文:2.1 Oracle 11g数据库还原的重要性在数据库管理中,数据的安全性和完整性是至关重要的。
由于各种原因,比如硬件故障、用户误操作或者系统遭受攻击,数据库可能会丢失或损坏。
因此,在这些情况下,数据库还原变得非常重要。
Oracle 11g数据库还原是指恢复已经丢失或被损坏的数据到其先前可用状态的过程。
2.2 Oracle 11g数据库还原的步骤概述数据库还原通常包括以下主要步骤:- 备份介质准备:确定可用的备份介质,并确保其处于良好状态。
- 目标库环境准备:在目标库上创建必需的目录结构,并配置参数以适应还原操作。

第一章:日志管理1.forcing log switchessql> alter system switch logfile;2.forcing checkpointssql> alter system checkpoint;3.adding online redo log groupssql> alter database add logfile [group 4]sql> ('/disk3/log4a.rdo','/disk4/log4b.rdo') size 1m;4.adding online redo log memberssql> alter database add logfile membersql> '/disk3/log1b.rdo' to group 1,sql> '/disk4/log2b.rdo' to group 2;5.changes the name of the online redo logfilesql> alter database rename file 'c:/oracle/oradata/oradb/redo01.log' sql> to 'c:/oracle/oradata/redo01.log';6.drop online redo log groupssql> alter database drop logfile group 3;7.drop online redo log memberssql> alter database drop logfile member 'c:/oracle/oradata/redo01.log';8.clearing online redo log filessql> alter database clear [unarchived] logfile 'c:/oracle/log2a.rdo';ing logminer analyzing redo logfilesa. in the init.ora specify utl_file_dir = ' 'b. sql> executedbms_logmnr_d.build('oradb.ora','c:\oracle\oradb\log');c. sql> executedbms_logmnr_add_logfile('c:\oracle\oradata\oradb\redo01.log',sql> dbms_logmnr.new);d. sql> executedbms_logmnr.add_logfile('c:\oracle\oradata\oradb\redo02.log',sql> dbms_logmnr.addfile);e. sql> executedbms_logmnr.start_logmnr(dictfilename=>'c:\oracle\oradb\log\oradb.ora ');f. sql> select * fromv$logmnr_contents(v$logmnr_dictionary,v$logmnr_parameterssql> v$logmnr_logs);g. sql> execute dbms_logmnr.end_logmnr;第二章:表空间管理1.create tablespacessql> create tablespace tablespace_name datafile'c:\oracle\oradata\file1.dbf' size 100m,sql> 'c:\oracle\oradata\file2.dbf' size 100m minimum extent 550k [logging/nologging]sql> default storage (initial 500k next 500k maxextents 500 pctinccease 0)sql> [online/offline] [permanent/temporary] [extent_management_clause]2.locally managed tablespacesql> create tablespace user_data datafile'c:\oracle\oradata\user_data01.dbf'sql> size 500m extent management local uniform size 10m;3.temporary tablespacesql> create temporary tablespace temp tempfile'c:\oracle\oradata\temp01.dbf'sql> size 500m extent management local uniform size 10m;4.change the storage settingsql> alter tablespace app_data minimum extent 2m;sql> alter tablespace app_data default storage(initial 2m next 2m maxextents 999);5.taking tablespace offline or onlinesql> alter tablespace app_data offline;sql> alter tablespace app_data online;6.read_only tablespacesql> alter tablespace app_data read only|write;7.droping tablespacesql> drop tablespace app_data including contents;8.enableing automatic extension of data filessql> alter tablespace app_data add datafile'c:\oracle\oradata\app_data01.dbf'size 200msql> autoextend on next 10m maxsize 500m;9.change the size fo data files manuallysql> alter database datafile 'c:\oracle\oradata\app_data.dbf'resize 200m;10.Moving data files: alter tablespacesql> alter tablespace app_data rename datafile'c:\oracle\oradata\app_data.dbf'sql> to 'c:\oracle\app_data.dbf';11.moving data files:alter databasesql> alter database rename file 'c:\oracle\oradata\app_data.dbf'sql> to 'c:\oracle\app_data.dbf';第三章:表1.create a tablesql> create table table_name (column datatype,column datatype]....) sql> tablespace tablespace_name [pctfree integer] [pctused integer] sql> [initrans integer] [maxtrans integer]sql> storage(initial 200k next 200k pctincrease 0 maxextents 50)sql> [logging|nologging] [cache|nocache]2.copy an existing tablesql> create table table_name [logging|nologging] as subquery3.create temporary tablesql> create global temporary table xay_temp as select * from xay;on commit preserve rows/on commit delete rows4.pctfree = (average row size - initial row size) *100 /average row size pctused = 100-pctfree- (average row size*100/available data space)5.change storage and block utilization parametersql> alter table table_name pctfree=30 pctused=50 storage(next 500k sql> minextents 2 maxextents 100);6.manually allocating extentssql> alter table table_name allocate extent(size 500k datafile'c:/oracle/data.dbf');7.move tablespacesql> alter table employee move tablespace users;8.deallocate of unused spacesql> alter table table_name deallocate unused [keep integer]9.truncate a tablesql> truncate table table_name;10.drop a tablesql> drop table table_name [cascade constraints];11.drop a columnsql> alter table table_name drop column comments cascade constraints checkpoint 1000;alter table table_name drop columns continue;12.mark a column as unusedsql> alter table table_name set unused column comments cascade constraints;alter table table_name drop unused columns checkpoint 1000;alter table orders drop columns continue checkpoint 1000data_dictionary : dba_unused_col_tabs第四章:索引1.creating function-based indexessql> create index summit.item_quantity onsummit.item(quantity-quantity_shipped);2.create a B-tree indexsql> create [unique] index index_name on table_name(column,.. asc/desc) tablespacesql> tablespace_name [pctfree integer] [initrans integer] [maxtrans integer]sql> [logging | nologging] [nosort] storage(initial 200k next 200k pctincrease 0sql> maxextents 50);3.pctfree(index)=(maximum number of rows-initial number ofrows)*100/maximum number of rows4.creating reverse key indexessql> create unique index xay_id on xay(a) reverse pctfree 30storage(initial 200ksql> next 200k pctincrease 0 maxextents 50) tablespace indx;5.create bitmap indexsql> create bitmap index xay_id on xay(a) pctfree 30 storage( initial 200k next 200ksql> pctincrease 0 maxextents 50) tablespace indx;6.change storage parameter of indexsql> alter index xay_id storage (next 400k maxextents 100);7.allocating index spacesql> alter index xay_id allocate extent(size 200k datafile'c:/oracle/index.dbf');8.alter index xay_id deallocate unused;第五章:约束1.define constraints as immediate or deferredsql> alter session set constraint[s] = immediate/deferred/default;set constraint[s] constraint_name/all immediate/deferred;2. sql> drop table table_name cascade constraintssql> drop tablespace tablespace_name including contents cascade constraints3. define constraints while create a tablesql> create table xay(id number(7) constraint xay_id primary key deferrablesql> using index storage(initial 100k next 100k) tablespace indx);primary key/unique/references table(column)/check4.enable constraintssql> alter table xay enable novalidate constraint xay_id;5.enable constraintssql> alter table xay enable validate constraint xay_id;第六章:LOAD数据1.loading data using direct_load insertsql> insert /*+append */ into emp nologgingsql> select * from emp_old;2.parallel direct-load insertsql> alter session enable parallel dml;sql> insert /*+parallel(emp,2) */ into emp nologgingsql> select * from emp_old;ing sql*loadersql> sqlldr scott/tiger \sql> control = ulcase6.ctl \sql> log = ulcase6.log direct=true第七章:reorganizing dataing expoty$exp scott/tiger tables(dept,emp) file=c:\emp.dmp log=exp.log compress=n direct=ying import$imp scott/tiger tables(dept,emp) file=emp.dmp log=imp.log ignore=y3.transporting a tablespacesql>alter tablespace sales_ts read only;$exp sys/.. file=xay.dmp transport_tablespace=y tablespace=sales_tstriggers=n constraints=n$copy datafile$imp sys/.. file=xay.dmp transport_tablespace=ydatafiles=(/disk1/sles01.dbf,/disk2/sles02.dbf)sql> alter tablespace sales_ts read write;4.checking transport setsql> DBMS_tts.transport_set_check(ts_list=>'sales_ts' ..,incl_constraints=>true);在表transport_set_violations 中查看sql> dbms_tts.isselfcontained 为true 是,表示自包含第八章: managing password security and resources1.controlling account lock and passwordsql> alter user juncky identified by oracle account unlock;er_provided password functionsql> function_name(userid in varchar2(30),password in varchar2(30),old_password in varchar2(30)) return boolean3.create a profile : password settingsql> create profile grace_5 limit failed_login_attempts 3sql> password_lock_time unlimited password_life_time 30sql>password_reuse_time 30 password_verify_function verify_function sql> password_grace_time 5;4.altering a profilesql> alter profile default failed_login_attempts 3sql> password_life_time 60 password_grace_time 10;5.drop a profilesql> drop profile grace_5 [cascade];6.create a profile : resource limitsql> create profile developer_prof limit sessions_per_user 2sql> cpu_per_session 10000 idle_time 60 connect_time 480;7. view => resource_cost : alter resource costdba_Users,dba_profiles8. enable resource limitssql> alter system set resource_limit=true;第九章:Managing users1.create a user: database authenticationsql> create user juncky identified by oracle default tablespace users sql> temporary tablespace temp quota 10m on data password expire sql> [account lock|unlock] [profile profilename|default];2.change user quota on tablespacesql> alter user juncky quota 0 on users;3.drop a usersql> drop user juncky [cascade];4. monitor userview: dba_users , dba_ts_quotas第十章:managing privileges1.system privileges: view =>system_privilege_map ,dba_sys_privs,session_privs2.grant system privilegesql> grant create session,create table to managers;sql> grant create session to scott with admin option;with admin option can grant or revoke privilege from any user or role;3.sysdba and sysoper privileges:sysoper: startup,shutdown,alter database open|mount,alter database backup controlfile,alter tablespace begin/end backup,recover databasealter database archivelog,restricted sessionsysdba: sysoper privileges with admin option,create database,recover database until4.password file members: view:=> v$pwfile_users5.O7_dictionary_accessibility =true restriction access to view or tables in other schema6.revoke system privilegesql> revoke create table from karen;sql> revoke create session from scott;7.grant object privilegesql> grant execute on dbms_pipe to public;sql> grant update(first_name,salary) on employee to karen with grant option;8.display object privilege : view => dba_tab_privs, dba_col_privs9.revoke object privilegesql> revoke execute on dbms_pipe from scott [cascade constraints];10.audit record view :=> sys.aud$11. protecting the audit trailsql> audit delete on sys.aud$ by access;12.statement auditingsql> audit user;13.privilege auditingsql> audit select any table by summit by access;14.schema object auditingsql> audit lock on summit.employee by access whenever successful;15.view audit option : view=>all_def_audit_opts,dba_stmt_audit_opts,dba_priv_audit_opts,dba_obj_audit_opts16.view audit result: view=>dba_audit_trail,dba_audit_exists,dba_audit_object,dba_audit_session,dba_audit_statement第十一章: manager role1.create rolessql> create role sales_clerk;sql> create role hr_clerk identified by bonus;sql> create role hr_manager identified externally;2.modify rolesql> alter role sales_clerk identified by commission; sql> alter role hr_clerk identified externally;sql> alter role hr_manager not identified;3.assigning rolessql> grant sales_clerk to scott;sql> grant hr_clerk to hr_manager;sql> grant hr_manager to scott with admin option;4.establish default rolesql> alter user scott default role hr_clerk,sales_clerk; sql> alter user scott default role all;sql> alter user scott default role all except hr_clerk; sql> alter user scott default role none;5.enable and disable rolessql> set role hr_clerk;sql> set role sales_clerk identified by commission; sql> set role all except sales_clerk;sql> set role none;6.remove role from usersql> revoke sales_clerk from scott;sql> revoke hr_manager from public;7.remove rolesql> drop role hr_manager;8.display role informationview: =>dba_roles,dba_role_privs,role_role_privs,dba_sys_privs,role_sys_privs,role_tab_privs,session_roles第十二章: BACKUP and RECOVERY1.v$sga,v$instance,v$process,v$bgprocess,v$database,v$datafile,v$sgasta t2. Rman need set dbwr_IO_slaves or backup_tape_IO_slaves andlarge_pool_size3. Monitoring Parallel Rollback> v$fast_start_servers , v$fast_start_transactions4.perform a closed database backup (noarchivelog)> shutdown immediate> cp files /backup/> startup5.restore to a different location> connect system/manager as sysdba> startup mount> alter database rename file '/disk1/../user.dbf'to'/disk2/../user.dbf';> alter database open;6.recover syntax--recover a mounted database>recover database;>recover datafile '/disk1/data/df2.dbf';>alter database recover database;--recover an opened database>recover tablespace user_data;>recover datafile 2;>alter database recover datafile 2;7.how to apply redo log files automatically>set autorecovery on>recover automatic datafile 4;plete recovery:--method 1(mounted databae)>copy c:\backup\user.dbf c:\oradata\user.dbf>startup mount>recover datafile 'c:\oradata\user.dbf;>alter database open;--method 2(opened database,initially opened,not system or rollback datafile)>copy c:\backup\user.dbf c:\oradata\user.dbf (alter tablespace offline)>recover datafile 'c:\oradata\user.dbf' or>recover tablespace user_data;>alter database datafile 'c:\oradata\user.dbf' online or>alter tablespace user_data online;--method 3(opened database,initially closed not system or rollback datafile)>startup mount>alter database datafile 'c:\oradata\user.dbf' offline;>alter database open>copy c:\backup\user.dbf d:\oradata\user.dbf>alter database rename file 'c:\oradata\user.dbf'to'd:\oradata\user.dbf'>recover datafile 'e:\oradata\user.dbf' or recover tablespace user_data; >alter tablespace user_data online;--method 4(loss of data file with no backup and have all archive log) >alter tablespace user_data offline immediate;>alter database create datafile 'd:\oradata\user.dbf'as'c:\oradata\user.dbf''>recover tablespace user_data;>alter tablespace user_data online9.perform an open database backup> alter tablespace user_data begin backup;> copy files /backup/> alter database datafile '/c:/../data.dbf' end backup;> alter system switch logfile;10.backup a control file> alter database backup controlfile to 'control1.bkp';> alter database backup controlfile to trace;11.recovery (noarchivelog mode)> shutdown abort> cp files> startup12.recovery of file in backup mode>alter database datafile 2 end backup;13.clearing redo log file>alter database clear unarchived logfile group 1;>alter database clear unarchived logfile group 1 unrecoverable datafile;14.redo log recovery>alter database add logfile group 3 'c:\oradata\redo03.log'size 1000k; >alter database drop logfile group 1;>alter database open;or >cp c:\oradata\redo02.log' c:\oradata\redo01.log>alter database clear logfile 'c:\oradata\log01.log';。

Oracle 11g数据库治理与开发技术SQL*Plus的要紧功能、启动SQL*Plus连接数据库使用SQL*Plus的编辑功能SQL语句、PL/SQL块与SQL*Plus命令的区不编辑命令、保存命令、加入注释、运行命令编写交互命令、使用绑定变量、跟踪语句使用SQL*Plus格式化查询结果格式化列定义页与报告的标题和维、存储和打印结果PL/SQL基础PL/SQL概述PL/SQL语言、PL/SQL的特点、PL/SQL的开发和运行环境运行PL/SQL程序PL/SQL编程差不多语言块、字符集和语法注释、数据类型和类型转换、变量和常量、表达式和运算符、流程操纵1. 过程和函数2. 过程、函数错误处理预定义异常、用户定义异常PL/SQL高级应用包包头、包体、重载、包的初始化、Oracle内置包集合ndex-by表、嵌套表、可变数组、集合的属性和方法PL/SQL游标游标创建、使用游标FOR循环、使用游标变量、游标变量实例、使用游标表达式、Oracle 11g中PL/SQL的新特性Oracle数据库结构Oracle体系结构差不多术语、体系结构图解、表空间与数据文件、临时表空间与临时文件、Oracle存储结构介绍、操纵文件、日志文件服务器参数文件、密码文件/跟踪文件/告警日志Oracle服务器结构1. Oracle服务器与Oracle实例、物理结构与逻辑结构的关系2. 系统全局区(SGA、后台进程、程序全局区PGA数据字典Oracle数据字典构成Oracle常用数据字典、Oracle常用动态性能视图治理操纵文件操纵文件概述操纵文件的内容、操纵文件的大小、操纵文件更新、可复用区与不可复用区操纵文件的多路复用使用init.ora 多路复用操纵文件、使用SPFILE多路复用操纵文件、添加更多操纵文件副本的步骤1. 查询操纵文件信息2. 操纵文件的创建步骤3. 维护操纵文件治理日志文件治理重做日志文件、日志文件组/日志切换/日志归档了解检查点、查询、新建、删除日志文件治理表空间和数据文件模式对象治理备份与恢复方法Oracle 11g的备份和恢复特性使用RMA工具RMA简介、RMA资料档案库/恢复目录/操纵文件、创建恢复目录RMAN与数据库的连接连接到目标数据库、连接到恢复目录注册数据库注册目标数据库、实例演示通道分配通道概述、RUN命令介绍、自动通道配置、手动通道配置、显示通道配置参数、设置通道操纵参数使用BACKU命令生成备份集备份集与备份片、BACKU命令语法、备份文件的存储格式、BACKU备份实例、B丿的冷备份与热备份Oracle 11g的备份和恢复特性使用COPY! BACK AS COP命令COPY命令语法、COP溶份实例、BACKUP AS COP命令备份压缩备份、完全备份与递增备份、查看备份信息使用RMAN恢复数据库RESTOR命令、RECOVE命令、实例解析Oracle 闪回技术(Flashback )使用OEM向导备份和恢复数据库逻辑备份/数据导入导出数据泵技术概述创建目录对象使用Data Pump导出数据Data Pump导出讲明、基于命令行数据泵导出实例、基于DBMS_DATAPl数据泵导出实例使用Data Pump导入数据Data Pump导入讲明、基于命令行数据泵导入实例、基于DBMS_DATAPl数据泵导入实例监控Data Pump作业进度EXP/IMP导出导入数据EXP/IMP概要讲明、EXP导出实例、IMP导入实例Oracle SQL语句优化一般的SQL技巧建议不用“ *”来代替所有列名、用TRUNCAT代替DELETE在确保完整性的情况下多用COMMI语句、尽量减少表的查询次数、用NOT EXISTS替代NOT IN 用EXISTS替代N、用EXISTS替代DISTINCT表的连接方法选择FROM!的顺序、驱动表的选择、WHER子句的连接顺序有效使用索引何时使用索弓I、索引列和表达式的选择、选择复合索引主列、幸免对大表的全表扫描、监视索引是否被使用Oracle的优化器与执行打算优化器概念、运行EXPLAIN PLAN Oracle 11g中SQL执行打算的治理Oracle 11g中的执行打算治理执行打算治理的工作原理、执行打算治理的测试、执行打算治理实例测试。

数据库结构化和非结构化介绍在信息时代,数据的处理和管理成为了一个关键问题。
数据库技术应运而生,成为了数据管理的核心工具。
在数据库中,数据可以以结构化和非结构化的方式进行存储和管理。
本文将深入探讨数据库结构化和非结构化的概念、特点以及使用场景。
结构化数据结构化数据是指按照预定义模式或模型进行组织和存储的数据。
这种数据存在于二维表格(如关系型数据库)中,每一行代表一个实例,每一列代表一个属性。
结构化数据具有以下特点:1.明确的数据模型:结构化数据在存储前需要定义数据模型,确定数据的类型、字段以及关系。
2.数据一致性:由于数据模型的限制,结构化数据的一致性较高。
数据类型、字段格式等都经过严格控制。
3.高度关联:结构化数据中的表格之间可以通过主键-外键的关系进行关联,使得数据之间存在关系,方便查询和分析。
结构化数据常见的存储形式有关系型数据库(如MySQL、Oracle)等。
由于结构化数据的特点,其适用于事务处理、报表查询、关系分析等场景。
例如,银行对于客户的账户信息、交易记录等可以使用结构化数据进行存储和管理,方便进行账目核对和风险评估。
非结构化数据非结构化数据是指没有明确数据模型的数据,不具备固定形式的数据。
这种数据通常不适合在结构化数据库中进行存储,而是以文本、图像、音频、视频等形式存在。
非结构化数据具有以下特点:1.多样化的格式:非结构化数据的格式多种多样,包括但不限于文本、图像、音频、视频等。
2.缺乏一致性:由于缺乏统一的数据模型,非结构化数据的一致性较差。
同一类数据的结构可能不同,难以进行统一的数据处理。
3.大数据量:非结构化数据往往具有大量的数据,难以通过传统的方法进行处理和分析。
非结构化数据的存储方式多种多样,例如文件系统、NoSQL数据库等。
非结构化数据适用于需要处理多媒体数据、文本挖掘、图像识别等场景。
例如,社交媒体平台中的用户发布的文本、图片等数据可以使用非结构化数据进行存储和分析,方便进行情感分析和个性化推荐。

oracle11g dataguard 完全手册一、前言:网络上关于dataguard的配置文章很多,但是很多打着oracle11g的文章实际都是只能在9 10 上运行,比如FAL_CLIENT在11g中已经废弃,但是现在网络上的文章都是没有标注这一点。
而且对于具体含义语焉不详对于新手只能知其然而不知其所以然。
这篇文章我就想让像我这样的人对于dataguard配置不仅仅知道怎么配置,还要知道为什么需要这样配置,这样的效果才是最好的。
这篇文章不仅仅是记录如何配置,还介绍了为什么是这样,以及注意要点,我希望这个文章可以作为进行dataguard配置的一个参考手册。
二、前提1.主库是归档模式:如果我们不清楚为什么是归档模式,那我们就应该也不会清楚dataguard是用来做什么的。
透过很多修饰的官方语言,我们需要明确DG(dataguard简称,后同)实际上的作用就是用来高可用。
而实现原理就是从主库获取数据到从库,在主库发生异常的时候,从库接管主库,完成身份的变化。
可以一个主库,最多9个从库。
同时分为逻辑standby和物理standby这里我们讨论的是物理standby.一旦创建并配置成standby 后,dg 负责传输primary数据库redo data 到standby 数据库,standby 数据库通过应用接收到的redo data 保持与primary 数据库的事务一致。
这下清楚了吧,需要保证主从库一致,需要传输archive log和redo log到从库,如果不是归档模式无法保证主从库的数据一致。
2.从库只需要安装数据库软件,数据从主库传输后完成。
3.很多人说11g有了active dataguard(ADG),逻辑standby 实际上已经没什么用处了。
4.主从库硬件最好一致。
oracle数据库版本需要一致。
(1)内存检查项:# grep MemTotal /proc/meminfo交换分区检查项:如果内存在1-2G,swap是1.5倍;2-16G,1倍;超过16G,设置为16G即可。

非结构化数据来源极为广泛,在省惩防体系综合信息平台数据环境中,包括文档、电子表格、演示文稿、电子邮件、音频和视频文件、即时消息、扫描的文档等。
由于文件系统操作简便性能较高,因此多采用文件系统来存储非结构化数据,而将关系型数据存储在数据库中。
然而在实际业务需求中,两种数据类型往往相伴而生,例如档案管理系统。
两种数据类型的分开管理损害了安全性、健壮性以及可管理性,具体存在以下弊端:互相孤立的安全审计模型;数据的更改无法保持原子性、备份和恢复需要分别进行;很难实现涉及到关系型数据和文件数据的综合查询;空间管理复杂;需要不同的接口和协议。
为了消除文件系统的弊端,在关系数据库中多采用二进制大对象(LOB)实现存储非结构化数据,然而LOB一直存在着性能瓶颈。
将非结构化数据存储在数据库中后,管理和检索非结构化数据(例如多媒体应用程序)需要额外的处理能力和内存才能获得与文件系统等同的性能。
综合以上原因,推荐使用Oracle Database中的SecureFile Lobs来存储非结构化数据。
自Oracle Database 11g开始,增加了SecureFile Lobs方式来解决非结构化数据存储,SecureFile支持检索非结构化数据,使得访问数据库内的文件与本地文件系统中的文件一样快,甚至超过了后者,同时还保持了与数据库中数据的事务一致性。
SecureFiles 是一个重要的新体系结构,它既具备所有最先进文件系统功能,又具备高级数据库功能。
其特性包括全新的磁盘格式、空间和内存管理技术,它可显著提升 LOB 性能并优化存储。
(1)提高了读写性能:SecureFiles 在数据库处理文件数据的方式上采用了全新的范例,对于基本查询和插入操作可提供类似文件系统的性能。
经过 SecureFiles 优化的算法速度最快可达LOB的10倍。
(2)统一的事务管理:非结构化数据可以是数据库事务的一部分,因此,免去了应用程序在保证原子性、读取一致性以及其他备份和恢复过程的复杂性。

Oracle 11g 日常维护手册目录第1章文档说明 (5)第2章CRS的管理 (5)2.1 RAC状态检查 (5)检查守护进程状态 (5)检查资源状态 (5)2.2 手工启动与关闭RAC (6)2.3 OCR的管理 (6)2.4 VOTING DISK的管理 (8)2.5 CSS管理 (9)2.6 管理工具SRVCTL (9)管理实例 (9)管理监听程序 (9)管理ASM (10)管理service (10)2.7 修改RAC的IP及VIP (11)修改外网IP及心跳IP (11)修改VIP (11)查看与删除IP (12)第3章ASM的管理 (13)3.1 管理DG (13)建立与扩充disk group (13)mount与unmount的吩咐 (14)删除disk group (14)增加DISK的total_mb (14)DG的属性-AU大小 (14)DG的属性-离线删除时间 (15)DG的属性-兼容版本 (15)向ASM中添加disk的完整步骤 (16)3.2 ASMCMD (17)ASMCMD常用吩咐 (17)复制ASM文件 (18)吩咐lsdg (18)元数据备份与复原 (18)3.3 ASM磁盘头信息备份与复原 (19)3.4 ASM常用视图 (20)视图V$ASM_DISKGROUP (20)视图V$ASM_DISK (21)3.5 常用方法 (22)如何确定ASM实例的编号 (22)查询DG-RAW-磁盘的对应关系 (22)第4章数据库管理 (24)4.1 参数文件管理 (24)4.2 表空间管理 (25)表空间自动扩张 (25)表空间更名 (26)表空间的数据文件更名 (26)缺省表空间 (26)表空间删除 (27)UNDO表空间 (27)TEMP表空间 (27)4.3 重做日志文件管理 (27)增加REDO日志组 (27)删除日志组 (28)日志切换 (28)日志清理 (28)重做日志切换次数查询 (28)4.4 归档模式 (29)单实例数据库修改为归档模式的方法 (29)RAC数据库修改为归档模式的方法 (29)归档路径 (30)4.5 重建限制文件 (31)4.6 内存参数管理 (32)Oracle内存管理发展阶段 (32)自动内存管理AMM (32)自动共享内存管理ASMM (33)自动PGA管理 (33)4.7 其他管理内容 (33)数据库版本查看 (33)字符集 (34)创建密码文件 (34)关闭审计功能 (34)帐号管理 (34)profile管理 (35)第1章文档说明本文档描述了Oracle11g中常见的维护和管理方法,包括CRS、ASM、数据库等。
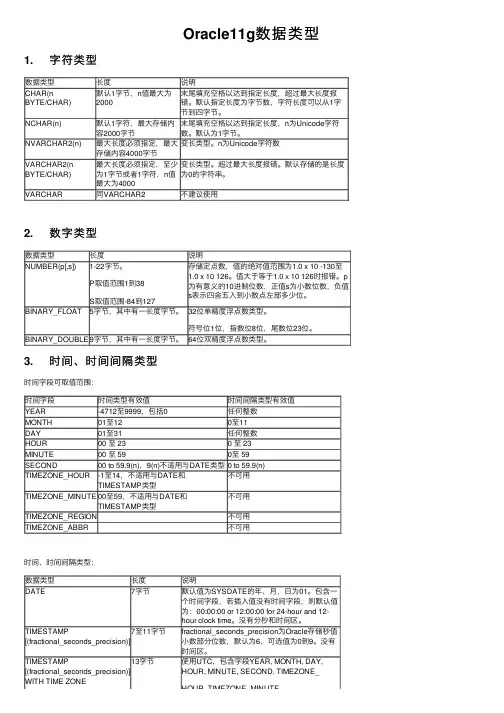
Oracle11g数据类型1. 字符类型数据类型长度说明CHAR(n BYTE/CHAR)默认1字节,n值最⼤为2000末尾填充空格以达到指定长度,超过最⼤长度报错。
默认指定长度为字节数,字符长度可以从1字节到四字节。
NCHAR(n)默认1字符,最⼤存储内容2000字节末尾填充空格以达到指定长度,n为Unicode字符数。
默认为1字节。
NVARCHAR2(n)最⼤长度必须指定,最⼤存储内容4000字节变长类型。
n为Unicode字符数VARCHAR2(n BYTE/CHAR)最⼤长度必须指定,⾄少为1字节或者1字符,n值最⼤为4000变长类型。
超过最⼤长度报错。
默认存储的是长度为0的字符串。
VARCHAR同VARCHAR2不建议使⽤2. 数字类型数据类型长度说明NUMBER(p[,s])1-22字节。
P取值范围1到38S取值范围-84到127存储定点数,值的绝对值范围为1.0 x 10 -130⾄1.0 x 10 126。
值⼤于等于1.0 x 10 126时报错。
p 为有意义的10进制位数,正值s为⼩数位数,负值s表⽰四舍五⼊到⼩数点左部多少位。
BINARY_FLOAT5字节,其中有⼀长度字节。
32位单精度浮点数类型。
符号位1位,指数位8位,尾数位23位。
BINARY_DOUBLE9字节,其中有⼀长度字节。
64位双精度浮点数类型。
3. 时间、时间间隔类型时间字段可取值范围:时间字段时间类型有效值时间间隔类型有效值YEAR-4712⾄9999,包括0任何整数MONTH01⾄120⾄11DAY01⾄31任何整数HOUR00 ⾄ 230 ⾄ 23MINUTE00 ⾄ 590⾄ 59SECOND00 to 59.9(n),9(n)不适⽤与DATE类型0 to 59.9(n)TIMEZONE_HOUR-1⾄14,不适⽤与DATE和TIMESTAMP类型不可⽤TIMEZONE_MINUTE00⾄59,不适⽤与DATE和TIMESTAMP类型不可⽤TIMEZONE_REGION不可⽤TIMEZONE_ABBR不可⽤时间、时间间隔类型:数据类型长度说明DATE7字节默认值为SYSDATE的年、⽉,⽇为01。
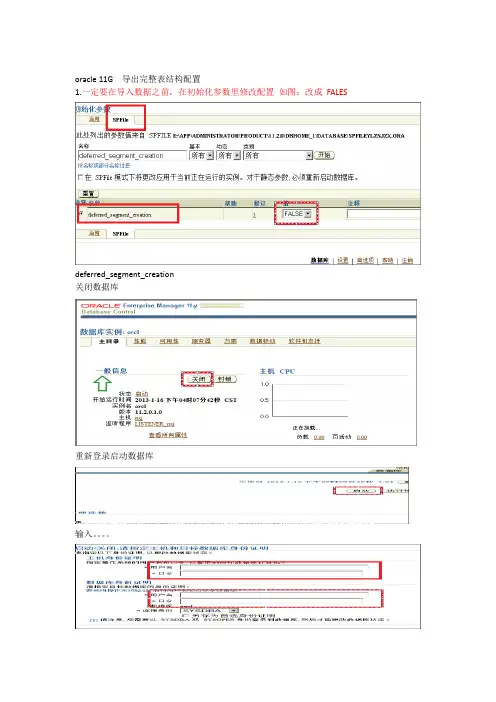
oracle 11G 导出完整表结构配置1.一定要在导入数据之前,在初始化参数里修改配置如图:改成FALESdeferred_segment_creation关闭数据库重新登录启动数据库输入。
在Oracle 11g里,默认空表不占空间,exp无法导出,因为11g里新加个参数deferred_segment_creation,默认为true,也就是延迟创建段空间。
在sys用户下,可以通过命令:alter system set deferred_segment_creation=false;调整这个参数的值,之后,创建的空表会立即分配空间,再通过exp就可以导出空表了。
但是之前的表仍然不占空间,可以通过sql生成批量命令:select 'alter table ' || table_name || ' allocate extent(size 64k);' sql_text,table_name,tablespace_namefrom user_tableswhere table_name not in(select segment_name from user_segments where segment_type = 'TABLE');把生成的命令执行一下,就可以通过exp导出了进入sqlplus 状态C:\Documents and Settings\Administrator>sqlplus "/as sysdba"关闭数据库SQL>shutdown immediate;启动数据库SQL>startup mount;开启数据库SQL> alter database open;。

oracle11gimp用法Oracle 11g IMP(Import)用法指南Oracle 11g是一种强大的关系数据库管理系统,它提供了多种工具和功能,其中之一是IMP(Import)工具,它用于将先前导出的数据和对象导入到Oracle数据库中。
本文将介绍Oracle 11g IMP工具的用法,帮助您使用它进行数据导入。
首先,确保您已经安装了Oracle 11g数据库,并具备正确的权限以执行导入操作。
使用IMP工具进行数据导入的基本语法如下:```imp username/password@database file=<导入文件路径> full=y```其中,`username/password@database`是您的数据库登录凭据,`file=<导入文件路径>`是导入文件的路径和名称,`full=y`表示导入所有数据和对象。
下面是一些常用的IMP工具参数:1. FROMUSER和TOUSER:用于指定要导入数据的源用户和目标用户。
例如:```imp username/password@database fromuser=<源用户> touser=<目标用户>file=<导入文件路径> full=y```2. TABLES:可以通过指定TABLES参数来限制只导入特定的表。
例如:```imp username/password@database tables=(table1, table2) file=<导入文件路径> full=y```3. IGNORE:用于指定在导入过程中遇到重复记录时的操作。
可以选择忽略(ignore)或替换(replace)重复记录。
例如:```imp username/password@database ignore=y file=<导入文件路径> full=y```4. INDEXES:可以使用INDEXES参数来控制是否导入表的索引。
高效处理结构化和非结构化数据的技巧和方法高效处理结构化和非结构化数据是数据分析和数据科学领域的关键技能之一。
在大数据时代,我们面临着数量庞大、多样化的数据,包括结构化数据(如数据库、电子表格等)和非结构化数据(如文本、图像、音频、视频等)。
有效地处理这些数据,提取有价值的信息和洞察力,对于业务决策和创新至关重要。
下面是一些高效处理结构化和非结构化数据的技巧和方法。
一、处理结构化数据的技巧和方法:1.数据清洗和预处理:结构化数据通常以表格形式存在,但往往包含缺失值、错误值、异常值等问题。
进行数据清洗和预处理是确保数据质量的关键步骤。
这包括处理缺失值、去除重复值、纠正错误值和异常值等。
2.数据合并和连接:在实际应用中,有时需要将多个表格中的数据合并或连接起来以获得更全面的信息。
这可以通过使用关系型数据库的JOIN操作或者数据处理工具(如Pandas)中的合并函数来实现。
3.数据转换和重塑:有时候,结构化数据需要转换为与分析目的相适应的形式。
这可能包括将数据从长格式转换为宽格式,进行数据透视操作,或者进行数据归一化处理等。
4.特征提取和构建:结构化数据中存在很多有用的信息,但有时需要将其提取出来以支持进一步的分析。
这包括选择和构建合适的特征变量,以支持模型构建和预测。
5.数据可视化:通过可视化结构化数据,可以更直观地理解数据的特征和模式。
这有助于发现数据中的隐藏信息和趋势,以及支持业务决策。
二、处理非结构化数据的技巧和方法:1.文本处理和分析:非结构化数据中常见的类型是文本数据。
对于文本数据的处理,可以采用自然语言处理(NLP)技术,如分词、词干提取、词频统计、情感分析等。
2.图像和视频处理:对于图像和视频数据,可以使用计算机视觉算法进行特征提取和图像分类。
例如,使用卷积神经网络(CNN)可以实现图像分类和目标检测等任务。
3.音频处理:音频数据的处理可以包括音频信号处理、音频识别和语音情感分析等。
这些技术可以应用于语音识别、语音合成、音乐推荐等领域。
安装Oracle前linux系统参数的配置检查下列包是否安装,如果未安装则要先安装。
# rpm -qa | grep make gcc glibc 等等binutils-2.17.50.0.6-2.el5compat-libstdc++-33-3.2.3-61elfutils-libelf-0.125-3.el5elfutils-libelf-devel-0.125glibc-2.5-12glibc-common-2.5-12glibc-devel-2.5-12gcc-4.1.1-52gcc-c++-4.1.1-52libaio-0.3.106libaio-devel-0.3.106libgcc-4.1.1-52libstdc++-4.1.1libstdc++-devel-4.1.1-52.e15make-3.81-1.1sysstat-7.0.0unixODBC-2.2.11unixODBC-devel-2.2.11在安装Oracle 11g前,先关闭系统防火墙,禁用selinux;需要手工更改系统的内核参数以及创建oracle用户和用户组,具体操作步骤如下所述。
(1)创建oracle用户和oinstall、dba用户组命令如下所示。
# /usr/sbin/groupadd oinstall //创建用户组oinstall# /usr/sbin/groupadd dba //创建用户组dba# /usr/sbin/useradd -m -g oinstall -G dba oracle //创建用户oracle# id oracle //查看用户oracle的属性uid=512(oracle) gid=1005(oinstall) groups=1005(oinstall),1006(dba)(2)设置oracle用户的口令,命令如下所示。
# passwd oracle //设置oracle用户的口令Changing password for user oracle.New UNIX password:BAD PASSWORD: it is too simplistic/systematicRetype new UNIX password:passwd: all authentication tokens updated successfully.//口令更改成功(3)创建Oracle的安装目录。
Oracle11g数据库基础教程参考答案第1章Oracle 11g数据库安装与配置1.简答题(1)企业版数据库服务器包含所有的数据库组件,主要针对高端的应用环境,适用于安全性和性能要求较高的联机事务处理(OLTP)、查询密集型的数据仓库和要求较高的Internet应用程序:标准版数据库服务器提供大部分核心的数据库功能和特性,适合于工作组或部门级的应用程序:个人版数据库服务器只提供基本数据库管理功能和特性,适合单用户的开发环境,为用户提供开发测试平台。
(2)常用数据库类型包括事务处理类、数据仓库类以通用类型。
其中事务处理类型主要针对具有大量并发用户连接,并且用户主要执行简单事务处理的应用环境。
事务处理数据库的典型应用有银行系统数据库、Internet电子商务数据库、证券交易系统数据库等。
对于需要较高的可用性和事务处理性能、存在大量用户并行访问相同数据以及需要较高恢复性能的数据库环境,事务处理类型的配置可以提供最佳性能;数据仓库类型的数据库主要针对有大量的对某个主题进行复杂查询的应用环境。
数据仓库的典型应用有客户订单研究、支持呼叫、销售预测、采购模式以及其他战略性业务问题的历史数据研究。
对于需要对大量数据进行快速访问,以及复杂查询的数据库环境,数据仓库类型配置是最佳选择;通用类型配置的数据库是事务处理数据库与数据仓库配置的折衷方案。
既可以支持大量并发用户的事务处理,又可以快速对大量历史数据进行复杂的数据扫描和处理。
(3)数据库名可以由字母、数字、下划线(_)、#和美元符号($)组成,且必须以字母开头,长度不超过30个字符。
在单机环境中,可以不设置域名,域名长度不能超过128个字符。
Oracle服务标识符(SID)是一个Oracle实例的唯一名称标识,长度不能超过12个字符。
(4)● OracleServiceORCL:数据库服务(数据库实例),是Oracle核心服务,是数据库启动的基础,只有该服务启动,Oracle数据库才能正常启动。
oracle 11g数据库参数及指标Oracle 11g数据库参数及指标Oracle 11g是一种功能强大的关系型数据库管理系统,通过合理设置数据库参数和监控关键指标,可以提高数据库的性能和稳定性。
在本文中,我们将讨论一些重要的Oracle 11g数据库参数及指标,并探讨它们的作用和优化方法。
数据库参数是控制数据库行为的设置,它们可以影响数据库的性能、安全性和可用性。
在Oracle 11g中,有许多重要的数据库参数需要重点关注。
其中,一些关键的参数包括SGA大小、PGA大小、日志文件大小、并行处理器数量等。
SGA(System Global Area)是Oracle数据库中的一个重要参数,它包含了数据库实例运行时所需要的共享内存结构。
通过适当调整SGA的大小,可以提高数据库的整体性能。
通常情况下,应根据实际需求和硬件配置来动态调整SGA的大小,以达到最佳性能。
PGA(Program Global Area)是每个数据库会话独立使用的内存区域,它包含了会话私有的内存结构。
合理设置PGA的大小可以有效控制数据库会话的内存消耗,避免内存不足导致的性能问题。
日志文件大小也是一个需要重点关注的参数。
日志文件用于记录数据库中的变更操作,对数据库恢复和故障恢复非常重要。
如果日志文件过小,可能会导致频繁的日志切换和性能下降;如果日志文件过大,可能会浪费存储空间。
因此,应根据数据库的写入速度和变更频率来合理设置日志文件大小。
除了数据库参数外,监控关键指标也是提高数据库性能的重要手段。
一些重要的数据库指标包括IOPS(每秒输入/输出操作数)、查询响应时间、锁定等待时间等。
IOPS是衡量存储性能的重要指标,它代表了存储系统每秒能够处理的输入/输出操作数量。
通过监控IOPS,可以了解存储系统的性能瓶颈,并采取相应的优化措施,提高数据库的读写性能。
查询响应时间是衡量数据库性能的重要指标之一,它代表了数据库处理查询请求所需的时间。
Oracle Data Guard 实施与维护方案1.项目背景介绍在2台RedHat5.4上使用ORACLE 的DataGuard组件实现容灾。
设备配置(VMWare虚拟机环境)清单如下:2.Oracle DataGuard 介绍备用数据库(standby database)是ORACLE 推出的一种高可用性(HIGH AVAILABLE)数据库方案,在主节点与备用节点间通过日志同步来保证数据的同步,备用节点作为主节点的备份,可以实现快速切换与灾难性恢复。
●STANDBY DATABASE的类型:有两种类型的STANDBY:物理STANDBY和逻辑STANDBY两种类型的工作原理可通过如下图来说明:physical standby提供与主数据库完全一样的拷贝(块到块),数据库SCHEMA,包括索引都是一样的。
它是可以直接应用REDO实现同步的。
l ogical standby则不是这样,在logical standby中,逻辑信息是相同的,但物理组织和数据结构可以不同,它和主库保持同步的方法是将接收的REDO转换成SQL语句,然后在STANDBY上执行SQL语句。
逻辑STANDBY除灾难恢复外还有其它用途,比如用于用户进行查询和报表,但其数据库用户相关对象均需要有主键。
✧本次实施将选择物理STANDBY(physical standby)方式●对主库的保护模式可以有以下三种模式:–Maximum protection (最高保护)–Maximum availability (最高可用性)–Maximum performance (最高性能)✧基于项目应用的特征及需求,本项目比较适合采用Maximum availability (最高可用性)模式实施。
3.Dataguard 实施前提条件和注意事项:●灾备环境中的所有节点必须安装相同的操作系统,尽可能令详细补丁也保持相同。
●灾备环境中的所有节点必须安装完全相同版本的Oracle数据库软件,包括版本号和发布号,比如必须都是Oracle 11.2.0.1●主库必须处于归档(ARCHIVELOG)模式。
Oracle数据库11g产品家族简介介绍Oracle数据库11g家族,是一个对不同级别的业务,不同规模的组织都有量身定做产品,对不同IT需求都有解决方案的家族。
Oracle也提供数据库选件产品来加强Oracle数据库11g某些特殊的应用需求。
本文将概要的介绍这些功能和选件。
●Oracle数据库11g标准版一(SE1)是个空前强大,易用,性价比非常好的工作组级软件。
适合单节点,在最高容量两个处理器的服务器上使用。
●Oracle数据库11g标准版(SE)可以支持单机或者集群服务器,在最高容量4个处理器的单机或者总计4处理器的集群上使用。
购买了标准版,就已经内含了Oracle的RAC而无需额外付费。
●Oracle数据库11g企业版(EE)提供了有效,可靠,安全的数据管理功能以应对关键的企业业务和在线事务处理应用,复杂查询的数据仓库或者WEB2.0应用。
企业版就没有SOCKET限制,单机或者集群都可以使用●Oracle数据库11g个人版(PE)是为个人开发部署使用,它和Oracle标准版一,标准版,企业版功能上是全面兼容的。
●Oracle数据库11g express版(XE)是个入门级的精巧数据库。
主代码是基于企业级数据库的,用户可以在这个基础上自由开发,部署和发布。
该版数据库占的空间很小,非常容易管理。
XE版可以安装在任何主机上,也没有CPU限制。
但是XE版的用户数据只能存储4G,内存只能使用1G,每台主机上也只能使用1个CPU。
如果使用XE版的时间久了需要升级,我们也可以很轻松的将其升级到标准版或者企业版。
这四个版本的Oracle数据库11g使用的是相同的引擎架构,互相兼容。
在相同的操作系统环境下,也支持相同的应用开发工具,程序接口。
使用Oracle数据库11个产品,您可以先购买标准版一上手,随着您的业务发展,再轻松的升级到标准版。
随着设备的扩容业务的进一步发展,我们再按需应变的进一步升级到企业版。
使用 Oracle 数据库 11g 管理非结构化数据Oracle 白皮书2007 年 7 月使用 Oracle 数据库 11g管理非结构化数据引言多年来,Oracle 一直通过运算符合并智能数据类型和优化数据结构,以分析和操作XML 文档、多媒体内容、文本以及地理空间信息 Oracle 数据库。
由于有了 Oracle 数据库 11g,Oracle 再次在非结构化数据管理领域开辟出一片新天地:大幅提升了受数据库管理系统支持的原生非结构化数据的性能、安全性以及类型。
公司、企业以及其他机构使用的绝大部分信息都可归类为非结构化数据。
非结构化数据是计算机或人生成的信息,其中的数据并不一定遵循标准的数据结构(如模式定义规范的行和列),若没有人或计算机的翻译,则很难理解这些数据。
常见的非结构化数据有文档、多媒体内容、地图和地理信息、人造卫星和医学影像,还有 Web 内容,如 HTML。
根据数据的创建方式和使用方式的不同,非结构化数据的管理方法大不相同。
z大量数据分布于桌面办公系统(如文档、电子表格和演示文稿)、专门的工作站和设备(如地理空间分析系统和医学捕获和分析系统)上。
z政府、学术界和企业中数 TB 的文档存档和数字库。
z生命科学和制药研究中使用的影像数据银行和库。
z公共部门、国防、电信、公用事业和能源地理空间数据仓库应用程序。
z集成的运营系统,包括零售、保险、卫生保健、政府和公共安全系统中的业务或健康记录、位置和项目数据以及相关音频、视频和图像信息。
z学术、制药以及智能研究和发现等应用领域中使用的语义数据(三元组)。
自数据库管理系统引入后,数据库技术就一直用于解决管理大量非结构化数据时所遇到的特有问题。
通常通过“基于指针的”方法使用数据库对存储在文件中的文档、影像和媒体内容进行编目和引用。
为了在数据库表内存储非结构化数据,二进制大对象(或简称为 BLOB)作为容器使用已经数十年了。
除了简单的 BLOB 外,多年以来,Oracle 数据库一直通过运算符合并智能数据类型和优化数据结构,以分析和操作 XML 文档、多媒体内容、文本和地理空间信息。
由于有了 Oracle 数据库 11g,Oracle 再次在非结构化数据管理领域开辟出一片新天地:大幅提升了通过数据库管理系统原生支持的非结构化数据的性能、安全性以及类型。
企业选择在 Oracle 数据库管理系统中存储非结构化数据的原因有很多:z强健的调优和管理z简单的应用程序部署z高可用性z可伸缩的体系结构z安全性在 ORACLE 中管理非结构化数据的优势企业选择在 Oracle 数据库管理系统中存储非结构化数据的原因有很多:z强健的调优和管理:存储在数据库中的内容可直接与相关数据链接。
元数据和内容同步进行维护;并在事务控制之下进行管理。
数据库还提供强健的备份、恢复、物理调优和逻辑调优服务。
z简单的应用程序部署:Oracle 支持各种特定类型的内容,包括SQL 语言扩展、PL/SQL 和 JAVA API、Xpath 和 Xquery(在使用 XML 时),在大多数情况下还支持 JSP 标记库以及通过内置运算符执行常见或重要运算的算法。
z高可用性:Oracle 的最高可用性体系结构使得“零数据丢失”配置可应用于所有数据。
在出现故障时只需一个恢复过程,这不同于常见配置。
在常见配置中,属性信息存储在数据库中,数据库具有指向文件中的非结构化数据的指针。
z可伸缩的体系结构:在许多情况下,通过触发器、视图处理或表和数据库级参数进行索引编制、分区和执行操作的能力使得构建在数据库而非文件系统上的应用程序可以支持更大的数据集。
z安全性:Oracle 数据库可实现细粒度(行级和列级)安全性。
同一安全机制既可应用于结构化数据,也可应用于非结构化数据。
使用许多文件系统时,目录服务无法实现细粒度级的访问控制。
限制单个用户的访问可能无法实现,在许多系统中,允许用户访问目录中的任何内容意味着可以访问目录中的所有内容。
在许多情况下中,管理和检索非结构化 数据需要额外的处理能力和内存才能获得与 文件系统等同的性能。
有了 Oracle 数据库 11g SecureFiles 后,一切都不同了,新的高性能 LOB 支持检索非结构化数据,速度 可与等价的文件系统配置媲美,甚至超过了后者。
.打破“性能障碍”在没有 Oracle 数据库 11g 之前,要获得这些好处是要付出代价的。
将内容存储在数据库而不是传统文件系统中后,数据库特性(如域索引、分区和并行)可以改进地理空间应用程序以及查询和更新密集型 XML 应用程序的性能。
然而,在许多情况下(例如多媒体应用程序),管理和检索非结构化数据需要额外的处理能力和内存才能获得与文件系统等同的性能。
有了 Oracle 数据库 11g SecureFiles 后,一切都不同了,新的高性能LOB 支持检索非结构化数据,速度可与等价的文件系统配置媲美,甚至超过了后者。
SecureFiles 是一个重要的新体系结构,其特性包括全新的磁盘格式、空间和内存管理技术,它可显著提升 LOB 性能并优化存储。
Oracle SecureFilesSecureFiles 在数据库处理文件数据的方式上采用了全新的范例,对于基本查询和插入操作可提供类似文件系统的性能。
经过 SecureFiles 优化的算法速度最快可达旧 LOB 的 10 倍。
SecureFiles 可利用文件系统无法使用的多个高级 Oracle 数据库功能。
在 Oracle RAC 环境中,SecureFiles 提供的高级别可伸缩性远非文件系统可比。
通过 SecureFiles,用户可使用“联机表重新定义”轻松地从旧 LOB 进行移植,而不会影响到现有应用程序。
应用程序不必再处理多个接口来操作关系和相关文件数据。
使用SecureFiles 时,非结构化数据可以是数据库事务的一部分,因此,免去了应用程序保证原子性、读取一致性以及其他备份和恢复过程的复杂性。
SecureFiles 将透明数据加密 (TDE) 功能扩展到了 LOB 数据。
数据库支持表内所有 LOB 列的自动密钥管理,并可以对数据、备份和重做/撤消日志文件进行透明加密/解密。
应用程序无需更改即可通过 SecureFiles LOB 透明地利用 TDE 功能。
SecureFiles 支持下列加密算法:z3DES168:三重数据加密标准,密钥长度为 168 位。
z AES128:高级加密标准,密钥长度为 128 位。
z AES192:高级加密标准,密钥长度为 192 位。
(默认值)z AES256:高级加密标准,密钥长度为 256 位。
SecureFiles 中的存储优化与 SecureFiles 一起提供的还有高级文件系统特性,如重复消除(Deduplication) 和压缩。
重复消除可消除多个冗余的 SecureFiles 数据副本,并且对于应用程序是完全透明的。
Oracle 可自动检测到多个相同的SecureFiles 数据副本,并仅存储一个副本,从而节省了存储空间。
重复消除不仅简化了存储管理,而且显著提高了性能,尤其是对于复制操作。
用户可使用行业标准的压缩算法压缩 LOB 数据,从而大幅节省存储空间并显著提升性能。
Oracle 可自动判断 SecureFile 数据是否可进行压缩,或压缩是否有益。
SecureFiles 对整个服务器使用默认的 LOB 压缩算法,并提供有各种级别的压缩。
每种压缩级别都是压缩系数和速度之间的一种平衡。
企业可以根据存储和 CPU 使用限制选择最适合其需求的压缩级别。
SecureFiles 可自动进行压缩和解压缩,并且对于应用程序是完全透明的。
专用数据类型和数据结构与数据库管理系统包括数据类型、存储和索引结构以及运算符以对结构化数据进行有效查询和分析一样,它们在管理非结构化数据时也需要这些元素以实现增值。
Oracle 数据库 11g 的这些特性在 XML、文本、空间、语义以及多媒体和 DICOM 数据管理方面具有独一无二的优势。
Oracle XML DB 是一项高性能的原生XML 存储和检索技术,可在所有版本的Oracle 数据库上使用。
它完全支持所有关键的 XML 标准……使用户可以针对 XML 内容充分利用 SQL 语言以及针对关系数据充分利用 XML 范例。
Oracle XML DBXML 已为各行各业广泛采用。
在卫生保健、制造、金融服务、政府以及出版等领域中都可以找到基于 XML 的标准。
事实上,基于 XML 的标准(如 XBRL)的引入已使 XML 成为应用系统之间的信息交换机制。
因此,越来越多的人将 XML 用作了任务关键数据的持久性模型。
为了满足这个需要,Oracle 开发了 Oracle XML DB。
Oracle XML DB 是一项高性能的原生 XML 存储和检索技术,可在所有版本的 Oracle 数据库上使用。
它完全支持所有关键的 XML 标准,包括 XML、命名空间、DOM、Xquery、SQL/XML 和 XSLT。
Oracle XML DB 是第一个真正融合了关系/XML 功能的平台,从而使用户可以针对 XML 内容充分利用SQL 语言以及针对关系数据充分利用 XML 范例。
随着 Oracle 数据库 11g 的发布,Oracle 扩展了其行业领先的 XML 支持,进而确保了 Oracle 仍是存储、管理和查询所有可能的 XML 内容类型的最佳平台。
Oracle 数据库 11g 中的新特性改善了性能和可伸缩性,并对灵活性提供充分支持,从而使更多不同机构为 XML 数据模型所吸引。
Oracle 数据库 11g 为使用 Oracle XMLSchema 优化的 XML 存储的用户在诸多方面进行了改进。
z XML 模式的适当发展。
z XML 模式优化的存储的 Oracle 分区。
z优化存储模型的 XML 模式优化的智能默认值。
z模式优化的存储上的 XQuery 操作改进z支持通过 Oracle Streams 复制基于文本的 XMLType 存储。
为了以最优的方式处理非基于模式的 XML,Oracle 数据库 11g 引入了一个新的二进制 XML 存储选件以及新的 XML 索引编制功能,从而带来高性能的插入、更新和查询操作。
Oracle 的二进制 XML 格式允许针对XML 内容进行基于路径的高效索引编制。
该格式可以优化 XQuery 执行和碎片提取。
Oracle 数据库 11g 新的 XML 索引编制功能可以充分利用此格式。
Oracle 数据库 11g 通过直接将 Oracle PL/SQL 程序包、过程和函数公开为 web 服务简化了面向服务的轻型应用程序的实施。