隐马尔科夫模型学习总结.pdf
- 格式:pdf
- 大小:441.74 KB
- 文档页数:8



⼀⽂搞懂HMM(隐马尔可夫模型)什么是熵(Entropy)简单来说,熵是表⽰物质系统状态的⼀种度量,⽤它⽼表征系统的⽆序程度。
熵越⼤,系统越⽆序,意味着系统结构和运动的不确定和⽆规则;反之,,熵越⼩,系统越有序,意味着具有确定和有规则的运动状态。
熵的中⽂意思是热量被温度除的商。
负熵是物质系统有序化,组织化,复杂化状态的⼀种度量。
熵最早来原于物理学. 德国物理学家鲁道夫·克劳修斯⾸次提出熵的概念,⽤来表⽰任何⼀种能量在空间中分布的均匀程度,能量分布得越均匀,熵就越⼤。
1. ⼀滴墨⽔滴在清⽔中,部成了⼀杯淡蓝⾊溶液2. 热⽔晾在空⽓中,热量会传到空⽓中,最后使得温度⼀致更多的⼀些⽣活中的例⼦:1. 熵⼒的⼀个例⼦是⽿机线,我们将⽿机线整理好放进⼝袋,下次再拿出来已经乱了。
让⽿机线乱掉的看不见的“⼒”就是熵⼒,⽿机线喜欢变成更混乱。
2. 熵⼒另⼀个具体的例⼦是弹性⼒。
⼀根弹簧的⼒,就是熵⼒。
胡克定律其实也是⼀种熵⼒的表现。
3. 万有引⼒也是熵⼒的⼀种(热烈讨论的话题)。
4. 浑⽔澄清[1]于是从微观看,熵就表现了这个系统所处状态的不确定性程度。
⾹农,描述⼀个信息系统的时候就借⽤了熵的概念,这⾥熵表⽰的是这个信息系统的平均信息量(平均不确定程度)。
最⼤熵模型我们在投资时常常讲不要把所有的鸡蛋放在⼀个篮⼦⾥,这样可以降低风险。
在信息处理中,这个原理同样适⽤。
在数学上,这个原理称为最⼤熵原理(the maximum entropy principle)。
让我们看⼀个拼⾳转汉字的简单的例⼦。
假如输⼊的拼⾳是"wang-xiao-bo",利⽤语⾔模型,根据有限的上下⽂(⽐如前两个词),我们能给出两个最常见的名字“王⼩波”和“王晓波 ”。
⾄于要唯⼀确定是哪个名字就难了,即使利⽤较长的上下⽂也做不到。
当然,我们知道如果通篇⽂章是介绍⽂学的,作家王⼩波的可能性就较⼤;⽽在讨论两岸关系时,台湾学者王晓波的可能性会较⼤。







机器学习中的隐马尔可夫模型解析隐马尔可夫模型(Hidden Markov Model,HMM)是一种常用于描述随机过程的概率模型,在机器学习领域得到广泛应用。
本文将对隐马尔可夫模型的原理、应用以及解析方法进行详细介绍。
一、隐马尔可夫模型的基本原理隐马尔可夫模型由两个基本假设构成:马尔可夫假设和观测独立假设。
根据这两个假设,隐马尔可夫模型可以表示为一个五元组:(N, M, A, B, π),其中:- N表示隐藏状态的数量;- M表示观测状态的数量;- A是一个N×N的矩阵,表示从一个隐藏状态转移到另一个隐藏状态的概率;- B是一个N×M的矩阵,表示从一个隐藏状态生成一个观测状态的概率;- π是一个长度为N的向量,表示初始隐藏状态的概率分布。
在隐马尔可夫模型中,隐藏状态无法被直接观测到,只能通过观测状态的序列来进行推断。
因此,对于给定的观测状态序列,我们的目标是找到最有可能生成该序列的隐藏状态序列。
二、隐马尔可夫模型的应用领域隐马尔可夫模型在自然语言处理、语音识别、图像处理等领域得到广泛应用。
以下是几个常见的应用场景:1. 自然语言处理:隐马尔可夫模型可以用于词性标注、语法分析等任务,通过学习文本中的隐藏状态序列来提取语义信息。
2. 语音识别:隐马尔可夫模型可以用于音频信号的建模,通过观测状态序列推断出音频中的语音内容。
3. 图像处理:隐马尔可夫模型可以用于图像分割、目标跟踪等任务,通过学习隐藏状态序列来提取图像中的特征。
三、隐马尔可夫模型的解析方法解析隐马尔可夫模型有两个基本问题:评估问题和解码问题。
1. 评估问题:给定模型参数和观测状态序列,计算生成该观测序列的概率。
一种常用的解法是前向算法,通过动态规划的方式计算前向概率,即在第t个时刻观测到部分序列的概率。
2. 解码问题:给定模型参数,找到最有可能生成观测状态序列的隐藏状态序列。
一种常用的解法是维特比算法,通过动态规划的方式计算最大后验概率路径,即在第t个时刻生成部分观测序列的概率最大的隐藏状态路径。
隐马尔科夫模型学习总结by terry__feng 隐马尔科夫模型,这个久违的老朋友。
大三上学期在实验室的时候,由于实验室项目需用到语音识别,所以就使用了微软的Microsoft Speech SDK,也关注了一下语音识别的原理,其中有以HMM作为模型进行识别的。
后来实验室的机器人项目中上位机的软件使用到了人脸识别的功能。
实验室有关于识别的工程源代码,但是工程庞大,结构复杂,并且里面有很多没有用到的功能,并且程序经常莫名其妙的跑飞,还存在严重的内存泄露问题。
所以就自己另起炉灶,重新编写上位机软件。
其中的人脸识别用到的核心算法的代码就来源于这个工程。
它使用到的技术不是PCA和LDA,而是HMM和DCT。
那时候为了看明白HMM实现的原理,在图书馆看了关于模式识别的书,但有基本都是工程相关的,所以说原理性的知识牵扯的不多,自己也就是学习了大概,只是摸熟了里面使用到的各种牛逼的算法,比如Forward-backward,Viterbi,Baum-Welch。
但是各种算法原理的理解上就差得远了。
没有什么理论的基础,也不知如何学起,最终未能继续。
后来又通过吴军老师的《数学之美》了解到隐马尔科夫模型在语音识别中的重要作用。
时隔快两年了,从李航博士的《统计学习方法》中又看到了HMM模型的魅影,里面对其原理进行了深刻的剖析,能够学习之内心自是欣慰至极。
于是便花了几天的时间读了关于HMM的几章,现在算是有点收获,总结一下(大部分内容来自对吴军老师的《数学之美》和李航博士的《统计学习方法》的总结)。
文章主要包括信息传递模型、HMM模型简介,和对所使用的三个主要算法:前向后向算法、Baum-Welch算法和维特比算法进行了总结。
由于公式比较的多……所以生成pdf版的了。
1、信息传递的模型任何信息都是通过一定的媒介从一端传递到另一端。
对于信息源的传输者来说,其所需传输的序列可假设为S={s1,s2,s3,…,sn},而处于媒介另一端的观测者观测到的序列是O={o1,o2,o3,…,om}。
对于观测者来说,他接收到序列O的目的是为了明白传输者的意图,这样才能达到信息交流的目的。
也就是说,观测者能够做的事情就是使用观测到的数据(即序列O)去揣测传输者要传输的数据(即序列S)。
但是仅仅根据序列O能够揣测出来的序列S的可能性太多了,哪一个猜到的序列S是我们想要的呢?按照概率论的观点,我们可以把上面的问题建立数学模型。
P(S|O)=P(s1,s2,s3,…,s n|o1,o2,o3,…,o m)上式的意思是:对于一个给定的观测序列o1,o2,o3,…,o m,它的原序列是s1,s2,s3,…,s n的概率。
然而s1,s2,s3,…,s n的可能取值有很多,究竟哪一个才是自己想要的呢?所以便有了下面的式子:s1,s2,s3,…,s n=argmaxall s1,s2,s3,…,s nP(S|O)(1.1)也就是说找到概率最大的原序列,或者说是最有可能的原序列。
利用贝叶斯定理可以把上式转化得:P (S |O )=P(o 1,o 2,o 3,…,o m |s 1,s 2,s 3,…,s n )∙P(s 1,s 2,s 3,…,s n )P(o 1,o 2,o 3,…,o m ) (1.2)由于我们要求的是能够使猜测到的S 序列是合乎情理的可能性最大,所以说比较的是不同的S 序列,而与已经观测到的O 序列无关,所以由式1.1和1.2可得:s 1,s 2,s 3,…,s n =argmax all s 1,s 2,s 3,…,s nP(o 1,o 2,o 3,…,o m |s 1,s 2,s 3,…,s n )P(s 1,s 2,s 3,…,s n ) (1.3)2、 隐马尔科夫模型简介2.1 马尔科夫假设对于任意的状态序列{s 1,s 2,s 3,…,s n },它的某一状态出现的概率只与上一个状态有关。
就像预报天气一样,若要预报明天的天气,就仅与今天的天气作为参考,而不考虑昨天、前天或者更早的天气情况(当然这样不合理,但是确是简化的模型),称之为马尔科夫假设。
所以可以得到:P (s 1,s 2,s 3,…,s n )=∏P(s t |s t−1)n t(2.1) 2.2 独立输出假设对于任何一个可以观测到的状态o t ,它只与一个s t 的状态有关,而与其他的状态s 无关,称之为独立输出假设。
所以可以得到:P (o 1,o 2,o 3,…,o m |s 1,s 2,s 3,…,s n )=∏P(o t |s t )n t(2.2) 由式1.3,2.1,2.2可得:s 1,s 2,s 3,…,s n =argmax all s 1,s 2,s 3,…,s n P (o 1,o 2,o 3,…,o m |s 1,s 2,s 3,…,s n )P (s 1,s 2,s 3,…,s n ) =∏P(s t |s t−1)P(o t |s t )nt2.3 隐含马尔科夫“隐”的含义“隐”是针对观测者来说的。
因为观测真能够观测到的只有序列O ,而序列S 是看不到的,只能由观测值来揣测,再结合2.1和2.2所说的,所以称之为隐含马尔科夫模型。
2.4 隐含马尔科夫模型的例子(选自李航博士的《统计学习方法》P173,稍作修改)假设有4个盒子,Boxes={box1,box2,box3,box4},每个盒子里都装有红白两种颜色的球,Colors={color1,color2},有两个实验者A 和B (假设两个实验者未曾见面,只能通过电话联系)。
每个盒子里面球的个数为:Step1:实验者A从4个盒子里面以等可能的概率随机选取1个盒子,记录其盒子s1;接着从这个盒子里抽取一个球,然后通过电话告知B所抽取的球的颜色,B记录其颜色o1后,A将球放回原盒子中;Step2:A从当前的盒子转移到下一个盒子,按照下面的概率矩阵转移:s t;接着从这个盒子里抽取一个球,然后通过电话告知B所抽取的球的颜色,B记录其颜色o t后,A将球放回原盒子中;Step3:继续step2,直到记录到的球数达到n。
经过以上的三个步骤,对于A来说,得到了盒子的序列S={s1,s2,s3,…,s n};对于B来说,得到了球的观测序列O={o1,o2,o3,…,o n}。
我们现在的就假设站在B的立场上分析这个问题。
我们只得到了序列O(称为观测序列),而序列S(称为状态序列)对于我们来说是不知道的,所以我们称之为隐含的。
但是我们可以通过一定的模型来推断序列S的分布,继而求出最有可能的序列S,而这样的一个模型可以有很多种,但是一种简单的、容易计算的并且预测精度高的模型就非隐含马尔科夫模型莫属了。
3、隐马尔科夫模型接下来就来总结一下关于隐马尔科夫模型的定义。
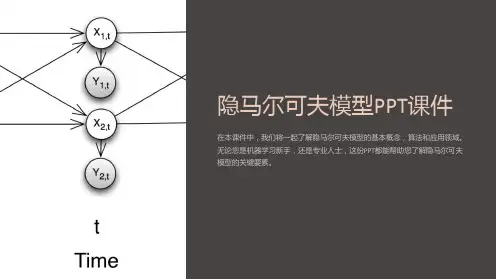
3.1 定义隐马尔科夫模型是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。
由隐马尔科夫链生成的状态随机序列称为状态序列(state sequence);每个状态生成一个观测,而由此产生的随机序列,称为观测序列(observation sequence)。
序列的每一个位置可以认为是一个时刻。
隐马尔科夫模型可以由初始概率分布、状态转移概率分布和观测概率分布确定。
隐马尔科夫模型的形式定义如下:设Q是所有可能的状态集合(N个状态),V是所有可能的观测的集合(M个观测)。
I是状态序列(长度T),O是对应的观测序列(长度T)。
A 是状态转移矩阵A =[a ij ]N×N ,其中a ij =P(i t+1=q j |i t =q i ),i =1,2,…,N;j =1,2,…,N 是在时刻t 处于q i 状态而在下一时刻t+1时刻处于q j 的概率。
B 是观测概率矩阵B =[b j (k)]N×M ,其中b j (k )=P(o t =v k |i t =q j ),k =1,2,…,M;j =1,2,…,N 是在时刻t 状态为q j 的条件下生成观测v k 的概率。
π是初始状态概率向量:π=(πi ),其中πi =P (i 1=q i ),i =1,2,…,N 是时刻t=1时处于状态q i 的概率。
隐马尔科夫模型就是有初始状态π、状态转移概率矩阵A 和观测概率矩阵B 决定的。
前两者确定了隐马尔科夫链,生成不可观测的状态序列,后者确定了如何从状态生成观测序列。
使用λ=(A,B,π)表示隐马尔科夫模型的参数。
例如2.4中提到的例子里面,状态集合Q 为四个盒子Boxes ,共4个状态;观测集合即为Colors ,共2个观测值;状态转移矩阵A 可由表2所得A=01000.400.6000.400.6000.50.5⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦;观测概率矩阵B 可有表1所得B=;初始状态π=。
3.2 3个基本问题1、概率计算问题给定模型λ=(A,B,π)和观测序列O =(o 1,o 2,…,o T ),计算在模型λ下观测序列O 出现的概率P(O|λ)。
2、学习问题已知观测序列O =(o 1,o 2,…,o T ),估计模型参数λ=(A,B,π)使得在该模型的参数下观测序列概率P(O|λ)最大。
即用极大似然估计的方法估计参数。
3、预测问题已知模型参数λ=(A,B,π)和观测序列O =(o 1,o 2,…,o T ),求在给定观测序列的情况下条件概率P(I|O)最大的状态序列I =(i 1,i 2,…,i T ),即给定观测序列,求最有可能对应的状态序列。
4、 概率计算问题我们首要的事情就是要解决概率计算的问题。
4.1 直接计算法此方法比较的简单,可以由下面的公式直接求得。
P (O |λ)=∑P(O,I|λ)I =∑P (O |I,λ)P (I |λ)I其中P (O |I,λ)=b i 1(o 1)b i 2(o 2)…b i T (o T )、P (I |λ)=πi 1a i 1i 2a i 2i 3…a i T−1i T 所以最终上式为: 0.50.50.30.70.60.40.80.2⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦()0.250.250.250.25TP (O |λ)=∑πi 1a i 1i 2b i 1(o 1)a i 2i 3b i 2(o 2)…a i T−1i T b i T (o T )i 1,i 2,…,i T但是此公式计算量大,因为I 的状态共有N 中,然后排列成长度为T 的序列,排法共有N T ,再加上式子之前的取和运算符,时间复杂度为O(TN T ),所以这种算法不可行。
4.2 前向算法这个算法将时刻t 的状态保存下来,然后利用递推的原理计算出地t+1时刻的状态,既而求出时刻T 的状态。
前向概率的定义:给定隐马尔科夫模型参数λ,定义到时刻t 部分观测序列o 1,o 2,…,o t 且状态为q i 的概率为前向概率,记作:αt (i )=P (o 1,o 2,…,o t ,i t =q i |λ)由上式可得,t+1时刻的前向概率为:αt+1(i )=[∑αt (j )a ji Nj=1]b i (o t+1)其中中括号里面表示的是时刻t 部分观测序列o 1,o 2,…,o t 且状态为q j 而时刻t+1时状态为q i 的联合概率,而乘以观测概率得到前向概率。