矢量量化技术
- 格式:pptx
- 大小:900.12 KB
- 文档页数:65

矢量量化编码1. 引言矢量量化是一种高效的数据压缩技术,它具有压缩比大、解码简单和失真较小等优点。
自从1980年提出矢量量化器(Vector Quantizater)码书设计的LBG算法[Linde et al(1980)]以来,矢量量化(Vector Quantization)技术[Gray(1984)]已经成功地应用到图像压缩和语音编码中。
矢量量化压缩中最核心的技术是码书的设计,码书的优化性直接影响到压缩效率和图像复原质量。
这里主要对码书设计算法进行讨论。
首先介绍了经典的LBG算法及其在图像压缩中的应用;然后,针对LBG算法的不足,结合图像处理的特点,提出了改进的覆盖聚类算法,有效改善了系统性能。
2 .码书的设计码书设计是矢量量化压缩系统的关键环节。
码书设计得越优化,矢量量化器的性能就越好。
实际中,不可能单独为每幅待编码的图像设计一个码书,因此通常是以一些代表性图像构成的训练集为基础,为一类图像设计一个最优码书。
从数学的观点看,矢量量化中的码书设计,实质是把系统的率失真函数看成目标函数,并使之在高维空间中成为最小的全局优化问题。
假设采用平方误差测度作为失真测度,训练集中的矢量数为M,目的是生成含N(N<M)个码字(码矢量)的码书。
码书设计过程就是寻求把M 个训练矢量分成N类的一种最佳方案(使均方误差最小),而把各类的质心矢量作为码书的码字。
可以证明,各种可能的码书个数为(1/ N!)Σ(一1)(N-i)CNiM,其中( 为组合数。
通过测试所有码书的性能可得到全局最优码书。
然而,在N 和M 比较大的情况下,搜索全部码书是根本不可能的。
为了克服这个困难,各种码书设计方法都采取搜索部分码书的方法得到局部最优或接近全局最优的码书。
因此,研究码书设计算法的目的就是寻求有效的算法尽可能找到全局最优或接近全局最优的码书以提高码书性能,并尽可能减少计算复杂度。
3 LBG算法描述经典的码书设计算法是LBG算法[它是Y.Linde,A.Buzo与R.M.Gray 在1980年推出的,其思想是对于一个训练序列,先找出其中心,再用分裂法产生一个初始码书A0,最后把训练序列按码书A0中的元素分组,找出每组的中心,得到新的码书,转而把新码书作为初始码书再进行上述过程,直到满意为止。

矢量量化在语音信号处理中的应用简介矢量量化是一种常用的数据压缩技术,旨在通过将连续信号离散化表示来减少数据传输和存储的成本。
在语音信号处理中,矢量量化广泛应用于语音编码、语音识别和语音合成等领域。
本文将深入探讨矢量量化在语音信号处理中的应用。
语音编码语音信号的特点为了更好地理解矢量量化在语音编码中的应用,首先需要了解语音信号的特点。
语音信号是一种时间连续的信号,具有较高的带宽要求和较低的信噪比。
此外,语音信号中的语音内容通常通过谐波周期、共振峰和无意义的噪声等特征进行表示。
矢量量化在语音编码中的角色在语音编码中,矢量量化被用于将连续的语音信号转换为离散表示,以实现对语音信号的压缩。
通过将语音信号分割成不同的时间段或频率帧,并将这些帧用离散的码矢量表示,矢量量化可以显著减少所需的传输和存储资源。
此外,矢量量化还能提供一种方式来描述和比较不同语音片段之间的相似性。
矢量量化的实现方法在语音编码中,有许多矢量量化的实现方法可供选择。
其中,最简单但性能相对较差的方法是基于均匀矢量量化。
该方法将矢量空间均匀划分为一系列子区域,并为每个子区域分配一个代表矢量。
然而,由于语音信号的非均匀分布特性,均匀矢量量化的效果有限。
为了克服均匀矢量量化的不足,研究人员提出了一些更高级的方法,如聚类算法和向量量化树。
聚类算法将语音帧分成几个类别,并为每个类别分配一个代表矢量。
而向量量化树则是一种层次结构,通过递归地将帧分成更小的子集,并为每个叶子节点分配一个代表矢量。
这些方法相对于均匀矢量量化能够更好地适应语音信号的分布特性,从而提高编码效果。
矢量量化的应用实例矢量量化在语音编码中的应用有很多,以下是一些常见的实例:1.无损压缩:通过高效地将连续语音信号转换为离散表示,矢量量化可以实现对语音信号的无损压缩。
这种压缩方法无需对语音信号进行任何信息损失,因此在一些对语音质量要求较高的应用中非常有用。
2.语音传输:矢量量化能够显著减少语音信号传输所需的带宽和存储资源。




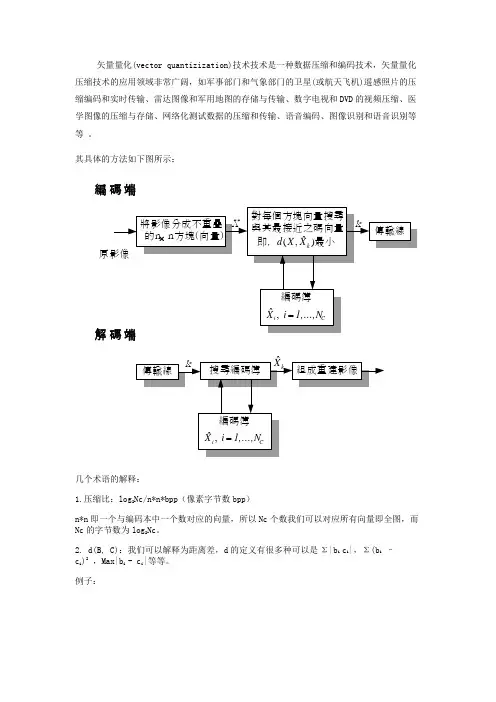
矢量量化(vector quantizization)技术技术是一种数据压缩和编码技术,矢量量化压缩技术的应用领域非常广阔,如军事部门和气象部门的卫星(或航天飞机)遥感照片的压缩编码和实时传输、雷达图像和军用地图的存储与传输、数字电视和DVD 的视频压缩、医学图像的压缩与存储、网络化测试数据的压缩和传输、语音编码、图像识别和语音识别等等 。
其具体的方法如下图所示:
几个术语的解释:
1.压缩比:log 2Nc/n*n*bpp (像素字节数bpp )
n*n 即一个与编码本中一个数对应的向量,所以Nc 个数我们可以对应所有向量即全图,而Nc 的字节数为log 2Nc 。
2. d(B, C):我们可以解释为距离差,d 的定义有很多种可以是Σ|b i c i |,Σ(b i – c i )2 ,Max|b i - c i |等等。
例子:
編碼端解
由上图我们可以看到左边为原图像,而右边为编码本。
例如我们可以讲原图像以如图所示的方式分为若干个有四个量的向量如(100,100,80,80)其余编码本中的
(100,100,90,90)计算的d (X ,Xk )最小故我们可以用数字k 表示向量
(100,100,80,80)。
其实我们可以理解为矢量量化就是讲图像中分割成若干的小块,然后再将小块分类,一类用一个码表示。
下面是一个我论文中看到的也是最常用的VQ 算法:LBG 算法也叫K 平均分类算法。
以下是步骤:
当然我们可以设置一个收敛的条件,这个可以根据自己需求设置ε大小,当到达某一步 时 收敛即迭代结束。
ε≤---)1()1(l l l D D
D。


第四章矢量量化1、矢量量化?(VQ)是1956年由steinhaus首次提出的,1970年代后期发展起来的数据压缩和编码技术。
它主要应用于:语音编码、语音合成、语音识别和说话人识别。
矢量量化在语音信号处理中占有重要地位。
2、标量量化和矢量量化?✓标量量化:是对标量进行量化,即一维的矢量量化。
将动态范围分成若干个小区间,每小区间有一个代表值。
当输入信号落入某区间时,量化成该代表值。
✓矢量量化:是对矢量进行量化。
将矢量空间分成若干个小区域,每小区域有一个代表矢量。
当输入矢量落入某区域时,量化成该代表矢量。
矢量量化是标量量化的发展。
矢量量化总是优于标量量化,维数越高,性能越优越。
矢量量化有效利用各分量间的互相关性。
1970年代末,Linde,Buzo,Gray和Markel等人首次解决了矢量量化码书生成的方法,并首先将矢量量化用于语音编码获得巨大成功。
如,在语音通信方面,将在原来编码速率为2.4kbit/s的线性预测声码器基础上,将每帧的10个反射系数加以10维的矢量量化,就可使编码速率降低到800bit/s,而声音质量基本未下降。
又如分段声码器,由于采用矢量量化,可以使数码率降低到150bit/s。
3、矢量量化的基本原理?标量量化是对信号的单个样本或参数的幅度进行量化;标量是指被量化的变量,为一维变量。
矢量量化的过程是将语音信号波形的K个样点的每一帧,或有K个参数的每一参数帧构成K维空间的一个矢量,然后对这个矢量进行量化。
标量量化可以说是K=1的矢量量化。
矢量量化的过程和标量量化过程相似。
在标量量化时,在一维的零至无穷大值之间设置若干个量化阶梯,当某输入信号的幅度值落在某相邻的两个量化阶梯之间时,就被量化成两阶梯的中心值。
而在矢量量化时,则将K维无限空间划分为M 个区域边界,然后将输入矢量与这些边界进行比较,并被量化为“距离”最小的区域边界的中心矢量值。
矢量量化的定义将信号序列{}i y 的每K 个连续样点分成一组,形成K 维欧氏空间中的一个矢量,矢量量化就是把这个K 维输入矢量X 映射成另一个K 维量化矢量。

矢量量化有损压缩是利用人眼的视觉特性有针对地简化不重要的数据,以减少总的数据量。
量化是有损数据压缩中常用的技术。
量化可以分为两种,即标量量化与矢量量化。
标量量化每次只量化一个采样点。
而矢量量化在量化时用输出组集合中最匹配的一组输出值来代替一组输入采样值。
根据香农的速率-失真理论,即使信源是无记忆的,利用矢量编码代替标量编码总能在理论上得到更好的性能,矢量量化可以看作标量量化的推广。
基本的矢量量化器编码,传输与解码过程如图所示。
矢量量化编码器根据一定的失真测度在码书中搜索出与输入矢量最匹配的码字。
传输时仅传输该码字的索引。
解码过程很简单,只要根据接收到的码字索引在码书中查找该码字,并将它作为输入矢量的重构矢量。
码字匹配信道查表信宿信源码书码书输入矢量索引索引编码器解码器输出矢量矢量量化编码和解码示意图假定码书}|,,,{110k j N R C ∈=-y y y y ,其中N 为码书的大小,而k 维输入矢量T k x x x ),,(110-= x 与码字T k j j j j y y y ),,()1(10-= y 之间的失真测度采用平方误差测度来表示,即:22210)(),(jjl k l l j y x d y x y x -=-=∑-=则矢量量化码字搜索问题就是在码书C 中搜索与输入矢量x 最匹配的码字bm y ,使得bm y 与x 之间的失真是所有码字中最小的,即:),(min ),(10bm N bm bm d d y x y x -≤≤= 全搜索算法(FS )是一种最原始、最直观的码字搜索算法,它需要计算输入矢量与所有码字之间的失真,并通过比较找出失真最小的码字。
由于FS 算法每次失真计算需要k 次乘法,12-k 次加法,故为了对矢量进行编码需要Nk 次乘法,)12(-k N 次加法和1-N 次比较运算。
而FS 算法的计算复杂度是由码书的大小和矢量维数决定,而高效率矢量量化编码系统往往采用大码书和高维矢量,这时计算复杂度是非常大的,故减少码字搜索的计算负担是非常必要的,必须寻求快速有效的码字搜索算法。

矢量量化在语音信号处理中的应用矢量量化是一种常用的数据压缩技术,它在语音信号处理中也有广泛的应用。
本文将详细介绍矢量量化在语音信号处理中的应用。
一、矢量量化概述矢量量化是将一个连续的信号空间映射到一个离散的码本空间的过程。
这个过程可以看作是对原始信号进行压缩,以便于存储和传输。
在语音信号处理中,矢量量化可以用来压缩语音信号,并且可以保证压缩后的信号质量不会太差。
二、矢量量化在语音编码中的应用1. 语音编码语音编码是指将语音信号转换为数字形式,以便于存储和传输。
在传统的PCM编码中,每个采样点都被分配一个固定长度的位数来表示其幅度值。
但是这种编码方式占据了大量存储空间和带宽资源。
而使用矢量量化技术可以将采样点分组,并且每组采样点都被映射到一个码本向量中,从而实现对采样点进行压缩。
2. 说话人识别说话人识别是指通过对语音信号的分析,识别说话人的身份。
在说话人识别中,矢量量化可以用来提取语音信号的特征向量,并将其映射到一个码本中。
这个码本可以用来训练模型,从而实现对不同说话人的识别。
3. 语音合成语音合成是指通过计算机程序生成一段类似于人类语音的声音。
在语音合成中,矢量量化可以用来对原始语音信号进行压缩,并且可以保证生成的声音质量不会太差。
三、矢量量化在语音增强中的应用1. 降噪降噪是指从含有噪声的语音信号中去除噪声。
在降噪过程中,矢量量化可以用来对原始信号进行压缩,并且可以保证去除噪声后的信号质量不会太差。
2. 声学回声消除声学回声消除是指从含有回声的语音信号中去除回声。
在回声消除过程中,矢量量化可以用来对原始信号进行压缩,并且可以保证去除回声后的信号质量不会太差。
四、总结总之,矢量量化在语音信号处理中有着广泛的应用,包括语音编码、说话人识别、语音合成、降噪和声学回声消除等方面。
通过使用矢量量化技术,可以实现对语音信号的压缩和特征提取,并且可以保证处理后的信号质量不会太差。
如何进行矢量化处理矢量化处理是一种数字图形处理技术,通过将图像转换为由数学方程描述的矢量图形,可以获得更加清晰、精确和可伸缩的图像效果。
在今天的数字时代,矢量化处理不仅仅是艺术设计师的重要工具,也成为了许多行业领域必备的技能。
无论是从事建筑设计、工程绘图、包装设计,还是进行数据分析和图形可视化,矢量化处理都能发挥出巨大的作用。
在进行矢量化处理之前,首先需要清楚地了解什么是矢量图形和像素图形。
像素图形是由一个个像素点组成的位图,每个像素点都有其特定的颜色和坐标值。
而矢量图形则由点、线、面构成,通过数学方程来描述其形状和属性。
相比之下,矢量图形具有无损编缉、缩放不失真等特点,因此在处理图像或设计复杂形状时,矢量化处理是非常重要的环节。
如何进行矢量化处理呢?首先,需要选择适当的矢量化处理软件。
市面上有许多功能强大的矢量化处理软件,比如Adobe Illustrator、CorelDRAW等。
这些软件不仅提供了丰富的工具和功能,还具备友好的用户界面和操作性能,能够满足各类用户的需求。
其次,在进行矢量化处理之前,需要对图像进行预处理。
这可以包括去除噪点、平滑边缘、调整对比度等操作,以便更好地捕捉图像的细节和形状。
此外,还可以使用图像分割技术将图像分割为不同的区域,便于后续的矢量化处理。
接着,选择合适的矢量化处理方法。
常见的矢量化处理方法包括自动追踪、手动描点和贝塞尔曲线等。
自动追踪是最常用的方法,它可以根据图像的边界自动捕捉形状,并生成相应的矢量图形。
手动描点则需要用户手动勾勒图形的轮廓,更加精确但也更加耗时。
贝塞尔曲线是一种数学曲线,通过控制点来刻画复杂的曲线形状,是设计师常用的矢量化处理方法。
在进行矢量化处理时,需要注意一些技巧和注意事项。
首先,要合理选择颜色模式和精度。
一般来说,RGB模式适用于屏幕显示,CMYK模式适用于印刷。
而精度的选择需要权衡处理速度和精确度,过高的精度可能会导致处理时间过长。
矢量量化矢量量化(VQ —Vector Quantization)是70年代后期发展起来的一种数据压缩技术基本思想:将若干个标量数据组构成一个矢量,然后在矢量空间给以整体量化,从而压缩了数据而不损失多少信息矢量量化编码也是在图像、语音信号编码技术中研究得较多的新型量化编码方法,它的出现并不仅仅是作为量化器设计而提出的,更多的是将它作为压缩编码方法来研究的。
在传统的预测和变换编码中,首先将信号经某种映射变换变成一个数的序列,然后对其一个一个地进行标量量化编码。
而在矢量量化编码中,则是把输入数据几个一组地分成许多组,成组地量化编码,即将这些数看成一个k维矢量,然后以矢量为单位逐个矢量进行量化。
矢量量化是一种限失真编码,其原理仍可用信息论中的率失真函数理论来分析。
而率失真理论指出,即使对无记忆信源,矢量量化编码也总是优于标量量化。
在矢量量化编码中,关键是码本的建立和码字搜索算法。
码本的生成算法有两种类型,一种是已知信源分布特性的设计算法;另一种是未知信源分布,但已知信源的一列具有代表性且足够长的样点集合(即训练序列)的设计算法。
可以证明,当信源是矢量平衡且遍历时,若训练序列充分长则两种算法是等价的。
码字搜索是矢量量化中的一个最基本问题,矢量量化过程本身实际上就是一个搜索过程,即搜索出与输入最为匹配的码矢。
矢量量化中最常用的搜索方法是全搜索算法和树搜索算法。
全搜索算法与码本生成算法是基本相同的,在给定速率下其复杂度随矢量维数K以指数形式增长,全搜索矢量量化器性能好但设备较复杂。
树搜索算法又有二叉树和多叉树之分,它们的原理是相同的,但后者的计算量和存储量都比前者大,性能比前者好。
树搜索的过程是逐步求近似的过程,中间的码字是起指引路线的作用,其复杂度比全搜索算法显著减少,搜索速度较快。
由于树搜索并不是从整个码本中寻找最小失真的码字,因此它的量化器并不是最佳的,其量化信噪比低于全搜索。