中文词性标注集
- 格式:docx
- 大小:13.82 KB
- 文档页数:3

浅谈《现代汉语词典》(第五版)词性标注的几个问题摘要:本文主要从功能的角度对《现代汉语词典》(第五版)的词性标注进行了初步的探索,主要涉及词性标注及其与释义和配例相一致、兼类词的释义等几个方面的问题,对《现汉》(五)的成功和不足之处作了一定说明。
关键词:《现代汉语词典》(第五版)词性标注释义《现代汉语词典》是目前国内最有影响的语文辞书之一。
对现代汉语词典质量产生影响的根本性因素,是词典的释义问题。
一、《现代汉语词典》(第五版)词性标注现代汉语词典标注词性,给汉语教学、用户的学习和使用和中文信息处理等带来了很大的方便。
标注词性必须要对词类系统和词与非词进行界定。
科学的给词归类,主要根据词的语法功能。
陆俭明提出的词类划分标准是:1、词充当句法成分的功能,2、词跟词结合的功能,3、词表示类别的功能,即语法意义。
《现代汉语词典》(第5版)依据的词类是中学语文课本的教学词类系统,是比较科学的。
如:集成:【动】同类著作汇集在一起(多用做书名):《丛书~》|《中国古典戏曲论著~》。
(《现汉》(五)p592)集锦:【名】编辑在一起的精彩的图画、诗文等(多用做标题):图片~|邮票~。
(《现汉》(五)p593)《现代汉语词典》(第5版)中的“集成”与“集锦”根据配例来看,“丛书集成”、“图片集锦”、“邮票集锦”,二者看似相同,但是语法意义不同。
根据“语料库在线”的检索结果,“集成”66条例句中,17个做谓语例句,13个做定语例句,且能带宾语;“集锦”6条例句中5个做中心语。
前者语法意义表示事物的动作、行为或变化、存在,后者的语法意义表示事物名称。
所以二者词性标注不同。
另外,在根据功能判断词性的基础上,也不能完全脱离意义。
“集成”与“集锦”词汇意义也不同,“集:1.集合;聚集”(《现汉》(五)p639),“成:3.【动】成为;变为”(《现汉》(五)p171),“集成”有“汇集成为”的意思,释义行文体现为动词性。
“锦:有彩色花纹的丝织品”(《古汉语常用字字》p150),这里应为比喻义,指美好的东西,所以“集锦”释义行文应体现为名词性。

中⽂词性标注与viterbi算法⼀、viterbi算法原理及适⽤情况当事件之间具有关联性时,可以通过统计两个以上相关事件同时出现的概率,来确定事件的可能状态。
以中⽂的词性标注为例。
中⽂中,每个词会有多种词性(⽐如"希望"即是名字⼜是动词),给出⼀个句⼦后,我们需要给这个句⼦的每个词确定⼀个唯⼀的词性,实际上也就是在若⼲词性组合中选择⼀个合适的组合。
动词、名词等词类的搭配是具有规律性的,⽐如动词+名词的形式是⼤量存在的,当我们看到句⼦"存在希望",如果确定了"存在"是动词,那么由于动名词组合的概率较⼤,我们就会认定"希望"是名词。
viterbi算法的原理就是基于此。
我们需要计算所有的名词+动词,名词+名词,动词+形容词。
等各种种词性搭配的出现概率,然后从中选出最⼤概率的组合。
⼆、操作步骤1、需要准备⼀个语料库,包含已经正确标注了词性的⼤量语句。
2、对语料库的内容进⾏统计。
需要得到以下数据。
(1)所有可能的词性。
(2)所有出现的词语。
(3)每个词语以不同词性出现的次数。
(4)记录句⾸词为不同词性的次数。
(5)记录句⼦中任⼀两种词性相邻的次数(如遇到:"看电影"这个句⼦,则有[动词][名词]的值加⼀。
3、针对前⾯统计的结果,进⾏分析计算。
需计算以下数据。
(1)计算每类词性作为句⾸出现的⽐例(⽐如:动词为句⾸,占所有不同词性为句⾸中的⽐例),记录到fstart[TYPE_NUM]。
(2)计算后词固定为词性[n]时,前词为词性[x]占总情况的⽐例(如:后词固定为[动词]时,前词[名词]出现的次数占所有[x][动词]的⽐例),记录到fshift[TYPE_NUM][TYPE_NUM];(3)计算每⼀个词作为不同类词性出现的次数,占所有该类词出现总数的⽐例(如:"中国"作为名词出现的次数占所有名词的⽐例),记录到ffashe[TYPE_NUM][60000]4、输⼊句⼦进⾏词性标注输⼊的句⼦中每个词有多个词性。


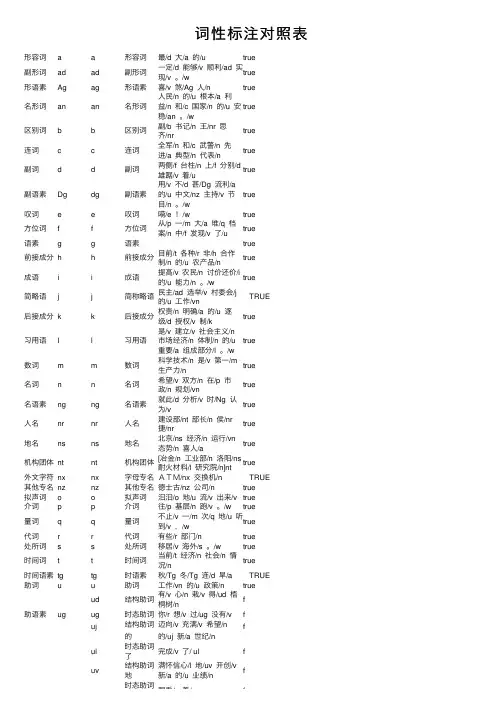
词性标注对照表形容词a a形容词最/d ⼤/a 的/u true副形词ad ad副形词⼀定/d 能够/v 顺利/ad 实现/v 。
/wtrue形语素Ag ag形语素喜/v 煞/Ag ⼈/n true名形词an an名形词⼈民/n 的/u 根本/a 利益/n 和/c 国家/n 的/u 安稳/an 。
/wtrue区别词b b区别词副/b 书记/n 王/nr 思齐/nrtrue连词c c连词全军/n 和/c 武警/n 先进/a 典型/n 代表/ntrue副词d d副词两侧/f 台柱/n 上/f 分别/d雄踞/v 着/utrue副语素Dg dg副语素⽤/v 不/d 甚/Dg 流利/a的/u 中⽂/nz 主持/v 节⽬/n 。
/wtrue叹词e e叹词嗬/e !/w true⽅位词f f⽅位词从/p ⼀/m ⼤/a 堆/q 档案/n 中/f 发现/v 了/utrue语素g g语素 true前接成分h h前接成分⽬前/t 各种/r ⾮/h 合作制/n 的/u 农产品/ntrue成语i i成语提⾼/v 农民/n 讨价还价/i的/u 能⼒/n 。
/wtrue简略语j j简称略语民主/ad 选举/v 村委会/j的/u ⼯作/vnTRUE后接成分k k后接成分权责/n 明确/a 的/u 逐级/d 授权/v 制/ktrue习⽤语l l习⽤语是/v 建⽴/v 社会主义/n市场经济/n 体制/n 的/u重要/a 组成部分/l 。
/wtrue数词m m数词科学技术/n 是/v 第⼀/m⽣产⼒/ntrue名词n n名词希望/v 双⽅/n 在/p 市政/n 规划/vntrue名语素ng ng名语素就此/d 分析/v 时/Ng 认为/vtrue⼈名nr nr⼈名建设部/nt 部长/n 侯/nr捷/nrtrue地名ns ns地名北京/ns 经济/n 运⾏/vn态势/n 喜⼈/atrue机构团体nt nt机构团体[冶⾦/n ⼯业部/n 洛阳/ns耐⽕材料/l 研究院/n]nttrue外⽂字符nx nx字母专名ATM/nx 交换机/n TRUE 其他专名nz nz其他专名德⼠古/nz 公司/n true拟声词o o拟声词汩汩/o 地/u 流/v 出来/v true介词p p介词往/p 基层/n 跑/v 。

汉语文本词性标注标记集的规范汉语文本词性标注标记集的规范代码名称帮助记忆的诠释 Ag 形语素形容词性语素。
形容词代码为a,语素代码g前面置以A。
a 形容词取英语形容词adjective的第1个字母。
ad 副形词直接作状语的形容词。
形容词代码a和副词代码d并在一起。
an 名形词具有名词功能的形容词。
形容词代码a和名词代码n并在一起。
b 区别词取汉字“别”的声母。
c 连词取英语连词conjunction的第1个字母。
Dg 副语素副词性语素。
副词代码为d,语素代码g前面置以D。
d 副词取adverb的第2个字母,因其第1个字母已用于形容词。
e 叹词取英语叹词exclamation的第1个字母。
f 方位词取汉字“方” g 语素绝大多数语素都能作为合成词的“词根”,取汉字“根”的声母。
h 前接成分取英语head的第1个字母。
i 成语取英语成语idiom的第1个字母。
j 简称略语取汉字“简”的声母。
k 后接成分 l 习用语习用语尚未成为成语,有点“临时性”,取“临”的声母。
m 数词取英语numeral的第3个字母,n,u已有他用。
Ng 名语素名词性语素。
名词代码为n,语素代码g前面置以N。
n 名词取英语名词noun的第1个字母。
nr 人名名词代码n和“人(ren)”的声母并在一起。
ns 地名名词代码n和处所词代码s 并在一起。
nt 机构团体“团”的声母为t,名词代码n和t并在一起。
nz 其他专名“专”的声母的第1个字母为z,名词代码n和z并在一起。
o 拟声词取英语拟声词onomatopoeia的第1个字母。
p 介词取英语介词prepositional的第1个字母。
q 量词取英语quantity的.第1个字母。
r 代词取英语代词pronoun的第2个字母,因p已用于介词。
s 处所词取英语space的第1个字母。
Tg 时语素时间词性语素。
时间词代码为t,在语素的代码g前面置以T。

CTB词性标注指南第一章引言中文几乎没有屈折语素。
譬如,词语不随时态、格、人称和数量而曲折变化。
因此,对特定文本中的词进行词性标注往往都很困难。
这个文件是专为宾州中文树库项目[XPS+00]所设计的。
这个项目的目标是构建一个十万词的有语法托架的中文官话文本语料库。
标注包括两个步骤:第一阶段是中文分词和词性标注,第二阶段是句法托架。
每个步骤包括至少两个经过,即数据库由一个标注者标注,结果文件由另一个标注者检查。
词性标注指南,就如分词指南和托架指南,在项目进行过程中已经修订了多次。
到目前为止,我们已经在我们的网站上发行了三个版本:第一部草作完成于1998年12月,在第一个中文分词和词性标注文件发行后;第二部草作完成于1999年3月,在第二个中文分词和词性标注文件发行后;这个文件,是第三部草作,修订于第二个托架文件发行后。
在这个第三部草作中,与前两部草作相比,主要改变在于:(1)我们增加了一章引言来解释指南中存在的一些基本原理;(2)我们增加了对中文词语的注释;(3)我们把这个指南写成了一个技术性报告,报告被发表于宾夕法尼亚大学认知科学研究机构(IRCS)。
1.1 标注标准词性标注(POS)的核心问题是词性标注是否应该基于意义或者句法分布来标注。
这个问题自1950年以来就被热烈争论到现在,并且始终存在两种不同的观点。
譬如,中文词“毁灭”可以被翻译为英文中的destroy或destroys或destroyed或destroying或destruction,并且如它英文所对应的词一样使用。
根据第一种观点,词性标注应该只基于意义。
因为词的意义在它所有的用法中基本都是一样的,它就应该总是被标注为一个动词。
第二种观点是词性标注应该由词的句法分布来决定。
当“毁灭”是一个名词短语的首词,它在那个文本中就应该被标注为一个名词;当“毁灭”是一个动词短语的首词,它就应该被标注为一个动词。
我们选择了句法分布作为我们词性标注的主要标准,因为这与当代语言学理论所采纳的原则一致,譬如X-bar理论和GB理论中的首字投射概念。


湖南文理学院课程设计报告课程名称:计算机软件技术基础系部:电信系专业班级:通信工程T09103班学生姓名:刘程程指导教师:完成时间:2011.12.28报告成绩:目录中文摘要 (I)ABSTRACT (II)第一章引言 (1)1.1背景和意义 (1)1.2词性标注定义及其困难 (1)1.2.1词性的定义 (2)1.2.2词性标注的难点 (2)第二章基础理论介绍 (3)2.1隐马尔科夫模型(H1DDEN M ARKOV M ODEL,HM) (3)2.2HMM用于词性标注 (4)第三章改进HMM标注模型与参数估计 (4)3.1改进HMM模型词性标注 (4)3.2参数估计 (5)3.2.1训练语料库 (5)3.2.2当用数据库 (5)第四章改进VITERBI算法标注 (7)4.1标注过程 (7)4.2改进后的V ITERBI算法的具体描述 (7)第五章实验结果与分析 (8)5.1评价标准 (8)5.2实验结果 (9)5.3错误分析 (10)参考文献 (11)中文摘要汉语词性标注是中文信息处理技术中的一项基础性课题。
一方面,它的研究成果可以直接融入到信息抽取、信息检索、机器翻译等诸多实际应用系统当中;另一方面,汉语自动词性标注也是汉语语块识别器、汉语句法分析器、汉语语义分析器必不可少的前端处理工具。
因此,研究和实现汉语词性标注器具有重要的理论意义和实用价值。
词性标注的方法主要有基于规则和基于统计的两大类。
由于基于统计的方法具有不需要人工总结语言学规则、正确识别率高等优点,已逐渐成为研究的热点。
在基于统计的方法中,隐马尔科夫模型是最主要的算法模型之一。
在本文中,我们以汉语的词性自动标注为研究对象,提出了一种基于改进的隐马尔科夫模型汉语词性标注方法。
该方法在原有隐马尔科夫模型的基础上,加入了更多的上下文信息,用于汉语词性的自动标注问题,取得了较好的效果。
主要的研究内容有以下几方面: 1.虽然隐马尔科夫模型有很好的标注效果,但是它在对当前词词语出现概率的估计只与其词性有关。


chinese-annotator用法概述及解释说明1. 引言1.1 概述在当今信息爆炸的时代,自然语言处理(Natural Language Processing, NLP)技术的发展越来越受到关注。
其中,中文标注工具(Chinese-annotator)作为一种重要的自然语言处理工具,在文本标注、实体识别、关系抽取等任务中发挥着重要作用。
本文旨在对Chinese-annotator的使用方法进行概述和解释说明,帮助读者更好地理解和应用该工具。
1.2 文章结构本文共分为五个部分。
首先是引言部分,介绍了本文的目的和结构。
第二部分是对Chinese-annotator的介绍,包括其简介、使用场景和主要功能。
第三部分是对各个功能进行详细解释说明。
第四部分通过示例应用来展示在不同场景下如何使用Chinese-annotator解决问题。
最后一部分是结论,总结了文章中的主要观点和发现,并展望了未来研究方向或应用前景。
1.3 目的本文旨在提供一个清晰、全面的Chinese-annotator 的用法概述,帮助初学者更快速上手并有效利用该工具进行中文文本处理。
通过深入了解Chinese-annotator 的不同功能和使用场景,读者将能够在各种实际应用中更好地应用该工具,并提升处理文本数据的效率和准确性。
同时,本文也将展示Chinese-annotator 在特定领域下的实例应用,为读者提供具体操作指导和灵感思路。
通过本文的阐述,读者将对Chinese-annotator有一个全面且清晰的认识,从而为自然语言处理相关项目或研究提供有力支持和指导。
2. Chinese-annotator用法:2.1 简介Chinese-annotator是一个功能强大的中文注释器工具,它可以帮助用户分析和理解中文文本。
通过使用Chinese-annotator,用户可以对中文文本进行实体命名识别、关键词提取、情感分析等一系列智能处理。
自然语言处理中的词性标注与句法分析自然语言处理(Natural Language Processing,简称NLP)是人工智能领域中的一个重要分支,主要研究如何让计算机能够理解、处理和生成人类语言。
在NLP领域中,词性标注与句法分析是两个重要的任务,它们可以帮助计算机更好地理解和处理自然语言。
本文将介绍词性标注与句法分析的基本概念、常见方法以及应用场景,并探讨它们在NLP领域的意义和作用。
一、词性标注词性标注(Part-of-Speech Tagging,简称POS Tagging)是NLP领域中的一个基础任务,其主要目标是为一个句子中的每个单词确定其词性。
词性标注可以帮助计算机理解句子的结构和含义,从而更好地进行后续处理和分析。
词性标注通常使用词性标记集合(如标注集)来标注每个单词的词性,常见的标注集包括Penn Treebank标注集、Universal标注集等。
词性标注的方法主要包括基于规则的方法和基于统计的方法。
基于规则的方法通过定义一系列的语法规则和模式来确定单词的词性,但这种方法需要大量的人工设置和维护规则,且适用性有限。
而基于统计的方法则是通过学习语料库中单词与其词性之间的统计关系来确定单词的词性,常见的统计方法包括隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)等。
词性标注在NLP领域中有着广泛的应用,例如在文本分类、信息检索和机器翻译等任务中都需要对文本进行词性标注来帮助计算机理解和处理文本。
此外,词性标注也可以作为更复杂的NLP任务的预处理步骤,如句法分析、语义分析等。
二、句法分析句法分析(Syntactic Parsing)是NLP领域中的另一个重要任务,其主要目标是确定一个句子的句法结构,即句子中单词之间的语法关系。
句法分析可以帮助计算机理解句子的结构和含义,从而更好地进行后续处理和分析。
第 54 卷第 8 期2023 年 8 月中南大学学报(自然科学版)Journal of Central South University (Science and Technology)V ol.54 No.8Aug. 2023基于BiLSTM-CRF 的中文分词和词性标注联合方法袁里驰(江西财经大学 软件与物联网工程学院,江西 南昌,330013)摘要:针对中文分词、词性标注等序列标注任务,提出结合双向长短时记忆模型、条件随机场模型和马尔可夫族模型或树形概率构建的中文分词和词性标注联合方法。
隐马尔可夫词性标注方法忽略了词本身到词性的发射概率。
在基于马尔可夫族模型或树形概率的词性标注中,当前词的词性不但与前面词的词性有关,而且与当前词本身有关。
使用联合方法有助于使用词性标注信息实现分词,有机地将两者结合起来有利于消除歧义和提高分词、词性标注任务的准确率。
实验结果表明:本文使用的中文分词和词性标注联合方法相比于通常的双向长短时记忆模型−条件随机场分词模型能够大幅度提高分词的准确率,并且相比于传统的隐马尔可夫词性标注方法能够大幅度提高词性标注的准确率。
关键词:双向长短时记忆模型;中文分词;词性标注;马尔可夫族模型;树形概率中图分类号:TP391.1 文献标志码:A 文章编号:1672-7207(2023)08-3145-09A joint method for Chinese word segmentation and part-of-speech tagging based on BiLSTM-CRFYUAN Lichi(School of Software and Internet of Things Engineering, Jiangxi University of Finance and Economics,Nanchang 330013,China)Abstract: For sequence tagging tasks such as Chinese word segmentation and part-of-speech tagging, a joint method for Chinese word segmentation and part-of-speech tagging that combines BiLSTM(bi-directional long-short term memory model), CRF(conditional random field model), Markov family model(MFM) or tree-like probability(TLP) was proposed. Part-of-speech tagging method based on HMM(hidden markov model) ignores the emission probability of the word itself to the part-of-speech. In part-of-speech tagging based on MFM or TLP, the part-of-speech of the current word is not only related to the part-of-speech of the previous word, but also related to the current word itself. The use of the joint method helps to use part-of-speech tagging information to achieve word segmentation, and organically combining the two is beneficial to eliminate ambiguity and improve the收稿日期: 2023 −02 −20; 修回日期: 2023 −03 −24基金项目(Foundation item):国家自然科学基金资助项目(61962025,61562034) (Projects(61962025, 61562034) supported by theNational Natural Science Foundation of China)通信作者:袁里驰,博士,教授,从事自然语言处理研究;E-mail :*****************DOI: 10.11817/j.issn.1672-7207.2023.08.018引用格式: 袁里驰. 基于BiLSTM-CRF 的中文分词和词性标注联合方法[J]. 中南大学学报(自然科学版), 2023, 54(8): 3145−3153.Citation: YUAN Lichi. A joint method for Chinese word segmentation and part-of-speech tagging based on BiLSTM-CRF[J]. Journal of Central South University(Science and Technology), 2023, 54(8): 3145−3153.第 54 卷中南大学学报(自然科学版)accuracy of word segmentation and part-of-speech tagging tasks. The results show that the joint method of Chinese word segmentation and part-of-speech tagging used in this paper can greatly improve the accuracy of word segmentation compared with the usual word segmentation model based on BiLSTM-CRF, and it can also greatly improve the accuracy of part-of-speech tagging compared with the traditional part-of-speech tagging method based on HMM.Key words: bi-directional long-short term memory model; Chinese word segmentation; part-of-speech tagging; Markov family model; tree-like probability分词的目的是将一个完整的句子切分成词语级别。